大数据学习笔记
大数据技术之大数据概论
第 1 章 大数据概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
按顺序给出数据存储单位:bit、Byte、KB、MB、GB、**TB、PB、EB、**ZB、YB、BB、NB、DB。
1Byte = 8bit
1K = 1024Byte
1MB = 1024K
1G = 1024M
1T = 1024G
1P = 1024T
第 2 章 大数据特点(4V)
- Volume (大量)
人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
- Velocity**(高速)**
天猫双十一:2017年3分01秒,天猫交易额超过100亿
2020年96秒,天猫交易额超过100亿
- Variety**(多样)**
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的
以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图
片、地理位置信息。
- Value**(低价值密度)**
价值密度的高低与数据总量的大小成反比。我们只想提取在大量数据中的有价值的信息。(”提纯“)
第三章 大数据的应用场景
- 抖音推荐你喜欢的视频
- 电商站内广告推荐:给用户推荐可能喜欢的商品
- 零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,纸尿布+啤酒。
- 物流仓储:京东物流,通过大数据分析各地该存储啥物品。
- 保险,金融,房产等
- 人工智能 + 5G + 物联网 + 虚拟与现实
第四章大数据发展前景
- 国家支持
- 下一个风口
- 人才缺,需求大,工资高
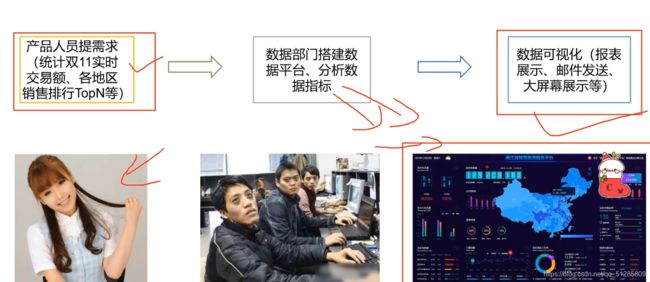
第五章 大数据部门间业务流程分析
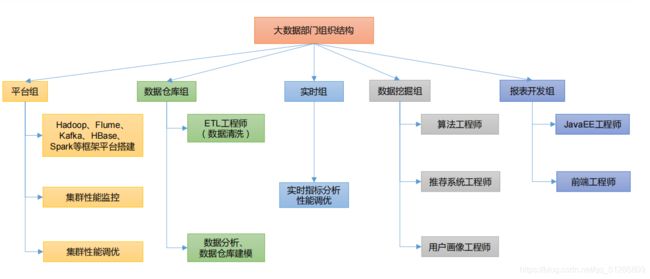
第 6 章 大数据部门内组织结构
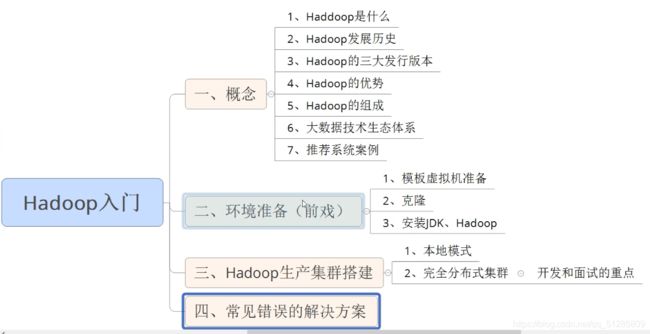
大数据技术之 Hadoop(入门)
学习路线图
一、概念
1.1、Hadoop是什么
-
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
-
主要解决,海量数据的存储和海量数据的分析计算问题。
-
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。

1.2、Hadoop的发展历史
-
Hadoop创始人Doug Cutting

-
名字来源于Doug Cutting儿子的玩具大象

1.3、Hadoop的三大发行版本**(了解)**
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008
Hortonworks 文档较好,对应产品 HDP。2011
Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌 CDP。
1.4、Hadoop 优势(4高)
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。

-
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
-
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度

- 高容错性:能够自动将失败的任务重新分配

1.5 Hadoop*组成(面试重点)
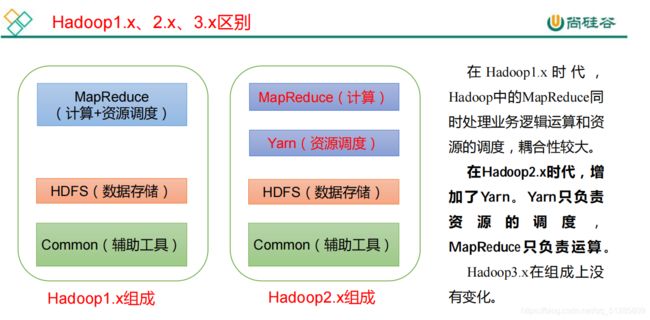
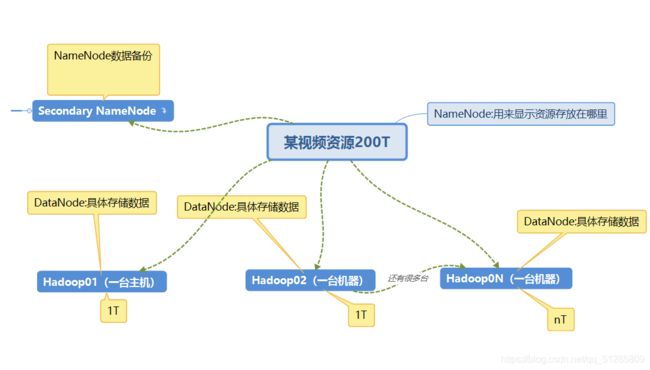
1.5.1 HDFS 架构概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
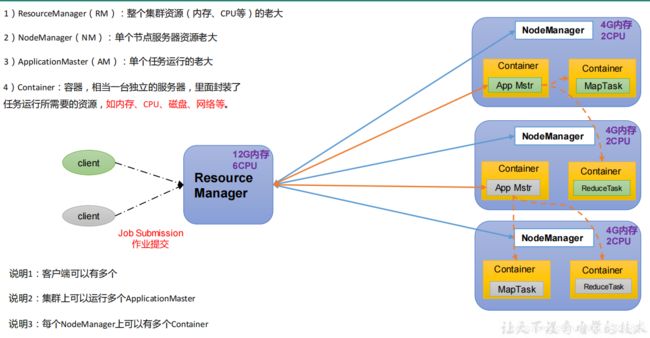
1.5.2 YARN架构概述
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
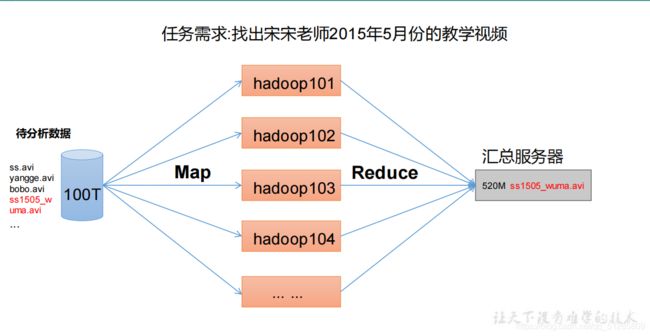
1.5.3 MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
-
Map 阶段并行处理输入数据
-
Reduce 阶段对 Map 结果进行汇总
1.5.4 HDFS、YARN、MapReduce 三者关系
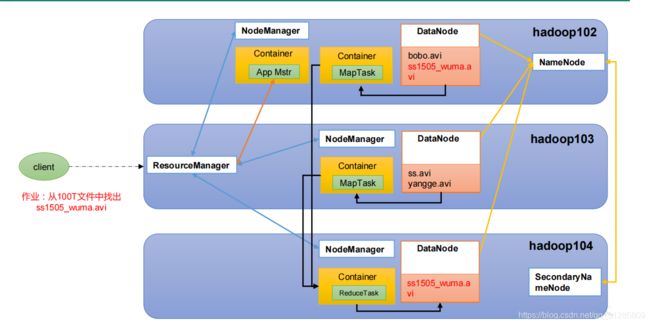
1.6 大数据技术生态体系
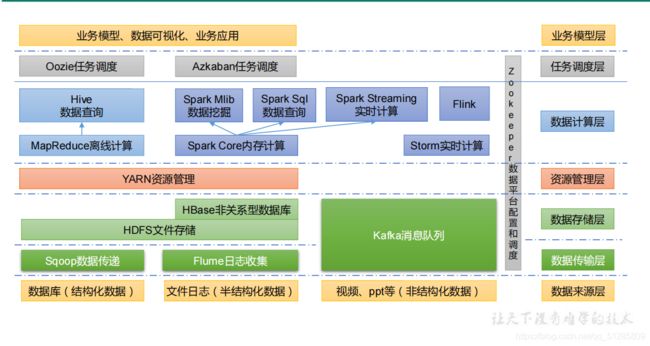
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)
间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进
到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数
据进行计算。
5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张
数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运
行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开
发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、
名字服务、分布式同步、组服务等。
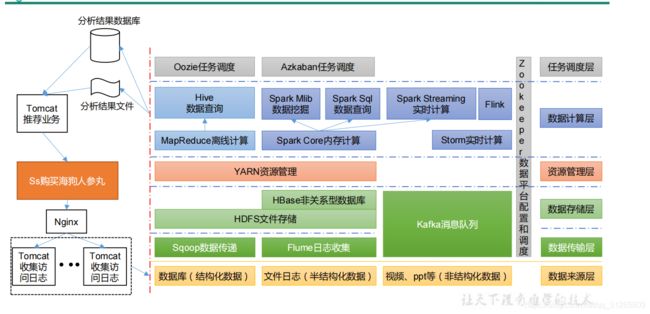
1.7 推荐系统框架图
二、环境准备
用户信息:
账号:lijunjie 密码123456,登录使用
1.模拟虚拟机准备
安装centos7.5镜像
模拟虚拟机准备
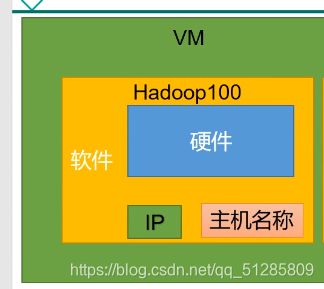
配置Ip和主机名配置
1.配置VM的ip

2.修改NAT设置
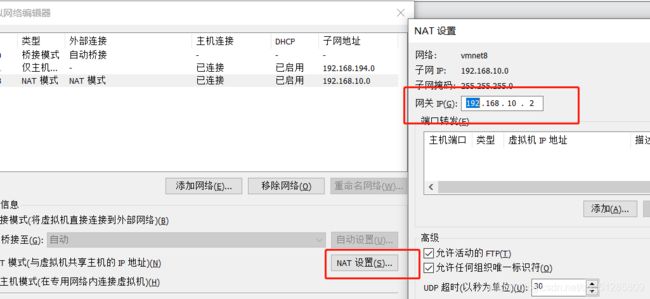
3.Windows的iP设置
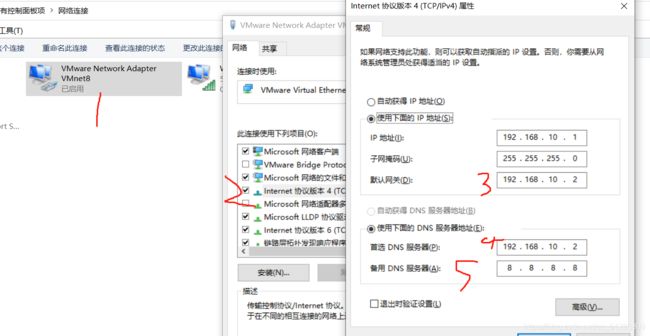
4.修改Hadoop的IP地址,主机名称
[root@Hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" //把ip地址改为静态ip地址,下次登录时ip不变
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="60915f68-5ac1-4e5c-bfaf-1ad91c02abcd"
DEVICE="ens33"
ONBOOT="yes"
//下面为新加内容
IPADDR=192.168.10.100 //设置ip地址
GATEWAY=192.168.10.2 //设置网关
DNS1=192.168.10.2 //设置域名解析器
5.修改主机名称
[root@Hadoop100 ~]# vim /etc/hostname
6.主机名称映射
- 将192.168.10.105的ip映射为为hadoop100,凡是出现192.168.10.105,。用hadoop100代替。
- 当因升级改变ip时,可以不用大量修改。

[root@Hadoop100 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.100 hadoop100 //一下都是添加的
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
7.然后重启reboot
- 查看当前ip(ifconfig)
- 能否联通外网(ping www.baidu.com)
- 查看主机名称(hostname)
Xshell远程访问工具
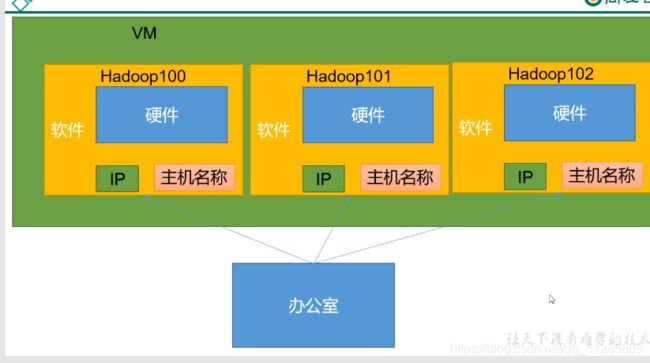
注意问题:
修改 windows 的主机映射文件(hosts 文件)
(1)如果操作系统是 window7,可以直接修改
(a)进入 C:\Windows\System32\drivers\etc 路径
(b)打开 hosts 文件并添加如下内容,然后保存
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
(2)如果操作系统是 window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入 C:\Windows\System32\drivers\etc 路径
(b)拷贝 hosts 文件到桌面
(c)打开桌面 hosts 文件并添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
(d)将桌面 hosts 文件覆盖 C:\Windows\System32\drivers\etc 路径 hosts 文件
hadoop100 虚拟机配置要求如下
- 使用 yum 安装需要虚拟机可以正常上网
- 安装 epel-release
[root@hadoop100 ~]# yum install -y epel-release
- 关闭防火墙,关闭防火墙开机自启
[root@Hadoop100 ~]# systemctl stop firewalld
[root@Hadoop100 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
-
创建 ljj 用户,并修改 ljj用户的密码(123456)
-
配置 ljj 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令
[root@hadoop100 ~]# vim /etc/sudoers 修改/etc/sudoers 文件,在%wheel 这行下面添加一行,如下所示: ## Allow root to run any commands anywhere root ALL=(ALL) ALL ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL 尚硅谷大数据技术之 Hadoop(入门) ljj ALL=(ALL) NOPASSWD:ALL -
在/opt 目录下创建文件夹,并修改所属主和所属组
(1) 在/opt 目录下创建 module、software 文件夹 [ljj@Hadoop100 opt]$ sudo mkdir module [ljj@Hadoop100 opt]$ sudo mkdir software (2)修改 module、software 文件夹的所有者和所属组均为 atguigu 用户 [root@hadoop100 ~]# chown ljj:ljj /opt/module [root@hadoop100 ~]# chown ljj:ljj /opt/software (3) (3)查看 module、software 文件夹的所有者和所属组 [root@hadoop100 ~]# cd /opt/ [root@hadoop100 opt]# ll 总用量 12 [root@Hadoop100 opt]# ll 总用量 0 drwxr-xr-x. 2 ljj ljj 6 4月 24 09:27 module drwxr-xr-x. 2 ljj ljj 6 4月 24 09:27 software -
卸载虚拟机自带的 JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
[root@Hadoop100 opt]# rpm -qa | grep -i java //查询已经安装的jdk
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
tzdata-java-2018c-1.el7.noarch
java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
- )重启虚拟机 reboot
2 . 克隆虚拟机
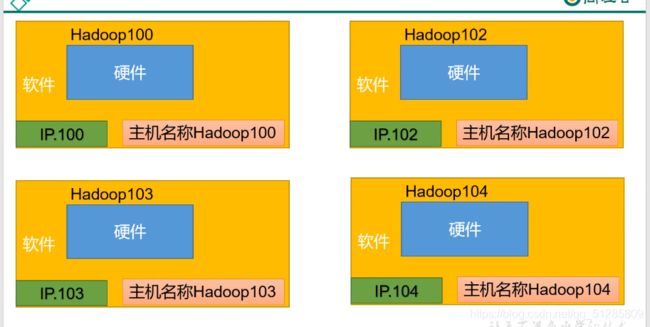
1.利用模板机 hadoop100
克隆三台虚拟机:hadoop102 hadoop103 hadoop104
- 注意:克隆时,要先关闭 hadoop100
2.修改克隆机 IP
以下以 hadoop102 举例说
1)修改克隆虚拟机的静态 IP
[root@hadoop100 ~]#vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.102 //改下IP地址
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
3.修改克隆机主机名,
- 以下以 hadoop102 举例说明
(1)修改主机名称
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
(2)配置 Linux 克隆机主机名称映射 hosts 文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
4.JDK的安装
-
在Hadoop102上安装jdk,然后复制到其它虚拟机
-
卸载现有 JDK
-
用 XShell 传输工具将 JDK 导入到 opt 目录下面的 software 文件夹下面
出现问题:远程登录使用lijunjie用户传输显示失败。
解决方法:改为远程登录使用root,即可成功。
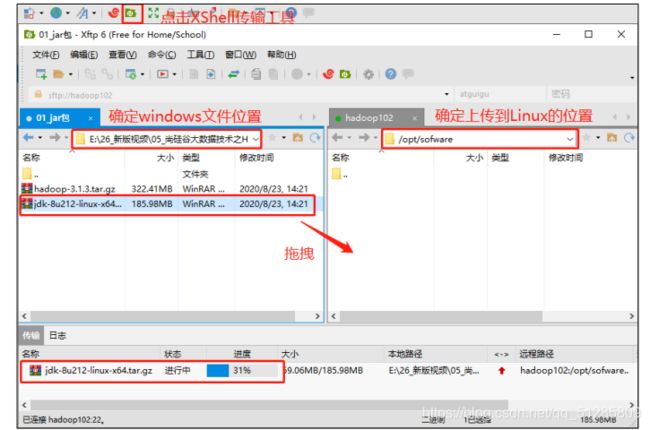
- 查看是否传输成功
- 解压 JDK 到/opt/module 目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 配置 JDK 环境变量
1)新建/etc/profile.d/my_env.sh 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出
:wq
(3)source 一下/etc/profile 文件,让新的环境变量 PATH 生效
[atguigu@hadoop102 ~]$ source /etc/profile
- )测试 JDK 是否安装成功
[ljj@Hadoop102 opt]$ java -version
java version "1.8.0_212" //出现这个即为成功
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[ljj@Hadoop102 opt]$
6.在 hadoop102 安装 Hadoop
- 1)用 XShell 文件传输工具将 hadoop-3.1.3.tar.gz 导入到 opt 目录下面的 software 文件夹
- 进入到 Hadoop 安装包路径下
[ljj@hadoop102 software]$ cd /opt/software/
- 解压安装文件到/opt/module 下面
[ljj@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ (时间有点长)
- 查看是否解压成功
查看是否解压成功
[ljj@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3
- 将 Hadoop 添加到环境变量
(1)获取 Hadoop 安装路径
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh 文件
[atguigu@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
➢ 在 my_env.sh 文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
➢ 保存并退出: :wq
(3)让修改后的文件生效
[atguigu@hadoop102 hadoop-3.1.3]$ source /etc/profile
- 测试是否安装成功
[ljj@Hadoop102 opt]$ hadoop version
Hadoop 3.1.3
- 重启(如果 Hadoop 命令不能用再重启虚拟机)
[atguigu@hadoop102 hadoop-3.1.3]$ sudo reboot
7.Hadoop 目录结构
- 查看 Hadoop 目录结构
[ljj@Hadoop102 module]$ cd hadoop-3.1.3/
[ljj@Hadoop102 hadoop-3.1.3]$ ll
总用量 176
drwxr-xr-x. 2 ljj ljj 183 9月 12 2019 bin
drwxr-xr-x. 3 ljj ljj 20 9月 12 2019 etc
drwxr-xr-x. 2 ljj ljj 106 9月 12 2019 include
drwxr-xr-x. 3 ljj ljj 20 9月 12 2019 lib
drwxr-xr-x. 4 ljj ljj 288 9月 12 2019 libexec
-rw-rw-r--. 1 ljj ljj 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 ljj ljj 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 ljj ljj 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 ljj ljj 4096 9月 12 2019 sbin
drwxr-xr-x. 4 ljj ljj 31 9月 12 2019 share
[ljj@Hadoop102 hadoop-3.1.3]$ cd bin/
- 重要目录
(1)bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
[ljj@Hadoop102 hadoop-3.1.3]$ cd bin/
[ljj@Hadoop102 bin]$ ll
-rwxr-xr-x. 1 ljj ljj 441936 9月 12 2019 container-executor
-rwxr-xr-x. 1 ljj ljj 8707 9月 12 2019 hadoop
-rwxr-xr-x. 1 ljj ljj 11265 9月 12 2019 hadoop.cmd
-rwxr-xr-x. 1 ljj ljj 11026 9月 12 2019 hdfs
-rwxr-xr-x. 1 ljj ljj 8081 9月 12 2019 hdfs.cmd
-rwxr-xr-x. 1 ljj ljj 6237 9月 12 2019 mapred
-rwxr-xr-x. 1 ljj ljj 6311 9月 12 2019 mapred.cmd
-rwxr-xr-x. 1 ljj ljj 483728 9月 12 2019 test-container-executor
-rwxr-xr-x. 1 ljj ljj 11888 9月 12 2019 yarn
-rwxr-xr-x. 1 ljj ljj 12840 9月 12 2019 yarn.cmd
(2)etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3)lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4)sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5)share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
三 、Hadoop 运行模式
3.1 三种运行模式基本介绍
- Hadoop 官方网站:http://hadoop.apache.org/
- Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 ➢ 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模 拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。

3.2 本地运行模式(官方 WordCount案例)
-
创建在 hadoop-3.1.3 文件下面创建一个 wcinput 文件夹
[ljj@Hadoop102 hadoop-3.1.3]$ mkdir wcinput -
在 wcinput 文件下创建一个 word.txt 文件
[ljj@hadoop102 hadoop-3.1.3]$ cd wcinput
- 编辑 word.txt 文件
[ljj@hadoop102 wcinput]$ vim word.txt ➢ 在文件中输入如下内容
ss ss
cls cls
shaolin
shaomin
wudang
wudang
wudang
➢ 保存退出::wq
- 回到 Hadoop 目录/opt/module/hadoop-3.1.3
- 执行程序
[ljj@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
出现一大长串字符
//可以通过连续两次按tab获取 下一步路径的信息
[ljj@Hadoop102 hadoop-3.1.3]$ hadoop jar share/
doc/ hadoop/
- 查看结果
[ljj@Hadoop102 hadoop-3.1.3]$ cd wcoutput/
[ljj@Hadoop102 wcoutput]$ ll
总用量 4
-rw-r--r--. 1 ljj ljj 44 4月 24 20:27 part-r-00000
-rw-r--r--. 1 ljj ljj 0 4月 24 20:27 _SUCCESS
[ljj@Hadoop102 wcoutput]$ cat part-r-00000
` 1
cls 2
shaolin 1
shaomin 1
ss 2
wudang 3
在文件中输入如下内容
ss ss
cls cls
shaolin
shaomin
wudang
wudang
wudang
➢ 保存退出::wq
4. 回到 Hadoop 目录/opt/module/hadoop-3.1.3
5. 执行程序
[ljj@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
出现一大长串字符
//可以通过连续两次按tab获取 下一步路径的信息
[ljj@Hadoop102 hadoop-3.1.3]$ hadoop jar share/
doc/ hadoop/
6. 查看结果
[ljj@Hadoop102 hadoop-3.1.3]$ cd wcoutput/
[ljj@Hadoop102 wcoutput]$ ll
总用量 4
-rw-r–r--. 1 ljj ljj 44 4月 24 20:27 part-r-00000
-rw-r–r--. 1 ljj ljj 0 4月 24 20:27 _SUCCESS
[ljj@Hadoop102 wcoutput]$ cat part-r-00000
` 1
cls 2
shaolin 1
shaomin 1
ss 2
wudang 3
3.3 完全分布式运行模式(开发重点)
分析:
1)准备 3 台客户机(关闭防火墙、静态 IP、主机名称)
2)安装 JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
6)配置集群 尚硅谷大数据技术之 Hadoop(入门)
7)单点启动
8)配置 ssh
9)群起并测试集群
3.3.1虚拟机准备
克隆一下Hadoop102
3.3.2 编写集群分发脚本 xsync
scp(secure copy)安全拷贝
1)scp 定义
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
(3)案例实操
➢ 前提:在 hadoop102、hadoop103、hadoop104 都已经创建好的/opt/module、
/opt/software 两个目录,并且已经把这两个目录修改为 atguigu:atguigu
[atguigu@hadoop102 ~]$ sudo chown atguigu:atguigu -R
/opt/module
(a)在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到
hadoop103 上。
[atguigu@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212
atguigu@hadoop103:/opt/module
(b)在 hadoop103 上,将 hadoop102 中/opt/module/hadoop-3.1.3 目录拷贝到
hadoop103 上。
[atguigu@hadoop103 ~]$ scp -r
atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
(c)在 hadoop103 上操作,将 hadoop102 中/opt/module 目录下所有目录拷贝到
hadoop104 上。
[atguigu@hadoop103 opt]$ scp -r
atguigu@hadoop102:/opt/module/*
atguigu@hadoop104:/opt/module
rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更
新。scp 是把所有文件都复制过去.
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
选项 功能
-a 归档拷贝
-v 显示复制过程
(2)案例实操
(a)删除 hadoop103 中/opt/module/hadoop-3.1.3/wcinput
[atguigu@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/
(b)同步 hadoop102 中的/opt/module/hadoop-3.1.3 到 hadoop103
[atguigu@hadoop102 module]$ rsync -av hadoop-3.1.3/
atguigu@hadoop103:/opt/module/hadoop-3.1.3/
xsync 集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync 命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt/
(b)期望脚本:
xsync 要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atgu
igu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin
(3)脚本实现
(a)在/home/atguigu/bin 目录下创建 xsync 文件
[atguigu@hadoop102 opt]$ cd /home/atguigu
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin
[atguigu@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
(b)修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod +x xsync
(c)测试脚本
[atguigu@hadoop102 ~]$ xsync /home/lijunjie/bin
(d)将脚本复制到/bin 中,以便全局调用
[atguigu@hadoop102 bin]$ sudo cp xsync /bin/
(e)同步环境变量配置(root 所有者)
[atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了 sudo,那么 xsync 一定要给它的路径补全。
让环境变量生效
[atguigu@hadoop103 bin]$ source /etc/profile
[atguigu@hadoop104 opt]$ source /etc/profile
ssh免密登录
免密登录原理
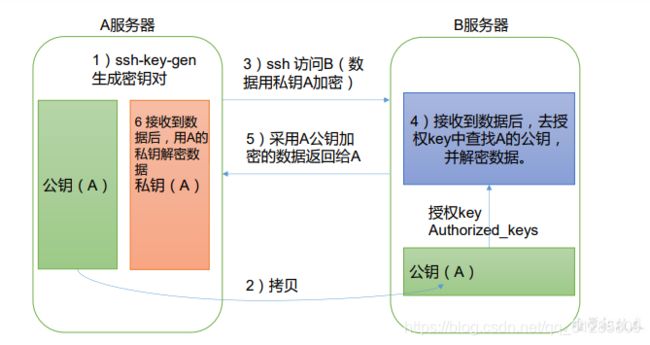
1.生成公钥和私钥
[atguigu@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
[lijunjie@Hadoop104 .ssh]$ ll
总用量 12
-rw-------. 1 lijunjie lijunjie 1675 4月 26 18:34 id_rsa
-rw-r--r--. 1 lijunjie lijunjie 400 4月 26 18:34 id_rsa.pub
-rw-r--r--. 1 lijunjie lijunjie 372 4月 26 18:25 known_hosts
2.将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id Hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id Hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id Hadoop104
3.注意
注意:
还需要在 Hadoop103 上采用 lijunjie 账号配置一下无密登录到 hadoop102、hadoop103、
Hadoop104 服务器上。
还需要在 hadoop104 上采用 lijunjie账号配置一下无密登录到 hadoop102、hadoop103、
Hadoop104 服务器上。
还需要在 Hadoop102 上采用 root 账号,配置一下无密登录到 hadoop102、hadoop103、
hadoop104;
4…ssh 文件夹下(~/.ssh)的文件功能解释
known_hosts 记录 ssh 访问过计算机的公钥(public key)
id_rsa 生成的私钥
id_rsa.pub 生成的公钥
authorized_keys 存放授权过的无密登录服务器公钥
集群配置
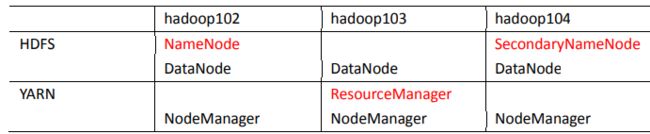
1.集群部署规划
注意:
➢ NameNode 和 SecondaryNameNode 不要安装在同一台服务器
➢ ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在
同一台机器上。
需求图:
2.配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认
配置值时,才需要修改自定义配置文件,更改相应属性值。
- 默认的配置文件

3.配置集群
- 核心配置文件
- 配置 core-site.xml
[lijunjie@Hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[lijunjie@Hadoop102 hadoop]$ vim core-site.xml
文件内容如下:
拷贝之间的内容
fs.defaultFS
hdfs://Hadoop102:8020
hadoop.tmp.dir //表示创建的临时文件,一个月后会自动销毁
/opt/module/hadoop-3.1.3/data //改成固定文件
hadoop.http.staticuser.user
lijunjie
- HDFS 配置文件
- 配置 hdfs-site.xml
[lijunjie@Hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下:
dfs.namenode.http-address
Hadoop102:9870
dfs.namenode.secondary.http-address
Hadoop104:9868
3.YARN 配置文件
-
配置 yarn-site.xml
[lijunjie@hadoop102 hadoop]$ vim yarn-site.xml
文件内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
Hadoop103
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME
4.MapReduce 配置文件
- 配置 mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
文件内容如下:
mapreduce.framework.name
yarn
5.在集群上分发配置好的 Hadoop 配置文件
[lijunjie@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
6.去 103 和 104 上查看文件分发情况
[atguigu@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[atguigu@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xm
3.3.3 群起集群
关闭服务命令
[lijunjie@hadoop102 software]$ stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as lijunjie in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [hadoop102]
Stopping datanodes
Stopping secondary namenodes [hadoop104]
Stopping nodemanagers
hadoop104: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
hadoop103: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
1.配置 workers
[lijunjie@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[lijunjie@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
2.启动集群
2.1如果集群是第一次启动
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式
化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找
不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停
止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式
化。)
[lijunjie@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
2.2启动 HDFS
[lijunjie@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
Starting namenodes on [hadoop102]
Starting datanodes
hadoop104: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
hadoop103: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [hadoop104]
----------------------------------------------
[lijunjie@hadoop102 hadoop-3.1.3]$ jps
4241 Jps
3977 DataNode
3820 NameNode
---------------------------------
[lijunjie@hadoop103 ~]$ jps
3072 DataNode
3480 Jps
-------------------------
[lijunjie@hadoop104 .ssh]$ jps
3030 DataNode
3094 SecondaryNameNode
3210 Jps
2.3启动 YARN
在配置了 ResourceManager 的节点(hadoop103)
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
[lijunjie@hadoop103 hadoop-3.1.3]$ jps
3072 DataNode
4069 Jps
3607 ResourceManager
3719 NodeManager
-------------------------
[lijunjie@hadoop102 hadoop-3.1.3]$ jps
4322 NodeManager
3977 DataNode
3820 NameNode
4447 Jps
-----------------
[lijunjie@hadoop104 hadoop-3.1.3]$ jps
8160 DataNode
8416 NodeManager
8563 Jps
8284 SecondaryNameNode
2.4 Web 端查看 HDFS 的 NameNode
-
浏览器中输入:http://hadoop102:9870
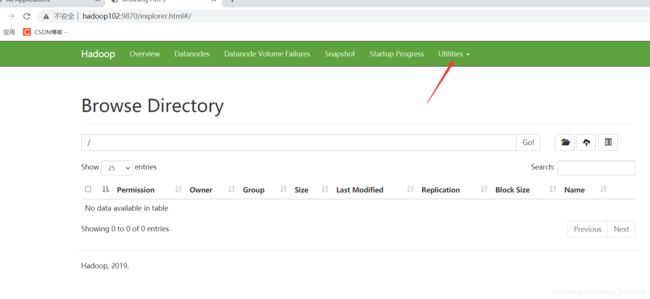
-
查看 HDFS 上存储的数据信息
2.5 Web 端查看 YARN 的 ResourceManager
- 浏览器中输入:http://hadoop103:8088
- 查看 YARN 上运行的 Job 信息
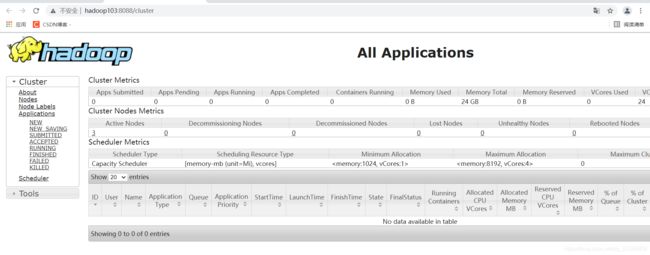
3. 集群基本测试
3.1 上传文件到集群
上传小文件
[lijunjie@hadoop102 subdir0]$ hadoop fs -mkdir /input //上传了一个input空文件夹
[lijunjie@hadoop102 subdir0]$ hadoop fs -put wcinput/word.txt /input // 把word.txt文件上传到input里面
上传大文件
把jdk上传到/ 下了
[lijunjie@hadoop102 subdir0]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
-put 表示上传

3.2上传后看文件存放在哪里
[lijunjie@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-238949251-192.168.10.102-1619877031998/current/finalized/subdir0/subdir0
[lijunjie@hadoop102 subdir0]$ ll
总用量 191944
-rw-rw-r--. 1 lijunjie lijunjie 51 5月 1 22:24 blk_1073741825
-rw-rw-r--. 1 lijunjie lijunjie 11 5月 1 22:24 blk_1073741825_1001.meta
-rw-rw-r--. 1 lijunjie lijunjie 134217728 5月 1 22:31 blk_1073741826
-rw-rw-r--. 1 lijunjie lijunjie 1048583 5月 1 22:31 blk_1073741826_1002.meta
-rw-rw-r--. 1 lijunjie lijunjie 60795424 5月 1 22:31 blk_1073741827
-rw-rw-r--. 1 lijunjie lijunjie 474975 5月 1 22:31 blk_1073741827_1003.meta
[lijunjie@hadoop102 subdir0]$ cat blk_1073741825
ss ss
cls cls
shaolin
shaomin
wudang
wudang
wudang
hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
3.3下载
hadoop fs -get 要下载的文件 在那个路径
[lijunjie@hadoop104 software]$ hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
2021-05-01 22:53:26,041 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[lijunjie@hadoop104 software]$ ll
总用量 190444
-rw-r--r--. 1 lijunjie lijunjie 195013152 5月 1 22:53 jdk-8u212-linux-x64.tar.gz
3.4 执行 wordcount 程序·
[lijunjie@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
在这看进行任务资源调度。表示有一个任务。

4.集群崩溃处理方式
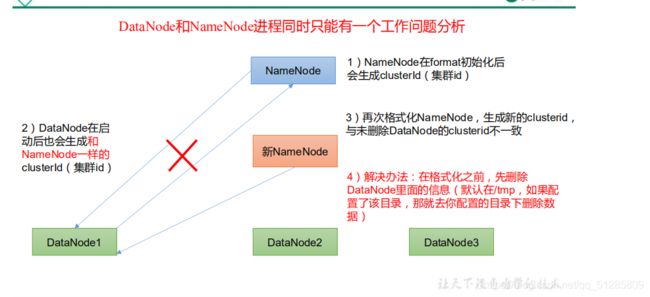
问题:Hadoop102中没有nameNode,或者不小心删除了虚拟机中的date目录等。
原因是:DateNode与NameNode版本不一致导致。新开启的NameNode不能和原先的DataNode匹配。
解决方法:1.先停到服务,各个服务都要停止。
2.在把每一个虚拟机中的date目录和logs目录全部删除
3.在格式化 NameNode,$ hdfs namenode -format
4.在开启服务即可
5.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
5.1配置 mapred-site.xml
[lijunjie@hadoop102 hadoop]$ vim mapred-site.xml
在该文件里面增加如下配置。
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
5.2分发配置
[lijunjie@hadoop102 hadoop]$ xsync mapred-site.xml
5.3 在hadoop102中启动历史服务器
[lijunjie@hadoop102 hadoop]$ mapred --daemon start historyserver
[lijunjie@hadoop102 hadoop]$ jps
1973 DataNode
1884 NameNode
2909 JobHistoryServer
2974 Jps
5.4查看 JobHistory
http://hadoop102:19888/jobhistory
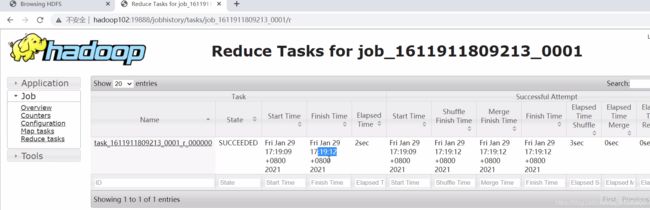
6.配置日志的聚集
(操作有问题)
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。

开启日志聚集功能
6.1 配置yarn-site.xml
[lijunjie@hadoop102 hadoop]$ vim yarn-site.xml
在文件中加入
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
6.2 分发配置
[lijunjie@hadoop102 hadoop]$ xsync yarn-site.xml
6.3关闭 NodeManager 、ResourceManager 和 HistoryServer
[lijunjie@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[lijunjie@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
[lijunjie@hadoop102 hadoop-3.1.3]$ jps
1973 DataNode
3834 Jps
1884 NameNode
6.4 启动 NodeManager 、ResourceManage 和 HistoryServer
[lijunjie@hadoop103 ~]$ start-yarn.sh
[lijunjie@hadoop102 ~]$ mapred --daemon start historyserver
6.5 案例
删除 HDFS 上已经存在的输入文件
[lijunjie@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /input
Deleted /input
执行 WordCount 程序
[lijunjie@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
wordcount /input /output
查看日志
(1)历史服务器地址
http://hadoop102:19888/jobhistory
7.集群启动/停止方式
7.1整体启动/停止 HDFS
start-dfs.sh
stop-dfs.sh
7.2 整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
7.3各个服务组件逐一启动/停止
分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
停止服务
kill -9 进程号
[lijunjie@hadoop102 hadoop-3.1.3]$ jps
5504 Jps
4067 JobHistoryServer
3908 NodeManager
1973 DataNode
1884 NameNode
[lijunjie@hadoop102 hadoop-3.1.3]$ kill -9 1973
[lijunjie@hadoop102 hadoop-3.1.3]$ jps
4067 JobHistoryServer
3908 NodeManager
5530 Jps
1884 NameNode
8.编写 Hadoop 集群常用脚本
8.1Hadoop 集群启停脚本
(包含 HDFS,Yarn,Historyserver):myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start
historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop
historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
8.2 查看三台服务器 Java 进程脚本:jpsall
[lijunjie@hadoop102 bin]$ vim jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
[lijunjie@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
9604 DataNode
9430 NameNode
9900 NodeManager
10076 JobHistoryServer
10223 Jps
=============== hadoop103 ===============
9025 Jps
8466 ResourceManager
8277 DataNode
8726 NodeManager
=============== hadoop104 ===============
7025 Jps
6820 NodeManager
6726 SecondaryNameNode
6605 DataNode
8.3 脚本:实现集群一键关机 shutdown.sh
vim shutdown.sh
如下:配置hadoop102 脚本
#!/bin/bash
#虚拟机群体关机脚本
for host in hadoop104 hadoop103 hadoop102
do
echo “==================== $host关机 ===================”
ssh $host "sudo init 0"
done
注意点:这里在利用for循环遍历的时候一定要区分先后顺序,比如在Linux2上编辑的集群关机脚本,那么最后再执行关机Linux2的命令–>也就是for循环最后在遍历Linux2;
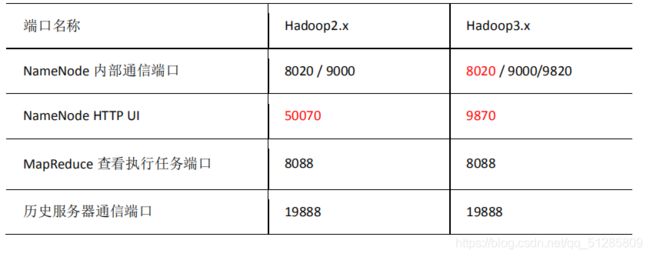
9.常用端口号说明
常用配置文件
| Hadoop2.x | Hadoop3.x |
|---|---|
| core-site.xml | core-site.xml |
| yarn-site.xml | yarn-site.xml |
| mapred-site.xml | mapred-site.xml |
| hdfs-site.xml | hdfs-site.xml |
| workers | slaves |
10.集群时间同步
能连外网的情况下,不需要配置集群时间同步,会影响集群性能。
1.如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
2.如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同
10.1需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用 1 分钟同步一次
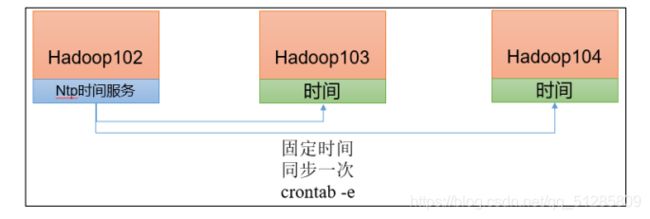
10.2时间服务器配置(必须 root 用户)
- 查看所有节点 ntpd 服务状态和开机自启动状态
[atguigu@hadoop102 ~]$ sudo systemctl status ntpd
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
[atguigu@hadoop102 ~]$ sudo systemctl is-enabled ntpd //设置开机自启动
-
修改 hadoop102 的 ntp.conf 配置文件
[atguigu@hadoop102 ~]$ sudo vim /etc/ntp.conf
(a)修改 1(授权 192.168.10.0-192.168.10.255 网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 修改为
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
b)修改 2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
(c)添加 3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中
的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
- 修改 hadoop102 的/etc/sysconfig/ntpd 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
- 重新启动 ntpd 服务
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
-
设置 ntpd 服务开机启动
[atguigu@hadoop102 ~]$ sudo systemctl enable ntpd
10.3 其他机器配置(必须 root 用户)
(1)关闭所有节点上 ntp 服务和自启动
[atguigu@hadoop103 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop103 ~]$ sudo systemctl disable ntpd
[atguigu@hadoop104 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop104 ~]$ sudo systemctl disable ntpd
(2)在其他机器配置 1 分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3)修改任意机器时间
[atguigu@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11"
(4)1 分钟后查看机器是否与时间服务器同步[atguigu@hadoop103 ~]$ sudo date
四、 常见错误及解决方案
1)防火墙没关闭、或者没有启动 YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)IP 地址配置错误
4)ssh 没有配置好
5)root 用户和 atguigu 两个用户启动集群不统一
6)配置文件修改不细心
7)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102
at
java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at
org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(Job
Submitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native
Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts 文件中添加 192.168.10.102 hadoop102
(2)主机名称不要起 hadoop hadoop000 等特殊名称
8)DataNode 和 NameNode 进程同时只能工作一个
9)执行命令不生效,粘贴 Word 中命令时,遇到-和长–没区分开。导致命令失效解决办法:尽量不要粘贴 Word 中代码。
10)jps 发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在 Linux 的根目录下/tmp 目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
11)jps 不生效原因:
全局变量 hadoop java 没有生效。解决办法:需要 source /etc/profile 文件。
12)8088 端口连接不上[atguigu@hadoop102 桌面]$ cat /etc/hosts注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4#::1 hadoop1
13)在hdfs web 端删除文件没有权限
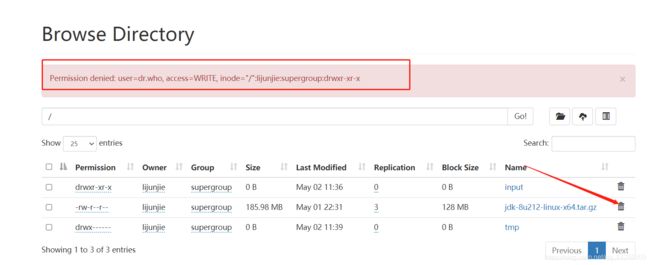
在core-site.xml中加入
hadoop.http.staticuser.user
lijunjie
