Spring Cloud 学习笔记(3 3)
Spring Cloud 学习笔记(1 / 3)
Spring Cloud 学习笔记(2 / 3)
-
-
-
108_Nacos之Linux版本安装
109_Nacos集群配置(上)
110_Nacos集群配置(下)
111_Sentinel是什么
112_Sentinel下载安装运行
113_Sentinel初始化监控
114_Sentinel流控规则简介
115_Sentinel流控-QPS直接失败
116_Sentinel流控-线程数直接失败
117_Sentinel流控-关联
118_Sentinel流控-预热
119_Sentinel流控-排队等待
120_Sentinel降级简介
121_Sentinel降级-RT
122_Sentinel降级-异常比例
123_Sentinel降级-异常数
124_Sentinel热点key(上)
125_Sentinel热点key(下)
126_Sentinel系统规则
127_SentinelResource配置(上)
128_SentinelResource配置(中)
129_SentinelResource配置(下)
130_Sentinel服务熔断Ribbon环境预说
131_Sentinel服务熔断无配置
132_Sentinel服务熔断只配置fallback
133_Sentinel服务熔断只配置blockHandler
134_Sentinel服务熔断fallback和blockHandler都配置
135_Sentinel服务熔断exceptionsToIgnore
136_Sentinel服务熔断OpenFeign
137_Sentinel持久化规则
138_分布式事务问题由来
139_Seata术语
140_Seata-Server安装
141_Seata业务数据库准备
142_Seata之Order-Module配置搭建
143_Seata之Order-Module撸码(上)
144_Seata之Order-Module撸码(下)
145_Seata之Storage-Module说明
146_Seata之Account-Module说明
147_Seata之@GlobalTransactional验证
148_Seata之原理简介
149_大厂面试第三季预告片之雪花算法(上)
150_大厂面试第三季预告片之雪花算法(下)
Spring Cloud组件总结
-
108_Nacos之Linux版本安装
预计需要,1个Nginx+3个nacos注册中心+1个mysql
请确保是在环境中安装使用:
- 64 bit OS Linux/Unix/Mac,推荐使用Linux系统。
- 64 bit JDK 1.8+;下载.配置。
- Maven 3.2.x+;下载.配置。
- 3个或3个以上Nacos节点才能构成集群。
link
Nacos下载Linux版
-
https://github.com/alibaba/nacos/releases/tag/1.1.4
-
nacos-server-1.1.4.tar.gz 解压后安装
109_Nacos集群配置(上)
集群配置步骤(重点)
1.Linux服务器上mysql数据库配置
SQL脚本在哪里 - 目录nacos/conf/nacos-mysql.sql

自己Linux机器上的Mysql数据库上运行
2.application.properties配置
位置
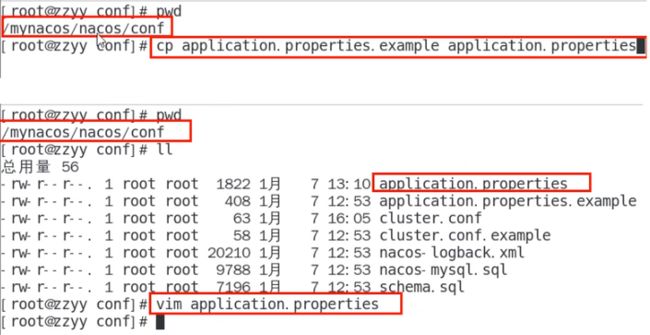
添加以下内容,设置数据源
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://localhost:3306/nacos_devtest?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=1234
3.Linux服务器上nacos的集群配置cluster.conf
梳理出3台nacos集器的不同服务端口号,设置3个端口:
- 3333
- 4444
- 5555
复制出cluster.conf

内容
192.168.111.144:3333
192.168.111.144:4444
192.168.111.144:5555
注意,这个IP不能写127.0.0.1,必须是Linux命令hostname -i能够识别的IP

4.编辑Nacos的启动脚本startup.sh,使它能够接受不同的启动端口
/mynacos/nacos/bin目录下有startup.sh

平时单机版的启动,都是./startup.sh即可
但是,集群启动,我们希望可以类似其它软件的shell命令,传递不同的端口号启动不同的nacos实例。
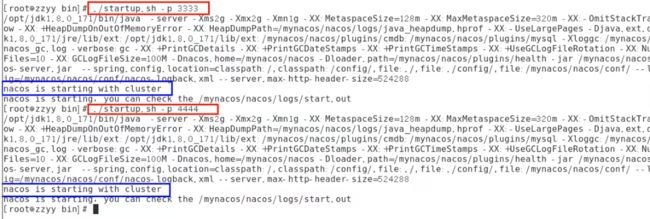
命令: ./startup.sh -p 3333表示启动端口号为3333的nacos服务器实例,和上一步的cluster.conf配置的一致。
修改内容
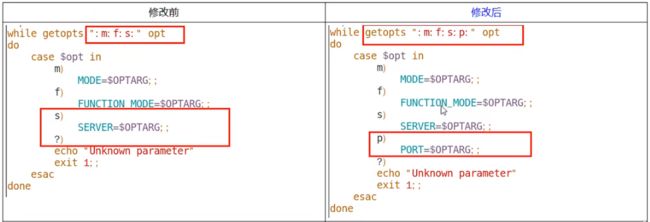

执行方式 - startup.sh - p 端口号
110_Nacos集群配置(下)
5.Nginx的配置,由它作为负载均衡器
修改nginx的配置文件 - nginx.conf
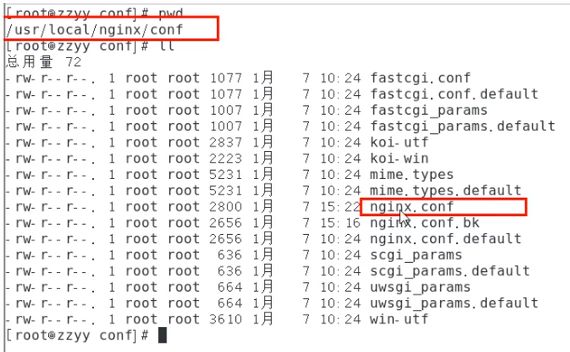
修改内容
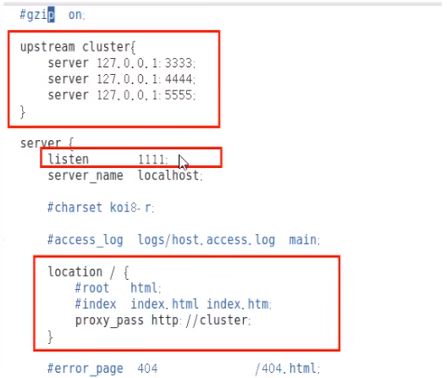
按照指定启动

6.截止到此处,1个Nginx+3个nacos注册中心+1个mysql
测试
-
启动3个nacos注册中心
-
startup.sh - p 3333 -
startup.sh - p 4444 -
startup.sh - p 5555 -
查看nacos进程启动数
ps -ef | grep nacos | grep -v grep | wc -l
-
-
启动nginx
./nginx -c /usr/local/nginx/conf/nginx.conf- 查看nginx进程
ps - ef| grep nginx
-
测试通过nginx,访问nacos - http://192.168.111.144:1111/nacos/#/login
-
新建一个配置测试
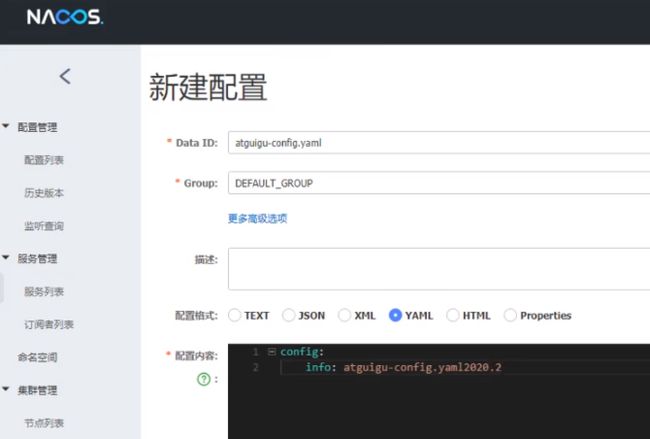
-
新建后,可在linux服务器的mysql新插入一条记录
select * from config;

-
让微服务cloudalibaba-provider-payment9002启动注册进nacos集群 - 修改配置文件
server:
port: 9002spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
#配置Nacos地址
#server-addr: Localhost:8848
#换成nginx的1111端口,做集群
server-addr: 192.168.111.144:1111management:
endpoints:
web:
exposure:
inc1ude: ‘*’ -
启动微服务cloudalibaba-provider-payment9002
-
访问nacos,查看注册结果

高可用小总结

111_Sentinel是什么
官方Github
官方文档
Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:
link
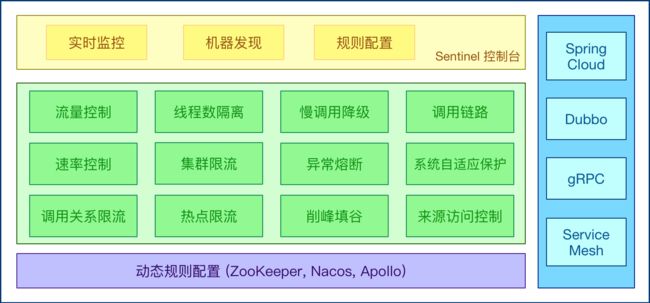
—句话解释,之前我们讲解过的Hystrix。
Hystrix与Sentinel比较:
- Hystrix
- 需要我们程序员自己手工搭建监控平台
- 没有一套web界面可以给我们进行更加细粒度化得配置流控、速率控制、服务熔断、服务降级
- Sentinel
- 单独一个组件,可以独立出来。
- 直接界面化的细粒度统一配置。
约定 > 配置 > 编码
都可以写在代码里面,但是我们本次还是大规模的学习使用配置和注解的方式,尽量少写代码
sentinel
英 [sentnl] 美 [sentnl]
n. 哨兵
112_Sentinel下载安装运行
官方文档
服务使用中的各种问题:
- 服务雪崩
- 服务降级
- 服务熔断
- 服务限流
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
安装步骤:
-
下载
- https://github.com/alibaba/Sentinel/releases
- 下载到本地sentinel-dashboard-1.7.0.jar
-
运行命令
- 前提
- Java 8 环境
- 8080端口不能被占用
- 命令
java -jar sentinel-dashboard-1.7.0.jar
- 前提
-
访问Sentinel管理界面
- localhost:8080
- 登录账号密码均为sentinel
113_Sentinel初始化监控
启动Nacos8848成功
新建工程 - cloudalibaba-sentinel-service8401
POM
cloud2020
com.atguigu.springcloud
1.0-SNAPSHOT
4.0.0
cloudalibaba-sentinel-service8401
com.atguigu.springcloud
cloud-api-commons
${project.version}
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-discovery
com.alibaba.csp
sentinel-datasource-nacos
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
org.springframework.cloud
spring-cloud-starter-openfeign
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-actuator
org.springframework.boot
spring-boot-devtools
runtime
true
cn.hutool
hutool-all
4.6.3
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
YML
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard地址
port: 8719
management:
endpoints:
web:
exposure:
include: '*'
feign:
sentinel:
enabled: true # 激活Sentinel对Feign的支持
主启动
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication
public class MainApp8401 {
public static void main(String[] args) {
SpringApplication.run(MainApp8401.class, args);
}
}
业务类FlowLimitController
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
@RestController
@Slf4j
public class FlowLimitController {
@GetMapping("/testA")
public String testA()
{
return "------testA";
}
@GetMapping("/testB")
public String testB()
{
log.info(Thread.currentThread().getName()+" "+"...testB");
return "------testB";
}
}
启动Sentinel8080 - java -jar sentinel-dashboard-1.7.0.jar
启动微服务8401
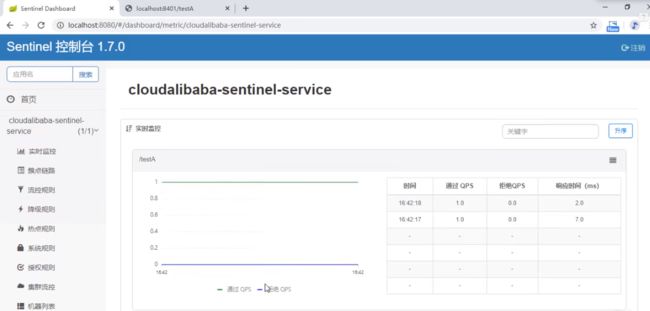
启动8401微服务后查看sentienl控制台
- 刚启动,空空如也,啥都没有
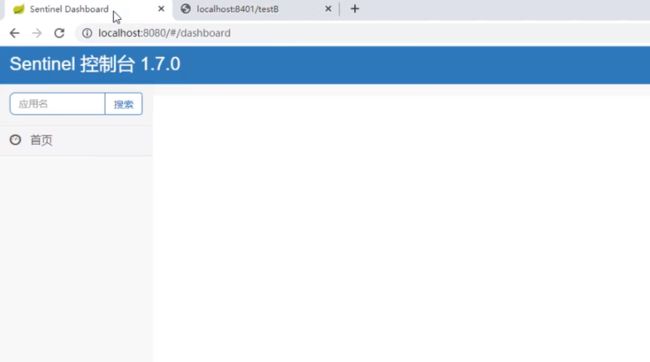
- Sentinel采用的懒加载说明
- 执行一次访问即可
- http://localhost:8401/testA
- http://localhost:8401/testB
- 效果 - sentinel8080正在监控微服务8401
- 执行一次访问即可
114_Sentinel流控规则简介
基本介绍
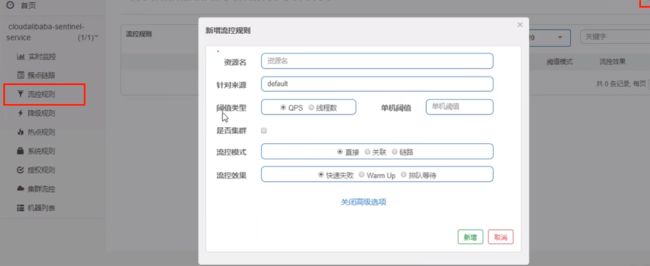
进一步解释说明:
- 资源名:唯一名称,默认请求路径。
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)。
- 阈值类型/单机阈值:
- QPS(每秒钟的请求数量)︰当调用该API的QPS达到阈值的时候,进行限流。
- 线程数:当调用该API的线程数达到阈值的时候,进行限流。
- 是否集群:不需要集群。
- 流控模式:
- 直接:API达到限流条件时,直接限流。
- 关联:当关联的资源达到阈值时,就限流自己。
- 链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【API级别的针对来源】。
- 流控效果:
- 快速失败:直接失败,抛异常。
- Warm up:根据Code Factor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的QPS阈值。
- 排队等待:匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效。
115_Sentinel流控-QPS直接失败
直接 -> 快速失败(系统默认)
配置及说明
表示1秒钟内查询1次就是OK,若超过次数1,就直接->快速失败,报默认错误

测试
快速多次点击访问http://localhost:8401/testA
结果
返回页面 Blocked by Sentinel (flow limiting)
源码
com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController
思考
直接调用默认报错信息,技术方面OK,但是,是否应该有我们自己的后续处理?类似有个fallback的兜底方法
116_Sentinel流控-线程数直接失败
线程数:当调用该API的线程数达到阈值的时候,进行限流。
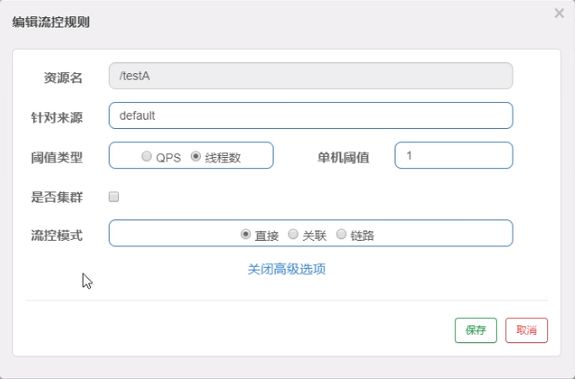
117_Sentinel流控-关联
是什么?
-
当自己关联的资源达到阈值时,就限流自己
-
当与A关联的资源B达到阀值后,就限流A自己(B惹事,A挂了)
设置testA
当关联资源/testB的QPS阀值超过1时,就限流/testA的Rest访问地址,当关联资源到阈值后限制配置好的资源名。
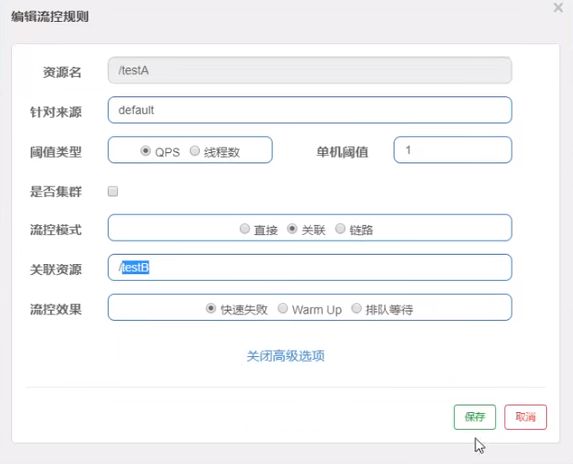
Postman模拟并发密集访问testB
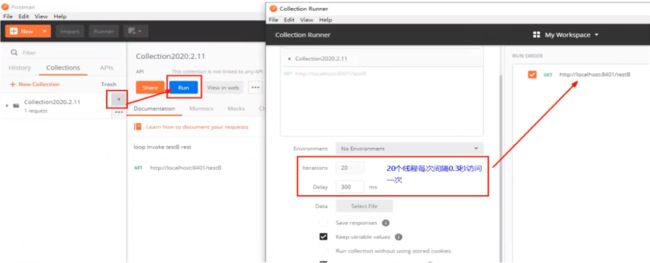
访问testB成功
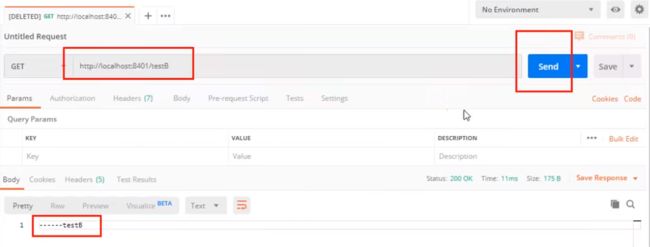
postman里新建多线程集合组
将访问地址添加进新新线程组
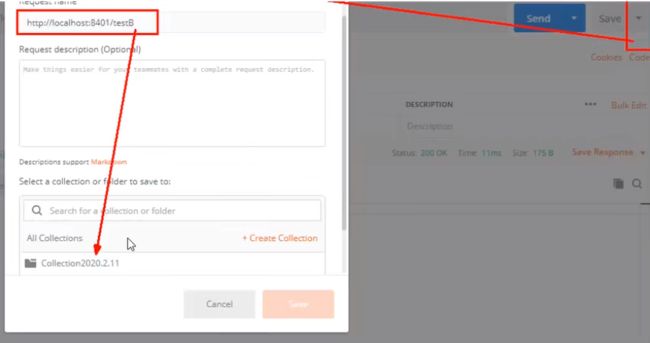
Run - 大批量线程高并发访问B
Postman运行后,点击访问http://localhost:8401/testA,发现testA挂了
- 结果Blocked by Sentinel(flow limiting)
HOMEWORK:
自己上机测试
链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【API级别的针对来源】
118_Sentinel流控-预热
Warm Up
Warm Up(
RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。详细文档可以参考 流量控制 - Warm Up 文档,具体的例子可以参见 WarmUpFlowDemo。通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:
link

默认coldFactor为3,即请求QPS 从 threshold / 3开始,经预热时长逐渐升至设定的QPS阈值。link
源码 - com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController
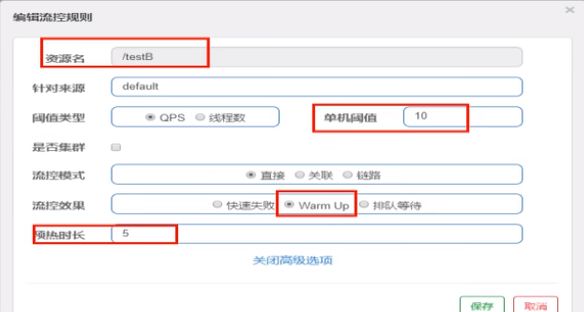
WarmUp配置
案例,阀值为10+预热时长设置5秒。
系统初始化的阀值为10/ 3约等于3,即阀值刚开始为3;然后过了5秒后阀值才慢慢升高恢复到10
测试
多次快速点击http://localhost:8401/testB - 刚开始不行,后续慢慢OK
应用场景
如:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阀值增长到设置的阀值。
119_Sentinel流控-排队等待
匀速排队,让请求以均匀的速度通过,阀值类型必须设成QPS,否则无效。
设置:/testA每秒1次请求,超过的话就排队等待,等待的超时时间为20000毫秒。

匀速排队
匀速排队(
RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。详细文档可以参考 流量控制 - 匀速器模式,具体的例子可以参见 PaceFlowDemo。该方式的作用如下图所示:
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
link

源码 - com.alibaba.csp.sentinel.slots.block.flow.controller.RateLimiterController
测试
-
添加日志记录代码到FlowLimitController的testA方法
@RestController
@Slf4j
public class FlowLimitController {
@GetMapping(“/testA”)
public String testA()
{
log.info(Thread.currentThread().getName()+" “+”…testA");//<----
return “------testA”;
}...}
-
Postman模拟并发密集访问testA。具体操作参考117_Sentinel流控-关联
-
后台结果

120_Sentinel降级简介
官方文档
熔断降级概述
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用别的模块,可能是另外的一个远程服务、数据库,或者第三方 API 等。例如,支付的时候,可能需要远程调用银联提供的 API;查询某个商品的价格,可能需要进行数据库查询。然而,这个被依赖服务的稳定性是不能保证的。如果依赖的服务出现了不稳定的情况,请求的响应时间变长,那么调用服务的方法的响应时间也会变长,线程会产生堆积,最终可能耗尽业务自身的线程池,服务本身也变得不可用。
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的某一环不稳定,就可能会层层级联,最终导致整个链路都不可用。因此我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
link
-
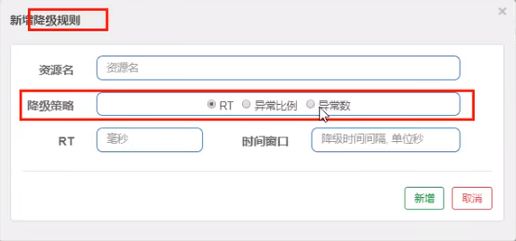
RT(平均响应时间,秒级)
- 平均响应时间 超出阈值 且 在时间窗口内通过的请求>=5,两个条件同时满足后触发降级。
- 窗口期过后关闭断路器。
- RT最大4900(更大的需要通过-Dcsp.sentinel.statistic.max.rt=XXXX才能生效)。
-
异常比列(秒级)
- QPS >= 5且异常比例(秒级统计)超过阈值时,触发降级;时间窗口结束后,关闭降级 。
-
异常数(分钟级)
- 异常数(分钟统计)超过阈值时,触发降级;时间窗口结束后,关闭降级
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
Sentinei的断路器是没有类似Hystrix半开状态的。(Sentinei 1.8.0 已有半开状态)
半开的状态系统自动去检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可用。
具体可以参考49_Hystrix的服务降级熔断限流概念初讲。
121_Sentinel降级-RT
是什么?
平均响应时间(
DEGRADE_GRADE_RT):当1s内持续进入5个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以ms为单位),那么在接下的时间窗口(DegradeRule中的timeWindow,以s为单位)之内,对这个方法的调用都会自动地熔断(抛出DegradeException)。注意Sentinel 默认统计的RT上限是4900 ms,超出此阈值的都会算作4900ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置。
注意:Sentinel 1.7.0才有平均响应时间(DEGRADE_GRADE_RT),Sentinel 1.8.0的没有这项,取而代之的是慢调用比例 (SLOW_REQUEST_RATIO)。
慢调用比例 (
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。