计算机组成原理——解决了我的一些困惑
全文电子版:408—电子笔记分享-CSDN博客
目录
1、代码中的——类型转换(int -> short)
2、换内存条——双通道要2和4才可以
3、买的硬盘容量 & 实际电脑显示容量——不匹配
4、固态硬盘 & 机械硬盘 谁更好
5、流水线 与 集群 (资本家看了都流泪)
5、真值(原码)、补码、移码
6、0.1和0.3用二进制(浮点数)表示不了
7、为什么会有反码、补码、移码?
8、为什么IEEE754的移码偏置值是127,而不是128?
9、IEEE754的阶码全0 和 全1的用处
10、ROM、RAM、DAM、SAM、PROM、Flash
11、计算机中的单位(B、KB、MB、GB、TB)
12、计算机中CPU的位数、32位、64位是什么?
13、异常和中断(区别)
14、从高级语言到机器语言的转换(翻译程序-编译-解释-汇编)
15、进制(个十百千万亿)
这个是复习408时,临时起意,把这些问题记录下来,我现在复习了一半有余,于是把这些发布出来(如果后面有新的,我会在这里面进行更新)
1、代码中的——类型转换(int -> short)
多变少(int -> short)——高位截断——精度丢失(高的)
少变多(short -> int)——高位拓展——开头为1就全补1,为0就全补0

2、换内存条——双通道要2和4才可以


3、买的硬盘容量 & 实际电脑显示容量——不匹配
由于硬盘制造商和计算机系统对容量单位的定义存在差异导致的。
硬盘制造商通常采用十进制计量系统来表示硬盘容量,即1GB等于10亿字节,1TB等于1万亿字节。而计算机系统则采用二进制计量系统,即1GB等于2的30次方(约10亿字节),1TB等于2的40次方(约1万亿字节)。这样一来,同一个硬盘容量在制造商和计算机系统之间的单位换算就会有所不同。
举例说明:
如果购买了一个标称容量为1TB(1万亿字节)的硬盘,在计算机系统中显示的容量大约为931GB左右。这是因为计算机系统将1TB转换为2进制计量系统的容量单位后,得到的数值比制造商标明的容量要小。
此外,硬盘中也会预留一部分空间用于文件系统的管理、坏道修复、性能维护等目的,这也会导致实际可用空间比标称容量更小一些。
因此,在购买硬盘时,可以通过将制造商标称的容量按照计算机系统的计量单位进行转换,以便更好地了解实际可用空间。
可以使用以下公式进行换算:
实际可用空间 = 标称容量 * 制造商容量单位 / 计算机系统容量单位
例如,对于一个标称容量为1TB的硬盘: 实际可用空间 = 1TB * 1000000000 / 1073741824 ≈ 931GB
这样就能更准确地估计实际可用空间与标称容量之间的差异。
请注意,不同品牌和型号的硬盘,其实际空间损失可能会有所差异。
4、固态硬盘 & 机械硬盘 谁更好
固态硬盘的优点:
- 速度更快:固态硬盘使用闪存芯片来存储数据,具有较快的读写速度,可以显著提升系统的响应速度和启动时间。
- 更高的数据可靠性:固态硬盘没有移动部件,较机械硬盘更耐震动,且不受碎片化影响,数据可靠性更高。
- 低功耗和无噪音:固态硬盘不需要马达等机械部件,具有更低的功耗和无噪音运行。
机械硬盘的优点:
- 存储容量更大:相对于固态硬盘,机械硬盘可以提供更大的存储容量,适合存储大量的文件和数据。
- 价格更经济:机械硬盘的价格相对较低,如果对存储容量要求较高或预算有限,机械硬盘可能是更经济的选择。
- 长时间存储:机械硬盘在长期不使用时不会出现数据丢失的问题,适合用于备份和长期存储。
5、流水线 与 集群 (资本家看了都流泪)
流水线(Assembly Line):流水线是一种生产制造工艺,它将产品的制造过程分为多个工序,并且每个工序都由特定的工人或机器完成。在流水线上,产品在每个工序之间按照固定的顺序传递,每个工序只需完成特定的任务,然后将产品传递给下一个工序。流水线可以提高生产效率、降低成本,并且适用于大规模生产的场景。
集群(Cluster):集群是指将多台计算机通过网络连接起来,形成一个整体,以共同完成某个任务或提供某种服务。在集群中,各个计算机被称为节点,它们之间可以相互通信和协作。集群可以通过将任务分配给多个节点并行执行来提高计算能力和处理大规模数据的能力。集群广泛应用于大数据处理、高性能计算、服务器集群等领域。
共同点:
- 提高效率:无论是流水线还是集群,它们都致力于提高工作效率。流水线通过将制造过程细分为多个工序并同时进行,实现了并行和专业化的生产方式,提高了生产效率。集群将多个计算机连接在一起并协同工作,可以同时处理更多的任务,提高了计算能力和效率。
- 分工协作:流水线和集群都涉及到任务的分工和协作。流水线中,每个工序负责特定的任务,产品在不同的工序之间传递,并最终完成制造。集群中,每个节点负责处理特定的任务或提供特定的服务,彼此之间相互协作共同完成整体任务或服务。
- 大规模应用:流水线和集群都适用于大规模应用场景。流水线广泛应用于制造业,如汽车制造、电子产品制造等;而集群广泛应用于计算领域,如大数据处理、云计算、超级计算等。
超标量流水线是一种计算机架构设计的技术,用于提高单个处理器的指令执行效率。它利用了指令级并行性,即同时执行多条指令,以加快程序的执行速度。超标量流水线通过将多个阶段的指令流水化处理,并采用多发射等技术,在一个时钟周期内同时执行多条指令,从而提高处理器的吞吐量和效率。
- 超标量流水线主要应用于单个处理器内部,通过优化指令执行顺序和并行执行多条指令,提高单个处理器的性能。
- 集群主要应用于多个计算机的协同工作,通过任务的并行分发和处理,以提供更高的计算能力和服务能力。
5、真值(原码)、补码、移码
(对于符号位相同的数——真值(原码)、补码、移码都是单调增的)

6、0.1和0.3用二进制(浮点数)表示不了

使用32位(单精度)浮点数表示0.1时,其值实际上是0.100000001490116119384765625,而不是精确的0.1。这是由于在二进制中,无法准确表示0.1的精确值,导致了舍入误差。
在计算机中,浮点数的二进制表示是有限的,而十进制小数0.3的二进制表示是无限循环的。具体地说,0.3的二进制表示为0.0100110011001100110011001100110011...,其中数字01不断重复下去。因此,在计算机中用有限的位数来表示0.3时,就会出现精度误差。
7、为什么会有反码、补码、移码?
1.反码(One's Complement):
- 正数的反码与原码相同。
- 负数的反码是将其原码按位取反(0变1,1变0)得到的结果。
反码解决的问题:
- 解决了符号位的表示问题,通过将最高位作为符号位来表示正负数。
- 但它存在两个表示零的编码(正零和负零),同时也使得加法和减法运算比较复杂。
2补码(Two's Complement):
- 正数的补码与原码相同。
- 负数的补码是将其反码末位加1得到的结果。
补码解决的问题:
- 解决了反码表示下存在两个零的问题,只有一个表示零的编码。
- 同时,加法和减法运算可以在补码的基础上进行,简化了运算。
3移码(Excess-K Code):
- 移码是在原码的基础上对于正数直接加上K,负数则是将其反码末位加1再加上K。
移码解决的问题:
- 主要用于浮点数的表示和运算,其中移码的偏移量K可以用来表示指数的偏移量,方便进行浮点数的比较和计算。
8、为什么IEEE754的移码偏置值是127,而不是128?
IEEE754设置的是2n-1-1 (普通移码就是:2n-1)注意!!!!!!!!!!!!
在IEEE 754中,一个单精度浮点数由1位符号位、8位指数位和23位尾数位组成。
看似-1多余,然而,偏移量-1的操作,就可以让浮点数表示的范围,提升了将近1半!!!

9、IEEE754的阶码全0 和 全1的用处
IEEE754的理解归纳_阶码全0,尾数不全为0_caseyzzz的博客-CSDN博客
阶码全0和全1是特殊用处的值:
阶码全0,尾数全0即为0【正负之分看最高符号位】
阶码全0,尾数不全为0,取消隐含1规则,为非规范化数,实际数为0.M * 2^(0-127) = 0.M * 2^-127
阶码全1,尾数全0,代表无穷【正负之分看符号】
阶码全1,尾数不为0,无效数
10、ROM、RAM、DAM、SAM、PROM、Flash

1. ROM(只读存储器):
• 嵌入式系统:ROM 用于存储固化的程序和数据,如传统游戏机、电子设备等。
• BIOS(基本输入/输出系统):计算机的 ROM 存储了启动时需要的基本指令集。
• 软件固件:一些设备上的固件是以 ROM 的形式存储的,如路由器、手机等。
2. RAM(随机存取存储器):
• 主存储器:计算机的主要内存用于暂时存储运行中的程序和数据。(一般是ROM+RAM)
• 缓存:CPU 缓存是用于加快数据访问速度的高速 RAM。
• 图形处理器(GPU)内存:用于高性能图形计算、游戏和视频处理等。
3. SAM(顺序访问存储器):
• 磁带存储:SAM 是一种顺序读写的存储介质,广泛用于数据备份、长期存档和归档等。
• 音频/视频录音:某些音频或视频设备使用 SAM 存储格式进行录制和存储。
DAM——直接存取存储器——用于磁盘
- PROM(可编程只读存储器):与 ROM 类似,但可以通过特定的编程过程进行一次性的写入操作。
- EPROM(可擦除可编程只读存储器):类似于 PROM,但可以通过特定的紫外线擦除操作重复写入。
- EEPROM(电子可擦除可编程只读存储器):类似于 EPROM,但可以通过电子方式擦除和重写。
- Flash 存储器:一种非易失性存储器,用于储存数据和程序代码。常见于 USB 驱动器、SSD(固态硬盘)、移动设备等。
- Cache 存储器:作为高速缓存的一部分,用于临时存储最常访问的数据,以提高计算机的性能。
- VRAM(显存):用于存储图形和视频数据,供显卡使用。
- Register(寄存器):位于 CPU 内部的高速存储器,用于存储指令、地址和数据,用于执行计算任务。
11、计算机中的单位(B、KB、MB、GB、TB)
计算机存储单位一般用B,KB,MB,GB,TB,PB,EB,ZB,YB,BB
1B (byte 字节);1B(byte)= 8bit
1KB(Kilobyte 千字节) = 2^10 B = 1024 B;
1MB(Megabyte 兆字节) = 2^10 KB = 1024 KB = 2^20 B;
1GB(Gigabyte 吉字节) = 2^10 MB = 1024 MB = 2^30 B;
1TB(Trillionbyte 太字节) = 2^10 GB = 1024 GB = 2^40 B;
1PB(Petabyte 拍字节) = 2^10 TB = 1024 TB = 2^50 B;
1EB(Exabyte 艾字节) = 2^10 PB = 1024 PB = 2^60 B;
1ZB(Zettabyte 泽字节) = 2^10 EB = 1024 EB = 2^70 B;
1YB(YottaByte 尧字节) = 2^10 ZB = 1024 ZB = 2^80 B;
1BB(Brontobyte ) = 2^10 YB = 1024 YB = 2^90 B;
1NB(NonaByte ) = 2^10 BB = 1024 BB = 2^100 B;
1DB(DoggaByte) = 2^10 NB = 1024 NB = 2^110 B
12、计算机中CPU的位数、32位、64位是什么?
安装软件时,软件后面都跟个(x32) 或者(x64)什么意思?
翻译:你的电脑CPU可以一次性处理的数据是多少位!
如果是x32,则是32位的
如果是x64,则是64位的(意味着你的CPU可以一次性处理64位)
CPU的一次性处理的位数 = 数据总线的位数
13、异常和中断(区别)
异常是在程序执行过程中出现的非预期事件,例如除零错误、访问无效内存、非法指令等。当出现异常时,处理器会中断当前的正常程序流程,并跳转到异常处理程序进行异常处理。异常通常由指令或者数据错误引起,是程序错误或者系统错误的结果。
中断是外部设备或者其他硬件信号请求处理器停止当前执行的指令,转而处理特定的任务。中断可以是来自外部设备的输入/输出请求、定时器触发、硬件错误等。当中断发生时,处理器会保存当前上下文,暂停当前执行的程序,并跳转到中断处理程序进行相应的处理。中断通常由硬件触发,用于处理外部事件或者设备的交互。
异常——在任何时间都可能发生
中断——在一条指令执行完后,才会发现(毕竟要保障指令的原子性)
异常——不可控(0容忍!)有了那么就必须处理(毕竟是出现了错误)
中断——可以等待的那种!!!(这个是设置的一个操作而已!)

14、从高级语言到机器语言的转换(翻译程序-编译-解释-汇编)
1.编译执行
编译方式是将整个高级语言编写的源程序先翻译成机器语言程序,然后再生成可在操作系统下直接运行的执行程序,通常会产生目标程序。

2.解释执行
解释方式是将源程序逐句解释执行,即解释一句执行一句,因此在解释方式中不产生目标文件。

| 特点 |
编译 |
解释 |
| 翻译过程 |
源程序整体翻译成目标代码,分阶段翻译和执行 |
逐行解释执行源程序,一次性完成翻译和执行 |
| 目标代码 |
生成可执行的目标代码文件 |
不生成可存储的目标代码 |
| 控制权 |
运行时控制权在用户程序 |
运行时控制权在解释器 |
| 动态特性 |
缺乏动态特性,执行前已确定的静态结构 |
具有动态特性,可以动态改变类型、修改程序等 |
| 可移植性 |
依赖于目标平台,不同平台需要重新编译 |
解释器移植到不同系统上,程序无需修改即可运行 |
| 运行速度 |
生成的目标代码直接执行,运行速度较快 |
逐行解释执行,运行速度相对较慢 |
| 调试性 |
需要通过调试工具进行调试 |
可以插入调试诊断信息,方便调试 |
| 示例语言 |
C、C++、Java等 |
Python、JavaScript等 |
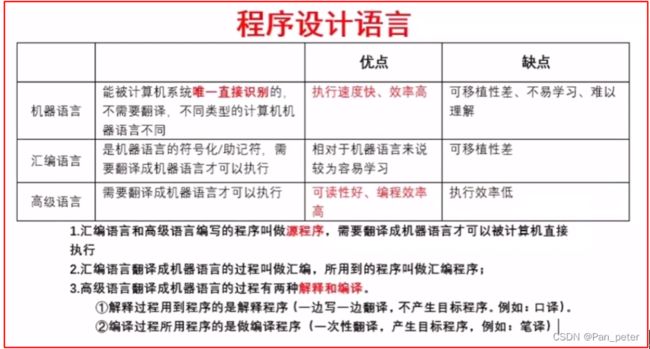
翻译程序是一种系统程序,它将计算机编程语言编写的程序翻译成另外一种计算机语言的一般来说等价的程序,主要包括编译程序和解释程序,汇编程序也被认为是翻译程序。
1、汇编程序是指把【汇编语言书写的程序】翻译【机器语言程序】的翻译程序。
2、编译程序是将【整个高级语言编写的源程序】先翻译成【机器语言程序】,然后再生成可在操作系统下直接运行的执行程序,通常会产生目标程序。
3、解释程序是将【源程序逐句解释执行】,即解释一句执行一句,因此在解释方式中不产生目标文件。
链接程序将汇编程序处理过的目标程序链续为可执行程序。
它将一组目标模块及所需的库函数链接在一起。不属于翻译程序。
(编译器和汇编程序都经常依赖于连接程序)

15、进制(个十百千万亿)
10的0次方——个
10的1次方——十
10的2次方——百
10的3次方——千
10的4次方——万
10的5次方——十万
10的6次方——百万
10的7次方——千万
10的8次方——亿
10的16次方——亿亿
5亿亿——5*10^16