任你五花八门预训练方法,我自监督学习依然能打!
长时间没看论文,外面已经发展成这样了?
以下都是新paper,挑了几个感兴趣的,一起粗略看看吧~
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
GitHub | https://github.com/hsouri/Battle-of-the-Backbones
arXiv | https://arxiv.org/abs/2310.19909
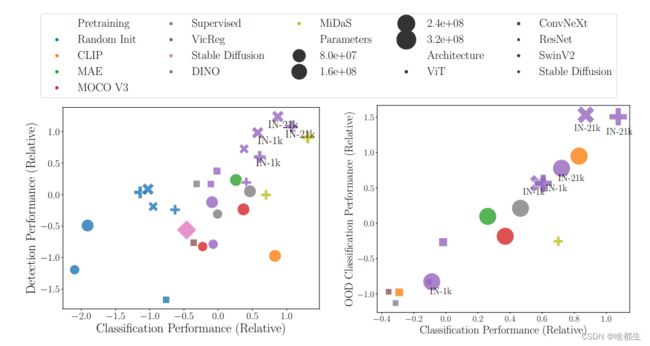
基于神经网络的计算机视觉框架通常主要由骨干(Backbones)构成,即一个经过预训练或随机初始化的特征提取器。几年前,首选项基本是在ImageNet上训练的卷积神经网络
然而,最近出现了很多采用各种算法和数据集进行预训练的骨干网络。虽然这些操作提高了部分网络的性能,但对于从业者来说,很难做出关于选择哪个骨干的决定
Battle of the Backbones (BoB) 通过对一系列经过预训练的模型进行基准测试,包括视觉语言模型、通过自监督学习训练的模型以及Stable Diffusion骨干,在从分类到目标检测再到OOD泛化等多样的计算机视觉任务中,使这个选择变得更加容易
此外,通过对1500多次训练的全面分析,揭示了现有方法的优势和劣势,为学界指明了推进计算机视觉的有希望的方向
虽然vision transformers(ViTs)和自监督学习(SSL)越来越受欢迎,但他们发现在大型训练集上以监督方式预训练的卷积神经网络在大多数任务中仍然表现最佳
此外,在相同架构和相似大小的预训练数据集上的同类比较中,作者发现自监督学习的Backbone仍然具有很强的竞争力,这表明未来的研究应该使用先进的架构和更大的预训练数据集进行自监督学习预训练
MM-VID: Advancing Video Understanding with GPT-4V(ision)

arXiv | https://arxiv.org/abs/2310.19773
MM-VID充分发挥了GPT-4V的能力,并结合了在视觉、音频和语音领域的专业工具,以促进对视频的高级理解
旨在解决长视频和复杂任务(如对长达一小时的内容进行推理以及理解跨多个剧集的情节)带来的挑战。利用GPT-4V进行视频到脚本的生成,将多模态元素转录成一个长文本脚本
生成的脚本详细描述了角色的移动、动作、表情和对话,为大型语言模型(LLMs)实现视频理解提供了数据。使得音频描述、角色识别和多模态高级理解成为可能
实验结果展示了处理不同视频流派和各种视频长度方面的有效性。此外,还展示了在交互环境中应用MM-VID的潜力,例如视频游戏和图形用户界面
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing

GitHub | https://github.com/LLaVA-VL/LLaVA-Interactive-Demo
arXiv | https://arxiv.org/abs/2311.00571
LLaVA-Interactive是一个用于多模态人机交互的研究原型。该系统能够通过获取多模态用户输入并生成多模态响应,与用户进行多轮对话
值得注意的是,LLaVA-Interactive不仅限于语言提示,还支持视觉提示,以对齐交互中人类的意图。该系统结合了LLaVA的视觉聊天、SEEM的图像分割以及GLIGEN的图像生成和编辑等三种预建AI模型的多模态技能,无需额外的模型训练
为了展示LLaVA-Interactive的潜力并激发未来多模式交互系统的研究,论文中演示了多种应用场景
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
GitHub | http://kylesargent.github.io/zeronvs/
arXiv | https://arxiv.org/abs/2310.17994
飞飞团队~,这篇论文介绍了一种3D感知扩散模型,ZeroNVS,用于野外场景的单图像新视角合成。虽然现有方法用于带有遮罩背景的单个对象,但本文提出了新的技术来解决野外多对象场景和复杂背景引入的挑战
具体而言,在捕获以对象为中心的室内和室外场景的混合数据源上训练生成先验。为了解决由深度尺度模糊等数据混合引入的问题,提出了一种新颖的相机调节参数化和归一化方案
此外,观察到在对360°场景进行蒸馏期间,Score Distillation Sampling(SDS)往往会截断复杂背景的分布,因此提出了SDS anchoring以提高合成新视角的多样性
在zero-shot settin下,提出的模型在DTU数据集上在LPIPS方面取得了新的最先进结果,甚至超过了专门在DTU上训练的方法
他们进一步将具有挑战性的Mip-NeRF 360数据集作为单图像新视角合成的新baseline,并在这一设置中展示了强大的性能
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
arXiv | https://arxiv.org/abs/2310.19512
视频生成在学术界和工业界越来越受到关注。尽管商业工具可以生成合理的视频,但对于研究人员和工程师来说,可用的开源模型数量有限。在这项工作中,作者介绍了两个用于高质量视频生成的扩散模型,即文本到视频(T2V)模型和图像到视频(I2V)模型
T2V模型根据给定的文本输入合成视频,而I2V模型则包含额外的图像输入。所提出的T2V模型可以生成分辨率为1024*576的电影画质视频,其在质量方面优于其他开源T2V模型。I2V模型旨在生成严格遵循所提供参考图像内容的视频,保持其内容、结构和风格的完整性
该模型是第一个能够将给定图像转换为视频剪辑并保持内容约束的开源I2V基础模型。作者相信这些开源视频生成模型将为社区内的技术进步做出重要贡献
以上就是本期全部内容,期待点赞在看,我是啥都生,下次再见