LLM 大规模语言模型综述
来源:中国人民大学 人工智能学院和信息学院
github地址:RUCAIBox/LLMSurvey
论文:A Survey of Large Language Models
时间:2023年3月31日
一、摘要
语言本质上是一个复杂、错综复杂的人类表达系统,受语法规则支配。开发用于理解和掌握语言的有能力的 AI 算法是一项重大挑战。作为一种主要方法,语言建模在过去二十年中被广泛研究用于语言理解和生成,从统计语言模型发展到神经语言模型。
近年来,LLMs的研究得到了学术界和产业界的大力推进,其中一个引人注目的进展是ChatGPT的推出,引起了社会的广泛关注。 LLM 的技术发展对整个 AI 社区产生了重要影响,这将彻底改变我们开发和使用 AI 算法的方式。
在本次调查中,我们通过介绍背景、主要发现和主流技术来回顾 LLM 的最新进展。特别是,我们关注 LLM 的四个主要方面,即预训练、自适应调优、下游使用和能力评估。此外,我们还总结了开发 LLM 的可用资源,并讨论了未来方向的剩余问题。
二、介绍
从NLP的历史开始介绍,SLM,n-gram,rnn,lstm,PLM(Elmo,BERT,GPT,BART),再到PaLM,Chat GPT,GPT4
然后注重介绍了ChatGPT 和 GPT4 卓越能力和表现效果,最后介绍了自己github地址用来收集LLM相关资源。
三、LLM资源
LLM 的资源 考虑到具有挑战性的技术问题和巨大的计算资源需求,开发或复制LLM 绝非易事。一种可行的方法是从现有的 LLM 中学习经验,并重用公开可用的资源进行增量开发或实验研究。
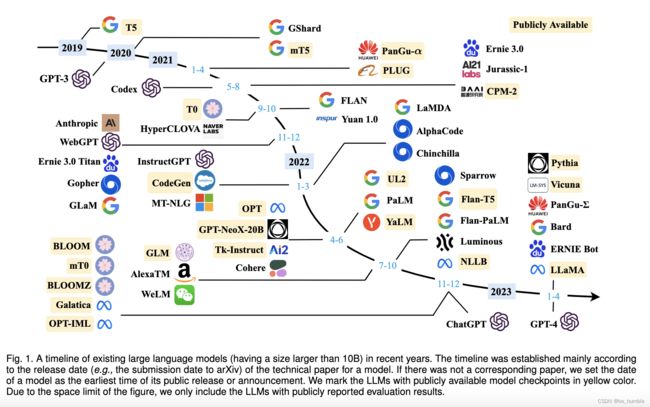
3.1 一些可用checkpoint
- LLaMA 65B
- NLLB 54.5B
- mT5
- PanGu-α (200B)
- T0
- GPT-NeoX-20B
- CodeGen
- UL2
- Flan-T5
- mT0
- OPT
- OPT-IML
- BLOOM
- BLOOMZ
- GPT-3
3.2 常用语料库
在本节中,我们将简要总结几种广泛用于训练 LLM 的语料库。根据它们的内容类型,我们将这些语料库分为六组:书籍、CommonCrawl、Reddit 链接、维基百科、代码等。图书。
- 书籍:BookCorpus 是以前小规模模型(例如 GPT 和 GPT-2 )中常用的数据集,由超过 11,000 本书组成,涵盖广泛的主题和类型(例如,小说和传记) ).另一个大型图书语料库是 Project Gutenberg ,包括 70,000 多本文学书籍,包括小说、散文、诗歌、戏剧、历史、科学、哲学和公共领域的其他类型的作品。它是目前最大的开源书籍集合之一,用于训练 MT-NLG 和 LLaMA。
- CommonCrawl 是最大的开源网络爬虫数据库之一,包含一个 PB 级的 7 表 2 常用数据源的统计数据。由于整个数据集非常庞大,现有研究主要从中提取特定时期内的网页子集。然而,由于网络数据中普遍存在噪声和低质量信息,因此在使用前需要进行数据预处理。基于 CommonCrawl,现有工作中常用的过滤数据集有四种:C4 、CC-Stories 、CC-News 和 RealNews 。
- Reddit 是一个社交媒体平台,允许用户提交链接和文本帖子,其他人可以通过“赞成票”或“反对票”对其进行投票。高票数的帖子通常被认为是有用的,可以用来创建高质量的数据集。 WebText 是一个著名的语料库,由来自 Reddit 的高度赞扬的链接组成,但它不是公开的。作为替代品,有一个易于访问的开源替代方案,称为 OpenWebText 。
- 维基百科。维基百科 是一个在线百科全书,包含大量关于不同主题的高质量文章。这些文章中的大多数都是以说明文的写作风格(带有支持性参考文献)撰写的,涵盖了广泛的语言和领域。
- 代码。为了收集代码数据,现有工作主要是从互联网上抓取开源许可代码。两个主要来源是开源许可下的公共代码存储库(例如 GitHub)和与代码相关的问答平台(例如 StackOverflow)。谷歌公开发布了 BigQuery 数据集 ,其中包括大量各种编程语言的开源许可代码片段,作为代表性代码数据集。 CodeGen 利用 BIGQUERY(BigQuery 数据集的一个子集)来训练 CodeGen 的多语言版本(CodeGen-Multi)。
- 其他。 Pile 是一个大规模、多样化和开源的文本数据集,由来自多个来源的超过 800GB 的数据组成,包括书籍、网站、代码、科学论文和社交媒体平台。它由 22 个不同的高质量子集构成。
3.2 开发LLM常用库
在这一部分中,我们简要介绍了一系列用于开发 LLM 的可用库。
- Transformers 是一个开源Python 库,用于使用Transformer 架构构建模型,由Hugging Face 开发和维护。它具有简单且用户友好的 API,可以轻松使用 8 和自定义各种预训练模型。它是一个功能强大的库,拥有庞大而活跃的用户和开发人员社区,他们会定期更新和改进模型和算法。
- DeepSpeed是微软开发的深度学习优化库(与 PyTorch 兼容),已用于训练许多 LLM,例如 MT-NLG 和 BLOOM 。它为分布式训练提供了各种优化技术的支持,例如内存优化(ZeRO 技术、梯度检查点)和流水线并行性。
- Megatron-LM 是NVIDIA 开发的用于训练大规模语言模型的深度学习库。它还为分布式训练提供了丰富的优化技术,包括模型和数据并行、混合精度训练和FlashAttention。这些优化技术可以大大提高训练效率和速度,从而实现跨 GPU 的高效分布式训练。
- JAX是谷歌开发的用于高性能机器学习算法的 Python 库,允许用户使用硬件加速(例如 GPU 或 TPU)轻松地对数组执行计算。它可以在各种设备上进行高效计算,还支持自动微分和即时编译等多种特色功能。
- Colossal-AI 是由HPC-AI Tech 开发的用于训练大规模AI 模型的深度学习库。它基于 PyTorch 实现,支持丰富的并行训练策略。
- BMTrain 是OpenBMB 开发的一个高效库,用于以分布式方式训练具有大规模参数的模型,强调代码简单、低资源和高可用性。 BMTrain 已经将几个常见的 LLM(例如,Flan-T5 和 GLM )合并到其模型中心,开发人员可以在其中直接使用这些模型。
- FastMoE 是一个专门用于 MoE(即专家混合)模型的训练库。它基于 PyTorch 开发,在设计上优先考虑效率和用户友好性。 FastMoE 简化了 Transformer 模型到 MoE 模型的迁移过程,同时支持训练时的数据并行和模型并行。
四、LLM预训练
预训练语料库的规模和质量对于 LLM 获得强大的能力至关重要。此外,为了有效地预训练 LLM,需要精心设计模型架构、加速方法和优化技术。首先在 4.1 节讨论数据收集和处理,然后在 4.2 节介绍常用的模型架构,最后在 4.3 节介绍稳定高效地优化 LLM 的训练技术。
4.1 数据预处理
在收集了大量文本数据后,必须对数据进行预处理以构建预训练语料库,尤其是去除噪声、冗余、不相关和潜在有毒数据,这可能会在很大程度上影响容量和 LLM 的表现。
在这一部分中,我们回顾了详细的数据预处理策略,以提高所收集数据的质量。现有工作通常采用两种方法:
(1)基于分类器
基于高质量文本训练选择分类器,并利用它来识别和过滤掉低质量数据。通常,这些方法 使用精心策划的数据(例如维基百科页面)作为正例训练二元分类器,并将候选数据样本作为负例,并预测衡量每个数据质量的分数例子。然而,一些研究 也发现,基于分类器的方法可能会无意中删除方言、口语和社会语言中的高质量文本,这可能会导致预训练语料库出现偏差并降低了语料库的多样性。
(2)基于启发式。
采用基于启发式的方法通过一组精心设计的规则来消除低质量文本,这些规则可以总结如下:
- 基于语言过滤。如果 LLM 主要用于某些语言的任务,则可以过滤其他语言的文本。
- 基于指标的过滤。关于生成的文本的评估指标,例如困惑度,可用于检测和删除不自然的句子。
- 基于统计的过滤。语料库的统计特征,例如标点符号分布、符号词比和句子长度,可以用来衡量文本质量并过滤低质量数据。
- 基于关键字的过滤。基于特定的关键字集,可以识别并删除文本中的嘈杂或无用元素,例如 HTML 标记、超链接、样板和攻击性词语。
- 重复数据删除。现有工作发现语料库中的重复数据会降低语言模型的多样性,这可能导致训练过程变得不稳定,从而影响模型性能。因此,有必要对预训练语料库进行去重。
- 隐私修订。大多数预训练文本数据是从网络资源中获得的,包括涉及敏感或个人信息的用户生成的内容,这可能会增加隐私泄露的风险。因此,有必要从预训练语料库中删除个人身份信息(PII)。一种直接有效的方法是采用基于规则的方法(例如关键字识别)来检测和删除 PII,例如姓名、地址和电话号码 。
4.2 预训练架构

4.3 模型训练
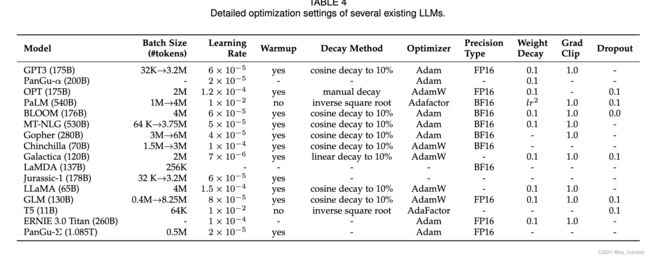
-
batch_size
批量训练。对于语言模型预训练,现有工作通常将批量大小设置为较大的数字(例如,8,196 个示例或 1.6M 令牌)以提高训练稳定性和吞吐量。对于 GPT-3 和 PaLM 等 LLM,他们引入了一种新策略,可以在训练期间动态增加批量大小,最终达到百万规模。具体来说,GPT-3 的 batch size 从 32K tokens 逐渐增加到 3.2M tokens。实证结果表明,批量大小的动态调度可以有效地稳定 LLM 的训练过程 。
-
learning_rate
现有的 LLM 通常在预训练期间采用类似的学习率计划以及预热和衰减策略。具体来说,在最初的 0.1% 到 0.5% 的训练步骤中,采用线性预热计划逐渐将学习率增加到最大值,范围从大约 5 × 10-5 到 1 × 10-4(例如, GPT-3 为 6 × 10−5)。然后,在后续步骤中采用余弦衰减策略,逐渐将学习率降低到其最大值的10%左右,直到训练损失收敛.
-
optimizer
Adam 优化器 和 AdamW 优化器 被广泛用于训练 LLM(例如 GPT-3),它们基于对低阶矩的自适应估计以进行一阶基于梯度的优化。通常,其超参数设置如下:β1 = 0.9,β2 = 0.95 和 = 10−8。同时,Adafactor 优化器也被用于训练 LLM(例如 PaLM 和 T5),这是 Adam 优化器的变体,专门为在训练期间节省 GPU 内存而设计。 Adafactor 优化器的超参数设置为:β1 = 0.9 和 β2 = 1.0 − k−0.8,其中 k 表示训练步数
-
Stabilizing the Training
在LLMs的预训练过程中,经常会遇到训练不稳定的问题,这可能会导致模型崩溃。为了解决这个问题,权重衰减和梯度裁剪被广泛使用,现有研究通常将梯度裁剪的阈值设置为1.0,权重衰减率设置为0.1。然而,随着 LLM 的缩放,训练损失尖峰也更有可能发生,从而导致训练不稳定。为了缓解这个问题,PaLM和 OPT使用一种简单的策略,即在尖峰出现之前从较早的检查点重新启动训练过程,并跳过可能导致问题的数据。此外,GLM发现嵌入层的异常梯度通常会导致尖峰,并提出收缩嵌入层梯度来缓解它
五、LLM自适应调整
经过预训练,LLM 可以获得解决各种任务的通用能力。然而,越来越多的研究表明,法学硕士的能力可以根据具体目标进一步调整。在本节中,我们介绍两种主要的方法来调整预训练的 LLM,即指令调优和对齐调优。
5.1 instruction tuning
指令微调,指令调优后,LLM 可以按照任务描述 很好地泛化到其他未见过的任务。特别是,已经表明指令是 LLM 任务泛化能力的关键因素。通过在标记数据集上微调模型并删除任务描述,它会导致模型性能急剧下降。为了更好地生成用于指令调整的标记实例,一个众包平台 PromptSource被提出来有效地创建、共享和验证不同数据集的任务描述。
5.2 alignment tuning
RLHF
为了使 LLM 与人类价值观保持一致,人们提出了从人类反馈中强化学习 (RLHF) 以使用收集到的人类反馈数据对 LLM 进行微调,这有助于改进对齐标准。 RLHF 采用强化学习 (RL) 算法通过学习奖励模型使 LLM 适应人类反馈。这种方法将人类纳入训练循环中以开发对齐良好的 LLM。
RLHF 系统。 RLHF 系统主要包括三个关键组件:一个预训练的 LM 要对齐,一个从人类反馈中学习的奖励模型,以及一个 RL 算法。

六、总结
在本次调查中,我们回顾了大型语言模型 (LLM) 的最新进展,并介绍了理解和利用 LLM 的关键概念、发现和技术。我们专注于大型模型(即尺寸大于 10B),而排除了现有文献中已充分涵盖的早期预训练语言模型(例如 BERT 和 GPT-2)的内容。
要了解 LLM 的底层工作机制,最大的谜团之一就是信息如何通过非常大的深度神经网络进行分发、组织和利用。重要的是要揭示建立 LLM 能力基础的基本原则或要素。特别是,当语言模型的参数规模增加到临界大小(例如 10B)时,一些紧急能力会以意想不到的方式发生,通常在 包括情境学习、指令遵循和逐步推理。这些新兴能力令人着迷但又令人费解。