数据库知识汇总(适合初学者)
数据库知识汇总
- 前言
- 一、数据库相关概念
-
- 1、数据库
- 2、数据库管理系统
- 3、SQL
- 4、数据模型
- 5、通用语法
- 二、增删改查对应语法
-
- 1、DDL(Data Definition Language)数据定义语言
-
- a)数据类型
- b)字符串类型
- c)日期类型
- 1>创建
-
- 数据库创建
- 表创建
- 2>删除
-
- 数据库删除
- 表删除
- 删除指定表,并重新创建该表
- 3>修改
- 4>表查询
- 2、DML(Data Manipulation Language)数据操作语言
- 3、DQL(Data Query Language)数据查询语言
-
- 语法
-
- 条件查询
- 聚合函数
- 分组查询
- 排序查询
- 分页查询
- 4、DCL(Data Control Language)数据控制语言
-
- 1、 查询用户
- 2、 创建用户
- 3、 修改用户密码
- 4、 删除用户
- DCL权限控制
-
- 1、 查询权限
- 2、 授予权限
- 3、 撤销权限
- 三、数据库连接池的应用以及代码实现(德鲁伊数据库)
-
- 1、概念
- 2、好处
- 3、实现
-
- 1、 标准接口:DataSource
- 步骤:
- 定义工具类
前言
这阶段学习计划也进入到了尾声,从刚开始学java到现在还没像这阶段一样这么忙过,花两天学的SQL语句过几天又忘完了,刚好趁这次写博客把学习的数据库相关知识总结总结顺便复习一下。
一、数据库相关概念
1、数据库
存储数据的仓库,数据是有组织的进行存储
英文:DataBase,简称DB
2、数据库管理系统
管理数据库的大型软件
英文:DataBase Management System 简称DBMS
3、SQL
英文:Structured Query Language,简称SQL,结构化查询语言
操作关系型数据库的编程语言
定义操作所有关系型数据库的统一标准
什么是关系型数据库呢?
简单理解就是关系型数据库里的数据使用一张表格来表示的,而非关系型数据库可能使用文档,图片等类型表示数据
4、数据模型
一个服务器中可以创建多个数据库,一个数据库中可以创建多个表

5、通用语法
SQL语句可以单行或多行书写,以分号结尾
SQL语句可以使用空格、缩进来增强语句的可读性
MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
注释:
单行注释:–注释内容或者#注释内容(MySQL特有)
多行注释:/注释内容/
二、增删改查对应语法
1、DDL(Data Definition Language)数据定义语言
a)数据类型
| 类型 | 大小 |
|---|---|
| TINYINT | byte |
| SMALLINT | short |
| MEDIUMINT | char |
| INT 或 INTEGER | int |
| BIGINT | long |
| FLOAT | float |
| DOUBLE | double |
| DECIMAL | 依赖于M和D的值,精确定点数 |
b)字符串类型
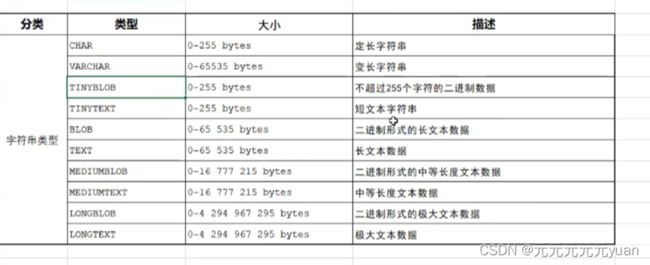
c)日期类型
| 类型 | 描述 | 格式 |
|---|---|---|
| DATE | 日期值 | YYYY-MM-DD |
| TIME | 时间值或持续时间 | HH:MM:SS |
| YEAR | 年份值 | YYYY |
| DATETIME | 混合日期和时间值 | YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | 混合日期和时间值,时间戳 | YYYY-MM-DD HH:MM:SS |
1>创建
数据库创建
CREAT DATAVASE[IF NOT EXISTS]数据库名[DEFAULT CHARSET 字符集][COLLATE 排序规则];
表创建
CREATE TABLE 表名(
字段1 字段1类型[COMMENT 字段1注释],
字段2 字段2类型[COMMENT 字段2注释],
字段3 字段3类型[COMMENT 字段3注释],
……
字段n 字段n类型[COMMENT 字段n注释]
)[COMMENT 表注释];
Ps:……为可选参数,最后一个字段没有逗号
2>删除
数据库删除
DROP DATABASE[IF EXISTS] 数据库名;
表删除
DROP TABLE[IF EXISTS] 表名;
删除指定表,并重新创建该表
TRUNCATE TABLE 表名;
3>修改
| 作用 | 代码 |
|---|---|
| 添加字段 | ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释][约束]; |
| 修改数据类型 | ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度); |
| 修改字段名和字段类型 | ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度)[COMMENT 注释][约束]; |
| 删除字段 | ALTER TABLE 表名 DROP字段名; |
| 修改表名 | ALTER TABLE 表名 RENAME TO 新表名; |
4>表查询
| 作用 | 代码 |
|---|---|
| 查询当前数据库的所有表 | SHOW TABLES; |
| 查询表结构 | DESC 表名; |
| 查询指定表的建表语句 | SHOW CREATE TABLE 表名 |
2、DML(Data Manipulation Language)数据操作语言
DML的主要作用是修改数据,添加数据,删除数据
| 作用 | 代码 |
|---|---|
| 给指定字段添加数据 | INSERT INTO 表名(字段名1,字段名2,……) VALUES(值1,值2,……); |
| 给全部字段添加数据 | INSERT INTO 表名 VALUES(值1,值2,……); |
| 批量添加数据 | INSERT INTO 表名(字段名1,字段名2,……) VALUES(值1,值2,……),(值1,值2,……),……;or INSERT INTO 表名 VALUES(值1,值2,……),(值1,值2,……),(值1,值2,……); |
| 修改数据 | UPDATE 表名 SET 字段名1 = 值1,字段名2 = 值2,……[WHERE 条件]; |
| 删除数据 | DELETE FROM 表名[WHRER 条件]; |
注意:
插入数据时,指定的字段顺序需要与值一一对应
字符串和日期型数据应该包含在引号中
插入的数据大小,应该在字段的规定范围内
注意:
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据
3、DQL(Data Query Language)数据查询语言
语法
SELECT
字段列表
FROM
表名列表
WHRER
条件列表
GROUP BY
分组字段列表
HAVNG
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
条件查询
1、 语法
SELECT 字段列表 FROM 表名 WHRER 条件列表;
2、条件
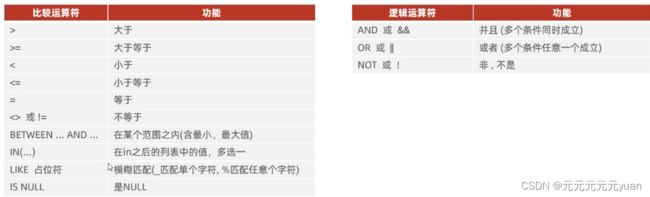
聚合函数
1、 介绍
将一列数据作为一个整体进行纵向计算
2、常见聚合函数
| Count | 统计数量 |
| Max | 最大值 |
| Min | 最小值 |
| Avg | 平均值 |
| Sum | 求和 |
3、 语法
SELECT 聚合函数(字段列表)FROM 表名;
分组查询
1、 语法
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];
Where 与 having区别
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组,;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以
注意:
执行顺序:where>聚合函数>having
分组之后,查询的字段一般是聚合函数和分组字段,查询其他字段无任何意义
排序查询
1、 语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1,字段2,排序方式2;
2、 排序方式
ASC:升序(默认值)
DESC:降序
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段排序
分页查询
1、 语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;
注意
起始索引从0开始,起始索引 = (查询页码-1)* 每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,mysql中是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写为limit10.
执行顺序
FROM->WHERE->GROUP BY->SELECT->HAVING->LIMIT
4、DCL(Data Control Language)数据控制语言
用来管理数据库用户,控制数据库的访问权限
1、 查询用户
USE mysql;
SELECT * FROM user;
2、 创建用户
CREATE USER ‘用户名’@’主机名’ IDENTIFIED BY ‘密码’;
3、 修改用户密码
ALTER USER ‘用户名’@’主机名’ IDENTIFIED WITH mysql_native_password BY ‘新密码’;
4、 删除用户
DROP USER’用户名’@’主机名’;
注意
主机名可以使用%通配
这类SQL开发人员操作的比较少,主要是DBA(数据库管理员)使用。
DCL权限控制

1、 查询权限
SHOW GRANTS FOR ’用户名’@’主机名’;
2、 授予权限
GRANT 权限列表 ON 数据库名,表名 TO ‘用户名’@‘主机名’;
3、 撤销权限
REVOKE 权限列表 ON 数据库名,表名 FROM ‘用户名’@‘主机名’;
注意
多个权限之间,使用逗号分隔
授权时,数据库名和表名可以使用*代表所有
PS:函数部分还有很多函数笔者没有写出,在此不作过多赘述,有兴趣的小伙伴可以自行搜索资源进行学习
三、数据库连接池的应用以及代码实现(德鲁伊数据库)
1、概念
容器(集合),存放数据库连接的容器。
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
2、好处
节约资源,用户访问更加高效
3、实现
1、 标准接口:DataSource
a) 方法:
i. 获取链接:getConnection()
ii. 归还链接:如果连接对象是Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了,而是归还链接
2、 一般我们不去实现它,由数据库厂商实现
Druid:数据库连接池实现技术,由阿里巴巴提供的
步骤:
1、 导入jar包
2、 定义配置文件:
a) 是propertise格式的
b) 可以叫任意名称,可以放在任意目录下
3、 加载配置文件
4、 获取数据库连接池对象:通过工厂来获取 DruidDataSourceFactory
5、获取链接:getConnection
定义工具类
1、 定义一个类JDBCUtils
2、 提供静态代码块加载配置文件,初始化连接池对象
3、 提供方法
a) 获取连接方法:通过数据库连接池获取链接
b) 释放资源
c) 获取连接池的方法
package util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCUtils {
private static DataSource ds;
static{
//加载配置文件,初始化连接池
Properties properties = new Properties();
InputStream ips = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties");
try {
properties.load(ips);
} catch (IOException e) {
e.printStackTrace();
}
//初始化连接池对象
try {
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static DataSource getDs(){
return ds;
}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
}
以上是我写的一个工具类,其中properties配置文件的格式如下
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///longindemo
username=root
password=123456yyj
initialSize=5
maxActive=10
maxWait=3000
(完)