因果推断《Causal Inference in Python》中文笔记第1章 因果推断导论
《Causal Inference in Python: Applying Causal Inference in the Tech Industry》因果推断啃书系列
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
《Causal Inference in Python》第1章 因果推断导论
- 第1章 因果推断导论
-
- 1.1 什么是因果推断
- 1.2 为什么需要因果推断
- 1.3 机器学习与因果推断
- 1.4 关联关系与因果关系
-
- 1.4.1 干预与结果
- 1.4.2 因果推断的基本问题
- 1.4.3 因果关系模型
- 1.4.4 介入(Interventions)
- 1.4.5 个体干预效果(Individual Treatment Effect)
- 1.4.6 潜在结果(Potential Outcomes)
- 1.4.7 一致性与稳定分析单元干预值
- 1.4.8 因果量(Causal Quantities)
- 1.4.9 因果量的一个例子
- 1.5 偏差
-
- 1.5.1 偏差方程
- 1.5.2 偏差的可视化
- 1.6 识别干预效果
-
- 1.6.1 独立假设(Independence Assumption)
- 1.6.2 使用随机化进行识别
- 1.7 要点总结
第1章 因果推断导论
1.1 什么是因果推断
人类的思维天然就具备因果推断能力,即使有时候是错误的。例如早上起床感觉精神不好,回想起昨晚熬夜了,我们便知道是熬夜导致了第二天的精神不佳。但是如果将睡眠时长和量化的精神状态记录下来,从数据上,机器就只知道睡眠时长和精神状态是相关的,并认为这个两个因素的地位是相同的。
如果说关联关系就是两个变量同时变化,那么因果关系就是一个变量的变化导致另一个变量发生变化。因果推断就是从关联关系中推理出因果关系。
1.2 为什么需要因果推断
在一定程度上将从关联关系中推理出因果关系的过程规范化,让机器帮助我们理解现实世界。利用因果推断得出的规律,就可以有目的地对原因进行干预,以带来预期的效果。换句话就是,辅助我们完成决策。
例如,每当到一些节日的时候,商家往往会采取促销活动,以期吸引更多的顾客,获得更多的利益。在规划促销活动前,商家就很想知道,假如采取一些“促销”干预行为,究竟会不会影响顾客的购买行为,如果有影响,会有多大的影响。
1.3 机器学习与因果推断
从上面商家促销的例子来看,因果推断更多解决的是“假如”类型的问题。这类问题往往是机器学习所不能解决的。
机器学习擅长的是预测类问题。“人工智能的新浪潮实际上并没有给我们带来智能,而是智能预测的一个关键组成部分”(来源《预测机器》)。机器学习可以作为一种工具,辅助实现因果推断。
1.4 关联关系与因果关系
其实上面已经将关联关系和因果关系的定义和区别讲清楚了。
现在假设我们是一个电子商务平台的工作人员,该平台上入驻了一些商家,这些商家有完全的定价权。我们在平台上收集了一份玩具企业销售数据,由此来说明因果推断相关的术语,并使用这些术语重新阐释因果推断的定义和过程。
数据文件在项目的路径为./data/xmas_sales.csv。
import pandas as pd
import numpy as np
from scipy.special import expit
import seaborn as sns
from matplotlib import pyplot as plt
from cycler import cycler
default_cycler = (cycler(color=['0.3', '0.5', '0.7', '0.5']) +
cycler(linestyle=['-', '--', ':', '-.']) +
cycler(marker=['o', 'v', 'd', 'p']))
color=['0.3', '0.5', '0.7', '0.5']
linestyle=['-', '--', ':', '-.']
marker=['o', 'v', 'd', 'p']
plt.rc('axes', prop_cycle=default_cycler)
plt.rc('font', size=20)
data = pd.read_csv("./data/xmas_sales.csv")
data.head(6)
| 商店ID | 距圣诞节周数 | 周均单价 | 是否促销 | 周均销售额 |
|---|---|---|---|---|
| 1 | 3 | 12.98 | 1 | 219.60 |
| 1 | 2 | 12.98 | 1 | 185.70 |
| 1 | 1 | 12.98 | 1 | 145.75 |
| 1 | 0 | 12.98 | 0 | 102.45 |
| 2 | 3 | 19.92 | 0 | 103.22 |
| 2 | 2 | 19.92 | 0 | 53.73 |
上面数据是临近圣诞节的12月中的四个星期的若干商店的销售情况。
- store:商店ID
- weeks_to_xmas:距离圣诞节的周数
- avg_week_sales:平均周销售量
- is_on_sale:是否促销
- weekly_amount_sold:周销售额
现在需要对上面的数据进行分析,这段时间的降价是如何增加销售额的。
所以需要我们干预的因素就是商品单价,我们关注的结果是销售额的变化。
1.4.1 干预与结果
上面的案例涉及的术语如下:
干预(Treatment):如果干预, T i = 1 T_i = 1 Ti=1;否则 T i = 0 T_i = 0 Ti=0结果(Outcome): Y i Y_i Yi分析单元(Unit of Analysis):希望干预的对象
用上面的术语重新阐释因果推断的定义:研究将干预 T T T 施加到分析单元上对 Y Y Y 的影响。
1.4.2 因果推断的基本问题
对一个分析单元,无法做到干预和不干预两种情况都发生,这就是因果推断中最根本的困难。
就像是开车是只能看到车前的情况,遇到一个分叉口,你永远只知道你选择的那个方向的前方是什么。
回到生命玩具商店是否要促销的例子,我们将变量是否促销作为X轴,周销售额作为Y轴绘制箱体图。
fig, ax = plt.subplots(1, 1, figsize=(10,5))
sns.boxplot(y="weekly_amount_sold", x="is_on_sale", data=data, ax=ax)
ax.set_xlabel("is_on_sale", fontsize = 20)
ax.set_ylabel("weekly_amount_sold", fontsize = 20)
ax.tick_params(axis='both', which='major', labelsize=18)
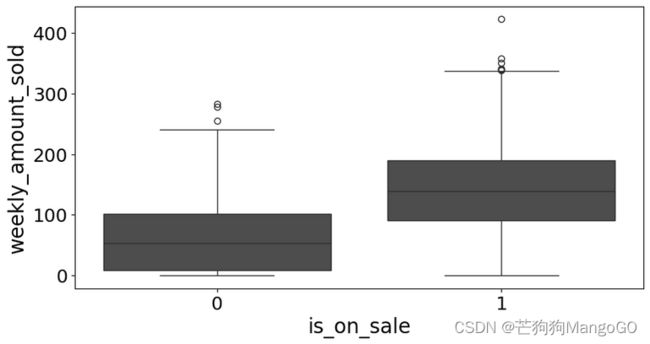
采取促销的情况整体上周销售额比不促销的情况要高。这和我们的常识相符,促销往往以为着降价,价格低的时候,顾客购买的量更大,也往往会形成更高的销售额。
但是上面的分析有可能是将关联关系误认为是因果关系了。有能力降价的企业往往是大公司,销量也会比较高。也有可能是临近圣诞节,顾客本身就会购买更多的东西。
只有在观察相同的商品,将该商品同时有促销和没有促销的两种反事实(Counterfactual)的情况作对比,才能知道促销对销售额的真正影响。
但是正如前面说的,因果推断就是无法做到这点,需要使用别的方式实现。
1.4.3 因果关系模型
因果模型是一系列由箭头表示的赋值过程。 u u u 表示模型之外的变量,这些变量我们不必关心,模型当中包含的变量才是我们要关心的。还有函数 f f f 将一个变量映射到另一个变量。
以下面的因果模型为例:
T ← f t ( u t ) Y ← f y ( T , u y ) T \leftarrow f_t(u_t) \\ Y \leftarrow f_y(T,u_y) T←ft(ut)Y←fy(T,uy)
第一条公式中的 u t u_t ut 表示一组外生变量(exogenous variables),通过函数 f t f_t ft 转换后形成干涉 T T T。
接下来, T T T 和另外一组外生变量 u y u_y uy 共同通过函数 f y f_y fy 转化为结果 Y Y Y。 T T T 包含在因果模型中,被称为内生变量(endogenous variables)。 u y u_y uy的存在说明结果并不是只受干预的影响。
针对上面玩具商店销售的案例,商品价格下降是受到模型之外的因素影响,可能是业务规模,可能是其他因素。商品价格下降,连同另外一些外部因素,导致销售额的变化。
i s _ o n _ s a l e ← f t ( u t ) w e e k l y _ a m o u n t _ s o l d ← f y ( i s _ o n _ s a l e , u y ) is\_on\_sale \leftarrow f_t(u_t) \\ weekly\_amount\_sold \leftarrow f_y(is\_on\_sale,u_y) is_on_sale←ft(ut)weekly_amount_sold←fy(is_on_sale,uy)
使用箭头而不是等号,表示了因果关系的不可逆性。
上面构建的因果模型很简单,现实中我们关心更多的变量。比如前面提到的,企业规模影响促销的能力,我们将企业规模business_size加入到模型中。
b u s i n e s s _ s i z e ← f s ( u s ) i s _ o n _ s a l e ← f t ( b u s i n e s s _ s i z e , u t ) w e e k l y _ a m o u n t _ s o l d ← f y ( i s _ o n _ s a l e , b u s i n e s s _ s i z e , u y ) business\_size \leftarrow f_s(u_s) \\ is\_on\_sale \leftarrow f_t(business\_size,u_t) \\ weekly\_amount\_sold \leftarrow f_y(is\_on\_sale,business\_size,u_y) business_size←fs(us)is_on_sale←ft(business_size,ut)weekly_amount_sold←fy(is_on_sale,business_size,uy)
1.4.4 介入(Interventions)
因果模型创建好之后,需要不断地尝试修补,以解决相应的问题,这个修补的过程就是介入(Interventions)(姑且先这样翻译)。
再看一眼1.6中的简单因果模型
T ← f t ( u t ) Y ← f y ( T , u y ) T \leftarrow f_t(u_t) \\ Y \leftarrow f_y(T,u_y) T←ft(ut)Y←fy(T,uy)
如果干预 T T T 是强制的某种措施 t 0 t_0 t0,那么模型就变成了:
T ← t 0 Y ← f y ( T , u y ) T \leftarrow t_0 \\ Y \leftarrow f_y(T,u_y) T←t0Y←fy(T,uy)
上面的模型就是用来回答问题:“如果将干预 T T T 定为 t 0 t_0 t0,会发生什么?”。这样将干预变量 T T T 赋值的过程就是介入,这个步骤可以用 d o ( . ) do(.) do(.) 操作符来表示:
d o ( T = t 0 ) do(T=t_0) do(T=t0)
介入后会发生什么,发生的效果往往使用期望(Expectations)来表示。数学上的期望可以在某种程度上理解成整体的平均值。对于随机变量 X X X,E(X)就是其期望值,可以使用 X X X 的平均值来近似表示。 E ( Y ∣ X = x ) E(Y|X=x) E(Y∣X=x) 表示当 X = x X=x X=x 时, Y Y Y 的期望值。
从数据上来看,当促销的时候,周销售额的期望为 E ( w e e k l y _ a m o u n t _ s o l d ∣ i s _ o n _ s a l e = 1 ) E(weekly\_amount\_sold|is\_on\_sale=1) E(weekly_amount_sold∣is_on_sale=1)。从因果模型来看,如果我们对所有商店采用促销的干涉,周销售额的期望为 E ( w e e k l y _ a m o u n t _ s o l d ∣ d o ( i s _ o n _ s a l e = 1 ) ) E(weekly\_amount\_sold|do(is\_on\_sale=1)) E(weekly_amount_sold∣do(is_on_sale=1))。前者是很可能大于后者的,因为前面说过,采用促销活动可能是多种因素决定的,有些企业可能规模较小而没有能力降价促销,如果我们对所有商店统一干涉采取促销活动,得到的结果大概率不太理想。
E ( w e e k l y _ a m o u n t _ s o l d ∣ i s _ o n _ s a l e = 1 ) ≠ E ( w e e k l y _ a m o u n t _ s o l d ∣ d o ( i s _ o n _ s a l e = 1 ) ) E(weekly\_amount\_sold|is\_on\_sale=1) \neq E(weekly\_amount\_sold|do(is\_on\_sale=1)) E(weekly_amount_sold∣is_on_sale=1)=E(weekly_amount_sold∣do(is_on_sale=1))
从数据中提取采取了促销措施的数据,得到的结构就是被抽样的样本的周销售热的期望值。当以干预为条件,是迫使每个所有企业降低价格,整体效果肯定是不及预期的。
d o ( . ) do(.) do(.) 的干预及结果并不总是可以从观测数据中获取的。前面的 d o ( i s _ o n _ s a l e = 1 ) do(is\_on\_sale=1) do(is_on_sale=1) 只是一个理论概念,往往不是真的会去做的。
1.4.5 个体干预效果(Individual Treatment Effect)
d o ( . ) do(.) do(.) 操作符也能表示个体干预效果(Individual Treatment Effect),即对于一个个体分析单元 i i i,干预对于结果的作用。个体干预效果就是某个分析单元分别取两种干预变量的情况的差值。
τ i = Y i ∣ d o ( T = t 1 ) − Y i ∣ d o ( t 0 ) \tau_i=Y_i|do(T=t_1)-Y_i|do(t_0) τi=Yi∣do(T=t1)−Yi∣do(t0)
对于促销活动的案例,促销对周销售额的个体干预效果就是:
τ i = w e e k l y _ a m o u n t _ s o l d ∣ d o ( i s _ o n _ s a l e = 1 ) − w e e k l y _ a m o u n t _ s o l d ∣ d o ( i s _ o n _ s a l e = 0 ) \tau_i=weekly\_amount\_sold|do(is\_on\_sale=1)-weekly\_amount\_sold|do(is\_on\_sale=0) τi=weekly_amount_sold∣do(is_on_sale=1)−weekly_amount_sold∣do(is_on_sale=0)
由于因果推断基本问题的限制,我们只能观察到上面公式中的某一项。我们虽然在理论上推导除了上面的公式,但是我们无法从数据中得到公式的值。
1.4.6 潜在结果(Potential Outcomes)
另外一个可以使用 d o ( . ) do(.) do(.) 符号来定义的是因果推断中最酷、最广泛使用的概念:反事实结果(Counterfactual Outcomes),或者叫潜在结果(Potential Outcomes)。
Y t i = Y i ∣ d o ( T i = t ) Y_{ti}=Y_i|do(T_i=t) Yti=Yi∣do(Ti=t)
使用文字描述潜在结果:当干预设定为 t t t 时,分析单元 i i i 的结果 Y Y Y。
下标有时候会变得太拥挤,可以使用函数表示法定义潜在结果:
Y t i = Y ( t ) i Y_{ti}=Y(t)_i Yti=Y(t)i
对于二元干预, Y 0 i Y_{0i} Y0i 表示没有对分析单元 i i i 进行干预的潜在结果, Y 1 i Y_{1i} Y1i 表示对分析单元 i i i 进行干预的潜在结果。其中总有一个是可以观测到的,被称为事实;另一个就是反事实,是无法被观测到的。
Y i = { Y 1 i i f u n i t i s r e c e i v e d t h e t r e a t m e n t Y 0 i o t h e r w i s e Y_i=\begin{cases} Y_{1i} & if\ unit\ is\ received\ the\ treatment \\ Y_{0i} & otherwise \end{cases} Yi={Y1iY0iif unit is received the treatmentotherwise
上式也可以写成下面的形式:
Y i = T i Y 1 i + ( 1 − T i ) Y 0 i = Y 0 i + ( Y 1 i − Y 0 i T i ) \begin{aligned} Y_i&=T_iY_{1i}+(1-T_i)Y_{0i} \\ &=Y_{0i}+(Y_{1i}-Y_{0i}T_i) \end{aligned} Yi=TiY1i+(1−Ti)Y0i=Y0i+(Y1i−Y0iTi)
纵观本书,因果推断总是伴随着假设(Assumptions)。假设就是陈述数据是在什么情况下产生的。
1.4.7 一致性与稳定分析单元干预值
让前面的公式成立需要有两个假设。
假设一: 潜在结果与干预是一致的。当 T i = t T_i=t Ti=t, Y i ( t ) = Y Y_i(t)=Y Yi(t)=Y。换句话说,干预 T T T 的值就是指定的版本,没有隐藏的多个版本。如果干预是多值的,而我们错误地认为该干预只是二元的,这个假设就不成立了。例如,我们关注折扣券对销售的影响时,将其视为是二元的(顾客收到折扣或者没有收到),但是实际上折扣券存在多种不同的折扣力度。再例如,接受理财规划师的帮助对理财有什么影响,这里的“帮助”非常不明确,是一次性咨询,还是日常建议加目标跟踪?“帮助”的程度范围很大,如果归类到一起就违背了一致性原则。
假设二:分析单元干预值无干扰,即稳定的分析单元干预值(SUTVA)。一个分析单元对应干预的结果,不受其他分析单元的干预的影响。 Y i ( T i ) = Y i ( T 1 , T 2 , . . . , T i , . . . , T n ) Y_i(T_i)=Y_i(T_1,T_2,...,T_i,...,T_n) Yi(Ti)=Yi(T1,T2,...,Ti,...,Tn)。如果存在溢出效应或者网络效应,该假设不成立。例如,衡量疫苗对预防传染病的效果,给一个人接种疫苗会降低其身边其他没有接种疫苗的人的感染概率,这样得出的干预的效果会比实际的情况要低。违背这个原则得到的结论通常都是比实际效果要低。
当违反这两个假设的时候,我们都能采取一些措施。当违反一致性原则时,在你的分析中让干预包含所有可能的值。当有外溢效应时,可以整合这些相关的干预,重新定义因果模型。
1.4.8 因果量(Causal Quantities)
学习了潜在结果的概念后,我们重新定义因果推断基本问题:因为只能观测到一种潜在结果,所以永远也不能知道个体干预效果。
虽然不能知道个体干预效果 τ i \tau_i τi,但是能从数据中得到其他有趣的因果量。
因果量一:平均干预效果(Average Treatment Effect,ATE)。
A T E = E ( τ i ) = E ( Y 1 i − Y 0 i ) = E ( Y ∣ d o ( T = 1 ) ) − E ( Y ∣ d o ( T = 0 ) ) \begin{aligned} ATE&=E(\tau_i) \\ &=E(Y_{1i}-Y_{0i}) \\ &=E(Y|do(T=1))-E(Y|do(T=0)) \end{aligned} ATE=E(τi)=E(Y1i−Y0i)=E(Y∣do(T=1))−E(Y∣do(T=0))
平均干预效果就是干预 T T T 造成的平均影响。要想从数据中计算平均干预效果,可以取样本的平均值来表示期望: 1 N ∑ i = 0 N τ i {1 \over N}\sum\limits_{i=0}^{N}{\tau_i} N1i=0∑Nτi 或者 1 N ∑ i = 0 N ( Y 1 i − Y 0 i ) {1 \over N}\sum\limits_{i=0}^{N}(Y_{1i}-Y_{0i}) N1i=0∑N(Y1i−Y0i)。
当然前面说过,因为因果推断基本问题,对于每个分析单元,我们只能观测到潜在结果中的一种。先不用考虑这个问题,我们先只弄清楚因果量的概念。
因果量二:被干预组的平均干预效果(Average Treatment Effect on the Treated,ATT)。
A T T = E ( Y 1 i − Y 0 i ∣ T = 1 ) ATT=E(Y_{1i}-Y_{0i}|T=1) ATT=E(Y1i−Y0i∣T=1)
被干预组的平均干预效果就是被干预的分析单元的干预效果。例如,你在一个城市完成了一次线下营销活动,现在想知道这次活动带来了多少额外的顾客,这个就是 A T T ATT ATT:开展活动的这个城市的营销效果。这里最重要的是弄清楚,对于相同的干预,两种潜在结果是如何定义的。因为你限制条件为实施干预,不干预的潜在结果 Y 0 i Y_{0i} Y0i 是不能被观测的,但定义是明确的。
因果量三:条件平均干预效果(Conditional Average Treatment Effects,CATE)。
C A T E = E ( Y 1 i − Y 0 i ∣ X = x ) CATE=E(Y_{1i}-Y_{0i}|X=x) CATE=E(Y1i−Y0i∣X=x)
条件平均干预效果是研究在使用变量 X X X 定义的群体中进行干预的效果。例如,想知道一份邮件对45岁以上和45岁以下的客户有什么影响。条件平均干预效果对于个性化推荐十分重要,因为能让你在介入的时候知道什么类型的分析单元是更好的选择。
当干预是持续不断的时候,当前结果和前一时刻的结果的差值可以使用偏导数来表示:
∂ ∂ t E ( Y i ) {\partial\over\partial{t}}E(Y_i) ∂t∂E(Yi)
1.4.9 因果量的一个例子
现在针对上面商店促销的案例进行定量的计算。按照因果推断基本问题,我们无法同时知道 w e e k l y _ a m o u n t _ s o l d 0 i weekly\_amount\_sold_{0i} weekly_amount_sold0i 和 w e e k l y _ a m o u n t _ s o l d 1 i weekly\_amount\_sold_{1i} weekly_amount_sold1i,但是我们还是可以构建一些虚拟数据,实际感受一下上面提到的平均干预效果 A T E ATE ATE、被干预组的平均干预效果 A T T ATT ATT、条件平均干预效果 C A T E CATE CATE 是怎样基于数据计算得到的。
A T E = E ( w e e k l y _ a m o u n t _ s o l d 1 i − w e e k l y _ a m o u n t _ s o l d 0 i ) ATE=E(weekly\_amount\_sold_{1i}-weekly\_amount\_sold_{0i}) ATE=E(weekly_amount_sold1i−weekly_amount_sold0i) 表示促销对周销售额的平均影响。
A T T = E ( w e e k l y _ a m o u n t _ s o l d 1 i − w e e k l y _ a m o u n t _ s o l d 0 i ∣ i s _ o n _ s a l e = 1 ) ATT=E(weekly\_amount\_sold_{1i}-weekly\_amount\_sold_{0i}|is\_on\_sale=1) ATT=E(weekly_amount_sold1i−weekly_amount_sold0i∣is_on_sale=1) 表示采用促销活动的商家周销售额的增长。
C A T E = E ( w e e k l y _ a m o u n t _ s o l d 1 i − w e e k l y _ a m o u n t _ s o l d 0 i ∣ w e e k _ t o _ x m a s = 0 ) CATE=E(weekly\_amount\_sold_{1i}-weekly\_amount\_sold_{0i}|week\_to\_xmas=0) CATE=E(weekly_amount_sold1i−weekly_amount_sold0i∣week_to_xmas=0) 表示圣诞节所在周干预的效果。
我们不能同时观测到两个潜在结果,但是为了让事情更加明确,假设现在有个因果推断之神赐予我们神力,让我们观测到了两个潜在结果,并收集到了下面六个企业的销售数据,其中三个采取了促销,另外三个没有。
下面的表中, i i i 是分析单元; y y y 是观测到的结果, y 0 y_0 y0 和 y 1 y_1 y1 是我们对照和干预的两个潜在结果; t t t 是干预,此处就是是否采取促销; x x x 是距离圣诞节的周数。
pd.DataFrame(dict(
i= [1,2,3,4,5,6],
y0=[200,120,300, 450,600,600],
y1=[220,140,400, 500,600,800],
t= [0,0,0,1,1,1],
x= [0,0,1,0,0,1],
)).assign(
y = lambda d: (d["t"]*d["y1"] + (1-d["t"])*d["y0"]).astype(int),
te=lambda d: d["y1"] - d["y0"]
)
| i | y0 | y1 | t | x | y | te |
|---|---|---|---|---|---|---|
| 1 | 200 | 220 | 0 | 0 | 200 | 20 |
| 2 | 120 | 140 | 0 | 0 | 120 | 20 |
| 3 | 300 | 400 | 0 | 1 | 300 | 100 |
| 4 | 450 | 500 | 1 | 0 | 500 | 50 |
| 5 | 600 | 600 | 1 | 0 | 600 | 0 |
| 6 | 600 | 800 | 1 | 1 | 800 | 200 |
使用神力,我们同时获取了 w e e k l y _ a m o u n t _ s o l d 0 weekly\_amount\_sold_0 weekly_amount_sold0 和 w e e k l y _ a m o u n t _ s o l d 1 weekly\_amount\_sold_1 weekly_amount_sold1,这样就能容易地计算之前说过的各种因果量。ATE就是上表中最后一列的均值,ATE=65,也就是说促销使得周销售额平均增长了65。ATT就是当t=0时最后一列的均值,ATT=83.33,也就是说对于选择促销的商家,促销使得他们的周销售额平均增加了83.33。限制距离圣诞节1周的数据,即x=1,CATE就是商家3和6最后一列的均值,CATE=150;限制圣诞节当周的数据,即x=0,CATE=22.5;也就是说提前一周促销使得周销售额平均增加150,当周促销使得周销售额平均增加22.5;所以商家早点促销比晚点促销要好。
上面的例子很美好,现实世界的数据处理起来更加困难。
pd.DataFrame(dict(
i= [1,2,3,4,5,6],
y0=[200,120,300, np.nan, np.nan, np.nan,],
y1=[np.nan, np.nan, np.nan, 500,600,800],
t= [0,0,0,1,1,1],
x= [0,0,1,0,0,1],
)).assign(
y = lambda d: np.where(d["t"]==1, d["y1"], d["y0"]).astype(int),
te=lambda d: d["y1"] - d["y0"]
)
| i | y0 | y1 | t | x | y | te |
|---|---|---|---|---|---|---|
| 1 | 200.0 | NaN | 0 | 0 | 200 | NaN |
| 2 | 120.0 | NaN | 0 | 0 | 120 | NaN |
| 3 | 300.0 | NaN | 0 | 1 | 300 | NaN |
| 4 | NaN | 500.0 | 1 | 0 | 500 | NaN |
| 5 | NaN | 600.0 | 1 | 0 | 600 | NaN |
| 6 | NaN | 800.0 | 1 | 1 | 800 | NaN |
你无法同时观测到干预和不干预两种情况的数据。所以因果推断的另外一个名称为“数据缺失问题”。为了计算出因果量,必须推断出缺失的潜在结果。
单纯只看上面的数据,我们的脑海中可能会不由自主地冒出这样的解决方案:取t=1时的y的均值,减去t=0时y的均值,ATE=633.33-206.66=426.67。这种想法是错误的,是犯了1.4.2中提到的将关联关系当作因果关系的错误。再看看前面假设数据得到的ATE才65,两者相差300以上。想想原因也很简单,采用促销的商家和没有促销的商家是不同的,采用促销的商家不管是否促销,销售额可能都会很高,使用促销的商家的情况类比不促销的商家如果采用促销行为的可能情况,是会严重高估的。再看前面的假设数据,采用了促销的商家的 Y 0 Y_0 Y0 是远远高于没有促销的商家的。干预组和不干预组之间商家的巨大差异,使得直接将两组进行类比的做法变得更加困难。
虽然类比不是最聪明的做法,但是这种直觉是对的,需要使用因果的概念完善这种直觉。
1.5 偏差
偏差(Bias)是使关联关系不同与因果关系的关键。从数据中估算的结果与想要恢复的因果量不匹配,就像前面说的案例,促销的商家可能具有更大的规模,有更多的能力进行促销,不能简单地将促销商家的销售情况与不促销商家的情况进行类比。
使用因果推断的术语来描述上面的情况。
为了计算ATE,我们需要确定促销的商家如果不促销的结果的期望 E ( Y 0 ∣ T = 1 ) E(Y_0|T=1) E(Y0∣T=1),也需要确定没有促销的商家如果采取促销的结果的期望 E ( Y 1 ∣ T = 0 ) E(Y_1|T=0) E(Y1∣T=0)。
我们将两组商家的平均结果进行类比,使用 E ( Y ∣ T = 0 ) E(Y|T=0) E(Y∣T=0) 去估算 E ( Y 0 ) E(Y_0) E(Y0),使用 E ( Y ∣ T = 1 ) E(Y|T=1) E(Y∣T=1) 去估算 E ( Y 1 ) E(Y_1) E(Y1)。也就是使用 E ( Y ∣ T = t ) E(Y|T=t) E(Y∣T=t) 估算 E ( Y t ) E(Y_t) E(Yt)。
如果这两者不能匹配, E ( Y ∣ T = t ) E(Y|T=t) E(Y∣T=t) 就是 E ( Y t ) E(Y_t) E(Yt) 的有偏估算量(Biased Estimator)。
偏差 B i a s = E ( β ^ − β ) Bias=E(\hat\beta-\beta) Bias=E(β^−β), β ^ \hat\beta β^ 是有偏估算量, β \beta β 是实际量。
对于上面使用不干预组的结果类比干预组如果不干预的结果的偏差为:
B i a s 1 = E ( Y 0 ∣ T = 0 ) − E ( Y 0 ∣ T = 1 ) Bias_1=E(Y_0|T=0)-E(Y_0|T=1) Bias1=E(Y0∣T=0)−E(Y0∣T=1)
使用干预组的结果类比不干预组如果干预的结果的偏差为:
B i a s 0 = E ( Y 1 ∣ T = 1 ) − E ( Y 1 ∣ T = 0 ) Bias_0=E(Y_1|T=1)-E(Y_1|T=0) Bias0=E(Y1∣T=1)−E(Y1∣T=0)
1.5.1 偏差方程
促销的案例中,干预与结果的关联关系由 E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) E(Y|T=1)-E(Y|T=0) E(Y∣T=1)−E(Y∣T=0) 度量,因果关系由 E ( Y 1 − Y 0 ) E(Y_1-Y_0) E(Y1−Y0) 度量。 E ( Y 1 − Y 0 ) E(Y_1-Y_0) E(Y1−Y0) 是 E ( Y ∣ d o ( t = 1 ) − Y ∣ d o ( t = 0 ) ) E(Y|do(t=1)-Y|do(t=0)) E(Y∣do(t=1)−Y∣do(t=0)) 的简写。
我们使用潜在结果替换关联关系度量中的观测结果。对于干预组,观测结果为 Y 1 Y_1 Y1,非干预组为 Y 0 Y_0 Y0。
E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) = E ( Y 1 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) E(Y|T=1)-E(Y|T=0)=E(Y_1|T=1)-E(Y_0|T=0) E(Y∣T=1)−E(Y∣T=0)=E(Y1∣T=1)−E(Y0∣T=0)
对于干预组,如果没有干预,结果为 E ( Y 0 ∣ T = 1 ) E(Y_0|T=1) E(Y0∣T=1),这是一个反事实的结果。在上式中加上这个结果,再减去这个结果:
E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) = E ( Y 1 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) + E ( Y 0 ∣ T = 1 ) − E ( Y 0 ∣ T = 1 ) = E ( Y 1 ∣ T = 1 ) − E ( Y 0 ∣ T = 1 ) + E ( Y 0 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) = E ( Y 1 − Y 0 ∣ T = 1 ) ⏟ A T T + ( E ( Y 0 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) ) ⏟ − B i a s 1 \begin{aligned} E(Y|T=1)-E(Y|T=0)&=E(Y_1|T=1)-E(Y_0|T=0)+E(Y_0|T=1)-E(Y_0|T=1) \\ &=E(Y_1|T=1)-E(Y_0|T=1)+E(Y_0|T=1)-E(Y_0|T=0) \\ &=\underbrace{E(Y_1-Y_0|T=1)}_{ATT}+\underbrace{(E(Y_0|T=1)-E(Y_0|T=0))}_{-Bias_1} \end{aligned} E(Y∣T=1)−E(Y∣T=0)=E(Y1∣T=1)−E(Y0∣T=0)+E(Y0∣T=1)−E(Y0∣T=1)=E(Y1∣T=1)−E(Y0∣T=1)+E(Y0∣T=1)−E(Y0∣T=0)=ATT E(Y1−Y0∣T=1)+−Bias1 (E(Y0∣T=1)−E(Y0∣T=0))
*原书上式中的Bias前没有负号,应该是写错了
这个简单的数学公式包含了因果问题中的所有问题。
首先上式正说明了关联关系不是因果关系:关联关系等于干预效果+偏差。偏差是干预组与对照组在不干预时的结果 Y 0 Y_0 Y0 的差异。由于干预组的商家可能具有更高的实力,所以偏置项 − B i a s = E ( Y 0 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) -Bias=E(Y_0|T=1)-E(Y_0|T=0) −Bias=E(Y0∣T=1)−E(Y0∣T=0) 大概率大于0。偏差的产生是因为有些无法观察到的因素随着干预发生了变化。被干预的企业和对照组的企业在很多方面存在差异,例如规模、地点、选择促销的时间、管理风格、所在的城市等。要确定促销能增加多少销售金额,需要有促销和没有销售的企业在平均水平上彼此相似。换句话说,干预和对照的分析单元必须是可交换的。
一天一杯酒,医生远离我
一种流行的观点认为,适量饮酒对健康有益。这种观点认为,地中海文化,如意大利和西班牙,以每天喝一杯葡萄酒而闻名,也显示出很高的寿命。如果这种观点是从人们的体感中总结的,就很有可能是有问题的。如果葡萄酒能够延长寿命,将喝酒和不喝酒的人互换,该结论还是应该成立才行。但是意大利和西班牙都有慷慨的医疗保健体系,人类发展指数也相对较高,是无法和其他对比国家的人做到互换的。从技术角度来说, E ( l i f e s p a n 0 ∣ w i n e _ d r i n k i n g = 1 ) > E ( l i f e s p a n 0 ∣ w i n e _ d r i n k i n g = 0 ) E(lifespan_0|wine\_drinking=1)>E(lifespan_0|wine\_drinking=0) E(lifespan0∣wine_drinking=1)>E(lifespan0∣wine_drinking=0),所以偏差可能掩盖了真正的因果关系。
1.5.2 偏差的可视化
我们可以在直觉和数学上讨论可交换性(exchangeability),也可以绘制不同干预组的变量与结果的关系图来判断。在促销案例中,我们可以绘制结果,也就是周销售额weekly_amount_sold,和企业规模(使用周销售量avg_week_sales来衡量)的散点图,按照是否促销is_one_sale给不同的分析单元标注不同的颜色。从图中可以看出,有干预的企业更加其中在右边,说明他们通常规模更大。也就是说,干预组合不干预组在企业规模变量上是不平衡的。
plt.rc('font', size=20)
fig = plt.figure()
sns.lmplot(data=data,
ci=None,
x="avg_week_sales",
y="weekly_amount_sold",
scatter=False,
height=4, aspect=2)
plt.scatter(x=data.query("is_on_sale==1")["avg_week_sales"],
y=data.query("is_on_sale==1")["weekly_amount_sold"],
label="on sale",
color=color[0], alpha=.8, marker=marker[0])
plt.scatter(x=data.query("is_on_sale==0")["avg_week_sales"],
y=data.query("is_on_sale==0")["weekly_amount_sold"],
label="not on sale",
color=color[2], alpha=.6, marker=marker[1])
plt.legend(fontsize="14")
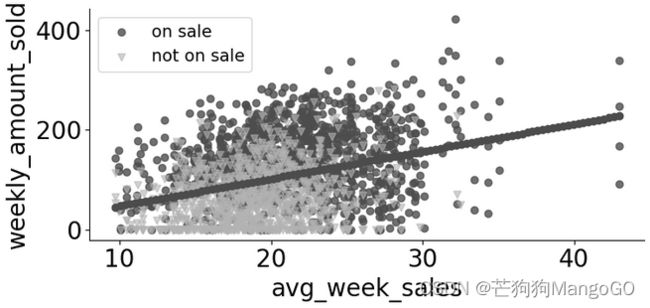
不管是干预组还是非干预组,趋势线的斜率都是大于0的,也就是这个变量对结果有向上的偏差。所以前面假设干预组如果不干预的潜在结果大于不干预组的结果是正确的, − B i a s = E ( Y 0 ∣ T = 1 ) − E ( Y 0 ∣ T = 0 ) > 0 -Bias=E(Y_0|T=1)-E(Y_0|T=0)>0 −Bias=E(Y0∣T=1)−E(Y0∣T=0)>0。
这个偏差就像是一个没那么极端的辛普森悖论。
辛普森悖论是指在两个或多个不同的分组中观察到的比例可能出现反向关系的现象。具体来说,当我们对整体数据进行分组后,某个因素的影响方向可能会发生改变。这种现象可能导致对数据的分析和结论得出错误的结果。例如,当观察整体数据时,因素A与结果X呈现正相关关系;但是,当对数据进行分组后,每个子组中因素A与结果X的关系都变成了负相关关系。这种情况下,对整体数据进行简单的聚合和分析可能会导致错误的结论。
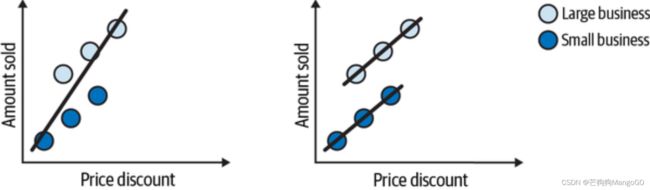
在我们的例子中,偏差不会极端到翻转关联的正负号。下图左边展示了整体上促销和销售额的关系,斜率是很高的。右边是控制了第三个变量(企业规模),按照企业规模分组后,每组的斜率降低了。
再列举一个虚构的、更明显的例子,可以使用偏差来解释。下图也是销售额和企业规模的关系图,企业规模越大,销售额越大。实心点为没有促销的企业,空心点是有促销的企业。如果简单地处理干预组和未干预组的平均销售额,会得到这样的结果:
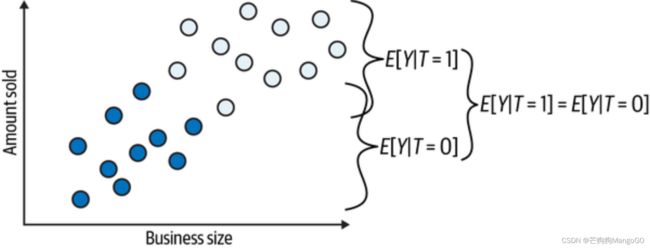
*上图中的等号应该改成减号
两组销售额差异的原因可能是:
- 干预效果
- 企业规模
因果推断的挑战在于解开这两个原因。
将这个结果与另外的潜在结果放到一起,反事实的结果使用倒三角表示。个体干预效果就是每个个体分析单元干预与不干预两种情况的结果的差值。平均干预效果就是所有分析单元潜在结果的平均差异 Y 1 − Y 0 Y_1-Y_0 Y1−Y0。这个个体平均差异明显比上图中的两组的差异小很多。造成这两种情况的原因就是偏差,如下图右边所示。
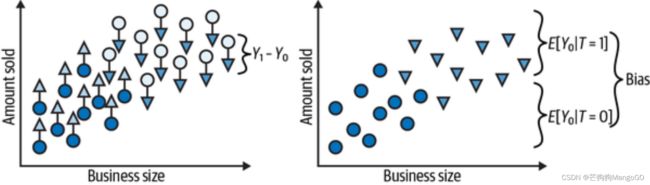
可以通过设置每个分析单元都不接受干预来表示偏差。在这种情况下,只剩下 Y 0 Y_0 Y0 潜在结果。然后,可以看到干预组和未干预组在未干预情况下的潜在结果有何不同。如果有,那么是干预以外的东西导致了干预组和未干预组的不同。这正是偏差,它遮蔽了真正的干预效果。
1.6 识别干预效果
了解了上面描述的问题,现在来看看一种解决方案。识别(Identification)是所有因果推断的第一步:从可观测数据中发现因果量。例如,使用 E ( Y ∣ T = t ) E(Y|T=t) E(Y∣T=t) 去发现 E ( Y t ) E(Y_t) E(Yt),这样就能简单地通过估算 E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) E(Y|T=1)-E(Y|T=0) E(Y∣T=1)−E(Y∣T=0) 来计算 E ( Y 1 ) − E ( Y 0 ) E(Y_1)-E(Y_0) E(Y1)−E(Y0),也就是通过估算干预组和非干预组的能观测到的平均结果达到目的。
另请参阅
2010-2020年,朱迪亚·珀尔(Judea Pearl)和他的团队普及了因果识别的知识体系,在因果推断语言的统一上做出了努力。本章及第3章使用了其中部分语言,虽然可能是不同的版本。如果想了解更多这个因果推断语言,可以去看这个Paul Hunermund和Elias Bareinboim撰写的简短但很酷的论文《Causal Inference and Data Fusion in Econometrics》。
也可以将识别看做是摆脱偏差的过程。通过潜在结果,也能知道什么是对将关联关系变成因果关系的关键。如果 E ( Y 0 ∣ T = 0 ) = E ( Y 0 ∣ T = 1 ) E(Y_0|T=0)=E(Y_0|T=1) E(Y0∣T=0)=E(Y0∣T=1),那么关联关系就是因果关系。因为 E ( Y 0 ∣ T = 0 ) = E ( Y 0 ∣ T = 1 ) E(Y_0|T=0)=E(Y_0|T=1) E(Y0∣T=0)=E(Y0∣T=1) 意味着,不管干预还是不干预,干预组和对照组是可类比的,偏差项会消失,只剩下干预的效果。
E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) = E ( Y 1 − Y 0 ∣ T = 1 ) = A T T E(Y|T=1)-E(Y|T=0)=E(Y_1-Y_0|T=1)=ATT E(Y∣T=1)−E(Y∣T=0)=E(Y1−Y0∣T=1)=ATT
并且,干预组和不干预组对干预的反应相同,即 E ( Y 1 − Y 0 ∣ T = 1 ) = E ( Y 1 − Y 0 ∣ T = 0 ) E(Y_1-Y_0|T=1)=E(Y_1-Y_0|T=0) E(Y1−Y0∣T=1)=E(Y1−Y0∣T=0),那么均值之差就变成了平均因果效果:
E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) = A T T = A T E = E ( Y 1 − Y 0 ) E(Y|T=1)-E(Y|T=0)=ATT=ATE=E(Y_1-Y_0) E(Y∣T=1)−E(Y∣T=0)=ATT=ATE=E(Y1−Y0)
上面的推导就是说,一旦让干预组和对照组互换,使用观测数据来计算因果量就很容易了。对于案例来说,就是促销和不促销的企业互相类似,也就是可交换的,那么这促销和不促销的两组销售额的差值就完全由促销导致的。
1.6.1 独立假设(Independence Assumption)
可交换性是因果推断的关键假设,不同的科学家对其有不同的陈述方式,本书使用最普遍的方式:独立假设(Independence Assumption)。这里,我们明确潜在结果与干预是独立的: ( Y 0 , Y 1 ) ⊥ T (Y_0,Y_1)\perp T (Y0,Y1)⊥T。
独立的意思是 E ( Y 0 ∣ T ) = E ( Y 0 ) E(Y_0|T)=E(Y_0) E(Y0∣T)=E(Y0),即干预不会给你关于潜在结果的信息,一个没被干预的分析单元,如果被干预,不表示其潜在结果 ( Y 0 ) (Y_0) (Y0) 将会有更高或更低的结果。这也可以使用公式 E ( Y 0 ∣ T = 1 ) = E ( Y 0 ∣ T = 0 ) E(Y_0|T=1)=E(Y_0|T=0) E(Y0∣T=1)=E(Y0∣T=0) 来表示。在商店促销的案例中,意味着你不能识别没有促销的企业有没有参与促销。抛开干预和干预对结果的影响,这些企业看起来是一样的。同样, E ( Y 1 ∣ T ) = E ( Y 1 ) E(Y_1|T)=E(Y_1) E(Y1∣T)=E(Y1) 表示你也不能分清参与了促销的企业到底有没有参与促销。简而言之,干预组和对照组是类似的、难以区分的,不管他们是否被干预。
1.6.2 使用随机化进行识别
上面假设了独立性条件,让关联关系变成了因果关系,但是我们还不知道如何使这个条件成立。
因果推断问题一般分成两个步骤:
- 识别:从观测数据中表示因果量
- 估算:用数据估算确定的因果量
用一个简单的例子说明这个过程。前面我们说过,假如我们正在为一个在线销售平台工作,平台入驻的商家有完全的定价权,但是我们可以随机化干预是否促销is_on_sale。例如,我们可以和商家谈判,强迫他们降价,但是平台会为此支付差价。那么我们应该如何随机化促销呢?
随机化就像是抛硬币,使得干预与因果机制中其他任何变量没有任何关系:
i s _ o n _ s a l e ← r a n d ( t ) w e e k l y _ a m o u n t _ s o l d ← f y ( i s _ o n _ s a l e , u y ) is\_on\_sale \leftarrow rand(t) \\ weekly\_amount\_sold \leftarrow f_y(is\_on\_sale, u_y) is_on_sale←rand(t)weekly_amount_sold←fy(is_on_sale,uy)
随机化 u t u_t ut 从模型中消失了,因为干预的赋值过程变成了已知。而且,干预变成了随机,与任何事情都是独立的关系。随机化保证独立性成立。
为了更清楚地说明这一点,让我们看看随机化是如何消除偏差的。下面图片的左边显示了尚未成为现实的潜在结果(薛定谔的三角形,随机干预之前处于未知状态。实心表示不干预对应的潜在结果,空心表示干预的潜在结果):
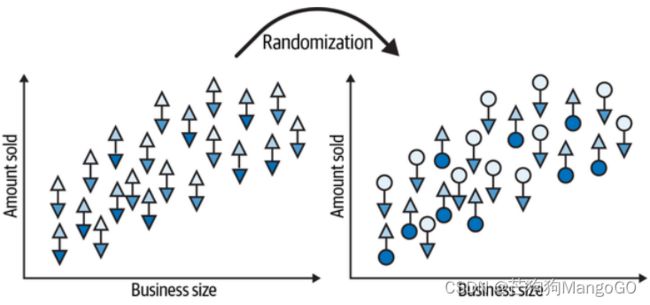
然后随机实施干预,也就是对每个分析单元的两种潜在结果进行随机选择,选择干预的分析单元的空心三角变成空心圆形,选择不干预的分析单元的实心三角变成实心圆形,如上图右边所示(圆形表示随机干预后事实,三角形表示反事实)。
随机(Randomized) vs 观测(Observational)
在因果推理中,我们使用术语随机来谈论干预是随机的或赋值过程是完全已知和不确定的数据。与此相反,观测这个术语是用来描述你可以看到谁得到了什么干预的数据,但你不知道干预是如何赋值的。
将上图中的未实现的潜在结果(反事实)剔除,只留下能观测到的情况。现在可以比较干预和不干预的情况:
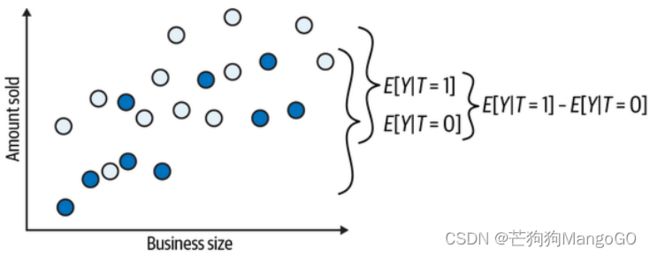
这样,干预组和未干预组结果的差异就是平均因果效应。因为除了干预外,两组没有其他因素是有差异的,所以全部的差异都应该归因于干预。如果我们将干预组的未干预潜在结果与未干预组的结果放在一起,会发现是没有偏差的:

这就是因果识别的全部内容。寻找方法消除偏差,是干预组和对照组具有可比性,这样所有的差异偶读可以归因为干预的效果。只有当我们了解(或愿意假设)有关数据生成过程的一些信息时,才能进行识别,通常就是干预是如何赋值的。这就是为什么之前说只使用数据是无法回答因果问题的。当然,数据在估算因果效应的过程中是很重要的,但是在数据之外,我们总是需要表述数据是如何产生的,尤其是干预的产生。我们使用专业知识,介入这个世界,得到符合我们表述的情况,影响干预的赋值,然后观测结果是如何变化反馈的。
令人惊艳的会员计划
一家大型在线零售商实施了一项会员计划,会员支付额外费用就可以获得更多折扣、更快的送货、免退货和出色的客户服务。为了了解该计划的影响,该公司对客户进行了随机抽样,这些客户可以选择支付费用以获得会员福利。过了一段时间,他们发现从参加会员计划的顾客身上能挣到比对照组的顾客更多的钱。这些顾客不仅买得多,而且花在客户服务上的时间也减少了。那么我们是否应该说会员计划在增加销售额和减少客户服务时间方面取得了巨大的成功?
并非如此。虽然该计划的资格是随机的,但是任然需要被选中的群体自愿加入该计划。换句话说,项目资格的随机化确保了获得资格的人与没有获得资格的人具有可比性。但是,在符合条件的人中,只有一小部分选择参加。这个选择不是随机的。可能只有那些更投入的顾客才会选择参与,而那些漫不经心的顾客则会退出。所以,尽管获取资格是随机的,但参与项目却不是随机的。结果是,那些参与的人与那些没有参与的人没有可比性。
认真想一下,哪些获取资格并愿意加入的人,可能正是因为原本就消费较高,参与项目能让额外的折扣变得更加物有所值。这就意味 E ( R e v e n u e s 0 ∣ O p t I n = 1 ) > E ( R e v e n u e s 0 ∣ O p t I n = 0 ) E(Revenues_0|OptIn=1)>E(Revenues_0|OptIn=0) E(Revenues0∣OptIn=1)>E(Revenues0∣OptIn=0),就是不管有没有加入项目,加入的顾客都是会给平台上带来更多的价值。
最终,因果推理是关于找出世界是如何运作的,剥离了所有的错觉和误解。既然你明白了这一点,你就可以继续掌握一些最有力的勇敢和真实的工具来消除偏见,来识别因果关系。
1.7 要点总结
我们已经学习了因果推断的数学语言,本书的其余部分将继续使用这些数学语言来讨论因果推断。重要的是,我们已经了解了潜在结果的定义,即如果该分析单元采取指定干预 T = t T=t T=t,将观察到的结果:
Y t i = Y i ∣ d o ( T i = t ) Y_{ti}=Y_i|do(T_i=t) Yti=Yi∣do(Ti=t)
潜在结果对于理解为什么关联不同于因果关系非常有用。也就是说,干预组和未干预组由于干预以外的原因会产生差异, E ( Y 0 ∣ T = 1 ) ≠ E ( Y 0 ∣ T = 0 ) E(Y_0|T=1) \not= E(Y_0|T=0) E(Y0∣T=1)=E(Y0∣T=0),两组之前的对比不会产生真正的因果效应,而是一个有偏差的估算。我们还使用潜在结果来看看需要什么才能使关联关系等于因果关系:
( Y 0 , Y 1 ) ⊥ T (Y_0,Y_1) \perp T (Y0,Y1)⊥T
当干预组和对照组可以互换或比较时,就像我们随机给干预赋值时,对干预组和未干预组的结果进行简单的比较就会得出干预效果:
E ( Y 1 − Y 0 ) = E ( Y ∣ T = 1 ) − E ( Y ∣ T = 0 ) E(Y_1-Y_0)=E(Y|T=1)-E(Y|T=0) E(Y1−Y0)=E(Y∣T=1)−E(Y∣T=0)
我们也开始理解做因果推理时需要一些关键的假设。例如,为了在估算干预效果时不产生任何偏差,我们假设干预的赋值和潜在结果之间是独立的, T ⊥ Y t T \perp Y_t T⊥Yt。
我们也假设对一个分析单元的干预不会影响另一个分析单元的结果(SUTVA),而且干预的所有可能情况都应该被覆盖(如果 Y i ( t ) = Y Y_i(t)=Y Yi(t)=Y,那么 T i = t T_i=t Ti=t),当我们用定义结果 Y Y Y 为潜在结果之间的转化函数:
Y i = ( 1 − T i ) Y 0 i + T i Y 1 i Y_i=(1-T_i)Y_{0i}+T_iY_{1i} Yi=(1−Ti)Y0i+TiY1i
一般来说,因果推断总是需要假设。有了假设,我们才能使用统计估算量来恢复我们想了解的因果量。
系列文章专栏:
使用Python进行因果推断(Causal Inference in Python)
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
【参考】
原版书籍《Causal Inference in Python: Applying Causal Inference in the Tech Industry》
原书github代码