【NeRF】3、MobileR2L | 移动端实时的神经光场(CVPR2023)

论文:Real-Time Neural Light Field on Mobile Devices
代码:https://github.com/snap-research/MobileR2L
出处:CVPR2023
贡献:
- 设计了一套移动端实时的 R2L 网络结构 MobileR2L,在 iphone13 上渲染一张 1008x756 的图片仅需要 18.04ms(约55fps)
- storage 仅需 8.3M (同期的 MobileNeRF 需要约 200M)
- 获得了和 NeRF 相媲美的效果,比 MobileNeRF 更好,MobileR2L 的 PSNR 是 26.15,MobileNeRF 是 25.91
一、背景
神经辐射场(NeRF)在 3D 场景的新视角的合成上表现出了很好的效果,但是,NeRF 是基于体渲染的,其推理速度很慢,限制了 NeRF 在移动端的使用
现在也有很多方法致力于研究如何降低 NeRF 的延时,但其主要是基于 GPU 加速,在移动端也是不可用的
但还有一种将 NeRF 转换成 neural light field (NeLF) 加速的方法,神经光场只需要一次前向递进就可以得到每个像素的颜色,所以渲染的速度很快,但递进的步数少了,质量自然就比较差,所以 NeLF 的网络结构设计了很多的密集计算,也不太适合移动端
比如 R2L 的方法提出了一个 88 层的全连接网络来蒸馏一个训练好的辐射模型,比原始的 NeRF 渲染速度提升了 30x,但渲染一个 200x200 的图片在 iphone13 上也需要 3s
在移动端运行 NeRF 或 NeLF 有困难的一大原因是需要 RAM,比如渲染一个 800x800 的图片,需要保存 640000 个 rays,会导致内存溢出
所以本文作者提出了一种可以在移动端实时渲染的网络结构,整个训练和 R2L 的过程很类似,不同的是 MobileR2L 没有使用 MLP 作为网络基本单元,而是使用的卷积网络

二、方法
2.1 NeRF 回顾
神经辐射场是什么样的呢:
- 多层类似 MLP 的全连接网络
- 输入为 5D coordinate: ( x , y , z , θ , ϕ ) ) (x,y,z,\theta, \phi)) (x,y,z,θ,ϕ))
- 输出为对应位置的透明度和 RGB 颜色

2.2 R2L
NeLF 函数是将一个特定方向的射线映射到 RGB。为了丰富输入信息,R2L提出了一种新的光线表示法——它们也像NeRF [33]那样沿着光线采样点,但不同的是,他们将这些点连接成一个向量,该向量被用作光线表示并输入到神经网络中以学习RGB。与NeRF类似,R2L也采用了位置编码[39]将每个标量坐标映射到高维空间。在训练期间,点是随机(通过均匀分布)采样的,在测试期间,这些点是固定的。
R2L模型的输出直接就是RGB,并没有学习密度,并且没有额外的alpha合成步骤, 这使得R2L在渲染上比NeRF快很多。然而, NeLF框架有一个缺陷, NeLF表示法比NeRF更难以学习,所以,R2L提出了一个 88 层深度 ResMLP(残差MLP) 架构 (比NeRF网络深得多) 来作为映射函数。
R2L训练有两个阶段:
- 第一阶段中, 使用预先训练好的NeRF模型作为教师来生成 (位置、方向、RGB) 三元组作为伪数据,然后将伪数据喂给深度 ResMLP 进行训练,这个阶段可以使 R2L 模型达到与教师 NeRF 模型相当的性能
- 在第二阶段中, 对第一阶段从原始数据上微调 R2L 网络,进一步提升渲染质量
2.3 MobileR2L
作者按照 R2L 的学习过程来训练 MobileR2L,即使用一个预训练的教师模型,如NeRF [33] 来为轻量级神经网络的训练生成伪数据。
为了提升推理速度,只在渲染图像时向前推理一次即可。然而,在R2L的设计下,尽管一个像素只需要一个网络向前推进,但直接将具有大空间大小(例如800×800)的光线输入到网络会导致内存问题。因此,R2L每次只向前推进部分光线,这会增加速度开销。为了解决这个问题,作者引入超分辨率模块, 这些模块可以将低分辨率输入(例如100×100)上采样到高分辨率图像。因此,在推断时间内, 我们可以通过神经网络仅仅一次前向传播就获得高分辨率图像,训练和推理流程如图 2 。

2.3.1 网络结构
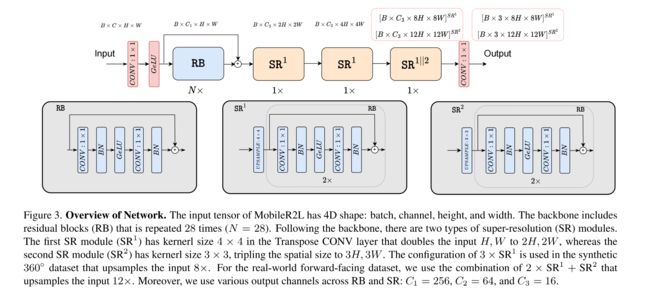
MobileR2L 的输入:
- ray 表示如下, x ∈ R B , 6 , H , W \text{x} \in R^{B,6,H,W} x∈RB,6,H,W,B 是 batch,H 和 W 是分辨率
- 然后使用 positional encoding γ ( . ) \gamma(.) γ(.) 来将 x \text{x} x 的位置和方向映射到高维上,所以 MobileR2L 的输入就是 γ ( x ) \gamma(\text{x}) γ(x)
MobileR2L 的网络结构:
- part1:efficient backbone,没有使用传统的 FC 层,而是使用卷积层
- part2:Super-Resolution(SR)modules,也使用的卷积层
使用卷积层替代 FC 层的原因:
- 卷积层更易于优化,同样的参数量下,使用 conv 1x1 的模型比 FC 的模型快 27%
- 如果在 backbone 中使用 FC 层,则要使用 reshape 和 permute 操作来将 FC 的输出变形成卷积支持的超分辨模块,但这两个操作对移动硬件不友好
1、Efficient Backbone
整个 backbone 的设计类似于 R2L,不同的是本文在每个残差块儿中使用的是卷积层而不是全连接层,卷积的 kernel 和 stride 都是 1,且每个模块中都使用了 BN 和 GeLU,能够提高效果,也不会引入额外的延时,backbone 总共包含 60 层卷积
2、Super-Resolution Modules
为了降低在移动端渲染时的延时,作者使用了一次递进就得到每个位置的颜色的方法
但是现有的方法需要很大的内存来渲染高分辨率的图片,移动端存储无法承受,假设渲染 800x800 的图片,就需要 640000 rays,这在 Nvidia A100 (40G memory) 上都可能发生内存溢出的问题
为了降低内存和延时,作者没有对所有 ray 都进行前向递进,而是选择了一部分 ray 来递进,对其他部分采样超分辨率重建的方法
所以本文作者提出了在 efficient backbone 之后使用超分辨率重建的方式来提高分辨率
假设要生成 800x800 的图片,作者会前向递进 100x100 rays,然后使用上采样 3 次,然后输入 SR 模型,之后输入 sigmoid 来预测最终的 RGB 颜色,模型名称定义为 D60-SR3(60 层卷积,3 个超分)
SR 模型包括两个堆叠的残差模块:
- 第一个模块包括 3 个卷积层
- 第二个模块包括 2 个 1x1 卷积
三、效果
3.1 数据集
作者使用了两个数据集:
- realistic synthetic 360◦ [33]
- real-world forward-facing [32, 33]
3.2 实验细节
训练过程类似 R2L,使用一个 teacher 模型来渲染出 pseudo image 来训练 MobileR2L 模型
作者为每个场景合成了约 10k pseudo images,首先在伪标签上训练 MobileR2L,然后在真实数据上训练 MobileR2L
和 R2L 不同的地方:
- input rays 的 spatial size 和 output 的渲染结果图像的大小是不同的
- 没有从不同的图片中采样 rays(R2L 中从多个图片中采样了 rays),而是每个 sample 的 ray 的位置都是一样的
3.3 渲染效果对比


3.4 推理速度对比

四、实际应用
虚拟试穿

五、代码
首先,下载数据集:lego 和 fern
sh script/download_example_data.sh
训练:
第一步:得到 rays_o 和 rays_d,维度都为 [10, 10000, 3],其中 10 是 batch,10000=100x100,3 表示每个位置或方向都由 3 维特征表示。得到 target_rgb,维度为 [10, 640000, 3]
先获得这 100 个 rays 的 directions
# 我们可以先看看设置的超参数如下
{'downscaled_height': 100, 'downscaled_width': 100, 'downscaled_focal': 138.88888549804688, 'scale': 2.6874192464086213, 'max_radius': 1.5000001192092896, 'ff': False, 'dataset_type': 'nerf', 'sc': None}
注意,数据的函数 colmap.py line372 中有这样一个操作,这个操作是很关键的一步,因为这个文章中其实是用 100x100 个 rays 来实现神经光场,所以需要对焦距进行变化。
focal = focal * (input_height / H)
这种变换是对焦距进行缩放的操作,目的是将图像从原始大小调整到新的大小。在计算机视觉中,焦距(focal length)是相机内部参数之一,它决定了相机能够"看到"场景中多大范围的内容。
在NeRF (Neural Radiance Fields)模型中,输入图像可能会被调整大小以适应模型或硬件限制。当我们改变图像的尺寸时(例如从800px高度缩小到100px),我们必须同时调整相应的焦距。
简单来说,如果你把图像尺寸改变了8倍(从800px降低到100px),那么你也需要将焦距除以8以保持场景内容不变。这就是为什么有focal = focal * (input_height / H)这个公式。
通过这样做, 我们可以确保无论输入图像如何缩放, 相机参数和场景内容都会按照同样比例进行调整, 使得渲染结果与原始图片保持一致.
然后,使用 get_rays() 来获得,其输入为 directions 和 c2w
directions: tensor([[-0.3564, 0.3564, -1.0000],
[-0.3492, 0.3564, -1.0000],
[-0.3420, 0.3564, -1.0000],
...,
[ 0.3420, -0.3564, -1.0000],
[ 0.3492, -0.3564, -1.0000],
[ 0.3564, -0.3564, -1.0000]])
cw2: tensor([[-0.8006, -0.5324, 0.2749, 1.1082],
[ 0.5992, -0.7114, 0.3673, 1.4807],
[ 0.0000, 0.4588, 0.8885, 3.5818]])
directions: torch.Size([10000, 3])
cw2: torch.Size([3, 4])
得到
rays_o: torch.Size([10000, 3])
rays_d: torch.Size([10000, 3])
rgb: (640000, 3)
第二步:对 rays_o 和 rays_d 进行采样
@torch.cuda.amp.autocast(enabled=False)
class PointSampler:
def __init__(self, dataset_info : dict):
"""_summary_
Args:
dataset_info (dict):
H
W
focal
device
cam_convention
near
far
n_sample
ndc
ff
"""
self.dataset_info = dataset_info
self.direction = get_ray_directions(
self.dataset_info['H'],
self.dataset_info['W'],
self.dataset_info['focal'],
self.dataset_info['device'],
self.dataset_info['camera_convention']
)
self.t = (
torch.linspace(0., 1., steps=self.dataset_info['n_sample_per_ray'])
.to(self.dataset_info['device'])
)
z = self.dataset_info['near'] * (1 - self.t) + self.dataset_info['far'] * self.t
self.z = (
z[None, :]
.expand(self.dataset_info['H'] * self.dataset_info['W'], self.dataset_info['n_sample_per_ray'])
)
def sample(
self,
rays_o : Optional[Float[Tensor, 'N 3']]=None,
rays_d : Optional[Float[Tensor, 'N 3']]=None,
c2w : Optional[Union[Float[Tensor, '3 4'], Float[Tensor, 'N 3 4']]]=None,
perturb : bool=True
):
if c2w is not None:
# during test phase
rays_o, rays_d = get_rays(self.direction, c2w)
#todo: confirm this is the behaviour of orignal code
perturb = False # don't perturb during inference
else:
# during training phase
assert rays_o is not None and rays_d is not None
if perturb:
mids = .5 * (self.z[..., 1:] + self.z[..., :-1]) # torch.Size([10000, 7])
upper = torch.cat([mids, self.z[..., -1:]], dim=-1) # torch.Size([10000, 8])
lower = torch.cat([self.z[..., :1], mids], dim=-1) # torch.Size([10000, 8])
t_rand = torch.rand(self.z.shape).to(self.dataset_info['device']) # [n_ray, n_sample],torch.Size([10000, 8])
z = lower + (upper - lower) * t_rand # torch.Size([10000, 8])
else:
z = self.z
if self.dataset_info['ff'] and self.dataset_info['ndc']:
# use ndc space for ff
rays_o, rays_d = self._to_ndc(rays_o, rays_d)
# (H*W, n_sample, 3)
pts = rays_o[..., None, :] + rays_d[..., None, :] * z[..., :, None] # [10, 10000, 8, 3]
#todo: check if .view is needed
return pts.view(pts.shape[0], -1) # [10, 240000]
第三步:对采样得到的 pts 进行位置编码
@torch.cuda.amp.autocast(enabled=False)
class PositionalEmbedder:
def __init__(
self,
L : int,
device : torch.device,
include_input : bool=True
):
self.weights = 2**torch.linspace(0, L - 1, steps=L).to(device) # [L],[ 1., 2., 4., 8., 16., 32.]
self.include_input = include_input
self.embed_dim = 2 * L + 1 if include_input else 2 * L
def __call__(self, x):
y = x[..., None] * self.weights # [n_ray, dim_pts, 1] * [L] -> [n_ray, dim_pts, L], [10, 240000, 1] -> [10, 240000, 6]
y = torch.cat([torch.sin(y), torch.cos(y)], dim=-1)
if self.include_input:
y = torch.cat([y, x.unsqueeze(dim=-1)], dim=-1) # [10, 240000, 13])
return y.view(y.shape[0], -1) # [n_ray, dim_pts*(2L+1)],[10, 3120000]
第四步:将位置编码后的 pts 输入网络,得到 rgb:[10, 3, 800, 800],R2L 的结构如下:
(Pdb) self.engine
R2L(
(head): Sequential(
(0): Conv2d(312, 256, kernel_size=(1, 1), stride=(1, 1))
(1): GELU()
)
(body): Sequential(
(0): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(9): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(10): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(11): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(12): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(13): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(14): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(15): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(16): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(17): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(18): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(19): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(20): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(21): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(22): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(23): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(24): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(25): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(26): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(27): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(28): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(tail): Sequential(
(0): ConvTranspose2d(256, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(4): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): ConvTranspose2d(64, 16, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(7): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): ResnetBlock(
(conv_block): Sequential(
(0): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): GELU()
(3): Conv2d(16, 16, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(9): Conv2d(16, 3, kernel_size=(1, 1), stride=(1, 1))
(10): Sigmoid()
)
)