【ToyDB-Rust】超详细介绍
文章目录
- 概述
- 节点组件
- 存储引擎
-
- 键/值存储
- 键/值tradeOffs
- MVCC事务
-
- MVCC tradeOffs
- Log-structured Storage
-
- Log tradeOffs
- Raft共识引擎
-
- Raft tradeOffs
- SQL引擎
-
- Types
- schemas
-
- Schema Tradeoffs
- Storage
- Storage tradeOffs
- Parsing
- Planning
-
- Planning tradeOffs
- Execution
- Server
-
- server tradeOffs
- Client
- Setup
- 建表
- 约束和参照完整性
- 基本sql查询
-
- 表达式
- joins
- explain
- arrgrgates
- 事务
概述
在最高级别,toyDB由一组节点组成,这些节点针对复制的状态机执行SQL事务。客户端可以连接到群集中的任何节点并提交SQL语句。它的目标是提供线性化(即强一致性)和串行化,但由于目前仅实现快照隔离,因此略显不足。
RAFT算法用于簇一致性,只要大多数节点仍然可用,它就可以容忍任何节点的故障。一个节点被选举为领导者,并将命令复制到其他节点,其他节点将命令应用于状态机的本地副本。如果领导丢失,则选举新的领导,并且群集继续运行。客户端命令会自动转发给领导者。
本体系结构指南将从节点组件的高级概述开始,然后自下而上地讨论每个组件。在此过程中,我们将记录权衡和设计选择。
节点组件
toyDB节点由三个主要组件组成:
存储引擎:在磁盘和内存中存储数据和管理事务。
RAFT共识引擎:处理集群协调和状态机复制。
SQL引擎:为客户端解析、计划和执行SQL语句。
这些组件集成在toyDB服务器中,该服务器处理与客户端和其他节点的网络通信。下图说明了其内部结构:
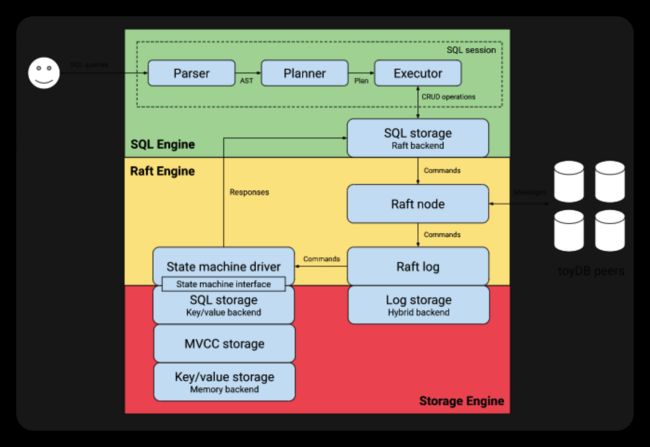
底部是一个简单的键/值存储,它存储所有SQL数据。它包装在添加ACID事务的MVCC键/值存储中。最上面是一个SQL存储引擎,提供对表、行和索引的基本CRUD操作。这构成了节点的核心存储引擎。
SQL存储引擎包装在RAFT状态机接口中,允许它由RAFT一致性引擎进行管理。RAFT节点接收来自客户端的命令,并与其他RAFT节点协调以在有序的命令日志上达成共识。将命令提交到日志后,它们被发送到状态机驱动程序,状态机驱动程序将它们应用于本地状态机。
在RAFT引擎之上是一个基于RAFT的SQL存储引擎,它实现SQL存储接口并向RAFT集群提交命令。这允许sql层使用RAFT集群,就好像它是本地存储一样。
SQL引擎管理客户端SQL会话,该会话将SQL查询视为文本,对其进行解析、生成查询计划并针对SQL存储引擎执行。
围绕这些组件的是toyDB服务器,除了网络通信之外,它还处理配置、日志记录和其他进程级别的问题。
存储引擎
存储引擎实际上是两个不同的存储引擎:SQL引擎使用键/值存储,RAFT节点使用日志结构存储。它们都可以通过STORAGE_SQL和STORAGE_RAFT配置选项进行插拔,并且有多个具有不同特征的实现。
SQL存储引擎将在SQL一节中单独讨论。
键/值存储
键/值存储引擎将任意键/值对存储为二进制Byte Slices,并实现storage::kv::Store trait:
pub trait Store: Display + Send + Sync {
/// Deletes a key, or does nothing if it does not exist.
fn delete(&mut self, key: &[u8]) -> Result<()>;
/// Flushes any buffered data to the underlying storage medium.
fn flush(&mut self) -> Result<()>;
/// Gets a value for a key, if it exists.
fn get(&self, key: &[u8]) -> Result<Option<Vec<u8>>>;
/// Iterates over an ordered range of key/value pairs.
fn scan(&self, range: Range) -> Scan;
/// Sets a value for a key, replacing the existing value if any.
fn set(&mut self, key: &[u8], value: Vec<u8>) -> Result<()>;
}
-
get, set and deletemethods simply read and write key/value pairs -
flushensures any buffered data is written out to storage (e.g. via the fsync system call). -
scan按顺序迭代键/值范围,这一属性对于更高级别的功能(例如SQL表扫描)至关重要,并且具有几个重要的含义:- 为了提高性能,实现应该存储按键排序的数据。
- 键应该使用保持顺序的字节编码,以允许范围扫描。
-
存储本身并不关心包含什么键,但是模块提供了一种保持顺序的键编码,以供更高层使用。这些存储层通常使用由几个可能的可变长度值组成的组合键(例如,索引键由表、列和值组成),并且必须保留每个段的自然顺序,这是此编码所满足的属性:
- bool: 0x00 for false, 0x01 for true.
- Vec: terminated with 0x0000, 0x00 escaped as 0x00ff.
- String: like Vec.
- u64: Big-endian binary encoding.
- i64: Big-endian binary encoding, sign bit flipped.
- f64: Big-endian binary encoding, sign bit flipped if +, all flipped if -.
- sql::Value: As above, with type prefix 0x00=Null, 0x01=Boolean, 0x02=Float, 0x03=Integer, 0x04=String
-
默认键/值存储是
STORAGE::KV::Memory。这是一个内存中的B+树,这是一个搜索树变体,每个节点有多个键(以利用缓存位置),值仅在叶节点中。随着键/值对的添加和删除,树节点将被拆分、合并和旋转,以保持它们的平衡和至少半满。 -
虽然键/值数据存储在内存中,但toyDB通过保存在磁盘上的RAFT日志提供持久性。启动时,将重放RAFT日志以填充内存存储。
键/值tradeOffs
- 内存中存储:与磁盘存储相比,在内存中存储键/值数据的性能要好得多,实现起来也更简单,但要求数据集可以放入内存中。对于大型数据集,在启动时重放RAFT日志也可能需要相当长的时间。但是,由于toyDB数据集预期较小,因此这是最有利的。
- 字节序列化:由于主存储在内存中,(反)序列化键/值对会增加大量不必要的开销。然而,一开始并不清楚toyDB是否会使用内存中存储,
Byte Slices是一个简单的接口,可以在任何存储介质中使用。 - B+树扫描:B+树通常在相邻的叶节点之间有指针,以提高范围扫描的效率,但是toyDB的实现没有。这会使实现变得复杂,在随机访问延迟较低的内存中,性能优势通常不会很大。但是,这一点与其他实现细节一起导致每个步骤的范围扫描为O(Logn)而不是O(1)。
key编码:不使用任何压缩,例如可变长度整数,更喜欢简单性和正确性。
MVCC事务
- 多版本并发控制是一个相对简单的并发控制机制,它为ACID事务提供
快照隔离snapshot isolation,而无需取出锁或进行写阻塞读。它还对所有数据进行版本化,允许查询历史数据。 - ToyDB在键/值层将MVCC实现为
STORAGE::KV::MVCC,对底层存储使用任何STORAGE::KV::MVCC实现。BEGIN返回一个新事务,该事务提供常见的键/值操作,如GET、SET和SCAN。此外,它还有一个COMMIT方法(持久化更改并使其对其他事务可见)和一个ROLLBACK方法(丢弃它们)。 - 当事务开始时,它从
key::TxnNext获取下一个可用的事务ID并递增,然后通过key::TxnActive(Id)将其自身记录为活动事务。它还获取一个Snapshot,其中包含截至事务启动时所有其他活动事务的ID,并将其另存为key::TxnSnapshot(Id)。 kv pairs另存为Key::Record(Key,Version),其中Key是用户提供的Key,Version是创建记录的事务ID。事务的键/值对的可见性如下所示:- 对于某个用户给定的key,从当前事务的ID开始对
Key::Record(Key,Version)执行反向扫描。 - 跳过其版本在快照的活动事务ID列表中的任何记录。
- 返回第一个匹配的记录(如果有)。如果键已删除,则此记录可以是Some(值)或None。
- 对于某个用户给定的key,从当前事务的ID开始对
- 当写入键/值对时,事务首先通过扫描对其不可见的
Key::Record(key, version)来检查任何冲突。- 如果找到,则返回序列化错误,客户端必须重试该事务。
- 否则,事务将写入新记录,并将更改记录为
key::update(id,key),以防以后必须回滚。
- 当事务提交时,它只会删除其
TXN::ACTIVE(Id)记录,从而使其更改对任何后续事务都可见。 - 如果事务回滚,它将迭代所有
key::update(id,key)条目,并在删除其txn::active(Id)条目之前删除写入的键/值记录。 - 这个简单的方案足以提供具有快照隔离的ACID事务保证:提交是原子的,事务在事务开始时看到键/值存储的一致快照,并且任何写冲突都会导致必须重试的序列化错误。
- 为了满足time travel查询,只读事务只需加载过去事务的Snapshot条目,并应用与普通事务相同的可见性规则。
MVCC tradeOffs
- 只读事务处理ID:所有事务处理(即使是只读事务处理)都分配有唯一的事务处理ID。这意味着单个独立的SELECT查询将导致写入操作以增加事务处理ID计数器,这可能代价高昂。
- 可序列化:快照隔离不是完全可序列化的,因为它表现出写偏差异常。这将需要可序列化的快照隔离,这在第一个版本中被认为是不必要的-它可能会在以后实现。
- 垃圾收集:旧的MVCC版本永远不会被删除,从而导致无限制的磁盘使用。但是,这也允许完整的数据历史记录,并简化了实现。
- 事务ID溢出:事务ID将在64位之后溢出,但toyDB永远不会发生这种情况。
Log-structured Storage
RAFT节点需要保持被编码为任意字节片的状态机命令的日志。此日志主要是仅附加的,并且将其存储在随机访问键/值存储中比使用专门为此访问模式构建的日志结构存储要慢且复杂。
日志存储实现STORAGE::LOG::STORE特征,其子集包括:
pub trait Store: Display + Sync + Send {
/// Appends a log entry, returning its index.
fn append(&mut self, entry: Vec<u8>) -> Result<u64>;
/// Commits log entries up to and including the given index, making them immutable.
fn commit(&mut self, index: u64) -> Result<()>;
/// Fetches a log entry, if it exists.
fn get(&self, index: u64) -> Result<Option<Vec<u8>>>;
/// Iterates over an ordered range of log entries.
fn scan(&self, range: Range) -> Scan;
/// Truncates the log by removing any entries above the given index, and returns the
/// highest remaining index. Attempting to truncate a committed entry will error.
fn truncate(&mut self, index: u64) -> Result<u64>;
}
RAFT节点将所有接收到的命令附加到其本地日志,但是只有在它们被一致确认之后才提交条目。例如在领导者变更的情况下,可能需要截断本地日志,从而移除多个未提交的条目。
此外,存储必须能够通过set_metadata(key, value) and get_metadata(key)方法为RAFT节点存储少量任意的键/值元数据对。
toyDB中的默认日志存储是STORAGE::LOG::HIXED,它将未提交的条目存储在内存中,并将已提交的条目存储在磁盘上。这允许仅按顺序附加写入日志,从而为写入和批量读取提供非常好的性能。未提交条目的数量通常也很少,因为共识通常很快。
新日志条目保留在VecDeque(双端队列)中,直到提交。提交时,条目将被附加到带有u32长度前缀的文件中,并且文件将被fsynced(如果启用)。条目位置保存在以条目索引为关键字的内存中的HashMap中,用于检索,该映射在启动时通过扫描日志文件重新构建。
元数据键/值对保存在内存中的HashMap中,并且在每次写入时将整个HashMap写入单独的文件。
Log tradeOffs
启动日志扫描:在启动时扫描整个文件以构建条目索引可能很耗时,并且索引需要一些内存。但是,这避免了必须维护单独的索引存储(fsync可能很昂贵),而且数据集预计会很小。
元数据存储:元数据键/值对应该存储在例如磁盘B-tree键/值存储中,但toyDB当前没有这样的存储。然而,元数据项的数量非常少–具体地说是1:当前的Raft term/vote tuple。
内存缓冲:如果共识停止(例如由于丢失仲裁),则缓冲内存中的未提交条目可能需要大量内存。但是,对于toyDB用例,这不是一个主要问题,而且它避免了必须执行额外的(可能是随机的)磁盘IO,从而极大地提高了性能。
垃圾收集:不会对旧日志条目进行垃圾收集,因此日志将不受限制地增长。但是,这是必要的,因为默认的toyDB配置默认使用内存中的键/值存储,并且没有其他持久存储。
Raft共识引擎
RAFT共识协议在原始的RAFT论文https://raft.github.io/raft.pdf中解释得很好,这里不再重复-详细信息请参阅它。ToyDB的实现非常紧跟本文的内容。
RAFT节点RAFT::NODE是实现的核心,它是一个有限状态机,带有节点角色(领导者、跟随者和候选人)的枚举变体。此枚举包装了RoleNode结构,该结构包含公共节点功能,并且对于实现RAFT协议的特定角色Leader、Follow和Candidate是通用的。
节点使用ID和对等点ID列表进行初始化,并通过传递RAFT::Message消息进行通信。入站消息通过Node.step()调用接收,出站消息通过MPSC通道发送。节点还使用逻辑时钟来跟踪例如选举超时和心跳,并且时钟通过Node.tick()调用定期计时。这些方法是同步的,可能会导致状态转换,例如,当候选人收到获胜的选票时,将其更改为领导人。
节点有一个命令log raft::log,使用storage::log::store进行存储。领导者通过请求消息接收客户端命令,将其复制到同行,并按照协商一致的方式将命令提交到日志中。提交命令后,将其异步应用于状态机。
RAFT管理的状态机(即SQL存储引擎)实现RAFT::STATE特性,并在初始化时提供给节点。状态机驱动程序RAFT::Driver拥有状态机的所有权,并在通过MPSC通道接收指令的单独线程(或更确切地说,Tokio任务)中运行-这避免了长时间运行的命令阻塞主RAFT节点响应消息。
除了应用状态机命令外,驱动程序还通过出站MPSC通道响应客户端请求。当领导者接收到来自客户端的状态变化请求时,它不仅将命令附加到其日志中,而且还告诉驱动程序,一旦应用该命令,就将结果通知客户端。当引导者接收到状态查询请求时,在引导者要求所有对等体确认它仍然是引导者(需要满足线性化)之前,将关于该查询通知状态驱动程序。确认被传递给状态机驱动程序,一旦收到多数票,就对状态机执行查询,并将结果返回给客户端。
实际的网络通信由服务器进程处理,这将在单独的一节中介绍。
Raft tradeOffs
单线程状态:所有状态操作在Leader上的单个线程中运行,从而防止水平可伸缩性。这里的改进需要运行多个分片的RAFT集群,这超出了该项目的范围。
日志复制:只实现最简单形式的RAFT日志复制,没有状态快照或快速日志重放。落后的节点将非常缓慢地迎头赶上。
调整集群大小:RAFT集群由启动时给定的一组静电节点组成,调整大小需要完全重新启动集群。
SQL引擎
SQL引擎构建在RAFT和MVCC之上,为客户端提供SQL接口。从逻辑上讲,SQL查询的生命周期如下:
查询→词法分析器→解析器→规划器→优化器→执行器→存储引擎
我们将首先查看基本的SQL类型和模式系统,以及SQL存储引擎及其会话接口。然后,我们将互换位置,看看查询是如何执行的,从解析器的前端开始,然后跟随查询,直到针对SQL存储引擎执行查询,从而完成链。
Types
toyDB有一个非常简单的类型系统,使用SQL::DataType枚举指定可用的数据类型:Boolean、Integer、Float和String。
SQL::Value枚举表示使用Rust的本机类型系统的特定值,例如,整数值是Value::Integer(I64)。此枚举还指定值的比较、排序和格式。特殊值Value::NULL表示未知类型的未知值,遵循三值逻辑规则。
可以将值分组到Row中,Row是vec的别名。Rows是易出错的行迭代器的别名,而COLUMN是包含名称的结果列。
表达式SQL::Expression表示对值的操作。例如,(1+2)*3表示为:
Expression::Multiply(
Expression::Add(
Expression::Constant(Value::Integer(1)),
Expression::Constant(Value::Integer(2)),
),
Expression::Constant(Value::Integer(3)),
)
对表达式调用valuate()会递归求值,返回Value::Integer(9)。
schemas
该模式定义了toyDB数据库中的表SQL::TABLE和列SQL::COLUMN。表有一个名称和一个列的列表,而一个列有几个属性,如名称、数据类型和各种约束。它们还具有验证行和值的方法,例如,确保值的类型对于列是正确的,或者强制执行引用完整性。
该方案使用sql::Catalog存储和管理
pub trait Catalog {
/// Creates a new table.
fn create_table(&mut self, table: &Table) -> Result<()>;
/// Deletes a table, or errors if it does not exist.
fn delete_table(&mut self, table: &str) -> Result<()>;
/// Reads a table, if it exists.
fn read_table(&self, table: &str) -> Result<Option<Table>>;
/// Iterates over all tables.
fn scan_tables(&self) -> Result<Tables>;
}
Schema Tradeoffs
单个数据库:每个toyDB集群只支持一个未命名的数据库。这对于toyDB的用例来说已经足够了,并且简化了实现。
架构更改:不支持创建或删除表以外的架构更改。这避免了复杂的数据迁移逻辑,并允许使用表名/列名作为存储标识符(因为它们永远不会更改),而不会有任何额外的间接影响。
Storage
The SQL storage engine trait is sql::Engine:
pub trait Engine: Clone {
type Transaction: Transaction;
/// Begins a transaction in the given mode.
fn begin(&self, mode: Mode) -> Result<Self::Transaction>;
/// Resumes an active transaction with the given ID.
fn resume(&self, id: u64) -> Result<Self::Transaction>;
/// Begins a SQL session for executing SQL statements.
fn session(&self) -> Result<Session<Self>> {
Ok(Session { engine: self.clone(), txn: None })
}
}
特征的主要用途是分配SQL::Session实例,即执行以纯文本形式提交的SQL查询并跟踪事务状态的各个客户端会话。实际的存储引擎功能通过SQL::Transaction特征公开,表示为表、行和索引提供基本CRUD(创建、读取、更新、删除)操作的ACID事务:
pub trait Transaction: Catalog {
/// Commits the transaction.
fn commit(self) -> Result<()>;
/// Rolls back the transaction.
fn rollback(self) -> Result<()>;
/// Creates a new table row.
fn create(&mut self, table: &str, row: Row) -> Result<()>;
/// Deletes a table row.
fn delete(&mut self, table: &str, id: &Value) -> Result<()>;
/// Reads a table row, if it exists.
fn read(&self, table: &str, id: &Value) -> Result<Option<Row>>;
/// Scans a table's rows, optionally filtering by the given predicate expression.
fn scan(&self, table: &str, filter: Option<Expression>) -> Result<Scan>;
/// Updates a table row.
fn update(&mut self, table: &str, id: &Value, row: Row) -> Result<()>;
/// Reads an index entry, if it exists.
fn read_index(&self, table: &str, column: &str, value: &Value) -> Result<HashSet<Value>>;
/// Scans a column's index entries.
fn scan_index(&self, table: &str, column: &str) -> Result<IndexScan>;
}
主要的SQL存储引擎实现是SQL::Engine::KV,它构建在MVCC键/值存储及其事务功能之上。
RAFT SQL存储引擎SQL::Engine::RAFT使用RAFT API客户端raft::client向本地RAFT节点提交由枚举突变和查询指定的状态机命令。它还提供了RAFT状态机SQL::Engine::RAFT::State,用于包装常规SQL::Engine::KV SQL存储引擎并对其应用状态机命令。由于RAFT SQL引擎实现了SQL::Engine特性,因此它可以与本地存储引擎互换使用。
Storage tradeOffs
RAFT结果流:结果流不是针对RAFT命令实现的,因此RAFT SQL引擎必须在内存中缓冲整个结果集并将其序列化,然后再将其返回给客户端-这对于表扫描来说特别昂贵。在RAFT中实现流被认为超出了该项目的范围。
Parsing
SQL会话SQL::Session通过Execute()接受纯文本SQL查询并返回结果。此过程的第一步是将查询解析为表示查询语义的抽象语法树(AST)。此过程如下所示:
Sql→词法分析器→tokens→解析器→AST
词法分析器SQL::lexer获取一个SQL字符串,将其拆分成几个片段,并将它们分类为令牌SQL::Token。它不关心标记的含义,而是删除空格,并尝试找出某个东西是数字、字符串、关键字等等。它还执行一些基本的预处理,例如解释字符串引号、检查数字格式和拒绝未知关键字。
例如,即使查询无效,以下输入字符串也会生成列出的令牌:
3.14 +UPDATE 'abc'
→
Token::Number("3.14") Token::Plus Token::Keyword(Keyword::Update) Token::String("abc")
解析器SQL::Parser迭代由词法分析器生成的标记,解释它们,并构建表示语义查询的AST。例如,选择Name,2020-BirthYear作为AGE from People会产生以下AST:
解析器SQL::Parser迭代由词法分析器生成的标记,解释它们,并构建表示语义查询的AST。例如,SELECT name, 2020 - birthyear AS age FROM people会产生以下AST:
ast::Statement::Select{
select: vec![
(ast::Expression::Field(None, "name"), None),
(ast::Expression::Operation(
ast::Operation::Subtract(
ast::Expression::Literal(ast::Literal::Integer(2020)),
ast::Expression::Field(None, "birthyear"),
)
), Some("age")),
],
from: vec![
ast::FromItem::Table{name: "people", alias: None},
],
where: None,
group_by: vec![],
having: None,
order: vec![],
offset: None,
limit: None,
}
解析器将解释SQL语法,确定查询类型及其参数,并为任何无效语法返回错误。但是,它不知道表People是否实际存在,或者字段BirthYear是否为整数-这是规划者的工作。
值得注意的是,解析器还解析表达式,如1+2*3。由于优先规则,这不是平凡的,即应首先计算2*3,但如果(1+2)周围有括号,则不会。toyDB解析器为此使用优先级攀升算法。还要注意,AST表达式不同于SQL引擎表达式,不是一对一映射的。这在函数调用的情况下最为明显,解析器不知道(或不关心)给定函数是否存在,它只是将函数调用解析为任意的函数名和参数。规划者将把它转换成可以计算的实际表达式。
Planning
SQL计划器SQL::Planner获取解析器生成的AST并构建SQL执行计划SQL::Plan,它是执行查询所需步骤的抽象表示。例如,下面显示了一个简单的查询和相应的执行计划,格式为EXPLAIN输出:
SELECT id, title, rating * 100 FROM movies WHERE released > 2010 ORDER BY rating DESC;
Order: rating desc
└─ Projection: id, title, rating * 100
└─ Filter: released > 2010
└─ Scan: movies
查询执行计划中的计划节点SQL::Node表示一个关系代数运算符,其中一个节点的输出作为输入流向下一个节点。在上面的示例中,查询首先对Movies表进行全表扫描,然后对行应用过滤Release>2010,然后投影(格式化)结果并按评级排序。
大多数规划都相当简单,将AST节点转换为规划节点和表达式。
最棘手的部分是解析表名和列名,以得到跨多层别名、联接和投影层的列索引-这是通过SQL::Plan::Scope处理的,它跟踪正在构建的节点可见的名称,并将它们映射到列索引。
另一个挑战是聚合函数,它被实现为函数参数和分组/隐藏列的预投影,然后是聚合节点,最后是计算最终聚合表达式的后投影-如下例所示:
SELECT g.name AS genre, MAX(rating * 100) - MIN(rating * 100)
FROM movies m JOIN genres g ON m.genre_id = g.id
WHERE m.released > 2000
GROUP BY g.id, g.name
HAVING MIN(rating) > 7
ORDER BY g.id ASC;
Projection: #0, #1
└─ Order: g.id asc
└─ Filter: #2 > 7
└─ Projection: genre, #0 - #1, #2, g.id
└─ Aggregation: maximum, minimum, minimum
└─ Projection: rating * 100, rating * 100, rating, g.id, g.name
└─ Filter: m.released > 2000
└─ NestedLoopJoin: inner on m.genre_id = g.id
├─ Scan: movies as m
└─ Scan: genres as g
计划者生成一个非常天真的执行计划,主要关注的是生成一个正确但不一定快速的执行计划。这意味着它将始终执行全表扫描,始终使用嵌套循环联接,等等。然后,该计划由一系列实现SQL::Optimizer的优化器进行优化:
ConstantFolder:预先计算常量表达式,以避免必须为每行重新计算它们。
FilterPushdown:将过滤器更深入到查询中,以减少每个节点计算的行数,例如,通过将单表谓词一直推送到表扫描节点,以便过滤的节点不必穿过RAFT层。
IndexLookup:在可能的情况下将表扫描转换为主键或索引查找。
NoopCleaner:尝试移除noop操作,例如,求值为恒定true值的过滤节点。
JoinType:将嵌套循环连接转换为等式连接(相等连接谓词)的散列连接。
优化器大量使用布尔代数将表达式转换为更方便使用的形式。例如,部分过滤下推(例如跨联接节点)只能下推合取从句(即和部分),因此表达式首先转换为合取范式,以便每个部分都可以单独考虑。
下面是一个复杂的优化计划示例,其中表扫描已替换为键和索引查找,筛选器已下推到扫描节点,嵌套循环连接已替换为散列连接。它获取了自2000年以来发行任何评分在8分或更高的电影的制片厂发行的科幻电影的数据:
SELECT m.id, m.title, g.name AS genre, m.released, s.name AS studio
FROM movies m JOIN genres g ON m.genre_id = g.id,
studios s JOIN movies good ON good.studio_id = s.id AND good.rating >= 8
WHERE m.studio_id = s.id AND m.released >= 2000 AND g.id = 1
ORDER BY m.title ASC;
Order: m.title asc
└─ Projection: m.id, m.title, g.name, m.released, s.name
└─ HashJoin: inner on m.studio_id = s.id
├─ HashJoin: inner on m.genre_id = g.id
│ ├─ Filter: m.released > 2000 OR m.released = 2000
│ │ └─ IndexLookup: movies as m column genre_id (1)
│ └─ KeyLookup: genres as g (1)
└─ HashJoin: inner on s.id = good.studio_id
├─ Scan: studios as s
└─ Scan: movies as good (good.rating > 8 OR good.rating = 8)
Planning tradeOffs
类型检查:仅在计算时检测到表达式类型冲突,而不在规划期间检测到。
Execution
每个sql都由sql::Executortrait执行
pub trait Executor<T: Transaction> {
/// Executes the executor, consuming it and returning a result set
fn execute(self: Box<Self>, txn: &mut T) -> Result<ResultSet>;
}
为执行者提供一个SQL::Transaction来访问SQL存储引擎,并在查询结果中返回SQL::ResultSet。大多数情况下,结果的类型为SQL::Result::Set::Query,其中包含一个列列表和一个行迭代程序。大多数执行器包含用作输入的其他执行器,例如,过滤执行器通常将扫描执行器作为源:
pub struct Filter<T: Transaction> {
source: Box<dyn Executor<T>>,
predicate: Expression,
}
在SQL::Plan上调用Execute将构建并执行根节点的Executor,而后者将递归地调用其源Executor(如果有)并处理其结果。执行器通常使用rust的迭代器功能来增强源的返回行迭代器,例如,通过对其调用过滤()并返回新的迭代器。因此,整个执行引擎以流方式工作,并利用Rust的零成本迭代器抽象。
最后,将根ResultSet返回给客户端。
Server
toyDB服务器使用Tokio异步执行器管理RAFT和SQL引擎的网络流量。它在端口9605上为SQL客户端打开TCP侦听器,在端口9705上为RAFT对等体打开TCP侦听器,两者都使用通过Serde编码的Tokio流传递的长度前缀Bincode编码的消息作为协议。
RAFT服务器被分成raft::server,其运行在本地RAFT节点、状态机驱动程序、TCP对等体和本地状态机客户端(即RAFT SQL引擎包装器)之间路由RAFT消息的主事件循环,并且以规则的间隔对RAFT逻辑时钟进行滴答操作。它会产生单独的Tokio任务,这些任务维护与所有RAFT对等设备的出站TCP连接,而内部通信则通过MPSC通道进行。
SQL服务器为每个连接的SQL客户端生成一个新的Tokio任务,从RAFT上的SQL存储引擎运行单独的SQL会话。它通过传递SERVER::REQUEST和SERVER::RESPONSE消息与客户端通信,这些消息被转换为SQL::Session调用。
主toydb二进制文件根据命令行参数和配置文件简单地初始化toyDB服务器,然后通过Tokio运行时运行它。
server tradeOffs
安全性:所有网络流量都是未经身份验证的明文,因为安全性被认为超出了项目的范围。
Client
toyDB客户端提供了与服务器交互的简单API,主要是通过返回SQL::ResultSet的Execute()执行SQL语句。它还有方便的方法with_txn(),它接受一个闭包,该闭包执行一系列SQL语句,同时自动捕获并重试序列化错误。
还有Client::Pool,它管理一组预先连接的客户端,可以检索这些客户端以便在多线程应用程序中运行短期查询,而不会产生连接设置成本。
toysql命令行客户端是一个简单的REPL客户端,它使用toyDB客户端连接到服务器,不断提示用户执行SQL查询,并显示返回的结果。
Setup
- 启动
$ (cd clusters/local && ./run.sh)
toydb-e 15:08:51 [INFO] Listening on 0.0.0.0:9605 (SQL) and 0.0.0.0:9705 (Raft)
toydb-e 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9703: Connection refused (os error 111)
toydb-e 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9704: Connection refused (os error 111)
toydb-e 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9701: Connection refused (os error 111)
toydb-e 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9702: Connection refused (os error 111)
toydb-b 15:08:51 [INFO] Listening on 0.0.0.0:9602 (SQL) and 0.0.0.0:9702 (Raft)
toydb-b 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9703: Connection refused (os error 111)
toydb-b 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9704: Connection refused (os error 111)
toydb-b 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9701: Connection refused (os error 111)
toydb-d 15:08:51 [INFO] Listening on 0.0.0.0:9604 (SQL) and 0.0.0.0:9704 (Raft)
toydb-d 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9703: Connection refused (os error 111)
toydb-d 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9701: Connection refused (os error 111)
toydb-c 15:08:51 [INFO] Listening on 0.0.0.0:9603 (SQL) and 0.0.0.0:9703 (Raft)
toydb-c 15:08:51 [ERROR] Failed connecting to Raft peer 127.0.0.1:9701: Connection refused (os error 111)
toydb-a 15:08:51 [INFO] Listening on 0.0.0.0:9601 (SQL) and 0.0.0.0:9701 (Raft)
toydb-d 15:08:51 [INFO] Starting election for term 1
toydb-e 15:08:51 [INFO] Discovered new term 1, following leader toydb-d
toydb-b 15:08:51 [INFO] Discovered new term 1, following leader toydb-d
toydb-e 15:08:51 [INFO] Voting for toydb-d in term 1 election
toydb-b 15:08:51 [INFO] Voting for toydb-d in term 1 election
toydb-c 15:08:51 [INFO] Starting election for term 1
toydb-d 15:08:52 [INFO] Won election for term 1, becoming leader
toydb-a 15:08:52 [INFO] Discovered new term 1, following leader toydb-d
toydb-c 15:08:52 [INFO] Discovered leader toydb-d for term 1, following
toydb-a 15:08:52 [INFO] Voting for toydb-d in term 1 election
(base) root@k8s-master-133:/home/y/toydb/clusters/local# ss -lp | grep toydb
tcp LISTEN 0 128 *:9705 *:* users:(("toydb",pid=32507,fd=9))
tcp LISTEN 0 128 *:9601 *:* users:(("toydb",pid=32498,fd=8))
tcp LISTEN 0 128 *:9602 *:* users:(("toydb",pid=32502,fd=8))
tcp LISTEN 0 128 *:9603 *:* users:(("toydb",pid=32506,fd=8))
tcp LISTEN 0 128 *:9604 *:* users:(("toydb",pid=32505,fd=8))
tcp LISTEN 0 128 *:9701 *:* users:(("toydb",pid=32498,fd=9))
tcp LISTEN 0 128 *:9605 *:* users:(("toydb",pid=32507,fd=8))
tcp LISTEN 0 128 *:9702 *:* users:(("toydb",pid=32502,fd=9))
tcp LISTEN 0 128 *:9703 *:* users:(("toydb",pid=32506,fd=9))
tcp LISTEN 0 128 *:9704 *:* users:(("toydb",pid=32505,fd=9))
- 其中run.sh如下
#!/usr/bin/env bash
set -euo pipefail
cargo build --release --bin toydb
for ID in a b c d e; do
(cargo run -q --release -- -c toydb-$ID/toydb.yaml 2>&1 | sed -e "s/\\(.*\\)/toydb-$ID \\1/g") &
done
trap 'kill $(jobs -p)' EXIT
wait < <(jobs -p)
~
- 启动client, 在另一个shell中执行
(base) root@k8s-master-133:/home/y/toydb/clusters/local# cargo run --release --bin toysql
Compiling toydb v0.1.0 (/home/y/toydb)
Finished release [optimized] target(s) in 3.66s
Running `/home/y/toydb/target/release/toysql`
Connected to toyDB node "toydb-e". Enter !help for instructions.
toydb>
toydb> !status
Server: toydb-e (leader toydb-d in term 1 with 5 nodes)
Raft log: 1 committed, 0 applied, 0.000 MB (hybrid storage)
Node logs: toydb-a:1 toydb-b:1 toydb-c:1 toydb-d:1 toydb-e:1
SQL txns: 0 active, 0 total (memory storage)
按Ctrl-C组合键可关闭群集。数据保存在clusters/local/toydb-?/data/下,删除内容重新开始。
建表
作为后面示例的基础,我们将创建一个小型电影数据库。可以将以下SQL语句粘贴到toysql中:
CREATE TABLE genres (
id INTEGER PRIMARY KEY,
name STRING NOT NULL
);
INSERT INTO genres VALUES
(1, 'Science Fiction'),
(2, 'Action'),
(3, 'Drama'),
(4, 'Comedy');
CREATE TABLE studios (
id INTEGER PRIMARY KEY,
name STRING NOT NULL
);
INSERT INTO studios VALUES
(1, 'Mosfilm'),
(2, 'Lionsgate'),
(3, 'StudioCanal'),
(4, 'Warner Bros'),
(5, 'Focus Features');
CREATE TABLE movies (
id INTEGER PRIMARY KEY,
title STRING NOT NULL,
studio_id INTEGER NOT NULL INDEX REFERENCES studios,
genre_id INTEGER NOT NULL INDEX REFERENCES genres,
released INTEGER NOT NULL,
rating FLOAT
);
INSERT INTO movies VALUES
(1, 'Stalker', 1, 1, 1979, 8.2),
(2, 'Sicario', 2, 2, 2015, 7.6),
(3, 'Primer', 3, 1, 2004, 6.9),
(4, 'Heat', 4, 2, 1995, 8.2),
(5, 'The Fountain', 4, 1, 2006, 7.2),
(6, 'Solaris', 1, 1, 1972, 8.1),
(7, 'Gravity', 4, 1, 2013, 7.7),
(8, '21 Grams', 5, 3, 2003, 7.7),
(9, 'Birdman', 4, 4, 2014, 7.7),
(10, 'Inception', 4, 1, 2010, 8.8),
(11, 'Lost in Translation', 5, 4, 2003, 7.7),
(12, 'Eternal Sunshine of the Spotless Mind', 5, 3, 2004, 8.3);
toyDB支持一些基本数据类型,以及主键、外键和列索引。有关这些方面的详细信息,请参阅SQL参考。不支持ALTER TABLE等架构更改,仅支持CREATE TABLE和DROP TABLE
可以通过!tables和!table命令检查表格:
toydb> select * from movies;
1|Stalker|1|1|1979|8.2
2|Sicario|2|2|2015|7.6
3|Primer|3|1|2004|6.9
4|Heat|4|2|1995|8.2
5|The Fountain|4|1|2006|7.2
6|Solaris|1|1|1972|8.1
7|Gravity|4|1|2013|7.7
8|21 Grams|5|3|2003|7.7
9|Birdman|4|4|2014|7.7
10|Inception|4|1|2010|8.8
11|Lost in Translation|5|4|2003|7.7
12|Eternal Sunshine of the Spotless Mind|5|3|2004|8.3
toydb> !tables
genres
movies
studios
toydb> !table genres
CREATE TABLE genres (
id INTEGER PRIMARY KEY,
name STRING NOT NULL
)
约束和参照完整性
架构强制实施参照完整性和其他约束:
toydb> DROP TABLE studios;
Error: Table studios is referenced by table movies column studio_id
toydb> DELETE FROM studios WHERE id = 1;
Error: Primary key 1 is referenced by table movies column studio_id
toydb> UPDATE movies SET id = 1;
Error: Primary key 1 already exists for table movies
toydb> INSERT INTO movies VALUES (13, 'Nebraska', 6, 3, 2013, 7.7);
Error: Referenced primary key 6 in table studios does not exist
toydb> INSERT INTO movies VALUES (13, 'Nebraska', NULL, 3, 2013, 7.7);
Error: NULL value not allowed for column studio_id
toydb> INSERT INTO movies VALUES (13, 'Nebraska', 'Unknown', 3, 2013, 7.7);
Error: Invalid datatype STRING for INTEGER column studio_id
基本sql查询
toydb> SELECT * FROM studios;
1|Mosfilm
2|Lionsgate
3|StudioCanal
4|Warner Bros
5|Focus Features
toydb> SELECT title, rating FROM movies WHERE released >= 2000 ORDER BY rating DESC LIMIT 3;
Inception|8.8
Eternal Sunshine of the Spotless Mind|8.3
Gravity|7.7
- !headers on
toydb> !headers on
Headers enabled
toydb> SELECT id, name AS genre FROM genres;
id|genre
1|Science Fiction
2|Action
3|Drama
4|Comedy
表达式
toydb> SELECT 1 + 2 * 3;
7
toydb> SELECT (1 + 2) * 4 / -3;
-4
SELECT 3! + 7 % 4 - 2 ^ 3;
1
- 数字运算
toydb> SELECT 3.14 * 2.718;
8.53452
toydb> SELECT 1.0 / 0.0;
inf
toydb> SELECT 1e10 ^ 8;
100000000000000000000000000000000000000000000000000000000000000000000000000000000
toydb> SELECT 1e10 ^ 8 / INFINITY, 1e10 ^ 1e10, INFINITY / INFINITY;
0|inf|NaN
- bool运算
toydb> SELECT TRUE AND TRUE, TRUE AND FALSE, TRUE AND NULL, FALSE AND NULL;
TRUE|FALSE|NULL|FALSE
toydb> SELECT TRUE OR FALSE, FALSE OR FALSE, TRUE OR NULL, FALSE OR NULL;
TRUE|FALSE|TRUE|NULL
toydb> SELECT NOT TRUE, NOT FALSE, NOT NULL;
FALSE|TRUE|NULL
toydb> SELECT 3 > 1, 3 <= 1, 3 = 3.0;
TRUE|FALSE|TRUE
toydb> SELECT 'a' = 'A', 'foo' > 'bar', '' != '';
FALSE|TRUE|TRUE
toydb> SELECT INFINITY > -INFINITY, NULL = NULL;
TRUE|NULL
joins
没有连接,没有SQL数据库是完整的,toyDB支持大多数连接类型,如内部连接(隐式和显式):
toydb> SELECT m.id, m.title, g.name FROM movies m JOIN genres g ON m.genre_id = g.id LIMIT 4;
1|Stalker|Science Fiction
2|Sicario|Action
3|Primer|Science Fiction
4|Heat|Action
toydb> SELECT m.id, m.title, g.name FROM movies m, genres g WHERE m.genre_id = g.id LIMIT 4;
1|Stalker|Science Fiction
2|Sicario|Action
3|Primer|Science Fiction
4|Heat|Action
- outer join
toydb> SELECT s.id, s.name, g.name FROM studios s LEFT JOIN genres g ON s.id = g.id;
1|Mosfilm|Science Fiction
2|Lionsgate|Action
3|StudioCanal|Drama
4|Warner Bros|Comedy
5|Focus Features|NULL
toydb> SELECT g.id, g.name, s.name FROM genres g RIGHT JOIN studios s ON g.id = s.id;
1|Science Fiction|Mosfilm
2|Action|Lionsgate
3|Drama|StudioCanal
4|Comedy|Warner Bros
NULL|NULL|Focus Features
- cross join
toydb> SELECT g.name, s.name FROM genres g, studios s WHERE s.name < 'S';
Science Fiction|Mosfilm
Science Fiction|Lionsgate
Science Fiction|Focus Features
Action|Mosfilm
Action|Lionsgate
Action|Focus Features
Drama|Mosfilm
Drama|Lionsgate
Drama|Focus Features
Comedy|Mosfilm
Comedy|Lionsgate
Comedy|Focus Features
- 我们可以根据任意谓词进行连接,例如将名称排在电影名称之后的任何类型的电影连接起来:
toydb> SELECT m.title, g.name
FROM movies m JOIN genres g ON g.name > m.title
ORDER BY m.title, g.name;
21 Grams|Action
21 Grams|Comedy
21 Grams|Drama
21 Grams|Science Fiction
Birdman|Comedy
Birdman|Drama
Birdman|Science Fiction
Eternal Sunshine of the Spotless Mind|Science Fiction
Gravity|Science Fiction
Heat|Science Fiction
Inception|Science Fiction
Lost in Translation|Science Fiction
Primer|Science Fiction
- 我们可以连接多个表,甚至可以多次使用同一个表-就像下面这个例子一样,我们可以找到自2000年以来所有由发行了8级或更高评级的电影的制片厂发行的所有科幻电影:
toydb> SELECT m.id, m.title, g.name AS genre, m.released, s.name AS studio
FROM movies m JOIN genres g ON m.genre_id = g.id,
studios s JOIN movies good ON good.studio_id = s.id AND good.rating >= 8
WHERE m.studio_id = s.id AND m.released >= 2000 AND g.id = 1
ORDER BY m.title ASC;
7|Gravity|Science Fiction|2013|Warner Bros
10|Inception|Science Fiction|2010|Warner Bros
5|The Fountain|Science Fiction|2006|Warner Bros
explain
在优化具有多个联接的复杂查询时,通过EXPLAIN查询检查查询计划通常很有用:
toydb> EXPLAIN
SELECT m.id, m.title, g.name AS genre, m.released, s.name AS studio
FROM movies m JOIN genres g ON m.genre_id = g.id,
studios s JOIN movies good ON good.studio_id = s.id AND good.rating >= 8
WHERE m.studio_id = s.id AND m.released >= 2000 AND g.id = 1
ORDER BY m.title ASC;
Order: m.title asc
└─ Projection: m.id, m.title, g.name, m.released, s.name
└─ HashJoin: inner on m.studio_id = s.id
├─ HashJoin: inner on m.genre_id = g.id
│ ├─ Filter: m.released > 2000 OR m.released = 2000
│ │ └─ IndexLookup: movies as m column genre_id (1)
│ └─ KeyLookup: genres as g (1)
└─ HashJoin: inner on s.id = good.studio_id
├─ Scan: studios as s
└─ Scan: movies as good (good.rating > 8 OR good.rating = 8)
在这里,我们可以看到规划者在流派上执行主键查找,在movies.genre_id上执行索引查找,按发行年份过滤结果电影并加入它们。它还执行工作室和电影的全表扫描(以查找好电影),并加入它们,将评级>=8的过滤向下推送到电影表扫描。这两个连接的结果也会连接在一起,以生成最终结果,然后对其进行格式化和排序。
arrgrgates
toydb> SELECT COUNT(*), MIN(rating), MAX(rating), AVG(rating), SUM(rating) FROM movies;
12|6.9|8.8|7.841666666666668|94.10000000000001
- group by
toydb> SELECT s.id, s.name, AVG(m.rating) AS average
FROM movies m JOIN studios s ON m.studio_id = s.id
GROUP BY s.id, s.name
HAVING average > 7.8
ORDER BY average DESC, s.name ASC;
1|Mosfilm|8.149999999999999
4|Warner Bros|7.919999999999999
5|Focus Features|7.900000000000001
- 聚合函数的运算
toydb> SELECT s.id, s.name, ((MAX(rating^2) - MIN(rating^2)) / AVG(rating^2)) ^ (0.5) AS spread
FROM movies m JOIN studios s ON m.studio_id = s.id
GROUP BY s.id, s.name
HAVING MAX(rating) - MIN(rating) > 0.5
ORDER BY spread DESC;
4|Warner Bros|0.6373540990222496
5|Focus Features|0.39194971607693424
事务
toyDB通过基于MVCC的快照隔离支持ACID事务。这为原子事务提供了良好的隔离性,而无需取出锁或阻止写入时的读取。作为一个基本示例,以下事务回滚而不生效,而不是提交,这将使其成为永久事务:
toydb> BEGIN;
Began transaction 131
toydb:131> INSERT INTO genres VALUES (5, 'Western');
toydb:131> SELECT * FROM genres;
1|Science Fiction
2|Action
3|Drama
4|Comedy
5|Western
toydb:131> ROLLBACK;
Rolled back transaction 131
toydb> SELECT * FROM genres;
1|Science Fiction
2|Action
3|Drama
4|Comedy
我们将通过介绍给定两个并发会话的大多数常见事务异常来演示事务,并展示toyDB如何在除一种情况之外的所有情况下防止这些异常。在这些示例中,左半部分是用户A,右半部分是用户B。时间向下流动,使得同一行上的命令同时发生。
- 脏写:A未提交的写操作不应受并发B写操作的影响。
a> BEGIN;
a> INSERT INTO genres VALUES (5, 'Western');
b> INSERT INTO genres VALUES (5, 'Romance');
Error: Serialization failure, retry transaction
a> SELECT * FROM genres WHERE id = 5;
5|Western
此处发生序列化失败是因为第一次写入总是成功的。这可能不是最佳策略,但在防止序列化异常方面是正确的。
- 脏读:在提交之前,A未提交的写入应该对B不可见。
a> BEGIN;
a> INSERT INTO genres VALUES (5, 'Western');
b> SELECT * FROM genres WHERE id = 5;
No rows returned
a> COMMIT;
b> SELECT * FROM genres WHERE id = 5;
5|Western
- 丢失更新:当A和B都读取一个值时,在轮流更新之前,第一次写入不应被第二次写入覆盖。
a> BEGIN; b> BEGIN;
a> SELECT title, rating FROM movies WHERE id = 2; b> SELECT title, rating FROM movies WHERE id = 2;
Sicario|7.6 Sicario|7.6
a> UPDATE movies SET rating = 7.8 WHERE id = 2;
b> UPDATE movies SET rating = 7.7 WHERE id = 2;
Error: Serialization failure, retry transaction
a> COMMIT;
- 模糊读取:即使A提交了一个新值,B也不应该在其事务中看到值突然改变。
a> BEGIN; b> BEGIN;
b> SELECT * FROM genres WHERE id = 1;
1|Science Fiction
a> UPDATE genres SET name = 'Scifi' WHERE id = 1;
a> COMMIT;
b> SELECT * FROM genres WHERE id = 1;
1|Science Fiction
b> COMMIT;
b> SELECT * FROM genres WHERE id = 1;
1|Scifi
- 读偏差:如果A读取两个值,而B在两次读取之间修改了第二个值,则A应该会看到旧的第二个值。
a> BEGIN;
a> SELECT * FROM genres WHERE id = 2;
2|Action
b> BEGIN;
b> UPDATE genres SET name = 'Drama' WHERE id = 2;
b> UPDATE genres SET name = 'Action' WHERE id = 3;
b> COMMIT;
a> SELECT * FROM genres WHERE id = 3;
3|Drama
- Phantom Read:当A使用谓词运行查询,而B提交匹配的写操作时,A在重新运行它时应该看不到写操作。
a> BEGIN;
a> SELECT * FROM genres WHERE id > 2;
3|Drama
4|Comedy
b> INSERT INTO genres VALUES (5, 'Western');
a> SELECT * FROM genres WHERE id > 2;
3|Drama
4|Comedy
- 写偏差:当A读取行X并将其写入行Y时,B应该不能同时读取行Y并将其写入行X。
a> BEGIN; b> BEGIN;
a> SELECT * FROM genres WHERE id = 2;
2|Action
b> SELECT * FROM genres WHERE id = 3;
3|Drama
b> UPDATE genres SET name = 'Drama' WHERE id = 2;
a> UPDATE genres SET name = 'Action' WHERE id = 3;
a> COMMIT; b> COMMIT;
在这里,写入实际上是通过。快照隔离不能防止这种异常,因此toyDB也不能防止这种异常-这样做需要实现可序列化的快照隔离。但是,这是toyDB没有处理的唯一常见的序列化异常,并且不是最严重的。
- Time-Traver 查询
由于toyDB使用MVCC进行事务并保存所有历史版本,因此可以在过去的任何时间点查询数据库的状态。ToyDB使用增量事务ID作为逻辑时间戳:
toydb> SELECT * FROM genres;
1|Science Fiction
2|Drama
3|Action
4|Comedy
toydb> BEGIN;
Began transaction 173
toydb:173> UPDATE genres SET name = 'Scifi' WHERE id = 1;
toydb:173> INSERT INTO genres VALUES (5, 'Western');
toydb:173> COMMIT;
Committed transaction 173
toydb> SELECT * FROM genres;
1|Scifi
2|Drama
3|Action
4|Comedy
5|Western
toydb> BEGIN READ ONLY AS OF SYSTEM TIME 172;
Began read-only transaction 175 in snapshot at version 172
toydb@172> SELECT * FROM genres;
1|Science Fiction
2|Drama
3|Action
4|Comedy