Redis 命令处理过程
我们知道 Redis 是一个基于内存的高性能键值数据库, 它支持多种数据结构, 提供了丰富的命令, 可以用来实现缓存、消息队列、分布式锁等功能。
而在享受 Redis 带来的种种好处时, 是否曾好奇过 Redis 是如何处理我们发往它的命令的呢?
本文将以伪代码的形式简单分析一下 Redis 命令处理的过程, 探讨其背后的机制。
1 例子
set myKey myValue
ok
上面是一个简单的 Redis 命令执行过程:
- 用户借助 Redis 的客户端 (redis-cli, 或者各种第三方的客户端) 向 Redis 服务端发送了一个 set 命令
- Redis 服务端将其后面的 myKey 和 myValue 存储下来
- Redis 服务端再向客户端响应一个 ok 值, 表示处理成功。
下面我们就以这个为例子, 来分析一下 Redis 命令处理的过程。
备注:
- 下面的逻辑, 是按照 Redis 5.x 的版本进行分析的, 各个大版本之间可能会有出入
- 在伪代码分析过程中, 会将大部分无关的逻辑和异常场景进行省略
- 因为整个过程会涉及到大量 Redis 事件轮询的知识和以 set 为例, 会涉及 Redis String 编码的知识, 可以先看一下往期这 2 篇先了解一下
2 认识一下 redisServer 和 client
在真正进行分析前, 有 2 个对象需要先介绍一下, 可以说他们贯穿了整个命令处理的过程。
2.1 redisServer
redisServer 可以看做是整个 Redis 服务端运行时的上下文, 保存着整个 Redis 的配置和运行中产生的数据。
public class redisServer {
// Tcp 连接对应的文件描述符 fd 存放的数组
int[] ipfd = new int[16];
// 所有存入到 Redis 中的数据, 都会存放到这里
redisDb[] db = new redisDb[16];
// 命令字典, 保存着 Redis 支持的所有命令
// Redis 支持的所有命令和命令对应的执行函数, 都会存放到这里
dict commands;
// 一个双向链表, 所有连接到 Redis 的客户端, 都会存放到这里
List<client> clients;
// 向 Redis 发起请求的客户端, Redis 处理完成后, 如果需要响应客户端数据
// 会将这个客户端先放到这里, 后面统一响应
List<client> clients_pending_write;
// 事件循环, Redis 的核心
aeEventLoop el;
}
2.1.1 int[] ipfd
bind 127.0.0.1
上面的配置应该很熟悉吧。
在 Redis 的配置文件中, 加上了这个配置, 就表示 Redis 只有本地可以访问, 因为他只会监听本地机器上的的连接, 当然也可以配置具体的 Ip 地址。
在 Redis 服务端启动后, 会和bind 指定的 Ip 地址 建立对应的 Tcp 连接, 同时会获取到一个文件描述符 fd (可以理解代表当前 Tcp 连接的唯一 Id, 持有这个文件描述符, 代表了持有了对应的端口的监听能力),
并将连接的 fd 存放在这个 ipfd 数组中, 最大支持 16 个连接。
2.1.2 redisDb[] db
Redis 本身默认支持 16 个数据库, 只是我们正常情况都是在使用 0 号数据库。 可以通过 select [0 到 15] 进行切换。
而这个 redisDb[] db 是一个长度为 16 的数组, 每个元素都是一个 redisDb 对象, 代表着一个 Redis 数据库。
redisDb 本身的定义很简单, 如下:

其中 dict 是字典的意思, 本身就是一个 key-value 的数据结构, 可以直接看做是一个 Map (JDK 1.7 的 HashMap), 本质是一个数组, 数组中的每个元素是一个 dictEntry。
当发送了 set myKey myValue 到服务端, myKey, myValue 就会以键值对的形式存储在 redisDb 中的 dict 中。
2.1.3 dict commands
首先它也是一个 dict, 也就是一个 Map, 一个 key-value 的映射属性, 具体的含义就是命令字典。
在平时中执行的 Redis 命令, 这个命令对应的执行函数就是存放在这里, 格式如: Map<命令的 key, redisCommand>。
当发送了 set myKey myValue 到服务端, 服务端就用通过 set 这个命令 key 到这里找到对应的 setCommand, 然后执行里面的函数。
2.1.4 List clients
客户端双向链表。
Redis 本身是支持多个客户端的, Redis 接收到客户端的连接后, Redis 内部会将其封装为 client, 然后维护在这个双向链表。
具体的属性下面讲解。
2.1.5 List clients_pending_write
待响应客户端双向链表。
服务端处理完客户端的请求后, 可能需要响应客户端结果, 也就是响应数据。
而 Redis 不是处理完就立即响应的, 而是先将响应结果放到客户端的输出缓存区, 然后再后面统一一起响应。
所以, 有数据需要响应的客户端, 会将其放到这个链表中。
2.1.6 aeEventLoop *el
事件轮询对象: 本质就是一个包装了多路复用的死循环。
大体的实现如下:

2.2 client
client 是理解 Redis 命令处理过程的另一个重要对象, 他代表着一个客户端连接。
Redis 客户端连接到服务端时, 服务端将这个客户端的封装成这个对象。
client 本身的属性如下:
public class client {
// 同 redisServer 的 ipfd
// 当 Redis 接收到客户端的连接后, 会获取到一个代表这个客户端 Tcp 连接的文件描述符 fd, 然后存放到这个属性中
int fd;
// 当前客户端的是否已经经过了密码认证, 0 代表未认证, 1 代表已认证
int authenticated;
// 输入缓存区, 客户端发送过来的数据会先存放在这里
sds querybuf;
// 命令参数的个数, 一个客户端发送过来的命令, 会被 Redis 拆分成多个参数
// 比如 set myKey myValue, 总共 3 个参数
int argc;
// 命令参数, 一个客户端发送过来的命令, 会被 Redis 拆分成多个参数
// 比如 set myKey myValue, 就会被拆分成 3 个参数, 3 个参数会存放在这个数组中
robj[] argv;
// 一个数组, 固定输出缓冲区, 用来存放响应客户端的数据
char[] buf = new char[16 * 1024];
// 一个链表, 动态输出缓冲区, 同样是用来存放响应客户端的数据
List<clientReplyBlock> reply;
}
下面介绍一下几个重要的属性。
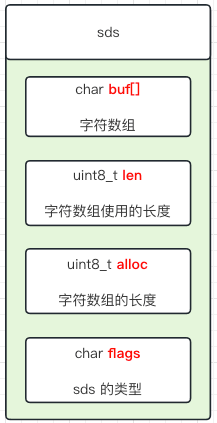
2.2.1 sds querybuf
输入缓冲区。
客户端发送到服务端的数据, Redis 服务端收到了, 会先存放到这里。实现结构是一个 sds。 大体的定义如下:
2.2.2 robj[] argv
querybuf 中的数据进行解析后的数据存放的地方, 具体的属性是一个 redisObject 的数组。
而一个 sds 类型 redisObject 的结构如下:

2.2.3 char[] buf
一个可以存放 16 * 1024 个字符的数组。 客户端发送的命令, Redis 服务端处理完成后, 需要进行响应, 而响应的内容会先存放到这里。
因为是一个长度固定的数组, 所以叫做固定输出缓冲区, 最多可以存放 16kb 的响应数据。
2.2.4 List reply
动态输出缓冲区。
当 Redis 服务端响应客户端数据大于上面的 char[] buf 的容量时, 就先放到这里 (双向链表理论上没有大小限制)。
本质是一个 clientReplyBlock 的双向链表。
clientReplyBlock 的定义也很简单。如下, 可以简单的看做是一个 char[] 的封装。

可以看出来, Redis 的响应缓存区是由一个固定大小的 char 数组加一个动态变化的 char 数组链表共同构成的。
这么组织的好处是: 16kb 的固定 buffer, 基本满足大部分的情况的使用, 提前声明好可以避免频繁分配、回收内存。
动态的响应链表则是起到一个兜底的作用, 保证大数据量时的响应。而本身在需要时进行再分配内存, 使用后释放, 可以起到节省内存的作用。
到此, Redis 命令处理过程中的 2 个重要对象: redisServer 和 client 就介绍完了, 只需要大体知道 2 个对象里面有哪些属性, 大体是干什么的即可,
怎么实现等都可以不用深入, 在开始前先介绍这 2 个对象, 只是是为了后面的分析更加清晰。
3 Redis 服务端启动流程
./redis-server ./redis.conf --port 6666 --dbfilename dump.rdb
在服务器上可以通过上面的命令启动一个 Redis 服务端。
启动脚本 redis-server 后面紧跟的是 Redis 的配置文件, 再后面是用户想要指定的参数 (这里将端口修改为 6666)。
整个启动的过程如下:

- 通过脚本启动 Redis 服务端
- 创建一个 redisServer 对象, 这时 redisServer 里面所有的配置都是默认值, 比如监听的端口, 连接超时等
- 读取配置文件和命令行参数并覆盖掉 redisServer 里面的默认配置, 比如这里的端口, 默认为 6379, 通过命令行参数覆盖为 6666, 在这个过程, 还会将 server.c 里面写好的命令和命令对应的函数从一个静态数组中加载到 redisServer 的 commands 字典中
- 将 redisServer 里面的事件轮询 aeEventLoop 创建出来
- 和配置文件里面的 bind 地址 + 启动端口建立起 Tcp 连接, 可以得到对应连接的文件描述 fd, 可以理解为一个 Id
- 为每一个文件描述符, 也就是 Tcp 连接, 在事件轮询中注册一个可读的文件事件, 执行函数为 acceptTcpHandler (可以理解为告诉多路复用, 关心对应的 Tcp 连接的连接事件, 触发了执行 acceptTcpHandler 函数)
- 从磁盘中将 Redis 上次运行的数据加载到 redisServer 的 16 个 redisDb 中 (如果有的话)
- 设置事件轮询的阻塞前和阻塞后执行的函数
- 启动事件轮询, 进入一个死循环, 整个 Redis 服务端启动成功
大体的伪代码逻辑如下:
// server.c
int main(int argc, char **argv) {
// 1. redisServer 各个属性进行默认值设置
initServerConfig();
// 2. 解析命令行参数
// 启动脚本的参数会通过 main 方法的 argv 传递进来, 这里会对这些参数进行解析处理
parsingCommandLineArguments();
// 3. 根据配置文件和命令行参数的配置覆盖掉 redisServer 的默认值
// 内部会执行一个函数 populateCommandTable(), 将 Reids 所以支持的命令和对应的函数放到 redisServer.commands 中
loadServerConfig()
// 4. 初始化服务端
// 4.1 创建事件轮询对象
// 4.2 对所有绑定的 Ip 对应的 6666 端口(默认为 6379, 上面启动命令修改为了 6666) 开启 TCP 监听, 并得到对应的 Ip 文件描述符 fd, 存放到 redisServer 的 ipfd 中
// 4.3 对 Redis 的 16 个数据库进行初始化
// 4.4 向事件轮询注册 1 个时间事件: 1 毫秒执行一次, 执行函数 serverCron
// 4.5 对每个 ipfd 向事件轮询注册 1 个可读的文件事件: 执行函数 acceptTcpHandler
// 其他无法的省略
initServer();
// 5. 从磁盘中加载数据到 redisServer 的 redisDB 中 (AOF, RDB)
loadDataFromDisk();
// 6. 向事件轮询注册 阻塞前调用函数 beforeSleep
aeSetBeforeSleepProc(server.el,beforeSleep);
// 7. 向事件轮询注册 阻塞后调用函数 afterSleep
aeSetAfterSleepProc(server.el,afterSleep);
// 8. 启动事件轮询, 这时进入了死循环, 整个服务端启动
aeMain(server.el);
// 9. 从事件轮询中退出来,表示程序需要退出了, 删除事件轮询
aeDeleteEventLoop(server.el);
return 0;
}
启动后的 redisServer 的状态如下:

4 Redis 客户端连接服务端
Redis 服务端端启动后, 整个 Redis 就进入到事件轮询里面的死循环, 一直在执行下面的逻辑
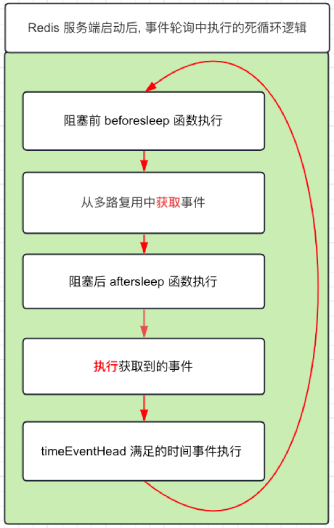
这时有个客户端通过 Ip + 端口连接到 Redis 服务端, 多路复用观察到有上游关心的可读事件, 会保留下这个连接请求事件。
这时 redisServer 的事件轮询执行到了 从多路复用中获取事件, 获取到了客户端的连接事件, 接着触发了 acceptTcpHandler 函数。

触发的 acceptTcpHandler 函数的逻辑如下:

- 将连接到 Redis 服务端的客户端封装为 client, 代表当前的客户端
- 将封装后的 client, 放到 redisServer 的客户端双写链表 List
clients 中 - 向事件轮询为这个客户端注册一个可读的文件事件, 触发执行的函数为 readQueryFromClient
大体的伪代码逻辑如下:
// networking.c
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask){
// 1. 获取客户端 Tcp 连接对应的文件描述符
int cfd = anetTcpAccept();
// 2. 创建 client
createClient();
// 3. 向事件轮询注册一个当前客户端的可读的文件事件, 执行函数为: readQueryFromClient
registerClientFdReadFilesEvent();
// 4. 初始化 client 的属性, 比如选中的数据库默认为第一个, 输入和输出缓存区创建
initClient();
// 5. 将 client 添加到 redisServer 的 client 双向链表中
linkClient();
// 6. 最大客户端数量检查, 如果超过了, 就关闭这个连接 (默认为 10000)
maxClientNumCheck();
// 7. 保护模式检查, 默认开启 (protected-mode yes)
// 开启保护模式时, 没有配置 bind Ip 和密码, 同时客户端的 Ip 地址不是 127.0.0.1 或 ::1, 就关闭这个连接
protectedModeCheck();
}
接受了客户端的连接后的 redisServer 的状态如下:

5 客户端发送命令到服务端
Redis 的客户端和服务端之间的数据的传输, 都是遵循内部自定义的一套协议: RESP。
5.1 RESP 协议
当用户在客户端输入对应的请求命令时, 比如 set myKey myValue, 客户端会将这个命令转换为 RESP 协议的格式, 然后发送到服务端。
RESP 介绍的具体介绍, 可以看一下这篇文章
所有的内容通过 \r\n 进行分割, 然后定义了几个标识符, 如下:
+ 标识后面是一个简单的字符串
$ 表示后面的内容是一个二进制安全的字符串, 后面会紧跟着一个数字, 表示字符串的长度
* 表示后面的内容是一个数组, 后面同样紧跟一个数字, 表示数组的长度
… 后面省略
比如:
set myKey myValue
- 三个字符串 (set + myKey + myValue), 那么转换后就是 3 个二进制安全的字符串, 所以开头就是
*3 - 跟后面的内容用 \r\n 分隔, 所以就是
*3\r\n - 第一个字符串是 set, 长度 3, 所以就是
*3\r\n$3\r\nset\r\n - 后面的 myKey 和 myValue 类似, 最终转换后的内容如下
*3\r\n$3\r\nset\r\n$5\r\nmyKey\r\n$7\r\nmyValue\r\n
5.2 请求类型
在 Redis 解析客户端的请求内容前, 还需要确定当前的请求的方式, 判断的逻辑如下:
// 请求内容以 * 开头, 那么请求类型为 mult bulk 请求, 否则是 inline 请求
if (c->querybuf[c->qb_pos] == '*') {
c->reqtype = PROTO_REQ_MULTIBULK;
} else {
c->reqtype = PROTO_REQ_INLINE;
}
可以看到 Redis 支持 2 种请求的类型 mult bulk 请求, 还是 inline 请求。
2 者的区别也很简单, 以请求内容的开头是否为 * 开头进行区分。
以 * 开头的内容, 可以看出就是遵循 REST 协议的请求, 而其他的请求就是 inline 请求。
之所以有 inline 请求, 其实是为了兼容一下特殊的客户端, 比如 Linux 的 telnet 等。
在 Linux 可以通过 telnet Ip 端口 连接到服务端, 然后直接发送请求到服务端, 而这些请求是直接发送到服务端的, 没有中间转为 RESP 协议的。
所以 Redis 选择了兼容这些特殊的情况, 并将这些请求称为 inline 请求。
所以客户端发送命令到服务端的过程如下

- Redis 客户端接收用户的输入请求
- 将这些请求按照 RESP 协议进行转换 (inline 请求, 不会有这一步)
- 将转换后的请求内容发送给 Redis 服务端
6 服务端接收到客户端发送的命令
在上面客户端连接时, 向事件轮询中为当前的客户端注册了一个可读的文件事件, 触发函数为 readQueryFromClient。
而在客户端将请求发送到服务端后, 事件轮询从多路复用中获取到了这个文件事件后, 会执行里面的函数 readQueryFromClient 函数。
整个 redisQueryFromClient 可以拆分为 2 部分
- 请求参数处理
- 具体请求命令的执行
6.1 请求参数处理
在上面我们知道, 客户端向服务端发送了一段 RESP 格式的请求 *3\r\n$3\r\nset\r\n$5\r\nmyKey\r\n$7\r\nmyValue\r\n, 服务端会
- 将客户端发送过来的请求
*3\r\n$3\r\nset\r\n$5\r\nmyKey\r\n$7\r\nmyValue\r\n, 原封不动的存储到对应 client 的输入缓冲区 queryBuf
- 存储在 client querybuf 的内容
*3\r\n$3\r\nset\r\n$5\r\nmyKey\r\n$7\r\nmyValue\r\n, 按照 RESP 协议解析为 3 个 embstr 编码的 redisObject (String 的三种编码有讲解), 然后存储到 client 的 argv 数组中。
- 根据 client 的参数数组 argv 的第一个参数 (第一个参数一定是命令参数) 到 redisServer 的命令字典 commands 查找当前的命令
- 找到命令后, 当然是执行对应的命令里面的函数了



上面是 redisQueryFromClient 第一部分, 忽略请求命令的逻辑后的简化过程, 想要继续深入了解里面的其他判断可以看一下下面的伪代码
// networking.c
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
// 1. 先将客户端的请求数据读取到 client 的 querybuf 中
putRequestContentIntoClientQueryBuffer();
// 2. 如果 querybuf 中的数据超过了 1GB, 就关闭这个连接
checkClientQueryBufferMoreThanOneGb();
// 3. 临时暂停这次请求, 等待后面触发, 对应的状态有
// 3.1 当前的 client 的为阻塞状态 (如果 querybuf 中的数据超过了 256MB, 就将这个 client 的状态设置为 REDIS_BLOCKED)
// 3.2 当前有一个 lua 脚本在执行中
// 3.3 当前的客户端是准备关闭状态
// 3.4 客户端被暂停了
temporaryPaurseThisRequest();
// 4. 根据请求参数的第一个字符是否为 *, 确定当前的请求是 mult bulk 请求还是 inline 请求
confirmThisRequestType();
// 5. 根据请求类型, 对 querybuf 的参数进行解析, 然后存放到 argv
parseRequestContentIntoClientArgvByRequestType();
// 6. 命令处理
processCommand();
}
// server.c
int processCommand(client *c) {
// 1. 模块过滤器, 前置处理
// https://redis.io/resources/modules/
moduleCallCommandFilters(c);
// 2. argv[0] 为 quit (断开连接)
// 将客户端的标识设置为 client_close_after_reply, 等待后面的处理, 然后返回
ifQuitCommandHandle(c);
// 3. 根据 argv[0], 也就是 key, 从 redisServer 的 commands 中找到对应的 redisCommand, 也就是执行命令
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
// 4. 命令 null 检查和命令需要的参数格个数和实际参数个数检查, 不符合就返回错误
commandNullAndArgumentsNumberCheck(c->cmd, c->argc);
// 5. 服务端需要密码认证, 同时当前的客户端未认证, 并且执行的命令不是 auth 命令, 返回错误
requirePassCheckWhenCmdNotAuth(c->authenticated, c->cmd);
// 6. 开启了集群模式, 根据 key 计算出对应的执行服务端节点, 如果当前的服务端不是执行的服务端节点, 通知客户端重定向
redirectClientIfNeedByKeyWhenClusterEnabled();
// 7. 如果设置了最大内存同时当前没有正在执行的 lua 脚本, 就尝试释放内存
tryToReleaseMemoryWhenSetMaxMemoryAndNoLuaScriptTimeout();
// 8. 当前是主节点, 磁盘检测失败, 执行的命令具备变更属性(新增, 修改, 删除等)或者是 ping 命令, 返回错误
// 磁盘检测失败的场景
// 8.1 开启了 RDB, 上一次 RDB 失败了, 同时配置了 RDB 失败停止写操作 (stop_writes_on_bgsave_error yes)
// 8.2 开启了 AOF, 上一次 AOF 失败了
pingAndWriteCommandsDeniedByDiskErrorByMaster();
// 9. 主从复制配置检查
// 配置了 repl_min_slaves_to_write 和 repl_min_slaves_max_lag
// 当前需要有多少个心跳正常的从节点存活, 否则变更属性的命令不执行, 返回错误
writeCommandsDeniedByMinSlavesNumberReply();
// 10. 当前的客户端是从节点, 并且配置了 slave_read_only, 并且执行的命令具备变更属性, 返回错误
writeCommandDeniedBySlaveReadOnly();
// 11. 当前的客户端是一个订阅客户端 (subscribe), 执行的命令不是 subscribe, unsubscribe, psubscribe, punsubscribe, ping, 返回错误
subscribeClientCanHandleCommandCheck();
// 12. 从节点和主节点失去了联系或者正在执行复制中, 同时 slave-serve-stale-data 设置为了 no, 执行的命令不是 stale 属性(info, slaveof), 返回错误
slaveSynchronizingOrConnectStateUnusualCheck();
// 13. 服务端正在从磁盘中加载数据, 执行的命令不是 loading 属性(info, subscribe, unsubscribe, psubscribe, punsubscribe, publish) , 返回错误
loadingFromDiskCheck();
// 14. 当前正在执行 lua 脚本, 执行的命令不是 auth, replconf, shutdown, script, 返回错误
luaScribtBusyCheck();
// 15. 开启了事务, 执行的命令不是 exec, discard, multi, watch, 返回错误
if (openTranscation() && commandIsNotExecAndDiscardAndMultiAndWatch()) {
// 15.1 命令入队列
queueMultiCommand()
return C_OK;
}
// 17. 将要执行的命令, 发送给监控器
// Redis 客户端可以成为服务端的监控器, 服务端执行的命令会同步传输给客户端
sendCommandToMonitors();
// 18. 对应 key 的命令函数执行, 后面会以 setCommand 为例进行分析
c->cmd->proc(c);
// 19. 如果需要,进行统计记录
latencyAddSampleIfNeeded();
// 20. 如果需要, 慢日志记录
slowlogPushEntryIfNeeded();
// 21. 命令传播, 如果有必要进行命令替换
// aof 和 主从复制需要当前执行的命令进行数据处理
// 一些随机性的命令, 不能直接就传播出去, 需要根据当前的执行结果进行替换, 比如 SPOP key [count], 从 set 中随机弹出若干个元素
propagateCommand();
}
6.2 具体请求命令的执行
在 redisQueryFromClient 的逻辑中, 有一段代码
int processCommand(client *c) {
......
// 这一步就是具体的命令执行的地方, 以 set 命令为例, 了解一下 set 命令的执行过程
c->cmd->proc(c);
......
}
就是具体的请求命令的执行时机, 这里以 setCommand 为了, 这次直接看伪代码先
// t_string.c
void setCommand(client *c) {
// 上面的 c->cmd->proc(c), 最终执行到的函数就是这个
// SET key value [NX] [XX] [EX ] [PX ]
// 1. 根据参数计算超时时间
robj *expire = calExpireTime(c->argv, c->argc);
// 2. 尝试对 value 进行字符串的编码优化
// 2.1 编码不是 embstr 和 raw, 就直接返回原数据, 不是字符串类型, 没必要优化
// 2.2 value 长度小于 20, 同时可以转为整数
// 2.2.1 没有配置最大内存, 同时内存回收策略不是 MAXMEMORY_FLAG_NO_SHARED_INTEGERS (涉及 lru/lfu 这 2 种模式的回收策略),
// 转换的数字大于等于 0, 小于 10000, 返回共享整数池中返回这个数字, 都不满足, 新建一个整数
// 2.2.2 原本的 reidsObject 的编码为 raw, 将入参的 redisObject 转为 int 编码, *ptr 修改为转换后的整数值
// 2.2.3 原本的 reidsObject 的编码为 embstr, 重新创建一个新的 int 编码的 redisObject
// 2.2 逻辑结束 下面为 2.2 不满足情况
// 2.3 入参的 redisObject 内容长度小于等于 44, 重新创建一个 embstr 的字符串, 将入参的 redisObject 转为 embstr 编码, *ptr 修改为转换后的整数值
// 2.3 逻辑结束 下面为 2.3 不满足情况
// 2.4 到了这里, 说明客户端传过来的 value 大于 44, 只能用 raw 编码, 但是 raw 编码还可以 尝试进行 trim 优化, 也就是去空格
c->argv[2] = tryObjectEncoding(c->argv[2]);
// 3. 将 key 和 value 存放到 当前客户端选择的 redisDb[] db 中
putTheKeyAndValueToDb(c->db, c->argv[1], c->argv[2]);
// 4. 如果设置了参数时间, 将更新 redisObject 的 expireTime
setExpireTimeIfNeed(c->db, c->argv[1], expire);
// 5. 如果需要, 将当前的客户端放到 redisServer 的 pending_write_clients 中, 表明当前的客户端有数据需要响应
putCurrentClientToClientsPendingWriteIfNeed();
// 6. 将响应内容 +OK\r\n (响应结果也遵循 RESP 协议) 写入到客户端的 buf 中, 无法写入就写入到客户端的 reply
tryWriteResponseToBufOrReply();
// 7. 当写入的内容是写入到 reply 中时, 需要检查当前客户端待响应的内容的大小是否超过了限制, 是的话, 关闭当前客户端
checkClientOutputBufferLimitsWhenWriteToReply();
}
逻辑概括如下:
- 根据参数计算超时时间, Redis 的 set 命令支持很多种参数格式, 需要根据这些参数计算出一个当前 String 的过期时间 (如果有设置的话)
- 参数数组 argv[2], 一定是要存入到 Redis 的 value, 当前的 value 虽然已经是 redisObject 了, 但如果它是 embstr 和 raw, 尝试寻找更合适的编码 (这一部分都是 Redis String 编码的内容)
- 将处理好的 myKey 和 myValue 存到 redisServer 的 redisDb 数组中的第一个 (如果使用前, 通过 select 修改了使用的数据库, 那么存在对应的数据库, 默认为 0, 第一个)
- 如果有必要, 对 redisObject 的过期时间的进行更新
- 数据处理完了, 当前的命令如果有数据需要响应客户端时, 需要将当前客户端放到 redisServer 的待响应客户端双向链表 clients_pending_write 中, set 命令处理完需要响应一个 ok, 所以当前 client 需要加入这个链表
- 如果有数据需要响应, 将响应的数据放到 client 的固定输出缓冲区 char buf[] 中, 如果无法直接存放进去, 则存放到动态输出缓冲区 List reply 中, set 回应的是 ok, 经过 RESP 协议后假设可以直接放到固定输出缓冲区




服务端接收到客户端发送的命令并处理后, redisServer 的状态如下:

此时 client 的状态如下:

7 服务端响应客户端
存放在 client 的输出缓冲区的数据, 是什么时候发送给客户端的呢?
在 Redis 里面是经过 2 个步骤实现的
- 为每一个待发送的客户端注册一个可写的文件事件, 执行函数为 sendReplyToClient
- 事件轮询获取这个可写事件并触发 sendReplyToClient 函数
7.1 为待发送的客户端注册发送数据的文件事件
Redis 服务端端启动后, 整个 Redis 就进入到事件轮询里面的死循环, 一直在执行下面的逻辑
!
而这次在阻塞前 beforesleep 函数执行 时, 在 beforesleep 函数中会:
遍历 redisServer 的待响应客户端双向链表 clients_pending_write 中的所有客户端,
- 将对应的客户端从双向链表删除
- 删除的客户端如果有数据要发送, 为他在多路复用各注册一个可写的文件事件, 触发函数 sendReplyToClient

对应的地方为 beforeSleep 函数逻辑如下:
// server.c
void beforeSleep(struct aeEventLoop *eventLoop) {
......
// 处理带有输出缓冲区的客户端
handleClientsWithPendingWrites();
......
}
int handleClientsWithPendingWrites(void) {
client *c
// 1. 遍历 redisServer 的 clients_pending_write
while(c = getNextNodeFromLinkList(server.clients_pending_write)) {
// 将当前的 client 从 clients_pending_write 链表中删除
removeTheClientFromeClientsPendingWrite(c);
// 当前的客户端有数据需要发送 (client->buf 或 client->reply 不为空),
// 向多路复用注册一个可写的文件事件, 执行函数为 sendReplyToClient
registFileEventForClientWhenClientHaveDataToWrite(c);
}
}
7.2 触发发送数据的文件事件
事件轮询在执行完阻塞前函数后, 又进入到多路复用中获取文件事件, 这时会获取到刚刚注册的可写事件文件, 触发 sendReplyToClient 的逻辑, 过程如下:

- 逐步将 client 的缓冲区推送给客户端 (单次推送数据有上限要求, 超过的需要到下次事件轮询再推送)
- client 推送数据完成, 将其对应的文件事件从多路复用中删除 (如果还有数据没推送, 事件不会被删除, 下次事件轮询还能触发, 推送剩下的)
具体的逻辑如下:
// networking.c
void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
// client 的输出缓冲区有数据需要发送
while(clientHasPendingReplies(c)) {
// client 的 buf 有数据需要发送
if (clientBufHasDataToSend(c)) {
writeDataToClient();
} else {
// 如果 client 的 reply 有数据, 获取链表的第一个节点, 将里面的数据发送给客户端, 同时从双写链表中删除这个节点
writeDataToClientIfClientReplyHasData();
}
// 当前已经发送的数据达到了单次发送的上线 1024*64
if (currentHaveSendMoreThanMaxLimit()) {
// 没有设置最大内存, 当前发送数据停止
if(noSetMaxMemory()) {
break;
}
// 设置了最大内存, 当前已经使用的内存大小小于最大内存, 当前发送数据停止
if (haveSetMaxMemoryAndCurrentUsedMemoryLessThanMaxMemory()) {
break;
}
// 设置了最大内存了, 当前使用的内存大于等于最大内存了, 继续循环, 尽量多发送一些, 释放内存
}
}
// 当前 client 没有数据需要发送了
if (!clientHasPendingReplies(c)) {
// 从事件轮询中删除当前的发送数据事件
delCurrentFileEventFromEventLoop();
}
// client 还有数据, 那么不删除事件, 继续保留, 下次事件轮询执行, 继续执行
需要留意的是执行一个 sendReplyToClient 函数, 给这个客户端推送数据
- 每次个客户端推送数据最大为 1024 * 64, 超过了会停止这次推送, 将剩下的留到下次再继续推送 (伪代码里面表明了一些特殊情况了)
至此
set myKey myValue
ok
一个完整的流程就结束了。