MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
Abstract
在本文中,我们介绍了一种高质量多重曝光图像融合(MEF)的新方法。我们表明,曝光的融合权重可以编码到一维查找表(LUT)中,该表将像素强度值作为输入并产生融合权重作为输出。我们为每次曝光学习一个 1D LUT,然后来自不同曝光的所有像素都可以独立查询该曝光的 1D LUT,以实现高质量和高效的融合。具体来说,为了学习这些 1D LUT,我们将帧、通道和空间等各个维度的注意力机制引入到 MEF 任务中,从而使我们的质量比最先进的 (SOTA) 有了显着的提高。此外,我们收集了一个新的 MEF 数据集,其中包含 960 个样本,其中 155 个样本由专业人员手动调整,作为评估的基本事实。我们的网络以无监督的方式由该数据集进行训练。进行了大量的实验来证明所有新提出的组件的有效性,结果表明,我们的方法在我们和另一个代表性数据集 SICE 中无论是定性还是定量都优于 SOTA。此外,我们的 1D LUT 方法在 PCGPU 上运行 4K 图像只需不到 4 毫秒。鉴于其高质量、高效性和稳健性,我们的方法已被应用于全球多个品牌的数百万部 Android 手机中。代码位于:https://github.com/Hedlen/MEFLUT。
1. Introduction
自然场景的动态范围比商业成像产品捕获的动态范围要宽得多,导致大多数数码摄影传感器难以捕获它们。因此,高动态范围 (HDR) [1, 2] 成像技术由于能够克服这些限制而引起了人们的极大兴趣。在 HDR 解决方案中,多重曝光图像融合 (MEF) [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15] 提供了一种经济高效的解决方案,可以生成可信的图像可以生成生动的细节。 MEF 引起了广泛的关注,并且有许多方法 [16、17、18、19、20、21、22、23、24] 可用于融合具有忠实细节和色彩再现的图像。然而,这些 MEF 方法使用手工设计的特征或转换,因此如果应用于修改的条件,它们通常会受到鲁棒性的影响。
受深度神经网络 (DNN) 在许多计算机视觉领域 [25, 26, 27, 28] 成功的启发,最近提出了一些基于深度学习的方法 [5, 7] 来改进 MEF。 DeepFuse [5] 首次使用 DNN 直接回归 YUV 图像的 Y 通道作为目标。由于核心权重图的学习被忽略,由于模型大小有限,尽管其效率可以接受,但其质量仍然受到限制。为了提高质量,MEFNet [7] 或者学习权重图来混合输入序列。然而,随着网络变得复杂,它的速度会降低,因此它仅适用于低分辨率输入,作为保持效率的解决方法。不幸的是,这些方法没有考虑实际部署,它们的速度和质量不能很好地平衡,导致它们难以广泛应用,例如移动平台。为了解决这些问题,我们提出了一种名为 MEFLUT 的方法,旨在利用深度学习技术同时实现更高的质量和效率。我们的方法对运行平台没有严格的要求,可以在PC和移动CPU和GPU上运行。如图所示。如图 1 和图 7 所示,我们的方法在图像细节保留和运行速度方面优于所有其他方法。
MEFLUT 由两部分组成。首先,我们设计了一个基于多维注意力机制的网络,通过无监督方法进行训练。注意力机制分别在帧、通道和空间维度上工作,融合帧间和帧内特征,这为我们带来了细节保留的质量增益。网络收敛后,我们将模型简化为多个 1D LUT,对特定曝光图像中给定输入像素值的融合权重进行编码。在测试阶段,直接从LUT中查询不同曝光对应的融合权重。为了进一步加速我们的方法,对输入进行下采样以获得融合掩模,然后通过上采样引导滤波(GFU)[7]将其上采样到原始分辨率以进行融合,以避免边界分层。我们验证了无论有没有 GFU,我们的方法总是比竞争对手运行得更快,揭示了学习的 LUT 的关键效果。
此外,考虑到现有的 MEF 数据集都不是完全通过移动设备收集的,因此我们构建了一个高质量的多重曝光图像序列数据集。具体来说,我们花了一个多月的时间,通过不同品牌的手机拍摄并筛选出960张涵盖多种场景的多重曝光图像。其中,155个用于定量评估的ground-truth(GT)样本是通过14种算法运行图像预测,经过20名志愿者投票,然后由图像质量(IQ)专家进行微调而产生的。如果不计算组织的工作量,制作这些 GT 样品总共至少需要 40 个工时。
总而言之,我们的主要贡献包括:
• 我们提出MEFLUT 为MEF 任务学习1D LUT。我们证明融合权重可以成功编码到 LUT 中。一旦学会,MEFLUT就可以轻松高效地部署,使得4K图像在PC GPU上的运行时间不到4毫秒。据我们所知,这是第一次展示 LUT 对 MEF 的好处。
• 我们提出了一种新的网络结构,在所有维度上都有两个注意模块,在质量尤其是细节保留方面优于最先进的技术。
• 我们还发布了一个新的数据集,其中包含由不同品牌和不同场景的手机收集的 960 个多重曝光图像序列。其中 155 个样本由专业人员手动生成详细图像作为地面实况目标。
2. Related Works
2.1. Existing MEF Algorithms
MEF 任务通常作为具有不同曝光的多个帧的加权求和来执行。因此,MEF的重点往往是寻找合适的方法来获得不同曝光的权重。默滕斯等人[17]使用每次曝光的对比度、饱和度和曝光度来获得融合权重。与这些传统的MEF方法[29,3,17,30,20,31,22]相比,这些方法侧重于提前获取权重,其他一些方法[5,32,24,8,9,13,14,15]更喜欢将MEF任务转化为优化问题。马等人[23]提出了一种基于梯度的方法来最小化 MEF-SSIM,以在图像空间中搜索更好的融合结果。然而,该方法需要在每个融合中进行搜索,导致其非常耗时。近年来,一些深度学习方法也尝试通过MEF-SSIM来优化模型。例如,DeepFuse[5]通过神经网络完成MEF任务,在保持融合质量的同时实现比传统方法更快的计算。最近,张等人[8]提出了一种通用图像融合框架IFCNN,它基于DNN,通过网络直接重建融合结果。曲等人[14]提出了TransMEF,它使用Transformer来进一步提高MEF的质量。然而,这些方法没有考虑速度,也不是为移动设备设计的。
2.2. Acceleration of MEF Algorithms
考虑到移动平台中的潜在部署,上述大多数方法都是耗时的,因为移动设备的计算能力相对有限。一种解决方案是基于云的解决方案,但对于高分辨率图像,图像传输也很耗时。另一种解决方案是在图像的下采样版本中进行计算,例如[33,34,35,36,37,7]。 MEFNet[7]使用引导滤波器[38]实现上采样,可以很好地保留高频和边缘信息。然而,即使对于小分辨率图像,这种方法也过于复杂且耗时。因此,我们提出了一种基于LUT的新MEF方法,以实现高效、高质量的融合。
移动设备上的MEF任务面临的另一个问题是缺乏因果相机捕获的数据集,尽管存在专业相机拍摄的公共数据集,例如SICE [39]和HDREYE [40],这意味着图像是高质量的。由于泛化问题,这些数据集训练的模型可能很难应用于移动设备。因此,我们提出了一个全面的数据集来扩大应用范围。
2.3. LUT
LUT已广泛应用于视觉任务,包括图像增强[41, 42]、超分辨率[43, 44]等。 [41, 42]提出了用于高效单图像增强的图像自适应3D LUT,它们都需要网络权重预测器来融合不同的3D LUT,这对于一些需要深度学习框架支持的平台来说将受到限制。 [43]训练具有受限感受野的深度超分辨率(SR)网络,然后将学习到的SR网络的输出值缓存到LUT。与[41, 42]相比,MEFLUT和SR-LUT[43]是离线LUT。此外,MEFLUT在生成LUT和训练策略的形式上也与SR-LUT[43]有本质的不同。
3. Algorithm

3.1. Network Structure


3.1.1 Convolution with frame and channel attention

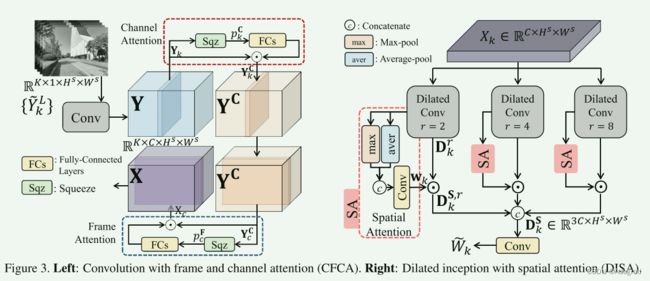

3.1.2 Dilated inception with spatial attention


我们进行了一项消融研究,以证明两个注意力模块的有效性,其中启用任一模块后,所有指标都会变得更高。
3.1.3 Unsupervised learning of the MEFLUT


3.2. LUT Generation


4. Data Preparation
考虑到现有的来自手机的多重曝光图像序列数据集很少,并且[47,39,40]中提供的图像序列在数量和多样性上都非常有限,我们创建了一个包含更多数量的多重曝光图像的新数据集序列并涵盖手机拍摄的更多样场景。
Data collection.
我们主要在静态场景下使用6种不同的常用品牌手机收集数据。确保场景的多样性和代表性,涵盖广泛的场景、主题和照明条件。更重要的是,收集到的图像涵盖了我们日常生活中的大部分曝光水平。对于每个序列,我们使用三脚架来确保帧对齐良好。曝光级别是手动设置的,我们的样本序列设置的曝光值 (EV) 范围从 -4.0 到 +2.0,以 0.5 为步长。我们根据不同品牌手机的特点,为每个场景选择曝光数6(K=6)。收集源序列后,进一步进行筛选以选择用于GT生成的所需序列。结果,总共 960 个静态但不同的序列被过滤掉。
GT generation.
我们进一步使用混合方法来生成 GT。具体来说,首先使用 14 种现有算法 [17, 48, 49, 30, 20, 50, 21, 22, 24, 51, 52, 53, 54, 7] 来预测每个序列的结果。然后我们邀请了 20 名志愿者来比较 14 种算法的结果,并投票选出一张图像作为每个序列的 GT。我们还邀请了图像质量调优工程师进一步手动调整色调映射算子以获得公平投票的结果,以生成高质量的 GT。每张图像的平均调优时间为10分钟,每位志愿者整个投票过程花费了60多分钟。由于工作量巨大,我们在155个测试集样本上调优并获得高质量的GT,只是为了通过无监督学习来评估结果,总共花费了2450/60 = 40.8工时。
5. Experimental Results
Limitation.
虽然我们的方法可以在各种场景中实现稳定高效的 MEF,但它有 1D LUT 的两个限制。首先,我们的 1D LUT 目前仅在 Y 通道上运行,这对于色彩平衡来说可能不够好。一种可能的解决方案是在 UV 通道上也使用 1D LUT,但兼容性需要进一步研究。其次,我们逐像素查询一维表,导致重建的权重图可能缺乏平滑度,并且由于未考虑邻域信息,可能会出现点伪影。尽管GFU在权重图上具有平滑能力,但其参数无法自适应设置,导致其对各个场景的效果不均匀,有的过于点化,有的过于平滑,导致佛光伪影。两种可能的解决方案包括学习一个为 1D LUT 提供更多语义信息指导的小模型,以及学习具有自适应参数的 GFU。
Discussion.
网络的拟合能力越强,生成的LUT的表现力就越大。 Transformer 等高级模块和更大的模型可以增强网络的性能,从而产生卓越的 1D LUT。此外,我们的方法通过离线生成 1D LUT 来加速 MEF。它可以扩展到多焦点图像融合和图像增强等任务。 1D LUT 的相同离线生成方法也可用于生成 2D/3D LUT,从而能够适应更广泛的任务。例如,在两帧 MEF 任务中,我们使用 256×256 组恒定灰度图像(灰度值范围从 0 到 255)来训练网络。我们成功地构建了离线生成的 2D LUT,表现出了良好的性能。然而,值得注意的是,随着 LUT 维数的增加,存储空间需求呈指数级增长。我们计划在未来的研究中进一步探索这些可能性。
6. Conclusion
我们提出了一种新方法来有效地融合多重曝光图像序列以产生视觉上令人愉悦的结果。我们为每次曝光学习一个 1D LUT,然后来自不同曝光的所有像素都可以独立查询该曝光的 1D LUT,以实现高质量和高效的融合。具体来说,为了学习这些 1D LUT,我们将帧、通道和空间注意机制纳入 MEF 任务中,以实现卓越的性能。我们还发布了一个新的数据集,由从不同品牌的手机和不同场景中收集的 960 个多重曝光图像序列组成。我们进行了全面的实验来证明 MEFLUT 的有效性。致谢这项工作得到了四川省科技计划项目的支持,资助号为2023NSFSC0462。