基于社区电商的Redis缓存架构-缓存数据库双写、高并发场景下优化
基于社区电商的Redis缓存架构
首先来讲一下 Feed 流的含义:
Feed 流指的是当我们进入 APP 之后,APP 要做一个 Feed 行为,即主动的在 APP 内提供各种各样的内容给我们
在电商 APP 首页,不停在首页向下拉,那么每次拉的时候,APP 就会根据你的喜好、算法来不停地展示新的内容给你看,这就是电商 APP 的 Feed 流了
那么接下来呢就基于首页 Feed 流以及社区电商 APP 中的一些业务场景,来实现一套基于 Redis 的企业级缓存架构,MySQL 为基础,RocketMQ 为辅助
那么在缓存中常见的问题有:
- 热 key 问题
- 大 key 问题
- 缓存雪崩(穿透)
- 数据库和缓存数据一致性问题
在 Redis 生产环境中,也存在一些问题,如下:
- Redis 集群部署,需要进行高并发压测
- 监控 Redis 集群:每个节点数据存储情况、接口 QPS、机器负载情况、缓存命中率
- Redis 节点故障的主从切换、Redis 集群扩容
下边我们来逐个剖析在缓存架构中常见的一些问题
首先,热 key 举个例子就是微博突然某个明星出现新闻,那么会有大量请求去访问这个数据,这个 key 就是热 key
大 key 指的是某个 key 所存储的 value 很大,value 多大 10 mb,那么如果读取这个大 key 过于频繁,就会对网络带宽造成影响,阻塞其他请求
缓存雪崩是因为大量缓存数据同时过期或者 Redis 集群故障,如果因为缓存雪崩导致 Redis 集群都崩掉了,那么此时只有数据库可以访问,我们的系统需要可以识别出来缓存故障,立马对各个接口进行限流、降级错误,来保护数据库,避免数据库崩掉,可以在 jvm 内存缓存中存储少量缓存数据,用于在 Redis 崩了之后提供降级备用数据,那么流程为:限流 --> 降级 --> jvm 缓存数据
读多写少数据缓存
那么我们先来分析一下在社区电商中,用户去分享一个内容时,如何操作缓存:
- 用户分享内容
- 加锁:针对用户 id 上分布式锁,避免同一用户重复请求,导致数据重复灌入
- 将用户分享内容写入数据库
- 将用户的个人信息在缓存写一份
(用户信息在注册后一般不会变化,读多写少,因此用户信息非常适合放入缓存中),这样在后续高并发访问用户的数据时,就可以在缓存中进行查询,根据用户前缀 + 用户 id 作为 key,并设置缓存过期时间,过期时间可以设置为 2 天加上随机几小时(添加随机几小时的原因是避免同一时间大量缓存同时过期) - 释放锁
缓存自动延期以及缓存穿透
那么上边我们已经对用户的个人信息进行了缓存,那么某些热门的用户是经常被很多人看到的,而有些冷门用户的内容没多少人看,因此将用户信息的缓存过期时间设置为 2天+随机几小时 ,因此我们针对热门的用户信息数据,要做一个缓存自动延期,因此只要访问用户数据,那么就对该缓存数据进行一个延期,流程如下:
- 获取用户个人信息
- 根据
用户前缀 + 用户id作为 key 去缓存中查询用户信息
public UserInfo getUserInfo(Integer userId) {
// 读缓存
String userInfoJson = redisCache.get("user_info_lock:" + userId);
if (!StringUtils.isEmpty(userInfoJson)) {
// 取到的是空缓存 避免一致访问数据库不存在的数据导致缓存穿透
if ("{}".equals(userInfoJson)) {
// 延期缓存
redisCache.expire("user_info_lock:" + userId, expireSecond);
return null;
} else {
// 延期缓存
redisCache.expire("user_info_lock:" + userId, expireSecond);
UserInfo userInfo = JSON.parseObject(productStr, UserInfo.class);
}
}
// 如果缓存中没有取到数据,则在数据库中查,并放入缓存
lock("user_lock_prefix" + userId); // 上分布式锁 伪代码
try {
// 读数据库
UserInfo userInfo = userInfoService.get(userId);
if(userInfo != null) {
// 如果用户信息不为空,就将用户数据写入缓存
redisCache.set("user_info_lock:" + userId, JSON.toJSONString(userInfo), expireSecond);
} else {
// 如果数据库为空,写入一个空字符串即可
redisCache.set("user_info_lock:" + userId, "{}", expireSecond);
}
} finally {
unlock("user_lock_lock:" + userId); // 解锁
}
}
缓存+数据库双写不一致
在上边存储用户个人信息时,使用的是 缓存+数据库双写,这样可能造成数据不一致性,如下:
有两个线程并发,一个读线程,一个写线程,假设执行流程如下,会造成双写不一致
- 当读线程去缓存中读取数据,此时缓存中数据正好过期,那么该线程就去读数据库中的数据
- 此时写线程开始执行,修改用户信息,并且写入数据库,再写入缓存
- 此时读线程再接着执行,将之前在数据库中读取的旧数据写入缓存,覆盖了写线程更新后的数据
造成这种情况的原因是,在读的时候,加的是读锁,key 为 user_info_lock:,在写的时候,加的是写锁,key 为 user_update_lock:,那么读写就可以并发
想要解决的话,可以让读和写操作加同一把锁,让读写串行化,就可以了,如下:
让读和写都加同一把锁:user_update_lock
- 针对先读后写的情况,就不会出现双写不一致了,读的时候先加上锁
user_update_lock,此时缓存假设正好过期,去数据库中读取数据,此时写线程开始执行,阻塞等待锁user_update_lock,此时读线程再去数据库读取数据放入缓存,结束后释放锁,那么写线程再拿到锁操作数据库,再将数据写入缓存,那么缓存中的数据是新数据 - 针对先写后读的情况,也不会出现双写不一致,在写的时候,加上锁
user_update_lock,那么在并发读的时候,先获取缓存内容,如果获取不到,尝试去 DB 中获取,此时就会阻塞等待锁user_update_lock,在写线程写完之后更新了缓存,释放锁,此时读线程就拿到了锁,此时在去数据库中查数据之前再加一个double check(双端检锁)的操作,也就是再尝试去缓存中取一次数据,如果取到了就返回;如果没有取到,就去数据库中查询
那么完整的写和读操作流程如下图:

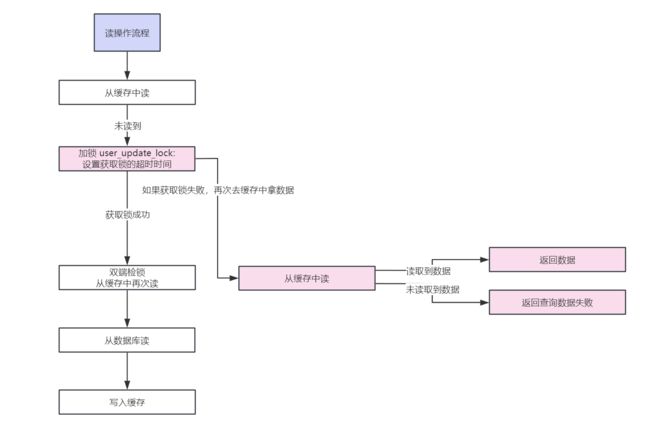
高并发场景下优化
在上边我们已经使用读写加同一把锁来实现缓存数据库双写一致了
但是还存在一种极端情况:某一个用户的信息并不在缓存中,但是突然火了,大量用户来访问,发现缓存中没有,那么大量用户线程就阻塞在了获取锁的这一步操作上,导致大量线程串行化的来获取锁,然后再到缓存中获取数据,下一个线程再获取锁取数据
这种情况的解决方案就是给获取锁加一个超时时间,如果在 200ms 内没有拿到锁,就算获取锁失败,这样大量用户线程获取锁失败,就会从串行再转为并发从缓存中取数据了,避免大量线程阻塞获取锁
完整流程图如下,粉色部分为优化:
代码如下:
private UserInfo getUserInfo(Long userId) {
String userLockKey = "user_update_lock:" + userId;
boolean lock = false;
try {
// 尝试加锁,并设置超时时间为 200 ms
lock = redisLock.tryLock("user_update_lock:", 200);
} catch(InterruptedException e) {
UserInfo user = getFromCache(userId);
if(user != null) {
return user;
}
log.error(e.getMessage(), e);
throw new BaseBizException("查询失败");
}
// 如果加锁超时,就再次去缓存中查询
if (!lock) {
UserInfo user = getFromCache(userId);
if(user != null) {
return user;
}
// 缓存数据为空,查询用户信息失败,因为用户没有拿到锁,因此也无法取 DB 中查询
throw new BaseBizException("查询失败");
}
// 双端检锁,如果拿到锁,再去缓存中查询
try {
UserInfo user = getFromCache(userId);
if(user != null) {
return user;
}
String userInfoKey = "user_info:" + userId;
// 数据库中查询
user = userService.getById(userId);
if (Objects.isNull(user)) {
redisCache.set(userInfoKey, "{}", RandomUtil.genRandomInt(30, 100));
return null;
}
// 缓存时间设置为 2 天 + 随机几小时
redisCache.set(userInfoKey, JSON.toJSONString(user), 2 * 24 * 60 * 60RandomUtil.genRandomInt(0, 10) * 60 * 60);
return user;
} finally {
redisLock.unlock(userLockKey);
}