1 人工智能与Agent(9-7,9-14,9-21)
文章目录
- 1 人工智能的定义
- 2 Agent示例:吸尘器
- 3 Agent设计的四种理念
- 4 理性Agent
- 5 自动驾驶Agent的PEAS
- 6 Agent所处环境的类型
- 7 Agent的类型
-
- 7.1 简单反射Agent
- 7.2 基于模型的反射Agent
- 7.3 基于目标的Agent
- 7.4 基于效用的Agent
- 8 可进行自学习的Agent
- 9 Agent的组织方式
1 人工智能的定义
人工智能是一门研究、设计智能体Agent的科学;智能体Agent的特点是:(1)可以从环境中感知信息;(2)可以作用于环境;(3)可以最大化行动成功的机会。
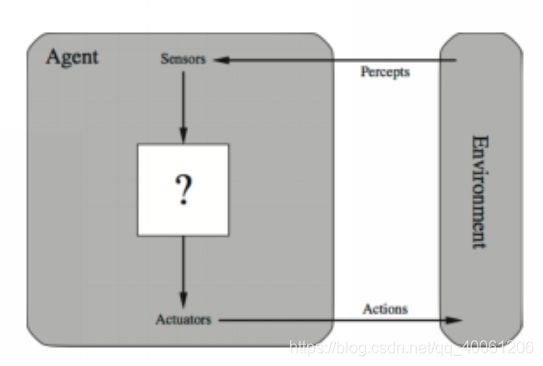
由上图可以看出,Agent通过传感器Sensor感知环境,并通过执行器Actuator作用于环境。Agent通过传感器和执行器与环境进行交互。
2 Agent示例:吸尘器
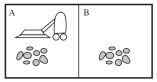
如上图:环境为A和B两个房间,房间内可能有灰尘;Agent为吸尘器。
吸尘器Agent可以感知自己的位置,即可以判断自己在那个房间;还可以感知两个房间是否有灰尘。
吸尘器Agent可以执行的行动有:Left、Right、Suck、NoOp,分别指左移、右移、吸尘、什么也不做。
吸尘器Agent的功能为从映射表中,将感知序列对应的行动通过执行器Actuator执行。映射表如下:

解释上面的映射表:
(1)若A房间clean,则右移到B房间;
(2)若A房间dirty,则吸尘;
(3)若B房间clean,则左移到A房间;
(4)若B房间dirty,则吸尘;
因此,人工智能的任务就是设计可以实现agent函数的agent程序。Agent函数是对agent功能的抽象数学描述;而Agent程序是对Agent函数的具体实现。
3 Agent设计的四种理念

合理Agent(rational agent)是一个为了实现最佳结果,或者,当存在不确定性时,为了实现最佳期望结果而行动的Agent。
理性Agent:对每一个可能的感知序列,根据已知的感知序列提供的证据和Agent具有的先验知识,理性Agent应该选择能使其性能度量最大化的行动。
理性是使期望的性能最大化,完美是使实际的性能最大化。
4 理性Agent
理性Agent的定义:对于任意的感知序列,一个理性Agent应该能根据自己已有的先验知识去选择执行使期望的性能度量最大化的行动。
在任何指定的时刻,什么是理性的判断依赖于以下4个方面PEAS:
- P:performance,定义成功标准的性能度量。
- E:environment,Agent对环境的先验知识。
- A:actuator,Agent的执行器可以完成的行动。
- S:sensor,Agent的传感器截止到此时的感知序列。
5 自动驾驶Agent的PEAS

(1)P:是否安全,时间多少,驾驶是否违规,乘客是否舒适;
(2)E:道路状况,其他车辆,行人,道路信号灯;
(3)A:方向盘,加速器,刹车,信号指示灯,喇叭;
(4)S:照相机,声纳,GPS,引擎传感器,键盘,速度计,里程表。
6 Agent所处环境的类型
(1)完全可观察(VS部分可观察):Agent的传感器可以在任何时候都能及时获取环境的完整状态。
(2)确定的(VS随机的):环境的下一状态完全取决于当前状态与Agent执行的行动。
(3)片段式(VS延续式):Agent的经验被分为一个个原子片段,其中每个片段包含Agent的感知序列与对应执行的单个行动。在每个原子片段中的行动仅取决于片段自身。
(4)静态的(VS动态的):在Agent进行思考或者计算时环境保持不变。若环境不随时间变化而Agent的性能度量随时间变化,则称环境是半动态的。
(5)离散的(VS连续的):环境的状态、时间的处理方式以及Agent的感知信息和行动,都有离散/连续之分。例如,国际象棋环境中的状态是有限的。国际象棋的感知信息和行动同时也是离散的。出租车驾驶是一个连续状态和连续时间问题:出租车和其他车辆的速度和位置都在连续空间变化,并且随时间的流逝而变化。出租车驾驶行动也是连续的(转弯角度等)。虽然严格来说,来自数字摄像头的输入信号是离散的,但处理时它表示的是连续变化的亮度和位置。
(6)单Agent(VS多Agent):在环境中只有一个Agent在运作。如:自动驾驶汽车的环境为多Agent,五子棋为双Agent,八皇后问题为单Agent。
(7)已知的(VS未知的):Agent的设计人员可能知道环境的组成要素,也可能不知道。若环境是未知的,则Agent必须知道环境的状况以便于决策。
7 Agent的类型
7.1 简单反射Agent
简单反射Agent基于当前的状态去抉择将执行的行动,并忽略历史的感知序列。这种Agent设计简单但是实际应用时受限。仅能在环境完全可观察时正常工作,即Agent的行动仅依赖于当前对环境的感知序列。
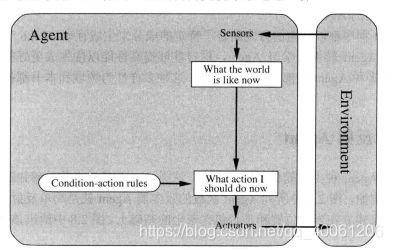
7.2 基于模型的反射Agent
处理部分可观测环境的最有效途径是让Agent跟踪记录现在看不到的那部分世界。即Agent应该根据感知历史维持内部状态,从而至少反映出当前状态看不到的信息。对于刹车问题,内部状态记录无需太大扩展——只需要记录视频的前一帧画面,这样Agent可以检测出车辆边缘的两盏红灯是否同时点亮或关闭。而对于其他驾驶任务如车辆变道,由于无法同时看到全部其他车辆,Agent需要跟踪记录其他车辆的位置。
世界/环境的模型基于:(1)世界/环境是怎样独立于Agent变化的;(2)Agent的行动会怎样影响世界/环境。

7.3 基于目标的Agent
一般仅知道环境的当前状态是远远不够的,Agent需要关于实现目标的信息。Agent程序根据【关于目标的信息】和【环境的模型】去抉择实现目标所采取的行动。基于目标的Agent需要考虑【如果我做了这样的行动,世界/环境会变成什么样】。
尽管基于目标的Agent效率较低,但是它更灵活,因为支持它决策的知识被显式表示出来,并且可以修改。

7.4 基于效用的Agent
有时候仅实现目标也是不够的:如对于规划行程的Agent,好的路线需要更快、更安全、更便宜…
“我这样做会很高兴吗?”——这些称为效用(Utility)。在基于效用的Agent中,效用函数即为对Agent性能的度量。
既然世界/环境充满了不确定性,则基于效用的Agent就必须可以最大化期望的效用。

基于效用的Agent要对环境建模并跟踪。基于效用的Agent比基于目标的Agent更灵活。
8 可进行自学习的Agent
学习Agent可以被划分为4个概念上的组件:
(1)学习元件:负责改进、提高。学习元件利用来自评判元件的反馈去确定应该如何修改性能元件以便将来做得更好。
(2)性能元件:负责选择外部行动。性能元件是前面考虑的整个Agent:它接受感知信息并决策。
(3)评判元件:评价Agent做得如何。
(4)问题产生器:负责可以得到新的和有信息的经验的行动提议。

9 Agent的组织方式
(1)原子表示:世界/环境是一个没有内部结构的“黑盒子”。如在选择一条行驶路线时,每一个状态为一个城市,可将世界状态简化地表示为只有城市的名字——知道单个原子。相关的AI算法有搜索、博弈论、马尔科夫决策过程、隐马尔科夫模型等等。

(2)要素化表示:每一种状态均有某些属性值。如在自动驾驶Agent中的GPS位置、油箱里的汽油量。相关的AI算法有规划、贝叶斯网络等等。
(3)结构化表示:不同状态之间的关系可以显示表示。相关的AI算法有一阶逻辑、基于知识的学习、自然语言理解。
END