5. MapReduce 和 Yarn 技术原理【华为HCIA-BigData】
5.1 导读
本章主要讲述大数据领域中最著名的批处理与离线处理计算框架 MapReduce,包括 MapReduce 的原理、流程、使用场景,以及 Hadoop 集群中负责统一的资源管理与调度的组件 Yarn,包括 Yarn 的定义、功能与架构、HA 方案和容错机制,以及利用 Yarn 完成资源调配的常用方法。最后,还简单介绍华为为这些组件所提供的增强特性。
-
MapReduce 适用于数据密集型任务,还是计算密集型任务?
- 数据密集型任务
-
MapReduce 1.x 主要包括哪些角色?主要功能是什么?
-
Client:用户编写的MapReduce程序通过Client提交到JobTracker端
-
JobTracker:负责资源控制和作业调度;负责监控所有TaskTracker与Job的健康状况,一旦出现失败,就把相应的任务转移到其他节点;JobTracker会跟踪任务的执行进度、资源使用量等信息,并把这些信息告诉任务调度器(TaskTracker),而调度器会在资源出现空闲的时候,选择合适的任务去使用这些资源。
-
TaskTracker:会周期地通过“心跳”将本节点上的资源使用情况和任务运行进度汇报给JobTracker,同时接收jobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker使用”slot”(槽)等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个Slot后才有机会运行。而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为MapSlot和ReduceSlot,分别提供给mapTask和reduceTask使用。 -
Task:分为MapTask和ReduceTask两种,均由TaskTracker启动。
-
-
Yarn主要分担了MapReduce 1.x中的哪些功能?
- MRv1中资源管理和作业管理均是由JobTracker实现的,集两个功能于一身,而在MRv2中,将这两部分分开了,其中,作业管理由ApplicationMaster实现,资源管理由新增系统YARN完成
-
Yarn默认包含哪三种三种资源调度器?
-
FIFO调度器
先进先出,但不适合资源公平性 -
容量调度器
独立的专门队列保证小作业也可以提交后就启动,队列容量是专门保留的以整个集群的利用率为代价,与FIFO比,大作业执行的时间要长 -
公平调度器
不需要预留资源,调度器可以在运行的作业之间动态平衡资源,大作业启动时,因为是唯一运行的,所以获得集群的所有资源,之后小作业启动时,被分配到集群的一半的资源,这样每个作业都能公平共享资源。
-
5.2 基本介绍
1. MapReduce 概述
MapReduce基于Google发布的MapReduce论文设计开发,基于分而治之的思想,用于大规模数据集(大于1TB)的并行计算和离线计算,具有如下特点:
- 高度抽象的编程思想:程序员仅需描述做什么,具体怎么做交由系统的执行框架处理。
- 良好的扩展性:可通过添加节点以扩展集群能力。
- 高容错性:通过计算迁移或数据迁移等策略提高集群的可用性与容错性。
MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。
MapReduce是一个并行计算与运行软件框架(Software Framework)。
MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。
2. 资源调度与分配
在 Hadoop1.0 版本中,只有 HDFS 和 MapReduce,而资源调度通过MRv1来进行,存在着很多缺陷:
- master是单点,故障恢复依赖于周期性的checkpoint,不保证可靠性,发生故障的时候会通知用户,由用户自行决定是否重新计算。
- 没有区分作业调度与资源调度。MR在运行时,环境会有大量的 job 并发,因此多样且高效的调度策略是非常重要的。
- 没有提到资源隔离与安全性。大量Job并发的时候,如何保证单个Job不占用过多的资源,如何保证用户的程序对系统而言是安全的,在Hadoop 1.0中是个大问题。
因此,针对Hadoop1.0中MRv1的不足,以及为了满足编程范式多样化的需求,Hadoop2.0中正式引入了Yarn框架,以便更好地完成集群的资源调度与分配。
3. Yarn 概述
Apache Hadoop YARN (Yet Another Resource Negotiator),中文名为“另一种资源协调者”。它是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
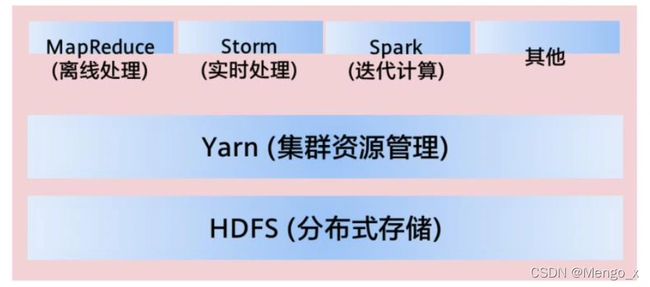
Yarn是轻量级弹性计算平台,除了MapReduce框架,还可以支持其他框架和多种计算模式,比如Spark、 Storm等。
5.3 功能与架构
1. MapReduce 过程
MapReduce 计算过程可具体分为两个阶段,:Map阶段和Reduce阶段。其中 Map 阶段输出的结果就是Reduce阶段的输入。可以把MapReduce理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。
- Map面对的是杂乱无章的互不相关的数据(HDFS文件),它把数据拆为为 split 分片,产生对应的 map 任务,从中提取出key和value(shuffle 洗牌,把数据洗得有规律),也就是提取了数据的特征。一般默认分片大小等于block大小,不过也能用户自定义。
- 到了Reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性。在此基础上我们可以做进一步的处理以便得到结果。
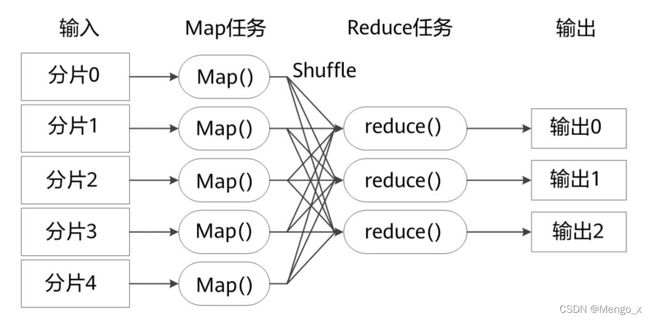
不同的Map任务之间不会进行通信,不同的Reduce任务之间也不会发生任何信息交换,用户不能显式地从一台机器向另一台机器发送消息,所有的数据交换都是通过MapReduce框架自身去实现的。
Map 阶段详解
Job提交前,先将待处理的文件进行分片(Split),MR框架默认将一个块(Block)作为一个分片。客户端应用可以重定义块与分片的映射关系。
Map阶段先把数据放入一个环形内存缓冲区,当缓冲区数据达到80%左右时发生溢写(Spill),需将缓冲区中的数据写入到本地磁盘,这个就是shuffle操作。输出文件作为 Reduce 的输入。
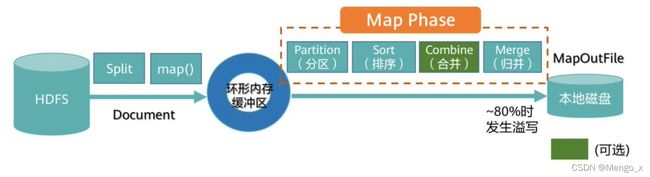
写入本地磁盘之前通常需要做如下处理(shuffle):
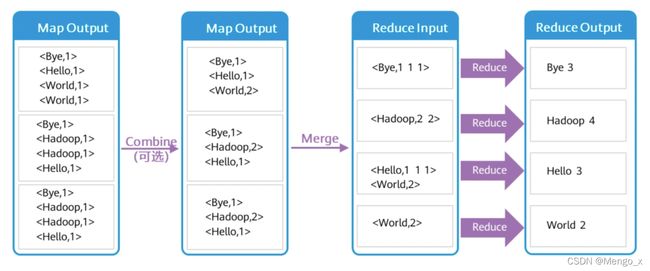
- 分区 (Partition)—默认采用Hash算法进行分区,MR框架根据Reduce Task个数来确定分区个数。具备相同Key值的记录最终被送到相同的Reduce Task来处理。
- 排序 (Sort) —将Map输出的记录排序,例如将(‘Hi’,’1’),(‘Hello’,’1’)重新排序为 (‘Hello’,’1’), (’Hi’,’1’)。
- 组合 (Combine) —这个动作MR框架默认是可选的。例如将 (’Hi’,’1’), (’Hi’,’1’),(‘Hello’,’1’), (Hello’,’1’)进行合并操作为 (’Hi’,’2’), (‘Hello’,’2’)。
- 合并 (Spill) —Map Task在处理后会产生很多的溢出文件(spill file),这时需将多个 溢出文件进行合并处理,生成一个经过分区和排序的Spill File (MOF:MapOutFile)。 为减少写入磁盘的数据量,MR支持对MOF进行压缩后再写入。
合并(Combine)和归并(Merge)的区别:两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到 <“a”,<1,1>>
Reduce 阶段详解
前面的MOF文件是经过排序处理的,将其从磁盘拷贝进对应 Reduce 任务的缓存中。
通常在Map Task任务完成MOF输出进度到3%时启动Reduce,从各个Map Task获取MOF 文件。前面提到Reduce Task个数由客户端决定,Reduce Task个数决定MOF文件分区数。 因此Map Task输出的MOF文件都能找到相对应的Reduce Task来处理。
当Reduce Task接收的数据量不大时,则直接存放在内存缓冲区中,随着缓冲区文件的增多, MR后台线程将它们合并成一个更大的有序文件,写到磁盘中,这个动作是Reduce阶段的Merge操作(shuffle),过程中会产生许多中间文件,然后从磁盘读出来,最后一次合并的结果直接输出到用户自定义的reduce函数。
当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
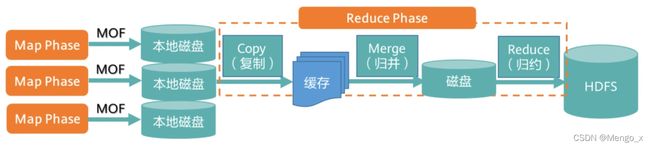
Shuffle 过程详解
Shuffle的定义:Map阶段和Reduce阶段之间传递中间数据的过程,包括ReduceTask从各个Map Task获取MOF文件的过程,以及对MOF的排序与合并处理。

- 每个Map任务分配一个缓存;MapReduce默认100MB缓存;设置溢写比例0.8;排序是默认的操作;排序后可以合并(Combine)。
- 在Map任务全部结束之前进行归并,归并得到一个大的文件,放在本地磁盘。
- 文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner,少于3 不需要。
- JobTracker会一直监测Map任务的执行,并通知Reduce任务来领取数据。
- Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据。
- Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘。
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的。
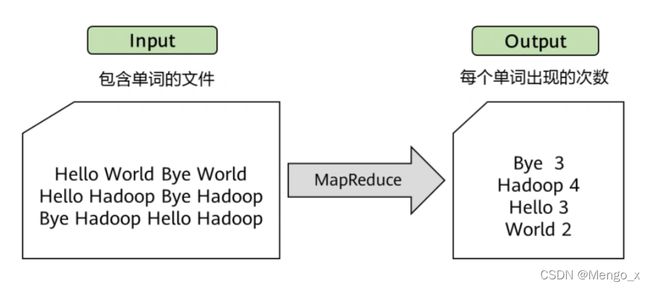
2. 典型应用:WordCount
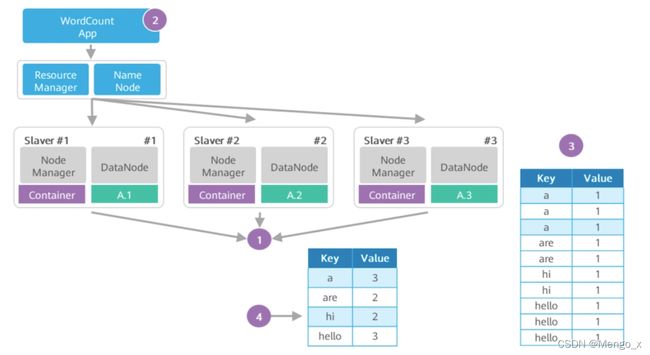
假设要分析一个大文件A里每个英文单词出现的个数,利用MapReduce框架能快速实现这一统计分析。
分析过程如图:
1、待处理的大文件A已经存放在HDFS上,大文件A被切分的数据块split:A.1、A.2、A.3分别 存放在DataNode #1、#2、#3上。
2、WordCount分析处理程序实现了用户自定义的Map函数和Reduce函数。WordCount 将分析应用提交给RM,RM根据请求创建对应的Job,并根据文件块个数按文件块分片,创建 3个 MapTask 和 3个Reduce Task,这些Task运行在Container中(2.0版本中的容器能复用)

3、Map Task 1、2、3的输出是一个经分区与排序的MOF文件。Map 端的输出是键值对,Merge以后 Reduce 端输入是键和值列表。
4、Reduce Task从 Map Task获取MOF文件,经过合并、排序,最后根据用户自定义的 Reduce逻辑,输出如表所示的统计结果。
3. Yarn 组件架构
主要包含三个组件:
- Resource Manager:资源管理调度
- Node Manager:具体执行计算任务
- Application Master:任务监控与调度
在 Hadoop 1.0 中只有 JobTracker 和 TaskTracker,其中 JobTracker 负责资源管理调度、任务监控与调度、任务重启与恢复,任务繁重。
Hadoop 2.0 中 JobTracker 部分任务给了 Resource Manager 和 Application Master,Node Manager 则负责监控任务执行。
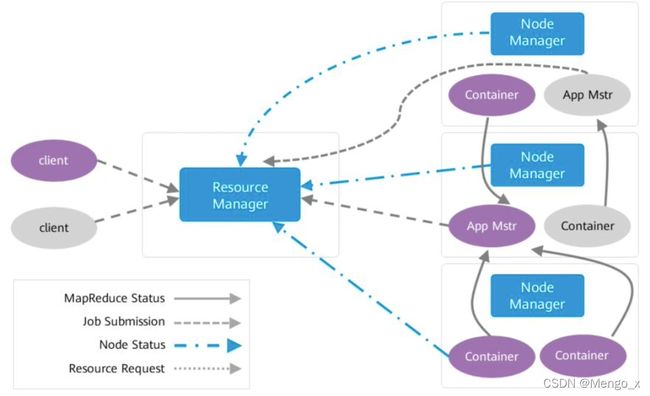
在图中有两个客户端向Yarn提交任务,蓝色表示一个任务流程,棕色表示另一个任务流程。
首先client提交任务,ResourceManager接收到任务,然后启动并监控起来的第一个Container,也就是App Mstr。 App Mstr通知nodemanager管理资源并启动其他container。任务最终是运行在Container当中。
4. MapReduce On Yarn 任务调度流程

- 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
- ResourceManager 为该应用程序分配第一个Container, 并与对应的 NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster 。
- ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过 ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的 运行状态,直到运行结束,即重复步骤4~7。
- ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
- 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
- NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等) 后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
5. Yarn HA 方案(高可用性)
Yarn中的ResourceManager负责整个集群的资源管理和任务调度,Yarn高可用性方案通 过引入冗余的ResourceManager节点的方式,解决了ResourceManager单点故障问题。
与HDFS的高可用性方案类似,任何时间点上都只能有一个ResourceManager 处于Active状态。当Active状态的ResourceManager发生故障时,可通过自动或手动的方式 触发故障转移,进行Active/Standby状态切换。

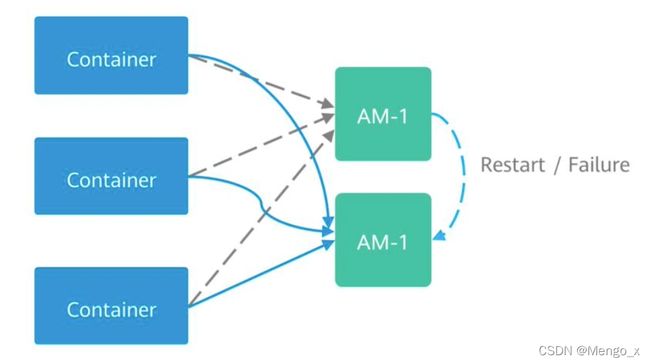
6. Yarn App Master 容错机制
如果AM意外停止运行, ResourceManager 会关闭 ApplicationAttempt 中管理的所有 Container,包括当前任务在 NodeManager 上正在运行的所有Container。RM会在另一计算节点上启动新的 ApplicationAttempt。
YARN支持在新的ApplicationAttempt启动时,保留之前Container的状态,因此运行中的作业可以继续无故障的运行。
5.4 Yarn 资源管理与任务调度
1. 资源管理
每个NodeManager可分配的内存和CPU的数量可以通过配置选项设置(可在Yarn服务配置页面配置)。
yarn.nodemanager.resource.memory-mb表示用于当前NodeManager上可以分配给容器 的物理内存的大小,单位:MB。必须小于NodeManager服务器上的实际内存大小。
yarn.nodemanager.vmem-pmem-ratio表示为容器设置内存限制时虚拟内存跟物理内存的 比值。容器分配值使用物理内存表示的,虚拟内存使用率超过分配值的比例不允许大于当前这个比例。
yarn.nodemanager.resource.cpu-vcore表示可分配给container的CPU核数。建议配置为 CPU核数的1.5-2倍。
在Hadoop3.x版本中,YARN资源模型已被推广为支持用户自定义的可数资源类型 ( support user-defined countable resource types ) ,而不是仅仅支持CPU和内存。
常见的可数资源类型,除了CPU和Memory以外,还包括GPU资源、软件licenses或本地附加存 储器( locally-attached storage )之类的资源,但不包括端口(Ports)和标签(Labels)。
2. 三种资源调度器
在一个很繁忙的集群资源往往是有限的。在Yarn中,负责给应用分配资源的叫做Scheduler (调度器)。根据不同的策略,共有三种调度器可供选择:
- FIFO Scheduler(先进先出调度器):把应用按提交的顺序排成一个队列,这是一个先进先出队列。
- Capacity Scheduler(容量调度器):允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,通过设置多个队列的方式给多个组织提供服务。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了。在一个队列内部,资源的调度是采用的是FIFO策略。
- 容量调度器使得Hadoop应用能够共享的、多用户的、操作简便的运行在集群上,同时最大化集群的吞吐量和利用率。
- 容量调度器以队列为单位划分资源,每个队列都有资源使用的下限和上限。每个用户可以设定资源使用上限。管理员可以约束单个队列、用户或作业的资源使用。支持作业优先级,但不支持资源抢占。
- 在Hadoop 3x中,OrgQueue扩展了容量调度器,通过REST API提供了以编程的方式来改变队列的配置。这样,管理员可以在队列的administerqueue ACL中自动进行队列配置管理。
- Fair Scheduler(公平调度器):为所有的应用动态分配公平的资源(对公平的定义可以通过参数来设置)。有较高资源利用率,也能保证小任务及时完成,应用最多。
4. 容量调度器资源分配模型
-
调度器维护一群队列的信息。用户可以向一个或者多个队列提交应用。
-
每次NM心跳的时候,调度器根据一定的规则选择一个队列,再在队列上选择一个应用,尝试在这个应用上分配资源。
-
调度器会优先匹配本地资源的申请请求,其次是同机架的,最后是任意机器的。

5.5 华为大数据平台Yarn增强特性
1. 动态内存管理
只有当NodeManager中的所有Containers的总内存使用超过了已确定的阈值,那么那些内存使用过多的Containers才会被终止。单个超过还能继续运行。

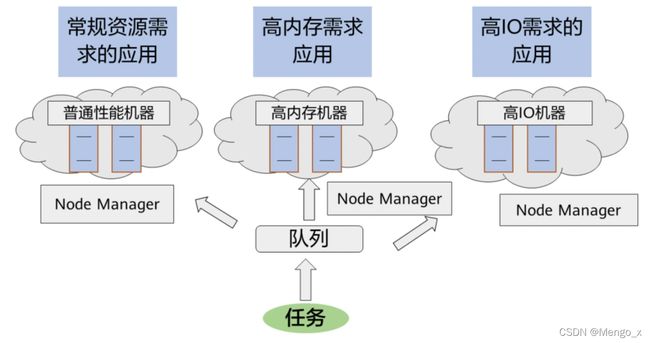
2. 基于标签调度
在没有标签调度之前,任务提交到哪个节点上是无法控制的,会根据一些算法及条件,集群随机分配到某些节点上。
而标签调度可以指定任务提交到哪些节点上。用户可以为每个 nodemanager标注一个标签,比如之前需要消耗高内存的应用提交上来,由于运行在那些节点不可控,任务可能运行在普通性能的机器上。
5.6 课后习题
-
下面哪些是MapReduce的特点? ( ABD )
A.易于编程
B. 良好的扩展性
C. 实时计算
D. 高容错性
-
Yarn中资源抽象用什么表示? ( C )
A.内存
B. CPU
C. Container
D. 磁盘空间
-
下面哪个是MapReduce适合做的? ( B )
A. 迭代计算
B. 离线计算
C. 实时交互计算
D. 流式计算
离线计算以Hadoop的MapReduce为代表、近实时计算以Spark内存计算为代表、在线实时计算以Storm、KafkaStream、SparkStream为代表


