AI模型训练——入门篇(一)
前言
一文了解NLP,并搭建一个简单的Transformers模型(含环境配置)
一、HuggingFace 与NLP
自从ChatGPT3 问世以来的普及性使用,大家或许才真正觉察AI离我们已经越来越近了,自那之后大家也渐渐的开始接触stable diffusion、midjourney和vits …等等各类AI大模型,它覆盖了图、音、文、像各个网络领域。曾经出现在科幻片里的镜头,正在逐步成为现实。公司的前线开发人员、学校上学的学生、各行各业的人们都在这个时代尝试着学习AI,各类网站关于AI的知识也比比皆是,毋庸置疑,大家都在积极的拥抱其带给我们的变化。那身为一线开发人员的我们,更要去了解它,使用它,才能紧跟时代步伐。但要学好一门新事物,我们就要知其然,然后才能知其所以然。
不同类型的人工智能采用了各种不同的技术和方法,目前比较火的GPT则涉及了自然语言处理(NLP),顾名思义,是用来处理自然语言的模型(自然语言:人类日常所说的话),它可以用来摘要、翻译、情感分析…但我们也要明确,NLP它是一种”能力“而不是一种”方案“。这两者听起来相似,但其实是完全不同的。“能力”注重的是过程,“方案”注重的是结果。既然它是一种能力,也就是说我们要训练它,以达到能够进行类比分析的境界,而不是只为了解决当下的某一问题。举个例子或许你就会明白了,就像我们上学时学数学,我们学习了一个公式,通过发散思维,我们就可以利用它解决N+问题;但如果只是单纯背会了一道题的解题步骤,下次题稍微一变形就不会做了。这就是“能力——过程”与“方案——结果”的差别,读到这里,我相信你对于抽象的NLP已经有了一个初步的认知。
继续拿人类举例,就像是学生时代的我们,可能会背公式的人有 10 个,但是真正能发散思维解决各类问题的人也就 5 个。NLP也一样,有能力强差之分的。那在NLP的世界里,什么决定了它的能力水平呢?想一想我们会通过背大量的公式去提分吗?不会,大家一般都会在学习一个公式之后,通过做大量能用此公式解题的类型题,培养出相应的思维。诶!想到这那就简单了,NLP也是同样的道理,决定NLP能力的关键点其实就是数据量和参数量。所以对于开发人员来说,独自训练一个优秀的模型,简直是难于上青天,因为我们根本没有那么大量的数据集去供我们使用,那么我们自己能玩点什么呢?我们可以去用其他人训练好的模型,在应用层下手,这就好比我们可以不用将一个婴儿培养到高中,然后去让他做高中的题,而是我们直接去找一个高中生去做高中题,一切都显得简单起来了,不是吗?
那我们应该怎么开始入手 NLP呢?有了上文的铺垫,其实可以推理出对于开发者个体来说,想要快速取得一定成就,可以不去学习海量的传统算法(当然万事无绝对,功底深厚大佬除外), 业界已经有很多开箱即用的模型,像我这种小白…只要在这个基础上,继续发挥,站在巨人的肩膀上,才是理智的。
铺垫到此结束,有了上文,相信你一定已经很清楚的知道NLP是什么,并且也知道如何去学它了,接下来就请出我们的主角——HuggingFace。它就是我刚才所说的“巨人”——一个开箱即用的,包含了NLP所有核心模型的仓库,我们甚至只要使用一行代码,就可以调用一个很强的模型,喂一点我们的数据,就可以达到我们的想要的效果!怎么样,听到这我相信你一定很动心了,即便你的数学知识不好(传统算法里有很多数学概念),即使你的代码水平也一般般,甚至说是非 T族,对于代码只是略知一二,也是可以上手训练出一个属于你的模型~
二、来聊聊HuggingFace的诞生历程
大家绝对不会想到成立于 2016 年的HuggingFace,最初的开发者仅仅只有 30 位左右,而且还是兼职。那他们是怎么做到短短几年就创建了一个市值几十亿的公司呢?早几年的时候,对于NLP领域的研究还没有什么统一的标准或者规范。拿两个大厂举例,比如说Chrome,在当时使用的是TensorFlow,而 Facebook 使用的是PyTorch,还有一些中小厂也在使用各式各样的框架,大家若想要使用TensorFlow就必须去应用Chrome的源码,使用PyTorch就必须去应用Facebook的源码,复杂得很。也正是这种各自为政的现象,导致了整体行业发展受阻。于是,HuggingFace就提出来统一的思想,将个大中小厂的框架封装起来,无论你想用哪一个,直接调用HuggingFace提供的接口,就可以获取到想要的资源了。后来随着AI发展的火热,HuggingFace作为其元老级别的开源社区,也就理所当然的成为了业界唯一。
三、HuggingFace初体验
3.1环境安装
从上图中可以看到几大仓库的语言都是 Python,所以我们要配置Python 环境,这里直接用了 Miniconda,它比起Anaconda更轻便。以 mac 为例:
Miniconda安装
安装地址: https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
大家可以根据自己的芯片以及习惯的安装方式下载对应包(X86_64:Inter芯片;arm64:Apple 芯片 ;.pkg:可视化安装;.sh:命令行安装)
本文用命令行继续进行安装,安装的版本是 py39。

安装好后,打开终端,进入.sh文件所在的路径下 ,输入一下命令:
代码如下(示例):
// 其中sh后填sh文件名,-b表示将环境变量自动写入到~/.bash文件,-p后面填安装路径
sh Miniconda3-py39_22.11.1-1-MacOSX-x86_64.sh -b -p ~/WorkSpace/SoftWare/miniconda
将miniconda路径写入shell配置。
source ~/WorkSpace/SoftWare/miniconda/bin/activate
此时若配置成功,则在命令行中看到有一个(base)前缀,如下图
![]()
初始化(shell类型可以在终端键入echo $SHELL 进行查看)
conda init zsh
//这里根据 shell 类型自行选择
conda init bash
最后重新打开终端就安装完毕了。(这里一定要重新启动一下,否则可能不好使,然后输入 conda ,若出现一下界面则安装成功)

conda环境创建
命令行输入(指定版本为py 3.9,版本过高可能会出错)
conda create -n transformers python=3.9
执行命令后,会询问是否安装一些包,键入y 即可。
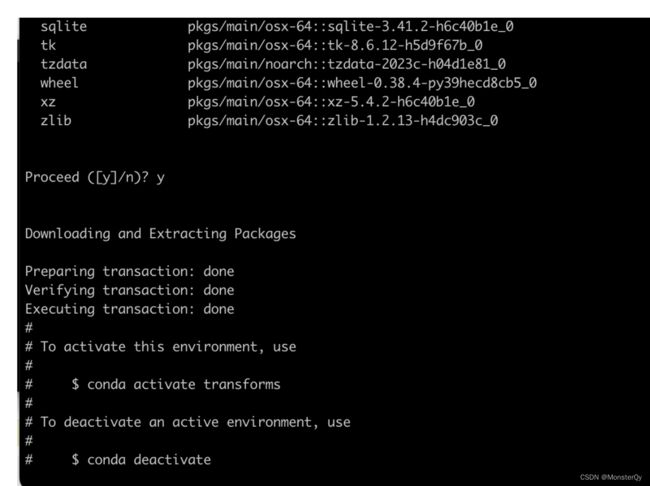
// 查看有哪些虚拟环境
conda env list

可以看到,刚才创建的 transforms 已经存在于环境列表中了。至此,虚拟环境就已经创建成功了。然后进入该环境下:
conda activate transformers
可以看到此时已经成功进入新建的transformers 环境。
为了提速日后安装包的速度,可以将 pypi 配置清华的国内源,网址如下 https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
这里,我直接设置为默认了。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pytorch环境安装
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。官网为: https://pytorch.org/ 这里我们最好选择 pip 安装,30xx 40xx显卡注意要安装cu11的版本
按照机器配置选择自己需要安装,
pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1
依赖包安装
直接在终端中 pip install(这里安装了一些NLP训练中常用的,可以自己取舍,下文的 demo 只用到了transformers)
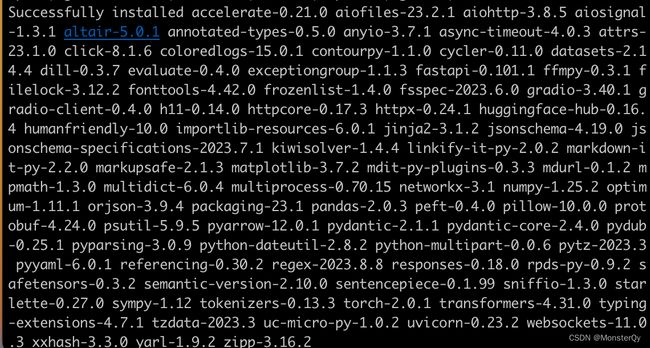
pip install transformers evaluate peft datasets accelerate gradio optimum sentencepiece
看到 sucessfully就证明安装成功了
(ps:一点插曲)这里或许是因为我的电脑问题,在输入安装transformers命令后一直报错,如下图:

我尝试着按照提示 update 了 pip,仍是没有什么用…后来通过安装rus t解决了此问题
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
其他要用到的包安装:
pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge
安装成功也是会提示 successfuly。
配置 hosts文件
为了后期下载模型方便,在这里做一下 host 映射:
终端输入:
sudo vi /etc/hosts
添加一下代码:
185.199.108.133 raw.githubusercontent.com
185.199.109.133 raw.githubusercontent.com
185.199.110.133 raw.githubusercontent.com
185.199.111.133 raw.githubusercontent.com
2606:50c0:8000::154 raw.githubusercontent.com
2606:50c0:8001::154 raw.githubusercontent.com
2606:50c0:8002::154 raw.githubusercontent.com
2606:50c0:8003::154 raw.githubusercontent.com
然后 wq 保存一下即可。
3.2Transformers初体验(图生文)
经过上述的一系列操作我们已经可以成功在自己的电脑上简单的训练模型了,这里的编译器使用的是 Vscode,在应用商店下载Python 、Remote-SSH和Jupyter 三个插件即可:

登录HuggingFace官方网址 https://huggingface.co/models 下可以查看到目前所有的 transformers 的模型~如下图所示,选择一个图像转文本的功能,可以看到共有 223 个模型供我们使用。
假设我们选择Salesforce/blip-image-captioning-base 然后打开 Vscode ,传入一张图片,输入以下代码,
from transformers import pipeline
def imgToText(url):
image_to_text = pipeline("image-to-text", model="Salesforce/blip-image-captioning-base")
text = image_to_text(url)[0]["generated_text"]
print(text)
return text
imgToText("./test.jpeg")
test.jpeg:

运行代码在终端输出的结果:
![]()
(ps:调试过程中产生的坑点)运行 py 文件的时候,一定要选择安装了对应 pip 包的环境,因为我电脑上有好几种 py 版本,而我的 pip 包安装在了 conda transformers 虚拟环境中,vscode 默认运行的时候加载了我的全局 py,就会导致找不到想要 import 的包,这里推荐一个vscode插件。


可以清楚的看到,自己的 py 版本,输入 pip list 就可以查看当前 py 环境下的 pip 有哪些,然后 ctrl+p 打开设置搜索,设置python 解释器为有所需要的 pip 包的 py 环境即可解决安装成功但是找不到包的情况啦~
