深度文本匹配概述
文章目录
- 深度文本匹配概述
-
- 文本匹配
-
-
- 基于表示的模型
- 基于交互的模型
- 基于预训练模型BERT
- 其他
- 参考
-
深度文本匹配概述
文本匹配
虽然文本匹配在BERT出现以前一直是以两类模型主导,但其实文本匹配时一个广泛的概念,在文本匹配下面还有许多的任务,正如下表所示
1.复述识别(paraphrase identification)
又称释义识别,也就是判断两段文本是不是表达了同样的语义,即是否构成复述(paraphrase)关系。有的数据集是给出相似度等级,等级越高越相似,有的是直接给出0/1匹配标签。这一类场景一般建模成分类问题。
2.文本蕴含识别(Textual Entailment)
文本蕴含属于NLI(自然语言推理)的一个任务,它的任务形式是:给定一个前提文本(text),根据这个前提去推断假说文本(hypothesis)与文本的关系,一般分为蕴含关系(entailment)和矛盾关系(contradiction),蕴含关系(entailment)表示从text中可以推断出hypothesis;矛盾关系(contradiction)即hypothesis与text矛盾。文本蕴含的结果就是这几个概率值。
3.问答(QA)
问答属于文本匹配中较为常见的任务了,这个任务也比较容易理解,根据Question在段落或文档中查找Answer,但是在现在这个问题常被称为阅读理解,还有一类是根据Question查找包含Answer的文档,QA任务常常会被建模成分类问题,但是实际场景往往是从若干候选中找出正确答案,而且相关的数据集也往往通过一个匹配正例+若干负例的方式构建,因此往往建模成ranking问题。
4.对话(Conversation)
对话实际上跟QA有一些类似,但是比QA更复杂一些,它在QA的基础上引入了历史轮对话,在历史轮的限制下,一些本来可以作为回复的候选会因此变得不合理。比如,历史轮提到过你18岁了,那么对于query”你今天在家做什么呢“,你就不能回复“我在家带孙子”了。该问题一般使用Recall_n@k(在n个候选中,合理回复出现在前k个位置就算召回成功)作为评价指标,有时也会像问答匹配一样使用MAP、MRR等指标。
5.信息检索(IR)
信息检索也是一个更为复杂的任务,往往会有Query——Tittle,Query——Document的形式,而且更为复杂的Query可能是一个Document,变成Document——Document的形式,相对于其他匹配任务而言,相似度计算、检索这些只是一个必须的过程,更重要的是需要排序,一般先通过检索方法召回相关项,再对相关项进行rerank。ranking问题就不能仅仅依赖文本这一个维度的feature了,而且相对来说判断两个文本的语义匹配的有多深以及关系有多微妙就没那么重要了。
基于表示的模型
基于表示的匹配模型的基本结构包括:
(1)嵌入层,即文本细粒度的嵌入表示;
(2)编码层,在嵌入表示的基础上进一步编码;
(3)表示层:获取各文本的向量表征;
(4)预测层:对文本pair的向量组进行聚合,从而进行文本关系的预测

代表:
1.DSMM
DSSM、CDSSM、DSSM+LSTM、DSSM+CNN、DSSM+GRU、DSSM+RNN、MV(Multi-View)-DSSM
关于DSSM双塔模型有人做了一些归纳,DSSM双塔模型
2.Siam(孪生)网络
SiamCNN、SiamLSTM、、
3.ARC-1
4.Multi-view
5.InferSent
6.SSE
【Reference】
DSSM: Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
CDSSM: A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
LSTM-DSSM: Semantic Modelling with Long-Short-Term Memory for Information Retrieval
MV-DSSM: A Multi-View Deep Learning Approach for Cross Domain
User Modeling in Recommendation Systems
ARC-1: Convolutional Neural Network Architectures for Matching Natural Language Sentences
SiamCNN: Applying Deep Learning to Answer Selection: A Study and An Open Task
SiamLSTM: Siamese Recurrent Architectures for Learning Sentence Similarity
Multi-view: Multi-view Response Selection for Human-Computer Conversation
InferSent: Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
SSE: Shortcut-Stacked Sentence Encoders for Multi-Domain Inference
基于交互的模型
表示型的文本匹配模型存在两大问题:(1)对各文本抽取的仅仅是最后的语义向量,其中的信息损失难以衡量;(2)缺乏对文本pair间词法、句法信息的比较
而交互型的文本匹配模型通过尽早在文本pair间进行信息交互,能够改善上述问题。
基于交互的匹配模型的基本结构包括:
(1)嵌入层,即文本细粒度的嵌入表示;
(2)编码层,在嵌入表示的基础上进一步编码;
(3)匹配层:将文本对的编码层输出进行交互、对比,得到各文本强化后的向量表征,或者直接得到统一的向量表征;
(4)融合层:对匹配层输出向量进一步压缩、融合;
(5)预测层:基于文本对融合后的向量进行文本关系的预测。
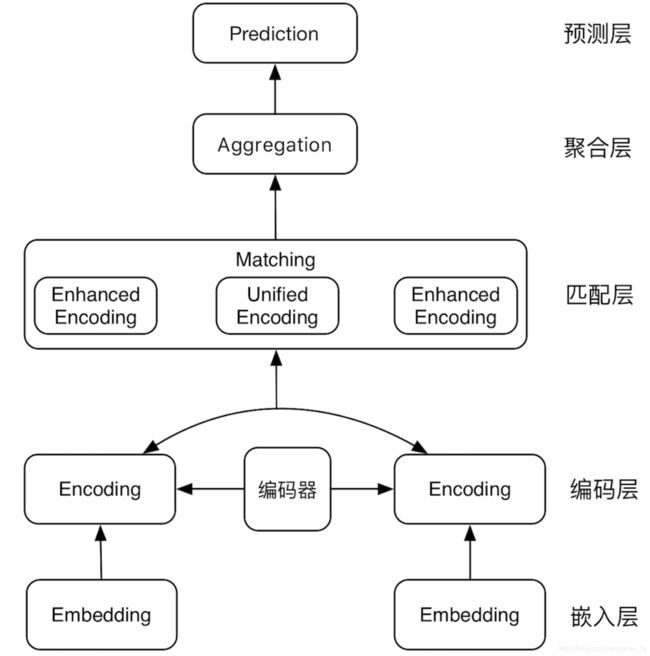
代表:
1.ARC-Ⅱ
2.PairCNN
3.MatchPyranmid
4.DecAtt
5.CompAgg
6.ABCNN
BCNN、ABCNN、ABCNN-2、ABCNN-3、
7.DIIN
8.DRCN
9.ESIM
10.Bimpm
11.HCAN
【Reference】
ARC-II: Convolutional Neural Network Architectures for Matching Natural Language Sentences
PairCNN: Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
MatchPyramid: Text Matching as Image Recognition
DecAtt: A Decomposable Attention Model for Natural Language Inference
CompAgg: A Compare-Aggregate Model for Matching Text Sequences
ABCNN: ABCNN: Attention-Based Convolutional Neural Network
for Modeling Sentence Pairs
DIIN:NATURAL LANGUAGE INFERENCE OVER INTERACTION SPACE
DRCN:Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
ESIM: Enhanced LSTM for Natural Language Inference
Bimpm: Bilateral Multi-Perspective Matching for Natural Language Sentences
HCAN: Bridging the Gap Between Relevance Matching and Semantic Matching
for Short Text Similarity Modeling
基于预训练模型BERT
SOTA模型,基于bert的改进还在学习中,base-bert、孪生bert等,此外BERT还有一个问题,无法解决长文本的匹配,但是对于此问题也有文章在解决了。
【Reference】
1.Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
2.Simple Applications of BERT for Ad Hoc Document Retrieval
其他
文本匹配的baseline有很多,借助一些好用的开源工具可以大大提升开发效率:MatchZoo、AnyQ、DGU
参考
1.文本匹配模型
2.文本匹配打卡
3.孪生BERT