【python】力扣题
剑指 Offer 09. 用两个栈实现队列
一、解题思路
1、【队列是先入先出,栈是后入先出】
stackA: 入队栈,入队操作,直接压入入队栈即可
stackB: 出队栈,出队操作需要优先检查出队栈是否有数据,若无,需要从入队栈倒入后再操作。
2、(1)加入队尾 appendTail()函数: 将数字 val 加入栈 A 即可。
(2)删除队首deleteHead()函数: 有以下三种情况。
- 当栈 B 不为空: B中仍有已完成倒序的元素,因此直接返回 B 的栈顶元素。
- 否则(栈 B 为空),当 A 为空: 即两个栈都为空,无元素,因此返回 −1 。
- 否则(栈 B 为空,栈 A不 为空): 将栈 A 元素全部转移至栈 B 中,实现元素倒序,并返回栈 B 的栈顶元素。
二、代码
class CQueue:
def __init__(self):
self.stackA = []
self.stackB = []
def appendTail(self, value: int) -> None:
self.stackA.append(value)
def deleteHead(self) -> int:
if self.stackB:
return self.stackB.pop()
if not self.stackA:
return -1
while self.stackA: ##将栈 A(不为空) 元素全部转移至栈 B 中,实现元素倒序,并返回栈 B 的栈顶元素。
self.stackB.append(self.stackA.pop())
return self.stackB.pop()剑指 Offer 10- I. 斐波那契数列
一、解题思路
1、解法一:可以使用动态规划,将每次前两数之和存起来,便于下次直接使用,这样子,我们就把一个栈溢出的问题,变为了单纯的数学加法,大大减少了内存的压力。
动态规划(dp)的思想:
1、最优子结构(递归式)
2、重复子问题

2、解法二:(记忆化递归法)
原理:在递归法的基础上,新建一个长度为n的数组,用于在递归时存储f(0)至f(n)的数字值,重复遇到某数字则直接从数组取用,避免了重复的递归计算。
缺点:记忆化存储需要使用0(N)的额外空间。
3、解法三:普通递归
由于子问题的重复计算,f(0)至f(n)的数字在重复计算,所以速度很慢。
二、代码
## 解法一:动态规划
class Solution:
def fib(self, n: int) -> int:
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a % 1000000007## 解法二:记忆化递归法
class Solution:
def fib(self, n):
a=[0,1,1]
if n<3:
return a[n]
for i in range(3,n+1):
a.append(a[i-1]+a[i-2])
return a[n]% 1000000007## 解法三:普通递归
class Solution:
def fib(self, n: int) -> int:
if n == 0 or n == 1:
return 1
else:
return fib(n-1)+fib(n-2)剑指 Offer 10- II. 青蛙跳台阶问题
一、解题思路
二、代码
## 解法一:
class Solution:
def numWays(self, n: int) -> int:
a,b = 1,1
for _ in range(n):
a,b = b,a+b
return a%1000000007## 解法二:
class Solution:
def numWays(self, n: int) -> int:
a = [1,1,2]
if n < 3:
return a[n]
for i in range(3,n+1):
a.append(a[i-1]+a[i-2])
return a[n]%1000000007剑指 Offer 11. 旋转数组的最小数字
一、解题思路
1、解法一:
这种方法暴力,因为不论怎么旋转,都是求整个数组中的最小值。
2、解法二:差值法
因为不论怎么旋转,肯定会变成两组半有序的序列,所以可以用一个列表存放相邻两个数的差值。对差值进行循环,当差值小于0的时候,就是旋转的点,结束循环。特殊情况:当旋转数组为[1,2,3,4,5]时,差值均大于0,所以第一个值就是最小数字。
3、解法三:二分法(分治思想)
【排序数组的查找问题首先考虑使用 二分法 解决,其可将 遍历法 的 线性级别 时间复杂度降低至 对数级别 。】
⚠️区间分为[i,m]和[m+1,j];左指针i和右指针j时用来移动的操作指针;
指针m是用来定位的。

第三种情况的分析:因为数组中可以有重复元素,所以mid处的值和right处的值可能会一样。这种情况下,mid和right所指的数都有可能是最小值,既然两个都可能是最小值,只要保留一个在查找区间内就可以了,把mid保留,令j= j - 1
参考【剑指 Offer 10- I. 斐波那契数列】
二、代码
## 解法一:
class Solution:
def minArray(self, numbers: List[int]) -> int:
return min(numbers)## 解法二:差值法
class Solution:
def minArray(self, numbers: List[int]) -> int:
diff_res = [numbers[i]-numbers[i-1] for i in range(len(numbers))]
for index,value in enumerate(diff_res):
if value < 0:
return numbers[index]
break
return numbers[0]## 解法三:二分法
class Solution:
def minArray(self, numbers: List[int]) -> int:
i,j = 0,len(numbers)-1
while i <= j:
m = (i + j) //2 ## 整除
if numbers[m] < numbers[j]: ## m在右排序数组,旋转点在[i,m]区间
j = m # j指针向左移动
elif numbers[m] > numbers[j]: ## m在左排序数组,旋转点在[m+1,j]区间
i = m+1 # i指针向右移动
else:
j = j-1
return numbers[i]剑指 Offer 03. 数组中重复的数字
一、解题思路
1、解法一:差值法
将数组中数据进行排序,然后用差值法找到相邻差值为0的,就是重复数字。
参考【剑指 Offer 11. 旋转数组的最小数字】的解法二,只不过不用进行特殊情况的判断了。
2、解法二:哈希法
新建一个空的集合unique_nums或者一个空的字典dic,遍历nums数组,判断该数是否存在于unique_nums中,若不存在,则添加进unique_nums中;若存在,则是重复数字,可以返回。
⚠️集合只存key,字典可以存key和value
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
3、解法三:原地置换
如果没有重复数字,那么正常排序后,数字i应该在下标为i的位置,所以思路是重头扫描数组,遇到下标为i的数字如果不是i的话,(假设为m),那么我们就拿与下标m的数字交换。在交换过程中,如果有重复的数字发生,那么终止返回ture。
复杂度分析
时间复杂度:O(n)
空间复杂度:O(1)
二、代码
## 解法一:差值法
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
numbers = sorted(nums) ## 排序
diff_res = [numbers[i]-numbers[i-1] for i in range(len(numbers))]
for index,value in enumerate(diff_res):
if value == 0:
return numbers[index]
break## 解法二:集合
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
unique_nums = set()
for n in nums:
if n not in unique_nums:
unique_nums.add(n) # set是add方法
else:
return n## 解法二:字典
Class Solution:
def findPepeatNumber(self,nums:List[int]) -> int:
dic = {}
for num in nums:
if nums in dic:
return num
dic[num] = 1 # 如果不在字典里,就将num存进key,并将value记为1## 解法三:原地置换
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
for i in range(len(nums)): ## i代表坑,nums[i]代表萝卜,正常排序下有:nums[i] == i,也就是一个萝卜一个坑
while nums[i]!= i: #发现nums[i]这个萝卜不是第i个坑里的
temp = nums[i] #假设nums[i]这个萝卜是temp坑里的萝卜
if nums[temp] == temp: # 查看temp坑:如果temp坑里的萝卜也是temp坑里的,则temp坑对应两个萝卜
return nums[temp] # 应该上交一个萝卜
else: #如果temp坑里的萝卜不是temp坑里的,则将nums[i]这个萝卜和nums[temp]这个萝卜交换,继续判断nums[i]代表萝卜是不是第i个坑里的
nums[temp] = nums[i]
nums[i] = nums[temp]剑指 Offer 04. 二维数组中的查找
一、解题思路
1、解法一:暴力循环,循环每一行,判断target是否存在
2、解法二:线性查找:从二维数组的右上角开始查找。如果当前元素等于目标值,则返回 true。如果当前元素大于目标值,则移到左边一列。如果当前元素小于目标值,则移到下边一行。
复杂度分析
时间复杂度:O(m+n)
空间复杂度:O(1)
二、代码
# 解法一:暴力循环
class Solution:
def findNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool:
for line in matrix:
if target in line:
return True
return False# 解法二:线性查找
class Solution:
def findNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool:
if not matrix: # 排除空矩阵
return False
m, n = len(matrix), len(matrix[0]) # m为行数,n为列数
row, col = 0, n - 1 # 从右上角开始(向下走或者向左走)
while row < m and col >= 0:
if matrix[row][col] == target:
return True
if matrix[row][col] < target:# 向下走
row += 1
else: # 向左走
col -= 1
return False #如果没找到target,则返回False(默认返回null)剑指 Offer 05. 替换空格
一、解题思路
1、解法一:
直接用字符串的replace方法,将空格替换成“%20”,但是没有用到算法思想。
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
2、解法二:字符串直接相加
因为Python和Java的字符串都是不可变的,因此这种方法的复杂度其实很高,可以和思路三对比
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n^2)
3、解法三:遍历添加
在 Python 和 Java 等语言中,字符串都被设计成「不可变」的类型,即无法直接修改字符串的某一位字符,需要新建一个字符串实现。
算法流程:
(1)初始化一个 list (Python) / StringBuilder (Java) ,记为 res ;
遍历列表 s 中的每个字符 c :
(2)当 c 为空格时:向 res 后添加字符串 “%20” ;
(3)当 c 不为空格时:向 res 后添加字符 c ;
(4)将列表 res 转化为字符串并返回。
复杂度分析:
时间复杂度 O(N) : 遍历使用 O(N) ,每轮添加(修改)字符操作使用O(1) ;
空间复杂度 O(N) : Python 新建的 list 和 Java 新建的 StringBuilder 都使用了线性大小的额外空间。
二、代码
# 解法一:replace方法
class Solution:
def replaceSpace(self, s: str) -> str:
return s.replace(' ','%20')# 解法二:字符串存储
class Solution:
def replaceSpace(self, s: str) -> str:
res = ''
for i in s:
if i==' ':
res += '%20'
else:
res += i
return res
# 解法三:list存储
class Solution:
def replaceSpace(self, s: str) -> str:
res = []
for i in s:
if i==' ':
res.append('%20')
else:
res.append(i)
return ''.join(res) #将列表转为字符串剑指 Offer 06. 从尾到头打印链表
一、解题思路
链表的定义
class ListNode:
def __init__(self, x):
self.val = x
self.next = None # 定义指针1、解法一:翻转数组
(1)遍历链表,将节点值存进数组中
(2)翻转数组并返回
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
2、解法二:辅助栈法(栈用列表(可看作一维数组)来存链,然后倒序
解题思路:
链表特点: 只能从前至后访问每个节点。
题目要求: 倒序输出节点值。
这种 先入后出 的需求可以借助 栈 来实现。
算法流程:
(1)入栈: 遍历链表,将各节点值 push 入栈。(Python 使用 append() 方法,Java借助 LinkedList 的addLast()方法)。
(2)出栈: 将各节点值 pop 出栈,存储于数组并返回。(Python 直接返回 stack 的倒序列表,Java 新建一个数组,通过 popLast() 方法将各元素存入数组,实现倒序输出)。
*复杂度分析:
时间复杂度 O(N): 入栈和出栈共使用 O(N) 时间。
空间复杂度 O(N): 辅助栈 stack 和数组 res 共使用 O(N) 的额外空间。
3、解法三:递归法
思路:先向后遍历链表,到最后一个,在逐层回溯
定义递归结束条件,head为空是返回上一层,将上一层节点val加入到list中
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
二、代码
# 解法一:翻转数组
class Solution:
def reversePrint(self, head: ListNode) -> List[int]:
res = []
while head:
res.append(head.val)
# res = [head.val] + res
res = head.next
return res[::-1]# 倒序
# return reverse(res)# 解法二:辅助栈
class Solution:
def reversePrint(self, head: ListNode) -> List[int]:
stack = []
while head:
stack.append(head.val)
head = head.next
res = []
while stack:
res.append(stack.pop())
return res## 解法三:递归
class Solution(object):
def reversePrint(self, head):
if head is None: # head为空时KM
return []
return self.reversePrint(head.next) + [head.val]剑指 Offer 07. 重建二叉树
一、解题思路:
树节点的定义
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None前序遍历列表: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。
(第一个元素永远是 【根节点 (root)】)
中序遍历列表: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。
(根节点 (root)【左边】的所有元素都在根节点的【左分支】,【右边】的所有元素都在根节点的【右分支】)
1、解法一:递归法
递归法的提升:在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。
对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。dic[key]=value
在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。在此后构造二叉树的过程中,我们就只需要O(1) 的时间对根节点进行定位了。
⚠️递推参数: 子树在前序遍历里左边界的索引pre_left 、子树在前序遍历里右边界的索引pre_right、子树在中序遍历里左边界的索引 in_left 、子树在中序遍历里右边界的索引in_right
复杂度分析
时间复杂度:O(n),其中 n 是树中的节点个数。
空间复杂度:O(n),除去返回的答案需要的 O(n) 空间之外,我们还需要使用 O(n) 的空间存储哈希映射,以及 O(h)(其中 h 是树的高度)的空间表示递归时栈空间。这里 h
2、解法二:迭代法
二、代码
# 解法一:递归法
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
if preorder == []:#或者if not preorder:
return None
root = TreeNode(preorder[0])#利用先序遍历找到根节点
loc = inorder.index(preorder[0])# 在中序遍历序列中找到根节点的位置loc,以此划分左子树和右子树
root.left = self.buildTree(preorder[1:loc+1] , inorder[:loc])#注意这里的右边界要比实际下标+1
root.right = self.buildTree(preorder[loc+1:] , inorder[loc+1:])
return root# 解法一:递归法的提升
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
##递推参数:子树在前序遍历里左边界的索引pre_left 、子树在前序遍历里右边界的索引pre_right、子树在中序遍历里左边界的索引 in_left 、子树在中序遍历里右边界的索引in_right
def recur(pre_left,pre_right,in_left,in_right):
if pre_left > pre_right:# 递归终止条件
return None
# 前序遍历中的第一个节点就是根节点:
pre_root = pre_left
# 先建立根节点
root = TreeNode(preorder[pre_root]) #根节点值为preorder[pre_root]== preorder[pre_left]
in_root = dic[preorder[pre_left]] ##在中序遍历中定位根节点的索引
# 左子树的节点数目
size_left = in_root-in_left
# 递归地构造左子树:参数为左子树在前序和中序里地边界位置索引
root.left = recur(pre_root+1,pre_root+size_left,in_left,in_root-1)
# 递归地构造右子树:参数为右子树在前序和中序里地边界位置索引
root.right = recur(pre_root+size_left+1,pre_right,in_root+1,in_right)
return root
n = len(inorder)
# 构造哈希映射,帮助我们快速定位根节点
dic = {}
for i in range(n): # 对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射
dic[inorder[i]]=i. # dic[key]=value
return recur(0, n - 1, 0, n - 1)剑指 Offer 24. 反转链表
一、解题思路
1、解法一:递归【内部再定义一个函数】
考虑使用递归法遍历链表,当越过尾节点后终止递归,在回溯时修改各节点的 next 引用指向。
recur(cur, pre) 递归函数:
终止条件:当 cur 为空,则返回尾节点 pre (即反转链表的头节点);
递归后继节点,记录返回值(即反转链表的头节点)为 tmp ;
修改当前节点 cur 引用指向前驱节点 pre ;
返回反转链表的头节点 tmp ;
reverseList(head) 函数:
调用并返回 recur(head, None) 。传入 None 是因为反转链表后, head 节点指向 null ;

解法一:递归【直接调用自身】
递归上来就先写终止条件:如果head为空或者head.next为空,返回head
新头结点newHead指向尾结点,此处进入递归,递归一直到遍历到尾结点时才会返回
每一层递归,该层递归中的head会让下一个节点指向自己,head.next.next = head;然后head自己指向空。以此达到反转的目的。
返回新链表的头结点newHead
复杂度分析:
时间复杂度 O(N) : 遍历链表使用线性大小时间。
空间复杂度 O(N) : 遍历链表的递归深度达到 N ,系统使用 O(N) 大小额外空间。
2、解法二:迭代(双指针)
指针的初始化:pre指向空节点,cur指向头结点head
tmp指向head.next (因为head.next可能不存在,tmp在循环中定义,这样如果head为空就不会进入循环)
迭代过程:
tmp指向cur.next 【在断开链之前,暂存后继节点】
cur指向pre 【断开现在的链,重新指向】
pre移动到cur位置【作为cur下一步的前继节点】
cur移动到tmp位置 【cur 访问下一节点】
当cur为空时,返回pre 【此时cur指向null,返回cur的前继节点pre】
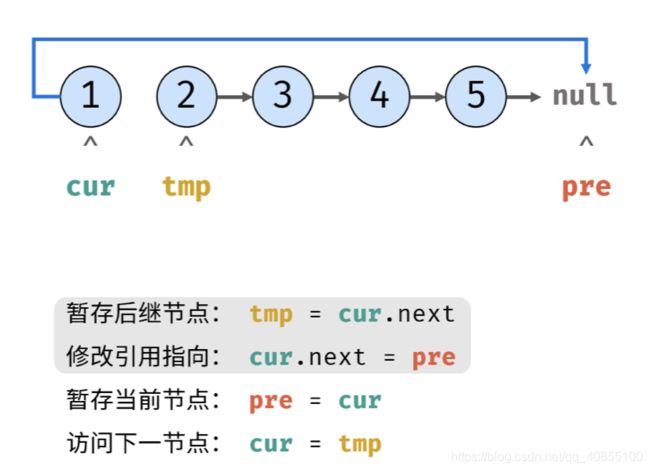

复杂度分析:
时间复杂度 O(N) : 遍历链表使用线性大小时间。
空间复杂度 O(1) : 变量 pre 和 cur 使用常数大小额外空间。
二、代码
# 解法一:递归
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
def recur(cur,pre):
if not cur:# 终止条件
return pre
tmp = recur(cur.next,cur) # 递归的后继节点
cur.next = pre # 修改节点引用指向
return tmp # 返回反转链表的头节点
return recur(head,None)
```python
# 递归【直接调用自身】
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
if not head or not head.next:
return head
newHead = self.reverseList(head.next)
head.next.next = head
head.next = None
return newHead# 解法二:迭代(双指针)
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
pre = None # pre指向空节点
cur = head # cur指向头结点head
while cur: # 如果head为空就不会进入循环
tmp = cur.next # 在断开链之前,暂存后继节点
cur.next = pre # 断开现在的链,重新指向
pre = cur # pre 暂存 cur,作为cur下一步的前继节点
cur = tmp # cur 访问下一节点
return pre # 此时cur指向null,返回cur的前继节点pre剑指 Offer 25. 合并两个排序的链表
一、解题思路
1、解法一:伪头节点(迭代)
解题思路:
根据题目描述, 链表 l1,l2 是 递增 的,因此容易想到使用双指针 l1 和 l2 遍历两链表,根据 l1 .val 和 l2.val 的大小关系确定节点添加顺序,两节点指针交替前进,直至遍历完毕。
引入伪头节点: 由于初始状态合并链表中无节点,因此循环第一轮时无法将节点添加到合并链表中。解决方案:初始化一个辅助节点(哑节点) dum 作为合并链表的伪头节点,将各节点添加至 dum 之后。
算法流程:
(1)初始化: 伪头节点 dum ,节点 cur 指向 dum 。
(2)循环合并: 当 l1 或 l2 为空时跳出;
当 l1.val
(3)节点 cur 向前走一步,即 cur=cur.next 。
(4)合并剩余尾部: 跳出时有两种情况,即 l1 为空 或 l2 为空。
若 l1 !=null :即l2为空时 ,将 l1 添加至节点 cur 之后;
否则: 将 l2 添加至节点 cur 之后。
(5)返回值: 合并链表在伪头节点 dum 之后,因此返回 dum.next 即可。
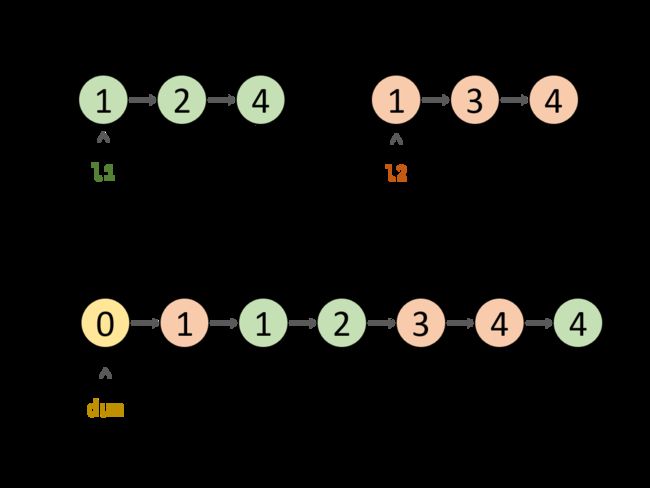
复杂度分析:
时间复杂度 O(M+N) :
M,N 分别为链表 l1,l2 的长度,合并操作需遍历两链表。
空间复杂度 O(1) : 节点引用 dum , cur 使用常数大小的额外空间。
2、解法二:递归
函数功能:
- 返回 l1 指向的结点和 l2 指向的结点中,值较小的结点
- 并将从下级函数获得的返回值,链接到当前结点尾部
算法流程:
(1)特判:如果有一个链表为空,返回另一个链表
(2)如果l1节点值比l2小,下一个节点应该是l1,应该return l1,在return之前,指定l1的下一个节点应该是【l1.next和l2俩链表的合并后的头结点】;
(3)如果l1节点值比l2大,下一个节点应该是l2,应该return l2,在return之前,指定l2的下一个节点应该是【l1和l2.next俩链表的合并后的头结点】。
复杂度分析
时间复杂度:O(m+n)
空间复杂度:O(m+n)
二、代码
#解法一:伪头节点
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
cur = dum = ListNode(0)# 初始化: 伪头节点 dum ,节点 cur 指向dum 。
while l1 and l2:
if l1.val < l2.val:
cur.next = l1
l1 = l1.next
else:
cur.next = l2
l2 = l2.next
cur = cur.next # 以上两种情况下都要运行这一步
## 合并剩余尾部(不在循环中)
#cur.next = l1 if l1 else l2
#Python 三元表达式写法 A if x else B ,代表当 x=True 时执行 A ,否则执行 B 。
if l1:
cur.next = l1
else:
cur.next = l2
return dum.next# 解法二:递归
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if not l1: # l1为空,not l1就是True
return l2
if not l2: # l2为空,not l2就是True
return l1
if l1.val < l2.val: # 只剩第三种情况l1,l2不为空
l1.next = self.mergeTwoLists(l1.next,l2)
return l1
l2.next = self.mergeTwoLists(l1,l2.next)
return l2
#其实以上为if...elif...elif...else的关系剑指 Offer 27. 二叉树的镜像
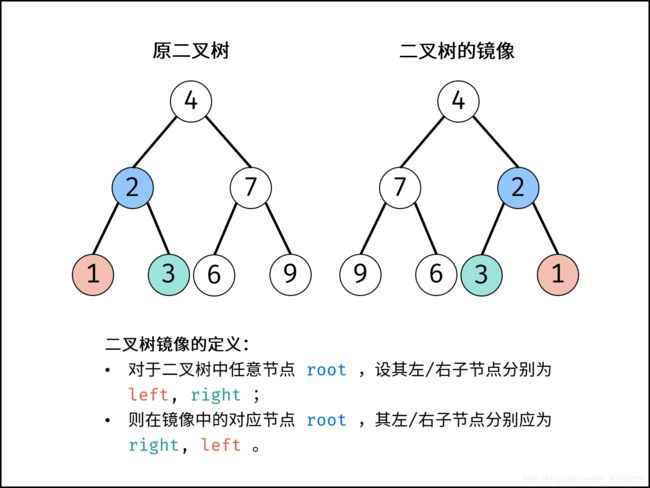
一、解题思路
1、解法一:递归法
思路:交换每个节点的左 / 右子树,然后左右子树的子树用递归的方式进行调换。
难点:递归法比较不容易想明白的就是递归结束(返回值 return)的条件,那么仔细思考一下本题就两种条件,第一种,以当前节点为根的树为空那么没法调换返回空;第二种,当前节点的左右子树全部交换完了那么就返回以当前节点为根的树,以供上层调用。
递归解析:
(1)终止条件: 当节点 root 为空时(即越过叶节点),则返回 None ;
递推工作:
(2)初始化节点 tmp ,用于暂存 root 的左子节点;(防止在递归右子节点执行完毕后, root.left 的值已经发生改变,此时递归左子节点 mirrorTree(root.left) 则会出问题。)
(3)开启递归 右子节点 mirrorTree(root.right) ,并将返回值作为 root 的 左子节点 。
(4)开启递归 左子节点 mirrorTree(tmp) ,并将返回值作为 root 的 右子节点。
(5)返回值: 返回当前节点 root ;
复杂度分析:
时间复杂度 O(N) : 其中 N 为二叉树的节点数量,建立二叉树镜像需要遍历树的所有节点,占用 O(N) 时间。
空间复杂度 O(N) : 最差情况下(当二叉树退化为链表),递归时系统需使用 O(N) 大小的栈空间。
2、解法二:方法二:辅助栈(或队列)
利用栈(或队列)遍历树的所有节点 node ,并交换每个 node 的左 / 右子节点。
算法流程:
(1)特例处理: 当 root 为空时,直接返回None(⚠️python中没有 null,只有None) ;
(2)初始化: 栈(或队列),本文用栈,并加入根节点 root 。
(3)循环交换: 【截止条件】当栈 stack 为空时跳出;
出栈: 记为 node ;
添加子节点: 将 node 左和右子节点入栈;
交换: 交换 node 的左 / 右子节点。
(4)返回值: 返回根节点 root 。
复杂度分析:
时间复杂度 O(N) : 其中 N 为二叉树的节点数量,建立二叉树镜像需要遍历树的所有节点,占用 O(N) 时间。
空间复杂度 O(N) : 如下图所示,最差情况下,栈 stack 最多同时存储
(N+1)/2个节点,占用 O(N) 额外空间。
二、代码
# 解法一:递归
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root:
return None
temp = root.left
root.left = self.mirrorTree(root.right)
root.right = self.mirrorTree(temp) #此处用temp
return root# 解法一:递归的提升
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root: return
root.left, root.right = self.mirrorTree(root.right), self.mirrorTree(root.left)
#Python 利用平行赋值的写法(即 a,b=b,a ),可省略暂存操作。其原理是先将等号右侧打包成元组 (b,a) ,再序列地分给等号左侧的 a,b 序列。
return root# 解法二:辅助栈
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root: return None
stack = [root] #初始化栈:加入根节点 root
while stack: #当栈 stack 不为空
node = stack.pop() #出栈:记为 node
if node.left: # node 左子节点入栈
stack.append(node.left)
if node.right: # node 右子节点入栈
stack.append(node.right)
node.left,node.right = node.right,node.left # 交换左右节点
return root # 此时栈 stack 为空剑指 Offer 29. 顺时针打印矩阵
一、解题思路
1、解法一:按层模拟
可以将矩阵看成若干层,首先打印最外层的元素,其次打印次外层的元素,直到打印最内层的元素。
定义矩阵的第 k 层是到最近边界距离为 k 的所有顶点。
对于每层,从左上方开始以顺时针的顺序遍历所有元素。假设当前层的左上角位于 (top,left),右下角位于 (bottom,right),按照如下顺序遍历当前层的元素。
算法流程:
(1)从左到右遍历上侧元素,依次为 (top,left) 到 (top,right)。
(2)从上到下遍历右侧元素,依次为 (top+1,right) 到 (bottom,right)。
(3)如果 left
(4)遍历完当前层的元素之后,将 left 和 top 分别增加 1,将 right 和 bottom 分别减少 1,进入下一层继续遍历,直到遍历完所有元素为止。
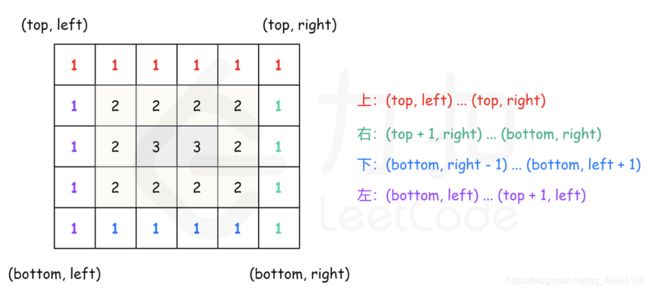
复杂度分析
时间复杂度:O(mn),其中 m和n 分别是输入矩阵的行数和列数。矩阵中的每个元素都要被访问一次。
空间复杂度:O(1)。除了输出数组以外,空间复杂度是常数。
二、代码
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix: # matrix为空时
return list() # 返回空列表[]
row = len(matrix) # matrix的行数
col = len(matrix[0]) # matrix的列数
left,right,top,bottom = 0, col-1, 0, row-1
order = list() #建一个空列表order,存储要打印的每一个数字
while left <= right and top <= bottom: ##等号成立时为一维数组
for j in range(left,right+1):# 从左到右遍历top行的[left,righ]列
order.append(matrix[top][j])
# 从上到下遍历right列的[top+1,bottom]行,注意range是左闭右开区间
for i in range(top+1,bottom+1):
order.append(matrix[i][right])
if left < right and top < bottom: # 至少为2*2的矩阵
for j in range(right-1,left, -1):# 从右到左遍历下侧元素,依次为(bottom,right−1) 到 (bottom,left+1)
order.append(matrix[bottom][j])
for i in range(bottom,top,-1): #从下到上遍历左侧元素,依次为 (bottom,left) 到 (top+1,left)
order.append(matrix[i][left])
#将 left 和 top 分别增加 1,将 right 和 bottom 分别减少 1,进入下一层继续遍历,直到遍历完所有元素为止。
left += 1
top += 1
right -= 1
bottom -= 1
return order剑指 Offer 22. 链表中倒数第k个节点
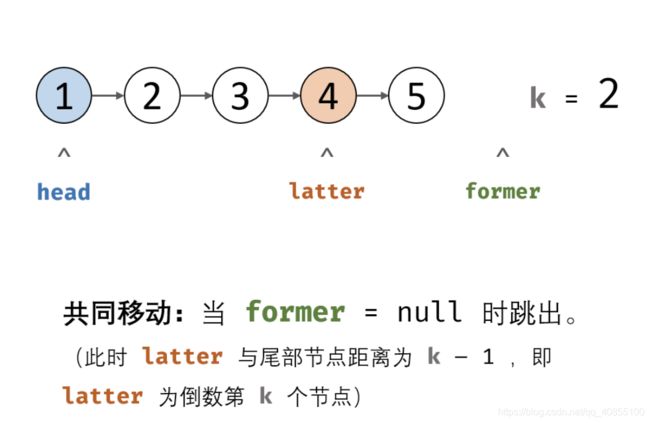
一、解题思路
1、解法一:双指针法
解题思路:
第一时间想到的解法:
先遍历统计链表长度,记为 n ;
设置一个指针走 (n−k) 步,即顺数第(n-k+1)个节点,就是链表倒数第 k 个节点。
但问题是n未知,而使用双指针则可以不用统计链表长度n。
算法流程:
初始化: 前指针 former 、后指针 latter ,双指针都指向头节点 head 。
构建双指针距离: 前指针 former 先向前走 k 步(结束后,双指针 former 和 latter 间相距 k 步)。
双指针共同移动: 循环中,双指针 former 和 latter 每轮都向前走一步,直至 former 走过链表 尾节点 时跳出(跳出后, latter 与尾节点距离为k−1,即 latter 指向倒数第 k 个节点)。
返回值: 返回 latter 即可。
复杂度分析:
时间复杂度 O(N) : N 为链表长度;总体看, former 走了 N 步, latter 走了 (N−k) 步。
空间复杂度 O(1) : 双指针 former , latter 使用常数大小的额外空间。
2、解法二:栈
二、代码
# 解法一:双指针法
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
former, latter = head, head
for _ in range(k):
if not former: return # 如果k>大于链表长度,即越界时
former = former.next
while former:
former, latter = former.next, latter.next # 共同移动
return latter#解法二:栈
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
p = head
#初始化栈
stack = []
# 遍历链表将沿途节点入栈
while p:
stack.append(p)
p = p.next
# 记录第k个出栈的节点即为所求
for _ in range(k):
res = stack.pop()
return res剑指 Offer 28. 对称的二叉树
对称二叉树定义: 对于树中 任意两个对称节点
L 和 R ,一定有:L.val=R.val :即此两对称节点值相等。L.left.val=R.right.val :即 L 的 左子节点 和 R 的 右子节点 对称;L.right.val=R.left.val :即 L 的 右子节点 和 R 的 左子节点 对称。
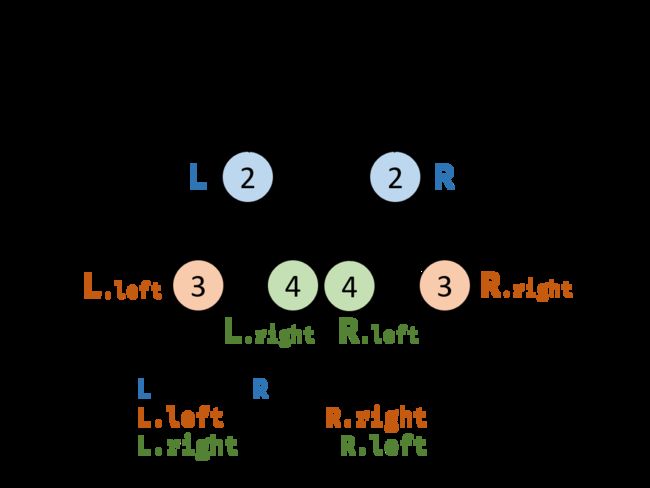
一、解题思路
判断二叉树是否是对称分为几个步骤:
1.空树那么一定对称
2.不为空,转化为根节点的两个子树是否对称
3.一个子树空的那么不对称
4.两个子树的根节点val不一致,那么不对称
5.val相同的话,那么将左子树定义为A,右子树定义为B
6.A.left with B.right and A.right with B.left是否相同。
1、解法一:递归法
算法流程:
isSymmetric(root) :
特例处理: 若根节点 root 为空,则直接返回 true 。
返回值: 即 recur(root.left, root.right) ;
recur(L, R) :
终止条件:
当 L 和 R 同时越过叶节点: 此树从顶至底的节点都对称,因此返回 true ;
当 L 或 R 中只有一个越过叶节点: 此树不对称,因此返回 false ;
当节点 L 值 ≠ 节点 R 值:此树不对称,因此返回 false;
递推工作:
判断两节点 L.left 和 R.right 是否对称,即 recur(L.left, R.right) ;
判断两节点 R.left 是否对称,即 recur(L.right, R.left) ;
返回值: 两对节点都对称时,才是对称树,因此用与逻辑符 && 连接。
复杂度分析:
时间复杂度 O(N) : 其中 N 为二叉树的节点数量,每次执行 recur() 可以判断一对节点是否对称,因此最多调用 N/2 次 recur() 方法。
空间复杂度 O(N) : 最差情况下(见下图),二叉树退化为链表,系统使用
O(N) 大小的栈空间。

2、解法二:迭代法
算法流程:
(1)特判:如果root为空,返回True,因为空树是对称的
(2)把root的左右节点分别加入两个列表q1、q2中
(3)q1和q2非空进入循环:
- 如果左右子树对应节点都不存在,continue,q1和q2非空则继续遍历,q1和q2为空则循环停止
- 如果左右子树对应节点有一个不存在而另一个存在(左右子树不对称)或者两个节点值不相等,返回False
- 左右子树的对应节点入队,注意入队顺序,一个先左后右,一个先右后左,因为对称嘛
(4)遍历完了左右子树也没有返回过False,说明左右子树确实是对称的,返回True
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
二、代码
# 解法一:递归法
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
def recur(L,R):
if not L and not R:
return True
if not L or not R or L.val != R.val:
return False
return recur(L.left,R.right) and recur(L.right,R.left)
if not root:
return True
else:
return recur(root.left,root.right)# 解法二:迭代法
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root: return True
q1 = [root.left]
q2 = [root.right]
while q1 and q2:
n1 = q1.pop()
n2 = q2.pop()
if not n1 and not n2:
continue
if not n1 or not n2 or n1.val != n2.val:
return False
q1.append(n1.left)
q1.append(n1.right)
q2.append(n2.right)
q2.append(n2.left)
return True1、两数之和
一、解题思路
最容易想到的方法是枚举数组中的每一个数 x,寻找数组中是否存在 target - x。
1、解法一:暴力枚举
当我们使用遍历整个数组的方式寻找 target - x 时,需要注意到每一个位于 x 之前的元素都已经和 x 匹配过,因此不需要再进行匹配。而每一个元素不能被使用两次,所以我们只需要在 x 后面的元素中寻找 target - x。
复杂度分析
时间复杂度:O(N^2),其中 N 是数组中的元素数量。最坏情况下数组中任意两个数都要被匹配一次。
空间复杂度:O(1)。
2、解法二:哈希法
创建一个哈希表,遍历每一个 x,我们首先查询哈希表中是否存在 target - x,若 target - x存在于哈希表中,我们就可以直接返回结果了。若 target - x 不存在,则将 target - x 插入到哈希表中,即可保证不会让target - x 和自己匹配,同时方便让后续遍历的数字使用。
复杂度分析
时间复杂度:O(N),其中 N 是数组中的元素数量。对于每一个元素 x,我们可以 O(1) 地寻找 target - x。
空间复杂度:O(N),其中 N 是数组中的元素数量。主要为哈希表的开销。
二、代码
# 解法一:暴力循环
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
n = len(nums)
for i in range(n-1):
for j in range(i + 1, n):
if nums[i] + nums[j] == target:
return [i, j]
return []# 解法二:哈希法
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dic = {}
for i,v in enumerate(nums):# i:index;v:value
if target - v in dic:
return [dic[target - v],i]
dic[v]= i
return []剑指 Offer 57. 和为s的两个数字
一、解题思路
利用 HashMap 可以通过遍历数组找到数字组合,时间和空间复杂度均为 O(N) ;
注意本题的 nums 是 排序数组 ,因此可使用 双指针法 将空间复杂度降低至 O(1) 。
算法流程:
(1)初始化: 双指针 i , j 分别指向数组 nums 的左右两端 (俗称对撞双指针)。
(2)循环搜索: 当双指针相遇时跳出;
计算和 s=nums[i]+nums[j] ;
若 s>target ,则指针 j 向左移动,即执行 j=j−1 ;
若 s
(3)返回空数组,代表无和为 target 的数字组合。
复杂度分析:
时间复杂度
O(N) : N 为数组 nums 的长度;双指针共同线性遍历整个数组。
空间复杂度 O(1) : 变量 i, j 使用常数大小的额外空间。
二、代码
# 双指针法
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
i = 0
j = len(nums)-1
while i < j:
s = nums[i]+nums[j]
if s > target:
j-=1
elif s < target:
i+=1
else: # s == target
return [nums[i],nums[j]]
return [] # 返回空数组# 用“两数之和”中哈希法求解
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dic = {}
for i,v in enumerate(nums):
if target - v in dic:
return [target - v,v]
dic[v]= i
return []剑指 Offer 40. 最小的k个数
一、解题思路
使用排序算法解决最直观,对数组 arr 执行排序,再返回前 k 个元素即可。
1、解法一:快速排序
快速排序算法有两个核心点,分别为 “哨兵划分” 和 “递归” 。
(1)哨兵划分操作: 以数组某个元素(一般选取首元素)为 基准数 ,将所有小于基准数的元素移动至其左边,大于基准数的元素移动至其右边。
(2)递归: 对 左、 右两边的子数组 递归执行 哨兵划分,直至子数组长度为 1 时终止递归,即可完成对整个数组的排序。
⚠️如果划分后某个子数组长度为0或者1,就可以停止划分。
复杂度分析:
时间复杂度 O(NlogN) : 库函数、快排等排序算法的平均时间复杂度为
O(NlogN) 。
空间复杂度 O(N) : 快速排序的递归深度最好(平均)为 O(logN) ,最差情况(即输入数组完全倒序)为 O(N)。
2、解法一:快速排序的提升
题目只要求返回最小的 k 个数,对这 k 个数的顺序并没有要求。因此,只需要将数组划分为 最小的 k 个数 和 其他数字 两部分即可。
根据快速排序原理,如果某次哨兵划分后 基准数正好是第 k+1 小的数字 ,那么此时基准数左边的所有数字便是题目所求的 最小的 k 个数 。
根据此思路,考虑在每次哨兵划分后,判断基准数在数组中的索引是否等于 k ,若 true 则直接返回此时数组的前 k 个数字即可。
3、解法二:堆排序
⚠️大根堆(求前 K 小) ;小根堆(求前 K 大)
最大堆的性质是:节点值大于子节点的值,堆顶元素是最大元素。利用这个性质,整体的算法流程如下:
(1)创建大小为 k 的最大堆,将数组的前 k 个元素放入堆中
(2)从下标 k 继续开始依次遍历数组的剩余元素:
如果元素小于堆顶元素,那么取出堆顶元素,将当前元素入堆
如果元素大于/等于堆顶元素,不做操作
Python 语言中的堆为小根堆,因此我们要对数组中所有的数取其相反数,才能使用小根堆维护前 k 小值。
复杂度分析
时间复杂度:
O(nlogk),其中 n 是数组 arr 的长度。由于大根堆实时维护前 k 小值,所以插入删除都是 O(logk) 的时间复杂度,最坏情况下数组里 n 个数都会插入,所以一共需要 O(nlogk) 的时间复杂度。
空间复杂度:O(k),因为大根堆里最多 k 个数。
二、代码
#解法一:快速排序
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
n = len(arr)
if k <= 0 or arr == [] :
return []
if n <= k:
return arr
self.quick_sort(arr, 0, n-1)
return arr[:k]
#快速排序
def quick_sort(self, nums, left , right):
if left < right:#快速排序的递归终止条件(至少有两个元素,0个或1个元素时不用递归)
mid = self.partition(nums , left , right) # 基准数已归位
self.quick_sort(nums, left, mid-1) # 左子数组递归
self.quick_sort(nums, mid+1, right) # 右子数组递归
def partition(self , nums , left , right):
pivot = nums[left] # pivot存储基准数
while left < right:
## 由于right指针在变化,需要再次加上循环截止条件,使得left==right时跳出循环
while left < right and nums[right] >= pivot:#从右边找比pivot小的数
right -= 1 # 往左走一步
nums[left] = nums[right] # 把右边的值写到左边的空位上
while left < right and nums[left] <= pivot: #从左边找比pivot大的数
left += 1
nums[right] = nums[left]# 把左边的值写到右边的空位上
nums[left] = pivot # 把pivot归位
return left # 返回left和right指针相碰时的位置# 解法一:快速排序的提升
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
n = len(arr)
if k <= 0 or arr == [] :
return []
if n <= k:
return arr
self.quick_sort(arr, 0, n-1,k)
return arr[:k]
#快速排序(多了判断和一个参数k)
def quick_sort(self, nums, left , right,k):
if left < right:#快速排序的递归终止条件(至少有两个元素,0个或1个元素时不用递归)
mid = self.partition(nums , left , right) # 基准数已归位
if k < mid:self.quick_sort(nums, left, mid-1,k) # 左子数组递归
if k > mid:self.quick_sort(nums, mid+1, right,k) # 右子数组递归
def partition(self , nums , left , right):
pivot = nums[left] # pivot存储基准数
while left < right:
## 由于right指针在变化,需要再次加上循环截止条件,使得left==right时跳出循环
while left < right and nums[right] >= pivot:#从右边找比pivot小的数
right -= 1 # 往左走一步
nums[left] = nums[right] # 把右边的值写到左边的空位上
while left < right and nums[left] <= pivot: #从左边找比pivot大的数
left += 1
nums[right] = nums[left]# 把左边的值写到右边的空位上
nums[left] = pivot # 把pivot归位
return left # 返回left和right指针相碰时的位置# python 内置小顶堆
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
return heapq.nsmallest(k, arr)class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
if k == 0:
return []
# Python自带的是小顶堆
# 把取负后的arr的前K个数字存进hp中(不用考虑k和数组长度的大小)
hp = [-x for x in arr[:k]]
# 初始化堆
heapq.heapify(hp)
#遍历剩余的数字 把比堆顶大的数字 塞入堆 丢掉较小的 这样只需要保持空间为K的堆
for i in range(k,len(arr)):
if -hp[0] > arr[i]:
heapq.heappop(hp)
heapq.heappush(hp,-arr[i])
res = [-x for x in hp] # 再次取负,还原成原来的数
return res 剑指 Offer 39. 数组中出现次数超过一半的数字
一、解题思路
1、直接排序法:
- 直接将数组排序,取中间元素
- 由于sort()函数使用的是Timsort方法,一种归并方法的改进
- 时间复杂度为O(nlogn)
2、哈希字典排序:
- 开始遍历整个数组,如果当前数字没有在字典中,就把它加入进去,如果在字典中,则把它的数量加 1 ,接着判断下它的数量是否是大雨整个数组的一半,如果是的话,则直接返回当前数值,否则,继续遍历.
- 由于字典的查找时间复杂度为O(1),所以总的时间复杂度为O(n),空间复杂度为O(n)
3、摩尔投票法
核心理念为 票数正负抵消 。投票法简单来说就是不同则抵消,占半数以上的数字必然留到最后。此方法时间和空间复杂度分别为 O(N) 和 O(1) ,为本题的最佳解法。
记数组首个元素为n1,超过数为x,遍历并统计票数。当发生票数和为0时,剩余数组的超过数一定不变 ,这是由于:
当n1 = x时: 抵消的所有数字中,有一半是超过数 x。
当 n1≠x 时: 抵消的所有数字中,有一半或 0 个是超过数 x 。
因此,当发生票数和=0 时,可以 缩小剩余数组区间 。当遍历完成时,最后一轮假设的数字即为众数。
二、代码
## 1、直接排序法
class Solution:
def majorityElement(self, nums: List[int]) -> int:
nums.sort()
return nums[len(nums)//2]## 2、哈希字典排序
class Solution:
def majorityElement(self, nums: List[int]) -> int:
if len(nums) == 1:
return nums[0]
dic = {}
for i in nums:
if i not in dic:
dic[i] = 1
else:
dic[i] += 1
if dic[i] > (len(nums)//2):
return i
return None## 3、摩尔投票法
class Solution:
def majorityElement(self, nums: List[int]) -> int:
x = nums[0] # 先将数组的第一个数看作是超大数x
vote = 0 # vote:票数统计
for i in range(len(nums)):
if nums[i] == x: # 如果是超大数,票数加1
vote += 1
else: # 否则,票数减1
vote -= 1
#票数改变后,要判断超大数是否改变
if vote == 0: # 将当前数的下一个数看作是超大数
x = nums[i+1] #
i += 1
return x # 票数抵消后,剩下的就是超大数剑指 Offer 42. 连续子数组的最大和
一、解题思路
以某个数作为结尾,意思就是这个数一定会加上去,那么要看的就是这个数前面的部分要不要加上去。大于零就加,小于零就舍弃。
动态规划解析:
状态定义: 设动态规划列表 dp[i] 代表以元素 nums[i] 为结尾的连续子数组最大和。
为何定义最大和 dp[i] 中必须包含元素 nums[i] :保证 dp[i] 递推到 dp[i+1] 的正确性;如果不包含 nums[i] ,递推时则不满足题目的 连续子数组 要求。
转移方程: 若 dp[i−1]≤0 ,说明 dp[i−1] 对 dp[i] 产生负贡献,即 dp[i−1]+nums[i] 还不如 nums[i] 本身大。
当 dp[i−1]>0 时:执行 dp[i]=dp[i−1]+nums[i] ;
当dp[i−1]≤0 时:执行 dp[i]=nums[i] ;
初始状态: dp[0]=nums[0],即以 nums[0] 结尾的连续子数组最大和为 nums[0] 。
返回值: 返回 dp 列表中的最大值,代表全局最大值。
复杂度分析:
时间复杂度O(N)
空间复杂度O(N)
2、动态规划的提升
由于省去 dp 列表使用的额外空间,因此空间复杂度O(N) 降至 O(1) 。
二、代码
## 1、动态规划
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
n = len(nums)
dp = [0 for _ in range(n)]
dp[0],max_res = nums[0],nums[0]
for i in range(1,n):
if dp[i-1] > 0:
dp[i] = dp[i-1] + nums[i]
else:
dp[i] = nums[i]
max_res = max(max_res,dp[i])
return max_res## 2、动态规划的提升
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
for i in range(1,len(nums)):
nums[i] += max(nums[i-1],0)
return max(nums)141. 环形链表(判断链表中是否有环)
一、解题思路
1、哈希表
思路及算法
最容易想到的方法是遍历所有节点,每次遍历到一个节点时,判断该节点此前是否被访问过。
具体地,我们可以使用哈希表来存储所有已经访问过的节点。每次我们到达一个节点,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复这一过程,直到我们遍历完整个链表即可。
复杂度分析
时间复杂度:O(N),其中 N 是链表中的节点数。最坏情况下我们需要遍历每个节点一次。
空间复杂度:O(N),其中 N 是链表中的节点数。主要为哈希表的开销,最坏情况下我们需要将每个节点插入到哈希表中一次。
2、快慢指针
思路及算法
本方法需要读者对「Floyd 判圈算法」(又称龟兔赛跑算法)有所了解。
快指针比慢指针走得快,若链表没有成环,则fast最后会等于None;若链表成环,则fast会先进入环,并且一直在环内移动,必定会出现fast == slow的情况。
复杂度分析
时间复杂度:O(N),其中 N 是链表中的节点数。
当链表中不存在环时,快指针将先于慢指针到达链表尾部,链表中每个节点至多被访问两次。
当链表中存在环时,每一轮移动后,快慢指针的距离将减小一。而初始距离为环的长度,因此至多移动 N 轮。
空间复杂度:O(1)。我们只使用了两个指针的额外空间。
二、代码
## 1、哈希表
class Solution:
def hasCycle(self, head: ListNode) -> bool:
dic = set()
while head:
if head in dic:
return True
else:
dic.add(head)
head = head.next
return False# 2、快慢指针
class Solution:
def hasCycle(self, head: ListNode) -> bool:
fast = slow = head
while fast and fast.next:# 保证fast指针能走两步
fast = fast.next.next
slow = slow.next
if fast == slow:
return True
return False704. 二分查找
一、解题思路
有序:二分法
复杂度分析:
时间复杂度:O(logn)
空间复杂度:O(1)
注意循环条件
二、代码
class Solution:
def search(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right: # 候选区有值
mid = (left + right) // 2
if nums[mid] > target:
right = mid -1
elif nums[mid] < target:
left = mid + 1
else:
return mid
return -135. 搜索插入位置
一、解题思路
仔细分析后,其实就是返回要插入位置的索引。要在数组中插入目标值,无非是这四种情况:
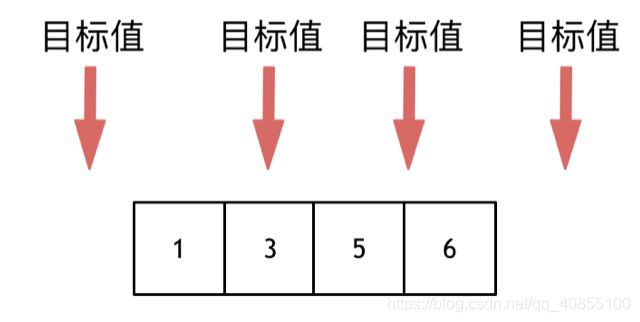
1、方法一:顺序查找
找到第一个大于等于target的元素将其位置返回即可
复杂度分析:
时间复杂度:O(n)
空间复杂度:O(1)
2、折半查找(二分法)
考虑这个插入的位置 pos,它成立的条件为:
nums[pos−1]
复杂度分析:
时间复杂度:O(logn)
空间复杂度:O(1)
二、代码
# 解法一:顺序查找
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
n = len(nums)
for i in range(n):
if target <= nums[i]: # 一旦发现大于或者等于target的num[i],那么i就是我们要的结果
return i
return n # 如果target是最大的,或者 nums为空,则返回nums的长度## 解法二:折半查找(二分法)
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right: # 候选区有值
mid = (left + right) // 2
if nums[mid] > target:
right = mid -1
elif nums[mid] < target:
left = mid + 1
else:
return mid
return left ## 返回插入位置367. 有效的完全平方数
一、解题思路
1、解法一:二分查找
1是完全平方数
边界范围:[2,num/2]
复杂度分析
时间复杂度:O(logN)。
空间复杂度:O(1)。
2、解法二:牛顿迭代法
牛顿迭代法的思想是从一个初始近似值开始,然后作一系列改进的逼近根的过程。
问题是找出:f(x)=x2-num=0 的根。
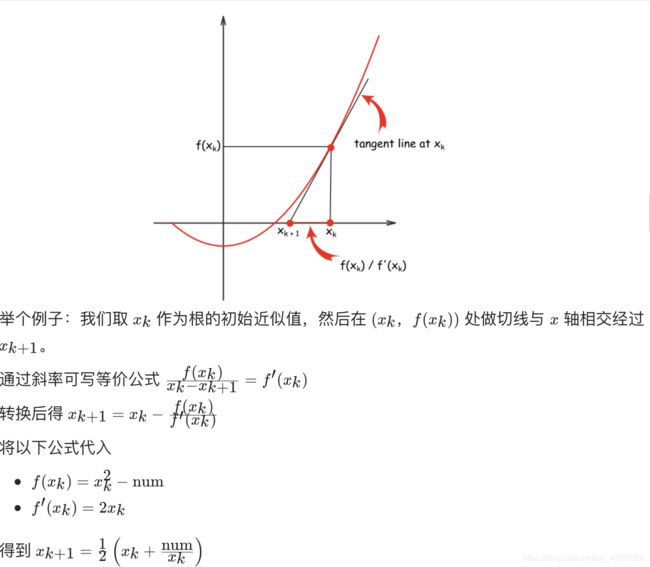
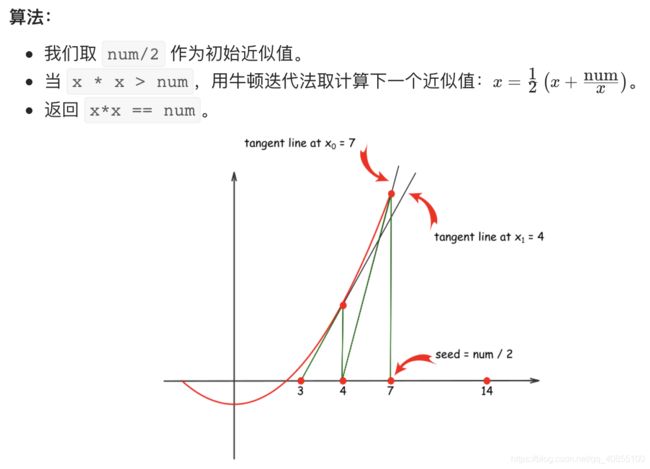
复杂度分析
时间复杂度:O(logN)。
空间复杂度:O(1)。
二、代码
# 解法一:二分查找
class Solution:
def isPerfectSquare(self, num: int) -> bool:
if num < 2:
return True
left = 2
right = num // 2
while left <= right:
mid = left + (right - left) // 2
square = mid * mid
if square == num:
return True
elif square > num:
right = mid - 1
else:
left = mid + 1
return False# 解法二:牛顿迭代法
class Solution:
def isPerfectSquare(self, num: int) -> bool:
if num < 2: # 特殊情况的判断
return True
x = num // 2
while x * x > num:
x = (x + num/x) // 2
return x * x == num # 判断True或者Fslse69. x 的平方根
一、解题思路
1、解法一、暴力循环
for i in range(2, x):
print(i)
如果x是2,什么也不会打印出来;所以x最小为3。
2、解法二、二分法
复杂度分析
时间复杂度:O(logN)
空间复杂度:O(1)
3、解法三、牛顿迭代法
但是我没有理解
二、代码
# 解法一、暴力循环
class Solution:
def mySqrt(self, x: int) -> int:
if x == 0: # 特殊情况的判断
return 0
if x <= 2:
return 1
for i in range(2, x):
if i * i == x:
return i
elif i * i > x:
return i - 1
else:
i += 1# 解法二、二分法
class Solution:
def mySqrt(self, x: int) -> int:
if x <= 1:
return x
left = 2
right = x//2
while left <= right:
mid = (left + right) // 2
square = mid * mid
if square == x:
return mid
elif square > x:
right = mid - 1
else:
left = mid + 1
return right ## 注意left > right时返回right27. 移除元素
一、解题思路
1、方法一:暴力法(两个for循环)
复杂度分析
时间复杂度:O(n^2)
空间复杂度:O(1)
2、方法二:双指针(快慢指针)
由于题目要求删除数组中等于 val 的元素,因此输出数组的长度一定小于等于输入数组的长度,我们可以把输出的数组直接写在输入数组上。可以使用双指针:右指针 right 指向当前将要处理的元素(遍历) ,左指针 left 指向下一个将要赋值的位置。
如果右指针指向的元素不等于 val,它一定是输出数组的一个元素,我们就将右指针指向的元素复制到左指针位置,然后将左右指针同时右移;
如果右指针指向的元素等于 val,它不能在输出数组里,此时左指针不动,右指针右移一位。
整个过程保持不变的性质是:区间 [0,left) 中的元素都不等于 val。当左右指针遍历完输入数组以后,left 的值就是输出数组的长度。
这样的算法在最坏情况下(输入数组中没有元素等于 val),左右指针各遍历了数组一次。
⚠️元素的相对位置没有改变
复杂度分析
时间复杂度:O(n),其中 n 为序列的长度。只需要遍历该序列至多两次。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
3、方法三:快慢双指针的优化
实现方面,我们依然使用双指针,两个指针初始时分别位于数组的首尾,向中间移动遍历该序列。
如果左指针 left 指向的元素等于 val,此时将右指针 right 指向的元素复制到左指针 left 的位置,然后右指针 right 左移一位。如果赋值过来的元素恰好也等于 val,可以继续把右指针 right 指向的元素的值赋值过来(左指针 left 指向的等于 val 的元素的位置继续被覆盖),直到左指针指向的元素的值不等于 val 为止。
当左指针 left 和右指针 right 重合的时候,左右指针遍历完数组中所有的元素。
这样的方法两个指针在最坏的情况下合起来只遍历了数组一次。与普通双指针法不同的是,优化后避免了需要保留的元素的重复赋值操作。
⚠️元素的相对位置发生了改变
复杂度分析
时间复杂度:O(n),其中 n 为序列 的长度。只需要遍历该序列至多一次。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
二、代码
# 方法一:暴力法
# 待补充# 方法二:双指针(快慢指针)
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
n = len(nums)
left = 0 # left是慢指针,指向下一个将要输出的位置
for right in range(n): # right是快指针,指向当前将要处理的元素(遍历)
if nums[right] != val: # 则nums[right]肯定要输出,要放到left位置上
nums[left] = nums[right]
left += 1 # 左右指针同时右移(右指针是循环自动右移)
# 当nums[right] == val:只有右指针因为循环自动右移
return left # left 的值就是最终要输出数组的长度# 方法三:快慢双指针的优化
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
n = len(nums)
left = 0 # 两个指针初始时分别位于数组的首尾,向中间移动遍历该序列
right = n - 1
while left < right: # 左右指针重合时,遍历完数组中所有的元素
if nums[left] == val:
nums[left] = nums[right-1]# 将right 指向的元素复制到left 的位置,即删除了left位置上的原值
right -= 1 # right 左移一位
left += 1 # left 右移一位
return left26. 删除有序数组中的重复项
一、解题思路
首先注意数组是有序的,那么重复的元素一定会相邻。
要求删除重复元素,实际上就是将不重复的元素移到数组的左侧。
1、方法一: 双指针
考虑用 2 个指针,一个在前记作 i,一个在后记作 j,算法流程如下:
(1)比较 i 和 j 位置的元素是否相等。
如果相等,j 后移 1 位;
如果不相等,将 j 位置的元素复制到 i+1 位置上,i 后移一位,j 后移 1 位
重复上述过程,直到 j 等于数组长度。
(2)返回 i + 1,即为新数组长度。
⚠️因为最初 i等于 0 时的数字未统计,所以最终返回结果需要 +1。
复杂度分析
时间复杂度:O(n),其中 n 是数组的长度。快指针和慢指针最多各移动 n 次。
空间复杂度:O(1)。只需要使用常数的额外空间。
2、方法二:通用解法
「通用解法」是一种针对「数据有序,相同元素最多保留 k 位」
- 由于是保留 k 个相同数字,对于前 k 个数字,我们可以直接保留。
- 对于后面的任意数字,能够保留的前提是:与当前写入的位置前面的第 k 个元素进行比较,不相同则保留。
二、代码
# 方法一: 双指针
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
n = len(nums)
if n == 0: # 空数组的判断
return 0
left = 0
for right in range(1, n):
if nums[right] != nums[left]:
nums[left+1] = nums[right] # 赋值给nums[left+1],而不是nums[left]
left += 1
return left+1 # 所以此处为left+1# 方法二:通用解法
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
def process(nums, k): # 保留 k 个相同数字
idx = 0 # idx,指向待插入位置
# idx < k: 直接保留前 k 个数字
# nums[idx-k] != x: 保留与前 k 个数字不相同的
for x in nums:
if idx < k or nums[idx-k] != x:
nums[idx] = x
idx += 1
return idx
return process(nums, 1)80. 删除有序数组中的重复项 II
与26. 删除有序数组中的重复项相似,只不过是使每个元素最多出现两次。
# 方法一: 双指针
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
n = len(nums)
if n == 0: # 空数组的判断
return 0
left = 0
for right in range(2, n):
if nums[right] != nums[left]:
nums[left+2] = nums[right] # 赋值给nums[left+2],而不是nums[left]
left += 1
return left+2 # 最多出现2次# 方法二:通用解法
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
def process(nums, k): # 保留 k 个相同数字
idx = 0 # idx,指向待插入位置
# idx < k: 直接保留前 k 个数字
# nums[idx-k] != x: 保留与前 k 个数字不相同的
for x in nums:
if idx < k or nums[idx-k] != x:
nums[idx] = x
idx += 1
return idx
return process(nums, 2)283. 移动零
一、解题思路
方法:双指针
使用双指针,左指针指向当前已经处理好的序列的尾部,右指针指向待处理序列的头部。
右指针不断向右移动,每次当右指针指向非零数时,则将左右指针对应的数交换,同时左指针右移。
注意到以下性质:
左指针左边均为非零数;
右指针左边直到左指针处均为零。
因此每次交换,都是将左指针的零与右指针的非零数交换,且非零数的相对顺序并未改变。
复杂度分析
时间复杂度:O(n),其中 n 为序列长度。每个位置至多被遍历两次。
空间复杂度:O(1)。只需要常数的空间存放若干变量。
二、代码
方法:双指针
class Solution:
def moveZeroes(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
i = 0
for j in range(len(nums)):
if nums[j] != 0:
nums[i], nums[j] = nums[j], nums[i]
i += 1844. 比较含退格的字符串
一、解题思路
1、方法一:重构字符串
将给定的字符串中的退格符和应当被删除的字符都去除,还原给定字符串的一般形式。然后直接比较两字符串是否相等即可。
具体地,我们用栈处理遍历过程,每次我们遍历到一个字符:
- 如果它是退格符,那么我们将栈顶弹出;
- 如果它是普通字符,那么我们将其压入栈中
复杂度分析
时间复杂度:O(N+M),其中 N 和 M 分别为字符串 S 和 T 的长度。我们需要遍历两字符串各一次。
空间复杂度:O(N+M),其中 N 和 M 分别为字符串 S 和T 的长度。主要为还原出的字符串的开销。
2、方法二:双指针
由于 # 号只会消除左边的一个字符,所以对右边的字符无影响,所以我们选择从后往前遍历S,T 字符串。
思路解析:
(1)准备两个指针 i, j 分别指向 S,T 的末位字符,再准备两个变量 skipS,skipT 来分别存放 S,T 字符串中的 # 数量。
(2)从后往前遍历 S,所遇情况有三,如下所示:
- 若当前字符是 #,则 skipS 自增 1;
- 若当前字符不是 #,且 skipS 不为 0,则 skipS 自减 1;
- 若当前字符不是 #,且 skipS 为 0,则代表当前字符不会被消除,我们可以用来和 T 中的当前字符作比较。
(3)若对比过程出现 S, T 当前字符不匹配,则遍历结束,返回 false,若 S,T 都遍历结束,且都能一一匹配,则返回 true。
二、代码
# 方法一:重构字符串
class Solution:
def backspaceCompare(self, s: str, t: str) -> bool:
def build(strs):
stack = []
for ch in strs:
if ch != "#":
stack.append(ch)
elif stack: # ch == "#" and not stack
stack.pop()
return "".join(stack)
return build(s) == build(t)# 方法二:双指针
class Solution:
def backspaceCompare(self, S: str, T: str) -> bool:
i, j = len(S) - 1, len(T) - 1
skipS = skipT = 0
while i >= 0 or j >= 0: # 大循环
while i >= 0: # 遍历S字符串
if S[i] == "#":
skipS += 1
i -= 1
elif skipS > 0:
skipS -= 1
i -= 1
else:
break # 跳出当前循环,进入外层大循环
while j >= 0: # 遍历T字符串
if T[j] == "#":
skipT += 1
j -= 1
elif skipT > 0:
skipT -= 1
j -= 1
else:
break # 跳出当前循环,进入外层大循环
s = "" if i < 0 else S[i]
t = "" if j < 0 else T[j]
if s != t:
return False
i -= 1
j -= 1
return True
977.有序数组的平方
一、解题思路
方法:双指针
left 指针指向 nums 数组的开头;right 指针指向 nums 数组的结尾。
因为 nums 数组在平方前是有序的,并且 nums 数组的平方的最大值一定是在两端找到的,不可能出现在中间位置。所以,利用 left 指针和 right 指针每次找到 剩余nums 数组两端中绝对值较大的那个元素,将其平方后,存入一个新的数组 res 中(注意:从后往前存)。
复杂度分析
时间复杂度:O(n),其中 n 是数组 nums 的长度。
空间复杂度:O(1)。除了存储答案的数组以外,我们只需要维护常量空间。
# 方法:双指针
class Solution:
def sortedSquares(self, nums: List[int]) -> List[int]:
n = len(nums)
ans = [0] * n
i, j, pos = 0, n - 1, n - 1
while i <= j: # 注意等号能否取到
if nums[i] * nums[i] > nums[j] * nums[j]:
ans[pos] = nums[i] * nums[i]
i += 1
else:
ans[pos] = nums[j] * nums[j]
j -= 1
pos -= 1
return ans15.三数之和
一、解题思路
排序 + 双指针
本题的难点在于如何去除重复解。
算法流程:
(1)特判,对于数组长度 n,如果数组为 null 或者数组长度小于3,返回 []。
(2)对数组进行排序。
(3)外部循环:遍历排序后数组:
对于重复元素:跳过,避免出现重复解
(4)内部循环:当 L
- 当 nums[i]+nums[L]+nums[R]=0,执行循环,判断左界和右界是否和下一位置重复,去除重复解。并同时将 L,R 移到下一位置,寻找新的解
- 若和大于 0,说明 nums[R] 太大,R 左移
- 若和小于 0,说明 nums[L] 太小,L 右移
当 L=R 时,循环结束,i++
复杂度分析
时间复杂度:数组排序 O(NlogN),遍历数组 O(n),双指针遍历 O(n),总体 O(NlogN)+O(n)∗O(n),
空间复杂度:O(1)
二、代码
# 排序 + 双指针
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
if not nums or n < 3: # 数组为空或者长度<3,返回[]
return []
nums.sort() # 排序
res = [] # 存储结果
for i in range(n):
if i > 0 and nums[i]==nums[i-1]:
continue # 对于重复元素:跳过,避免出现重复解
L, R = i + 1, n - 1
while L < R:
if nums[i] + nums[L] + nums[R] < 0: # nums[L] 太小
L += 1
elif nums[i] + nums[L] + nums[R] > 0: # nums[R] 太大
R -= 1
else: #nums[i] + nums[L] + nums[R] == 0:
res.append([nums[i],nums[L],nums[R]])
# 执行循环,判断左界是否和下一位置重复,去除重复解。
while(L<R and nums[L]==nums[L+1]):
L += 1
# 执行循环,判断右界是否和下一位置重复,去除重复解。
while(L<R and nums[R]==nums[R-1]):
R -= 1
# 将 L,R 移到下一位置,寻找新的解
L += 1
R -= 1
return res18. 四数之和
一、解题思路
在三数之和上再套一层for循环
复杂度分析
时间复杂度:数组排序 O(NlogN),总体 O(NlogN)+O(n3),
空间复杂度:O(1)
二、代码
class Solution:
def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
n = len(nums)
if not nums or n < 4:
return []
nums.sort() # 排序
res = []
for i in range(n-3):
if i > 0 and nums[i]==nums[i-1]:
continue # 对于重复元素:跳过,避免出现重复解
num1 = nums[i]
for j in range(i+1,n-2):
if j > i+1 and nums[j]==nums[j-1]:
continue # 对于重复元素:跳过,避免出现重复解
num2 = nums[j]
L, R = j+1, n-1 # 第3,4个数的初始位置
while L < R:
if nums[i]+nums[j]+nums[L]+nums[R] < target:
L += 1
elif nums[i]+nums[j]+nums[L]+nums[R] > target:
R -= 1
else:# nums[i]+nums[j]+nums[L]+nums[R] == target:
res.append([nums[i],nums[j],nums[L],nums[R]])
# 执行循环,判断左界是否和下一位置重复,去除重复解。
while(L<R and nums[L]==nums[L+1]):
L += 1
# 执行循环,判断右界是否和下一位置重复,去除重复解。
while(L<R and nums[R]==nums[R-1]):
R -= 1
# 将 L,R 移到下一位置,寻找新的解
L += 1
R -= 1
return res142. 环形链表 II
一、解题思路
方法:快慢指针
(1)判断链表是否有环?
分别定义 fast 和 slow指针,均从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在环中相遇 ,说明这个链表有环。
如果有环,则fast 会一直在环中运动,直到遇到slow指针。
(2)如果有环,如何找到这个环的入口?
这个代码还看不大懂
二、代码
class Solution:
def detectCycle(self, head: ListNode) -> ListNode:
slow, fast = head, head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 如果相遇
if slow == fast:
p = head
q = slow
while p!=q:
p = p.next
q = q.next
#你也可以return q
return p
return Noneclass Solution(object):
def detectCycle(self, head):
fast, slow = head, head
while True:
if not (fast and fast.next): return
fast, slow = fast.next.next, slow.next
if fast == slow: break
fast = head
while fast != slow:
fast, slow = fast.next, slow.next
return fast
作者:jyd
链接:https://leetcode-cn.com/problems/linked-list-cycle-ii/solution/linked-list-cycle-ii-kuai-man-zhi-zhen-shuang-zhi-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。54. 螺旋矩阵
相似题:59. 螺旋矩阵II
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
m = len(matrix) # m: matrix的行数
n = len(matrix[0]) # n: matrix的列数
res = [] # res:存储矩阵中的所有元素
left, right, top, bottom = 0, n-1, 0, m-1
while left<= right and top<= bottom:
for i in range(left,right+1):
res.append(matrix[top][i])
for j in range(top+1,bottom+1):
res.append(matrix[j][right])
if left< right and top< bottom: # 必须加上if判断
for i in range(right-1,left,-1):
res.append(matrix[bottom][i])
for j in range(bottom, top,-1):
res.append(matrix[j][left])
left += 1
top += 1
right -= 1
bottom -= 1
return res不懂54. 螺旋矩阵为什么必须加上if判断语句,不加会出错?
而59. 螺旋矩阵II加不加if判断语句,都不会出错??
203.移除链表元素
一、解题思路
1、方法一:直接使用原来的链表来进行删除操作。
2、方法二:设置一个虚拟头结点在进行删除操作。
复杂度分析
时间复杂度:O(N),只遍历了一次。
空间复杂度:O(1)。
二、代码
# 方法一:
class Solution:
def removeElements(self, head: ListNode, val: int) -> ListNode:
# 删除头节点
while head and head.val == val: # 有可能新的头节点值仍等于val,所以用while循环
head = head.next
if not head: # 判断链表是否为空
return
# 删除非头节点
pre = head
while pre.next:
if pre.next.val == val:
pre.next = pre.next.next
else:
pre = pre.next
return head # 返回头节点⚠️如果先判断链表是否为空,则删除非头节点时,要再次保证头节点不鞥为空,即改为while pre and pre.next:
if not head: # 判断链表是否为空
return
不懂判断链表是否为空这里,if not head:
return正确,而return []会报错?
# 方法二:
class Solution:
def removeElements(self, head: ListNode, val: int) -> ListNode:
# 添加虚拟头节点,指向head节点
dummy = ListNode(0)
dummy.next = head
# 或者 dummy = ListNode(0,head)
pre = dummy # 工作指针pre
while pre.next:
if pre.next.val == val:
pre.next = pre.next.next
else:
pre = pre.next
return dummy.next # 返回真正的头节点