XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。
一个 XML 文档实例
XML 文档使用简单的具有自我描述性的语法:
xml version="1.0" encoding="UTF-8"?> <note> <to>Toveto> <from>Janifrom> <heading>Reminderheading> <body>Don't forget me this weekend!body> note>
第一行是 XML 声明。它定义 XML 的版本(1.0)和所使用的编码(UTF-8 : 万国码, 可显示各种语言)。
下一行描述文档的根元素(像在说:"本文档是一个便签"):
接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body):
<to>Toveto> <from>Janifrom> <heading>Reminderheading> <body>Don't forget me this weekend!body>
最后一行定义根元素的结尾:
您可以假设,从这个实例中,XML 文档包含了一张 Jani 写给 Tove 的便签。
XML 具有出色的自我描述性,您同意吗?
XML 文档形成一种树结构
XML 文档必须包含根元素。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有的元素都可以有子元素:
<root> <child> <subchild>.....subchild> child> root>
父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
所有的元素都可以有文本内容和属性(类似 HTML 中)。
实例:
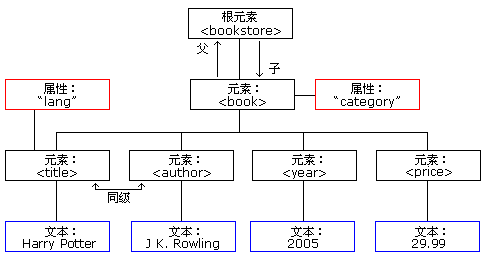
上图表示下面的 XML 中的一本书:
XML 文档实例
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italiantitle> <author>Giada De Laurentiisauthor> <year>2005year> <price>30.00price> book> <book category="CHILDREN"> <title lang="en">Harry Pottertitle> <author>J K. Rowlingauthor> <year>2005year> <price>29.99price> book> <book category="WEB"> <title lang="en">Learning XMLtitle> <author>Erik T. Rayauthor> <year>2003year> <price>39.95price> book> bookstore>
实例中的根元素是 。文档中的所有 元素都被包含在 中。
元素有 4 个子元素:、<author>、<year>、<price>。</p>
<h2>XML <span class="color_h1">语法规则</span></h2>
<hr>
<p class="intro">XML 的语法规则很简单,且很有逻辑。这些规则很容易学习,也很容易使用。</p>
<hr>
<h3>XML 文档必须有根元素</h3>
<p>XML 必须包含根元素,它是所有其他元素的父元素,比如以下实例中 root 就是根元素:</p>
<div class="example">
<div class="example_code">
<div class="hl-main"> <span class="hl-brackets"><<span class="hl-reserved">root<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">child<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">subchild<span class="hl-brackets">><span class="hl-code">.....<span class="hl-brackets"></<span class="hl-reserved">subchild<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">child<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">root<span class="hl-brackets">></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
</div>
</div>
</div>
<p>以下实例中 note 是根元素:</p>
<div class="example">
<div class="example_code">
<div class="hl-main"> <span class="hl-brackets"><?<span class="hl-reserved">xml<span class="hl-code"> <span class="hl-var">version<span class="hl-code">=<span class="hl-quotes">"<span class="hl-string">1.0<span class="hl-quotes">"<span class="hl-code"> <span class="hl-var">encoding<span class="hl-code">=<span class="hl-quotes">"<span class="hl-string">UTF-8<span class="hl-quotes">"<span class="hl-brackets">?><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">note<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code">Tove<span class="hl-brackets"></<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code">Jani<span class="hl-brackets"></<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">heading<span class="hl-brackets">><span class="hl-code">Reminder<span class="hl-brackets"></<span class="hl-reserved">heading<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code">Don't forget me this weekend!<span class="hl-brackets"></<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">note<span class="hl-brackets">></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
</div>
</div>
</div>
<hr>
<h3>XML 声明</h3>
<p>XML 声明文件的可选部分,如果存在需要放在文档的第一行,如下所示:</p>
<pre class="prettyprint prettyprinted"><span class="pun"><?<span class="pln">xml version<span class="pun">=<span class="str">"1.0"<span class="pln"> encoding<span class="pun">=<span class="str">"utf-8"<span class="pun">?></span></span></span></span></span></span></span></span></pre>
<blockquote>
<p>以上实例包含 XML 版本(<version="1.0"),甚至包含字符编码(encoding="utf-8")。< p=""></p>
<p>UTF-8 也是 HTML5, CSS, JavaScript, PHP, 和 SQL 的默认编码。</p>
</blockquote>
<hr>
<h3>所有的 XML 元素都必须有一个关闭标签</h3>
<p>在 HTML 中,某些元素不必有一个关闭标签:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><p><span class="pln">This is a paragraph.
<span class="tag"><br></span></span></span></pre>
<p>在 XML 中,省略关闭标签是非法的。所有元素都<strong>必须</strong>有关闭标签:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><p><span class="pln">This is a paragraph.<span class="tag"></p><span class="pln">
<span class="tag"><br<span class="pln"> <span class="tag">/></span></span></span></span></span></span></span></pre>
<p><strong>注释:</strong>从上面的实例中,您也许已经注意到 XML 声明没有关闭标签。这不是错误。声明不是 XML 文档本身的一部分,它没有关闭标签。</p>
<hr>
<h3>XML 标签对大小写敏感</h3>
<p>XML 标签对大小写敏感。标签 <Letter> 与标签 <letter> 是不同的。</p>
<p>必须使用相同的大小写来编写打开标签和关闭标签:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><Message><span class="pln">这是错误的<span class="tag"></message><span class="pln">
<span class="tag"><message><span class="pln">这是正确的<span class="tag"></message></span></span></span></span></span></span></span></pre>
<p><strong>注释:</strong>打开标签和关闭标签通常被称为开始标签和结束标签。不论您喜欢哪种术语,它们的概念都是相同的。</p>
<hr>
<h3>XML 必须正确嵌套</h3>
<p>在 HTML 中,常会看到没有正确嵌套的元素:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><b><i><span class="pln">This text is bold and italic<span class="tag"></b></i></span></span></span></pre>
<p>在 XML 中,所有元素都<strong>必须</strong>彼此正确地嵌套:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><b><i><span class="pln">This text is bold and italic<span class="tag"></i></b></span></span></span></pre>
<p>在上面的实例中,正确嵌套的意思是:由于 <i> 元素是在 <b> 元素内打开的,那么它必须在 <b> 元素内关闭。</p>
<hr>
<hr>
<h3>XML 属性值必须加引号</h3>
<p>与 HTML 类似,XML 元素也可拥有属性(名称/值的对)。</p>
<p>在 XML 中,XML 的属性值必须加引号。</p>
<p>请研究下面的两个 XML 文档。 第一个是错误的,第二个是正确的:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><note<span class="pln"> <span class="atn">date<span class="pun">=<span class="atv">12/11/2007<span class="tag">><span class="pln"> <span class="tag"><to><span class="pln">Tove<span class="tag"></to><span class="pln"> <span class="tag"><from><span class="pln">Jani<span class="tag"></from><span class="pln"> <span class="tag"></note></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
<pre class="prettyprint prettyprinted"><span class="tag"><note<span class="pln"> <span class="atn">date<span class="pun">=<span class="atv">"12/11/2007"<span class="tag">><span class="pln"> <span class="tag"><to><span class="pln">Tove<span class="tag"></to><span class="pln"> <span class="tag"><from><span class="pln">Jani<span class="tag"></from><span class="pln"> <span class="tag"></note></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
<p>在第一个文档中的错误是,note 元素中的 date 属性没有加引号。</p>
<hr>
<h3>实体引用</h3>
<p>在 XML 中,一些字符拥有特殊的意义。</p>
<p>如果您把字符 "<" 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。</p>
<p>这样会产生 XML 错误:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><message><span class="pln">if salary < 1000 then<span class="tag"></message></span></span></span></pre>
<p>为了避免这个错误,请用<strong>实体引用</strong>来代替 "<" 字符:</p>
<pre class="prettyprint prettyprinted"><span class="tag"><message><span class="pln">if salary < 1000 then<span class="tag"></message></span></span></span></pre>
<p>在 XML 中,有 5 个预定义的实体引用:</p>
<table class="reference">
<tbody>
<tr>
<td><</td>
<td><</td>
<td>less than</td>
</tr>
<tr>
<td>></td>
<td>></td>
<td>greater than</td>
</tr>
<tr>
<td>&</td>
<td>&</td>
<td>ampersand</td>
</tr>
<tr>
<td>'</td>
<td>'</td>
<td>apostrophe</td>
</tr>
<tr>
<td>"</td>
<td>"</td>
<td>quotation mark</td>
</tr>
</tbody>
</table>
<p><strong>注释:</strong>在 XML 中,只有字符 "<" 和 "&" 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。</p>
<hr>
<h3>XML 中的注释</h3>
<p>在 XML 中编写注释的语法与 HTML 的语法很相似。</p>
<pre class="prettyprint prettyprinted"><span class="com"><!-- This is a comment --></span></pre>
<hr>
<h3>在 XML 中,空格会被保留</h3>
<p>HTML 会把多个连续的空格字符裁减(合并)为一个:</p>
<table class="reference notranslate">
<tbody>
<tr>
<td>HTML:</td>
<td>Hello Tove</td>
</tr>
<tr>
<td>Output:</td>
<td>Hello Tove</td>
</tr>
</tbody>
</table>
<p>在 XML 中,文档中的空格不会被删减。</p>
<hr>
<h3>XML 以 LF 存储换行</h3>
<p>在 Windows 应用程序中,换行通常以一对字符来存储:回车符(CR)和换行符(LF)。</p>
<p>在 Unix 和 Mac OSX 中,使用 LF 来存储新行。</p>
<p>在旧的 Mac 系统中,使用 CR 来存储新行。</p>
<p>XML 以 LF 存储换行。</p>
<h2>XML <span class="color_h1">元素</span></h2>
<hr>
<p class="intro">XML 文档包含 XML 元素。</p>
<hr>
<h3>什么是 XML 元素?</h3>
<p>XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。</p>
<p>一个元素可以包含:</p>
<ul>
<li>其他元素</li>
<li>文本</li>
<li>属性</li>
<li>或混合以上所有...</li>
</ul>
<div class="example">
<div class="example_code">
<div class="hl-main"> <span class="hl-brackets"><<span class="hl-reserved">bookstore<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">book<span class="hl-code"> <span class="hl-var">category<span class="hl-code">=<span class="hl-quotes">"<span class="hl-string">CHILDREN<span class="hl-quotes">"<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">title<span class="hl-brackets">><span class="hl-code">Harry Potter<span class="hl-brackets"></<span class="hl-reserved">title<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">author<span class="hl-brackets">><span class="hl-code">J K. Rowling<span class="hl-brackets"></<span class="hl-reserved">author<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">year<span class="hl-brackets">><span class="hl-code">2005<span class="hl-brackets"></<span class="hl-reserved">year<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">price<span class="hl-brackets">><span class="hl-code">29.99<span class="hl-brackets"></<span class="hl-reserved">price<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">book<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">book<span class="hl-code"> <span class="hl-var">category<span class="hl-code">=<span class="hl-quotes">"<span class="hl-string">WEB<span class="hl-quotes">"<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">title<span class="hl-brackets">><span class="hl-code">Learning XML<span class="hl-brackets"></<span class="hl-reserved">title<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">author<span class="hl-brackets">><span class="hl-code">Erik T. Ray<span class="hl-brackets"></<span class="hl-reserved">author<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">year<span class="hl-brackets">><span class="hl-code">2003<span class="hl-brackets"></<span class="hl-reserved">year<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">price<span class="hl-brackets">><span class="hl-code">39.95<span class="hl-brackets"></<span class="hl-reserved">price<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">book<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">bookstore<span class="hl-brackets">></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
</div>
</div>
</div>
<p>在上面的实例中,<bookstore> 和 <book> 都有 <strong>元素内容</strong>,因为他们包含其他元素。<book> 元素也有<strong>属性</strong>(category="CHILDREN")。<title>、<author>、<year> 和 <price> 有<strong>文本内容</strong>,因为他们包含文本。</p>
<hr>
<h3>XML 命名规则</h3>
<p>XML 元素必须遵循以下命名规则:</p>
<ul>
<li>名称可以包含字母、数字以及其他的字符</li>
<li>名称不能以数字或者标点符号开始</li>
<li>名称不能以字母 xml(或者 XML、Xml 等等)开始</li>
<li>名称不能包含空格</li>
</ul>
<p>可使用任何名称,没有保留的字词。</p>
<hr>
<h3>最佳命名习惯</h3>
<p>使名称具有描述性。使用下划线的名称也很不错:<first_name>、<last_name>。</p>
<p>名称应简短和简单,比如:<book_title>,而不是:<the_title_of_the_book>。</p>
<p>避免 "-" 字符。如果您按照这样的方式进行命名:"first-name",一些软件会认为您想要从 first 里边减去 name。</p>
<p>避免 "." 字符。如果您按照这样的方式进行命名:"first.name",一些软件会认为 "name" 是对象 "first" 的属性。</p>
<p>避免 ":" 字符。冒号会被转换为命名空间来使用(稍后介绍)。</p>
<p>XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。有一个实用的经验,即使用数据库的命名规则来命名 XML 文档中的元素。</p>
<p>在 XML 中,éòá 等非英语字母是完全合法的,不过需要留意,您的软件供应商不支持这些字符时可能出现的问题。</p>
<hr>
<h3>XML 元素是可扩展的</h3>
<p>XML 元素是可扩展,以携带更多的信息。</p>
<p>请看下面的 XML 实例:</p>
<div class="example">
<div class="example_code">
<div class="hl-main"> <span class="hl-brackets"><<span class="hl-reserved">note<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code">Tove<span class="hl-brackets"></<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code">Jani<span class="hl-brackets"></<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code">Don't forget me this weekend!<span class="hl-brackets"></<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">note<span class="hl-brackets">></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
</div>
</div>
</div>
<p>让我们设想一下,我们创建了一个应用程序,可将 <to>、<from> 以及 <body> 元素从 XML 文档中提取出来,并产生以下的输出:</p>
<table border="1">
<tbody>
<tr>
<td><strong>MESSAGE</strong> <p><strong>To:</strong> Tove<br><strong>From:</strong> Jani</p> <p>Don't forget me this weekend!</p> </td>
</tr>
</tbody>
</table>
<p>想象一下,XML 文档的作者添加的一些额外信息:</p>
<div class="example">
<div class="example_code">
<div class="hl-main"> <span class="hl-brackets"><<span class="hl-reserved">note<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">date<span class="hl-brackets">><span class="hl-code">2008-01-10<span class="hl-brackets"></<span class="hl-reserved">date<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code">Tove<span class="hl-brackets"></<span class="hl-reserved">to<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code">Jani<span class="hl-brackets"></<span class="hl-reserved">from<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">heading<span class="hl-brackets">><span class="hl-code">Reminder<span class="hl-brackets"></<span class="hl-reserved">heading<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"><<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code">Don't forget me this weekend!<span class="hl-brackets"></<span class="hl-reserved">body<span class="hl-brackets">><span class="hl-code"> <span class="hl-brackets"></<span class="hl-reserved">note<span class="hl-brackets">></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
</div>
</div>
</div>
<p>那么这个应用程序会中断或崩溃吗?</p>
<p>不会。这个应用程序仍然可以找到 XML 文档中的 <to>、<from> 以及 <body> 元素,并产生同样的输出。</p>
<p>XML 的优势之一,就是可以在不中断应用程序的情况下进行扩展。</p>
<h2>XML <span class="color_h1">属性</span></h2>
<hr>
<p class="intro">XML元素具有属性,类似 HTML。</p>
<p class="intro">属性(Attribute)提供有关元素的额外信息。</p>
<hr>
<h3>XML 属性</h3>
<p>在 HTML 中,属性提供有关元素的额外信息:</p>
<div class="code notranslate">
<div>
<img src="computer.gif">
<br><a href="demo.html">
</div>
</div>
<p>属性通常提供不属于数据组成部分的信息。在下面的实例中,文件类型与数据无关,但是对需要处理这个元素的软件来说却很重要:</p>
<div class="code notranslate">
<div>
<file type="gif">computer.gif</file>
</div>
</div>
<p> </p>
<hr>
<h3>XML 属性必须加引号</h3>
<p>属性值必须被引号包围,不过单引号和双引号均可使用。比如一个人的性别,person 元素可以这样写:</p>
<div class="code notranslate">
<div>
<person sex="female">
</div>
</div>
<p>或者这样也可以:</p>
<div class="code notranslate">
<div>
<person sex='female'>
</div>
</div>
<p>如果属性值本身包含双引号,您可以使用单引号,就像这个实例:</p>
<div class="code notranslate">
<div>
<gangster name='George "Shotgun" Ziegler'>
</div>
</div>
<p>或者您可以使用字符实体:</p>
<div class="code notranslate">
<div>
<gangster name="George "Shotgun" Ziegler">
</div>
</div>
<p> </p>
<hr>
<h3>XML 元素 vs. 属性</h3>
<p>请看这些实例:</p>
<div class="code notranslate">
<div>
<person sex="female">
<br><firstname>Anna</firstname>
<br><lastname>Smith</lastname>
<br></person>
</div>
</div>
<p> </p>
<div class="code notranslate">
<div>
<person>
<br><sex>female</sex>
<br><firstname>Anna</firstname>
<br><lastname>Smith</lastname>
<br></person>
</div>
</div>
<p>在第一个实例中,sex 是一个属性。在第二个实例中,sex 是一个元素。这两个实例都提供相同的信息。</p>
<p>没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用元素。我的经验是在 HTML 中,属性用起来很便利,但是在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用元素吧。</p>
<hr>
<h3>我最喜欢的方式</h3>
<p>下面的三个 XML 文档包含完全相同的信息:</p>
<p>第一个实例中使用了 date 属性:</p>
<div class="code notranslate">
<div>
<note date="10/01/2008">
<br><to>Tove</to>
<br><from>Jani</from>
<br><heading>Reminder</heading>
<br><body>Don't forget me this weekend!</body>
<br></note>
</div>
</div>
<p>第二个实例中使用了 date 元素:</p>
<div class="code notranslate">
<div>
<note>
<br><date>10/01/2008</date>
<br><to>Tove</to>
<br><from>Jani</from>
<br><heading>Reminder</heading>
<br><body>Don't forget me this weekend!</body>
<br></note>
</div>
</div>
<p>第三个实例中使用了扩展的 date 元素(这是我的最爱):</p>
<div class="code notranslate">
<div>
<note>
<br><date>
<br><day>10</day>
<br><month>01</month>
<br><year>2008</year>
<br></date>
<br><to>Tove</to>
<br><from>Jani</from>
<br><heading>Reminder</heading>
<br><body>Don't forget me this weekend!</body>
<br></note>
</div>
</div>
<p> </p>
<hr>
<h3>避免 XML 属性?</h3>
<p>因使用属性而引起的一些问题:</p>
<ul>
<li>属性不能包含多个值(元素可以)</li>
<li>属性不能包含树结构(元素可以)</li>
<li>属性不容易扩展(为未来的变化)</li>
</ul>
<p>属性难以阅读和维护。请尽量使用元素来描述数据。而仅仅使用属性来提供与数据无关的信息。</p>
<p>不要做这样的蠢事(这不是 XML 应该被使用的方式):</p>
<div class="code notranslate">
<div>
<note day="10" month="01" year="2008"
<br>to="Tove" from="Jani" heading="Reminder"
<br>body="Don't forget me this weekend!">
<br></note>
</div>
</div>
<p> </p>
<hr>
<h3>针对元数据的 XML 属性</h3>
<p>有时候会向元素分配 ID 引用。这些 ID 索引可用于标识 XML 元素,它起作用的方式与 HTML 中 id 属性是一样的。这个实例向我们演示了这种情况:</p>
<div class="code notranslate">
<div>
<messages>
<br><note id="501">
<br><to>Tove</to>
<br><from>Jani</from>
<br><heading>Reminder</heading>
<br><body>Don't forget me this weekend!</body>
<br></note>
<br><note id="502">
<br><to>Jani</to>
<br><from>Tove</from>
<br><heading>Re: Reminder</heading>
<br><body>I will not</body>
<br></note>
<br></messages>
</div>
</div>
<p>上面的 id 属性仅仅是一个标识符,用于标识不同的便签。它并不是便签数据的组成部分。</p>
<p>在此我们极力向您传递的理念是:元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。</p>
<p> </p>
<h2>XML <span class="color_h1">验证</span></h2>
<hr>
<p class="intro">拥有正确语法的 XML 被称为"形式良好"的 XML。</p>
<p class="intro">通过 DTD 验证的XML是"合法"的 XML。</p>
<hr>
<h3>形式良好的 XML 文档</h3>
<p>"形式良好"的 XML 文档拥有正确的语法。</p>
<p>在前面的章节描述的语法规则:</p>
<ul>
<li>XML 文档必须有一个根元素</li>
<li>XML元素都必须有一个关闭标签</li>
<li>XML 标签对大小写敏感</li>
<li>XML 元素必须被正确的嵌套</li>
<li>XML 属性值必须加引号</li>
</ul>
<div class="code notranslate">
<div>
<?xml version="1.0" encoding="ISO-8859-1"?>
<br><note>
<br><to>Tove</to>
<br><from>Jani</from>
<br><heading>Reminder</heading>
<br><body>Don't forget me this weekend!</body>
<br></note>
</div>
</div>
<p> </p>
<hr>
<h3>验证 XML 文档</h3>
<p>合法的 XML 文档是"形式良好"的 XML 文档,这也符合文档类型定义(DTD)的规则:</p>
<div class="code notranslate">
<div>
<?xml version="1.0" encoding="ISO-8859-1"?>
<br> <span class="marked"><!DOCTYPE note SYSTEM "Note.dtd"><br><note><br><to>Tove</to><br><from>Jani</from><br><heading>Reminder</heading><br><body>Don't forget me this weekend!</body><br></note></span>
</div>
</div>
<p>在上面的实例中,DOCTYPE 声明是对外部 DTD 文件的引用。下面的段落展示了这个文件的内容。</p>
<hr>
<h3>XML DTD</h3>
<p>DTD 的目的是定义 XML 文档的结构。它使用一系列合法的元素来定义文档结构:</p>
<div class="code notranslate">
<div>
<!DOCTYPE note
<br>[
<br><!ELEMENT note (to,from,heading,body)>
<br><!ELEMENT to (#PCDATA)>
<br><!ELEMENT from (#PCDATA)>
<br><!ELEMENT heading (#PCDATA)>
<br><!ELEMENT body (#PCDATA)>
<br>]>
</div>
</div>
<p>如果您想要学习 DTD,请在我们的首页查找 DTD 教程。</p>
<hr>
<h3>XML Schema</h3>
<p>W3C 支持一种基于 XML 的 DTD 代替者,它名为 XML Schema:</p>
<div class="code notranslate">
<div>
<xs:element name="note">
<br>
<br><xs:complexType>
<br><xs:sequence>
<br><xs:element name="to" type="xs:string"/>
<br><xs:element name="from" type="xs:string"/>
<br><xs:element name="heading" type="xs:string"/>
<br><xs:element name="body" type="xs:string"/>
<br></xs:sequence>
<br></xs:complexType>
<br>
<br></xs:element>
</div>
</div>
<p> </p>
<p> </p>
<p>http://www.runoob.com/xml/xml-tutorial.html</p>
<p> </p>
<h3>使用xml.dom解析xml</h3>
<p>文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。</p>
<p>一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。</p>
<p>python中用xml.dom.minidom来解析xml文件,实例如下:</p>
<pre class="prettyprint prettyprinted"><span class="com">#!/usr/bin/python<span class="pln">
<span class="com"># -*- coding: UTF-8 -*-<span class="pln">
<span class="kwd">from<span class="pln"> xml<span class="pun">.<span class="pln">dom<span class="pun">.<span class="pln">minidom <span class="kwd">import<span class="pln"> parse <span class="kwd">import<span class="pln"> xml<span class="pun">.<span class="pln">dom<span class="pun">.<span class="pln">minidom <span class="com"># 使用minidom解析器打开 XML 文档<span class="pln"> <span class="typ">DOMTree<span class="pln"> <span class="pun">=<span class="pln"> xml<span class="pun">.<span class="pln">dom<span class="pun">.<span class="pln">minidom<span class="pun">.<span class="pln">parse<span class="pun">(<span class="str">"movies.xml"<span class="pun">)<span class="pln"> collection <span class="pun">=<span class="pln"> <span class="typ">DOMTree<span class="pun">.<span class="pln">documentElement <span class="kwd">if<span class="pln"> collection<span class="pun">.<span class="pln">hasAttribute<span class="pun">(<span class="str">"shelf"<span class="pun">):<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Root element : %s"<span class="pln"> <span class="pun">%<span class="pln"> collection<span class="pun">.<span class="pln">getAttribute<span class="pun">(<span class="str">"shelf"<span class="pun">)<span class="pln"> <span class="com"># 在集合中获取所有电影<span class="pln"> movies <span class="pun">=<span class="pln"> collection<span class="pun">.<span class="pln">getElementsByTagName<span class="pun">(<span class="str">"movie"<span class="pun">)<span class="pln"> <span class="com"># 打印每部电影的详细信息<span class="pln"> <span class="kwd">for<span class="pln"> movie <span class="kwd">in<span class="pln"> movies<span class="pun">:<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"*****Movie*****"<span class="pln"> <span class="kwd">if<span class="pln"> movie<span class="pun">.<span class="pln">hasAttribute<span class="pun">(<span class="str">"title"<span class="pun">):<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Title: %s"<span class="pln"> <span class="pun">%<span class="pln"> movie<span class="pun">.<span class="pln">getAttribute<span class="pun">(<span class="str">"title"<span class="pun">)<span class="pln"> type <span class="pun">=<span class="pln"> movie<span class="pun">.<span class="pln">getElementsByTagName<span class="pun">(<span class="str">'type'<span class="pun">)[<span class="lit">0<span class="pun">]<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Type: %s"<span class="pln"> <span class="pun">%<span class="pln"> type<span class="pun">.<span class="pln">childNodes<span class="pun">[<span class="lit">0<span class="pun">].<span class="pln">data format <span class="pun">=<span class="pln"> movie<span class="pun">.<span class="pln">getElementsByTagName<span class="pun">(<span class="str">'format'<span class="pun">)[<span class="lit">0<span class="pun">]<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Format: %s"<span class="pln"> <span class="pun">%<span class="pln"> format<span class="pun">.<span class="pln">childNodes<span class="pun">[<span class="lit">0<span class="pun">].<span class="pln">data rating <span class="pun">=<span class="pln"> movie<span class="pun">.<span class="pln">getElementsByTagName<span class="pun">(<span class="str">'rating'<span class="pun">)[<span class="lit">0<span class="pun">]<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Rating: %s"<span class="pln"> <span class="pun">%<span class="pln"> rating<span class="pun">.<span class="pln">childNodes<span class="pun">[<span class="lit">0<span class="pun">].<span class="pln">data description <span class="pun">=<span class="pln"> movie<span class="pun">.<span class="pln">getElementsByTagName<span class="pun">(<span class="str">'description'<span class="pun">)[<span class="lit">0<span class="pun">]<span class="pln"> <span class="kwd">print<span class="pln"> <span class="str">"Description: %s"<span class="pln"> <span class="pun">%<span class="pln"> description<span class="pun">.<span class="pln">childNodes<span class="pun">[<span class="lit">0<span class="pun">].<span class="pln">data</span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
<p>以上程序执行结果如下:</p>
<pre class="prettyprint prettyprinted"><span class="typ">Root<span class="pln"> element <span class="pun">:<span class="pln"> <span class="typ">New<span class="pln"> <span class="typ">Arrivals<span class="pln"> <span class="pun">*****<span class="typ">Movie<span class="pun">*****<span class="pln"> <span class="typ">Title<span class="pun">:<span class="pln"> <span class="typ">Enemy<span class="pln"> <span class="typ">Behind<span class="pln"> <span class="typ">Type<span class="pun">:<span class="pln"> <span class="typ">War<span class="pun">,<span class="pln"> <span class="typ">Thriller<span class="pln"> <span class="typ">Format<span class="pun">:<span class="pln"> DVD <span class="typ">Rating<span class="pun">:<span class="pln"> PG <span class="typ">Description<span class="pun">:<span class="pln"> <span class="typ">Talk<span class="pln"> about a US<span class="pun">-<span class="typ">Japan<span class="pln"> war <span class="pun">*****<span class="typ">Movie<span class="pun">*****<span class="pln"> <span class="typ">Title<span class="pun">:<span class="pln"> <span class="typ">Transformers<span class="pln"> <span class="typ">Type<span class="pun">:<span class="pln"> <span class="typ">Anime<span class="pun">,<span class="pln"> <span class="typ">Science<span class="pln"> <span class="typ">Fiction<span class="pln"> <span class="typ">Format<span class="pun">:<span class="pln"> DVD <span class="typ">Rating<span class="pun">:<span class="pln"> R <span class="typ">Description<span class="pun">:<span class="pln"> A schientific fiction <span class="pun">*****<span class="typ">Movie<span class="pun">*****<span class="pln"> <span class="typ">Title<span class="pun">:<span class="pln"> <span class="typ">Trigun<span class="pln"> <span class="typ">Type<span class="pun">:<span class="pln"> <span class="typ">Anime<span class="pun">,<span class="pln"> <span class="typ">Action<span class="pln"> <span class="typ">Format<span class="pun">:<span class="pln"> DVD <span class="typ">Rating<span class="pun">:<span class="pln"> PG <span class="typ">Description<span class="pun">:<span class="pln"> <span class="typ">Vash<span class="pln"> the <span class="typ">Stampede<span class="pun">!<span class="pln"> <span class="pun">*****<span class="typ">Movie<span class="pun">*****<span class="pln"> <span class="typ">Title<span class="pun">:<span class="pln"> <span class="typ">Ishtar<span class="pln"> <span class="typ">Type<span class="pun">:<span class="pln"> <span class="typ">Comedy<span class="pln"> <span class="typ">Format<span class="pun">:<span class="pln"> VHS <span class="typ">Rating<span class="pun">:<span class="pln"> PG <span class="typ">Description<span class="pun">:<span class="pln"> <span class="typ">Viewable<span class="pln"> boredom</span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span><br><br></pre>
<h2>用 ElementTree 在 Python 中解析 XML</h2>
<p>原文: http://eli.thegreenplace.net/2012/03/15/processing-xml-in-python-with-elementtree/</p>
<p>译者: TheLover_Z</p>
<p>当你需要解析和处理 XML 的时候,Python 表现出了它 “batteries included” 的一面。 标准库 中大量可用的模块和工具足以应对 Python 或者是 XML 的新手。</p>
<p>几个月前在 Python 核心开发者之间发生了一场 有趣的讨论 ,他们讨论了 Python 下可用的 XML 处理工具的优点,还有如何将它们最好的展示给用户看。这篇文章是我本人的拙作,我打算讲讲哪些工具比较好用还有为什么它们好用,当然,这篇文章也可以当作一个如何使用的基础教程来看。</p>
<p>这篇文章所使用的代码基于 Python 2.7,你稍微改动一下就可以在 Python 3.x 上面使用了。</p>
<div id="xml" class="section">
<h3>应该使用哪个 XML 库?</h3>
<p>Python 有非常非常多的工具来处理 XML。在这个部分我想对 Python 所提供的包进行一个简单的浏览,并且解释为什么 <code class="docutils literal">ElementTree</code> 是你最应该用的那一个。</p>
<p><code class="docutils literal">xml.dom.*</code> 模块 - 是 W3C DOM API 的实现。如果你有处理 DOM API 的需要,那么这个模块适合你。注意:在 <cite>xml.dom</cite> 包里面有许多模块,注意它们之间的不同。</p>
<p><code class="docutils literal">xml.sax.*</code> 模块 - 是 SAX API 的实现。这个模块牺牲了便捷性来换取速度和内存占用。SAX 是一个基于事件的 API,这就意味着它可以“在空中”(on the fly)处理庞大数量的的文档,不用完全加载进内存(见注释1)。</p>
<p><code class="docutils literal">xml.parser.expat</code> - 是一个直接的,低级一点的基于 C 的 <code class="docutils literal">expat</code> 的语法分析器(见注释2)。 <code class="docutils literal">expat</code> 接口基于事件反馈,有点像 SAX 但又不太像,因为它的接口并不是完全规范于 <code class="docutils literal">expat</code> 库的。</p>
<p>最后,我们来看看 <code class="docutils literal">xml.etree.ElementTree</code> (以下简称 ET)。它提供了轻量级的 Python 式的 API ,它由一个 C 实现来提供。相对于 DOM 来说,ET 快了很多(见注释3)而且有很多令人愉悦的 API 可以使用。相对于 SAX 来说,ET 也有 <code class="docutils literal">ET.iterparse</code> 提供了 “在空中” 的处理方式,没有必要加载整个文档到内存。ET 的性能的平均值和 SAX 差不多,但是 API 的效率更高一点而且使用起来很方便。我一会儿会给你们看演示。</p>
<p><strong>我的建议</strong> 是尽可能的使用 ET 来处理 XML ,除非你有什么非常特别的需要。</p>
</div>
<div id="elementtree-api" class="section">
<h3>ElementTree - 一个 API ,两种实现</h3>
<p><code class="docutils literal">ElementTree</code> 生来就是为了处理 XML ,它在 Python 标准库中有两种实现。一种是纯 Python 实现例如 <code class="docutils literal">xml.etree.ElementTree</code> ,另外一种是速度快一点的 <code class="docutils literal">xml.etree.cElementTree</code> 。你要记住: <strong>尽量使用</strong> C 语言实现的那种,因为它速度更快,而且消耗的内存更少。如果你的电脑上没有 <code class="docutils literal">_elementtree</code> (见注释4) 那么你需要这样做:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="k">try<span class="p">:
<span class="kn">import <span class="nn">xml.etree.cElementTree <span class="kn">as <span class="nn">ET <span class="k">except <span class="ne">ImportError<span class="p">: <span class="kn">import <span class="nn">xml.etree.ElementTree <span class="kn">as <span class="nn">ET </span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>这是一个让 Python 不同的库使用相同 API 的一个比较常用的办法。还是那句话,你的编译环境和别人的很可能不一样,所以这样做可以防止一些莫名其妙的小问题。注意:从 Python 3.3 开始,你没有必要这么做了,因为 <code class="docutils literal">ElementTree</code> 模块会自动寻找可用的 C 库来加快速度。所以只需要 <code class="docutils literal"><span class="pre">import <span class="pre">xml.etree.ElementTree</span></span></code> 就可以了。但是在 3.3 正式推出之前,你最好还是使用我上面提供的那段代码。</p>
</div>
<div id="id3" class="section">
<h3>将 XML 解析为树的形式</h3>
<p>我们来讲点基础的。XML 是一种分级的数据形式,所以最自然的表示方法是将它表示为一棵树。ET 有两个对象来实现这个目的 - <code class="docutils literal">ElementTree</code> 将整个 XML 解析为一棵树, <code class="docutils literal">Element</code> 将单个结点解析为树。如果是整个文档级别的操作(比如说读,写,找到一些有趣的元素)通常用 <code class="docutils literal">ElementTree</code> 。单个 XML 元素和它的子元素通常用 <code class="docutils literal">Element</code> 。下面的例子能说明我刚才啰嗦的一大堆。(见注释5)</p>
<p>我们用这个 XML 文件来做例子:</p>
<div class="highlight-python">
<div class="highlight">
<pre><?xml version="1.0"?>
<doc>
<branch name="testing" hash="1cdf045c">
text,source
</branch>
<branch name="release01" hash="f200013e">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
<branch name="invalid">
</branch>
</doc>
</pre>
</div>
</div>
<p>让我们加载并且解析这个 XML :</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="kn">import <span class="nn">xml.etree.cElementTree <span class="kn">as <span class="nn">ET
<span class="gp">>>> <span class="n">tree <span class="o">= <span class="n">ET<span class="o">.<span class="n">ElementTree<span class="p">(<span class="nb">file<span class="o">=<span class="s1">'doc1.xml'<span class="p">) </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>然后抓根结点元素:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="n">tree<span class="o">.<span class="n">getroot<span class="p">()
<span class="go"><Element 'doc' at 0x11eb780> </span></span></span></span></span></span></pre>
</div>
</div>
<p>和预期一样,root 是一个 <code class="docutils literal">Element</code> 元素。我们可以来看看:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="n">root <span class="o">= <span class="n">tree<span class="o">.<span class="n">getroot<span class="p">() <span class="gp">>>> <span class="n">root<span class="o">.<span class="n">tag<span class="p">, <span class="n">root<span class="o">.<span class="n">attrib <span class="go">('doc', {}) </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>看吧,根元素没有任何状态(见注释6)。就像任何 <code class="docutils literal">Element</code> 一样,它可以找到自己的子结点:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="k">for <span class="n">child_of_root <span class="ow">in <span class="n">root<span class="p">: <span class="gp">... <span class="k">print <span class="n">child_of_root<span class="o">.<span class="n">tag<span class="p">, <span class="n">child_of_root<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">branch {'hash': '1cdf045c', 'name': 'testing'} <span class="go">branch {'hash': 'f200013e', 'name': 'release01'} <span class="go">branch {'name': 'invalid'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>我们也可以进入一个指定的子结点:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="n">root<span class="p">[<span class="mi">0<span class="p">]<span class="o">.<span class="n">tag<span class="p">, <span class="n">root<span class="p">[<span class="mi">0<span class="p">]<span class="o">.<span class="n">text <span class="go">('branch', '\n text,source\n ') </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
</div>
<div id="id4" class="section">
<h3>找到我们感兴趣的元素</h3>
<p>从上面的例子我们可以轻而易举的看到,我们可以用一个简单的递归获取 XML 中的任何元素。然而,因为这个操作比较普遍,ET 提供了一些有用的工具来简化操作.</p>
<p><code class="docutils literal">Element</code> 对象有一个 <code class="docutils literal">iter</code> 方法可以对子结点进行深度优先遍历。 <code class="docutils literal">ElementTree</code> 对象也有 <code class="docutils literal">iter</code> 方法来提供便利。</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="k">for <span class="n">elem <span class="ow">in <span class="n">tree<span class="o">.<span class="n">iter<span class="p">(): <span class="gp">... <span class="k">print <span class="n">elem<span class="o">.<span class="n">tag<span class="p">, <span class="n">elem<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">doc {} <span class="go">branch {'hash': '1cdf045c', 'name': 'testing'} <span class="go">branch {'hash': 'f200013e', 'name': 'release01'} <span class="go">sub-branch {'name': 'subrelease01'} <span class="go">branch {'name': 'invalid'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>遍历所有的元素,然后检验有没有你想要的。ET 可以让这个过程更便捷。 <code class="docutils literal">iter</code> 方法接受一个标签名字,然后只遍历那些有指定标签的元素:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="k">for <span class="n">elem <span class="ow">in <span class="n">tree<span class="o">.<span class="n">iter<span class="p">(<span class="n">tag<span class="o">=<span class="s1">'branch'<span class="p">): <span class="gp">... <span class="k">print <span class="n">elem<span class="o">.<span class="n">tag<span class="p">, <span class="n">elem<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">branch {'hash': '1cdf045c', 'name': 'testing'} <span class="go">branch {'hash': 'f200013e', 'name': 'release01'} <span class="go">branch {'name': 'invalid'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
</div>
<div id="xpath" class="section">
<h3>来自 XPath 的帮助</h3>
<p>为了寻找我们感兴趣的元素,一个更加有效的办法是使用 XPath 支持。 <code class="docutils literal">Element</code> 有一些关于寻找的方法可以接受 XPath 作为参数。 <code class="docutils literal">find</code> 返回第一个匹配的子元素, <code class="docutils literal">findall</code> 以列表的形式返回所有匹配的子元素, <code class="docutils literal">iterfind</code> 为所有匹配项提供迭代器。这些方法在 <code class="docutils literal">ElementTree</code> 里面也有。</p>
<p>给出一个例子:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="k">for <span class="n">elem <span class="ow">in <span class="n">tree<span class="o">.<span class="n">iterfind<span class="p">(<span class="s1">'branch/sub-branch'<span class="p">): <span class="gp">... <span class="k">print <span class="n">elem<span class="o">.<span class="n">tag<span class="p">, <span class="n">elem<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">sub-branch {'name': 'subrelease01'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>这个例子在 <code class="docutils literal">branch</code> 下面找到所有标签为 <code class="docutils literal">sub-branch</code> 的元素。然后给出如何找到所有的 <code class="docutils literal">branch</code> 元素,用一个指定 <code class="docutils literal">name</code> 的状态即可:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="k">for <span class="n">elem <span class="ow">in <span class="n">tree<span class="o">.<span class="n">iterfind<span class="p">(<span class="s1">'branch[@name="release01"]'<span class="p">): <span class="gp">... <span class="k">print <span class="n">elem<span class="o">.<span class="n">tag<span class="p">, <span class="n">elem<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">branch {'hash': 'f200013e', 'name': 'release01'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>想要深入学习 XPath 的话,请看 这里 。</p>
</div>
<div id="id7" class="section">
<h3>建立 XML 文档</h3>
<p>ET 提供了建立 XML 文档和写入文件的便捷方式。 <code class="docutils literal">ElementTree</code> 对象提供了 <code class="docutils literal">write</code> 方法。</p>
<p>现在,这儿有两个常用的写 XML 文档的脚本。</p>
<p>修改文档可以使用 <code class="docutils literal">Element</code> 对象的方法:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="n">root <span class="o">= <span class="n">tree<span class="o">.<span class="n">getroot<span class="p">() <span class="gp">>>> <span class="k">del <span class="n">root<span class="p">[<span class="mi">2<span class="p">] <span class="gp">>>> <span class="n">root<span class="p">[<span class="mi">0<span class="p">]<span class="o">.<span class="n">set<span class="p">(<span class="s1">'foo'<span class="p">, <span class="s1">'bar'<span class="p">) <span class="gp">>>> <span class="k">for <span class="n">subelem <span class="ow">in <span class="n">root<span class="p">: <span class="gp">... <span class="k">print <span class="n">subelem<span class="o">.<span class="n">tag<span class="p">, <span class="n">subelem<span class="o">.<span class="n">attrib <span class="gp">... <span class="go">branch {'foo': 'bar', 'hash': '1cdf045c', 'name': 'testing'} <span class="go">branch {'hash': 'f200013e', 'name': 'release01'} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>我们在这里删除了根元素的第三个子结点,然后为第一个子结点增加新状态。然后这个树可以写回到文件中。</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="kn">import <span class="nn">sys
<span class="gp">>>> <span class="n">tree<span class="o">.<span class="n">write<span class="p">(<span class="n">sys<span class="o">.<span class="n">stdout<span class="p">) <span class="c1"># ET.dump can also serve this purpose <span class="go"><doc> <span class="go"> <branch foo="bar" hash="1cdf045c" name="testing"> <span class="go"> text,source <span class="go"> </branch> <span class="go"><branch hash="f200013e" name="release01"> <span class="go"> <sub-branch name="subrelease01"> <span class="go"> xml,sgml <span class="go"> </sub-branch> <span class="go"></branch> <span class="go"></doc> </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>注意状态的顺序和原文档的顺序不太一样。这是因为 ET 讲状态保存在无序的字典中。语义上来说,XML 并不关心顺序。</p>
<p>建立一个全新的元素也很容易。ET 模块提供了 <code class="docutils literal">SubElement</code> 函数来简化过程:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="gp">>>> <span class="n">a <span class="o">= <span class="n">ET<span class="o">.<span class="n">Element<span class="p">(<span class="s1">'elem'<span class="p">) <span class="gp">>>> <span class="n">c <span class="o">= <span class="n">ET<span class="o">.<span class="n">SubElement<span class="p">(<span class="n">a<span class="p">, <span class="s1">'child1'<span class="p">) <span class="gp">>>> <span class="n">c<span class="o">.<span class="n">text <span class="o">= <span class="s2">"some text" <span class="gp">>>> <span class="n">d <span class="o">= <span class="n">ET<span class="o">.<span class="n">SubElement<span class="p">(<span class="n">a<span class="p">, <span class="s1">'child2'<span class="p">) <span class="gp">>>> <span class="n">b <span class="o">= <span class="n">ET<span class="o">.<span class="n">Element<span class="p">(<span class="s1">'elem_b'<span class="p">) <span class="gp">>>> <span class="n">root <span class="o">= <span class="n">ET<span class="o">.<span class="n">Element<span class="p">(<span class="s1">'root'<span class="p">) <span class="gp">>>> <span class="n">root<span class="o">.<span class="n">extend<span class="p">((<span class="n">a<span class="p">, <span class="n">b<span class="p">)) <span class="gp">>>> <span class="n">tree <span class="o">= <span class="n">ET<span class="o">.<span class="n">ElementTree<span class="p">(<span class="n">root<span class="p">) <span class="gp">>>> <span class="n">tree<span class="o">.<span class="n">write<span class="p">(<span class="n">sys<span class="o">.<span class="n">stdout<span class="p">) <span class="go"><root><elem><child1>some text</child1><child2 /></elem><elem_b /></root> </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
</div>
<div id="iterparse-xml" class="section">
<h3>使用 iterparse 来处理 XML 流</h3>
<p>就像我在文章一开头提到的那样,XML 文档通常比较大,所以将它们全部读入内存的库可能会有点儿小问题。这也是为什么我建议使用 SAX API 来替代 DOM 。</p>
<p>我们刚讲过如何使用 ET 来将 XML 读入内存并且处理。但它就不会碰到和 DOM 一样的内存问题么?当然会。这也是为什么这个包提供一个特殊的工具,用来处理大型文档,并且解决了内存问题,这个工具叫 <code class="docutils literal">iterparse</code> 。</p>
<p>我给大家演示一个 <code class="docutils literal">iterparse</code> 如何使用的例子。我用 自动生成 拿到了一个 XML 文档来进行说明。这只是开头的一小部分:</p>
<div class="highlight-python">
<div class="highlight">
<pre><?xml version="1.0" standalone="yes"?>
<site>
<regions>
<africa>
<item id="item0">
<location>United States</location> <!-- Counting locations -->
<quantity>1</quantity>
<name>duteous nine eighteen </name>
<payment>Creditcard</payment>
<description>
<parlist>
[...]
</pre>
</div>
</div>
<p>我已经用注释标出了我要处理的元素,我们用一个简单的脚本来计数有多少 <code class="docutils literal">location</code> 元素并且文本内容为“Zimbabwe”。这是用 <code class="docutils literal">ET.parse</code> 的一个标准的写法:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="n">tree <span class="o">= <span class="n">ET<span class="o">.<span class="n">parse<span class="p">(<span class="n">sys<span class="o">.<span class="n">argv<span class="p">[<span class="mi">2<span class="p">]) <span class="n">count <span class="o">= <span class="mi">0 <span class="k">for <span class="n">elem <span class="ow">in <span class="n">tree<span class="o">.<span class="n">iter<span class="p">(<span class="n">tag<span class="o">=<span class="s1">'location'<span class="p">): <span class="k">if <span class="n">elem<span class="o">.<span class="n">text <span class="o">== <span class="s1">'Zimbabwe'<span class="p">: <span class="n">count <span class="o">+= <span class="mi">1 <span class="k">print <span class="n">count </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>所有 XML 树中的元素都会被检验。当处理一个大约 100MB 的 XML 文件时,占用的内存大约是 560MB ,耗时 2.9 秒。</p>
<p>注意:我们并不需要在内存中加载整颗树。它检测我们需要的带特定值的 <code class="docutils literal">location</code> 元素。其他元素被丢弃。这是 <code class="docutils literal">iterparse</code> 的来源:</p>
<div class="highlight-python">
<div class="highlight">
<pre><span class="n">count <span class="o">= <span class="mi">0
<span class="k">for <span class="n">event<span class="p">, <span class="n">elem <span class="ow">in <span class="n">ET<span class="o">.<span class="n">iterparse<span class="p">(<span class="n">sys<span class="o">.<span class="n">argv<span class="p">[<span class="mi">2<span class="p">]): <span class="k">if <span class="n">event <span class="o">== <span class="s1">'end'<span class="p">: <span class="k">if <span class="n">elem<span class="o">.<span class="n">tag <span class="o">== <span class="s1">'location' <span class="ow">and <span class="n">elem<span class="o">.<span class="n">text <span class="o">== <span class="s1">'Zimbabwe'<span class="p">: <span class="n">count <span class="o">+= <span class="mi">1 <span class="n">elem<span class="o">.<span class="n">clear<span class="p">() <span class="c1"># discard the element <span class="k">print <span class="n">count </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre>
</div>
</div>
<p>这个循环遍历 <code class="docutils literal">iterparse</code> 事件,检测“闭合的”(end)事件并且寻找 <code class="docutils literal">location</code> 标签和指定的值。在这里 <code class="docutils literal">elem.clear()</code> 是关键 - <code class="docutils literal">iterparse</code> 仍然建立一棵树,只不过不需要全部加载进内存,这样做可以有效的利用内存空间(见注释7)。</p>
<p>处理同样的文件,这个脚本占用内存只需要仅仅的 7MB ,耗时 2.5 秒。速度的提升归功于生成树的时候只遍历一次。相比较来说, <code class="docutils literal">parse</code> 方法首先建立了整个树,然后再次遍历来寻找我们需要的元素(所以慢了一点)。</p>
</div>
<div id="id9" class="section">
<h3>结论</h3>
<p>在 Python 众多处理 XML 的模块中, <code class="docutils literal">ElementTree</code> 真是屌爆了。它将轻量,符合 Python 哲学的 API ,出色的性能完美的结合在了一起。所以说如果要处理 XML ,果断地使用它吧!</p>
<p>这篇文章简略地谈了谈 ET 。我希望这篇拙作可以抛砖引玉。</p>
</div>
<div id="id10" class="section">
<h3>注释</h3>
<p>注释1:和 DOM 不一样,DOM 将整个 XML 加载进内存并且允许随机访问任何深度地元素。</p>
<p>注释2: expat 是一个开源的用于处理 XML 的 C 语言库。Python 将它融合进自身。</p>
<p>注释3:Fredrik Lundh,是 <cite>ElementTree</cite> 的原作者,他提到了一些 基准 。</p>
<p>注释4:当我提到 <code class="docutils literal">_elementtree</code> 的时候,我意思是 C 语言的 <code class="docutils literal">cElementTree._elementtree</code> 扩展模块。</p>
<p>注释5:确定你手边有 模块手册 然后可以随时查阅我提到的方法和函数。</p>
<p>注释6: <em>状态</em> 是一个意义太多的术语。Python 对象有状态,XML 元素也有状态。希望我能将它们表达的更清楚一点。</p>
<p>注释7:准确来说,树的根元素仍然存活。在某些情况下根结点非常大,你也可以丢弃它,但那需要多一点点代码。</p>
<p><span style="font-size:18pt;">Python基于DOM的XML编程接口</span></p>
<p><span style="font-size:18pt;">Python自带支持XML DOM的模块:xml.dom和xml.dom.minidom。</span></p>
<div>
</div>
<div>
<div>
<div> <strong>模块包含的函数</strong>
</div>
<div>
getDOMImplementation( )
</div>
<div>
返回一个DOMImplementation对象,由该对象的createDocument( )方法创建一个DOM对象。
</div>
<div>
<div>
代码示例:
</div>
<div>
<div>
from xml.dom.minidom import getDOMImplementation
</div>
<div>
impl = getDOMImplementation()
</div>
<div>
newdoc = impl.createDocument(None, "some_tag", None)
</div>
<div>
top_element = newdoc.documentElement
</div>
<div>
text = newdoc.createTextNode('Some textual content.')
</div>
<div>
top_element.a(text)
</div>
<div>
</div>
<div>
<div> <strong>DOMImplementation对象</strong>
</div>
<div>
DOMImplementation对象中的createDocument()方法创建并返回一个Document对象,语法:
</div>
<div>
createDocument( <em>namespaceUri</em>, <em>qualifiedName</em>, <em>doctype</em>)
</div>
<div>
前两个命令参数用于指定命名空间、顶级标签,可以都是None, 表示没有任何文档元素。参数doctype必须是由createDocumentType()方法创建的DocumentType对象,或是None。
</div>
<div>
</div>
<div>
<div>
DOMImplementation对象中的createDocumentType()方法创建并返回一个DocumentType对象,语法:
</div>
<div>
createDocumentType( <em>qualifiedName</em>, <em>publicId</em>, <em>systemId</em>)
</div>
<div>
返回的DocumentType对象由参数qualifiedName, publicId和systemId字串封装。
</div>
</div>
<div>
</div>
</div>
</div>
</div>
</div>
<div> <strong>从外部文件创建DOM对象</strong>
</div>
<div>
代码示例:
</div>
<div>
from xml.dom.minidom import parse, parseString
</div>
<div>
dom1 = parse('c:\\temp\\mydata.xml') # 直接指定XML文件名创建DOM对象。
</div>
<div>
datasource = open('c:\\temp\\mydata.xml')
</div>
<div>
dom2 = parse(datasource) # 由一个已打开的文件句柄创建DOM对象。
</div>
<div>
dom3 = parseString('< myxml > ... < /myxml >') #从XML描述字符串创建DOM对象。
</div>
</div>
<div>
assert dom3.documentElement.tagName == "myxml"
</div>
<div>
</div>
<div>
<div> <strong>minidom中Node对象特有的方法</strong>
</div>
<div>
Python的DOM API说明主要包含在“xml.dom”模块文档中, “xml.dom.minidom”有如下一些特有的方法:
</div>
<div>
(1)Node.unlink( )
</div>
<div>
断开对象的所有引用,通过Python垃圾回收机制,对象所占用的内存空间能够被尽快释放。该方法主要用在Document对象,但也可以用于其下级子对象,释放某个子对象的内存空间。
</div>
<div>
(2)Node.toxml([ <em>encoding</em>])
</div>
<div>
返回XML DOM对象的可显示字符串。如果参数缺省,XML头中将不指定字符集,此时默认字符集如不能显示所有字符,将选用Unicode字符集。"utf-8"是XML的缺省字符集。
</div>
<div>
(3)Node.toprettyxml([ <em>indent</em>=""[, <em>newl</em>=""[, <em>encoding</em>=""]]])
</div>
<div>
返回进行过优化处理的可显示字符串。参数缺省情况下:indent为制表符(tabulator);newl为新行符(\n)。
</div>
<div>
</div>
<div> <strong>Node对象</strong>
</div>
</div>
<div>
<div>
XML文档的所有组件都可以看作是Node对象。
</div>
<div>
Node.nodeType 用一个整数表示Node对象的类型。该属性为只读。
</div>
<div>
Node.parentNode 当前对象的双亲对象,对于Document对象该属性为None,对于Attr对象总是None。 该属性只读。
</div>
<div>
Node.attributes 包含的属性对象,只有节点对象的类型为元素是才有实际的值。该属性只读。
</div>
<div>
Node.previousSibling 与当前节点同属一个双亲节点的前一个紧邻的节点。对于第一个节点,该属性为
</div>
<div>
None。 该属性只读。
</div>
<div>
Node.nextSibling 与当前节点同属一个双亲节点的后一个紧邻的节点。对于最后一个节点,该属性为None。 该属性只读。
</div>
<div>
Node.childNodes 一个包含当前节点的子节点的列表。该属性只读。
</div>
<div>
Node.firstChild 第一个子节点,可以是None。 该属性只读。
</div>
<div>
Node.lastChild 最后一个子节点,可以是None。 该属性只读。
</div>
<div>
Node.localName 本地标签名称,完整名称中如有冒号,则为冒号之后的部分,否则为完整名称。该属性为字符串。
</div>
<div>
Node.prefix 名称前缀,完整名称中如有冒号,则为冒号之前的部分,否则为空。该属性为字符串,或None。
</div>
<div>
Node.namespaceURI 与元素关联的命名空间,为一字符串或None。该属性只读。
</div>
<div>
Node.nodeName 对于元素节点,等同于tagName;对于属性节点,等同于name。该节点只读。
</div>
<div>
Node.nodeValue 与nodeName类似,对于不同类型的节点,有不同的含义。该属性只读。
</div>
<div>
Node.hasAttributes() 如果节点包含有属性,返回True。
</div>
<div>
Node.hasChildNodes() 如果节点包含子节点,返回True。
</div>
<div>
Node.isSameNode(other) 如果指定的节点对象引用的就是本节点,该方法返回True。
</div>
<div>
Node.append Child( <em>newChild</em>) 在当前节点的最后一个子节点后增加一个新的子节点。该方法将返回新子节点。
</div>
<div>
<div>
Node.insertBefore( <em>newChild</em>, <em>refChild</em>) 在指定的子节点前插入一个新的节点,如果参照的节点为None,新节点将插入到子节点列表的末尾。该方法返回新子节点。
</div>
<div>
Node.removeChild( <em>oldChild</em>) 删除一个子节点,该方法执行成功后返回被删除的节点,应适用unlink()方法释放被删除节点占用的内存。
</div>
<div>
Node.replaceChild( <em>newChild</em>, <em>oldChild</em>) 用一个新的节点替换一个已经存在的子节点。
</div>
<div>
Node.normalize() 将邻接的文本节点(textNode)连接为单个文本实例,以简化对文本的处理。
</div>
<div>
Node.cloneNode( <em>deep</em>) 克隆当前节点,设置deep表示克隆所有的子节点。该方法返回克隆节点。
</div>
<div>
</div>
<div> <strong>NodeList对象</strong>
</div>
<div>
<div>
NodeList是一个有序的对象列表。它通常用来表示一个节点的子节点列表,或执行getElementsByTagName_r()和getElementsByTagNameNS()方法返回的对象列表。
</div>
<div>
NodeList.item( <em>i</em>) 返回序列中的第i各元素,如果不存在返回None。
</div>
<div>
NodeList.length 序列中节点的数量。
</div>
<div>
</div>
</div>
<div>
<div> <strong>DocumentType对象</strong>
</div>
<div>
Document对象的doctype属性是一个DocumentType对象。 它是一类特殊的节点,有如下属性:
</div>
<div>
DocumentType.publicId 文档类型定义外部子集中的公共标识符,可以是一个字符串,或None。
</div>
<div>
DocumentType.systemId 文档类型定义外部子集中的系统标识符,可以是一个URI字符串,或None。
</div>
<div>
DocumentType.internalSubset
</div>
<div>
DocumentType.name 如果存在,用来声明根元素的名称。
</div>
<div>
DocumentType.entities
</div>
<div>
DocumentType.notations
</div>
<div>
</div>
<div>
<div> <strong> Document对象</strong>
</div>
<div>
Document代表整个XML文档,由getDOMImplementation()创建,它从Node继承属性,nodeType值为9。
</div>
<div>
</div>
<div>
Document.documentElement Document对象的根元素。
</div>
<div>
</div>
<div>
document. create Element( <em>tagName</em>) 建立并返回一个新元素节点,但要加入的节点树中,需使用insertBefore() 或 append Child()方法。
</div>
<div>
document. create ElementNS( <em>namespaceURI</em>, <em>tagName</em>)
</div>
<div>
</div>
<div>
document. create TextNode( <em>data</em>) 以参数传入的数据建立并返回一个文本节点,但未加入到节点树中。
</div>
<div>
</div>
<div>
document. create Comment( <em>data</em>) 以参数传入的数据建立并返回一个注释节点,但未加入到节点树中。
</div>
<div>
</div>
<div>
document. create ProcessingInstruction( <em>target</em>, <em>data</em>)
</div>
<div>
</div>
<div>
document. create Attribute( <em>name</em>) 建立并返回一个属性节点,但要关联到一个元素节点,需要使用方法setAttributeNode()。
</div>
<div>
document. create AttributeNS( <em>namespaceURI</em>, <em>qualifiedName</em>)
</div>
<div>
</div>
<div>
Document.getElementsByTagName ( <em>tagName</em>) 在所有后代节点中查找指定tagname的元素节点,返回子元素到列表,注意是列表。
</div>
<div>
Document.getElementsByTagNameNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
</div>
</div>
<div>
<div> <strong>Element对象</strong>
</div>
<div>
Element是Node的子类,nodeType值为1。
</div>
<div>
Element.tagName 元素类型名称。
</div>
<div>
Element.getElementsByTagName ( <em>tagName</em>) 与Document类相同。
</div>
<div>
Element.getElementsByTagNameNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
Element.hasAttribute( <em>name</em>)
</div>
<div>
Element.hasAttributeNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
Element.getAttribute( <em>name</em>)
</div>
<div>
Element.getAttributeNode( <em>attrname</em>) 返回属性节点。
</div>
<div>
Element.getAttributeNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
Element.getAttributeNodeNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
Element.removeAttribute( <em>name</em>)
</div>
<div>
Element.removeAttributeNode( <em>oldAttr</em>)
</div>
<div>
Element.removeAttributeNS( <em>namespaceURI</em>, <em>localName</em>)
</div>
<div>
Element.setAttribute( <em>name</em>, <em>value</em>)
</div>
<div>
Element.setAttributeNode( <em>newAttr</em>)
</div>
<div>
Element.setAttributeNodeNS( <em>newAttr</em>)
</div>
<div>
Element.setAttributeNS( <em>namespaceURI</em>, <em>qname</em>, <em>value</em>)
</div>
<div>
</div>
</div>
<div>
<div> <strong>Attr对象</strong>
</div>
<div>
Attr继承自Node。 nodeType值为2。
</div>
<div>
Attr.name 属性名称,存在命名空间时,名称中包含冒号。
</div>
<div>
Attr.localName 存在命名空间时,为冒号后的部分。
</div>
<div>
Attr.prefix 存在命名空间时,为冒号前的部分。
</div>
<div>
Attr.value 文本类型的属性值,与nodeValue同义。
</div>
<div>
</div>
<div>
<div> <strong>NamedNodeMap对象</strong>
</div>
<div>
NamedNodeMap继承自Node。
</div>
<div>
NamedNodeMap.length 属性列表的长度。
</div>
<div>
NamedNodeMap.item( <em>index</em>) 返回指定索引的属性项,通过value属性获得属性值。
</div>
<div>
</div>
</div>
<div>
<div> <strong>Comment对象</strong>
</div>
<div>
表示XML文档中的注释,是Node的子类,本身不能有自节点。
</div>
<div>
Comment.data 注释文本字符串。
</div>
<div>
</div>
</div>
<div>
<div> <strong>Text和CDATASection对象</strong>
</div>
<div>
Text接口表示XML文档中的文本,它不存在子节点。如果支持XML扩展,CDATA标记中的文本将被保存在CDATASection对象中。Text节点到nodeType值为3。
</div>
<div>
Text.data 节点的文本字符串。
</div>
<div>
</div>
<div>
<div> <strong>ProcessingInstruction对象</strong>
</div>
<div>
表示XML文档中的处理指定,它不存在子节点。
</div>
<div>
ProcessingInstruction.target 处理指令到出现的第一个空格为止的内容,是只读属性。
</div>
<div>
ProcessingInstruction.data 处理指令出现的第一个空格字符之后的内容。
</div>
<div>
</div>
</div>
<div>
<div> <strong>异常类</strong>
</div>
<div>
DOM级别2 推荐定义单一的异常类DOMException作为基类,并通过定义一系列的常量为可能发生的错误分类。DOMException实例的code属性用来存储表示错误类型的值。异常类型常量对应的派生异常类如下:
</div>
<div>
DOMSTRING_SIZE_ERR DomstringSizeErr
</div>
<div>
HIERARCHY_REQUEST_ERR HierarchyRequestErr
</div>
<div>
INDEX_SIZE_ERR IndexSizeErr
</div>
<div>
INUSE_ATTRIBUTE_ERR InuseAttributeErr
</div>
<div>
INVALID_ACCESS_ERR InvalidAccessErr
</div>
<div>
INVALID_CHARACTER_ERR InvalidCharacterErr
</div>
<div>
INVALID_MODIFICATION_ERR InvalidModificationErr
</div>
<div>
INVALID_STATE_ERR InvalidStateErr
</div>
<div>
NAMESPACE_ERR NamespaceErr
</div>
<div>
NOT_FOUND_ERR NotFoundErr
</div>
<div>
NOT_SUPPORTED_ERR NotSupportedErr
</div>
<div>
NO_DATA_ALLOWED_ERR NoDataAllowedErr
</div>
<div>
NO_MODIFICATION_ALLOWED_ERR NoModificationAllowedErr
</div>
<div>
SYNTAX_ERR SyntaxErr
</div>
<div>
WRONG_DOCUMENT_ERR WrongDocumentErr
</div>
<p> http://blog.sina.com.cn/s/blog_da4487c40102v3jx.html</p>
<p><span style="font-size:18pt;">使用minidom来处理XML的示例(Python 学习)(转载)</span></p>
<p>一.XML的读取.<br><br>在 NewEdit 中有代码片段的功能,代码片段分为片段的分类和片段的内容。在缺省情况下都是用XML格式保存的。下面我讲述一下,如何使用minidom来读取和保存XML文件。</p>
<p>下面是片段分类的一个示例文件--catalog.xml</p>
<blockquote>
<p><?xml version="1.0" encoding="utf-8"?><br><catalog><br> <maxid>4</maxid><br> <item id="1"><br> <caption>Python</caption><br> <item id="4"><br> <caption>测试</caption><br> </item><br> </item><br> <item id="2"><br> <caption>Zope</caption><br> </item><br></catalog></p>
</blockquote>
<p>分类是树状结构,显示出来可能为:</p>
<blockquote>
<p>Python<br> 测试<br>Zope</p>
</blockquote>
<p>先简单介绍一下XML的知识,如果你已经知道了可以跳过去。</p>
<p>1. XML文档的编码</p>
<p>此XML文档的编码为utf-8,因此你看到的“测试”其实是UTF-8编码。在XML文档的处理中都是使用UTF-8编码进行的,因此,如果你不写明encoding的话,都是认为文件是UTF-8编码的。在Python中,好象只支持几种编码,象我们常用的GB2312码就不支持,因此建议大家在处理XML时使用UTF-8编码。</p>
<p>2. XML文档的结构</p>
<p>XML文档有XML头信息和XML信息体。头信息如:</p>
<blockquote>
<p><?xml version="1.0" encoding="utf-8"?></p>
</blockquote>
<p>它表明了此XML文档所用的版本,编码方式。有些复杂的还有一些文档类型的定义(DOCTYPE),用于定义此XML文档所用的DTD或Schema和一些实体的定义。这里并没有用到,而且我也不是专家,就不再细说了。</p>
<p>XML信息体是由树状元素组成。每个XML文档都有一个文档元素,也就是树的根元素,所有其它的元素和内容都包含在根元素中。</p>
<p>3. DOM</p>
<p>DOM是Document Object Model的简称,它是以对象树来表示一个XML文档的方法,使用它的好处就是你可以非常灵活的在对象中进行遍历。</p>
<p>4. 元素和结点</p>
<p>元素就是标记,它是成对出现的。XML文档就是由元素组成的,但元素与元素之间可以有文本,元素的内容也是文本。在minidom中有许多的结点,元素也属于结点的一种,它不是叶子结点,即它存在子结点;还存在一些叶子结点,如文本结点,它下面不再有子结点。</p>
<p>象catalog.xml中,文档元素是catalog,它下面有两种元素:maxid和item。maxid用来表示当前最大的item的id值。每一个item都有一个id属性,id属性是唯一的,在 NewEdit 中用来生成每个分类所对应的代码片段的XML文档名,因此不能重复,而且它是一个递增的值。item元素有一个caption子元素,用来表示此分类项的名称,它还可以包含item元素。这样,就定义了一个树状XML结构,下面让我们看一看如果把它们读出来。</p>
<p><br>一、得到dom对象</p>
<blockquote>
<p>>>> import xml.dom.minidom<br>>>> dom = xml.dom.minidom.parse('d:/catalog.xml')</p>
</blockquote>
<p>这样我们得到了一个dom对象,它的第一个元素应该是catalog。</p>
<p>二、得到文档元素对象</p>
<blockquote>
<p>>>> root = dom.documentElement</p>
</blockquote>
<p>这样我们得到了根元素(catalog)。</p>
<p>三、结点属性</p>
<p>每一个结点都有它的nodeName,nodeValue,nodeType属性。nodeName为结点名字。</p>
<blockquote>
<p>>>> root.nodeName<br>u'catalog'</p>
</blockquote>
<p>nodeValue是结点的值,只对文本结点有效。nodeType是结点的类型,现在有以下几种:</p>
<blockquote>
<p>'ATTRIBUTE_NODE'<br>'CDATA_SECTION_NODE'<br>'COMMENT_NODE'<br>'DOCUMENT_FRAGMENT_NODE'<br>'DOCUMENT_NODE'<br>'DOCUMENT_TYPE_NODE'<br>'ELEMENT_NODE'<br>'ENTITY_NODE'<br>'ENTITY_REFERENCE_NODE'<br>'NOTATION_NODE'<br>'PROCESSING_INSTRUCTION_NODE'<br>'TEXT_NODE'</p>
</blockquote>
<p>这些结点通过名字很好理解。catalog是ELEMENT_NODE类型。</p>
<blockquote>
<p>>>> root.nodeType<br>1<br>>>> root.ELEMENT_NODE<br>1</p>
</blockquote>
<p>四、子元素、子结点的访问</p>
<p>访问子元素、子结点的方法很多,对于知道元素名字的子元素,可以使用getElementsByTagName方法,如读取maxid子元素:</p>
<blockquote>
<p>>>> root.getElementsByTagName('maxid')<br>[<DOM Element: maxid at 0xb6d0a8>]</p>
</blockquote>
<p>这样返回一个列表,由于我们的例子中maxid只有一项,因此列表也只有一项。</p>
<p>如果想得到某个元素下的所有子结点(包括元素),可以使用childNodes属性:</p>
<blockquote>
<p>>>> root.childNodes<br>[<DOM Text node "\n ">, <DOM Element: maxid at 0xb6d0a8>, <DOM Text node "\n ">, <DOM Element: item at 0xb6d918>, <DOM Text node "\n ">, <DOM Element: item at 0xb6de40>, <DOM Text node "\n ">, <DOM Element: item at 0xb6dfa8>, <DOM Text node "\n">]</p>
</blockquote>
<p>可以看出所有两个标记间的内容都被视为文本结点。象每行后面的回车,都被看到文本结点。从上面的结果我们可以看出每个结点的类型,本例中有文本结点和元素结点;结点的名字(元素结点);结点的值(文本结点)。每个结点都是一个对象,不同的结点对象有不同的属性和方法,更详细的要参见文档。由于本例比较简单,只涉及文本结点和元素结点。</p>
<p>getElementsByTagName可以搜索当前元素的所有子元素,包括所有层次的子元素。childNodes只保存了当前元素的第一层子结点。</p>
<p>这样我们可以遍历childNodes来访问每一个结点,判断它的nodeType来得到不同的内容。如,打印出所有元素的名字:</p>
<blockquote>
<p>>>> for node in root.childNodes:<br> if node.nodeType == node.ELEMENT_NODE:<br> print node.nodeName<br> <br>maxid<br>item<br>item</p>
</blockquote>
<p>对于文本结点,想得到它的文本内容可以使用: .data属性。</p>
<p>对于简单的元素,如:<caption>Python</caption>,我们可以编写这样一个函数来得到它的内容(这里为Python)。</p>
<blockquote>
<p>def getTagText(root, tag):<br> node = root.getElementsByTagName(tag)[0]<br> rc = ""<br> for node in node.childNodes:<br> if node.nodeType in ( node.TEXT_NODE, node.CDATA_SECTION_NODE):<br> rc = rc + node.data<br> return rc</p>
</blockquote>
<p>这个函数只处理找到的第一个符合的子元素。它会将符合的第一个子元素中的所有文本结点拼在一起。当nodeType为文本类结点时,node.data为文本的内容。如果我们考查一下元素caption,我们可能看到:</p>
<blockquote>
<p>[<DOM Text node "Python">]</p>
</blockquote>
<p>说明caption元素只有一个文本结点。</p>
<p>如果一个元素有属性,那么可以使用getAttribute方法,如:</p>
<blockquote>
<p>>>> itemlist = root.getElementsByTagName('item')<br>>>> item = itemlist[0]<br>>>> item.getAttribute('id')<br>u'1'</p>
</blockquote>
<p>这样就得到了第一个item元素的属性值。</p>
<p>下面让我们简单地小结一下如何使用minidom来读取XML中的信息</p>
<p>1. 导入xml.dom.minidom模块,生成dom对象<br>2. 得到文档对象(根对象)<br>3. 通过getElementsByTagName()方法和childNodes属性(还有其它一些方法和属性)找到要处理的元素<br>4. 取得元素下文本结点的内容</p>
<p><span style="font-size:18pt;"> <br>二.写入.<br><br></span></p>
<p>下面我来演示一下如何从无到有生成象catalog.xml一样的XML文件。</p>
<p>一、生成dom对象</p>
<blockquote>
<p>>>> import xml.dom.minidom<br>>>> impl = xml.dom.minidom.getDOMImplementation()<br>>>> dom = impl.createDocument(None, 'catalog', None)</p>
</blockquote>
<p>这样就生成了一个空的dom对象。其中catalog为文档元素名,即根元素名。</p>
<p>二、显示生成的XML内容</p>
<p>每一个dom结点对象(包括dom对象本身)都有输出XML内容的方法,如:toxml(), toprettyxml()</p>
<p>toxml()输出紧凑格式的XML文本,如:</p>
<blockquote>
<p><catalog><item>test</item><item>test</item></catalog></p>
</blockquote>
<p>toprettyxml()输出美化后的XML文本,如:</p>
<blockquote>
<p><catalog><br> <item><br> test<br> </item><br> <item><br> test<br> </item><br></catalog></p>
</blockquote>
<p>可以看出,它是将每个结点后面都加入了回车符,并且自动处理缩近。但对于每一个元素,如果元素只有文本内容,则我希望元素的tag与文本是在一起的,如:</p>
<blockquote>
<p><item>test</item></p>
</blockquote>
<p>而不想是分开的格式,但minidom本身是不支持这样的处理。关于如何实现形如:</p>
<blockquote>
<p><catalog><br> <item>test</item><br> <item>test</item><br></catalog></p>
</blockquote>
<p>这样的XML格式,后面我们再说。</p>
<p>三、生成各种结点对象</p>
<p>dom对象拥有各种生成结点的方法,下面列出文本结点,CDATA结点和元素结点的生成过程。</p>
<p>1. 文本结点的生成</p>
<blockquote>
<p>>>> text=dom.createTextNode('test')<br>test</p>
</blockquote>
<p>要注意的是,在生成结点时,minidom并不对文本字符进行检查,象文本中如果出现了'<','&'之类的字符,应该转换为相应的实体符号'<','&'才可以,这里没有做这个处理。</p>
<p>2. CDATA结点的生成</p>
<blockquote>
<p>>>> data = dom.createCDATASection('aaaaaa\nbbbbbb')<br>>>> data.toxml()<br>'<![CDATA[aaaaaa\nbbbbbb]]>'</p>
</blockquote>
<p>CDATA是用于包括大块文本,同时可以不用转换'<','&'字符的标记,它是用<![CDATA[文本]]>来包括的。但文本中不可以有"]]>"这样的串存在。生成结点时minidom不作这些检查,只有当你输出时才有可能发现有错。</p>
<p>3. 元素结点的生成</p>
<blockquote>
<p>>>> item = dom.createElement('caption')<br>>>> item.toxml()<br>'<caption/>'</p>
</blockquote>
<p>对于象元素这样的结点,生成的元素结点其实是一个空元素,即不包含任何文本,如果要包含文本或其它的元素,我们需要使用appendChild()或insertBefore()之类的方法将子结点加就到元素结点中。如将上面生成的text结点加入到caption元素结点中:</p>
<blockquote>
<p>>>> item.appendChild(text)<br><DOM Text node "test"><br>>>> item.toxml()<br>'<caption>test</caption>'</p>
</blockquote>
<p>使用元素对象的setAttribute()方法可以向元素中加入属性,如:</p>
<blockquote>
<p>>>> item.setAttribute('id', 'idvalue')<br>>>> item.toxml()<br>'<caption id="idvalue">test</caption>'</p>
</blockquote>
<p>四、生成dom对象树</p>
<p>我们有了dom对象,又知道了如何生成各种结点,包括叶子结点(不包含其它结点的结点,如文本结点)和非叶子结点(包含其它结点的结点,如元素结点)的生成,然后就需要利用结点对象本身的appendChild()或insertBefore()方法将各个结点根据在树中的位置连起来,串成一棵树。最后要串到文档结点上,即根结点上。如一个完整的示例为:</p>
<blockquote>
<p>>>> import xml.dom.minidom<br>>>> impl = xml.dom.minidom.getDOMImplementation()<br>>>> dom = impl.createDocument(None, 'catalog', None)<br>>>> root = dom.documentElement<br>>>> item = dom.createElement('item')<br>>>> text = dom.createTextNode('test')<br>>>> item.appendChild(text)<br><DOM Text node "test"><br>>>> root.appendChild(item)<br><DOM Element: item at 0xb9cf80><br>>>> print root.toxml()<br><catalog><item>test</item></catalog></p>
</blockquote>
<p>五、简单生成元素结点的函数</p>
<p>下面是我写的一个小函数,用于简单的生成类似于:</p>
<blockquote>
<p><caption>test</caption></p>
</blockquote>
<p>或形如:</p>
<blockquote>
<p><item><![CDATA[test]]></item></p>
</blockquote>
<p>的元素结点</p>
<blockquote>
<p>1 def makeEasyTag(dom, tagname, value, type='text'):<br>2 tag = dom.createElement(tagname)<br>3 if value.find(']]>') > -1:<br>4 type = 'text'<br>5 if type == 'text':<br>6 value = value.replace('&', '&')<br>7 value = value.replace('<', '<')<br>8 text = dom.createTextNode(value)<br>9 elif type == 'cdata':<br>10 text = dom.createCDATASection(value)<br>11 tag.appendChild(text)<br>12 return tag</p>
</blockquote>
<p>参数说明:</p>
<ul>
<li>dom为dom对象</li>
<li>tagname为要生成元素的名字,如'item'</li>
<li>value为其文本内容,可以为多行</li>
<li>type为文本结点的格式,'text'为一般Text结点,'cdata'为CDATA结点</li>
</ul>
<p>函数处理说明:</p>
<ul>
<li>首先创建元素结点</li>
<li>查找文本内容是否有']]>',如果找到,则此文本结点只可以是Text结点</li>
<li>如果结点类型为'text',则对文本内容中的'<'替换为'<','&'替换为'&',再生成文本结点</li>
<li>如果结点类型为'cdata',则生成CDATA结点</li>
<li>将生成的文本结点追加到元素结点上</li>
</ul>
<p>因此这个小函数可以自动地处理字符转化及避免CDATA结点中出现']]>'串。</p>
<p>上面生成'item'结点的语句可以改为:</p>
<blockquote>
<p>>>> item = makeEasyTag(dom, 'item', 'test')<br>>>> item.toxml()<br>'<item>test</item>'</p>
</blockquote>
<p>六、写入到XML文件中</p>
<p>dom对象树已经生成好了,我们可以调用dom的writexml()方法来将内容写入文件中。writexml()方法语法格式为:</p>
<blockquote>
<p>writexml(writer, indent, addindent, newl, encoding)</p>
</blockquote>
<ul>
<li>writer是文件对象</li>
<li>indent是每个tag前填充的字符,如:' ',则表示每个tag前有两个空格</li>
<li>addindent是每个子结点的缩近字符</li>
<li>newl是每个tag后填充的字符,如:'\n',则表示每个tag后面有一个回车</li>
<li>encoding是生成的XML信息头中的encoding属性值,在输出时minidom并不真正进行编码的处理,如果你保存的文本内容中有汉字,则需要自已进行编码转换。</li>
</ul>
<p>writexml方法是除了writer参数必须要有外,其余可以省略。下面给出一个文本内容有汉字的示例:</p>
<blockquote>
<p>1 >>> import xml.dom.minidom<br>2 >>> impl = xml.dom.minidom.getDOMImplementation()<br>3 >>> dom = impl.createDocument(None, 'catalog', None)<br>4 >>> root = dom.documentElement<br>5 >>> text = unicode('汉字示例', 'cp936')<br>6 >>> item = makeEasyTag(dom, 'item', text)<br>7 >>> root.appendChild(item)<br>8 <DOM Element: item at 0xb9ceb8><br>9 >>> root.toxml()<br>10 u'<catalog><item>\u6c49\u5b57\u793a\u4f8b</item></catalog>'<br>11 >>> f=file('d:/test.xml', 'w')<br>12 >>> import codecs<br>13 >>> writer = codecs.lookup('utf-8')[3](f)<br>14 >>> dom.writexml(writer, encoding='utf-8')<br>15 >>> writer.close()</p>
</blockquote>
<p>5行 因为XML处理时内部使用Unicode编码,因此象汉字首先要转成Unicode,如果你不做这一步minicode并不检查,并且保存时可能不会出错。但读取时可能会出错。<br>12-13行 生成UTF-8编码的写入流对象,这样在保存时会自动将Unicode转换成UTF-8编码。</p>
<p>这样写XML文件就完成了。<br><br>三.美化.<br><br></p>
<p>对于dom对象的writexml()方法,虽然可以控制一些格式上的输出,但结果并不让人满意。比如我想实现:</p>
<blockquote>
<p><catalog><br> <item>test</item><br> <item>test</item><br></catalog></p>
</blockquote>
<p>而不是:</p>
<blockquote>
<p><catalog><br> <item><br> test<br> </item><br> <item><br> test<br> </item><br></catalog></p>
</blockquote>
<p>如果是象下面的输出结果我无法区分原来文本中是否带有空白,而上一种结果则不存在这一问题。好在我在wxPython自带的XML资源编辑器(xred)发现了美化的代码。代码如下:</p>
<blockquote>
<p>1 def Indent(dom, node, indent = 0):<br>2 # Copy child list because it will change soon<br>3 children = node.childNodes[:]<br>4 # Main node doesn't need to be indented<br>5 if indent:<br>6 text = dom.createTextNode('\n' + '\t' * indent)<br>7 node.parentNode.insertBefore(text, node)<br>8 if children:<br>9 # Append newline after last child, except for text nodes<br>10 if children[-1].nodeType == node.ELEMENT_NODE:<br>11 text = dom.createTextNode('\n' + '\t' * indent)<br>12 node.appendChild(text)<br>13 # Indent children which are elements<br>14 for n in children:<br>15 if n.nodeType == node.ELEMENT_NODE:<br>16 Indent(dom, n, indent + 1)</p>
</blockquote>
<p>参数说明:</p>
<blockquote>
<p>dom为dom对象<br>node为要处理的元素结点<br>indent指明缩近的层数</p>
</blockquote>
<p>函数说明:</p>
<p>Indent是一个递归函数,当一个结点有子元素时进行递归处理。主要是解决子元素的换行和缩近的处理。这里缩近是写死的,每一级缩近使用一个制表符。如果你愿意可以改为你想要的内容。就是把函数中的'\t'换替一下。或干脆写成一个全局变量,或参数以后改起来可能要容易的多。不过在 <strong><span style="color:#006bad;">NewEdit</span></strong> 中,这样的处理足够了,就没有做这些工作。</p>
<p>Indent基本的想法就是递归遍历所有子结点,在所有需要加入回车和缩近的地方插入相应的文本结点。这样再使用writexml()输出时就是缩近好了的。具体程序不再细说,直接用就行了。</p>
<p>但这里要注意的是:</p>
<p>Indent()要修改原dom对象,因此在调用它之前最好先复制一个临时dom对象,使用完毕后再清除这个临时dom对象即可。下面是详细的调用过程:</p>
<blockquote>
<p>1 domcopy = dom.cloneNode(True)<br>2 Indent(domcopy, domcopy.documentElement)<br>3 f = file(xmlfile, 'wb')<br>4 writer = codecs.lookup('utf-8')[3](f)<br>5 domcopy.writexml(writer, encoding = 'utf-8')<br>6 domcopy.unlink()</p>
</blockquote>
<p>1行 克隆一个dom对象<br>2行 进行缩近处理<br>3-4行 进行UTF-8编码处理<br>5行 生成XML文件<br>6行 清除dom对象的内容</p>
<h2 class="post-title">Python 使用 ElementTree 处理 XML</h2>
<h3 id="一、引用方法">一、引用方法</h3>
<p>ElementTree 所在文件保存在 Lib/xml/etree/ElementTree.py,所以我们通过下面的代码引用它,之后就可以使用 ET. 来访问 ElementTree 中的函数。</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">import xml.etree.ElementTree <span class="keyword">as ET<br></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<h3>二、一个 XML 例子</h3>
<p>下面所有的操作都将下面这段 XML 为例,我们将它保存为sample.xml。</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br><span class="line">5<br><span class="line">6<br><span class="line">7<br><span class="line">8<br><span class="line">9<br><span class="line">10<br><span class="line">11<br><span class="line">12<br><span class="line">13<br><span class="line">14<br><span class="line">15<br><span class="line">16<br><span class="line">17<br><span class="line">18<br><span class="line">19<br><span class="line">20<br><span class="line">21<br><span class="line">22<br><span class="line">23<br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><?xml version="1.0"?><br><span class="line"><span class="tag"><<span class="name">data><br><span class="line"> <span class="tag"><<span class="name">country <span class="attr">name=<span class="string">"Liechtenstein"><br><span class="line"> <span class="tag"><<span class="name">rank>1<span class="tag"></<span class="name">rank><br><span class="line"> <span class="tag"><<span class="name">year>2008<span class="tag"></<span class="name">year><br><span class="line"> <span class="tag"><<span class="name">gdppc>141100<span class="tag"></<span class="name">gdppc><br><span class="line"> <span class="tag"><<span class="name">neighbor <span class="attr">name=<span class="string">"Austria" <span class="attr">direction=<span class="string">"E"/><br><span class="line"> <span class="tag"><<span class="name">neighbor <span class="attr">name=<span class="string">"Switzerland" <span class="attr">direction=<span class="string">"W"/><br><span class="line"> <span class="tag"></<span class="name">country><br><span class="line"> <span class="tag"><<span class="name">country <span class="attr">name=<span class="string">"Singapore"><br><span class="line"> <span class="tag"><<span class="name">rank>4<span class="tag"></<span class="name">rank><br><span class="line"> <span class="tag"><<span class="name">year>2011<span class="tag"></<span class="name">year><br><span class="line"> <span class="tag"><<span class="name">gdppc>59900<span class="tag"></<span class="name">gdppc><br><span class="line"> <span class="tag"><<span class="name">neighbor <span class="attr">name=<span class="string">"Malaysia" <span class="attr">direction=<span class="string">"N"/><br><span class="line"> <span class="tag"></<span class="name">country><br><span class="line"> <span class="tag"><<span class="name">country <span class="attr">name=<span class="string">"Panama"><br><span class="line"> <span class="tag"><<span class="name">rank>68<span class="tag"></<span class="name">rank><br><span class="line"> <span class="tag"><<span class="name">year>2011<span class="tag"></<span class="name">year><br><span class="line"> <span class="tag"><<span class="name">gdppc>13600<span class="tag"></<span class="name">gdppc><br><span class="line"> <span class="tag"><<span class="name">neighbor <span class="attr">name=<span class="string">"Costa Rica" <span class="attr">direction=<span class="string">"W"/><br><span class="line"> <span class="tag"><<span class="name">neighbor <span class="attr">name=<span class="string">"Colombia" <span class="attr">direction=<span class="string">"E"/><br><span class="line"> <span class="tag"></<span class="name">country><br><span class="line"><span class="tag"></<span class="name">data><br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>先对 XML 的格式做一些说明:</p>
<ul>
<li>Tag: 使用 < 和 > 包围的部分,如 成为 start-tag,是 end-tags;</li>
<li>Element:被 Tag 包围的部分,如68,可以认为是一个节点,它可以有子节点;</li>
<li>Attribute:在 Tag 中可能存在的 name/value 对,如 中的 name=”Liechtenstein”,一般表示属性。</li>
</ul>
<h3>三、解析 XML</h3>
<h4>读入 XML 数据</h4>
<p>首先读入 XML,有两种途径,从文件读入和从字符串读入。<br>从文件读入:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">import xml.etree.ElementTree <span class="keyword">as ET<br><span class="line">tree = ET.parse(<span class="string">'sample.xml')<br><span class="line">root = tree.getroot()<br></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>从字符串读入:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br></span></pre> </td>
<td class="code"> <pre><span class="line">root = ET.fromstring(sample_as_string)<br></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>tree 和 root 分布是 ElementTree 中两个很重要的类的对象:</p>
<ul>
<li>ElementTree</li>
<li>Element</li>
</ul>
<h4>查看 Tag 和 Attribute</h4>
<p>这时得到的 root 是一个指向Element 对象,我们可以通过查看 root 的 tag 和 attrib 来验证这一点:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="meta">>>> root.tag<br><span class="line"><span class="string">'data'<br><span class="line"><span class="meta">>>> root.attrib<br><span class="line">{}<br></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>上面的代码说明了查看一个 Element 的 Tag 和 Attribute 的方法,Tag 是一个 <em>字符串 </em>,而 Attribute 得到的是一个<em> 字典</em>。</p>
<p>另外,还可以使用</p>
<ul>
<li>Element.get(AttributeName)</li>
</ul>
<p>来代替 Element.attrib[AttributeName]来访问。</p>
<h4 id="查看孩子">查看孩子</h4>
<p>root.attrib 返回的是一个空字典,如果看 root 的孩子,可以得到非空的 attrib 字典。</p>
<h5>1、使用 for…in…访问</h5>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">for child <span class="keyword">in root:<br><span class="line"> <span class="keyword">print child.tag, child.attrib<br></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p>得到</p>
<blockquote>
<p>country {‘name’: ‘Liechtenstein’}<br>country {‘name’: ‘Singapore’}<br>country {‘name’: ‘Panama’}</p>
</blockquote>
<h5 id="2、使用下标访问">2、使用下标访问</h5>
<p>如:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="meta">>>> <span class="keyword">print root[<span class="number">0].tag<br><span class="line">country<br><span class="line"><span class="meta">>>> <span class="keyword">print root[<span class="number">0][<span class="number">0].tag<br><span class="line">rank<br></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<h5>3、使用 Tag 名称访问</h5>
<p>下标访问的方法虽然简单,但是在未知 XML 具体结构的时候并不适用,通过 Tag 名称访问的方法更具有普适性。这里用到 Element 类的几个函数,分别是</p>
<ul>
<li>Element.iter()</li>
<li>Element.findall()</li>
<li>Element.find()</li>
</ul>
<p>这两个函数使用的场景有所差异:<br>Element.iter()用来寻找 所有 符合要求的 Tag,注意,这里查找的范围 是所有孩子和孩子的孩子 and so on。如果查看所有的 year,可以使用下面的代码:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">for neighbor <span class="keyword">in root.iter(<span class="string">'year'):<br><span class="line"> <span class="keyword">print neighbor.text<br></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<p>返回</p>
<blockquote>
<p>2008<br>2011<br>2011</p>
</blockquote>
<p>Element.findall()只查找 直接的孩子 ,返回所有符合要求的 Tag 的 Element,而Element.find() 只返回符合要求的第一个 Element。如果查看 Singapore 的 year 的值,可以使用下面的代码:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">for country <span class="keyword">in root.findall(<span class="string">'country'):<br><span class="line"> <span class="keyword">if country.attrib[<span class="string">'name'] == <span class="string">'Singapore':<br><span class="line"> year = country.find(<span class="string">'year') <span class="comment"># 使用 Element.find()<br><span class="line"> <span class="keyword">print year.text<br></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">for country <span class="keyword">in root.findall(<span class="string">'country'):<br><span class="line"> <span class="keyword">if country.attrib[<span class="string">'name'] == <span class="string">'Singapore':<br><span class="line"> years = country.findall(<span class="string">'year') <span class="comment"># 使用 Element.findall()<br><span class="line"> <span class="keyword">print years[<span class="number">0].text <span class="comment"># 注意和上段的区别<br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<h4>查看 Element 的值</h4>
<p>我们可以直接用 Element.text 来得到这个 Element 的值。</p>
<h3>四、修改 XML</h3>
<p>前面已经介绍了如何获取一个 Element 的对象,以及查看它的 Tag、Attribute、值和它的孩子。下面介绍如何修改一个 Element 并对 XML 文件进行保存</p>
<h4>修改 Element</h4>
<p>修改 Element 可以直接访问 Element.text。<br>修改 Element 的 Attribute,也可以用来新增 Attribute:</p>
<blockquote>
<p>Element.set(‘AttributeName’,’AttributeValue’)</p>
</blockquote>
<p>新增孩子节点:</p>
<blockquote>
<p>Element.append(childElement)</p>
</blockquote>
<p>删除孩子节点:</p>
<blockquote>
<p>Element.remove(childElement)</p>
</blockquote>
<h4>保存 XML</h4>
<p>我们从文件解析的时候,我们用了一个 ElementTree 的对象 tree,在完成修改之后,还用 tree 来保存 XML 文件。</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br></span></pre> </td>
<td class="code"> <pre><span class="line">tree.write(<span class="string">'output.xml')<br></span></span></pre> </td>
</tr>
</tbody>
</table>
<p> </p>
<h4>构建 XML</h4>
<p>ElementTree 提供了两个静态函数(直接用类名访问,这里我们用的是 ET)可以很方便的构建一个 XML,如:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br><span class="line">5<br><span class="line">6<br><span class="line">7<br></span></span></span></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line">root = ET.Element(<span class="string">'data') <br><span class="line"> country = ET.SubElement(root,<span class="string">'country', {<span class="string">'name':<span class="string">'Liechtenstein'})<br><span class="line"> rank = ET.SubElement(country,<span class="string">'rank')<br><span class="line"> rank.text = <span class="string">'1'<br><span class="line"> year = ET.SubElement(country,<span class="string">'year')<br><span class="line"> year.text = <span class="string">'2008'<br><span class="line"> ET.dump(root)<br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<p>就可以得到</p>
<blockquote>
<p>12008</p>
</blockquote>
<h3>五、XPath 支持</h3>
<p>XPath 表达式用来在 XML 中定位 Element,下面给一个例子来说明:</p>
<table>
<tbody>
<tr>
<td class="gutter"> <pre><span class="line">1<br><span class="line">2<br><span class="line">3<br><span class="line">4<br><span class="line">5<br><span class="line">6<br><span class="line">7<br><span class="line">8<br><span class="line">9<br><span class="line">10<br><span class="line">11<br><span class="line">12<br><span class="line">13<br><span class="line">14<br><span class="line">15<br><span class="line">16<br><span class="line">17<br><span class="line">18<br><span class="line">19<br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
<td class="code"> <pre><span class="line"><span class="keyword">import xml.etree.ElementTree <span class="keyword">as ET<br><span class="line"><br><span class="line">root = ET.fromstring(countrydata)<br><span class="line"><br><span class="line"><span class="comment"># Top-level elements<br><span class="line">root.findall(<span class="string">".")<br><span class="line"><br><span class="line"><span class="comment"># All 'neighbor' grand-children of 'country' children of the top-level<br><span class="line"><span class="comment"># elements<br><span class="line">root.findall(<span class="string">"./country/neighbor")<br><span class="line"><br><span class="line"><span class="comment"># Nodes with name='Singapore' that have a 'year' child<br><span class="line">root.findall(<span class="string">".//year/..[@name='Singapore']")<br><span class="line"><br><span class="line"><span class="comment"># 'year' nodes that are children of nodes with name='Singapore'<br><span class="line">root.findall(<span class="string">".//*[@name='Singapore']/year")<br><span class="line"><br><span class="line"><span class="comment"># All 'neighbor' nodes that are the second child of their parent<br><span class="line">root.findall(<span class="string">".//neighbor[2]")<br></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></pre> </td>
</tr>
</tbody>
</table>
<h4 id="参考">参考</h4>
<p>ElementTree 主页<br>ElementTree 的函数与类介绍</p>
<p>【<strong>ElementTree解析</strong>】</p>
<p><strong><span style="text-decoration:underline;">两种实现</span></strong></p>
<p>ElementTree生来就是为了处理XML ,它在python标准库中有两种实现。</p>
<p>一种是纯Python实现,例如: xml.etree.ElementTree </p>
<p>另外一种是速度快一点的: xml.etree.cElementTree</p>
<p>尽量使用C语言实现的那种,因为它速度更快,而且消耗的内存更少! 在程序中可以这样写:</p>
<p> </p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt"><span class="keyword">try: </span></li>
<li> <span class="keyword">import xml.etree.cElementTree as ET </span></li>
<li class="alt"><span class="keyword">except ImportError: </span></li>
<li> <span class="keyword">import xml.etree.ElementTree as ET </span></li>
</ol>
</div>
<p>常用方法</p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt"><span class="comment"># 当要获取属性值时,用attrib方法。 </span></li>
<li><span class="comment"># 当要获取节点值时,用text方法。 </span></li>
<li class="alt"><span class="comment"># 当要获取节点名时,用tag方法。 </span></li>
</ol>
</div>
<p>示例XML</p>
<div class="dp-highlighter bg_html">
<ol class="dp-xml" start="1">
<li class="alt"><span class="tag"><?<span class="tag-name">xml <span class="attribute">version=<span class="attribute-value">"1.0" <span class="attribute">encoding=<span class="attribute-value">"utf-8"<span class="tag">?> </span></span></span></span></span></span></span></li>
<li><span class="tag"><<span class="tag-name">info<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">intro<span class="tag">>Book message<span class="tag"></<span class="tag-name">intro<span class="tag">> </span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">list <span class="attribute">id=<span class="attribute-value">'001'<span class="tag">> </span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">head<span class="tag">>bookone<span class="tag"></<span class="tag-name">head<span class="tag">> </span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">name<span class="tag">>python check<span class="tag"></<span class="tag-name">name<span class="tag">> </span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">number<span class="tag">>001<span class="tag"></<span class="tag-name">number<span class="tag">> </span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">page<span class="tag">>200<span class="tag"></<span class="tag-name">page<span class="tag">> </span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">list<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">list <span class="attribute">id=<span class="attribute-value">'002'<span class="tag">> </span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">head<span class="tag">>booktwo<span class="tag"></<span class="tag-name">head<span class="tag">> </span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">name<span class="tag">>python learn<span class="tag"></<span class="tag-name">name<span class="tag">> </span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">number<span class="tag">>002<span class="tag"></<span class="tag-name">number<span class="tag">> </span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">page<span class="tag">>300<span class="tag"></<span class="tag-name">page<span class="tag">> </span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">list<span class="tag">> </span></span></span></li>
<li><span class="tag"></<span class="tag-name">info<span class="tag">> </span></span></span></li>
</ol>
</div>
<p>###########</p>
<p>## <strong>加载XML</strong> </p>
<p>###########<br><strong>方法一</strong>:<em>加载文件</em></p>
<div class="dp-highlighter bg_html">
<ol class="dp-xml" start="1">
<li class="alt"><span class="attribute">root = <span class="attribute-value">ET.parse('book.xml') </span></span></li>
</ol>
</div>
<p> <strong>方法二</strong>:<em>加载字符串</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt">root = ET.fromstring(xmltext) </li>
</ol>
</div>
<p> </p>
<p>###########</p>
<p>## <strong>获取节点</strong></p>
<p> ###########<br><strong>方法一</strong>:<em>获得指定节点->getiterator()方法</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt">book_node = root.getiterator(<span class="string">'list') </span></li>
</ol>
</div>
<p> <strong>方法二</strong>:<em>获得指定节点->findall()方法</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt">book_node = root.findall(<span class="string">'list') </span></li>
</ol>
</div>
<p> <strong>方法三</strong>:<em>获得指定节点->find()方法</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt">book_node = root.find(<span class="string">'list') </span></li>
</ol>
</div>
<p><strong>方法四</strong>:<em>获得儿子节点->getchildren()</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt"><span class="keyword">for node <span class="keyword">in book_node: </span></span></li>
<li> book_node_child = node.getchildren()[<span class="number">0] </span></li>
<li class="alt"> <span class="keyword">print book_node_child.tag, <span class="string">'=> ', book_node_child.text </span></span></li>
</ol>
</div>
<p> ###########</p>
<p>## <strong>例子01</strong> </p>
<p>###########</p>
<p> </p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li class="alt"><span class="comment"># coding=utf-8 </span></li>
<li> </li>
<li class="alt"><span class="keyword">try: <span class="comment"># 导入模块 </span></span></li>
<li> <span class="keyword">import xml.etree.cElementTree as ET </span></li>
<li class="alt"><span class="keyword">except ImportError: </span></li>
<li> <span class="keyword">import xml.etree.ElementTree as ET </span></li>
<li class="alt"> </li>
<li>root = ET.parse(<span class="string">'book.xml') <span class="comment"># 分析XML文件 </span></span></li>
<li class="alt">books = root.findall(<span class="string">'/list') <span class="comment"># 查找所有根目录下的list的子节点 </span></span></li>
<li><span class="keyword">for book_list <span class="keyword">in books: <span class="comment"># 对查找后的结果遍历 </span></span></span></li>
<li class="alt"> <span class="keyword">print <span class="string">"=" * <span class="number">30 <span class="comment"># 输出格式 </span></span></span></span></li>
<li> <span class="keyword">for book <span class="keyword">in book_list: <span class="comment"># 对每个子节点再进行遍历,找出里面你的属性及值 </span></span></span></li>
<li class="alt"> <span class="keyword">if book.attrib.has_key(<span class="string">'id'): <span class="comment"># 一句id来做条件判断 </span></span></span></li>
<li> <span class="keyword">print <span class="string">"id:", book.attrib[<span class="string">'id'] <span class="comment"># 根据id打印出属性值 </span></span></span></span></li>
<li class="alt"> <span class="keyword">print book.tag + <span class="string">'=> ' + book.text <span class="comment"># 输出标签及文本内容 </span></span></span></li>
<li><span class="keyword">print <span class="string">"=" * <span class="number">30 </span></span></span></li>
</ol>
</div>
<p> </p>
<p><em>输出结果:</em></p>
<div class="dp-highlighter bg_python">
<ol class="dp-py" start="1">
<li>
<ol class="dp-py" start="1">
<li class="alt">============================== </li>
<li>head=> bookone </li>
<li class="alt">name=> python check </li>
<li>number=> <span class="number">001 </span></li>
<li class="alt">page=> <span class="number">200 </span></li>
<li>============================== </li>
<li class="alt">head=> booktwo </li>
<li>name=> python learn </li>
<li class="alt">number=> <span class="number">002 </span></li>
<li>page=> <span class="number">300 </span></li>
<li class="alt">============================== </li>
</ol></li>
</ol>
<h2 class="postTitle">Python 标准库之 xml.etree.ElementTree</h2>
<div class="clear">
</div>
<div class="postBody">
<div>
<p><strong>简介</strong></p>
<p> </p>
<p>Element类型是一种灵活的容器对象,用于在内存中存储结构化数据。</p>
<p>[注意]xml.etree.ElementTree模块在应对恶意结构数据时显得并不安全。</p>
<p>每个element对象都具有以下属性:</p>
<p> 1. tag:string对象,表示数据代表的种类。</p>
<p> 2. attrib:dictionary对象,表示附有的属性。</p>
<p> 3. text:string对象,表示element的内容。</p>
<p> 4. tail:string对象,表示element闭合之后的尾迹。</p>
<p> 5. 若干子元素(child elements)。</p>
<div class="cnblogs_code">
<pre><tag attrib1=1>text</tag>tail<br> 1 2 3 4</pre>
</div>
<p>创建元素的方法有Element或者SubElement(),前者称作元素的构建函数(constructor),用以构建任一独存的元素;后者称作元素的制造函数(factory function),用以制造某一元素的子元素。</p>
<p>有了一串元素之后,使用ElementTree类来将其打包,把一串元素转换为xml文件或者从xml文件中解析出来。</p>
<p>若想加快速度,可以使用C语言编译的API xml.etree.cElementTree。</p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre><?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data></pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p> </p>
<h3>XML操作</h3>
<ul>
<li> <h4>读取</h4> </li>
</ul>
<div class="cnblogs_code">
<pre>#从变量读取,参数为XML段,返回的是一个根Element对象
root = ET.fromstring(country_data_as_string)
#从xml文件中读取,用getroot获取根节点,根节点也是Element对象
tree = ET.parse('file.xml')
root = tree.getroot()</pre>
</div>
<ul>
<li> <h4>访问</h4>
<ul>
<li>访问Element对象的标签、属性和值</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<pre>tag = element.tag
attrib = element.attrib
value = element.text</pre>
</div>
<ul>
<li>
<ul>
<li>访问子节点</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<pre>#打印根节点的标签和属性,获取
for child in root:
print(child.tag, child.attrib)</pre>
</div>
<ul>
<li> <h4>查找操作</h4>
<ul>
<li>Element元素迭代子元素:Element.iter("tag"),可以罗列该节点所包含的所有其他节点(element对象)</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<pre>#打印根节点中所有的neighbor对象的name属性
for neighbor in root.iter('neighbor'):
print(neighbor.attrib['name'])</pre>
</div>
<ul>
<li>
<ul>
<li>Element.findall("tag"):查找当前元素为“tag”的直接子元素</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<pre>#findall只能用来查找直接子元素,不能用来查找rank,neighbor等element
for country in root.findall('country'):
rank = country.find('rank').text
name = country.find('rank').text
neig = country.find('neighbor').attrib
print(rank, name,neig)</pre>
</div>
<ul>
<li>
<ul>
<li>Element.find("tag"):查找为tag的第一个直接子元素</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<pre>#返回第一个tag为country的element,如没有,返回None
firstCountry = root.find("country")
print(firstCountry)</pre>
</div>
<ul>
<li> <h4>创建xml文件</h4> </li>
</ul>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>__author__ = 'xua'
import xml.etree.ElementTree as ET
#创建根节点
a = ET.Element("root")
#创建子节点,并添加属性
b = ET.SubElement(a,"sub1")
b.attrib = {"name":"name attribute"}
#创建子节点,并添加数据
c = ET.SubElement(a,"sub2")
c.text = "test"
#创建elementtree对象,写文件
tree = ET.ElementTree(a)
tree.write("test.xml")</pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p>创建的新文件内容为:<strong><root><sub1 name="name attribute" /><sub2>test</sub2></root></strong></p>
<ul>
<li> <h4>修改XML文件</h4>
<ul>
<li>ElementTree.write("xmlfile"):更新xml文件</li>
<li>Element.append():为当前element对象添加子元素(element)</li>
<li>Element.set(key,value):为当前element的key属性设置value值</li>
<li>Element.remove(element):删除为element的节点</li>
</ul></li>
</ul>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>#读取待修改文件
updateTree = ET.parse("test.xml")
root = updateTree.getroot()
#创建新节点并添加为root的子节点
newEle = ET.Element("NewElement")
newEle.attrib = {"name":"NewElement","age":"20"}
newEle.text = "This is a new element"
root.append(newEle)
#修改sub1的name属性
sub1 = root.find("sub1")
sub1.set("name","New Name")
#修改sub2的数据值
sub2 = root.find("sub2")
sub2.text = "New Value"
#写回原文件
updateTree.write("test.xml")</pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p>更新完的文件为:<root><sub1 name="New Name" /><sub2>New Value</sub2><NewElement age="20" name="NewElement">This is a new element</NewElement></root></p>
<p> </p>
<h3>总结</h3>
<p> XML的操作比较常见,当然也有很多第三方的库可以使用,所需要做的操作无非就是常用的读写xml文件、元素节点的增删改查,大家还可以在python官方文档上学习更多的操作。</p>
<p>https://docs.python.org/3.5/library/xml.etree.elementtree.html </p>
<p> </p>
<p>xml源文件格式[例]</p>
<p> </p>
<div class="dp-highlighter bg_html">
<div class="bar">
<div class="tools"> <strong>[html]</strong> view plain copy
<div>
</div> print?
</div>
</div>
<ol class="dp-xml" start="1">
<li class="alt"><span class="tag"><?<span class="tag-name">xml <span class="attribute">version=<span class="attribute-value">"1.0" <span class="attribute">encoding=<span class="attribute-value">"UTF-8"<span class="tag">?> </span></span></span></span></span></span></span></li>
<li><span class="tag"><<span class="tag-name">framework<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">processers<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">processer <span class="attribute">name=<span class="attribute-value">"AProcesser" <span class="attribute">file=<span class="attribute-value">"lib64/A.so" </span></span></span></span></span></span></li>
<li class="alt"> <span class="attribute">path=<span class="attribute-value">"/tmp"<span class="tag">> </span></span></span></li>
<li> <span class="tag"></<span class="tag-name">processer<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">processer <span class="attribute">name=<span class="attribute-value">"BProcesser" <span class="attribute">file=<span class="attribute-value">"lib64/B.so" <span class="attribute">value=<span class="attribute-value">"fordelete"<span class="tag">> </span></span></span></span></span></span></span></span></span></li>
<li> <span class="tag"></<span class="tag-name">processer<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">processer <span class="attribute">name=<span class="attribute-value">"BProcesser" <span class="attribute">file=<span class="attribute-value">"lib64/B.so2222222"<span class="tag">/> </span></span></span></span></span></span></span></li>
<li> </li>
<li class="alt"> <span class="tag"><<span class="tag-name">services<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">service <span class="attribute">name=<span class="attribute-value">"search" <span class="attribute">prefix=<span class="attribute-value">"/bin/search?" </span></span></span></span></span></span></li>
<li class="alt"> <span class="attribute">output_formatter=<span class="attribute-value">"OutPutFormatter:service_inc"<span class="tag">> </span></span></span></li>
<li> </li>
<li class="alt"> <span class="tag"><<span class="tag-name">chain <span class="attribute">sequency=<span class="attribute-value">"chain1"<span class="tag">/> </span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">chain <span class="attribute">sequency=<span class="attribute-value">"chain2"<span class="tag">><span class="tag"></<span class="tag-name">chain<span class="tag">> </span></span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">service<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">service <span class="attribute">name=<span class="attribute-value">"update" <span class="attribute">prefix=<span class="attribute-value">"/bin/update?"<span class="tag">> </span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">chain <span class="attribute">sequency=<span class="attribute-value">"chain3" <span class="attribute">value=<span class="attribute-value">"fordelete"<span class="tag">/> </span></span></span></span></span></span></span></li>
<li> <span class="tag"></<span class="tag-name">service<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">services<span class="tag">> </span></span></span></li>
<li> <span class="tag"></<span class="tag-name">processers<span class="tag">> </span></span></span></li>
<li class="alt"><span class="tag"></<span class="tag-name">framework<span class="tag">> </span></span></span></li>
</ol>
</div>
<p><br>使用库:</p>
<p> </p>
<p>xml.etree.ElementTree </p>
<p>官方文档地址:http://docs.python.org/library/xml.etree.elementtree.html</p>
<p> </p>
<p>实现思想:</p>
<p>使用ElementTree,先将文件读入,解析成树,之后,根据路径,可以定位到树的每个节点,再对节点进行修改,最后直接将其输出</p>
<p> </p>
<p>代码附文档:</p>
<p> </p>
<div class="dp-highlighter bg_python">
<div class="bar">
<div class="tools"> <strong>[python]</strong> view plain copy
<div>
</div> print?
</div>
</div>
<ol class="dp-py" start="1">
<li class="alt"><span class="comment">#!/usr/bin/python </span></li>
<li><span class="comment"># -*- coding=utf-8 -*- </span></li>
<li class="alt"><span class="comment"># author : wklken@yeah.net </span></li>
<li><span class="comment"># date: 2012-05-25 </span></li>
<li class="alt"><span class="comment"># version: 0.1 </span></li>
<li> </li>
<li class="alt"><span class="keyword">from xml.etree.ElementTree <span class="keyword">import ElementTree,Element </span></span></li>
<li> </li>
<li class="alt"><span class="keyword">def read_xml(in_path): </span></li>
<li> <span class="string">''<span class="comment">'''读取并解析xml文件 </span></span></li>
<li class="alt"><span class="comment"> in_path: xml路径 </span></li>
<li><span class="comment"> return: ElementTree''' </span></li>
<li class="alt"> tree = ElementTree() </li>
<li> tree.parse(in_path) </li>
<li class="alt"> <span class="keyword">return tree </span></li>
<li> </li>
<li class="alt"><span class="keyword">def write_xml(tree, out_path): </span></li>
<li> <span class="string">''<span class="comment">'''将xml文件写出 </span></span></li>
<li class="alt"><span class="comment"> tree: xml树 </span></li>
<li><span class="comment"> out_path: 写出路径''' </span></li>
<li class="alt"> tree.write(out_path, encoding=<span class="string">"utf-8",xml_declaration=<span class="special">True) </span></span></li>
<li> </li>
<li class="alt"><span class="keyword">def if_match(node, kv_map): </span></li>
<li> <span class="string">''<span class="comment">'''判断某个节点是否包含所有传入参数属性 </span></span></li>
<li class="alt"><span class="comment"> node: 节点 </span></li>
<li><span class="comment"> kv_map: 属性及属性值组成的map''' </span></li>
<li class="alt"> <span class="keyword">for key <span class="keyword">in kv_map: </span></span></li>
<li> <span class="keyword">if node.get(key) != kv_map.get(key): </span></li>
<li class="alt"> <span class="keyword">return <span class="special">False </span></span></li>
<li> <span class="keyword">return <span class="special">True </span></span></li>
<li class="alt"> </li>
<li><span class="comment">#---------------search ----- </span></li>
<li class="alt"> </li>
<li><span class="keyword">def find_nodes(tree, path): </span></li>
<li class="alt"> <span class="string">''<span class="comment">'''查找某个路径匹配的所有节点 </span></span></li>
<li><span class="comment"> tree: xml树 </span></li>
<li class="alt"><span class="comment"> path: 节点路径''' </span></li>
<li> <span class="keyword">return tree.findall(path) </span></li>
<li class="alt"> </li>
<li> </li>
<li class="alt"><span class="keyword">def get_node_by_keyvalue(nodelist, kv_map): </span></li>
<li> <span class="string">''<span class="comment">'''根据属性及属性值定位符合的节点,返回节点 </span></span></li>
<li class="alt"><span class="comment"> nodelist: 节点列表 </span></li>
<li><span class="comment"> kv_map: 匹配属性及属性值map''' </span></li>
<li class="alt"> result_nodes = [] </li>
<li> <span class="keyword">for node <span class="keyword">in nodelist: </span></span></li>
<li class="alt"> <span class="keyword">if if_match(node, kv_map): </span></li>
<li> result_nodes.append(node) </li>
<li class="alt"> <span class="keyword">return result_nodes </span></li>
<li> </li>
<li class="alt"><span class="comment">#---------------change ----- </span></li>
<li> </li>
<li class="alt"><span class="keyword">def change_node_properties(nodelist, kv_map, is_delete=<span class="special">False): </span></span></li>
<li> <span class="string">''<span class="comment">'''修改/增加 /删除 节点的属性及属性值 </span></span></li>
<li class="alt"><span class="comment"> nodelist: 节点列表 </span></li>
<li><span class="comment"> kv_map:属性及属性值map''' </span></li>
<li class="alt"> <span class="keyword">for node <span class="keyword">in nodelist: </span></span></li>
<li> <span class="keyword">for key <span class="keyword">in kv_map: </span></span></li>
<li class="alt"> <span class="keyword">if is_delete: </span></li>
<li> <span class="keyword">if key <span class="keyword">in node.attrib: </span></span></li>
<li class="alt"> <span class="keyword">del node.attrib[key] </span></li>
<li> <span class="keyword">else: </span></li>
<li class="alt"> node.set(key, kv_map.get(key)) </li>
<li> </li>
<li class="alt"><span class="keyword">def change_node_text(nodelist, text, is_add=<span class="special">False, is_delete=<span class="special">False): </span></span></span></li>
<li> <span class="string">''<span class="comment">'''改变/增加/删除一个节点的文本 </span></span></li>
<li class="alt"><span class="comment"> nodelist:节点列表 </span></li>
<li><span class="comment"> text : 更新后的文本''' </span></li>
<li class="alt"> <span class="keyword">for node <span class="keyword">in nodelist: </span></span></li>
<li> <span class="keyword">if is_add: </span></li>
<li class="alt"> node.text += text </li>
<li> <span class="keyword">elif is_delete: </span></li>
<li class="alt"> node.text = "" </li>
<li> <span class="keyword">else: </span></li>
<li class="alt"> node.text = text </li>
<li> </li>
<li class="alt"><span class="keyword">def create_node(tag, property_map, content): </span></li>
<li> <span class="string">''<span class="comment">'''新造一个节点 </span></span></li>
<li class="alt"><span class="comment"> tag:节点标签 </span></li>
<li><span class="comment"> property_map:属性及属性值map </span></li>
<li class="alt"><span class="comment"> content: 节点闭合标签里的文本内容 </span></li>
<li><span class="comment"> return 新节点''' </span></li>
<li class="alt"> element = Element(tag, property_map) </li>
<li> element.text = content </li>
<li class="alt"> <span class="keyword">return element </span></li>
<li> </li>
<li class="alt"><span class="keyword">def add_child_node(nodelist, element): </span></li>
<li> <span class="string">''<span class="comment">'''给一个节点添加子节点 </span></span></li>
<li class="alt"><span class="comment"> nodelist: 节点列表 </span></li>
<li><span class="comment"> element: 子节点''' </span></li>
<li class="alt"> <span class="keyword">for node <span class="keyword">in nodelist: </span></span></li>
<li> node.append(element) </li>
<li class="alt"> </li>
<li><span class="keyword">def del_node_by_tagkeyvalue(nodelist, tag, kv_map): </span></li>
<li class="alt"> <span class="string">''<span class="comment">'''同过属性及属性值定位一个节点,并删除之 </span></span></li>
<li><span class="comment"> nodelist: 父节点列表 </span></li>
<li class="alt"><span class="comment"> tag:子节点标签 </span></li>
<li><span class="comment"> kv_map: 属性及属性值列表''' </span></li>
<li class="alt"> <span class="keyword">for parent_node <span class="keyword">in nodelist: </span></span></li>
<li> children = parent_node.getchildren() </li>
<li class="alt"> <span class="keyword">for child <span class="keyword">in children: </span></span></li>
<li> <span class="keyword">if child.tag == tag <span class="keyword">and if_match(child, kv_map): </span></span></li>
<li class="alt"> parent_node.remove(child) </li>
<li> </li>
<li class="alt"> </li>
<li> </li>
<li class="alt"><span class="keyword">if __name__ == <span class="string">"__main__": </span></span></li>
<li> </li>
<li class="alt"> <span class="comment">#1. 读取xml文件 </span></li>
<li> tree = read_xml(<span class="string">"./test.xml") </span></li>
<li class="alt"> </li>
<li> <span class="comment">#2. 属性修改 </span></li>
<li class="alt"> <span class="comment">#A. 找到父节点 </span></li>
<li> nodes = find_nodes(tree, <span class="string">"processers/processer") </span></li>
<li class="alt"> <span class="comment">#B. 通过属性准确定位子节点 </span></li>
<li> result_nodes = get_node_by_keyvalue(nodes, {<span class="string">"name":<span class="string">"BProcesser"}) </span></span></li>
<li class="alt"> <span class="comment">#C. 修改节点属性 </span></li>
<li> change_node_properties(result_nodes, {<span class="string">"age": <span class="string">"1"}) </span></span></li>
<li class="alt"> <span class="comment">#D. 删除节点属性 </span></li>
<li> change_node_properties(result_nodes, {<span class="string">"value":""}, <span class="special">True) </span></span></li>
<li class="alt"> </li>
<li> <span class="comment">#3. 节点修改 </span></li>
<li class="alt"> <span class="comment">#A.新建节点 </span></li>
<li> a = create_node(<span class="string">"person", {<span class="string">"age":<span class="string">"15",<span class="string">"money":<span class="string">"200000"}, <span class="string">"this is the firest content") </span></span></span></span></span></span></li>
<li class="alt"> <span class="comment">#B.插入到父节点之下 </span></li>
<li> add_child_node(result_nodes, a) </li>
<li class="alt"> </li>
<li> <span class="comment">#4. 删除节点 </span></li>
<li class="alt"> <span class="comment">#定位父节点 </span></li>
<li> del_parent_nodes = find_nodes(tree, <span class="string">"processers/services/service") </span></li>
<li class="alt"> <span class="comment">#准确定位子节点并删除之 </span></li>
<li> target_del_node = del_node_by_tagkeyvalue(del_parent_nodes, <span class="string">"chain", {<span class="string">"sequency" : <span class="string">"chain1"}) </span></span></span></li>
<li class="alt"> </li>
<li> <span class="comment">#5. 修改节点文本 </span></li>
<li class="alt"> <span class="comment">#定位节点 </span></li>
<li> text_nodes = get_node_by_keyvalue(find_nodes(tree, <span class="string">"processers/services/service/chain"), {<span class="string">"sequency":<span class="string">"chain3"}) </span></span></span></li>
<li class="alt"> change_node_text(text_nodes, <span class="string">"new text") </span></li>
<li> </li>
<li class="alt"> <span class="comment">#6. 输出到结果文件 </span></li>
<li> write_xml(tree, <span class="string">"./out.xml") </span></li>
<li class="alt"> </li>
<li> </li>
</ol>
</div>
<p> <br><br></p>
<p> </p>
<p>通过main处理后的结果文件:</p>
<p> </p>
<div class="dp-highlighter bg_html">
<div class="bar">
<div class="tools"> <strong>[html]</strong> view plain copy
<div>
</div> print?
</div>
</div>
<ol class="dp-xml" start="1">
<li>
<ol class="dp-xml" start="1">
<li class="alt"><span class="tag"><?<span class="tag-name">xml <span class="attribute">version=<span class="attribute-value">'1.0' <span class="attribute">encoding=<span class="attribute-value">'utf-8'<span class="tag">?> </span></span></span></span></span></span></span></li>
<li><span class="tag"><<span class="tag-name">framework<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">processers<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">processer <span class="attribute">file=<span class="attribute-value">"lib64/A.so" <span class="attribute">name=<span class="attribute-value">"AProcesser" <span class="attribute">path=<span class="attribute-value">"/tmp"<span class="tag">> </span></span></span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">processer<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">processer <span class="attribute">age=<span class="attribute-value">"1" <span class="attribute">file=<span class="attribute-value">"lib64/B.so" <span class="attribute">name=<span class="attribute-value">"BProcesser"<span class="tag">> </span></span></span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">person <span class="attribute">age=<span class="attribute-value">"15" <span class="attribute">money=<span class="attribute-value">"200000"<span class="tag">>this is the firest content<span class="tag"></<span class="tag-name">person<span class="tag">> </span></span></span></span></span></span></span></span></span></span></li>
<li> <span class="tag"></<span class="tag-name">processer<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">processer <span class="attribute">age=<span class="attribute-value">"1" <span class="attribute">file=<span class="attribute-value">"lib64/B.so2222222" <span class="attribute">name=<span class="attribute-value">"BProcesser"<span class="tag">> </span></span></span></span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">person <span class="attribute">age=<span class="attribute-value">"15" <span class="attribute">money=<span class="attribute-value">"200000"<span class="tag">>this is the firest content<span class="tag"></<span class="tag-name">person<span class="tag">> </span></span></span></span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">processer<span class="tag">> </span></span></span></li>
<li> </li>
<li class="alt"> <span class="tag"><<span class="tag-name">services<span class="tag">> </span></span></span></li>
<li> <span class="tag"><<span class="tag-name">service <span class="attribute">name=<span class="attribute-value">"search" <span class="attribute">output_formatter=<span class="attribute-value">"OutPutFormatter:service_inc" </span></span></span></span></span></span></li>
<li class="alt"> <span class="attribute">prefix=<span class="attribute-value">"/bin/search?"<span class="tag">> </span></span></span></li>
<li> </li>
<li class="alt"> <span class="tag"><<span class="tag-name">chain <span class="attribute">sequency=<span class="attribute-value">"chain2" <span class="tag">/> </span></span></span></span></span></li>
<li> <span class="tag"></<span class="tag-name">service<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"><<span class="tag-name">service <span class="attribute">name=<span class="attribute-value">"update" <span class="attribute">prefix=<span class="attribute-value">"/bin/update?"<span class="tag">> </span></span></span></span></span></span></span></li>
<li> <span class="tag"><<span class="tag-name">chain <span class="attribute">sequency=<span class="attribute-value">"chain3" <span class="attribute">value=<span class="attribute-value">"fordelete"<span class="tag">>new text<span class="tag"></<span class="tag-name">chain<span class="tag">> </span></span></span></span></span></span></span></span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">service<span class="tag">> </span></span></span></li>
<li> <span class="tag"></<span class="tag-name">services<span class="tag">> </span></span></span></li>
<li class="alt"> <span class="tag"></<span class="tag-name">processers<span class="tag">> </span></span></span></li>
<li><span class="tag"></<span class="tag-name">framework<span class="tag">> </span></span></span></li>
</ol></li>
</ol>
</div>
<p><strong> 导入ElementTree</strong></p>
<p> </p>
<p>在使用xml.etree.ElementTree时,一般都按如下导入:</p>
<div class="cnblogs_code">
<pre>try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET</pre>
</div>
<p>XML是中结构化数据形式,在ET中使用ElementTree代表整个XML文档,并视其为一棵树,Element代表这个文档树中的单个节点。</p>
<p>ET对象具有多种方法从不同来源导入数据,如下:</p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>#从硬盘的xml文件读取数据
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml') #载入数据
root = tree.getroot() #获取根节点
#从字符串读取数据
root = ET.fromstring(country_data_as_string)</pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p>[注意]fromstring()是直接获取string对象中的根节点,因此以上root其实是一个Element。</p>
<p>作为一个Element对象,本身是具有子元素,因此可以直接对Element进行迭代取值:</p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>>>> for child in root:
... print child.tag, child.attrib
...
country {'name': 'Liechtenstein'}
country {'name': 'Singapore'}
country {'name': 'Panama'}<br><br>或者直接使用索引寻找子节点:</pre>
<pre><span class="gp">>>> <span class="n">root<span class="p">[<span class="mi">0<span class="p">][<span class="mi">1<span class="p">]<span class="o">.<span class="n">text <span class="go">'2008'</span></span></span></span></span></span></span></span></span></span></pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p> </p>
<p> <strong>Element中的遍历与查询</strong></p>
<p> </p>
<p>Element.iter(tag=None):遍历该Element所有后代,也可以指定tag进行遍历寻找。</p>
<p>Element.findall(path):查找当前元素下tag或path能够匹配的直系节点。</p>
<p>Element.find(path):查找当前元素下tag或path能够匹配的首个直系节点。</p>
<p>Element.text: 获取当前元素的text值。</p>
<p>Element.get(key, default=None):获取元素指定key对应的属性值,如果没有该属性,则返回default值。</p>
<p> </p>
<p> <strong>Element对象</strong> </p>
<p> </p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>class xml.etree.ElementTree.Element(tag, attrib={}, **extra)
tag:string,元素代表的数据种类。
text:string,元素的内容。
tail:string,元素的尾形。
attrib:dictionary,元素的属性字典。
#针对属性的操作
clear():清空元素的后代、属性、text和tail也设置为None。
get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值。
items():根据属性字典返回一个列表,列表元素为(key, value)。
keys():返回包含所有元素属性键的列表。
set(key, value):设置新的属性键与值。
#针对后代的操作
append(subelement):添加直系子元素。
extend(subelements):增加一串元素对象作为子元素。#python2.7新特性
find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。
findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。
findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。
insert(index, element):在指定位置插入子元素。
iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。#python2.7新特性
iterfind(match):根据tag或path查找所有的后代。
itertext():遍历所有后代并返回text值。
remove(subelement):删除子元素。</pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p> </p>
<p> <strong>ElementTree对象</strong></p>
<p> </p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<pre>class xml.etree.ElementTree.ElementTree(element=None, file=None)<br> element如果给定,则为新的ElementTree的根节点。<br><br> _setroot(element):用给定的element替换当前的根节点。慎用。<br> <br> # 以下方法与Element类中同名方法近似,区别在于它们指定以根节点作为操作对象。<br> find(match)<br> findall(match)<br> findtext(match, default=None)<br> getroot():获取根节点.<br> iter(tag=None)<br> iterfind(match)<br> parse(source, parser=None):装载xml对象,source可以为文件名或文件类型对象.<br> <tt class="descname">write</tt>(<em>file</em>, <em>encoding="us-ascii"</em>, <em>xml_declaration=None</em>, <em>default_namespace=None</em>,<em>method="xml"</em>) </pre>
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
</div>
<p><strong> </strong></p>
<p> <strong>模块方法</strong></p>
<p> </p>
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar"> <span class="cnblogs_code_copy"><img src="http://img.e-com-net.com/image/info8/ab544354af934f8997b79d5b4245e68a.gif" alt="复制代码" width="0" height="0"></span>
</div>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">Comment</tt> <big>(</big> <em>text=None</em> <big>)</big>
<dd>
<p>创建一个特别的element,通过标准序列化使其代表了一个comment。comment可以为bytestring或unicode。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">dump</tt> <big>(</big> <em>elem</em> <big>)</big>
<dd>
<p>生成一个element tree,通过sys.stdout输出,elem可以是元素树或单个元素。这个方法最好只用于debug。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">fromstring</tt> <big>(</big> <em>text</em> <big>)</big>
<dd>
<p>text是一个包含XML数据的字符串,与XML()方法类似,返回一个Element实例。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">fromstringlist</tt> <big>(</big> <em>sequence</em>, <em>parser=None</em> <big>)</big>
<dd>
<p>从字符串的序列对象中解析xml文档。缺省parser为XMLParser,返回Element实例。</p>
<p class="versionadded"><span class="versionmodified">New in version 2.7.</span></p>
<p class="versionadded"> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">iselement</tt> <big>(</big> <em>element</em> <big>)</big>
<dd>
<p>检查是否是一个element对象。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">iterparse</tt> <big>(</big> <em>source</em>, <em>events=None</em>, <em>parser=None</em> <big>)</big>
<dd>
<p>将文件或包含xml数据的文件对象递增解析为element tree,并且报告进度。events是一个汇报列表,如果忽略,将只有end事件会汇报出来。</p>
<p>注意,iterparse()只会在看见开始标签的">"符号时才会抛出start事件,因此届时属性是已经定义了,但是text和tail属性在那时还没有定义,同样子元素也没有定义,因此他们可能不能被显示出来。如果你想要完整的元素,请查找end事件。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">parse</tt> <big>(</big> <em>source</em>, <em>parser=None</em> <big>)</big>
<dd>
<p>将一个文件或者字符串解析为element tree。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">ProcessingInstruction</tt> <big>(</big> <em>target</em>, <em>text=None</em> <big>)</big>
<dd>
<p>这个方法会创建一个特别的element,该element被序列化为一个xml处理命令。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">register_namespace</tt> <big>(</big> <em>prefix</em>, <em>uri</em> <big>)</big>
<dd>
<p>注册命名空间前缀。这个注册是全局有效,任何已经给出的前缀或者命名空间uri的映射关系会被删除。</p>
<p class="versionadded"><span class="versionmodified">New in version 2.7.</span></p>
<p class="versionadded"> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">SubElement</tt> <big>(</big> <em>parent</em>, <em>tag</em>, <em>attrib={}</em>, <em>**extra</em> <big>)</big>
<dd>
<p>子元素工厂,创建一个Element实例并追加到已知的节点。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">tostring</tt> <big>(</big> <em>element</em>, <em>encoding="us-ascii"</em>, <em>method="xml"</em> <big>)</big>
<br>
<dd>
<p>生成一个字符串来表示表示xml的element,包括所有子元素。element是Element实例,method为"xml","html","text"。返回包含了xml数据的字符串。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">tostringlist</tt> <big>(</big> <em>element</em>, <em>encoding="us-ascii"</em>, <em>method="xml"</em> <big>)</big>
<dd>
<p>生成一个字符串来表示表示xml的element,包括所有子元素。element是Element实例,method为"xml","html","text"。返回包含了xml数据的字符串列表。</p>
<p>New in version 2.7.</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">XML</tt> <big>(</big> <em>text</em>, <em>parser=None</em> <big>)</big>
<dd>
<p>从一个字符串常量中解析出xml片段。返回Element实例。</p>
<p> </p>
</dd>
</dl>
<dl class="function"> <tt class="descclassname">xml.etree.ElementTree.</tt> <tt class="descname">XMLID</tt> <big>(</big> <em>text</em>, <em>parser=None</em> <big>)</big>
<dd>
<p>从字符串常量解析出xml片段,同时返回一个字典,用以映射element的id到其自身。</p>
</dd>
</dl>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<p>转载于:https://www.cnblogs.com/JZ-Ser/p/7219428.html</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1731023865980727296"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(人工智能,c/c++,数据库)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1835513803861749760.htm"
title="机器学习与深度学习间关系与区别" target="_blank">机器学习与深度学习间关系与区别</a>
<span class="text-muted">ℒℴѵℯ心·动ꦿ໊ོ꫞</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/1.htm">深度学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入</div>
</li>
<li><a href="/article/1835513699826233344.htm"
title="android系统selinux中添加新属性property" target="_blank">android系统selinux中添加新属性property</a>
<span class="text-muted">辉色投像</span>
<div>1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property</div>
</li>
<li><a href="/article/1835513551624695808.htm"
title="【iOS】MVC设计模式" target="_blank">【iOS】MVC设计模式</a>
<span class="text-muted">Magnetic_h</span>
<a class="tag" taget="_blank" href="/search/ios/1.htm">ios</a><a class="tag" taget="_blank" href="/search/mvc/1.htm">mvc</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a><a class="tag" taget="_blank" href="/search/objective-c/1.htm">objective-c</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/ui/1.htm">ui</a>
<div>MVC前言如何设计一个程序的结构,这是一门专门的学问,叫做"架构模式"(architecturalpattern),属于编程的方法论。MVC模式就是架构模式的一种。它是Apple官方推荐的App开发架构,也是一般开发者最先遇到、最经典的架构。MVC各层controller层Controller/ViewController/VC(控制器)负责协调Model和View,处理大部分逻辑它将数据从Mod</div>
</li>
<li><a href="/article/1835513551142350848.htm"
title="OC语言多界面传值五大方式" target="_blank">OC语言多界面传值五大方式</a>
<span class="text-muted">Magnetic_h</span>
<a class="tag" taget="_blank" href="/search/ios/1.htm">ios</a><a class="tag" taget="_blank" href="/search/ui/1.htm">ui</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/objective-c/1.htm">objective-c</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>前言在完成暑假仿写项目时,遇到了许多需要用到多界面传值的地方,这篇博客来总结一下比较常用的五种多界面传值的方式。属性传值属性传值一般用前一个界面向后一个界面传值,简单地说就是通过访问后一个视图控制器的属性来为它赋值,通过这个属性来做到从前一个界面向后一个界面传值。首先在后一个界面中定义属性@interfaceBViewController:UIViewController@propertyNSSt</div>
</li>
<li><a href="/article/1835513424734416896.htm"
title="UI学习——cell的复用和自定义cell" target="_blank">UI学习——cell的复用和自定义cell</a>
<span class="text-muted">Magnetic_h</span>
<a class="tag" taget="_blank" href="/search/ui/1.htm">ui</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a>
<div>目录cell的复用手动(非注册)自动(注册)自定义cellcell的复用在iOS开发中,单元格复用是一种提高表格(UITableView)和集合视图(UICollectionView)滚动性能的技术。当一个UITableViewCell或UICollectionViewCell首次需要显示时,如果没有可复用的单元格,则视图会创建一个新的单元格。一旦这个单元格滚动出屏幕,它就不会被销毁。相反,它被添</div>
</li>
<li><a href="/article/1835512920797179904.htm"
title="element实现动态路由+面包屑" target="_blank">element实现动态路由+面包屑</a>
<span class="text-muted">软件技术NINI</span>
<a class="tag" taget="_blank" href="/search/vue%E6%A1%88%E4%BE%8B/1.htm">vue案例</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>el-breadcrumb是ElementUI组件库中的一个面包屑导航组件,它用于显示当前页面的路径,帮助用户快速理解和导航到应用的各个部分。在Vue.js项目中,如果你已经安装了ElementUI,就可以很方便地使用el-breadcrumb组件。以下是一个基本的使用示例:安装ElementUI(如果你还没有安装的话):你可以通过npm或yarn来安装ElementUI。bash复制代码npmi</div>
</li>
<li><a href="/article/1835512542735200256.htm"
title="C语言宏函数" target="_blank">C语言宏函数</a>
<span class="text-muted">南林yan</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80/1.htm">C语言</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>一、什么是宏函数?通过宏定义的函数是宏函数。如下,编译器在预处理阶段会将Add(x,y)替换为((x)*(y))#defineAdd(x,y)((x)*(y))#defineAdd(x,y)((x)*(y))intmain(){inta=10;intb=20;intd=10;intc=Add(a+d,b)*2;cout<<c<<endl;//800return0;}二、为什么要使用宏函数使用宏函数</div>
</li>
<li><a href="/article/1835511911769272320.htm"
title="C语言如何定义宏函数?" target="_blank">C语言如何定义宏函数?</a>
<span class="text-muted">小九格物</span>
<a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参</div>
</li>
<li><a href="/article/1835511912843014144.htm"
title="理解Gunicorn:Python WSGI服务器的基石" target="_blank">理解Gunicorn:Python WSGI服务器的基石</a>
<span class="text-muted">范范0825</span>
<a class="tag" taget="_blank" href="/search/ipython/1.htm">ipython</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>理解Gunicorn:PythonWSGI服务器的基石介绍Gunicorn,全称GreenUnicorn,是一个为PythonWSGI(WebServerGatewayInterface)应用设计的高效、轻量级HTTP服务器。作为PythonWeb应用部署的常用工具,Gunicorn以其高性能和易用性著称。本文将介绍Gunicorn的基本概念、安装和配置,帮助初学者快速上手。1.什么是Gunico</div>
</li>
<li><a href="/article/1835511036317364224.htm"
title="Cell Insight | 单细胞测序技术又一新发现,可用于HIV-1和Mtb共感染个体诊断" target="_blank">Cell Insight | 单细胞测序技术又一新发现,可用于HIV-1和Mtb共感染个体诊断</a>
<span class="text-muted">尐尐呅</span>
<div>结核病是艾滋病合并其他疾病中导致患者死亡的主要原因。其中结核病由结核分枝杆菌(Mycobacteriumtuberculosis,Mtb)感染引起,获得性免疫缺陷综合症(艾滋病)由人免疫缺陷病毒(Humanimmunodeficiencyvirustype1,HIV-1)感染引起。国家感染性疾病临床医学研究中心/深圳市第三人民医院张国良团队携手深圳华大生命科学研究院吴靓团队,共同研究得出单细胞测序</div>
</li>
<li><a href="/article/1835511030260789248.htm"
title="c++ 的iostream 和 c++的stdio的区别和联系" target="_blank">c++ 的iostream 和 c++的stdio的区别和联系</a>
<span class="text-muted">黄卷青灯77</span>
<a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/iostream/1.htm">iostream</a><a class="tag" taget="_blank" href="/search/stdio/1.htm">stdio</a>
<div>在C++中,iostream和C语言的stdio.h都是用于处理输入输出的库,但它们在设计、用法和功能上有许多不同。以下是两者的区别和联系:区别1.编程风格iostream(C++风格):C++标准库中的输入输出流类库,支持面向对象的输入输出操作。典型用法是cin(输入)和cout(输出),使用>操作符来处理数据。更加类型安全,支持用户自定义类型的输入输出。#includeintmain(){in</div>
</li>
<li><a href="/article/1835509897106649088.htm"
title="Long类型前后端数据不一致" target="_blank">Long类型前后端数据不一致</a>
<span class="text-muted">igotyback</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>响应给前端的数据浏览器控制台中response中看到的Long类型的数据是正常的到前端数据不一致前后端数据类型不匹配是一个常见问题,尤其是当后端使用Java的Long类型(64位)与前端JavaScript的Number类型(最大安全整数为2^53-1,即16位)进行数据交互时,很容易出现精度丢失的问题。这是因为JavaScript中的Number类型无法安全地表示超过16位的整数。为了解决这个问</div>
</li>
<li><a href="/article/1835509769822105600.htm"
title="LocalDateTime 转 String" target="_blank">LocalDateTime 转 String</a>
<span class="text-muted">igotyback</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>importjava.time.LocalDateTime;importjava.time.format.DateTimeFormatter;publicclassMain{publicstaticvoidmain(String[]args){//获取当前时间LocalDateTimenow=LocalDateTime.now();//定义日期格式化器DateTimeFormatterformat</div>
</li>
<li><a href="/article/1835509770287673344.htm"
title="swagger访问路径" target="_blank">swagger访问路径</a>
<span class="text-muted">igotyback</span>
<a class="tag" taget="_blank" href="/search/swagger/1.htm">swagger</a>
<div>Swagger2.x版本访问地址:http://{ip}:{port}/{context-path}/swagger-ui.html{ip}是你的服务器IP地址。{port}是你的应用服务端口,通常为8080。{context-path}是你的应用上下文路径,如果应用部署在根路径下,则为空。Swagger3.x版本对于Swagger3.x版本(也称为OpenAPI3)访问地址:http://{ip</div>
</li>
<li><a href="/article/1835509770749046784.htm"
title="mysql禁用远程登录" target="_blank">mysql禁用远程登录</a>
<span class="text-muted">igotyback</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>去mysql库中的user表里,将host都改成localhost之后刷新权限FLUSHPRIVILEGES;</div>
</li>
<li><a href="/article/1835509391361667072.htm"
title="Linux下QT开发的动态库界面弹出操作(SDL2)" target="_blank">Linux下QT开发的动态库界面弹出操作(SDL2)</a>
<span class="text-muted">13jjyao</span>
<a class="tag" taget="_blank" href="/search/QT%E7%B1%BB/1.htm">QT类</a><a class="tag" taget="_blank" href="/search/qt/1.htm">qt</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/sdl2/1.htm">sdl2</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>需求:操作系统为linux,开发框架为qt,做成需带界面的qt动态库,调用方为java等非qt程序难点:调用方为java等非qt程序,也就是说调用方肯定不带QApplication::exec(),缺少了这个,QTimer等事件和QT创建的窗口将不能弹出(包括opencv也是不能弹出);这与qt调用本身qt库是有本质的区别的思路:1.调用方缺QApplication::exec(),那么我们在接口</div>
</li>
<li><a href="/article/1835508761310097408.htm"
title="店群合一模式下的社区团购新发展——结合链动 2+1 模式、AI 智能名片与 S2B2C 商城小程序源码" target="_blank">店群合一模式下的社区团购新发展——结合链动 2+1 模式、AI 智能名片与 S2B2C 商城小程序源码</a>
<span class="text-muted">说私域</span>
<a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">小程序</a>
<div>摘要:本文探讨了店群合一的社区团购平台在当今商业环境中的重要性和优势。通过分析店群合一模式如何将互联网社群与线下终端紧密结合,阐述了链动2+1模式、AI智能名片和S2B2C商城小程序源码在这一模式中的应用价值。这些创新元素的结合为社区团购带来了新的机遇,提升了用户信任感、拓展了营销渠道,并实现了线上线下的完美融合。一、引言随着互联网技术的不断发展,社区团购作为一种新兴的商业模式,在满足消费者日常需</div>
</li>
<li><a href="/article/1835508130608410624.htm"
title="html 中如何使用 uniapp 的部分方法" target="_blank">html 中如何使用 uniapp 的部分方法</a>
<span class="text-muted">某公司摸鱼前端</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/uni-app/1.htm">uni-app</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div>示例代码:Documentconsole.log(window);效果展示:好了,现在就可以uni.使用相关的方法了</div>
</li>
<li><a href="/article/1835508131032035328.htm"
title="ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)" target="_blank">ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)</a>
<span class="text-muted">研学随笔</span>
<a class="tag" taget="_blank" href="/search/arcgis/1.htm">arcgis</a><a class="tag" taget="_blank" href="/search/%E7%BB%8F%E9%AA%8C%E5%88%86%E4%BA%AB/1.htm">经验分享</a>
<div>我们在使用ArcGIS时通常经常用到栅格计算器,今天主要给大家介绍我日常中经常用到的几个公式,供大家参考学习。将特定值(-9999)赋值为0,例如-9999.Con("raster"==-9999,0,"raster")2.给空值赋予特定的值(如0)Con(IsNull("raster"),0,"raster")3.将特定的栅格值(如1)赋值为空值,其他保留原值SetNull("raster"==</div>
</li>
<li><a href="/article/1835508131489214464.htm"
title="高级编程--XML+socket练习题" target="_blank">高级编程--XML+socket练习题</a>
<span class="text-muted">masa010</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>1.北京华北2114.8万人上海华东2,500万人广州华南1292.68万人成都华西1417万人(1)使用dom4j将信息存入xml中(2)读取信息,并打印控制台(3)添加一个city节点与子节点(4)使用socketTCP协议编写服务端与客户端,客户端输入城市ID,服务器响应相应城市信息(5)使用socketTCP协议编写服务端与客户端,客户端要求用户输入city对象,服务端接收并使用dom4j</div>
</li>
<li><a href="/article/1835507626276909056.htm"
title="水平垂直居中的几种方法(总结)" target="_blank">水平垂直居中的几种方法(总结)</a>
<span class="text-muted">LJ小番茄</span>
<a class="tag" taget="_blank" href="/search/CSS_%E7%8E%84%E5%AD%A6%E8%AF%AD%E8%A8%80/1.htm">CSS_玄学语言</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a><a class="tag" taget="_blank" href="/search/css3/1.htm">css3</a>
<div>1.使用flexbox的justify-content和align-items.parent{display:flex;justify-content:center;/*水平居中*/align-items:center;/*垂直居中*/height:100vh;/*需要指定高度*/}2.使用grid的place-items:center.parent{display:grid;place-item</div>
</li>
<li><a href="/article/1835506996258893824.htm"
title="回溯 Leetcode 332 重新安排行程" target="_blank">回溯 Leetcode 332 重新安排行程</a>
<span class="text-muted">mmaerd</span>
<a class="tag" taget="_blank" href="/search/Leetcode%E5%88%B7%E9%A2%98%E5%AD%A6%E4%B9%A0%E8%AE%B0%E5%BD%95/1.htm">Leetcode刷题学习记录</a><a class="tag" taget="_blank" href="/search/leetcode/1.htm">leetcode</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E8%81%8C%E5%9C%BA%E5%92%8C%E5%8F%91%E5%B1%95/1.htm">职场和发展</a>
<div>重新安排行程Leetcode332学习记录自代码随想录给你一份航线列表tickets,其中tickets[i]=[fromi,toi]表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从JFK开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。例如,行程[“JFK”,“LGA”]与[“JFK”,“LGB</div>
</li>
<li><a href="/article/1835506868877881344.htm"
title="每日一题——第八十九题" target="_blank">每日一题——第八十九题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>题目:在字符串中找到提取数字,并统计一共找到多少整数,a123xxyu23&8889,那么找到的整数为123,23,8889//思想:#include#include#includeintmain(){charstr[]="a123xxyu23&8889";intcount=0;intnum=0;//用于临时存放当前正在构建的整数。boolinNum=false;//用于标记当前是否正在读取一个整</div>
</li>
<li><a href="/article/1835506869339254784.htm"
title="每日一题——第九十题" target="_blank">每日一题——第九十题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>题目:判断子串是否与主串匹配#include#include#include//////判断子串是否在主串中匹配//////主串///子串///boolisSubstring(constchar*str,constchar*substr){intlenstr=strlen(str);//计算主串的长度intlenSub=strlen(substr);//计算子串的长度//遍历主字符串,对每个可能得</div>
</li>
<li><a href="/article/1835506616166871040.htm"
title="每日一题——第八十一题" target="_blank">每日一题——第八十一题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>打印如下图案:#includeintmain(){inti,j;charch='A';for(i=1;i<5;i++,ch++){for(j=0;j<5-i;j++){printf("");//控制空格输出}for(j=1;j<2*i;j++)//条件j<2*i{printf("%c",ch);//控制字符输出}printf("\n");}return0;}</div>
</li>
<li><a href="/article/1835506616682770432.htm"
title="每日一题——第八十四题" target="_blank">每日一题——第八十四题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>题目:编写函数1、输入10个职工的姓名和职工号2、按照职工由大到小顺序排列,姓名顺序也随之调整3、要求输入一个职工号,用折半查找法找出该职工的姓名#define_CRT_SECURE_NO_WARNINGS#include#include#defineMAX_EMPLOYEES10typedefstruct{intid;charname[50];}Empolyee;voidinputEmploye</div>
</li>
<li><a href="/article/1835506489377255424.htm"
title="每日一题——第八十二题" target="_blank">每日一题——第八十二题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>题目:将一个控制台输入的字符串中的所有元音字母复制到另一字符串中#include#include#include#include#defineMAX_INPUT1024boolisVowel(charp);intmain(){charinput[MAX_INPUT];charoutput[MAX_INPUT];printf("请输入一串字符串:\n");fgets(input,sizeof(inp</div>
</li>
<li><a href="/article/1835506489817657344.htm"
title="每日一题——第八十三题" target="_blank">每日一题——第八十三题</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/C%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E6%AF%8F%E6%97%A5%E4%B8%80%E7%BB%83/1.htm">C语言程序设计每日一练</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>题目:将输入的整形数字输出,输出1990,输出"1990"#include#defineMAX_INPUT1024intmain(){intarrr_num[MAX_INPUT];intnum,i=0;printf("请输入一个数字:");scanf_s("%d",&num);while(num!=0){arrr_num[i++]=num%10;num/=10;}printf("\"");for(</div>
</li>
<li><a href="/article/1835506236842405888.htm"
title="C#中使用split分割字符串" target="_blank">C#中使用split分割字符串</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/c%23/1.htm">c#</a>
<div>1、用字符串分隔:usingSystem.Text.RegularExpressions;stringstr="aaajsbbbjsccc";string[]sArray=Regex.Split(str,"js",RegexOptions.IgnoreCase);foreach(stringiinsArray)Response.Write(i.ToString()+"");输出结果:aaabbbc</div>
</li>
<li><a href="/article/1835506237316362240.htm"
title="WPF中的ComboBox控件几种数据绑定的方式" target="_blank">WPF中的ComboBox控件几种数据绑定的方式</a>
<span class="text-muted">互联网打工人no1</span>
<a class="tag" taget="_blank" href="/search/wpf/1.htm">wpf</a><a class="tag" taget="_blank" href="/search/c%23/1.htm">c#</a>
<div>一、用字典给ItemsSource赋值(此绑定用的地方很多,建议熟练掌握)在XMAL中:在CS文件中privatevoidBindData(){DictionarydicItem=newDictionary();dicItem.add(1,"北京");dicItem.add(2,"上海");dicItem.add(3,"广州");cmb_list.ItemsSource=dicItem;cmb_l</div>
</li>
<li><a href="/article/80.htm"
title="java杨辉三角" target="_blank">java杨辉三角</a>
<span class="text-muted">3213213333332132</span>
<a class="tag" taget="_blank" href="/search/java%E5%9F%BA%E7%A1%80/1.htm">java基础</a>
<div>
package com.algorithm;
/**
* @Description 杨辉三角
* @author FuJianyong
* 2015-1-22上午10:10:59
*/
public class YangHui {
public static void main(String[] args) {
//初始化二维数组长度
int[][] y</div>
</li>
<li><a href="/article/207.htm"
title="《大话重构》之大布局的辛酸历史" target="_blank">《大话重构》之大布局的辛酸历史</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/%E9%87%8D%E6%9E%84/1.htm">重构</a>
<div>《大话重构》中提到“大布局你伤不起”,如果企图重构一个陈旧的大型系统是有非常大的风险,重构不是想象中那么简单。我目前所在公司正好对产品做了一次“大布局重构”,下面我就分享这个“大布局”项目经验给大家。
背景
公司专注于企业级管理产品软件,企业有大中小之分,在2000年初公司用JSP/Servlet开发了一套针对中</div>
</li>
<li><a href="/article/334.htm"
title="电驴链接在线视频播放源码" target="_blank">电驴链接在线视频播放源码</a>
<span class="text-muted">dubinwei</span>
<a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81/1.htm">源码</a><a class="tag" taget="_blank" href="/search/%E7%94%B5%E9%A9%B4/1.htm">电驴</a><a class="tag" taget="_blank" href="/search/%E6%92%AD%E6%94%BE%E5%99%A8/1.htm">播放器</a><a class="tag" taget="_blank" href="/search/%E8%A7%86%E9%A2%91/1.htm">视频</a><a class="tag" taget="_blank" href="/search/ed2k/1.htm">ed2k</a>
<div>本项目是个搜索电驴(ed2k)链接的应用,借助于磁力视频播放器(官网:
http://loveandroid.duapp.com/ 开放平台),可以实现在线播放视频,也可以用迅雷或者其他下载工具下载。
项目源码:
http://git.oschina.net/svo/Emule,动态更新。也可从附件中下载。
项目源码依赖于两个库项目,库项目一链接:
http://git.oschina.</div>
</li>
<li><a href="/article/461.htm"
title="Javascript中函数的toString()方法" target="_blank">Javascript中函数的toString()方法</a>
<span class="text-muted">周凡杨</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/js/1.htm">js</a><a class="tag" taget="_blank" href="/search/toString/1.htm">toString</a><a class="tag" taget="_blank" href="/search/function/1.htm">function</a><a class="tag" taget="_blank" href="/search/object/1.htm">object</a>
<div>简述
The toString() method returns a string representing the source code of the function.
简译之,Javascript的toString()方法返回一个代表函数源代码的字符串。
句法
function.</div>
</li>
<li><a href="/article/588.htm"
title="struts处理自定义异常" target="_blank">struts处理自定义异常</a>
<span class="text-muted">g21121</span>
<a class="tag" taget="_blank" href="/search/struts/1.htm">struts</a>
<div>很多时候我们会用到自定义异常来表示特定的错误情况,自定义异常比较简单,只要分清是运行时异常还是非运行时异常即可,运行时异常不需要捕获,继承自RuntimeException,是由容器自己抛出,例如空指针异常。
非运行时异常继承自Exception,在抛出后需要捕获,例如文件未找到异常。
此处我们用的是非运行时异常,首先定义一个异常LoginException:
/**
* 类描述:登录相</div>
</li>
<li><a href="/article/715.htm"
title="Linux中find常见用法示例" target="_blank">Linux中find常见用法示例</a>
<span class="text-muted">510888780</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>Linux中find常见用法示例
·find path -option [ -print ] [ -exec -ok command ] {} \;
find命令的参数;</div>
</li>
<li><a href="/article/842.htm"
title="SpringMVC的各种参数绑定方式" target="_blank">SpringMVC的各种参数绑定方式</a>
<span class="text-muted">Harry642</span>
<a class="tag" taget="_blank" href="/search/springMVC/1.htm">springMVC</a><a class="tag" taget="_blank" href="/search/%E7%BB%91%E5%AE%9A/1.htm">绑定</a><a class="tag" taget="_blank" href="/search/%E8%A1%A8%E5%8D%95/1.htm">表单</a>
<div>1. 基本数据类型(以int为例,其他类似):
Controller代码:
@RequestMapping("saysth.do")
public void test(int count) {
}
表单代码:
<form action="saysth.do" method="post&q</div>
</li>
<li><a href="/article/969.htm"
title="Java 获取Oracle ROWID" target="_blank">Java 获取Oracle ROWID</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a>
<div>
A ROWID is an identification tag unique for each row of an Oracle Database table. The ROWID can be thought of as a virtual column, containing the ID for each row.
The oracle.sql.ROWID class i</div>
</li>
<li><a href="/article/1096.htm"
title="java获取方法的参数名" target="_blank">java获取方法的参数名</a>
<span class="text-muted">antlove</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a><a class="tag" taget="_blank" href="/search/parameter/1.htm">parameter</a><a class="tag" taget="_blank" href="/search/method/1.htm">method</a><a class="tag" taget="_blank" href="/search/reflect/1.htm">reflect</a>
<div>reflect.ClassInformationUtil.java
package reflect;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtMethod;
import javassist.Modifier;
import javassist.bytecode.CodeAtt</div>
</li>
<li><a href="/article/1223.htm"
title="JAVA正则表达式匹配 查找 替换 提取操作" target="_blank">JAVA正则表达式匹配 查找 替换 提取操作</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1.htm">正则表达式</a><a class="tag" taget="_blank" href="/search/%E6%9B%BF%E6%8D%A2/1.htm">替换</a><a class="tag" taget="_blank" href="/search/%E6%8F%90%E5%8F%96/1.htm">提取</a><a class="tag" taget="_blank" href="/search/%E6%9F%A5%E6%89%BE/1.htm">查找</a>
<div>正则表达式的查找;主要是用到String类中的split();
String str;
str.split();方法中传入按照什么规则截取,返回一个String数组
常见的截取规则:
str.split("\\.")按照.来截取
str.</div>
</li>
<li><a href="/article/1350.htm"
title="Java中equals()与hashCode()方法详解" target="_blank">Java中equals()与hashCode()方法详解</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/set/1.htm">set</a><a class="tag" taget="_blank" href="/search/equals%28%29/1.htm">equals()</a><a class="tag" taget="_blank" href="/search/hashCode%28%29/1.htm">hashCode()</a>
<div>一.equals()方法详解
equals()方法在object类中定义如下:
public boolean equals(Object obj) {
return (this == obj);
}
很明显是对两个对象的地址值进行的比较(即比较引用是否相同)。但是我们知道,String 、Math、I</div>
</li>
<li><a href="/article/1477.htm"
title="精通Oracle10编程SQL(4)使用SQL语句" target="_blank">精通Oracle10编程SQL(4)使用SQL语句</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/plsql/1.htm">plsql</a>
<div>--工资级别表
create table SALGRADE
(
GRADE NUMBER(10),
LOSAL NUMBER(10,2),
HISAL NUMBER(10,2)
)
insert into SALGRADE values(1,0,100);
insert into SALGRADE values(2,100,200);
inser</div>
</li>
<li><a href="/article/1604.htm"
title="【Nginx二】Nginx作为静态文件HTTP服务器" target="_blank">【Nginx二】Nginx作为静态文件HTTP服务器</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/HTTP%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">HTTP服务器</a>
<div> Nginx作为静态文件HTTP服务器
在本地系统中创建/data/www目录,存放html文件(包括index.html)
创建/data/images目录,存放imags图片
在主配置文件中添加http指令
http {
server {
listen 80;
server_name </div>
</li>
<li><a href="/article/1731.htm"
title="kafka获得最新partition offset" target="_blank">kafka获得最新partition offset</a>
<span class="text-muted">blackproof</span>
<a class="tag" taget="_blank" href="/search/kafka/1.htm">kafka</a><a class="tag" taget="_blank" href="/search/partition/1.htm">partition</a><a class="tag" taget="_blank" href="/search/offset/1.htm">offset</a><a class="tag" taget="_blank" href="/search/%E6%9C%80%E6%96%B0/1.htm">最新</a>
<div>kafka获得partition下标,需要用到kafka的simpleconsumer
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.</div>
</li>
<li><a href="/article/1858.htm"
title="centos 7安装docker两种方式" target="_blank">centos 7安装docker两种方式</a>
<span class="text-muted">ronin47</span>
<div> 第一种是采用yum 方式
yum install -y docker
</div>
</li>
<li><a href="/article/1985.htm"
title="java-60-在O(1)时间删除链表结点" target="_blank">java-60-在O(1)时间删除链表结点</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
public class DeleteNode_O1_Time {
/**
* Q 60 在O(1)时间删除链表结点
* 给定链表的头指针和一个结点指针(!!),在O(1)时间删除该结点
*
* Assume the list is:
* head->...->nodeToDelete->mNode->nNode->..</div>
</li>
<li><a href="/article/2112.htm"
title="nginx利用proxy_cache来缓存文件" target="_blank">nginx利用proxy_cache来缓存文件</a>
<span class="text-muted">cfyme</span>
<a class="tag" taget="_blank" href="/search/cache/1.htm">cache</a>
<div>user zhangy users;
worker_processes 10;
error_log /var/vlogs/nginx_error.log crit;
pid /var/vlogs/nginx.pid;
#Specifies the value for ma</div>
</li>
<li><a href="/article/2239.htm"
title="[JWFD开源工作流]JWFD嵌入式语法分析器负号的使用问题" target="_blank">[JWFD开源工作流]JWFD嵌入式语法分析器负号的使用问题</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E5%B5%8C%E5%85%A5%E5%BC%8F/1.htm">嵌入式</a>
<div>
假如我们需要用JWFD的语法分析模块定义一个带负号的方程式,直接在方程式之前添加负号是不正确的,而必须这样做:
string str01 = "a=3.14;b=2.71;c=0;c-((a*a)+(b*b))"
定义一个0整数c,然后用这个整数c去</div>
</li>
<li><a href="/article/2366.htm"
title="如何集成支付宝官方文档" target="_blank">如何集成支付宝官方文档</a>
<span class="text-muted">dai_lm</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a>
<div>官方文档下载地址
https://b.alipay.com/order/productDetail.htm?productId=2012120700377310&tabId=4#ps-tabinfo-hash
集成的必要条件
1. 需要有自己的Server接收支付宝的消息
2. 需要先制作app,然后提交支付宝审核,通过后才能集成
调试的时候估计会真的扣款,请注意
</div>
</li>
<li><a href="/article/2493.htm"
title="应该在什么时候使用Hadoop" target="_blank">应该在什么时候使用Hadoop</a>
<span class="text-muted">datamachine</span>
<a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a>
<div>原帖地址:http://blog.chinaunix.net/uid-301743-id-3925358.html
存档,某些观点与我不谋而合,过度技术化不可取,且hadoop并非万能。
--------------------------------------------万能的分割线--------------------------------
有人问我,“你在大数据和Hado</div>
</li>
<li><a href="/article/2620.htm"
title="在GridView中对于有外键的字段使用关联模型进行搜索和排序" target="_blank">在GridView中对于有外键的字段使用关联模型进行搜索和排序</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/yii/1.htm">yii</a>
<div>在GridView中使用关联模型进行搜索和排序
首先我们有两个模型它们直接有关联:
class Author extends CActiveRecord {
...
}
class Post extends CActiveRecord {
...
function relations() {
return array(
'</div>
</li>
<li><a href="/article/2747.htm"
title="使用NSString 的格式化大全" target="_blank">使用NSString 的格式化大全</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/Objective-C/1.htm">Objective-C</a>
<div>格式定义The format specifiers supported by the NSString formatting methods and CFString formatting functions follow the IEEE printf specification; the specifiers are summarized in Table 1. Note that you c</div>
</li>
<li><a href="/article/2874.htm"
title="使用activeX插件对象object滚动有重影" target="_blank">使用activeX插件对象object滚动有重影</a>
<span class="text-muted">蕃薯耀</span>
<a class="tag" taget="_blank" href="/search/activeX%E6%8F%92%E4%BB%B6/1.htm">activeX插件</a><a class="tag" taget="_blank" href="/search/%E6%BB%9A%E5%8A%A8%E6%9C%89%E9%87%8D%E5%BD%B1/1.htm">滚动有重影</a>
<div>
使用activeX插件对象object滚动有重影 <object style="width:0;" id="abc" classid="CLSID:D3E3970F-2927-9680-BBB4-5D0889909DF6" codebase="activex/OAX339.CAB#</div>
</li>
<li><a href="/article/3001.htm"
title="SpringMVC4零配置" target="_blank">SpringMVC4零配置</a>
<span class="text-muted">hanqunfeng</span>
<a class="tag" taget="_blank" href="/search/springmvc4/1.htm">springmvc4</a>
<div>基于Servlet3.0规范和SpringMVC4注解式配置方式,实现零xml配置,弄了个小demo,供交流讨论。
项目说明如下:
1.db.sql是项目中用到的表,数据库使用的是oracle11g
2.该项目使用mvn进行管理,私服为自搭建nexus,项目只用到一个第三方 jar,就是oracle的驱动;
3.默认项目为零配置启动,如果需要更改启动方式,请</div>
</li>
<li><a href="/article/3128.htm"
title="《开源框架那点事儿16》:缓存相关代码的演变" target="_blank">《开源框架那点事儿16》:缓存相关代码的演变</a>
<span class="text-muted">j2eetop</span>
<a class="tag" taget="_blank" href="/search/%E5%BC%80%E6%BA%90%E6%A1%86%E6%9E%B6/1.htm">开源框架</a>
<div>问题引入
上次我参与某个大型项目的优化工作,由于系统要求有比较高的TPS,因此就免不了要使用缓冲。
该项目中用的缓冲比较多,有MemCache,有Redis,有的还需要提供二级缓冲,也就是说应用服务器这层也可以设置一些缓冲。
当然去看相关实现代代码的时候,大致是下面的样子。
[java]
view plain
copy
print
?
public vo</div>
</li>
<li><a href="/article/3255.htm"
title="AngularJS浅析" target="_blank">AngularJS浅析</a>
<span class="text-muted">kvhur</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>概念
AngularJS is a structural framework for dynamic web apps.
了解更多详情请见原文链接:http://www.gbtags.com/gb/share/5726.htm
Directive
扩展html,给html添加声明语句,以便实现自己的需求。对于页面中html元素以ng为前缀的属性名称,ng是angular的命名空间</div>
</li>
<li><a href="/article/3382.htm"
title="架构师之jdk的bug排查(一)---------------split的点号陷阱" target="_blank">架构师之jdk的bug排查(一)---------------split的点号陷阱</a>
<span class="text-muted">nannan408</span>
<a class="tag" taget="_blank" href="/search/split/1.htm">split</a>
<div>1.前言.
jdk1.6的lang包的split方法是有bug的,它不能有效识别A.b.c这种类型,导致截取长度始终是0.而对于其他字符,则无此问题.不知道官方有没有修复这个bug.
2.代码
String[] paths = "object.object2.prop11".split("'");
System.ou</div>
</li>
<li><a href="/article/3509.htm"
title="如何对10亿数据量级的mongoDB作高效的全表扫描" target="_blank">如何对10亿数据量级的mongoDB作高效的全表扫描</a>
<span class="text-muted">quentinXXZ</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a>
<div> 本文链接:
http://quentinXXZ.iteye.com/blog/2149440
一、正常情况下,不应该有这种需求
首先,大家应该有个概念,标题中的这个问题,在大多情况下是一个伪命题,不应该被提出来。要知道,对于一般较大数据量的数据库,全表查询,这种操作一般情况下是不应该出现的,在做正常查询的时候,如果是范围查询,你至少应该要加上limit。
说一下,</div>
</li>
<li><a href="/article/3636.htm"
title="C语言算法之水仙花数" target="_blank">C语言算法之水仙花数</a>
<span class="text-muted">qiufeihu</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a>
<div>/**
* 水仙花数
*/
#include <stdio.h>
#define N 10
int main()
{
int x,y,z;
for(x=1;x<=N;x++)
for(y=0;y<=N;y++)
for(z=0;z<=N;z++)
if(x*100+y*10+z == x*x*x</div>
</li>
<li><a href="/article/3763.htm"
title="JSP指令" target="_blank">JSP指令</a>
<span class="text-muted">wyzuomumu</span>
<a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a>
<div>
jsp指令的一般语法格式: <%@ 指令名 属性 =”值 ” %>
常用的三种指令: page,include,taglib
page指令语法形式: <%@ page 属性 1=”值 1” 属性 2=”值 2”%>
include指令语法形式: <%@include file=”relative url”%> (jsp可以通过 include</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>