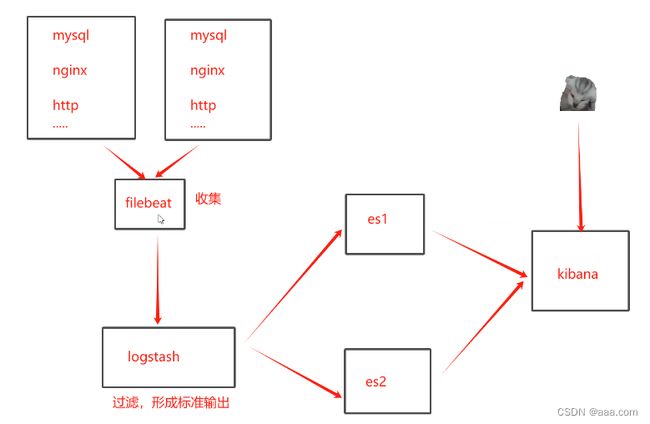
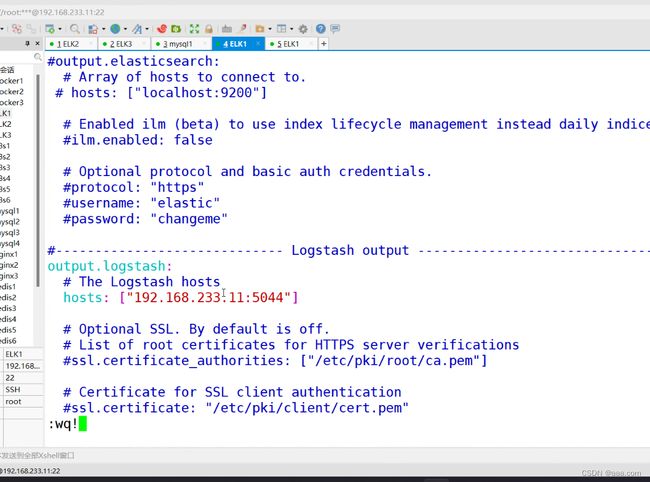
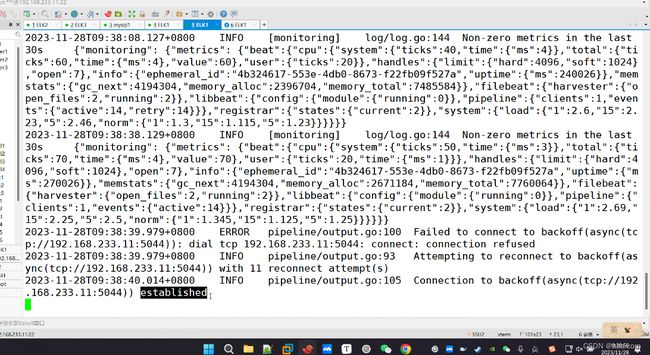
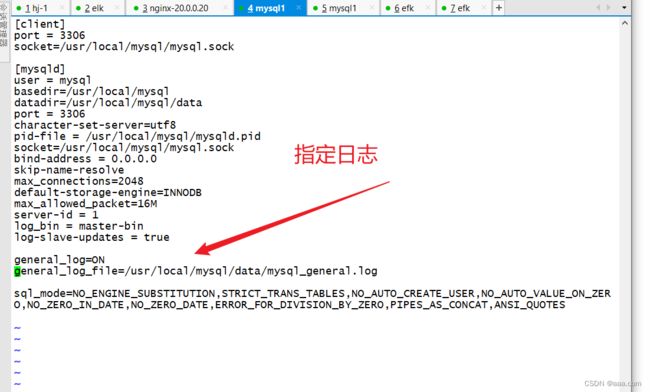
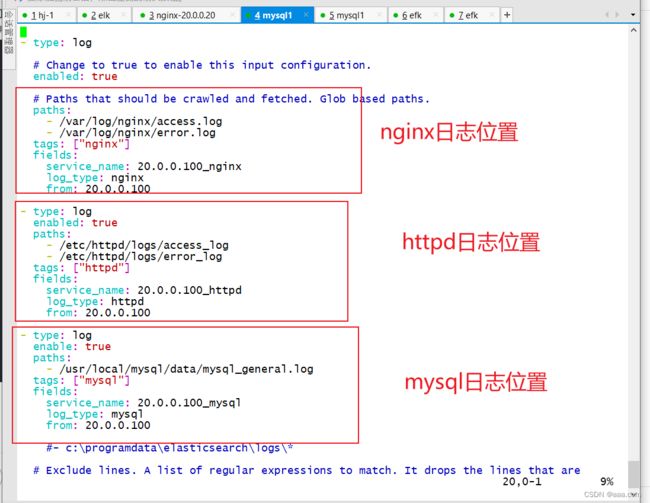
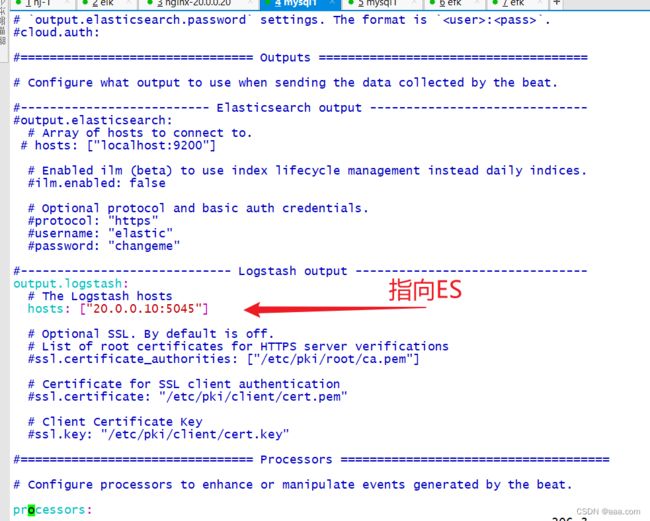
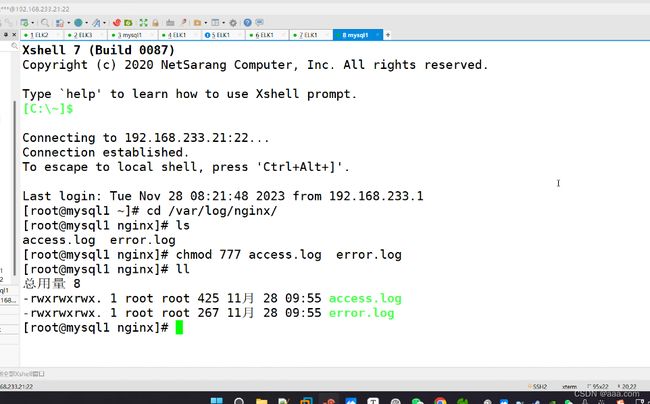
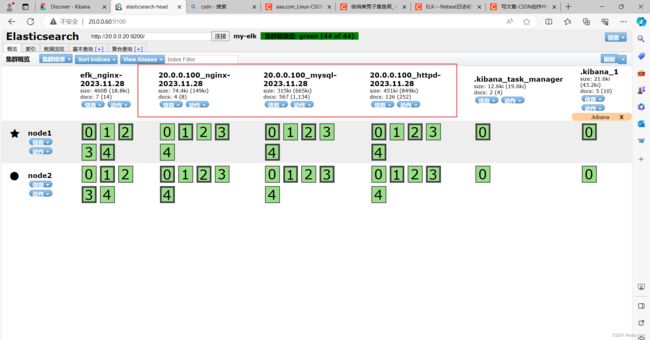
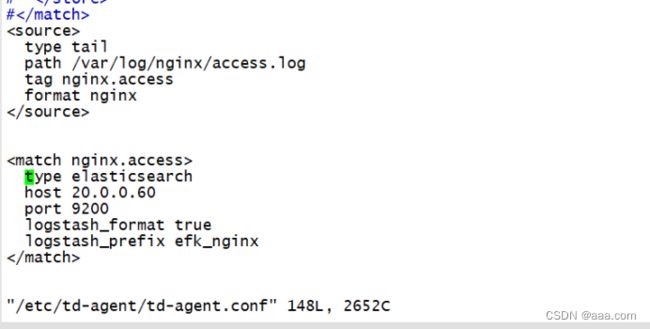
type tail
path /var/log/nginx/access.log
tag nginx.access
format nginx
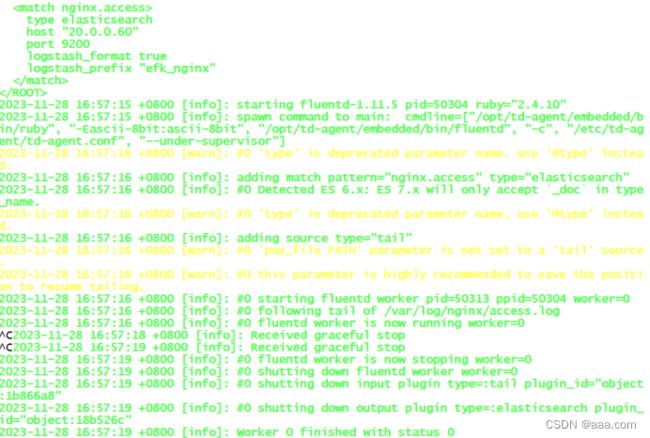
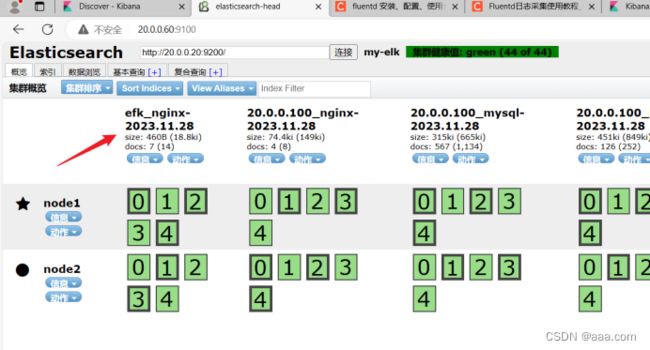
type elasticsearch
host 20.0.0.60
port 9200
logstash_format true
logstash_prefix efk_nginx
Wq退出之后用
/opt/td-agent/embedded/bin/fluentd -c /etc/td-agent/td-agent.conf
来检测配置文件是否正确
例如,你想myuser使用mypassword从任何主机连接到mysql服务器的话。
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%'IDENTIFIED BY 'mypassword' WI
TH GRANT OPTION;
如果你想允许用户myuser从ip为192.168.1.6的主机连接到mysql服务器,并使用mypassword作
在 Service Pack 4 (SP 4), 是运行 Microsoft Windows Server 2003、 Microsoft Windows Storage Server 2003 或 Microsoft Windows 2000 服务器上您尝试安装 Microsoft SQL Server 2000 通过卷许可协议 (VLA) 媒体。 这样做, 收到以下错误信息CD KEY的 SQ
OS 7 has a new method that allows you to draw a view hierarchy into the current graphics context. This can be used to get an UIImage very fast.
I implemented a category method on UIView to get the vi
方法一:
在my.ini的[mysqld]字段加入:
skip-grant-tables
重启mysql服务,这时的mysql不需要密码即可登录数据库
然后进入mysql
mysql>use mysql;
mysql>更新 user set password=password('新密码') WHERE User='root';
mysq
背景
2014年11月12日,ASP.NET之父、微软云计算与企业级产品工程部执行副总裁Scott Guthrie,在Connect全球开发者在线会议上宣布,微软将开源全部.NET核心运行时,并将.NET 扩展为可在 Linux 和 Mac OS 平台上运行。.NET核心运行时将基于MIT开源许可协议发布,其中将包括执行.NET代码所需的一切项目——CLR、JIT编译器、垃圾收集器(GC)和核心