数据结构——树(习题篇)
本文会挑选树中相关例题进行讲解,并复习相关的知识点
建议先将题做一次,再看题解和答案
解二叉树的题目最简单的方法就是画图,即使某些概念忘记了,也可以通过对每个答案通过画图的方式去理解,反推或是排除等
题1
由权值分别为3,8,6,2,5的叶子结点生成一棵哈夫曼树,它的带权路径长度为__________
[分析]
该题给出了5个叶子节点,要求通过5个叶子节点构建哈夫曼树
[方法]
1.对权值节点排序,在n个权值节点中选出两个最小的,这两个节点作为左右子树形成一棵新的二叉树,根节点的值是左右子树权值的加和(左到右数值递增)
2.将原序列中最小的两个权值删除,将新的权值加入到序列中(原最小两个权值的和),并排序
3.不断重复1和2步骤,直至只剩下一棵树结束的表示是序列只剩1个节点值,此树为所构造的哈夫曼树
最后生成的哈夫曼树如下:
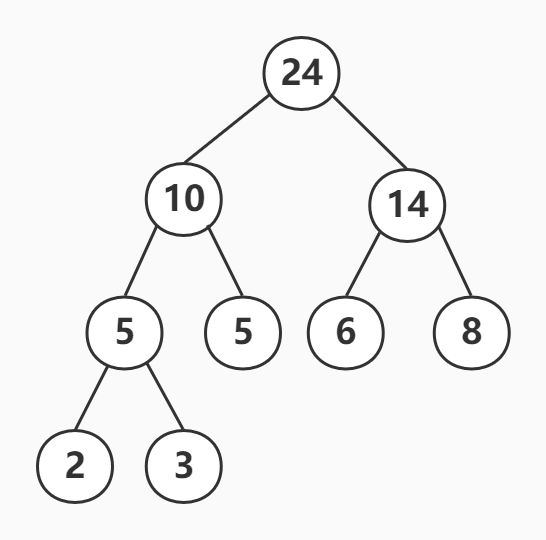
由该哈夫曼树可得,从根到权值5、6、8的距离为2,从根到权值2、3的距离为3,因此带权路径长度为(5+6+8)*2+(2+3)*3=53
[答案]53
题2
一棵完全二叉树上有1001个结点,其中叶子结点的个数是( )。
A. 250 B . 500 C.254 D.501
[分析]
考察的是完全二叉树的性质,利用二叉树根节点和左右子树节点的关系解题
[方法]
由完全二叉树性质可知,若给每个结点依次序标上1~n序号,序号为i的结点,若其有左右节点,左节点为2i(偶),右节点为2i+1(奇),下图为完全二叉树的例子
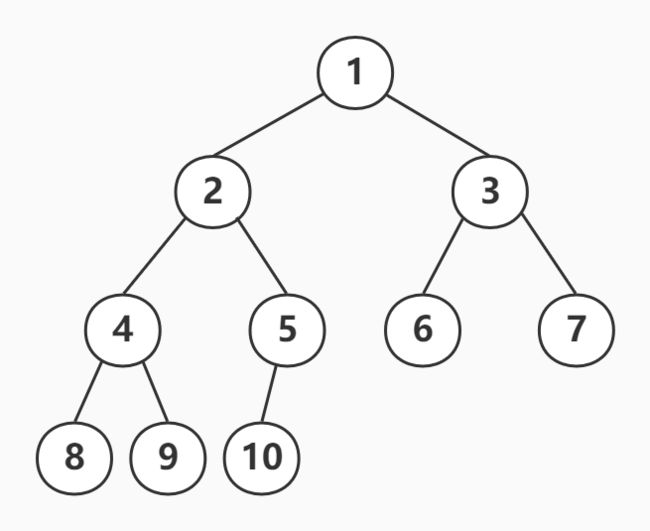
根据上述规律,1001应为节点500的右孩子(2i+1=1001,即i=500)
假设此时节点度为0的个数记为n0,节点度为0的个数记为n1,节点度为2的个数记为n2
由题意可以得到n0+n1+n2=1001,关键要判断此时n1为0还是1,因为此时500号节点的左孩子为1000,右孩子为1001,假设此时501有左右孩子,其序号应为1002和1003,因为本题中只有1001个结点,不存在节点1002和1003,说明此时n1为0,且节点500以后均为叶子节点,即n0=500,n1=0,n2=501
[答案]D
[补充]满二叉树与完全二叉树的区别
完全二叉树指若二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,如上图所示
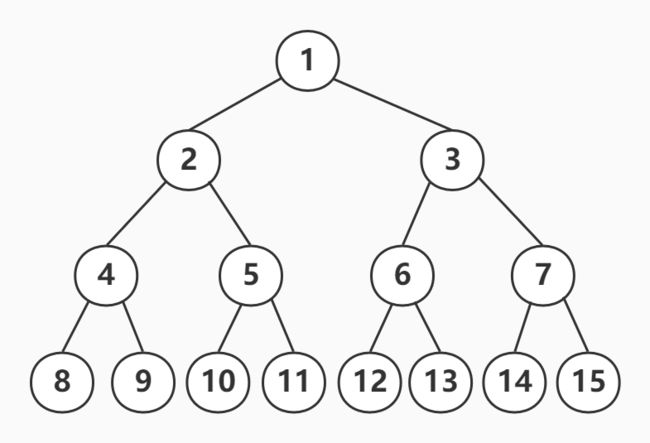
满二叉树指深度为k且有2^k-1个结点的二叉树称为满二叉树,即下图
题3
在森林的二叉树表示中,节点M和节点N是同一父节点的左儿子和右儿子,则在该森林中()
A.M和N有同一双亲 B.M和N可能无公共祖先 C.M是N的儿子 D.M是N的左兄弟
[分析]
考察的是森林转化为二叉树的原则
[方法]
二叉树还原为森林的步骤为:
1.从根节点开始,若右孩子存在,则把与右孩子结点的连线删除。再查看分离后的二叉树,若其根节点的右孩子存在,则继续删除。直到所有这些根结点与右孩子的连线都删除为止
2.将每棵分离后的二叉树转换为树
假设原森林的二叉树表示为:
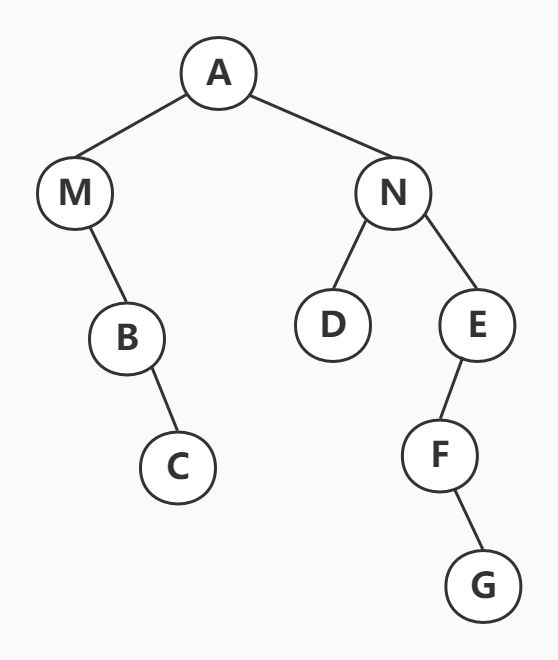
依照二叉树还原为森林的步骤,首先去掉右节点的链接,并转换为树如下图
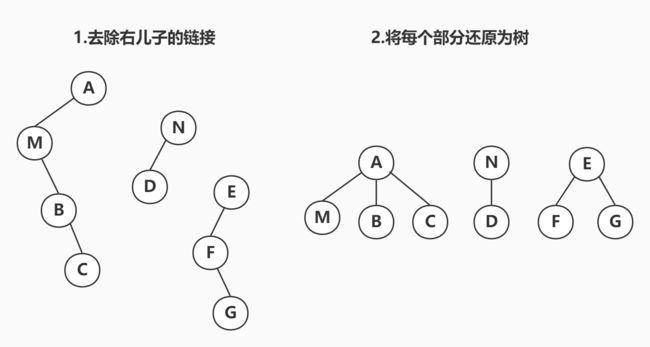
在此情况下,M和N可能无公共祖先
[补充]大家也可以尝试推一下M和N有共同祖先的例子。
[答案]B
题4
要使一棵非空二叉树的先序序列与中序序列相同,其所有非叶结点须满足的条件是()
A.只有左子树 B.只有右子树 C.结点的度均为1 D.结点的度均为2
[分析]
该题考查的是对二叉树前序遍历和中序遍历
[方法]
由二叉树的遍历性质入手,因为二叉树先序遍历是按根-左-右的顺序遍历整颗二叉树,二叉树的中序遍历是按左-根-右遍历整颗二叉树(后序遍历是按左-右-根的顺序遍历整颗二叉树,本题没有提及但要掌握)
因为要使先序序列和中序序列相同
假设只有左子树没有右子树,则先序序列为根-左,而中序序列为左-根,不能保证相同
假设只有右子树没有左子树,则先序序列为根-右,而中序序列为根-右,能保证相同
而结点的度为1或2都不能证明一定使得先序序列和中序序列相同(轻易能举出反例)
[答案]B
[补充]一棵非空的二叉树的先序遍历序列与后序遍历序列正好相反,可以推推有什么结论
题5
由3个节点可以构造出________种形状的二叉树
[分析]
考察的是用如何3个节点形成二叉树的数目,极易漏掉其中一种情况
[方法]
因为本题问的是二叉树的形状,根节点和子节点的排列不是本题的要点,假如以A为根,很容易能想到的是B为A的左子树,C为B的左子树或右子树,或是B为A的右子树,C为B的左子树或右子树,容易忽略的是BC同为A的左右子树
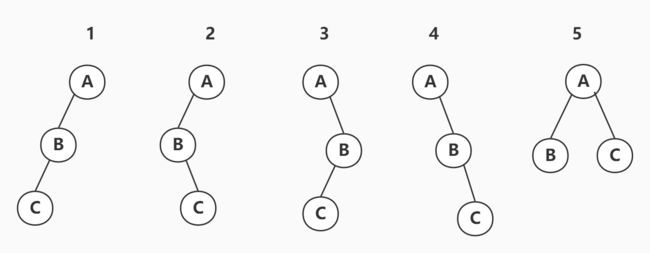
[答案]5
题6
下列关于树的叙述正确的是( )
A.树中可以有环
B.树的度是指所有结点中度最小的结点的度
C.树的深度指的是结点数最多的那一层的深度
D.树的根结点是所有结点的祖先结点
[分析]
考察的是对树的基础概念
[方法]
A.环是指在途中一条由边组成的路径,从一个节点出发,可以回到这个节点自身,树没有该特性,图可能会有
B.树的度为所有节点中最大节点的度
C.树的深度指的是根节点到叶子节点的最大深度
[答案]D
题7
如果二叉树的后序遍历结果是FDEBGCA,中序遍历结果是FDBEACG,那么该二叉树的前序遍历结果是什么?
A.ABCDEFG
B.ABDFEGC
C.ABDFECG
D.ABDEFCG
[分析]
考察的是根据后序遍历和中序遍历得到二叉树,再由先序遍历得到相应的答案
[方法]
根据后序遍历确定根节点的位置,再根据中序遍历按根节点切分为左右子树,如此递归直至遍历结束
根据后序遍历的最后一个节点可以确定A为该树的根节点,再根据中序遍历的结果切分出A的左树(FDBE)及A的右树(CG)
此时根节点为A
对A的左子树:中序遍历为FDBE,后序遍历为FDEB
对A的右子树,中序遍历为CG,后序遍历为GC
对A的左树递归上述过程,根据A的后序遍历为FDEB可以得到B为此时根节点,再根据中序遍历的结果切分出B的左树(FD)及B的右树(E)
此时根节点为B
对B的左子树:中序遍历为FD,后序遍历为FD
对B的右子树,中序遍历为E,后序遍历为E
此时对B的左子树,根据后序遍历FD,可以确定D为B的左子树,根据中序遍历FD,可以确定F为D的左子树
对A的右树递归上述过程,根据中序遍历为CG,后序遍历为GC,可以确定C为A的右子树,且G为C的右子树(中序遍历左-根-右)
综上分析,该二叉树形态如下:
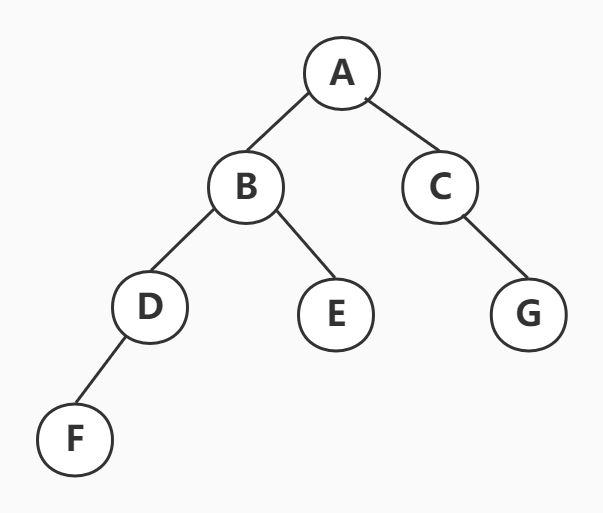
很简单得到先序遍历的序列为:ABDFECG
[答案]C
题8
(判)由二叉树的先序遍历和后序遍历可以唯一确定这棵二叉树()
[分析]
考察的是根据两种遍历方式构造二叉树
[方法]
在前一个专题中我们讲到根据前序遍历和中序遍历能够唯一确定二叉树,根据中序遍历和后续遍历也能唯一确定二叉树。
对前序遍历和中序遍历,方法是先序遍历确定一个子树的根节点,而中序遍历根据根节点将一颗子树再次分为左右子树
对中序遍历和后序遍历,方法是根据后序遍历确定根节点的位置(类似于前序遍历,只是遍历的顺序不一样),再根据中序遍历按根节点切分为左右子树
但对于前序遍历和后序遍历,我们只能获得根节点的信息,无法通过中序遍历的性质用根节点将左右子树分开,因此在某些情况下,不能唯一确定
例子如下:
对先序遍历序列:A B C D ,对后序遍历:B D C A,可能的情况有
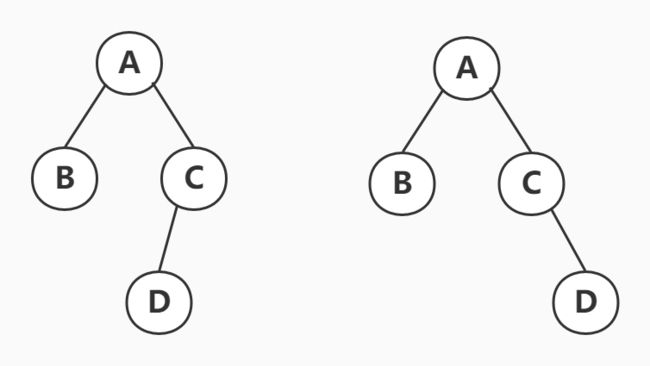
[答案]×
题9
下面的函数PreOrder(TreeNode T)按前序遍历的顺序打印出二叉树T的所有叶子结点。则下列哪条表达式应被填在空中?
void PreOrder( TreeNode* T )
{ if (BT) {
if (___________________) printf(" %d", T->Data);
PreOrder( T->Left );
PreOrder( T->Right );
}
}
A.BT->Data != 0
B.!BT->Right
C.!BT->Left
D.!(BT->Left || BT->Right)
[分析]
本题为填代码题,要求掌握对叶子节点的理解
[方法]
由于本体要求打印出二叉树的所有叶子节点, 一棵树当中没有子结点(即度为0)的结点称为叶子结点,由叶子节点的定义可以得到如果这个节点的左子树是空,且右子树为空,即符合叶子节点的定义,因此可以输出该节点对应的值
[答案]D
[补充]需要掌握树的前序遍历,中序遍历和后序遍历的递归代码实现
先序遍历(根-左-右):
void preorder(TreeNode* t)
{
if(t == NULL) return ;
visit(t); //访问根的值
preorder(t->left); //访问左子树
preorder(t->right); //访问右子树
}
中序遍历(左-根-右):
void inorder(TreeNode* t)
{
if(t == NULL) return ;
inorder(t->left); //访问左子树
visit(t); //访问根的值
inorder(t->right); //访问右子树
}
中序遍历(左-右-根):
void postorder(TreeNode* t)
{
if(t == NULL) return ;
postorder(t->left); //访问左子树
postorder(t->right); //访问右子树
visit(t); //访问根的值
}
题10
假设用于通信的电文仅由8个字母组成,字母在电文中出现的频率分别为0.07、0.19、0.02、0.06、0.32、0.03、0.21和0.10,试为这8个字母设计哈夫曼编码,并对比和等长二进制编码的压缩率
[分析]
考察的是哈夫曼树的构建以及编码,同时要和二进制编码进行对比
[方法]
1.对权值节点排序,在n个权值节点中选出两个最小的,这两个节点作为左右子树形成一棵新的二叉树,根节点的值是左右子树权值的加和(答案不唯一)
2.将原序列中最小的两个权值删除,将新的权值加入到序列中(原最小两个权值的和),并排序
3.不断重复1和2步骤,直至只剩下一棵树**(结束的表示是序列只剩1个节点值)**,此树为所构造的哈夫曼树
按照上述方法可构造出哈夫曼树,如下(本文按左到右递增构造):

按照哈夫曼编码的规则,每个根节点的左子树编码为0 每个根节点的右子树编码为1。
| 编号 | 频率 | 哈夫曼编码 | 等长编码 |
|---|---|---|---|
| 1 | 0.07 | 1010 | 000 |
| 2 | 0.19 | 00 | 001 |
| 3 | 0.02 | 10000 | 010 |
| 4 | 0.06 | 1001 | 011 |
| 5 | 0.32 | 11 | 100 |
| 6 | 0.03 | 10001 | 101 |
| 7 | 0.21 | 01 | 110 |
| 8 | 0.1 | 1011 | 111 |
由哈夫曼编码构成的序列长度为:4 * 7 + 2 * 19 + 5 * 2 + 4 * 6 + 2 * 32 + 5 * 3 + 2 * 21 + 4 * 10 = 261
而由等长编码构成的序列长度为3 * 100 = 300
因此压缩率为261 / 300