深度学习笔记
目录
- TensorBoard的使用
- Transforms的使用
- TorchVision中数据集的使用
- Dataloader的使用
- 卷积操作
- 神经网络-卷积层
- 最大池化
- 非线性激活
- 线性层
- 小型网络搭建和Sequential使用
- 损失函数与反向传播
- 优化器
- 网络模型的使用及修改
- 完整模型的训练
- 利用gpu训练
- 模型验证
- 自动求导
- 线性神经网络
-
- 线性回归
- 基础优化算法
- 线性回归的从零开始实现
- 线性回归的简洁实现
- softmax回归
- 图像分类数据集
- softmax回归的从零开始实现
- softmax回归的简洁实现
- 多层感知机
-
- 多层感知机
- 多层感知机的从零开始实现
- 多层感知机的简洁实现
- 模型选择、欠拟合和过拟合
- 权重衰退
- 权重衰退的从零开始实现和简洁实现
- 丢弃法(Dropout)
- 丢弃法的从零开始实现和简洁实现
- 数值稳定性和模型初始化
- 深度学习计算
- 卷积神经网络
- 深度卷积神经网络
-
- AlexNet
- VGG
- NiN模型
- GoogLeNet
- BatchNorm
- ResNet
- Transformer、GPT、BERT,预训练语言模型的有关理论知识
-
- 预训练
- 语言模型
- 词向量
- Word2Vec 模型
TensorBoard的使用
SummaryWriter类的使用
参考:SummaryWriter类(pytorch版)
SummaryWriter类中的常用函数 ---- add_scalar()和add_image()
以以下代码为说明:
from PIL import Image
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 创建一个logs文件夹,writer写的文件都在该文件夹下
img_path = "data/train/ants/0013035.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL) #将格式转换为numpy.array形式
writer.add_image("test", img_array, 1, dataformats="HWC") #add_image()函数的shape默认设置为'CHW'形式,此出需要通过dataformats进行修改
for i in range(100):
writer.add_scalar("y=4x", 4 * i, i)
writer.close()

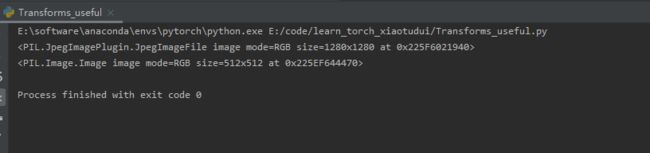
Transforms的使用
Transforms用途
① Transforms当成工具箱的话,里面的class就是不同的工具。例如像totensor、resize这些工具。
② Transforms拿一些特定格式的图片,经过Transforms里面的工具,获得我们想要的结果。
transforms.Totensor的使用
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "data/train/bees/39747887_42df2855ee.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor() # 创建 transforms.ToTensor类 的实例化对象
tensor_img = tensor_trans(img) #转化为Tensor类型
writer = SummaryWriter("logs")
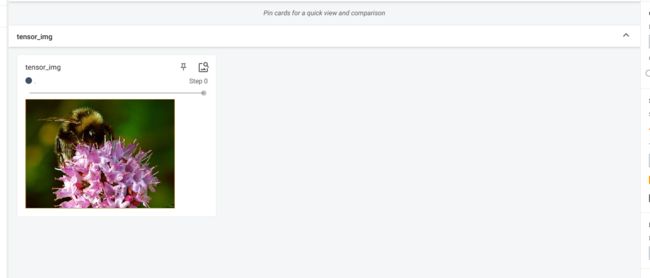
writer.add_image("tensor_img", tensor_img)
writer.close()
在pycharm的控制台下使用 tensorboard --logdir="创建的文件夹名"即可查看tensorboard显示日志情况。
由于我创建的文件夹名为"logs",使用命令为tensorboard --logdir="logs"

Normanize归一化
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
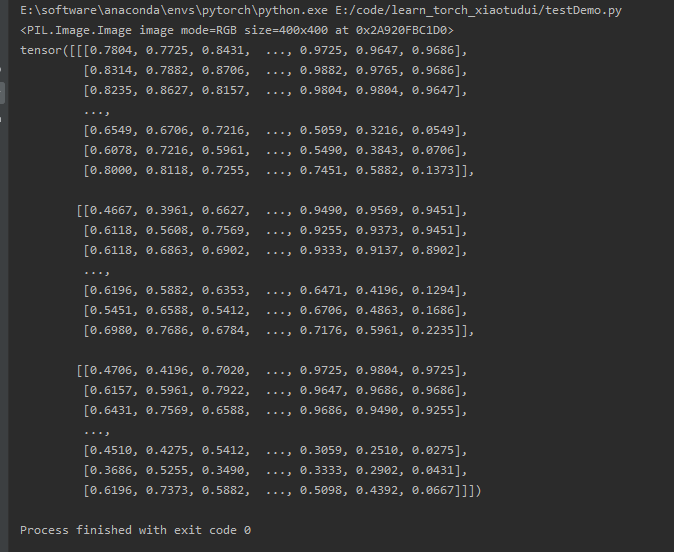
img = Image.open("images/demo1.jpg")
# toTensor
trans_toTensor = transforms.ToTensor()
img_tensor = trans_toTensor(img)
print(img_tensor[0][0][0])
# 计算方式``output[channel] = (input[channel] - mean[channel]) / std[channel]``
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
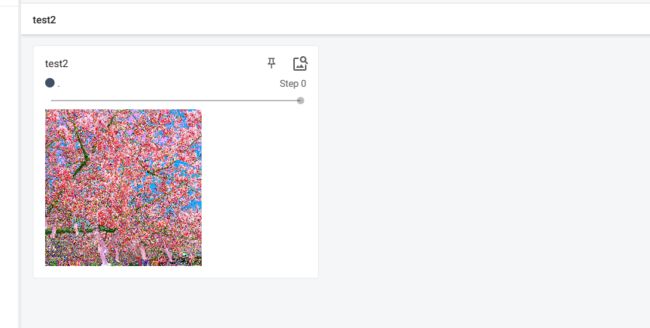
writer.add_image("test2", img_norm)
writer.close()
计算结果:

显示的日志情况如下:
Resize
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/demo1.jpg")
# Resize
print(img)
trans_resize = transforms.Resize((512, 512))#将图片裁剪为512x512的样式
img_resize = trans_resize(img)
print(img_resize)
结果如下:
Compose
torchvision.transforms是pytorch中的图像预处理包,一般用Compose把多个步骤整合到一起,以下代码我们将Resize和ToTensor操作整合到一起。
from PIL import Image
from torchvision import transforms
# toTensor
trans_toTensor = transforms.ToTensor()
img_tensor = trans_toTensor(img)
# compose
trans_resize2 = transforms.Resize(400)
print(trans_resize2(img))
trans_compose = transforms.Compose([trans_resize2, trans_toTensor])
img_resize2 = trans_compose(img)
print(img_resize2)
结果如下:
TorchVision中数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 定义对dataset的ToTensor操作
trans_dataset = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=trans_dataset, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=trans_dataset, download=True)
# 打印test_set的第一个样本
print(test_set[0])
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_img", img, i)
writer.close()
结果如下:

日志显示情况如下:
Dataloader的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
test_set = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试集中第一张图片的shape和target
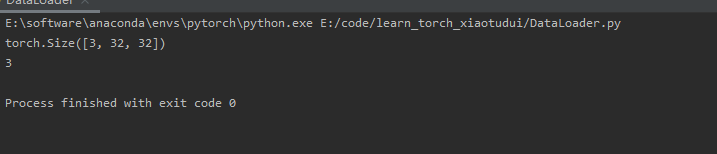
img, target = test_set[0]
print(img.shape)
print(target)
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("test_loader", imgs, step)
step += 1
writer.close()
测试集中第一张图片的shape和target结果如下:
日志显示情况如下:
#将drop_last值设置为True
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
日志显示情况如下:

卷积操作
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
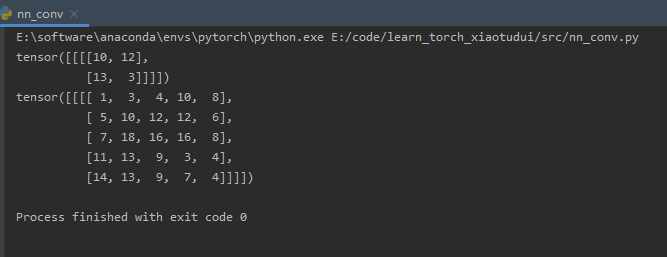
output = F.conv2d(input, kernel, stride=1)
# print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
结果如下:
神经网络-卷积层
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Module_conv(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, input):
input = self.conv1(input)
return input
module_conv = Module_conv()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
imgs_output = module_conv(imgs)
step += 1
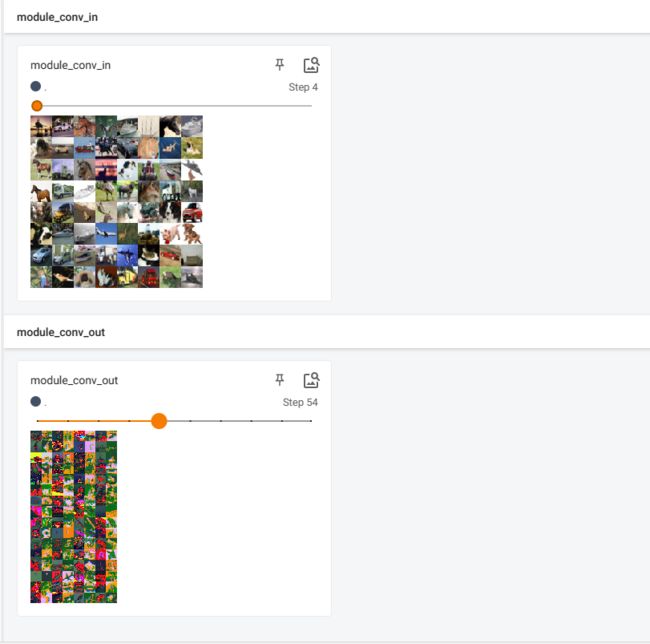
writer.add_images("module_conv_in", imgs, step)
# torch.Size([16, 6, 30, 30]) --->torch.Size([xx, 3, 30, 30])
imgs_output = torch.reshape(imgs_output, (-1, 3, 30, 30))
writer.add_images("module_conv_out", imgs_output, step)
writer.close()
日志显示情况如下:
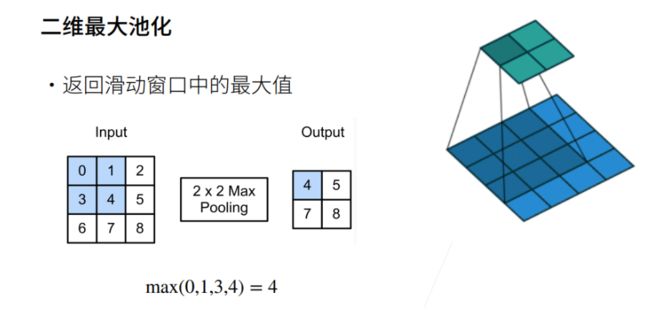
最大池化
对input进行最大池化操作(input值如下代码所示)
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 5, 5))
class Maxpool_nn(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
maxpool2d_nn = Maxpool_nn()
output = maxpool2d_nn(input)
print(output)

对CIFAR10(点击加入pytorch官网查看CIFAR10数据集)测试集中的图片进行最大池化操作
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Maxpool_nn(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
writer = SummaryWriter("../logs")
maxpool2d_nn = Maxpool_nn()
step = 0
for data in dataloader:
imgs, targets = data
step += 1
writer.add_images("img", imgs, global_step=step)
maxpool_imgs = maxpool2d_nn(imgs)
writer.add_images("maxpool_img", maxpool_imgs, global_step=step)
writer.close()

非线性激活
Relu函数
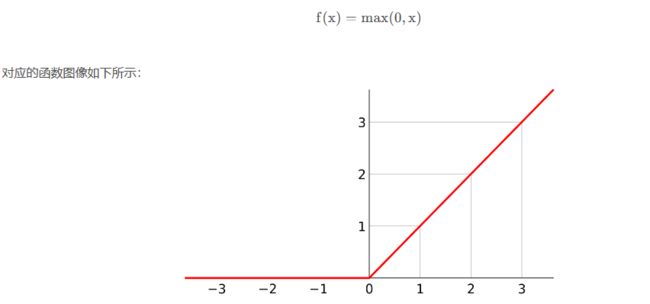
Relu函数计算方式如下:
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -1.5],
[-2.5, 3]])
input = torch.reshape(input, (1, 1, 2, 2))
class Nolinear_nn(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
nolinear1 = Nolinear_nn()
output = nolinear1(input)
print(output)

Sigmoid函数
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Nolinear_nn(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
nolinear1 = Nolinear_nn()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
step += 1
imgs, targets = data
imgs_sigmoid = nolinear1(imgs)
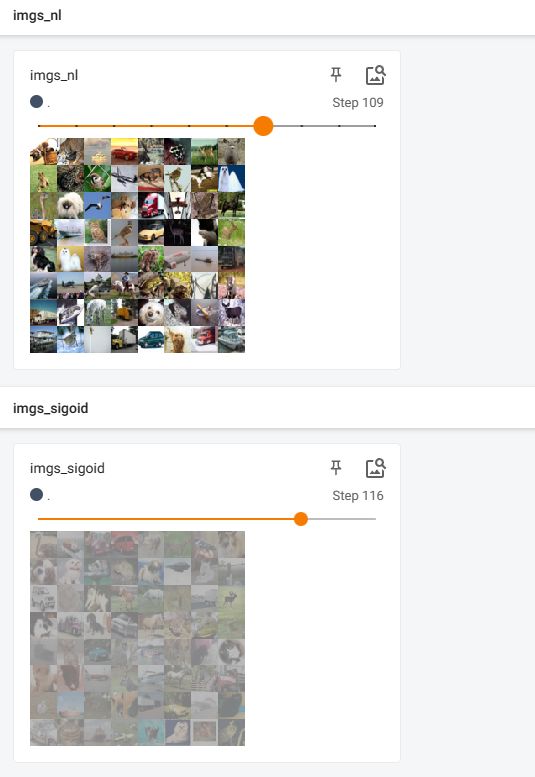
writer.add_images("imgs_nl", imgs, global_step=step)
writer.add_images("imgs_sigoid", imgs_sigmoid, global_step=step)
writer.close()
线性层
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True
dataloader = DataLoader(dataset, batch_size=64, drop_last=True) # 样本数量可能不是batch_size的整数倍,使用drop_last=True将多余的样本舍去
class linear_nn(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
linear1 = linear_nn()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
imgs_re = torch.reshape(imgs, (1, 1, 1, -1))# 此行代码可用imgs_re = torch.flatten(imgs)替换
print(imgs_re.shape)
imgs_linear = linear1(imgs_re)
print(imgs_linear.shape)
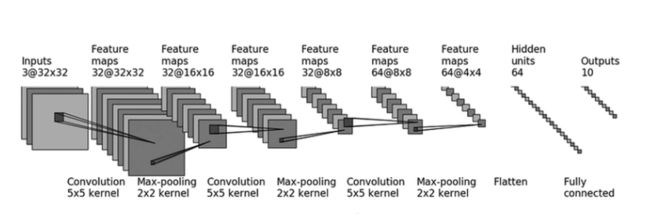
小型网络搭建和Sequential使用
使用的模型框架(由三层卷积、最大池化层以及两层的线性层构成)如下:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class ModulePrac(nn.Module):
def __init__(self):
super().__init__()
self.module1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
module1 = ModulePrac()
input1 = torch.ones((64, 3, 32, 32))
output = module1(input1)
print(output.shape)
writer = SummaryWriter("../logs")
writer.add_graph(module1, input1)
writer.close()
使用的输入其batch_size设置为64,最后经过模型后的输入大小即为64x10,结果如下:


损失函数与反向传播
使用的模型框架是上一节(小型网络搭建和Sequential使用)中定义
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class ModulePrac(nn.Module):
def __init__(self):
super().__init__()
self.module1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
loss = nn.CrossEntropyLoss()
modulePrac1 = ModulePrac()
for data in dataloader:
imgs, targets = data
outputs = modulePrac1(imgs)
loss_res = loss(outputs, targets)
loss_res.backward()
print("ok")
我们在第41行代码中打上断点进行调试,可以看到以下这些属性:

优化器
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class ModulePrac(nn.Module):
def __init__(self):
super().__init__()
self.module1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
loss = nn.CrossEntropyLoss()
modulePrac1 = ModulePrac()
optim = torch.optim.SGD(modulePrac1.parameters(), lr=0.001)
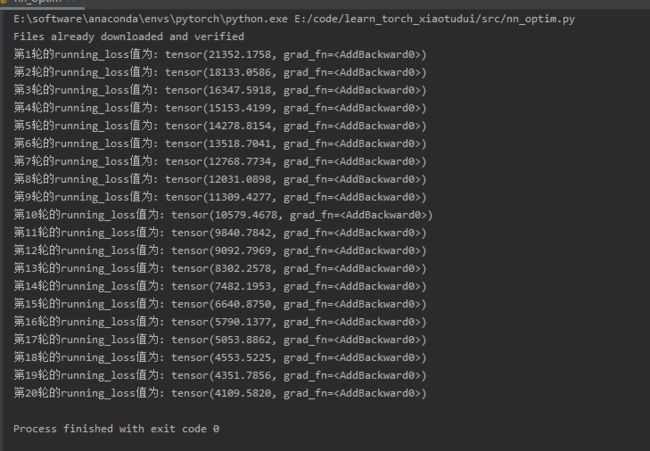
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = modulePrac1(imgs)
loss_res = loss(outputs, targets)
optim.zero_grad()
loss_res.backward()
optim.step()
running_loss += loss_res
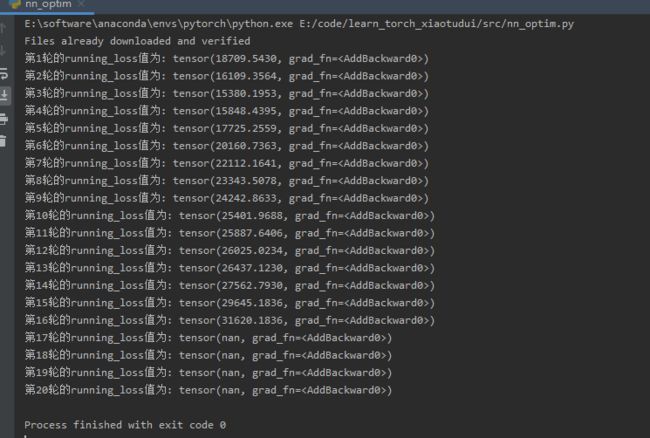
print(f'第{epoch+1}轮的running_loss值为:', running_loss)
我们将训练轮次设为20,输出每轮累积的loss值,结果如下:
网络模型的使用及修改
代码以vgg16模型为例进行展示:
import torchvision
from torch import nn
dataset = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_false)
vgg16_false.classifier.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_false)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
vgg16_true.classifier[6] = nn.Linear(1000, 10)
print(vgg16_true)
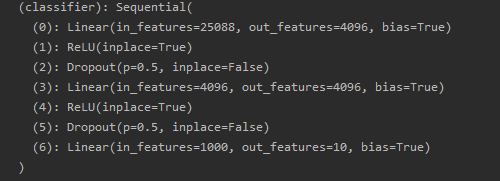
代码是在vgg16模型中的classifier中的结构如下:
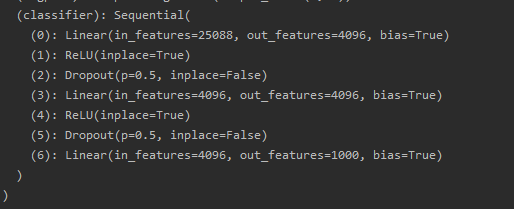
网络模型的修改
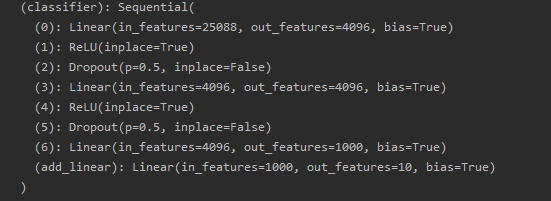
使用以下代码在classifier中增加一个1000x10的线性层
vgg16_false.classifier.add_module("add_linear", nn.Linear(1000, 10))
结果如下:
使用以下代码在classifier中将第7层的4096x1000的线性层改为1000x10的线性层
vgg16_true.classifier[6] = nn.Linear(1000, 10)
结果如下:
完整模型的训练
使用的模型框架(由三层卷积、最大池化层以及两层的线性层构成)如下:
模型的代码如下:
# 搭建神经网络
from torch import nn
class ModuleTrain(nn.Module):
def __init__(self) -> None:
super().__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
使用的数据集为CIFAR10来进行分类,示例代码如下:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from src.module_common import *
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
module1 = ModuleTrain()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optim = torch.optim.SGD(module1.parameters(), lr=learning_rate)
# 设置网络训练的一些参数
# 训练次数
train_step = 0
# 测试次数
test_step = 0
# 训练轮数
epoch = 10
writer = SummaryWriter('../logs')
for i in range(epoch):
print(f"第{i + 1}轮训练开始!")
# 训练步骤开始
for data in train_dataloader:
imgs, tragets = data
output = module1(imgs)
loss = loss_fn(output, tragets)
# 优化器优化模型
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
if train_step % 100 == 0:
# print(f'第{train_step}次训练的loss值:{loss}')
writer.add_scalar("train_loss", loss, train_step)
# 测试步骤开始
with torch.no_grad():
loss_test_sum = 0
total_accuracy = 0
for data in test_dataloader:
imgs, targets = data
output = module1(imgs)
loss = loss_fn(output, targets)
loss_test_sum += loss
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
# print(f"第{i + 1}轮测试集的loss值和:{loss_test_sum}")
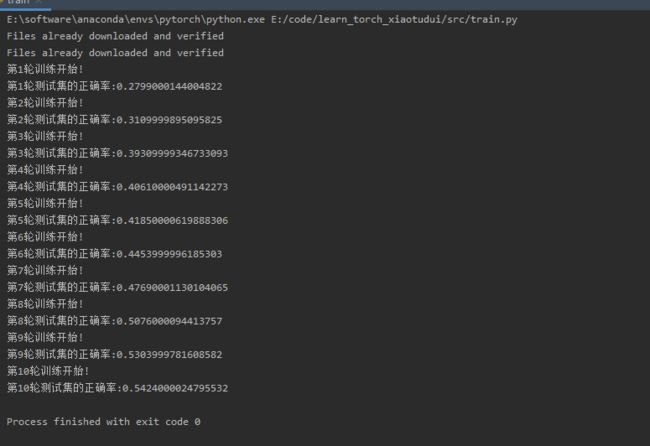
print(f"第{i + 1}轮测试集的正确率:{total_accuracy / len(test_data)}")
test_step += 1
writer.add_scalar("test_lossSum", loss_test_sum, test_step)
writer.add_scalar("test_lossAccuract", total_accuracy / len(test_data), test_step)
# 保存模型
# torch.save(module1, f"module1_{i}.pth")
writer.close()
结果如下:
利用gpu训练
利用gpu训练1——cuda
对网络模型、损失函数、数据(输入和标注)使用.cuda(),示例如下:
# 网络模型
module1 = module1.cuda()
# 损失函数
loss_fn = loss_fn.cuda()
# 数据(输入和标注)
imgs = imgs.cuda()
tragets = targets.cuda()
以上一章节的代码为例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch.utils.tensorboard import SummaryWriter
from torch import nn
import torchvision
from torch.utils.data import DataLoader
import time
# 准备数据集
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class ModuleTrain(nn.Module):
def __init__(self) -> None:
super().__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
module1 = ModuleTrain()
if torch.cuda.is_available():
module1 = module1.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 1e-2
optim = torch.optim.SGD(module1.parameters(), lr=learning_rate)
# 设置网络训练的一些参数
# 训练次数
train_step = 0
# 测试次数
test_step = 0
# 训练轮数
epoch = 10
time_start = time.time()
writer = SummaryWriter('../logs')
for i in range(epoch):
print(f"第{i + 1}轮训练开始!")
# 训练步骤开始
for data in train_dataloader:
imgs, tragets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
tragets = targets.cuda()
output = module1(imgs)
loss = loss_fn(output, tragets)
# 优化器优化模型
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
time_end = time.time()
if train_step % 100 == 0:
# print(f'第{train_step}次训练的loss值:{loss}')
writer.add_scalar("train_loss", loss, train_step)
# 测试步骤开始
with torch.no_grad():
loss_test_sum = 0
total_accuracy = 0
for data in test_dataloader:
imgs, targets = data
output = module1(imgs)
if torch.cuda.is_available():
imgs = imgs.cuda()
tragets = targets.cuda()
loss = loss_fn(output, targets)
loss_test_sum += loss
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
# print(f"第{i + 1}轮测试集的loss值和:{loss_test_sum}")
print(f"第{i + 1}轮测试集的正确率:{total_accuracy / len(test_data)}")
test_step += 1
writer.add_scalar("test_lossSum", loss_test_sum, test_step)
writer.add_scalar("test_lossAccuract", total_accuracy / len(test_data), test_step)
# 保存模型
# torch.save(module1, f"module1_{i}.pth")
writer.close()
利用gpu训练2——device
对网络模型、损失函数、数据(输入和标注)使用.to(device),先torch.device(“cuda或cpu”)定义训练的设备,然后对网络模型、损失函数、数据(输入和标注).to(device)示例如下:
#定义训练的设备
device = torch.device("cuda")
#若没有gpu则使用cpu进行训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 网络模型
module1 = module1.to(device) #等价于module1.to(device)
# 损失函数
loss_fn = loss_fn.to(device)#等价于loss_fn.to(device)
# 数据(输入和标注)
imgs = imgs.to(device)
tragets = targets.to(device)
具体代码如下:
import torch
from torch.utils.tensorboard import SummaryWriter
from torch import nn
import torchvision
from torch.utils.data import DataLoader
import time
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class ModuleTrain(nn.Module):
def __init__(self) -> None:
super().__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
module1 = ModuleTrain()
module1.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
module1.to(device)
# 优化器
learning_rate = 1e-2
optim = torch.optim.SGD(module1.parameters(), lr=learning_rate)
# 设置网络训练的一些参数
# 训练次数
train_step = 0
# 测试次数
test_step = 0
# 训练轮数
epoch = 10
time_start = time.time()
writer = SummaryWriter('../logs')
for i in range(epoch):
print(f"第{i + 1}轮训练开始!")
# 训练步骤开始
for data in train_dataloader:
imgs, tragets = data
imgs = imgs.to(device)
tragets = tragets.to(device)
output = module1(imgs)
loss = loss_fn(output, tragets)
# 优化器优化模型
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
time_end = time.time()
if train_step % 100 == 0:
# print(f'第{train_step}次训练的loss值:{loss}')
print(time_end-time_start)
writer.add_scalar("train_loss", loss, train_step)
# 测试步骤开始
with torch.no_grad():
loss_test_sum = 0
total_accuracy = 0
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
tragets = tragets.to(device)
output = module1(imgs)
loss = loss_fn(output, targets)
loss_test_sum += loss
accuracy = (output.argmax(1) == targets).sum()
total_accuracy += accuracy
# print(f"第{i + 1}轮测试集的loss值和:{loss_test_sum}")
print(f"第{i + 1}轮测试集的正确率:{total_accuracy / len(test_data)}")
test_step += 1
writer.add_scalar("test_lossSum", loss_test_sum, test_step)
writer.add_scalar("test_lossAccuract", total_accuracy / len(test_data), test_step)
# 保存模型
# torch.save(module1, f"module1_{i}.pth")
writer.close()
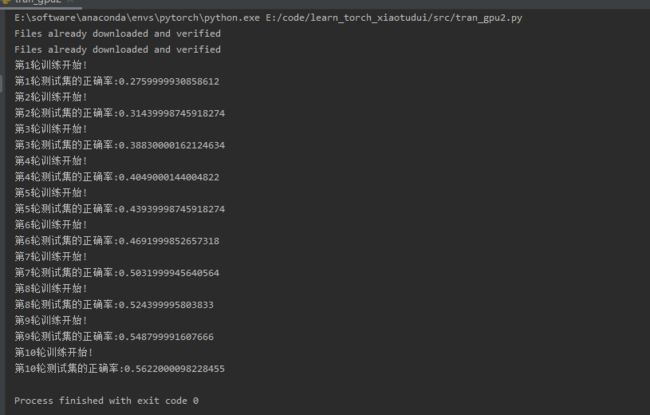
模型验证
使用上一章节中gpu训练了10轮模型,然后将模型保存,训练的模型情况如下:

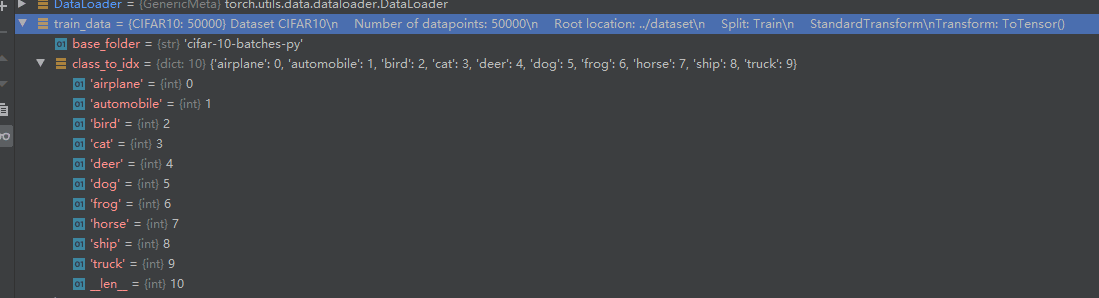
使用的测试集有10类别,如下所示:
使用module1和module10模型进行测试:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from PIL import Image
from torch import nn
import torchvision
image_path = "../images/cat.jpg"
image_path2 = "../images/dog.jpg"
image_path3 = "../images/airplane.jpg"
list_test = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
image1 = Image.open(image_path)
image2 = Image.open(image_path2)
image3 = Image.open(image_path3)
# print(image1)
# 使用网络模型需要32x32的图片
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image1 = transform(image1)
image2 = transform(image2)
image3 = transform(image3)
# print(image1.shape)
# 搭建神经网络
class ModuleTrain(nn.Module):
def __init__(self) -> None:
super().__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
# 使用已训练好保存的模型
module1 = torch.load("module1.pth")
module10 = torch.load("module10.pth")
# print(module)
image1 = torch.reshape(image1, (1, 3, 32, 32))
image2 = torch.reshape(image2, (1, 3, 32, 32))
image3 = torch.reshape(image3, (1, 3, 32, 32))
with torch.no_grad():
output1 = module1(image1)
output2 = module1(image2)
output3 = module1(image3)
output4 = module10(image1)
output5 = module10(image2)
output6 = module10(image3)
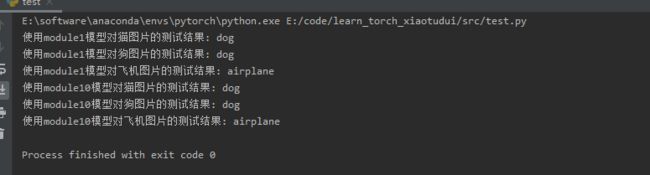
print("使用module1模型对猫图片的测试结果:", list_test[output1.argmax(1).item()])
print("使用module1模型对狗图片的测试结果:", list_test[output2.argmax(1).item()])
print("使用module1模型对飞机图片的测试结果:", list_test[output3.argmax(1).item()])
print("使用module10模型对猫图片的测试结果:", list_test[output4.argmax(1).item()])
print("使用module10模型对狗图片的测试结果:", list_test[output5.argmax(1).item()])
print("使用module10模型对飞机图片的测试结果:", list_test[output6.argmax(1).item()])
结果如下:
自动求导
自动求导分为以下两种模式:

在反向累积过程中计算需要正向累积中存储的中间结果

如下是一个简单的自动求导的例子:
import torch
x = torch.arange(4.0) # x为tensor([0., 1., 2., 3.]),arange函数中需使用float
x.requires_grad_(True)# 等价于x=torch.arange(4.0,requires_grad=True)
y = 2 * torch.dot(x, x)
y.backward()
print(x.grad)
结果如下:
梯度自动累积
PyTorch默认会对梯度进行累加。即PyTorch会在每一次backward()后进行梯度计算,但是梯度不会自动归零,如果不进行手动归零的话,梯度会不断累加。
#以x为例,清除之前x中梯度的值
x.grad.zero_()
线性神经网络
线性回归
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。机器学习模型中的关键要素是训练数据、损失函数、优化算法,还有模型本身。
线性模型
线性模型可以看做是一个单层的神经网络

衡量预估质量
一般采用平方损失来衡量真实值与预测值之间的误差

训练数据
收集一些数据来决定参数值(权重和偏差),这些数据被称为训练数据,训练数据通常越多越好
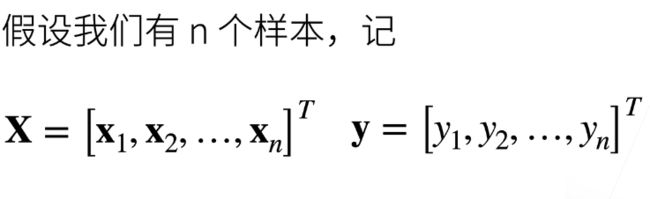
学习参数
损失函数采用平方损失,根据定义的损失函数来求均值
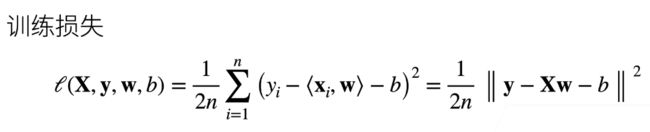
最小化损失函数来决定参数值

其中线性模型是有显示解的(一般来说,模型都没有显示解,有显示解的模型过于简单,复杂度有限,很难衡量复杂的数据)
基础优化算法
梯度下降

小批量随机梯度下降
梯度下降时,每次计算梯度,要对整个损失函数求导,损失函数是对所有样本的平均损失,所以每求一次梯度,要对整个样本的损失函数进行计算,计算量大且耗费时间长,代价太大。我们可以随机采样b个样本来计算近似损失。

选择批量大小不能太大,也不能太小。

线性回归的从零开始实现
import random
import torch
# 使用线性模型参数w = torch.tensor([2, -3.4]),b = 4.2生成数据集及其标签
def synthetic_data(w, b, num_examples): # @save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
# data_iter函数功能为接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
# yield就是return一个值,并且记住返回的位置,下次迭代就从这个位置开始。
yield features[batch_indices], labels[batch_indices]
# for X, y in data_iter(batch_size, features, labels):
# print(X, '\n', y)
# break
# 定义初始化模型参数
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 定义模型
def linreg(X, w, b): # @save
"""线性回归模型"""
return torch.matmul(X, w) + b
# 定义损失函数
def squared_loss(y_hat, y): # @save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
# 定义优化算法
def sgd(params, lr, batch_size): # @save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
# 训练
batch_size = 10
learning_rate = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], learning_rate, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
可以看到loss值越来越小,结果如下:

若学习率过大,将学习率设置为3,即learning_rate = 3,结果如下:

若学习率过小,将学习率设置为0.003,即learning_rate = 0.003,结果如下:

若学习率不变,仍设置为0.003,更改num_epochs = 10,结果如下:
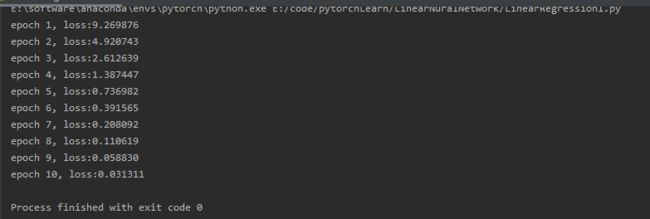
线性回归的简洁实现
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn # nn是神经网络的缩写
# 生成数据集
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# 使用synthetic_data(w, b, num_examples)生成数据集及其标签
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
# 读取数据集
def load_array(data_arrays, batch_size, is_train=True): # @save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# 定义模型
net = nn.Sequential(nn.Linear(2, 1))
# 初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
# 定义损失函数
loss = nn.MSELoss()
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
num_epochs = 3,batch_size = 10,学习率设置为0.03,结果如下:

softmax回归
分类问题
分类问题通常有多个输出,输出i是预测为第i类的置信度。
对类别进行一位有效编码
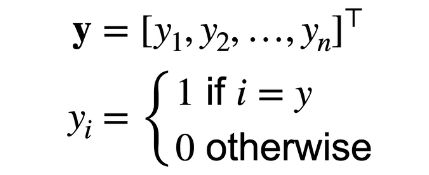
最大值进行预测
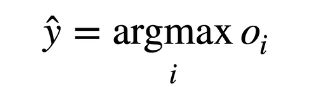
softmax运算
softmax计算公式如下:
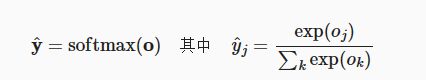
softmax和交叉熵损失

将y与y_hat作为损失:


图像分类数据集
读取数据集
将Fashion-MNIST数据集下载并读取到内存中
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
# Fashion-MNIST数据集下载并读取到内存中
mnist_train = torchvision.datasets.FashionMNIST(root="E:\code\homework_dpLearning\softmaxImgData", train=True,
transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="E:\code\homework_dpLearning\softmaxImgData", train=False,
transform=trans, download=True)
print(len(mnist_train), len(mnist_test))
print(mnist_train[0][0].shape)
Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。

Fashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。我们定义show_images()函数来对样本进行可视化。
def get_fashion_mnist_labels(labels): # @save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
# 样本可视化
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): # @save
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
d2l.plt.show()
return axes
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
训练数据集中前几个样本的图像及其相应的标签结果如下:

读取小批量
batch_size = 256
def get_dataloader_workers(): # @save
"""使用4个进程来读取数据"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
# 查看读取训练数据所需的时间
timer = d2l.Timer()
for X, y in train_iter:
continue
print(f'训练时间:{timer.stop():.2f} sec')
训练时间结果如下:

整合所有组件
# 定义load_data_fashion_mnist函数,用于获取和读取Fashion-MNIST数据集
def load_data_fashion_mnist(batch_size, resize=None): # @save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="E:\code\homework_dpLearning\softmaxImgData", train=True,
transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="E:\code\homework_dpLearning\softmaxImgData", train=False,
transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
指定resize参数来测试load_data_fashion_mnist函数的图像大小调整功能
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
结果如下:

softmax回归的从零开始实现
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
# 定义softmax操作
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
# 定义模型
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
# 定义损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
# 分类精度
def accuracy(y_hat, y): # @save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter): # @save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
# 定义一个实用程序类Accumulator,用于对多个变量进行累加
class Accumulator: # @save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 训练
def train_epoch_ch3(net, train_iter, loss, updater): # @save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
# 定义一个在动画中绘制数据的实用程序类Animator
class Animator: # @save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): # @save
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
d2l.plt.show()
结果如下:
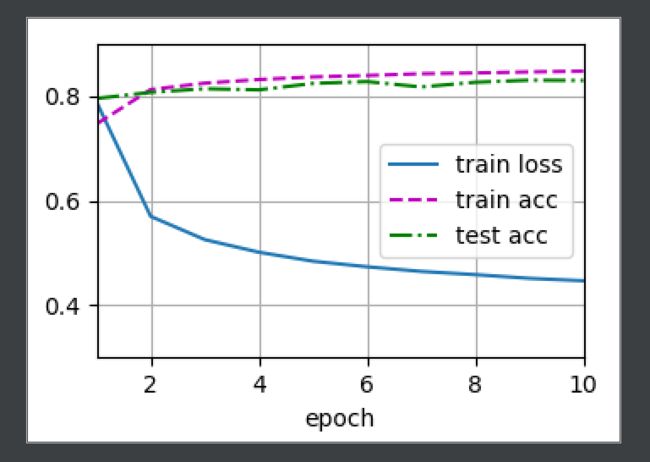
softmax回归的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
loss = nn.CrossEntropyLoss()
# 优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
结果如下:

多层感知机
多层感知机
单层感知机

训练感知机
(1)如果分类正确的话y
(2)如果分类错了,y

多层感知机
单隐藏层
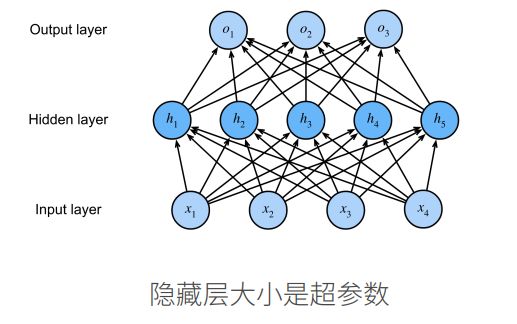
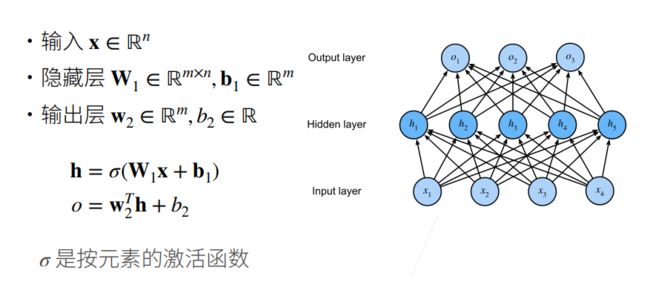
若不使用激活函数,全连接层连接在一起仍相遇于一个线性函数。
激活函数
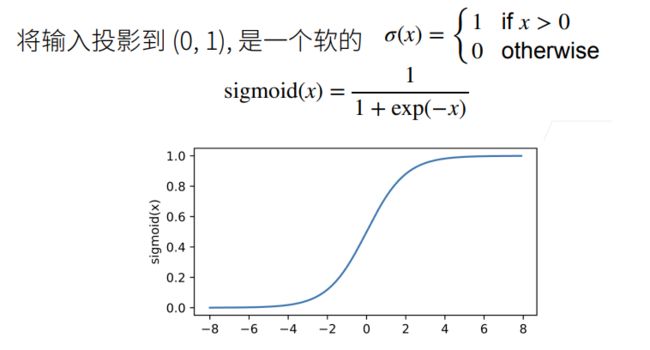
(1)Sigmoid函数
(2)Tanh函数
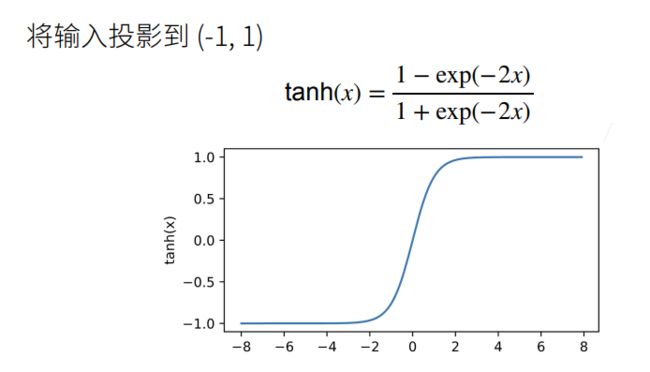
(3)ReLU函数
① ReLU的好处在于不需要执行指数运算。
② 在CPU上一次指数运算相当于上百次乘法运算。
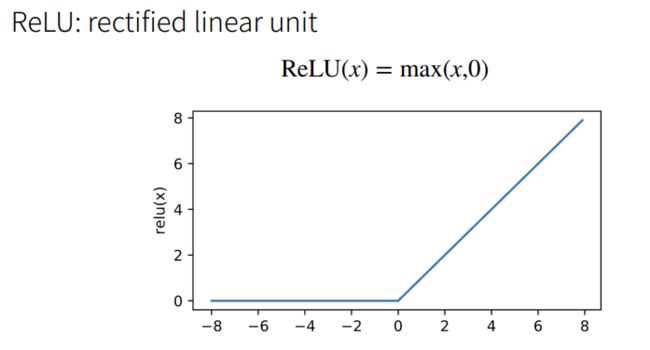
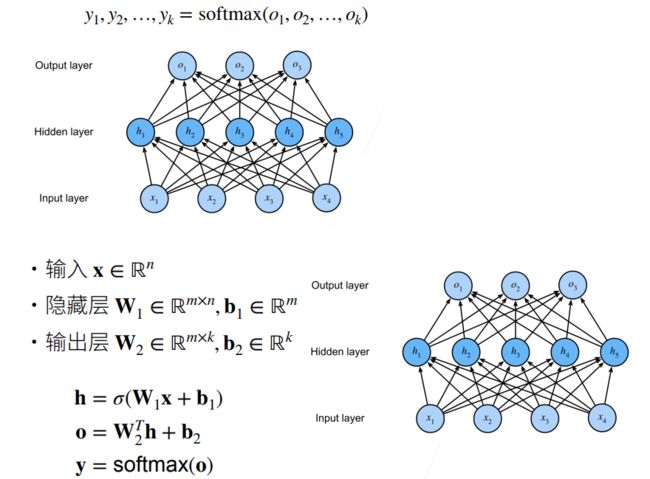
多类分类
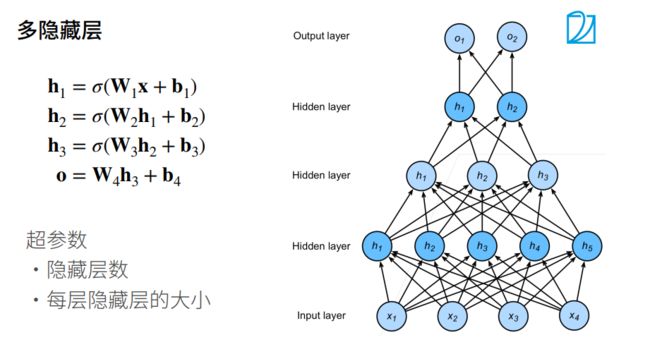
多隐藏层
多层感知机的从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
# ReLU激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法
return (H @ W2 + b2)
# 损失函数
loss = nn.CrossEntropyLoss()
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.plt.show()
结果如下:

多层感知机的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
# 模型
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
结果如下:
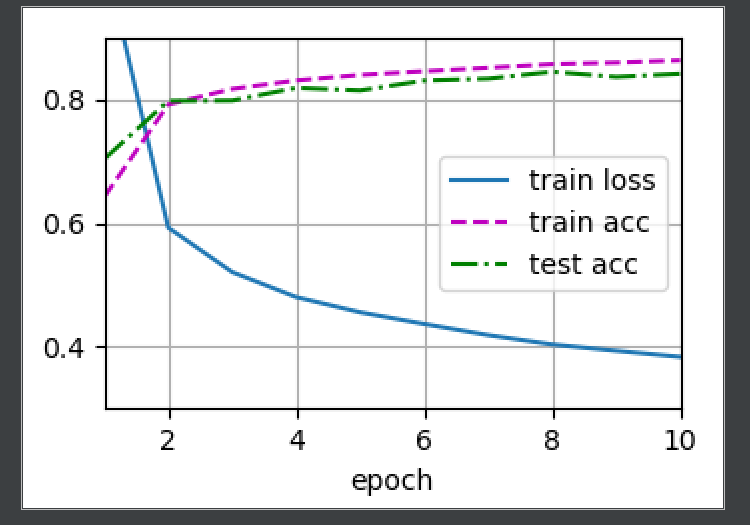
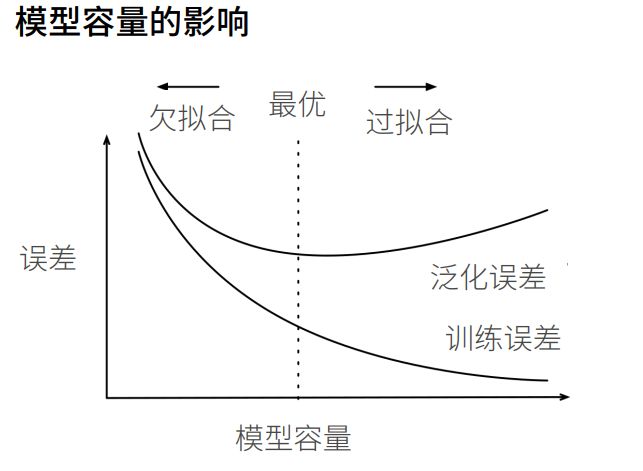
模型选择、欠拟合和过拟合
训练误差和泛化误差



过拟合、欠拟合

模型容量也可以说是模型复杂度






多项式解释欠拟合、过拟合
使用以下三阶多项式来生成训练和测试数据的标签:
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
# NumPy ndarray转换为tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=
torch.float32) for x in [true_w, features, poly_features, labels]]
# 对模型进行训练和测试
def evaluate_loss(net, data_iter, loss): # @save
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
# 定义训练函数
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
三阶多项式函数拟合(正常)
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
d2l.plt.show()
结果如下:

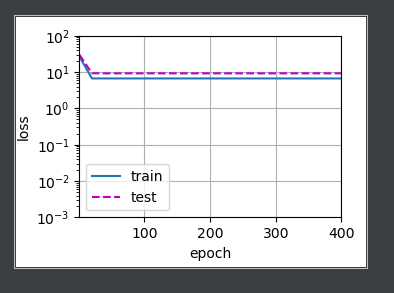
线性函数拟合(欠拟合)
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
d2l.plt.show()
结果如下:
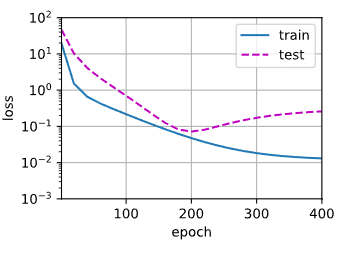
高阶多项式函数拟合(过拟合)
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:])
d2l.plt.show()
结果如下:
权重衰退
权重衰退是常见的处理过拟合的一种方法。把模型容量控制比较小有两种方法,方法一:模型控制的比较小,使得模型中参数比较少。方法二:控制参数选择范围来控制参数容量。
如下图所示,w向量中每一个元素的值都小于θ的根号。 约束就是正则项。每个特征的权重都大会导致模型复杂,从而导致过拟合。控制权重矩阵范数可以使得减少一些特征的权重,甚至使他们权重为0,从而导致模型简单,减轻过拟合。



权重衰退的从零开始实现和简洁实现
从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
# 初始化模型参数
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
# 定义L2范数惩罚
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
# 定义训练代码实现
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
忽略正则化直接训练
train(lambd=0)
d2l.plt.show()
结果如下:
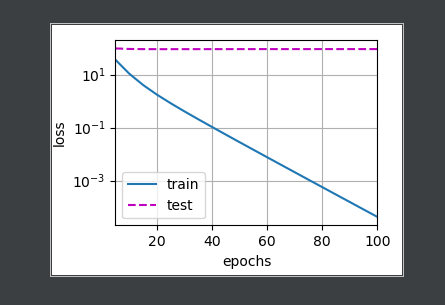
使用权重衰减
train(lambd=3)
d2l.plt.show()
结果如下:

简洁实现
import torch
from d2l import torch as d2l
from torch import nn
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss()
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params": net[0].weight, 'weight_decay': wd},
{"params": net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
忽略正则化直接训练
train_concise(0)
d2l.plt.show()
使用权重衰减
train_concise(3)
d2l.plt.show()
丢弃法(Dropout)


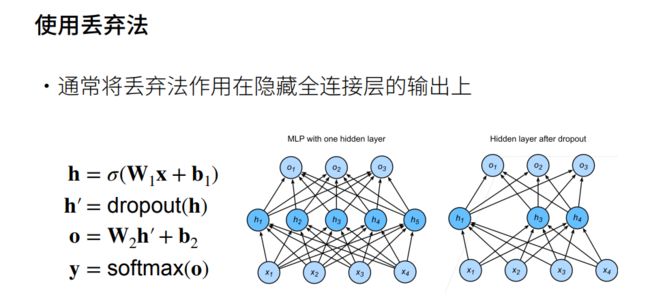

丢弃法的从零开始实现和简洁实现
从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
# 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
结果如下:
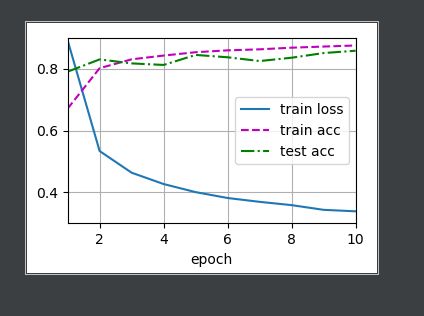
简洁实现
from d2l import torch as d2l
import torch
from torch import nn
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
数值稳定性和模型初始化
初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要,数值稳定性的两个常见问题是梯度消失和梯度爆炸。
梯度爆炸
当W元素值大于1时,神经网络层数很深时,连乘会导致梯度爆炸。


梯度消失



训练更稳定






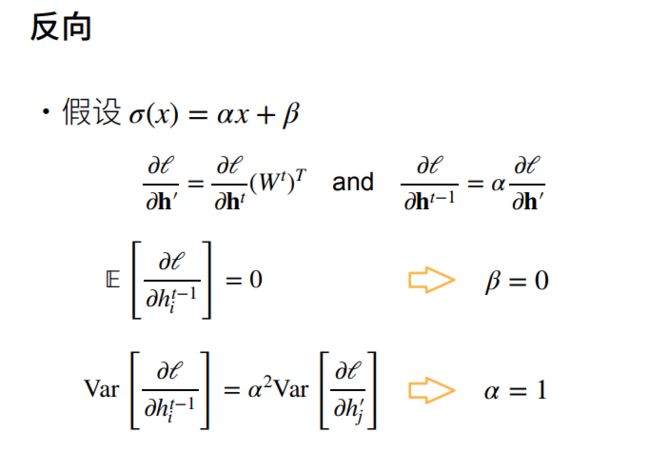
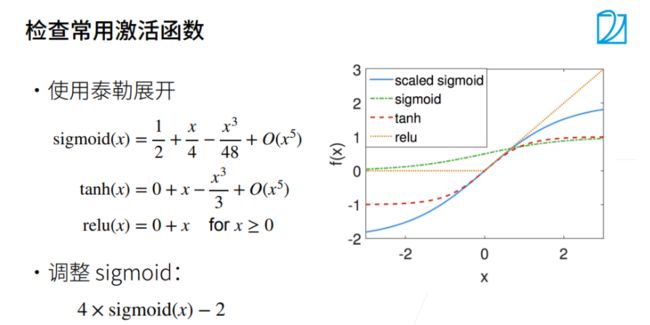
深度学习计算
层和块
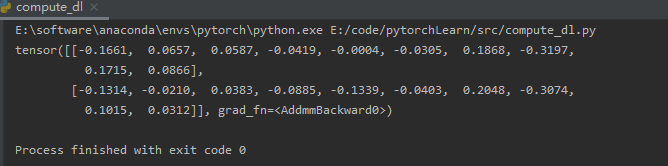
nn.Sequential 定义了一种特殊的Module,下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from torch import nn
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
x = torch.rand(2, 20)
print(net(x))
结果如下:
自定义块
import torch
from torch import nn
from torch.nn import functional as F
class MLP(nn.Module):
def __init__(self):
super().__init__() # 调用父类的__init__函数
self.hidden = nn.Linear(20, 256)
self.out = nn.Linear(256, 10)
def forward(self, X):
return self.out(F.relu(self.hidden(X)))
# 实例化多层感知机的层,然后在每次调用正向传播函数调用这些层
net = MLP()
X = torch.rand(2, 20)
print(net(X))
结果如下:
顺序块
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for block in args:
self._modules[block] = block # block 本身作为它的key,存在_modules里面的为层,以字典的形式
def forward(self, X):
for block in self._modules.values():
print(block)
X = block(X)
return X
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
print(net(X))
结果如下:
正向传播
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
X = F.relu(torch.mm(X, self.rand_weight + 1))
X = self.linear(X)
while X.abs().sum() > 1:
X /= 2
return X.sum()
net = FixedHiddenMLP()
X = torch.rand(2, 20)
print(net(X))
结果如下:

混合组合块
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimear = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
X = torch.rand(2, 20)
print(chimear(X))
结果如下:

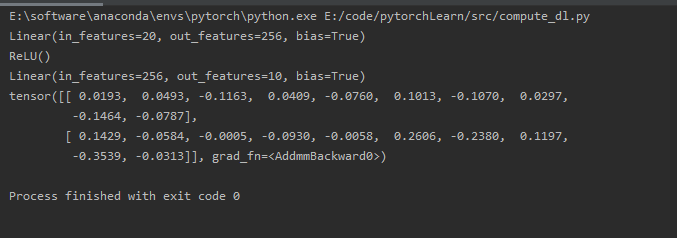
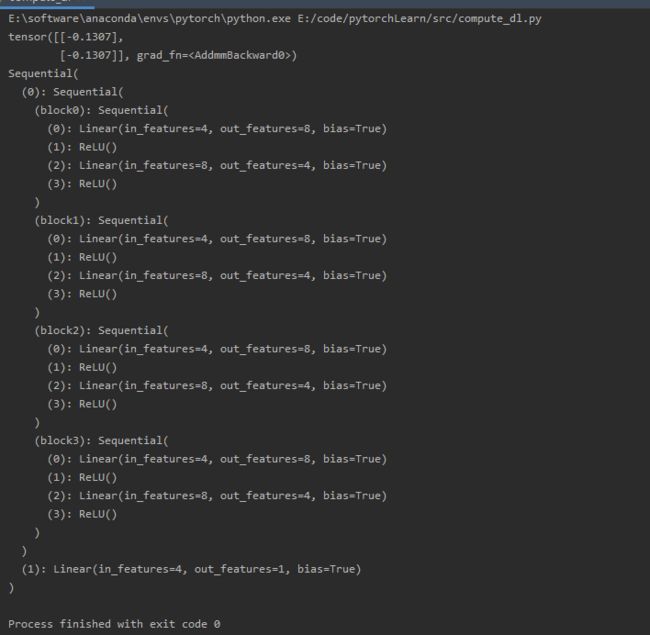
参数管理
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
print(net(X))
print(net[2].state_dict()) # 访问参数,net[2]就是最后一个输出层
print(type(net[2].bias)) # 目标参数
print(net[2].bias)
print(net[2].bias.data)
print(net[2].weight.grad == None) # 还没进行反向计算,所以grad为None
print(*[(name, param.shape) for name, param in net[0].named_parameters()]) # 一次性访问所有参数
print(*[(name, param.shape) for name, param in net.named_parameters()]) # 0是第一层名字,1是ReLU,它没有参数
print(net.state_dict()['2.bias'].data) # 通过名字获取参数
结果如下:
嵌套块
# 从嵌套块收集参数
def block1():
return nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 4), nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
net.add_module(f'block{i}',
block1()) # f'block{i}' 可以传一个字符串名字过来,block2可以嵌套四个block1
return net
X = torch.rand(2, 4)
rgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet(X))
print(rgnet)
结果如下:
参数绑定
# 参数绑定
X = torch.rand(2, 4)
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), shared, nn.ReLU(), shared, nn.ReLU(),
nn.Linear(8, 1)) # 第2个隐藏层和第3个隐藏层是share权重的,第一个和第四个是自己的
net(X)
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
print(net[2].weight.data[0] == net[4].weight.data[0])
结果如下:

自定义层
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
layer = CenteredLayer()
print(layer(torch.FloatTensor([1, 2, 3, 4, 5])))
# 将层作为组件合并到构建更复杂的模型中
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
Y = net(torch.rand(4, 8))
print(Y.mean())
# 带参数的图层
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units)) # nn.Parameter使得这些参数加上了梯度
self.bias = nn.Parameter(torch.randn(units, ))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
dense = MyLinear(5, 3)
print(dense.weight)
# 使用自定义层直接执行正向传播计算
print(dense(torch.rand(2, 5)))
# 使用自定义层构建模型
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
print(net(torch.rand(2, 64)))
结果如下:

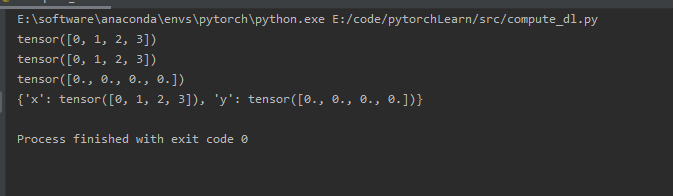
读写文件
# 加载和保存张量
x = torch.arange(4)
torch.save(x, 'x-file')
x2 = torch.load("x-file")
print(x2)
# 存储一个张量列表,然后把它们读回内存
y = torch.zeros(4)
torch.save([x, y], 'x-files')
x2, y2 = torch.load('x-files')
print(x2)
print(y2)
# 写入或读取从字符串映射到张量的字典
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
print(mydict2)
结果如下:
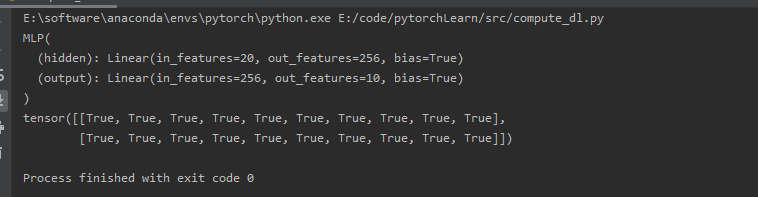
# 加载和保存模型参数
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.output = nn.Linear(256, 10)
def forward(self, x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)
# 将模型的参数存储为一个叫做"mlp.params"的文件
torch.save(net.state_dict(), 'mlp.params')
# 实例化了原始多层感知机模型的一个备份。直接读取文件中存储的参数
clone = MLP() # 必须要先声明一下,才能导入参数
clone.load_state_dict(torch.load("mlp.params"))
print(clone.eval()) # eval()是进入测试模式
Y_clone = clone(X)
print(Y_clone == Y)
结果如下:
卷积神经网络
卷积层
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。

二维卷积运算
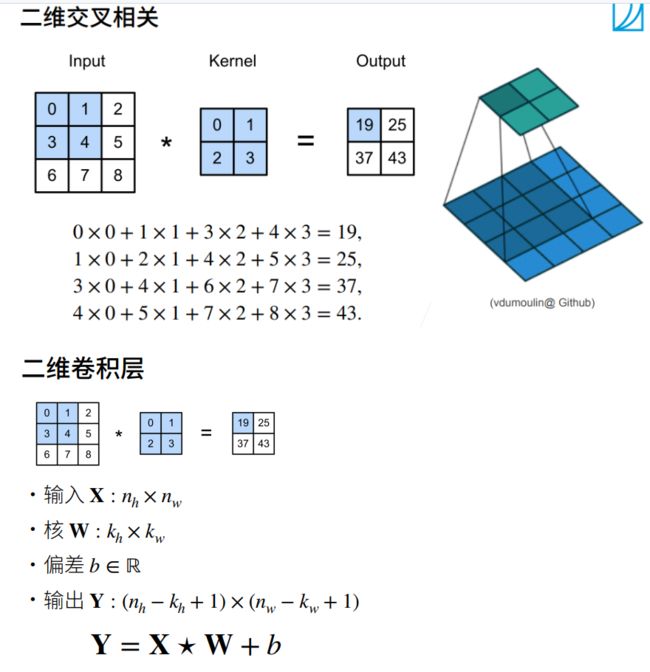
卷积层中的填充和步幅
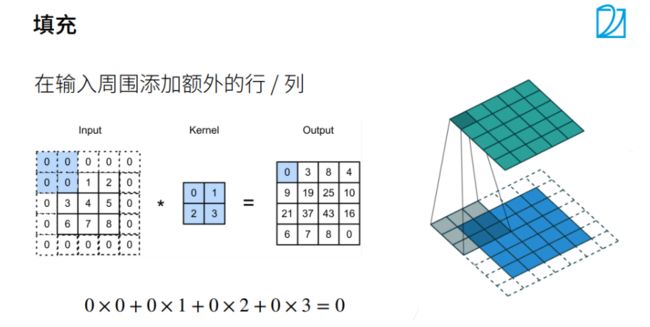
我们假设卷积核大小为k * k,为了让卷积后的图像大小与原图一样大,根据公式可得到padding=(k-1)/2,这里的k只有在取奇数的时候,padding才能是整数,否则padding不好进行图片填充。
k为偶数时,p为浮点数,所做的操作为一个为向上取整,填充,一个为向下取整,填充。

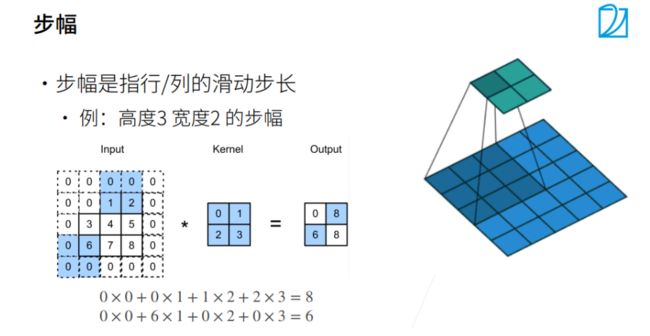
步幅

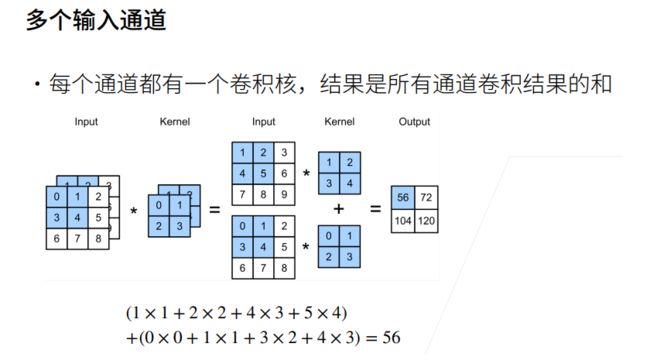
卷积层里的多输入多输出通道

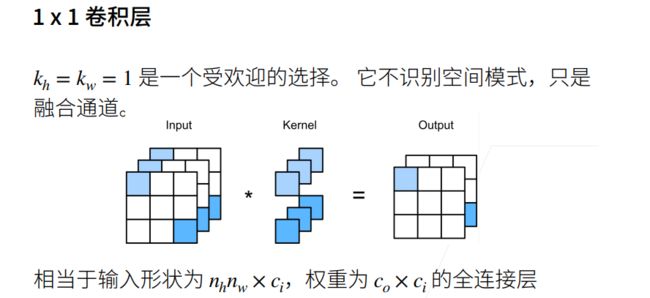
1x1卷积层
二维卷积层

池化层

LeNet网络
网络架构如下:

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28) # 批量数自适应得到,通道数为1,图片为28X28
net = torch.nn.Sequential(
Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
# LeNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
device = torch.device("cuda")
# 对evaluate_accuracy函数进行轻微的修改
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # net.eval()开启验证模式,不用计算梯度和更新梯度
if not device:
device = next(iter(net.parameters())).device # 看net.parameters()中第一个元素的device为哪里
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X] # 如果X是个List,则把每个元素都移到device上
else:
X = X.to(device) # 如果X是一个Tensor,则只用移动一次,直接把X移动到device上
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel()) # y.numel() 为y元素个数
return metric[0] / metric[1]
# 为了使用GPU,还需要一点小改动
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight) # 根据输入、输出大小,使得随即初始化后,输入和输出的的方差是差不多的
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f},train acc {train_acc:.3f},'
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
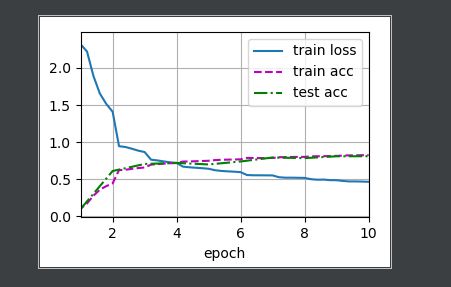
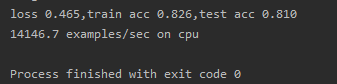
# 训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
深度卷积神经网络
AlexNet
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28) # 批量数自适应得到,通道数为1,图片为28X28
net = torch.nn.Sequential(
Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
# LeNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 对evaluate_accuracy函数进行轻微的修改
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # net.eval()开启验证模式,不用计算梯度和更新梯度
if not device:
device = next(iter(net.parameters())).device # 看net.parameters()中第一个元素的device为哪里
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X] # 如果X是个List,则把每个元素都移到device上
else:
X = X.to(device) # 如果X是一个Tensor,则只用移动一次,直接把X移动到device上
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel()) # y.numel() 为y元素个数
return metric[0] / metric[1]
# 为了使用GPU,还需要一点小改动
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight) # 根据输入、输出大小,使得随即初始化后,输入和输出的的方差是差不多的
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f},train acc {train_acc:.3f},'
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
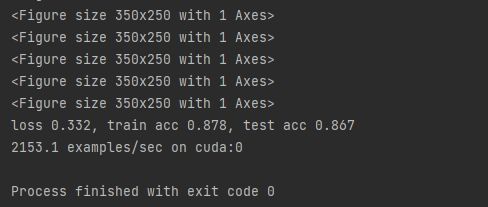
# 训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:

VGG
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
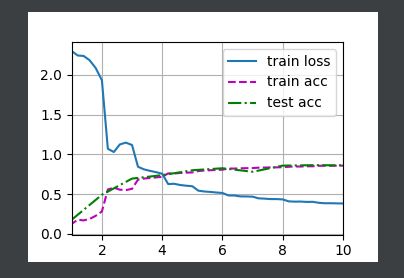
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:

NiN模型
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
lr, num_epochs, batch_size = 0.1, 10, 128
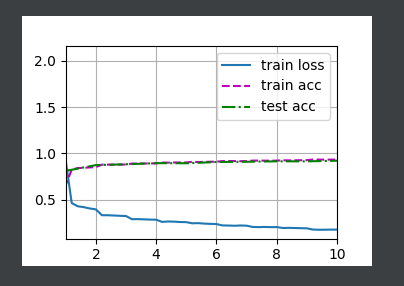
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:
GoogLeNet
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:
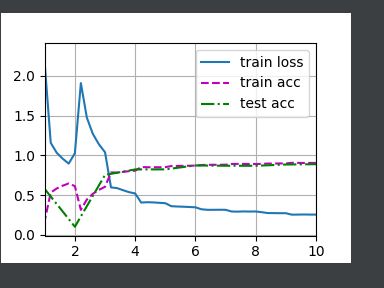
BatchNorm
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:
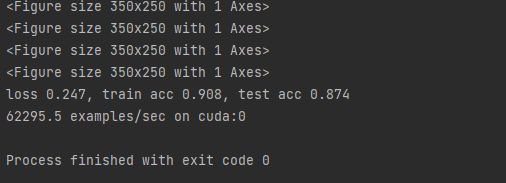

ResNet
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : czyxw
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): # @save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()
结果如下:


Transformer、GPT、BERT,预训练语言模型的有关理论知识
预训练
图像领域的预训练
在介绍图像领域的预训练之前,我们首先介绍下卷积神经网络(CNN),CNN 一般用于图片分类任务,并且CNN 由多个层级结构组成,不同层学到的图像特征也不同,越浅的层学到的特征越通用(横竖撇捺),越深的层学到的特征和具体任务的关联性越强(人脸-人脸轮廓、汽车-汽车轮廓),如下图所示:

由此,假设我们有一个任务:对猫、狗、马等动物进行分类,但每类动物仅有十张图片。
对于上述任务,如果我们亲手设计一个深度神经网络基本是不可能的,因为深度学习一个弱项就是在训练阶段对于数据量的需求特别大,而合计三十张图片显然这是不够的。
虽然上述任务的数据量很少,但是我们是否可以利用网上现有的大量已做好分类标注的图片。比如 ImageNet 中有 1400 万张图片,并且这些图片都已经做好了分类标注。
上述利用网络上现有图片的思想就是预训练的思想,具体做法就是:
通过 ImageNet 数据集我们训练出一个模型 A
由于上面提到 CNN 的浅层学到的特征通用性特别强,我们可以对模型 A 做出一部分改进得到模型 B(两种方法):
冻结:浅层参数使用模型 A 的参数,高层参数随机初始化,浅层参数一直不变,然后利用给出的 30 张图片训练参数
微调:浅层参数使用模型 A 的参数,高层参数随机初始化,然后利用给出的 30 张图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化
预训练是什么
通过一个训练好的模型A去完成一个数据量小的任务B(使用模型A的浅层参数),任务A和任务B是相似的。
语言模型
语言模型通俗点讲就是计算一个句子的概率,下面将介绍语言模型的两个分支,统计语言模型和神经网络语言模型。
统计语言模型
统计语言模型的基本思想就是计算条件概率。给定一句由 n个词组成的句子 W = w1,w2,…wn,计算这个句子的概率 P(w1,w2,…wn)的公式如下(条件概率乘法公式的推广,链式法则):

神经网络语言模型
神经网络语言模型则引入神经网络架构来估计单词的分布,并且通过词向量的距离衡量单词之间的相似度,因此,对于未登录单词,也可以通过相似词进行估计,进而避免出现数据稀疏问题。
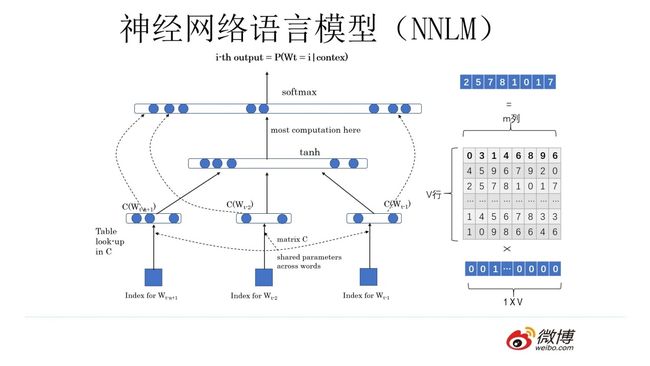
词向量
独热(Onehot)编码
把单词用向量表示,是把深度神经网络语言模型引入自然语言处理领域的一个核心技术。
在自然语言处理任务中,训练集大多为一个字或者一个词,把他们转化为计算机适合处理的数值类数据非常重要。
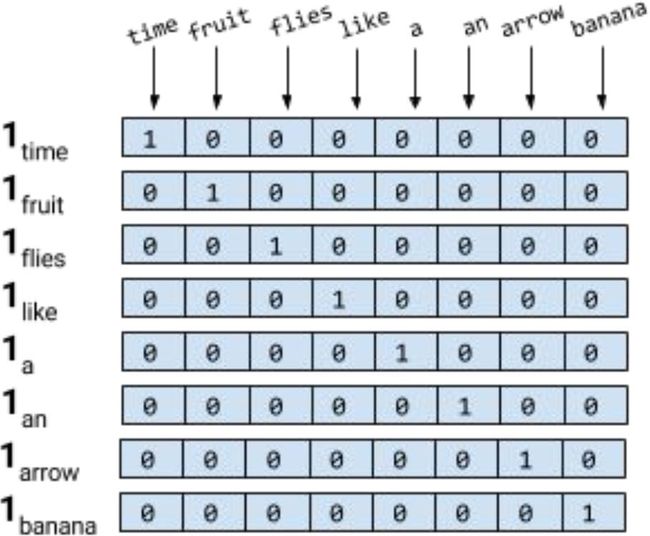
但是,对于独热表示的向量,如果采用余弦相似度计算向量间的相似度,可以明显的发现任意两者向量的相似度结果都为 0,即任意二者都不相关,也就是说独热表示无法解决词之间的相似性问题。
余弦相似度计算公式:

Word Embedding
简单来说词向量就是用一个向量表示一个单词。
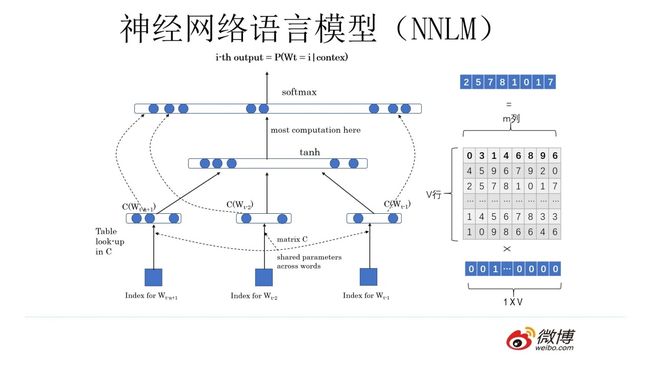
如上图所示,有一个Vxm的矩阵Q,这个矩阵 Q包含 V 行,V 代表词典大小,每一行的内容代表对应单词的 Word Embedding 值。矩阵Q是随机的,需要学习获得。
Word2Vec 模型
Word2Vec 的网络结构其实和神经网络语言模型(NNLM)是基本类似的,不过这里需要指出:尽管网络结构相近,而且都是做语言模型任务,但是他们训练方法不太一样。
Word2Vec 有两种训练方法:
第一种叫 CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;
第二种叫做 Skip-gram,和 CBOW 正好反过来,输入某个单词,要求网络预测它的上下文单词。
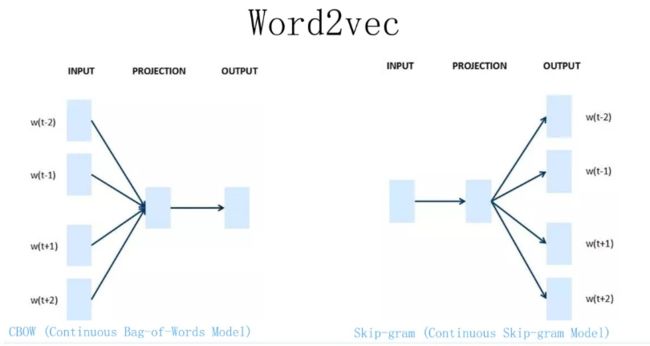
Word2Vec主要任务是通过训练学习获得矩阵Q,利用矩阵Q得到 Word Embedding,但是 Word2Vec无法解决一词多义的问题。