集合知识点总结02
6、list体系结构:
|--ArrayList:低层数据结构是数组,不同步,有别于vector,替代了它,也是可 延长数组,百分之五十,提升了空间的效率。查询很快,增删很慢。
|--LinkedList:低层数据结构是链表数据结构,查询速度慢,增删比较快,元素也 是有角标的,以为内其父类list都有角标。
|--Vector:低层数据结构是数组结构,超过长度就会创建一个新数组,长度为前数组 的一倍,对其进行重新赋值。同步 安全但是效率低。
|--特有方法:
Enumeration:枚举:支持枚举接口,但是该接口因为名称过长,被Iterator取代。
实现代码:
Public stati void main(String[] arsg)
{
Vector v=new Vector();
v.addElement("abc1");
v.addElement("abc2");
v.addElement("abc3");
v.addElement("abc4");
Enumeration en=v.elements();
While(en.hasNext())
{
Sop(en.nextElement());
}
}
注意:此接口和iteration接口的功能是重复的。
Arrrylist和linkedlist的内存分析比较:

总结:当增删操作较多时用linkedlist。当查询较多的时候用ArrayList,自有增删有查询的还是Arraylist,因为后面还是查询的使用较多。
1、LinkedList:
特有方法:
1、增加:addFirst()
addLast()
JDk1.6之后出现了替代方法
Boolean offerFirst()
Boolean offerLast()
实现代码:
Public static void main(String[] args){
LinkedLis link=new LinkedList();
Link.addFirst("abc1");
Link.addFirst("abc2");
Link.addFirst("abc3");
Link.addFirst("abc4");
While(!link.isEmpty()){//此方法可以按照顺序取出元素,但是被删除,可以去模拟一些简单的数据结构
Sop(link.removeLast());//abc1、abc2、abc3、abc4
}
}
重点:模拟堆栈、队列这两种常见的数据结构;
实现代码:队列:先进先出
Public static void main(String[] args){
DuiLie d=new DuiLie();
d.myAdd("abc1");
d.myAdd("abc2");
d.myAdd("abc3");
While(!d.isNull()){//判断是否有元素
Sop(d.myGet());
}
}
Class DuiLie
{
Private LinkedList link;
DuiLie(){
Link=new LinkedList();
}
提供添加元素的方法
Public void myAdd(Object obj)
{
link.addFirst(obj);//这里修改为link.addLast()就是堆栈
}
提供获取元素的方法
Public Object myGet(){
Return link.removeLast();
}
判断集合中是否有内容
Public boolean isNull(){
Return link.isEmpty();
}
}
2、获取:Object getFirst()获取对象,不删除,如果集合中没有元素会抛出NoSuchElementException;
Object getLast();
JDK1.6后
Object peekFirst()
Object peeklast()
3、获取对象:
Object removeFirst()获取到元素,但是删除了。
Object removeLast();
Object pollFirst()
Object pollLasr()
2、Set集合:无序、不重复、该接口中的方法和Collection接口中的方法一致。
|--HashSet:低层哈希表数据结构,不同步的,它保证元素唯一性的方式:
根据元素的两个方法来完成的,一个是hashCode、一个equals。只有当hashCode方法算出的哈希值相同时,会再次判断两个元素的equals方法是否为ture;
如果是true说明两个元素相同,不存储,所以往hashSet集合中存储自定义对象时,要覆盖hashCode、equals方法,通过自定义独享具备的特有数据来定义hashCode、equals的具体实现。
哈希结构表分析:
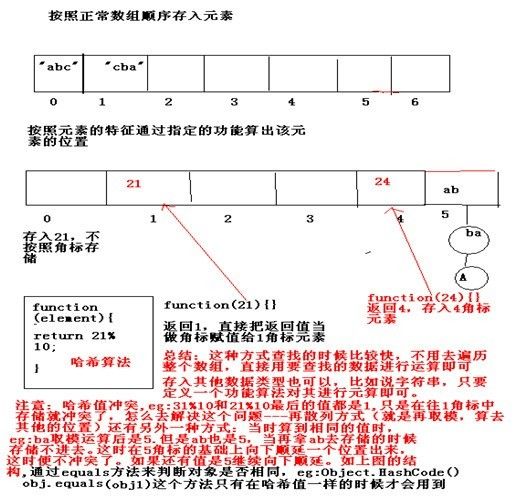
Hash表和数组表的比较,哈希表数据结构是按照元素的特征通过指定的功能算出该元素的位置,这种方式查找时候比较快,不 用去遍历整个数组,直接用要查找的数据进行元素即可,存入其他的数据类型也可以,比如说字符串,只要定义一个功能算法对其进行运算即可,
注意:哈希值冲突,比如31%10和21%10最后的值都是1,只是往1角标中存储就冲突了,怎么去解决这个问题呢?哈希表有种特殊的方式:再散列方式(就是再把这个数据进行取模,算出其他的位置),除此之外还有另外一种方式:当算到相同的值时,就在该冲突的位置的基础上向下顺延一个位置出来,这时候便不再冲突了,如过还有值冲突就继续向下顺延,上图结构通过equals方法来判断对象是否想用,这个方法只有在哈希值一样的时候才会用到。
实现代码:
需求:存储自定义对象,比如Person,同姓名和同年龄视为同一个人,是相同元素。
hashSet hs=new hashSet();
Hs..add(new Person("lisi1",20));
Hs..add(newPerson("zhangsan",20));
Hs..add(new Person("wangwu",20));
Hs..add(new Person("sunba",20));
Hs..add(newPerson("zhangsan",20));
取出来
Iterator it=hs.iterator();
While(it.hasNext())
{
Person p=(Person)it.next();
Sop(p.getName()+p.getAge());
}
Class Person()
{
Private String name;
Private int age;
Person(String name,int age)
{
This.name=name;
This.age=age;
}
Public void setName(String name){
This.name=name;
}
Public void getName()
{
Return name;
}
Public void setAge(){
This.age=age;
}
Public int getAge()
{
Return age;
}
Public String toString(){
Return"Person:"+name+"::"+age;
}
定义一个比较方式,按照年龄进行自然排序
Public int compareTo(Object o){
Person p=(Person)o;
Int temp=this.age-p.age;
Returntemp==0?this.name.compareTo(p.name):temp;
/**按照姓名进行自然排序
Int temp=this.name.compareTo(p.name){
Return temp=-0?this,.age-p.age:temp;
}
*/
}
覆盖hashCode()方法
Public int hashCode(){
Final int NUMBER=28;//为什么要定义常量,是因为避免哈希值冲突的情况,比如说一个姓名取哈希值为20,年龄取哈希值为40.另外一个人的姓名取哈希值为40年龄哈希值为20;两个的和都是60,用它进行哈希运算,可能得到的值都是相同的,这样的话再哈希结构表中的数据存储都是冲突的。所以才定义这样一个常量类避免这种冲突。
Return name.hashCode()+age*NUMBER;
}
覆写equals方法其实就是建立对象自身特有的判断对象是否相同的依据。
Public boolean equals(Object o){
If(!(Obj instanceof Person))
Throw new ClassCastException("数据错误"):
Person p=(Person)obj;
Returnthis.name.equals(p,.name)&&this.age==p.age;
}
}
|--TreeSet:用于给Set集合中的元素按照指定的顺序进行排序,低层是二叉树数据结构,线程是不同步的。
如何保证元素的唯一性呢?就是用过元素对象的比较方法返回值来确定的,如果为0,视为两个元素为相同的元素,不存储。
两种排序方式:
1、让元素自身具备比较功能,就是强制让元素去实现comparable接口,覆盖compareTo方法。这时元素具备的自然排序。可是如果元素自身不具备比较的功能,获取具备的比较功能不是所需要的。这时该排序方式就不能用了。
2、让集合自身具备比较功能,需要定义比较器,其实就是将实现了Comparator接口的子类对象作为参数传递给TreeSet集合的构造函数,让treeSet集合一创建就具备了比较功能。该子类必须要覆盖compare方法。
二叉树数据结构分析:
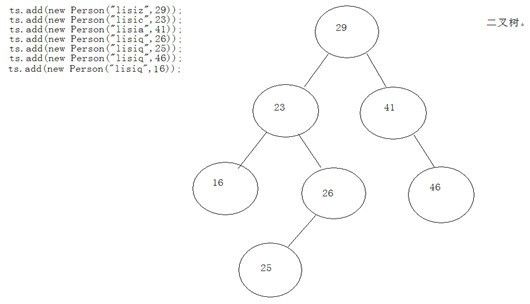
二叉树数据结构的特点,当第一个元素存入时,后面存入的数据都要跟它进行比较,如果小则存储在这个元素的左边的位置,如果大就存储在这个元素的右边的位置,依次下去,它在对元素进行遍历的时候,不是从上到下,而是跟你要遍历的元素与它进行比较。
实现代码:
TreeSet ts=new TreeSet(newComparatorByName());
Ts.add(new Person("lisia",29));
Ts.add(new Person("lisic",30));
Ts.add(new Person("lisiz",21));
Ts.add(new Person("lisi11",41));
Iterator it=ts.iterator();
While(it.hasNext()){
Person p=(Person)it.next();
Sop(p.getName()+p.getAge());
}
当元素自身没有比较功能的时候要定义实现Comparator接口的方法,让对象具备有比较功能,这时候要覆盖comparator接口的compare方法
实现代码:
Class ComparatorByName implementsComparator{
Public int compare(Object o1,Object O2){
Person p1=(Person)o1;
Person p2=(Person)o2;
Inttemp=p1.getName().compareTo(p2.getName());
Returntemp==0?p1.getAge()-p2.getAge():temp;
}
}
3、查阅集合的技巧
List
|--Vector
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
在JDk1.2集合框架出现后,名称的阅读性非常强,通过名称就可以识别。明确所属的子体系,只要看后罪名,到底具体这个集合是什么结构,有什么特点,只要看前缀即可。
看到Array:数组结构,就要想到角标,有序,可重复,查询快
看到link:链表结构,想到增删快,同时可以明确操作first last的方法、
看到hash:哈希表结构,就要想到无序,不可以重复,必须要想到元素依靠的hashCode和equals方法来保证唯一性。
看到Tree:二叉树,就要想到比较的功能和排序,必须要想到两个接口,Comparable--compareTo Comparator---compare
集合中常用的集合对象都是不同步的。
4、泛型:
1、由来:
在jdk1.4版本之前,定义容器可以存储任意类型的对象,但是取出时,如果使用了具体元素的方法,需要向下转型的动作,因为元素类型的不一致,会导致运行时类型转换异常。
原因是:在定义集合时,并没有明确集合中的元素的具体类型,借鉴数组的定义方式就可以避免这个问题。
在JDk1.5版本以后出现了一个解决机制,忽悠事故在定义容器时,直接明确容器中的元素的类型,这既是泛型的表现,用<>格式来使用。
其实泛型就是使用到了带有<.>的类和接口时,传递需要操作的对象类型就可,其实就是传递类型参数。
2、什么时候写泛型?
最简单的而一种体现,只要使用了带有<>的类和接口,就指定具体对象类型、
3、泛型的好处:
1、将运行时出现的类型转换异常问题在编译时期给解决了,运行就安全了.
2、避免了强制转换的麻烦.
所以泛型就是JDK1,5后出现一个安全机制。
泛型擦除:
泛型是编译时期的安全机制,编译时通过泛型机制,编译器多了对元素类型进行检查的步骤,如果检查通过,差生的class文件是不带有泛型的。
泛型补偿:
在对元素存储的时候,可以完成类型的判断,怎么用指定的类型来接收呢?JVM在运行时,会获取元素的类型,并用该类型对元素进行转换即可。