CNN实现手写数字识别(Pytorch)
CNN结构
CNN(卷积神经网络)主要包括卷积层、池化层和全连接层。输入数据经过多个卷积层和池化层提取图片信息后,最后经过若干个全连接层获得最终的输出。
 CNN的实现主要包括以下步骤:
CNN的实现主要包括以下步骤:
- 数据加载与预处理
- 模型搭建
- 定义损失函数、优化器
- 模型训练
- 模型测试
以下基于Pytorch框架搭建一个CNN神经网络实现手写数字识别。
CNN实现
此处使用MNIST数据集,包含60000个训练样本和10000个测试样本。分为图片和标签,每张图片是一个 28 × 28 28 \times 28 28×28 的像素矩阵,标签是0~9一共10种数字。每个样本的格式为[data, label]。
1. 导入相关库
import numpy as np
import torch
from torch import nn
from torchvision import datasets, transforms,utils
from PIL import Image
import matplotlib.pyplot as plt
2. 数据加载与预处理
# 定义超参数
batch_size = 128 # 每个批次(batch)的样本数
# 对输入的数据进行标准化处理
# transforms.ToTensor() 将图像数据转换为 PyTorch 中的张量(tensor)格式,并将像素值缩放到 0-1 的范围内。
# 这是因为神经网络需要的输入数据必须是张量格式,并且需要进行归一化处理,以提高模型的训练效果。
# transforms.Normalize(mean=[0.5],std=[0.5]) 将图像像素值进行标准化处理,使其均值为 0,标准差为 1。
# 输入数据进行标准化处理可以提高模型的鲁棒性和稳定性,减少模型训练过程中的梯度爆炸和消失问题。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])])
# 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transform,
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transform,
download=True)
# 创建数据加载器(用于将数据分次放进模型进行训练)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True, # 装载过程中随机乱序
num_workers=2) # 表示2个子进程加载数据
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=2)
加载完数据后,可以得到60000个训练样本和10000个测试样本
print(len(train_dataset))
print(len(test_dataset))
![]()
以及469个训练批次和79测试批次
# batch=128
# train_loader=60000/128 = 469 个batch
# test_loader=10000/128=79 个batch
print(len(train_loader))
print(len(test_loader))
![]()
打印前5个手写数字样本看看
for i in range(0,5):
oneimg,label = train_dataset[i]
grid = utils.make_grid(oneimg)
grid = grid.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
grid = grid * std + mean
# 可视化图像
plt.subplot(1, 5, i+1)
plt.imshow(grid)
plt.axis('off')
plt.show()

这里用了 make_grid() 函数将多张图像拼接成一张网格图像,并调整了网格图像的形状,使得它可以直接作为 imshow() 函数的输入。这种方式可以在一张图中同时显示多张图像,比单独显示每张图像更加方便,常用于可视化深度学习中的卷积神经网络(CNN)中的特征图、卷积核等信息。
在 PyTorch 中,默认的图像张量格式是 (channel, height, width),即通道维度在第一个维度。 torchvision.transforms.ToTensor() 函数会将 PIL 图像对象转换为 PyTorch 张量,并将通道维度放在第一个维度。因此,当我们使用 ToTensor() 函数加载图像数据时,得到的 PyTorch 张量的格式就是 (channel, height, width)。代码中的 oneimg.numpy().transpose(1,2,0) 就是将 PyTorch 张量 oneimg 转换为 NumPy 数组,然后通过 transpose 函数将图像数组中的通道维度从第一个维度(channel-first)调整为最后一个维度(channel-last),即将 (channel, height, width) 调整为 (height, width, channel),以便于 Matplotlib 库正确处理通道信息。
2. 模型搭建
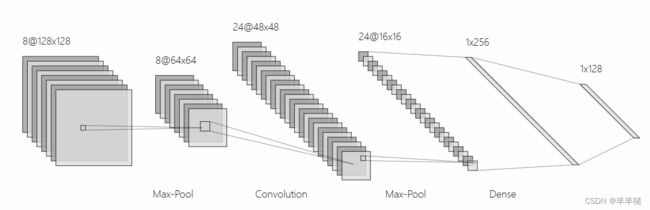
我们将使用Pytorch构建一个如下图所示的CNN,包含两个卷积层,和全连接层,并使用Relu作为激活函数。

接下来看以下不同层的参数。
卷积层: Connv2d
- in_channels ——输入数据的通道数目
- out_channels ——卷积产生的通道数目
- kernel_size ——卷积核的尺寸
- stride——步长
- padding——输入数据的边缘填充0的层数
池化层: MaxPool2d
- kernel_siez ——池化核大小
- stride——步长
- padding——输入数据的边缘填充0的层数
全连接层: Linear
- in_features:输入特征数
- out_features:输出特征数
代码实现如下:
class CNN(nn.Module):
# 定义网络结构
def __init__(self):
super(CNN, self).__init__()
# 图片是灰度图片,只有一个通道
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16,
kernel_size=5, stride=1, padding=2)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32,
kernel_size=5, stride=1, padding=2)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=7*7*32, out_features=256)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(in_features=256, out_features=10)
# 定义前向传播过程的计算函数
def forward(self, x):
# 第一层卷积、激活函数和池化
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
# 第二层卷积、激活函数和池化
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
# 将数据平展成一维
x = x.view(-1, 7*7*32)
# 第一层全连接层
x = self.fc1(x)
x = self.relu3(x)
# 第二层全连接层
x = self.fc2(x)
return x
定义损失函数和优化函数
import torch.optim as optim
learning_rate = 0.001 # 学习率
# 定义损失函数,计算模型的输出与目标标签之间的交叉熵损失
criterion = nn.CrossEntropyLoss()
# 训练过程通常采用反向传播来更新模型参数,这里使用的是SDG(随机梯度下降)优化器
# momentum 表示动量因子,可以加速优化过程并提高模型的泛化性能。
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9)
#也可以选择Adam优化方法
# optimizer = torch.optim.Adam(net.parameters(),lr=1e-2)
3. 模型训练
model = CNN() # 实例化CNN模型
num_epochs = 10 # 定义迭代次数
# 如果可用的话使用 GPU 进行训练,否则使用 CPU 进行训练。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 将神经网络模型 net 移动到指定的设备上。
model = model.to(device)
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images,labels) in enumerate(train_loader):
images=images.to(device)
labels=labels.to(device)
optimizer.zero_grad() # 清空上一个batch的梯度信息
# 将输入数据 inputs 喂入神经网络模型 net 中进行前向计算,得到模型的输出结果 outputs。
outputs=model(images)
# 使用交叉熵损失函数 criterion 计算模型输出 outputs 与标签数据 labels 之间的损失值 loss。
loss=criterion(outputs,labels)
# 使用反向传播算法计算模型参数的梯度信息,并使用优化器 optimizer 对模型参数进行更新。
loss.backward()
# 更新梯度
optimizer.step()
# 输出训练结果
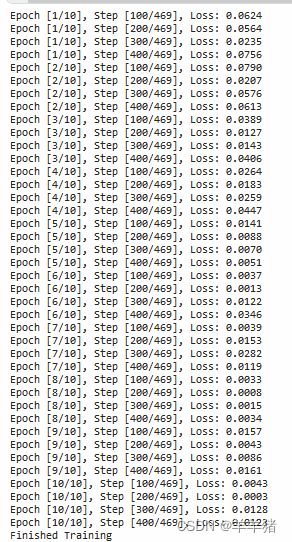
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
print('Finished Training')
保存模型
# 模型保存
PATH = './mnist_net.pth'
torch.save(model.state_dict(), PATH)
4. 模型测试
# 测试CNN模型
with torch.no_grad(): # 进行评测的时候网络不更新梯度
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
![]()
这里训练的模型准确率达到了98%,非常高,如果还想继续提高模型准确率,可以调整迭代次数、学习率等参数或者修改CNN网络结构实现。
可视化检验一个批次测试数据的准确性
# 将 test_loader 转换为一个可迭代对象 dataiter
dataiter = iter(test_loader)
# 使用 next(dataiter) 获取 test_loader 中的下一个 batch 的图像数据和标签数据
images, labels = next(dataiter)
# print images
test_img = utils.make_grid(images)
test_img = test_img.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
test_img = test_img*std+0.5
plt.imshow(test_img)
plt.show()
plt.savefig('./mnist_net.png')
print('GroundTruth: ', ' '.join('%d' % labels[j] for j in range(128)))

参考来源:
使用Pytorch框架的CNN网络实现手写数字(MNIST)识别
PyTorch初探MNIST数据集