ArrayList 和 HashMap 源码解析
1、ArrayList
1.1、ArrayList 构造方法
无参创建一个 ArrayList 数组默认为空数组
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private int size; // 数组容量大小
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
指定数组大小 创建一个 ArrayList 数组默认为 指定大小,
如果 initialCapacity == 0 默认为空数组
如果 initialCapacity < 0 则会抛出异常
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
1.2、add 方法
1、判断数组是否为空,为空则扩容为10,然后修改次数加1,添加数据到数组
2、不为空,则获取扩容大小(原数组大小 + 原数组右移1位),相当于扩容为原来的1.5倍,判断扩容后若小于当前需要的容量,则扩容为当前需要容量大小,然后修改次数加1,添加数据到数组
3、不为空,则扩容(原数组大小 + 原数组右移1位),相当于扩容为原来的1.5倍,判断扩容后若不小于当前需要的容量,则1.5倍扩容,然后修改次数加1,添加数据到数组
4、第四重则是判断是否超过 Integer.MAX_VALUE,2的31次方-1.若是则抛出异常 OutOfMemoryError
- 扩容机制:默认大小为0,在新增的时候才会扩容,正常情况默认扩容为原来的1.5倍,然后会重新创建一个1.5倍大小的数组,再把原来数组上面的数据复制到新数组上面。
第二种情况只有设置数组初始容量为1时,才会发生。因为 1 >> 1 = 0;这时扩容时才会出现扩容后的比需要的小,才会进入 if (newCapacity - minCapacity < 0) 中
public boolean add(E e) {
ensureCapacityInternal(size + 1); // size 是当前数组大小,目前是0,传入1
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) { // 进入这个方法
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 判断当前数组是否为空
return Math.max(DEFAULT_CAPACITY, minCapacity); // 为空则返回一个大的值,10 和 1,10比较大,所以返回10
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
总结:
ArrayList 底层基于数组实现,查询快O(1),新增修改慢O(n),
查询基于索引,新增删除可能涉及到索引移位,新增还会涉及扩容
数组的元素都是连续存储的,这意味着在内存中,数组的元素之间是相邻的
2、LinkedList
LinkedList 是一个双向链表结构,每个节点是一个 node 节点,如下:
item 中存储的是数据,next存储的是下一个node节点的地址,prev存储的是上一个node节点的地址
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList 提供了针对头尾节点的操作,使得对头尾节点的 增删查 较快
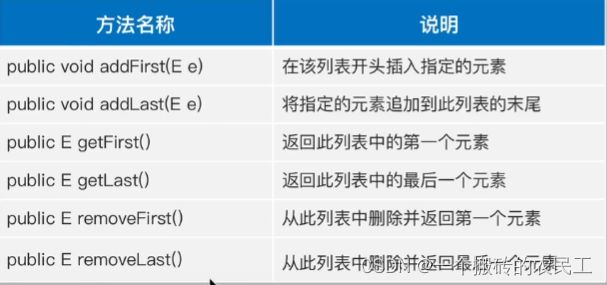
总结:
LinkedList 底层基于双向链表结构,增删快O(1),查询慢O(n)。
链表中的节点并不一定是在内存中连续存放的。每个节点实际上是一个对象,而对象在内存中是根据可用的空间分配的,因此它们不一定是连续的。LinkedList 中的节点通过引用(指针)来连接,而这些节点在内存中的位置是不连续的。
应用场景:
因为 removeFirst 会返回删除的元素,所以可以模拟 FIFO(先进先出)
1、可以用于设计队列
2、可以用于设计栈
3、HashMap
- 初始化的时候设置大小,因为扩容、重新计算hash值非常费时,建议为2的n次方。如果没有设置初始值默认为16(首次put时才会创建16的数组)
- jdk1.8以前是数组+单向链表,jdk1.8以后是数组+单向链表+红黑树
- HashMap 不是线程安全的,涉及到线程安全建议使用 ConcurrentHashMap
- 当链表长度等于8时,如果容量没有达到64,会先扩容。如果容量达到了64,链表会转为红黑树。当红黑树节点小于6个时会转为链表
- 数组为Node类型,在jdk7中称为Entry类型
- 链表时间复杂度为O(n),红黑树为O(logn)
3.1、HashMap 扩容机制
扩容是为了减少哈希冲突,提高存取效率。
HashMap 负载因子默认为 0.75
当临界值 > HashMap数组长度 * 0.75就会进行扩容- 当链表长度为8,HashMap数组长度小于64,就会进行扩容
hashmap扩容时会创建一个原数组两倍大的数组,然后遍历原数组,将原来所有的数据都移到新数组中。扩容之后需要重新hash,因为哈希值 = hashcode % (length -1),扩容后长度改变,hash值也会随之改变。
3.2、Node节点
哈希值(hash)、键(key)、值(value)以及指向下一个节点的引用(next)。
在 HashMap 的实现中,存储的键值对数据结构是通过链表来实现的。每个 Node 对象就是链表中的一个节点,通过 next 引用指向下一个节点。这样就可以处理哈希冲突,因为具有相同哈希值的键值对会放在同一个哈希桶中,通过链表进行连接。当链表长度达到一定阈值时,会将链表转换为红黑树以提高查询效率。
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
3.3、负载因子
为什么负载因子是0.75呢?
参数的设置是经过实际测试和经验得出的。加载因子的选择需要权衡空间和时间效率,
过小的加载因子会导致哈希表频繁扩容,
而过大的加载因子会导致链表过长,查找效率下降。
因此,0.75 是一个比较合理的折衷选择,可以在空间和时间上实现比较好的性能。