Redis 面试常问问题
Redis 系列笔记:
第一篇:Redis 基础命令
第二篇:Redis 常见应用场景
第三篇:Redis Cluster集群搭建
第四篇:Redis 主从及哨兵搭建
第五篇:Redis 主从及集群
第六篇:Redis 持久化
第七篇:Redis 分布式锁
第八篇:Redis 底层数据存储结构
第九篇:Redis 面试常问问题
文章目录
- Redis 系列笔记:
- 前言
- 一、单线程的Redis为什么那么快
-
- 1、Redis为什么是单线程
- 2、Redis为什么那么快
- 1、多路I/O复用模型
- 2、VM(虚拟内存)机制
- 二、Redis 缓存问题及预防措施
-
- 1、缓存穿透
- 2、缓存击穿
- 3、缓存雪崩
- 4、预防措施
-
- 1、缓存预热
- 2、熔断
- 3、降级
- 4、限流
- 三、Redis与数据库的数据一致性问题
-
- 1、先删除缓存、再更新数据库
- 2、先更新数据库、再删除缓存(推荐)
- 3、主从一致性
- 4、删除失败怎么办
- 四、分布式锁
- 五、Redis持久化机制
- 六、秒杀场景
- 七、Redis和Memcahe对比
- 八、Redis的过期策略及淘汰机制
-
- 1、过期策略
- 2、淘汰机制
- 3、其他场景过期key的操作
- 九、Redis常见性能问题及解决方案
- 总结
前言
本篇文章简单总结一下 Redis 的常见问题及解决办法。
提示:以下是本篇文章正文内容,下面案例可供参考
一、单线程的Redis为什么那么快
1、Redis为什么是单线程
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽,既然单线程容易实现,且避免了线程切换和资源竞争带来的开销,而CPU又不会成为瓶颈,那就顺理成章地采用单线程的方案了。
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。

横轴是连接数,纵轴是QPS。
2、Redis为什么那么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了
VM(虚拟内存)机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
1、多路I/O复用模型
为什么 Redis 中要使用 I/O 多路复用这种技术呢?因为 Redis 是跑在「单线程」中的,所有的操作都是按照顺序线性执行的,但是「由于读写操作等待用户输入 或 输出都是阻塞的」,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导,致整个进程无法对其它客户提供服务。而 I/O 多路复用就是为了解决这个问题而出现的。「为了让单线程(进程)的服务端应用同时处理多个客户端的事件,Redis 采用了 IO 多路复用机制。」
多路:指的是多个网络连接客户端。
复用:指的是复用同一个线程(单进程)。
I/O 多路复用其实是使用一个线程来检查多个 Socket 的就绪状态,在单个线程中通过记录跟踪每一个 socket(I/O流)的状态来管理处理多个 I/O 流。如下图是 Redis 的 I/O 多路复用模型:

1、Redis 的 I/O 多路复用程序函数有 select、poll、epoll、kqueue。select 作为备选方案,由于其在使用时会扫描全部监听的文件描述符,并且只能同时服务 1024 个文件描述符,所以是备选方案。
- 以 Redis 的 I/O 多路复用程序 epoll 函数为例:
多个客户端连接服务端时,Redis 会将客户端 socket 对应的 fd 注册进 epoll,然后 epoll 同时监听多个文件描述符(FD)是否有数据到来,如果有数据来了就通知事件处理器赶紧处理,这样就不会存在服务端一直等待某个客户端给数据的情形。2、 I/O 多路复用模型是利用 select、poll、epoll 函数可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉。当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),依次顺序的处理就绪的流,这种做法就避免了大量无用的等待操作。
参考:说说Redis之I/O多路复用模型实现原理
2、VM(虚拟内存)机制
Redis的 VM(虚拟内存)机制 就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis提高数据库容量的办法有两种:一种是可以将数据分割到多个Redis Server上;另一种是使用虚拟内存把那些不经常访问的数据交换到磁盘上。需要特别注意的是Redis并没有使用OS提供的Swap,而是自己实现。
Redis为了保证查找的速度,只会将value交换出去,而在内存中保留所有的Key。所以它非常适合Key很小,Value很大的存储结构。如果Key很大,value很小,那么vm可能还是无法满足需求。
通过在redis的redis.conf文件里,设置VM的相关参数来实现数据在内存和磁盘之间 换入和 换出操作。
二、Redis 缓存问题及预防措施
1、缓存穿透
问题: 当有大量查询请求未命中redis缓存时,引起对后台数据库的频繁访问,导致数据库负载压力增大。
解决方案 :
- 1、布隆过滤器:使用布隆过滤器,过滤掉一些不存在的key。布隆过滤器判定为true时,key可能存在于数据库中,也可能不存在;判定为false时,key一定不存在于数据库。
- 2、缓存空对象:如果该key在redis和数据库中都没有,那么在redis中设置该key值为NULL,再设置一个有效期。
2、缓存击穿
问题: 指大量请求并发访问的key-value数据,而在这个时候缓存key突然失效了,缓存未命中引起对后台数据库的频繁访问,导致数据库负载压力增大。
解决方案:
- 1、设置缓存永远不过期。
- 2、加互斥锁,使用分布式锁,保证每个key只有一个线程去查询后端服务,而其他线程为等待状态。这种模式将压力转到了分布式锁上。
3、缓存雪崩
问题: 当某⼀时刻发⽣⼤规模的缓存失效的情况,例如缓存服务宕机、大量key在同一时间过期,如:缓存集体过期、redis宕机
解决方案:
- 1、 给key的失效时间设置为随机时间,避免集体过期或者永不过期;
- 2、搭建集群;
- 3、加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
- 4、当访问次数急剧增加导致服务出现问题时,我们如何确保服务仍然可用。在国内使用比较多的是 Hystrix,它通过熔断、降级、限流三个手段来降低雪崩发生后的损失。
- 5、Redis备份和快速预热:Redis数据备份和恢复、快速缓存预热。
缓存穿透: 并发时请求不存在的数据。
缓存击穿: 并发请求时单个缓存过期。
缓存雪崩: 大量的缓存同一时刻过期。
4、预防措施
1、缓存预热
缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统中,避免刚上线使用户有太多请求打到数据库上去,然后再去将数据缓存的问题。
1、直接写个缓存刷新页面.上线时手工操作下;
2、数据且不大.可以在项目启动的时候自动进行加载;
3、定时刷新缓存;
2、熔断
缓存雪崩会造成大面积的服务节点出现异常,为了解决这个问题出现了 熔断机制 :当下游服务器不可用或相应过慢的时候,上游服务器为保证自己整体服务的可用性,不再继续调用目标服务器,直接返回,快速释放资源,如果目标服务器好转则恢复调用。
3、降级
缓存降级是指缓存失效或者缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或者访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对业务的影响程度。
系统可以根据一些关键数据进行自动降级,降级的最终目的是保证核心服务可用,即使是有损的。但是有的一些业务的核心服务是不能降级的。这是一种丢卒保帅的思想。
1. 一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
2. 警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
3. 错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
4. 严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
4、限流
参考:Redis 限流的 3 种方式,速速拿走
1、基于Redis的setnx的操作:
- 比如我们需要在10秒内限定20个请求,那么我们在setnx的时候可以设置过期时间10,当请求的setnx数量达到20时候即达到了限流效果。
- 缺点:当统计1-10秒的时候,无法统计2-11秒之内,如果需要统计N秒内的M个请求,那么我们的Redis中需要保持N个key等等问题。
2、基于Redis的数据结构zset:
- 我们可以将请求打造成一个zset数组,当每一次请求进来的时候,value保持唯一,可以用UUID生成,而score可以用当前时间戳表示,因为score我们可以用来计算当前时间戳之内有多少的请求数量。而zset数据结构也提供了range方法让我们可以很轻易的获取到2个时间戳内有多少请求。
- 缺点:zset的数据结构会越来越大。
3、基于Redis的令牌桶算法:
- 令牌桶算法提及到输入速率和输出速率,当输出速率大于输入速率,那么就是超出流量限制了。也就是说我们每访问一次请求的时候,可以从Redis中获取一个令牌,如果拿到令牌了,那就说明没超出限制,而如果拿不到,则结果相反。
- 实现:依靠List的LPOP来获取令牌,再依靠定时任务,定时往List中RPUSH令牌,当然令牌也需要唯一性,所以我这里还是用UUID进行了生成。
三、Redis与数据库的数据一致性问题
Redis 与数据库的数据一致性不能保证强一致性,也就是不能保证时时刻刻数据一样,只能保证一段时候后数据最终一致性。那么操作上就有一个先后顺序的问题:
1、先更新数据库,再更新缓存;
2、更新缓存,再更新数据库;
而缓存又有更新和删除两种选择,无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
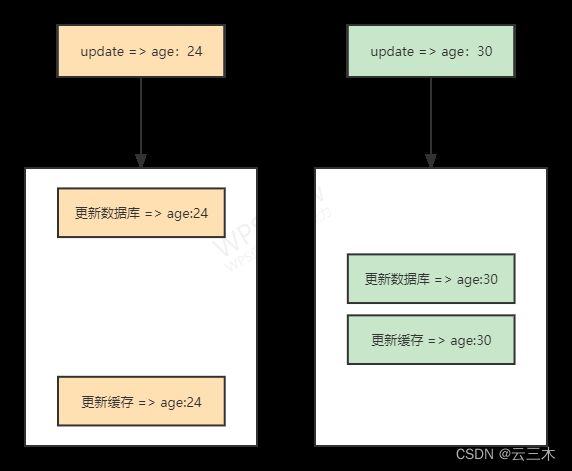

所以来看看下面两种删除缓存的情况:
1、先删除缓存、再更新数据库
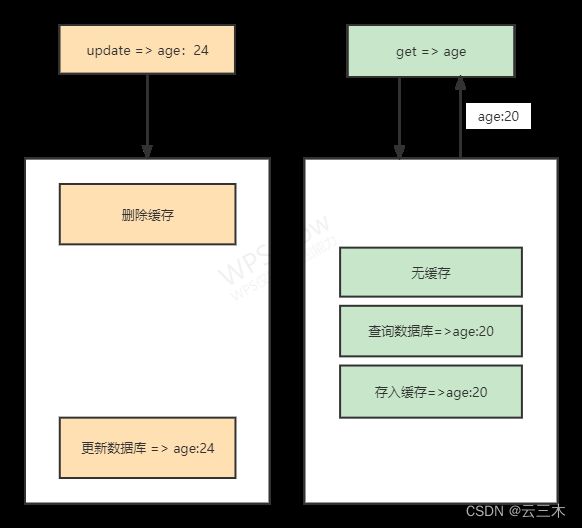
如果删除了缓存Redis,还没来得及写入数据库,另一个请求就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
这种情况下可以使用双删策略:先删除缓存,,再写数据库,休眠N秒,再次删除缓存(N秒根据业务需要判断);如果第二次删除失败,那就把第二次删除加入到消息队列中执行或者多次删除(删除缓存重试机制)。
cache.delKey(X)
db.update(X)
Thread.sleep(N)
cache.delKey(X)
2、先更新数据库、再删除缓存(推荐)
当前这种方式是比较推荐的,更新数据库和删除缓存这段时间内,请求读取的还是缓存内的旧数据,不过等数据库更新完成后,就会恢复一致。
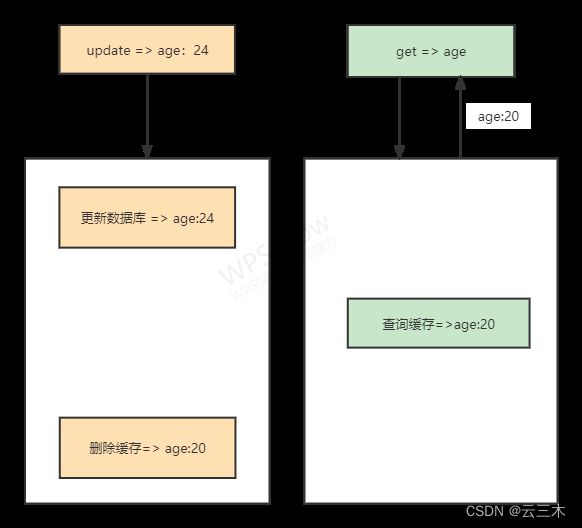
上图是情况发生后,现在已经没有缓存,哪呢就有可能发生下图这种情况:

发生上述情况有一个先天性条件,就是右侧更新数据库操作比左侧读数据库操作耗时更短,才有可能发生上图的情况,但是数据库的读操作的速度远快于写操作的,因此这一情形很难出现。缓存数据可以加上过期时间,就算在这期间存在缓存数据不一致,有过期时间来兜底,这样也能达到最终一致。
先写数据库 ,后删除缓存不会出现双写不一致,只会出现读写并发不一致。
3、主从一致性

主从同步有时延,这个时延期间读从库,可能读到不一致的数据。任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间不一致。如果业务能接受,别把系统架构搞得太复杂。
强制读主:
1、使用一个高可用主库提供数据库服务
2、读和写都落到主库上
3、采用缓存来提升系统读性能
这是很常见的微服务架构,可以避免数据库主从一致性问题。
针对主从一致性的问题常用解决办法:
1、主从同步有时延,业务可以接受,系统不优化
2、强制读主,使用一个高可用主库提供数据库服务,读和写都落到主库上(仅针对需要强一致性数据)
3、选择性读主
前两个不用多说,现在讲讲 选择性读主:
缓存标记法:
1)用户A发起写请求,更新了主库,并在客户端设置标记,过期时间(预估的主库和从库同步延迟的时间),可以使用cookie实现
2)用户A再发起读请求时,带上这个cookie
3)服务器处理请求时,获取请求传过来的数据,看有没有这个标记
4)有这个业务标记,走主库;没有走从库。
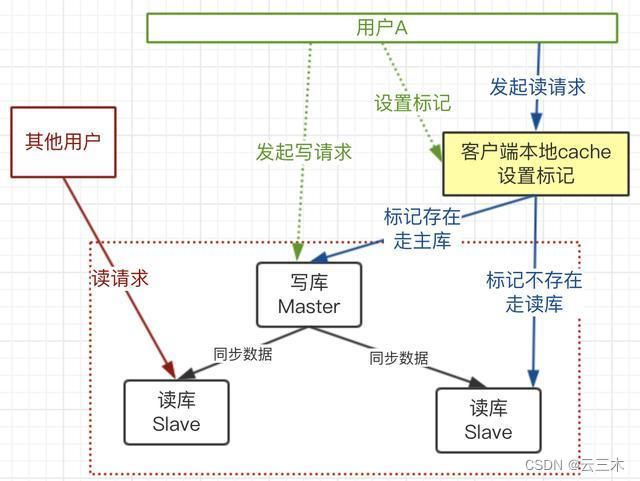
这个方案就保证了用户A的读请求肯定是数据一致的,而且没有性能问题,因为标记是本地客户端传过去的。
但是无法保证其他用户读数据是一致的,但是实际场景很少需要保持其他用户也保持强一致。延迟个几秒也没问题。
参考:读写分离数据库如何保持数据一致性
4、删除失败怎么办
双删策略,消息队列。
四、分布式锁
1、SET NX|EX
2、SETNX + EXPIRE + LUA
3、分布式锁:redLock(有争议)、zookeeper
这个问题在之前文章中已经讲过了,可参考Redis 分布式锁。
五、Redis持久化机制
Redis的持久化有两种aof和rdb,默认情况下,使用快照RDB的持久化方式。
RDB文件是一个紧凑的二进制压缩文件,是Redis在某个时间点的全部数据快照。所以使用RDB恢复数据的速度远远比AOF的快,非常适合备份、全量复制、灾难恢复等场景。
AOF是每次写命令追加写入日志中,主要作用是解决了数据持久化的实时性。
RDB 和 AOF 各有其优缺点, Redis 4.0 之后推出的 RDB-AOF 混合持久化模式,即以 RDB 作为全量备份,AOF 作为增量备份。修改配置文件redis.conf:
aof-use-rdb-preamble yes
在该模式下,AOF 重写产生的文件将同时包含 RDB 格式的内容和 AOF 格式的内容,该文件的前半段是 RDB 格式的全量数据,而后半段是 Redis 命令格式的增量数据,这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的简单优势, 实际环境中用的很多.。
详情可参考Redis 持久化。
六、秒杀场景
在双11,618这样的网络购物节,平台会提供一些物美价廉、限时限量的是商品或者优惠券来引流,Redis 经常用于这种秒杀场景。秒杀场景的两个特征:瞬时并发高、多读少写;使用 Redis 可以拦截绝大部分的请求,把库存存在 Redis 队列中,超出数量直接返回结果抢购失败 。
秒杀流程:在秒杀开始前大量用户就是频繁的刷新抢购页面,秒杀开始后用户点击抢购按钮需要返回抢购结果。所以为了解决秒杀问题在抢购页面就需要做一些处理,如:抢购页面静态化、按钮加锁定。
解决思路:
秒杀开始前准备:
- 1、前端抢购页面静态化,使用CDN或者浏览器缓存。点击抢购后锁定按钮或者打开新页面等待抢购结果。
- 2、秒杀开始前 redis 开启持久化,把商品和存库都存入 redis 中。(库存存到消息队列中,通过LPOP取出,库存数也要另存)
秒杀时:
- 1、redis使用 消息队列 实现商品秒杀。每次点击都从消息队列中取出一个元素,当队列的 LPOP 操作失败则代表活动结束。(因为 redis 是单线程的,所以可以将并发请求串行化,而且 redis LPOP 操作是原子性的。)
- 2、同步库存量到数据库。数据库开始处理抢购成功后的业务逻辑。
也可以使用乐观锁配合 incr实现秒杀。
示例代码:
header("content-type:text/html;charset=utf-8");
$redis = new redis();
$result = $redis->connect('127.0.0.1', 7379);
// 把所有抢购数量导入列表
if ($redis->lpop("stock")) {
$redis->hset("user_list", "user_id_" . rand(100000, 999999), 123);
echo "抢购成功!
";
} else {
echo "已卖光!";
exit;
}
// 计数器 - 创建活动商品时把库存翻入消息队列中
public function maple()
{
$count=999; // 库存
//添加到redis list中
for($i=0;$i<$count;$i++){
$redis->lpush('stock', 111);
}
}
以上只写了 Redis 的解决办法,实际情况还是根据业务需要使用不同解决办法。
七、Redis和Memcahe对比
说到缓存技术,就会想到redis和memcache。他们都是内存型数据库。但互联网用到的缓存技术绝大部分都是使用redis,那我们来分析一下redis和memcache的区别,以及redis是如何成为大众的宠儿呢。
1、支持的数据类型不同
- memcache支持string类型,图片,视屏等缓存;
- redis不仅支持简单的k/v类型,还提供list,hash,set,zset等数据类型。
2、是否支持持久化
- memcache不支持持久化,数据都是在内存中,一旦停电则会造成数据丢失,且不可以恢复;
- redis支持持久化,通过RDB/AOF两种方式来将数据持久化到磁盘,若停电还可以恢复数据。
3、内存空间和key数量
- memcache的key最长250个字符,value不能超过1MB(可以通过配置文件修改);
- redis的key和valve均不能超过512MB。(字符串值的最大长度为512MB)。
4、缓存时间
- memcache默认支持最多缓存30天;
- redis缓存时间没有限制。
5、应用场景不同
- redis不仅用做数据缓存,还可以用来消息队列,数据堆栈等方面;
- memcache适合简单数据类型,热点常用数据。
6、redis支持主从复制

八、Redis的过期策略及淘汰机制
1、过期策略
Redis的过期策略——“定期删除+惰性删除” 。
1、定期删除
- 定期删除是指Redis默认每隔100ms就随机抽取 N 个设置了过期时间的key,检测这些key是否过期,如果过期了就将其删除。
- 100ms:在Redis的配置文件redis.conf中有一个属性
hz,默认为10,表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置值。- N 个key:N 同样是由redis.conf文件中的
maxmemory-samples属性决定的,默认为5。、
2、惰性删除
- 惰性删除不是去主动删除,而是在你要获取某个key 的时候,redis会先去检测一下这个key是否已经过期,如果没有过期则返回给你,如果已经过期了,那么redis会删除这个key,不会返回给你。
2、淘汰机制
在配置文件redis.conf 中,可以通过参数 maxmemory 来设定最大内存,不设定该参数默认是无限制的。当内存不足时,就会采取内存淘汰机制,Redis内存淘汰方式有以下八种:
| 策略 | 注释 |
|---|---|
| no-eviction | 新写入操作会报错。(默认选项,一般不会选用) |
| allkeys-lru | 通过LRU算法移除最近最少使用的key。(这个是最常用的) |
| allkeys-lfu | 通过LFU算法移除最不经常(最少)使用的key(4.0及以上版本可用)。 |
| allkeys-random | 随机移除某个key。 |
| volatile-lru | 在设置了过期时间的键中,通过LRU算法移除最近最少使用的key。 |
| volatile-lfu | 在设置了过期时间的键中,通过LFU算法移除最不经常(最少)使用的key(4.0及以上版本可用)。 |
| volatile-random | 在设置了过期时间的键中,随机移除某个key。 |
| volatile-ttl | 在设置了过期时间的键中,有更早过期时间的key优先移除。 |
在配置文件redis.conf 中,可以通过参数 maxmemory-policy 来设置淘汰的方式。
过期策略用于处理过期的缓存数据;内存淘汰策略用于处理内存不足时的需要申请额外空间的数据。所以内存淘汰策略的选取并不会影响过期的key的处理。
3、其他场景过期key的操作
1、快照生成RDB文件时:
- 过期的key不会被保存在RDB文件中。
2、服务重启载入RDB文件时:
- Master载入RDB时,文件中的未过期的键会被正常载入,过期键则会被忽略。Slave 载入RDB 时,文件中的所有键都会被载入,当主从同步时,再和Master保持一致。
3、AOF 文件写入时:
- 因为AOF保存的是执行过的Redis命令,所以如果redis还没有执行del,AOF文件中也不会保存del操作,当过期key被删除时,DEL 命令也会被同步到 AOF 文件中去。
4、重写AOF文件时:
- 执行 BGREWRITEAOF 时 ,过期的key不会被记录到 AOF 文件中。
5、主从同步时:
- Master 删除 过期 Key 之后,会向所有 Slave 服务器发送一个 DEL命令,Slave 收到通知之后,会删除这些 Key。
Slave 在读取过期键时,不会做判断删除操作,而是继续返回该键对应的值,只有当Master 发送 DEL 通知,Slave才会删除过期键,这是统一、中心化的键删除策略,保证主从服务器的数据一致性。
参考:Redis过期策略及内存淘汰机制
九、Redis常见性能问题及解决方案
1、主服务器写内存快照,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务。
- 解决方案:主服务器最好不要写内存快照。如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次;
2、Redis 主从复制的性能问题
- 解决方案:为了主从复制的速度和连接的稳定性,主从库最好在同一个局域网内。尽量避免在压力很大的主库上增加从库。
总结
本篇简单总结一下面试时 Redis常问问题的回答,如果有错误或不全的地方欢迎补充。