python笔记爬虫
目录标题
- request库
-
- request库的get方法
- Response对象的属性
-
- http状态码
- Response的编码
- request异常
- 爬取网页的通用代码框架
- Requests库的7个主要方法
- HTTP协议
- 网络图片格式
- 例子
-
- 第一周单元三实例二
-
- 对网络爬虫的限制
- 用程序模拟浏览器对亚马逊进行请求
- 第一周单元三实例三
-
- 对百度
- 对360
- 第一周单元三实例四
- beautiful soup
-
- beautiful soup库
-
- 例子(demo)
- 解析器
- beautiful soup库的基本元素
-
- 将demo进行解析
-
- 例子
- 标签树形结构
- 标签树下行遍历
-
- 代码
- 标签树上行遍历
- 标签树平行遍历
-
- 代码1
- 代码2
- prettify方法
- bs4库的编码
- 信息标记形式
-
- xml
- json
- yaml
- 例子
- find_all
-
- name
- attrs
- recursive
- string
- 扩展方法
- 实例
-
- 大学排名
- html
-
- html例子1:
- html例子2:
-
- 表格1:
- 表格2:(加入边框,边框数字可变)
- 下划线,换行,加粗,斜体
- 图片
-
- div
request库
request库的get方法
统一资源定位符(Uniform Resource Locator)”简称为URL。URL是web页的地址。

Response对象的属性

http状态码
r.status_code
http状态码

HTTP响应状态码
Response的编码

request异常


爬取网页的通用代码框架

import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引友HTTPError异吊
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url ="http://www.baidu.com"
print(getHTMLText(url))
Requests库的7个主要方法

HTTP协议
HTTP, Hypertext Transfer Protocol,超文本传输协议。
操作功能






网络图片格式
例子
第一周单元三实例二
import requests
r = requests.get("https://www.amazon.cn/gp/product/B01M8L5Z3Y")
print(r.status_code)
print(r.encoding)
r.encoding =r.apparent_encoding
print(r.text)
对网络爬虫的限制
两种方法:
1.通过roborts协议
2。通关判断对网站的http头来查看你的网站是否是一个爬虫引起的
用程序模拟浏览器对亚马逊进行请求
import requests
r = requests.get("https://www.amazon.cn/gp/product/B01M8L5Z3Y")
# print(r.status_code)
# print(r.encoding)
# r.encoding =r.apparent_encoding
# print(r.text)
# print(r.request.headers)
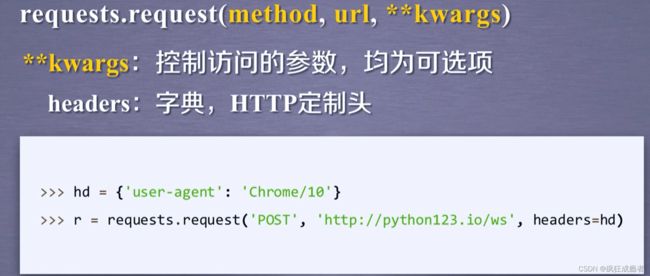
kv={'user-agent':'Mozilla/5.0'}
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url, headers=kv)
print(r.status_code)
最终代码
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url, headers=kv)
r.raise_for_status()
r.encoding =r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
第一周单元三实例三
对百度
import requests
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
对360
import requests
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get("http://www.so.com/s", params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
第一周单元三实例四
存入图片
import requests
path ="D:/abc.jpg"
url="https://img-blog.csdnimg.cn/9d499349bd444682b2cd1e8a0b459369.png"
r=requests.get(url)
print(r.status_code)
with open(path,'wb') as f:
print(f.write(r.content))
f.close()
名字为abc:

最终代码:
import requests
import os
url="https://img-blog.csdnimg.cn/9d499349bd444682b2cd1e8a0b459369.png"
root="D://pics//"
path =root +url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open (path, 'wb') as f:
f.write (r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
直接访问网站
import requests
r=requests.get("http://www.baidu.com")
print(r.status_code)
r.encoding ='utf-8'
print(r.text)
更改表头访问网站
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.status_code)
beautiful soup
import requests
r = requests.get( "http://python123.io/ws/demo.html")
print(r.text)
beautiful soup库
例子(demo)
import requests
r = requests.get( "http://python123.io/ws/demo.html")
print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
print(soup.prettify())

解析器

beautiful soup库的基本元素

将demo进行解析
例子
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
print(soup.title)
tag = soup.a
print(tag)
标签树形结构
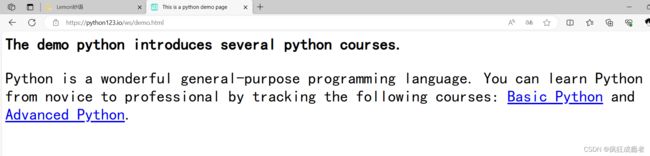
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
标签树下行遍历

\n也是一个节点

代码
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
# print(soup.head)
# print(soup.head.contents)
# print(soup.body.contents)
# print(len(soup.body.contents))
print(soup.body.contents[1])
标签树上行遍历

标签树平行遍历


代码1
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
# print(soup.a.next_sibling)
# print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
代码2
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
# print(soup.a.next_sibling)
for sibling in soup.a.next_siblings:
print(sibling)
prettify方法
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
#用html进行解析
# print(soup.a.next_sibling)
# print(soup.a.prettify())#将soup中的a标签进行prettify处理
bs4库的编码
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
# soup = BeautifulSoup(demo,"html.parser")
soup = BeautifulSoup("中文
","html.parser")
#用html进行解析
print(soup.p.prettify())#将soup中的p标签进行prettify处理
自动加入换行符
信息标记形式
xml

HTML格武也是XML格武这—个类别的

json


需要用双引号表达它的类型
yaml


用无类型键值对表示的
例子
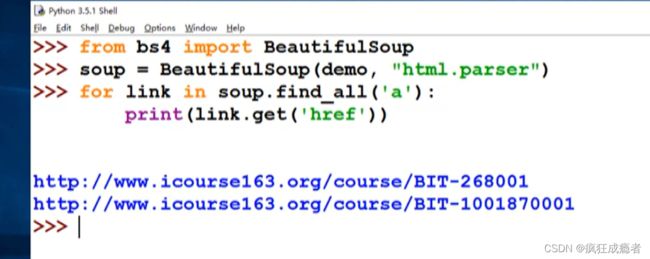
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
find_all
name

1.找在列表中包含在这个文件中包含所有a标签
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
print(soup.find_all('a'))
2.我们即希望查找a标签和b标签
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# print(soup.find_all('a'))
print(soup.find_all(['a','b']))
3.如果我们给出的标签是true,将显示当前soup的所有标签信息
import requests
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# print(soup.find_all('a'))
# print(soup.find_all(['a','b']))
for tag in soup.find_all(True):
print(tag.name)
4.我们希望只显示其中以b开头的标签,包扩b和body标签
使用正则表达式库
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
for tag in soup.find_all(re.compile('b')):
print(tag.name)
attrs
1.我们查找p标签中包含course字符串的信息
给出了带有course属性值的p标签
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# for tag in soup.find_all(re.compile('b')):
print(soup.find_all('p','course'))
2.我们以查找lD属性等于link1的值作为查找元素
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# for tag in soup.find_all(re.compile('b')):
print(soup.find_all(id='link1'))
3.我们以查找lD属性等于link的值作为查找元素
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
print(soup.find_all(id=re.compile('link')))
recursive
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# print(soup.find_all('a'))
print(soup.find_all('a',recursive=False))
string
1.我们看到我们检索Python时,回以把这个页面中所有在字特串检索出来
import requests
import re
r = requests.get( "http://python123.io/ws/demo.html")
# print(r.text)
demo=r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
# print(soup.find_all(string = "Basic Python"))
print(soup.find_all(string=re.compile("Python")))
扩展方法
实例
大学排名
html

html例子1:
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
html例子2:
<!DOCTYPE HTML>
<html>
<head>
<title>这里是一个标题</title>
</head>
<body>
<h1>我是一个一级标题</h1>
<p>这是一<i>个文本</i>段落<b>这是一个文本</b>段落
</p>
<p>这是<u>一个文</u>本段落<br></br>这是一个文本段落
</p>
<img src="https://img-blog.csdnimg.cn/ffae8ffb0b724cecadd9a8692ce2338e.png">
<br></br>
<img src="https://img-blog.csdnimg.cn/ffae8ffb0b724cecadd9a8692ce2338e.png" width="500px">
<br></br>
<a href="https://space.bilibili.com/523995133" target="_self">我的主页</a>
<br></br>
<a href="https://space.bilibili.com/523995133" target="_blank">我的主页</a>
新建网站
<h1>我是一个一级标题示例一</h1>
<div style="background-color: red;">
<p>这是一<i>个文本</i>段落<b>这是一个文本</b>段落
</p>
<p>这是<u>一个文</u>本段落<br></br>这是一个文本段落
</p>
</div>
<h1>我是一个一级标题示例二</h1>
<p>这是一<i>个文本</i>段落<b>这是一个文本</b>段落
</p>
<p>这是一<span style="background-color: aqua;">个文本</span>段落
<br></br>
这是一<span style="background-color: violet;">个文本</span>段落
</p>
</body>
</html>
添加链接:
我的主页
我的主页
当前网站
我的主页
新建网站
有序列表:
- 语文
- 数学
- 英语
无序列表:
- 语文
- 数学
- 英语


https://s.taobao.com/search?q=书包
表格1:
| 表头1 | 表头2 |
| 111 | 222 |
| 333 | 444 |
表格2:(加入边框,边框数字可变)
| 表头1 | 表头2 |
| 111 | 222 |
| 333 | 444 |
下划线,换行,加粗,斜体
我是一个一级标题
我是一个三级标题
我是一个六级标题
这是一个文本段落这是一个文本段落
这是一个文本段落
这是一个文本段落
图片
原图片:

修改大小的图片1:
修改大小的图片2:(后续研究)
div
我是一个一级标题
这是一个文本段落这是一个文本段落
这是一个文本段落
这是一个文本段落