C语言进阶之笔试题详解(2)
前言
这里的内容包括二维数组笔试题和指针笔试题,供给读者对这部分知识进行加深和巩固。
✨ 猪巴戒:个人主页✨
所属专栏:《C语言进阶》
跟着猪巴戒,一起学习C语言
目录
前言
笔试题
二维数组
题目
解析:
一维数组
二维数组
总结:
指针笔试题
题目1
解析:
题目2
解析:
总结:
题目3
解析
题目4
解析:
题目5
解析:
总结:
题目6:
解析:
题目7:
解析:
总结:
题目8:
解析:
最后
笔试题
二维数组
题目
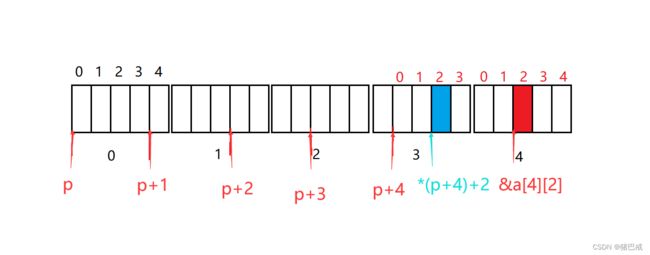
以下代码的打印结果是什么?
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0]+1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));
return 0;
}解析:
一维数组
一维数组的数组名表示的是首元素的地址,通过数组名加下标的形式可以访问数组的每个元素。
arr[1]这里的1就是元素的下标,arr[1]访问的是数组的第二个元素。
二维数组
arr[3][4]是一个二维数组,二维数组可以看作是3个一维数组组成,每个一维数组就是二维数组的一个元素,因此二维数组的首元素其实是第一行的所有元素。
二维数组的数组名arr,表示的是第一行的地址,也就是第一个一维数组的地址。一共有多少行就有多少个一维数组。
arr[0]其实就是第一个一维数组的数组名。
arr[1]就是第二个一维数组的数组名。
arr[2]就是第三个一维数组的数组名。
一共是3行,就是3个一维数组。
想要访问二维数组的每个元素:一维数组的数组名加下标,arr[0][0],访问的是第一行第一列的元素。

1|printf (" %d\n ", sizeof ( a ) ) 48
这里a是数组名,sizeof(数组名),就代表整个数组的大小,数组一共12个元素,每个元素4个字节,整个数组的大小就是48个字节。
2|printf (" %d\n ", sizeof ( a[0][0] ) ) 4
a[0][0]就是第一行第一列的元素,一个整形元素,就是4个字节的大小。
3|printf (" %d\n ", sizeof ( a[0] ) ) 16
a[0]就是第一个一维数组,a[0]就是第一个一维数组的数组名,sizeof(数组名)表示的就是整个数组的大小,这个一维数组一共有4个元素,每个元素的大小是4个字节。
4|printf (" %d\n ", sizeof ( a[0]+1 ) ) 4 / 8
a[0]就是第一个一维数组的数组名,因为a[0]并不是单独放在sizeof内部的,所以这里的a[0]表示的就是首元素的地址,a[0]是一维数组,首元素地址就是第一行第一列的元素的地址。那a[0]+1表示的就是第一行第二个的元素的地址,地址为4个字节或者8个字节。
5|printf (" %d\n ", sizeof ( *( a[0] + 1) ) ) 4
在4|中,我们就分析了a[0]+1是第一行第二个元素的地址,现在把它解引用。*(a[0]+1)得到的就是第一行第二个元素,一个整形元素的大小是4个字节。
6|printf (" %d\n ", sizeof ( a + 1 ) ) 4 / 8
a是一个二维数组,a不是单独放在sizeof内部,a表示的就是首元素的地址,而二维数组首元素的地址表示的是第一个一维数组的地址,也就是第一行的地址,a+1表示的就是第二个一维数组的地址,也就是第二行的地址,即使是一维数组的地址,大小也是4个字节或者8个字节。
7|printf (" %d\n ", sizeof ( *(a + 1) ) ) 16
在6|中,我们分析到a+1表示的就是第二个一维数组的地址,也就是第二行的地址,这里对第二个一维数组进行解引用操作,*(a+1)得到的就是第二个一维数组的元素,一共有4个元素,每个元素的大小是4个字节。
8|printf (" %d\n ", sizeof ( &a[0] + 1 ) ) 4 / 8
&a[0],&数组名表示就是取整个数组的地址,a[0]就是第一个一维数组,取的就是第一行的地址,,因为这个地址的类型是一行的地址,&a[0]+1跳过一行,得到的就是第二行的地址。地址的大小是4个字节或者8个字节。
9|printf (" %d\n ", sizeof ( *a ) ) 16
a是一个二维数组,a并没有单独放在sizeof的内部,a表示的就是首元素的地址,二维数组首元素的地址,就是第一行的地址。*a对第一行的地址解引用得到的就是第一行的所有元素,一个4个元素,每个元素的大小是4个字节。
10|printf (" %d\n ", sizeof ( a[3] ) ) 16
sizeof()只关心内部类型的大小,如果有这个二维数组第4行,同样是是4个元素,sizeof(数组名),依旧是向后访问4个元素,每个元素是整形的大小,所以是16个字节,sizeof不会真的去访问,程序会返回16。
总结:
数组名的意义:
1.sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
2.&数组名,这里的数组名表示整个数组,去除掉是整个数组的地址。
3.除此之外所以的数组名都表示首元素的地址。
4.二维数组可以看作有多个一维数组组成,一维数组可以看作二维数组的每个元素,行数代表制二维数组的意思个数,列数代表一维数组的元素个数。
指针笔试题
题目1
int main()
{
int a[5] = {1,2,3,4,5};
int* ptr = (int*)(&a+1);
printf("%d\n",*(a+1),*(ptr-1));
return 0;
}解析:
*(a+1): 2
a是数组名,表示的是首元素的地址,一个元素的地址,+1就跳过一个元素,所以(a+1)表示就是第二个元素的地址,解引用得到的就是第二个元素,等于2.
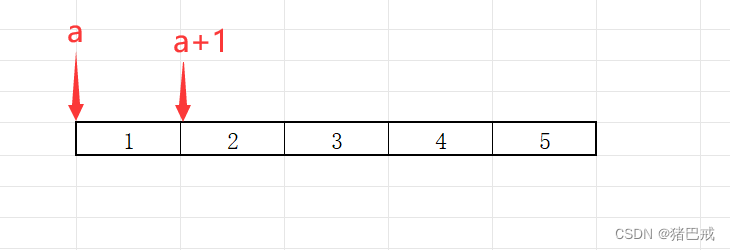
*(ptr-1): 5
&a,a是数组名,&a取的是整个数组的地址,+1跳过整个数组,指向的位置:
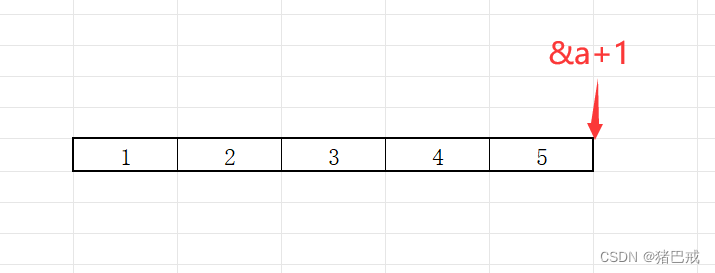
将(&a+1)强制类型转化为(int*),就是由数组指针转成整形指针的类型, 原来是数组的地址,所以是数组指针,现在是整形指针的地址,就意味着,+1或-1的操作只能跳过一个整形元素的大小。
ptr-1跳过4个字节,位置如下图所示,对ptr-1解引用就得到5.
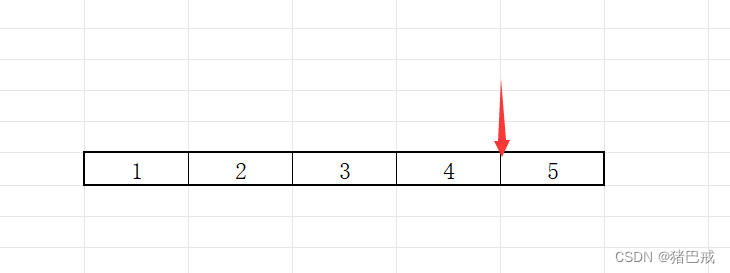
题目2
假设p的值为0x100000.如下表表达式的值分别为多少?
已知,结构体Test类型的变量大小是20个字节
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
int main()
{
printf("%p\n",p+0x1);
printf("%p\n",(unsigned long)p +0x1);
printf("%p\n",(unsigned int*)p +0x1);
return 0;
}解析:
1. printf (" %p\n ", p+0x1 )
p是结构体指针,结构体变量的大小是20个字节,
指针+1,跳过一个指针变量的大小,0x100000这是16进制,我们加上20个字节
十进制中的20转化为十六进制就是14.
结果为0x100014.
2. printf (" %p\n ", (unsigned long)p +0x1 )
将p一个结构体指针强制类型转化为unsigned long类型,也就是整数,那结果就为
0x100001
因为指针+1-1需要考虑指针类型,整数直接加减就可以了
3. printf (" %p\n ", (unsigned int*)p + 0x1)
p是结构体指针,将p强制类型转化为unsigned int* 类型,无符号整形指针,整形指针+1就会跳过一个整形的大小,也就是4个字节。结果:
0x100004
总结:
这道题考察的是
指针+1-1的操作,什么类型的指针就会跳过一个多大的元素。
比如整形指针+1就会跳过4个字节,字符指针+1就会跳过1个字节。
-1也类比如此。
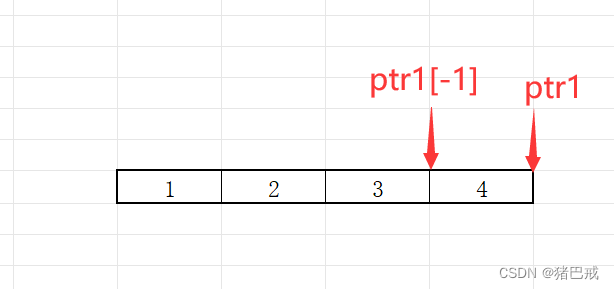
题目3
int main()
{
int a[4] = { 1,2,3,4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}解析
1. int* ptr1 = (int*)(&a + 1)
&a+1,&数组名,取的是整个数组的地址,所以加1就会跳过整个数组。
(int*)(&a+1),将(&a+1)强制类型转化成整形指针,ptr1就是一个整形指针
ptr1[-1],ptr1[-1]其实就等同于*(ptr1-1),ptr1是整形指针,所以-1跳过一个整形元素,4个字节。
ptr1[-1]的打印结果:
0x00 00 00 04 打印会省略前面的0,所以结果为4
%x是打印十六进制的数字
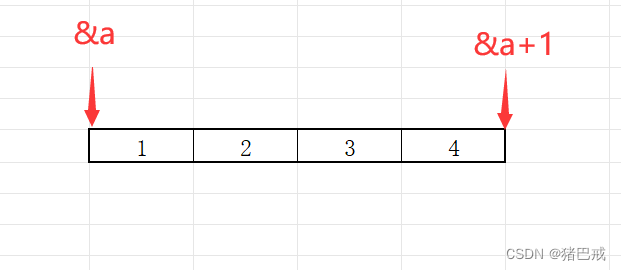
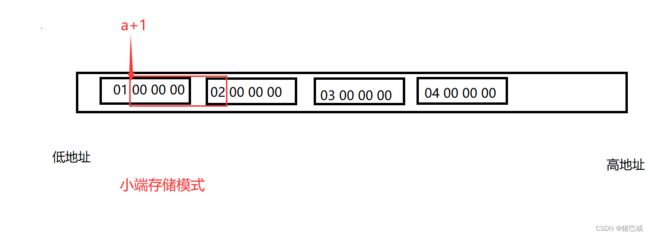
2. int* ptr2 = (int*) ( ( int ) a + 1) 0x02 00 00 00
a是数组名,表示首元素的地址
(int) a 对首元素的地址强制类型转化为(int)
(int)a+1,a已经强制类型转化为整数,+1直接在a的地址加1就可以了。
(int*) ( ( int ) a + 1),强制类型转化会整形指针,那整形指针ptr2指向的就是a+1指向的后面4个字节。
msvc采用的是小端存储模式,所以读出来的要再次进行倒置,结果:
0x02 00 00 00
%x是打印十六进制
题目4
#include
int main()
{
int arr[3][2] = { (0,1),(2,3),(4,5) };
int* p;
p = arr[0];
printf("%d", p[0]);
return 0;
}
解析:
如果我们想要对一个三行二列的数组进行初始化,我们可以用这种形式。
int arr[3][2] = { {0,1}, {2,3}, {4,5} };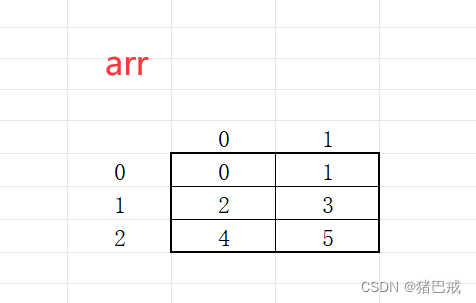
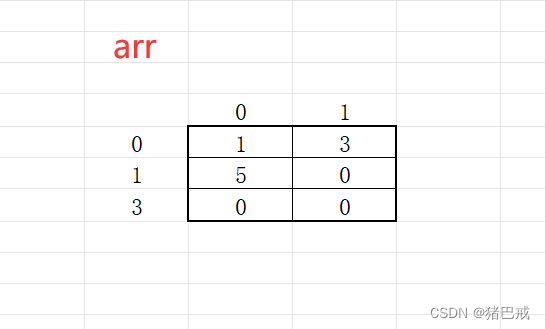
但是用()就不是这个初始化了,这是逗号表达式,逗号表达式取最后的一位,依次取,剩余不够就会初始化为0。
int arr[3][2] = { (0,1),(2,3),(4,5) };
//实际上
int arr[3][2] = { 1 , 3 , 5 };
arr[0]是第一行的数组名,arr[0]表示首元素的地址,a[0][0]的地址,&a[0][0],第一行的地址和第一个元素的地址表示形式是一样的
int*p,p是整形指针, 所以存放的是arr[0][0]的地址
p[0] -> *(p+0) -> *p
结果:1
题目5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}解析:
a是每行有5个元素,一共5行的二维数组。
p是数组指针,一个指向4个整形的数组。
p = a, 数组名a表示首元素的地址,即第一行的地址,地址的表示形式就是第一个元素的地址,p只有4个元素,但是地址的位置传给了p。
&p[4][2]-->*(*(p+4)+2),p是一个4个整形元素的数组指针,所以p+1就跳过4个字节,
*(p+4)就是一个4个元素的整形数组的数组名,表示这个数组首元素的地址,即整形指针,整形指针+2,跳过2个整形元素,实际上是8个字节。
&a[4][2],找到数组a第5行第3列的元素地址位置
指针-指针,指针之间相减,等于指针之间的元素个数。
&p[4][2] - &a[4][2],由于是低地址-高地址,结果为:-4
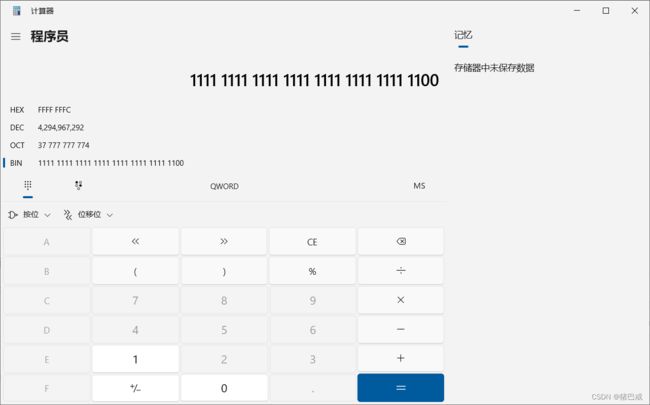
%p的打印结果
%p是打印地址,地址是没有负数概念的,所以这里的-4是将其存放在内存中的补码打印出来,-4的补码是:11111111111111111111111111111100
将它变成十六进制,0xFFFF FFFC
%d的打印结果
-4
总结:
1.指针相减得到的是指针之间的元素个数。
题目6:
int main()
{
int aa[2][5] = { 1,2,3,4,5,6,7,8,9,10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}解析:
*(ptr1-1): 10
&aa取的是二维数组的起始地址,&aa+1就会跳过整个二维数组。
然后传给整形指针ptr1,整形指针ptr1-1,向前跳过一个元素。
ptr1-1指向的数字就是10。
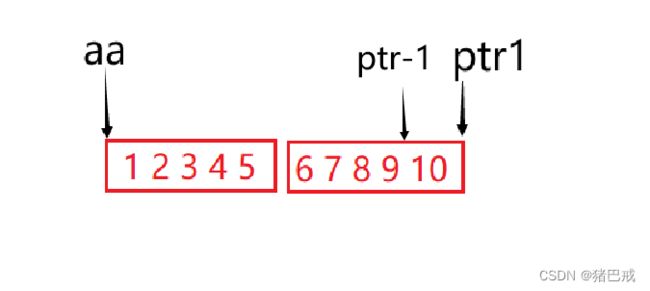
*(ptr2-1): 5
aa为首元素的地址,即第一行的地址,aa+1跳过一个一维数组,就是第二行的地址
*(aa+1)对第二行的地址解引用得到的就是第二行的数组名,数组名表示首元素的地址,ptr2表示的是6的地址。
ptr2-1,ptr2是整形指针,-1向前跳过1个元素,得到的就是5的地址。
*(ptr2-1),解引用得到5.
题目7:
#include
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
} 解析:
pa是一个char**类型,一个二级字符指针,指向的是a,a表示数字首元素的地址,就是“work”的地址。
因为pa是char**类型,所以pa+1,跳过一个char*元素,pa++也就是跳到“at”。
对pa解引用,得到的结果:
at
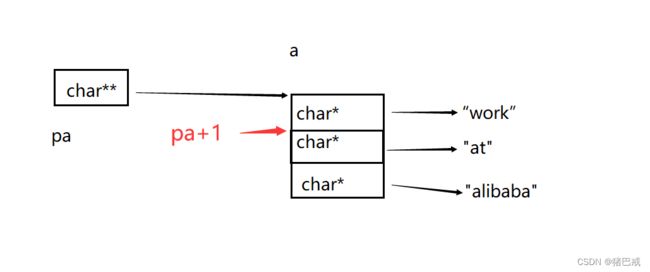
总结:
1.整形指针int*,+1-1跳过一个整形元素
2.二级字符指针char**,+1-1跳过一个char*类型的元素。
题目8:
int main()
{
char* c[] = { "ENTER","NEW","POITER","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}解析:
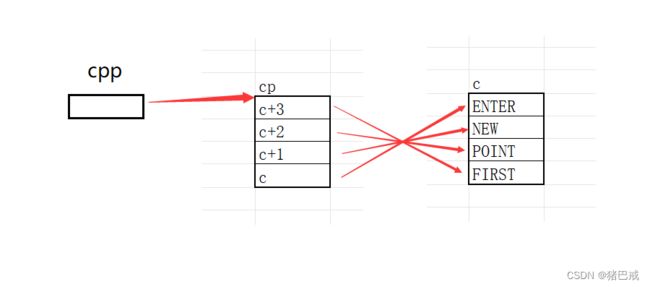
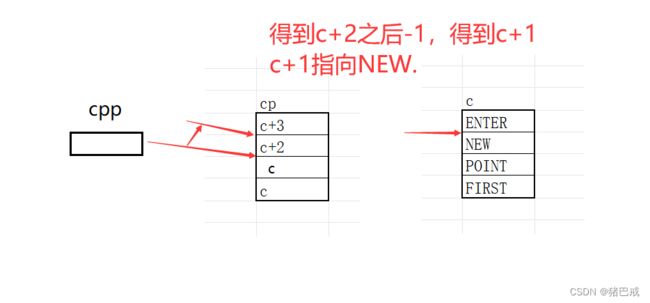
1. printf (" %s\n ", **++cpp)
cpp = cp,cpp指向的是数组cp的首元素,就是c+3.
++cpp,cpp指向的位置发生了改变,cpp指向c+2
*++cpp,解引用后,得到的就是c+2.
**++cpp,再次解引用,得到的就是c+2所指向的"POINT".
打印结果:POINT
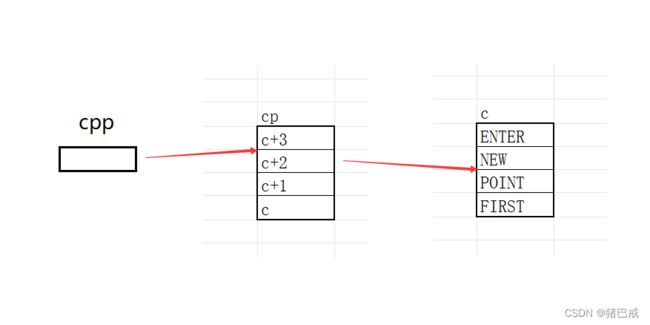
2. printf (" %s\n ", *-- * ++cpp + 3)
上一轮的操作中,cpp所指向的位置已经发生了改变,cpp指向的对象是c+2
++cpp,cpp所指向的位置改变,指向c+1.
*++cpp,解引用,就是c+1
--*++cpp,前置减减,得到的c.
*--*++cpp,得到c所指向的对象,“ENTER”
*--*++cpp+3,这个*--*++cpp得到的是c所指向的对象,即字符串首个字符的地址,就是字符指针。
字符指针+3,跳过3个字符,得到的结果是:
“ER”
在字符数组中的字符串存放的其实是这个常量字符串首个字符的地址,
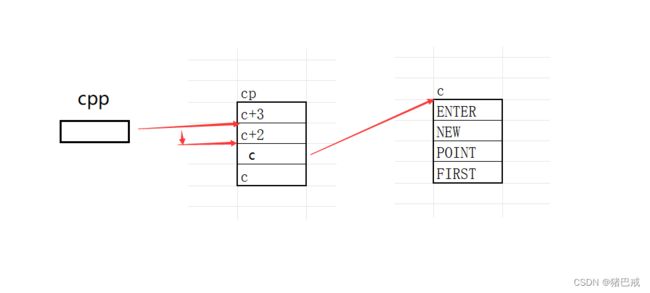
3. printf (" %s\n ", *cpp[-2] + 3)
经过上一轮,cpp所指向的对象变成了cp数组的第三个元素,第三个元素本来是c+1,但是--之后变成了c。
cpp[-2],等同于*(cpp-2),cpp向前跳过2个元素,指向的对象变成了c+3,然后解引用得到c+3.
*cpp[-2],对c+2进行解引用,c+3所指向的对象是“FIRST”,得到“FIRST”.得到的“FIRST”其实是F的地址,是一个字符指针
*cpp[-2]+3,字符指针+3,跳过3个字符,得到的结果就是“ST”.
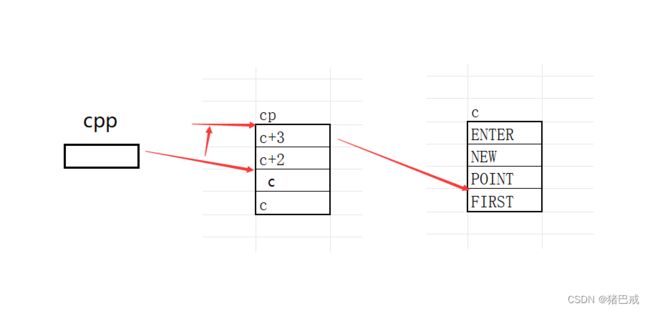
4. printf (" %s\n ", cpp[-1][-1] + 1)
cpp指向cp的第三个元素,第三个元素已经变成了c。
cpp[-1][-1],等同于*(*(cpp-1)-1)
cpp-1,cpp指向的是cp第三个元素,向前移动一位,得到c+2的地址.
*(cpp-1),对c+2的地址解引用,就会得到c+2.
*(cpp-1)-1,c+2-1,得到的就是c+1。
*(*(cpp-1)-1),对c+1进行解引用,得到的就是c所指向的对象,“NEW”.“NEW”得到的是N的地址,是一个字符指针。
以上对cpp[-1][-1]的解析,
cpp[-1][-1] + 1,我们已经得到“ENTER”,也就是字符指针,字符指针+1-1跳过一个字符,+1跳过N,得到的结果是“EW”.
最后
如果你能够走到这里,那么恭喜你,请给自己比个大拇指吧!