《地理信息系统原理》笔记/期末复习资料(8. 数字高程模型)
目录
8. 数字高程模型
8.1 概述
8.1.1 数字高程模型概念
8.1.2 数字高程模型特点
8.2 DEM数据分布特征
8.2.1 格网状数据
8.2.2 离散数据
8.3 DEM的表示方法
8.3.1 数学方法
8.3.2 图形方法
8.3.3 DEM三维表达方法
8.4 TIN的生成方法
8.4.1 人工方法
8.4.2 程序自动建立
8.5 Grid的生成
8.5.1 网格化插值计算
8.5.2 网格尺寸的确定
8.5.3 空间插值方法
8.5.4 几种典型数据网格化插值方法选择
8.6 DEM的数据源和采样方法
8.7 DEM的应用
8.7.1 DEM的主要用途
8.7.2 DEM的应用
8.8 DEM分析的误差与精度
8.8.1 DEM的误差研究概况
8.8.2 DEM的误差来源
8.8.3 DEM的误差分析
8.8.4 DEM的误差评价模型
8.9 习题
8. 数字高程模型
8.1 概述
8.1.1 数字高程模型概念
与土地利用、土壤分级、地质单元划分等不同,地球表面高低起伏,呈现一种连续变化的曲面,这种曲面是无法用平面地图来确切表示。因此,用一种既方便又准确的方法来表达实际的地表现象。随着计算机数据处理能力的提高,自动测量仪器的广泛使用以及制图技术的发展,一种全新的数字描述地球表面的方法普遍被采用,这就是数字高程模型(Digital Elevation Model),简称DEM,它是以数字的形式按一定结构组织在一起,表示实际地形特征空间分布的实体地面模型数字模型,也是地形形状大小和起伏的数字描述。DEM的核心是地形表面特征点的三维坐标数据和一套对地表提供连续描述的算法,最基本的DEM是由一系列地面点x,y位置及其相联系的高程Z所组成,用数学函数式的表达是:Z= f(x,y),(x,y)∈DEM所在的区域。
尽管DEM是为了模拟地面起伏而发展起来的,但也可以用来模拟其它二维表面上连续变化的特征,比如说还可以表示地面景观的属性,地面温度、降水、地球磁力、重力、土地利用、土壤类型等其它地面特性信息,此时的DEM也称为数字地形模型(Digital Terrain Models),简称DTM。关于DTM和DEM的含义,无论在国外或国内文献中都存在着不同的理解,DTM包含着地面起伏和属性两个含义,所以DEM和DTM是有区别的。
另外,自从DTM的概念被提出以后,又相继出现了许多其他相近的术语。如在德国使用的DHM(Digital Height Model)、英国使用的DGM(Digital Ground Model)、美国地质测量局US―GS使用的DTEM(Digital Terrain Elevation Model)、DEM(Digital Elevation Model)等。这些术语在使用上可能有些限制,但实质上差别很小。当然,DTM趋向于表达比DEM和DHM具有更广意义的内容。
8.1.2 数字高程模型特点
与传统地形图比较,DEM作为地形表面的一种数字表达形式有如下特点:
1. 易以多种形式显示地形信息。地形数据经过计算机软件处理后,能产生多种比例尺的地形图、纵横断面图和立体图,而常规地形图一经制作完成后,比例尺不容易改变,如需改变或者要绘制其他形式的地形图,则需要人工处理,工作量大。
2. 精度不会损失。常规地图随着时间的椎移,图纸将会变形,失掉原有的精度,DEM采用数字媒介而能保持精度不变。另外,由常规的地图用人工的方法制作其他种类的图,精度会受到损失。而由DEM直接输出,精度可得到控制。
3. 容易实现自动化、实时化。常规地图信息的增加和修改都必须重复相同的工序,劳动强度大而且周期长,不利于地图的实时更新,而DEM由于是数字形式的,所以增加或改变地形信息只得将修改信息直接输入到计算机,经软件处理后即可产生实时化的各种地形图。
4. 具有多比例尺特性。如1m分辨率的DEM自动涵盖了更小分辨率如10m和100m的DEM内容。
8.2 DEM数据分布特征
DEM数据由于数据观则方法和获得途径不同,数据分布规律、数据特征有明显的差异,DEM数据按其空间分布特征可分成两类:格网状数据和离散数据。
8.2.1 格网状数据
把DEM覆盖区划分成为规则格网,每个网格大小和形状都相同,用相应矩阵元素的行列号来实现网格点的二维地理空间定位,第三维为特性值,可以是高程和属性。网格大小代表数据精度,例如地质勘探可在小范围内布置规则格网测点,使用仪器测定重力或磁场强度等数据。对于规则网来说,仅用z的矩阵数据来描述地理场,其对应的平面坐标位置数据蕴含在向量序列关系之中,n个数据观测点的数据记录个数也为n,用公式表示如下: DEM={zij},其中i=1,2,3,・・・,m-1;j=1,2,3,・・・,n-1。格网DEM数据不仅数据量小而且便于管理和检索,更适合于分析处理。
 DEM数据分布
DEM数据分布
8.2.2 离散数据
由于受观测手段的限制,无法得到所有地理位置上观测场值,一般也不可能按规则网获取数据,离散数据DEM的平面二维地理空间定位由不规则分布的离散样点平面坐标实现,第三维仍为高程和属性特性值。例如人工地震勘探则通常布设多条测线读取有关地层结构的数据;航测一般沿测线观测,沿测线的测点密度远大于测线间隔的密度,并且测线也并不是等间距的直线;分散流数据常按一定的采样密度沿水系随机采样;更多的数据,如气象、水文以及其它地理抽样调查等呈不规则分布。每个离散数据的记录必须使用三项数据,分别记录其坐标值x,y和特性值z,这样,n个离散数据点的数据记录个数为3n个。
8.3 DEM的表示方法
 DEM的表示方法
DEM的表示方法
8.3.1 数学方法
数学方法拟合表面时需依靠连续三维函数,连续的三维函数能以高平滑度表示复杂表面。局部拟合法将复杂表面分成正方形象元,或面积大致相等的不规则形状的小块,而小块内的点观测值与表面匹配。尽管在小块的边缘,表面坡度不一定都是连续变化的,还是应使用加权函数来保证小块接边处的匹配。分块近似数学函数不太适合于制图,图9-3为分块法绘制的等高线图,其中可清晰地看出块间连续时漏掉了一些数据。但分块模拟广泛应用于复杂表面模拟的机助设计系统,已用于地下水、土壤特征或其它环境数据的表面内插。
 分块法绘制的等高线图
分块法绘制的等高线图
8.3.2 图形方法
1. 线模式――等高线
表示地形的最普通线模式是一系列描述高程测量曲线的等高线。剖面通常是坡度分析、正射影象制作和块状图生成等必须使用的派生产品。由于现有的地图大多数都绘有等高线,这些地图便是数字地面模型的现成数据源,用扫描仪在这些图上自动获取DEM数据方面已取得了很大进展。但数字化现有等高线产生的DEM比直接利用航空摄影测量方法产生的DEM数据质量差(Yoeli 1982)。而且数字等高线并不适合于坡度计算和制作晕渲地图,于是常将数字等高线转换成离散高程矩阵之类的点模式(见后面)。Ceruti(1980)和Yoeli(1984)阐述了将等高线内插成为高程矩阵的计算方法。Oswald和Raetzsch(1984)阐述了从一组表示等高线多边形产生高程矩阵的处理系统,此处所指的等高线是人工或栅格扫描仪数字化现有等高线加上谷底和山脊线组成的数字等高线。该系统就是有名的“格拉茨(Graz)地面模型”系统,该系统被认为是数字等高线转换成高程矩阵的现代化系统的代表。
格拉茨地面模型产生高程短阵的步骤是:将象元尺寸适合的格网复盖在包含山脊线、谷底线的等高线数字图象上,凡是位于或接近某一等高线的象元都将该等高线的高程值分配为这些象元的高程值,其它象元则分配-1。获得-1值的象元又按下述步骤分配高程值,即在栅格数据库的矩阵子集(或窗口)中进行内插。内插工作通常沿4条定向线搜索,即东西、南北、东南西北、东北西南等。内插时按已分配高程的象元高差的简单函数计算窗口内的局部最大坡度。然后将各窗口内的坡度分成4类,从最陡的一类开始给未分配高程的象元分配高程值。其它坡度类别重复相同的分配过程,而平坦地区是在所有DEM的非平坦部分都计算完后单独计算。Oswald和Raetzsch(1984)断定这种内插法──“依次最陡坡度算法”是完善而实用的技术。其他一些作者则持相反的观点(如Clarke等1982),他们认为非线性内插法“完全不令人满意”。
2. 点模式
(1)规则矩形格网――Grid
DEM最普通的形式是高程矩阵或规则矩形格网(GRID),高程数据直接由解析立体测图仪从立体航片上定量测量(Kelly等,1977)。高程矩阵还可由规则或不规则离散数据点内插产生。
由于计算机中矩阵的处理比较方便,特别是栅格为基础的地理信息系统中高程矩阵已成为DEM最通用的形式。英国和美国都用较粗略的矩阵(美国用63.5m象元格网)从全国1:25万地形图上产生了全国的高程矩阵,以1:5万或1:2.5万比例尺地图和航片为基础的分辨率更高的高矩阵正在这两个国家或其它国家扩大其使用范围。
虽然高程矩阵有利于计算等高线、坡度、坡向、山地阴影、自动描绘流域轮廓等,但规则的格网系统也有如下几方面的缺点:
① 在地形简单的地区存在大量冗余数据;
② 如不改变格网大小,无法适用于起伏复杂程度不同的地区;
③ 对于某些特种计算如视线计算时,过分依赖格网轴线。
先进采样法(Progressive Sampling)的实际应用很大程度上解决了采样过程中产生的冗余数据问题。先进采样法就是通过立体像对,根据视差模型自动选配左右影像的同名点建立数字高程模型。在产生DEM数据时,地形变化复杂的地区增加格网数(提高分辨率),而在地形起伏变化不大的地区则减少格网数(降低分辨率)。然而,数据存储中的冗余数据问题仍没有解决,因为连续变化的高度表面不太容易按照与栅格数据兼容的形式编码,而栅格数据又是专题制图需用的各种属性数据,当属性数据与地形数据组合使用时,它们的栅格大小必须统一,使DEM数据不得不填充所有的象元。
高程矩阵也和其它属性数据一样可能因栅格过于粗略而不能精确表示地形的关键特征,例如,山峰、洼坑、隘口、山脊、山谷线等。这些特征表示不正确时会给地貌分析带来一些问题。
不规则的离散采样点可以按两种方法产生高程矩阵:将规则格网覆盖在这些数据点的分布图上,然后用内插技术产生高程矩阵。当然,内插技术也可用来从一个粗略的高程矩阵产生更精细高程矩阵;把离散采样点作为点模式中不规则三角网系统的基础。
(2)不规则三角网(TIN―Triangulated Irregular Network)
① TIN特点
不规则三角网(TIN)是由Peuker和他的同事(1978)设计的一个系统,它是由不规则分布的数据点连成的三角网组成,三角面的形状和大小取决于不规则分布的观测点或称结点的密度和位置。不规则三角网与高程矩阵不同之处是能随地形起伏变化的复杂性而改变采样点的密度和决定采样点的位置,因而能克服地形起伏不大的地区产生数据冗余的问题,利用它来绘制三维立体图具有较好的显示效果。对于某些类型运算比建立在数字等高线基础上的系统更有效。同时还能按地形特征点如山脊、山谷及其它重要地形特征获得DEM数据。不规则三角网方法能够较好地表示复杂地形,它的缺点是数据结构复杂,不便于规范化管理, 难以与矢量和栅格数据进行联合分析。而且,由于三角网是不规则排列的,计算每一点高程值的实时性不如规则网格模型。
TIN相当于是对采样点的一个平面三角剖分,因而它是一个连通平面图(黄力等,1999)。下面是计算N个点的任意一个平面三角剖分所含的三角形数和边数。设E表示边的数量,T表示三角形的数量。根据平面图中的欧拉公式有:N - E+ T + 1= 2,由于同一条边为两个相邻三角形所共有,故2*E= 3*T + Nh,其中Nh是包围这N个点的凸壳上的点数。由上两式,我们可得到:E= 3*(N - 1) - Nh,T = 2*(N - 1) - Nh,因此,可知对N个点的任何一个三角剖分,三角形的数量和边的数量是常量。
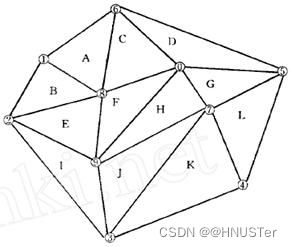 不规则三角网
不规则三角网
② TIN数据结构
用来描述TIN的基本元素有三个:结点、边和面。结点是相邻三角形的公共顶点,也是用来构建TIN的采样数据。边是两个三角形的公共边界,是TIN不光滑性的具体反映,它同时包含特征线、断裂线和区域边界。面是由最近的三个结点组成的三角形面,是TIN描述地形表面的基本单元,不能交叉和重叠。结点、边和面之间存在着关联、邻接等拓扑关系,类似于第二章定义的多边形网络完整的拓扑结构,但TIN没有考虑“洞”和“岛”的情形。TIN的表示方法有许多种,但是都比较复杂。图9-5是对应于图9-4的不规则三角网的一种表示方法,它包括点数据结构,边数据结构和三角形数据结构。
③ 狄洛尼(Delaunay)三角网
对于TIN模型,其基本要求有三点:
-
TIN是唯一的;
-
力求最佳的三角形几何形状,每个三角形尽量接近等边形状;
-
保证最邻近的点构成三角形,即三角形的边长之和最小。
 TIN的数据结构
TIN的数据结构
在所有可能的三角网中,狄洛尼(Delaunay)三角网在地形拟合方面表现最为出色,因此常常被用于TIN的生成。当不相交的断裂线等被作为预先定义的限制条件作用于TIN的生成当中时,则必须考虑带约束条件的Delaunay三角网。Delaunay三角网为相互邻接且互不重叠的三角形的集合,每一个三角形的外接圆内不包含其他的点。三角形外接圆内不包含其他点的特性被用作从一系列不重合的平面点建立狄洛尼三角网的基本法则,可称做空圆法则。Delaunay三角网是Voronoi图的对偶图,由对应Voronoi多边形共边的点连接而成。Delaunay三角形由三个相邻点连接而成,这三个相邻点对应Voronoi多边形有一个公共的顶点,此顶点同时也是狄洛尼三角形外接圆的圆心。图9-6描述了欧几里得平面上16个点的Delaunay三角网以及Voronoi图的对偶。
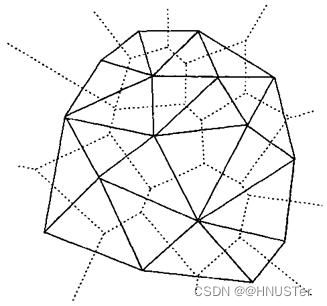 16个平面点集的Delaunay三角网
16个平面点集的Delaunay三角网
④ Voronoi图及泰森多边形
Voronoi图又称为Dirichlet镶嵌( tessellation),其概念由Dirichlet 于1850 年首先提出;1907后俄国数学家Voronoi 对此作了进一步阐述,并提出高次方程化简;1911年荷兰气候学家A1H1Thiessen为提高大面积气象预报的准确度,应用Voronoi图对气象观测站进行了有效区域划分(吴立新,2003)。因此在二维空间中,Voronoi图也称为泰森(Thiessen)多边形。
设P = { p1 , p2 , …, pn } < R2 是二维欧式空间上的点集, d (・,・) 为欧式距离。称V ( pi ) = { p ∈R2 | d ( p , pi ) ≤d ( p , pj ) , i , j = 1 ,2 , …, n ,i ≠j}为Voronoi区域。简单地说,Voronoi 图是平面的一个划分,其控制点集P中任意两点都不共位,且任意四点不共圆,任意一个内点到该凸多边形的控制点pi的距离都小于该点到其他任何控制点pj 的距离(冯仲科,2006)。Voronoi 区域的边称为Voronoi 图的边,Voronoi 区域的顶点成为Voronoi 区域的顶点。Voronoi图如图9-6 虚线所示。因此,Voronoi图具有以下特性(华一新等,2001):
-
每个Voronoi 区域内仅含一个离散点数据;
-
每个Voronoi 区域内的点到相应离散点的距离最近;
-
位于Voronoi 区域边上的点到其两边的离散点的距离相等。
由于Delaunay三角网与Voronoi图的对偶关系。因此,在构造点集的Voronoi图之后,再对其做对偶图,即对每条Voronoi边(限有限长线段)做通过点集中某两点的垂线,便得到Delaunay三角网。同样,由Delaunay三角网也可以方便的得到与之对偶的Voronoi图。除了可以利用Delaunay三角网来求解Voronoi图以外,还有很多构造Voronoi图的方法,如半平面的交、增量构造方法、分而治之法等。
8.3.3 DEM三维表达方法
DEM的三维表达常用的包括立体等高线图、线框透视图、立体透视图以及各种地形模型与图像数据叠加而形成的地形景观等等。
1. 立体等高线模型
为了表示陆地和海底的地形高低起伏变化情况和形态特征,地形立体等高线表示法属于写景法,它将等高线作为空间直角坐标系中函数为Z=f(x,y)的空间图形投影到平面上所得到的立体效果,它在采用了三维坐标投影变换的同时,还需根据视线方向作隐线处理,以便使图形效果更富有立体感,如图9-7所示(许海涛,1999)。
 普通等高线
普通等高线
 立体等高线(视角15°)
立体等高线(视角15°)
2. 三维线框透视模型
线框透视图或线框模型(Wireframe)是计算机图形学和CAD/CAM领域中较早用来表示三维对象的模型,至今仍广为运用,流行的CAD软件、GIS软件等都支持三维对象的线框透视图建立。线框模型是三维对象的轮廓描述,用顶点和邻边来表示三维对象,其优点是结构简单、易于理解、数据量少、建模速度快,缺点是线框模型没有面和体的特征、表面轮廓线将随着视线方向的变化而变化、由于不是连续的几何信息因而不能明确地定义给定点与对象之间的关系(如点在形体内、外等),如下图所示。
 DEM三维线框透视图
DEM三维线框透视图
3. 地形三维表面模型
三维线框透视图是通过点和线来建立三维对象的立体模型,仅提供可视化效果而无法进行有关的分析。地形三维表面模型是在三维线框模型基础上,通过增加有关的面、表面特征、边的连接方向等信息,实现对三维表面的以面为基础的定义和描述,从而可满足面面求交、线面消除、明暗色彩图等应用的需求。简言之,三维表面模型是用有向边所围成的面域来定义形体表面,由面的集合来定义形体。
若把数字高程模型的每个单元看作是一个个面域,可实现地形表面的三维可视化表达,表达形式可以是不渲染的线框图,也可采用光照模型进行光照模拟,同时也可叠加各种地物信息,以及与遥感影像等数据叠加形成更加逼真的地形三维景观模型。
 三维模型
三维模型
 叠加沟谷河网后的三维模型
叠加沟谷河网后的三维模型
8.4 TIN的生成方法
由于相同的离散点集可以生成多个不同的三角网,因此也就有着多种不同的三角网的构网算法。一般三角网法未考虑地形线的骨架作用,同时在构网时有一定盲目性或任意性,有的三角形边不是贴在地面上,而是“架空”在河谷上或是“贯穿”于山体中。因此这种方法不能用来建立“地貌上”精确的数字地面模型,而只能用于精度要求不高且瞬时性较强的三维空间模型(如气压、气温、磁场等地理现象)。为了使三角网能够顾及地性线关系,可用人工的方法和程序自动建立的两种方法建立TIN模型。
8.4.1 人工方法
地形测量员注意选取地面上的转折点并且在测量中携带一幅野外草图,用以表示由哪些测点构成地性线,例如山脊线及谷底线。在这些资料的基础上,人工构成三角形时,以可能的最短的边来构成三角形,并保证每条边位于地面上而不是悬空通过或贯穿地球表面。只要上述条件满足,三角形的形状是无关紧要的,因此,取得高质量等高线的关键在于获得地性线资料。如果没有它,任何自动化的处理都不能指望达到常规的人工勾绘等高线的质量。
8.4.2 程序自动建立
Delaunay三角网构网算法可归纳为两大类,即静态三角网和动态三角网。静态三角网指的是在整个建网过程中,已建好的三角网不会因新增点参与构网而发生改变;而对于动态三角网则相反,在构网时,当一个点被选中参与构网时,原有的三角网被重构以满足Delaunay外切圆规则。
静态三角网(李志林,2000)构网法主要有辐射扫描算法、递归分裂算法、分解吞并算法、逐步扩展算法、改进层次算法等。动态三角网构网算法主要有增量式算法和增量式动态生成和修改算法。以上算法基本上反映了构建Delaunay三角网的各种途径。在生成TIN的算法中数据结构的设计和选择对算法的运行效率紧密相关。
1. 三角网生长算法
三角形生长算法是一种典型的静态三角网生长算法。
(1)递归生长算法
递归生长算法的基本过程如图9-10所示:
① 在所有数据中取任意一点l(一般从几何中心附近开始),查找距离此点最近的点2,相连后作为初始基线1-2;
② 在初始基线右边应用Delaunay法则搜寻第三点3,形成第一个Delaunay三角形;
③ 并以此三角形的两条新边(2-3,3-1)作为新的初始基线;
④ 重复步骤②和③直至所有数据点处理完毕。
该算法主要的工作是在大量数据点中搜寻给定基线符合要求的邻域点。一种比较简单的搜索方法是通过计算三角形外接圆的圆心和半径来完成对邻域点的搜索。为减少搜索时间,还可以预先将数据按X或Y坐标分块并进行排序。使用外接圆的搜索方法限定了基线的待选邻域点,因而降低了用于搜寻Delaunay三角网的计算时间。如果引入约束线段,则在确定第三点时还要判断形成的三角形边是否与约束线段交叉。
(2)凸闭包收缩算法
与递归生长算法相反。凸闭包搜索法的基本思想是首先找到包含数据区域的最小凸多边形。并从该多边形开始从外向里逐层形成三角形网络。平面点凸闭包的定义是包含这些平面点的最小凸多边形。在凸闭包中,连接任意两点的线段必须完全位于多边形内。凸闭包是数据点的自然极限边界。相当于包围数据点的最短路径。显然,凸闭包是数据集标准Delaunay三角网的一部分。计算凸闭包算法步骤包括:
① 搜寻分别对应x-y,x+y最大值及x-y,x+y最小值的各两个点。这些点为凸闭包的顶点,且总是位于数据集的四个角上,如图9-11(a)中曲点7,9,12,6;
② 将这些点以逆时针方向存储于循环链表中;
③ 搜索线段IJ及其右边的所有点,计算对IJ有最大偏移量的点K作为IJ之间新的凸闭包顶点,如点11对边7―9。
④ 重复①~②,直至找不到新的顶点为止。
一旦提取出数据区域的凸闭包,就可以从其中的一条边开始逐层构建三角网,具体算法如下:
① 将凸多边形按逆时针顺序存入链表结构,左下角点附近的顶点排第一;
② 选择第一个点作为起点,与其相邻点的连线作为第一条基边,如图9-12(a)中的9―5;
③ 从数据点中寻找与基边左最邻近的点8作为三角形的顶点。这样便形成了第一个Delaunay三角形;
④ 将起点9与顶点8的连线换做基边。重复③即可形成第二个三角形;
⑤ 重复第④步,直到三角形的顶点为另一个边界点11。这样,借助于一个起点9便形成了一层Delaunay三角形;
⑥ 适当修改边界点序列。依次选取前一层三角网的顶点作为新起点,重复前面的处理,便可建立起连续的一层一层的三角网。
该方法同样可以考虑约束线段。但随着数据点分布密度的不同,实际情况往往比较复杂。比如边界收缩后一个完整的区域可能会分解成若干个相互独立的子区域。当数据量较大时,如何提高顶点选择的效率是该方法的关键。
2. 数据逐点插入法
数据逐点插入法是一种典型的动态三角网生长算法。三角网生长算法最大的问题是计算的时间复杂性,其原因是由于每个三角形的形成都涉及所有待处理的点,且难于通过简单的分块或排序予以彻底解决。数据点越多,问题越突出。而数据逐点插入法在很大程度上克服了这个问题。其具体算法如下(见图9-13):
(1)首先提取整个数据区域的最小外界矩形范围,并以此作为最简单的凸闭包。
(2)按一定规则将数据区域的矩形范围进行格网划分。为了取得比较理想的综合效率,可以限定每个格网单元平均拥有的数据点数。
(3)根据数据点的(x,y)坐标建立分块索引的线性链表。
(4)剖分数据区域的凸闭包形成两个超三角形,所有的数据点都一定在这两个三角形范围内。
(5)按照(3)建立的数据链表顺序往(4)的三角形中插入数据点。首先找到包含数据点的三角形,进而连接该点与三角形的三个顶点,简单剖分该三角形为三个新的三角形。
(6)根据Delaunay三角形的空圆特性,分别调整新生成的三个三角形及其相邻的三角形。对相邻的三角形两两进行检测,如果其中一个三角形的外接圆中包含有另一个三角形除公共顶点外的第三个顶点,则交换公共边。
(7)重复(5)―(6),直至所有的数据点都被插入到三角网中。
可见,由于步骤(3)的处理,从而保证了相邻的数据点渐次插入,并通过搜寻加入点的影响三角网(Influence Triangulation),现存的三角网在局部范围内得到了动态更新,从而大大提高了寻找包含数据点的三角形的效率。
8.5 Grid的生成
8.5.1 网格化插值计算
将离散DEM数据经插值计算转换为格网DEM数据的过程称为DEM数据网格化,即生成Grid。也就是说,需要用离散的观测点值去估算未知的格网点的值。插值的算法有许多种,但不论用哪种方法,如果希望通过插值加密数据点,使一个粗糙的初始地形模型变成一个新的精确模型,那肯定是不现实的。相反,原始模型经过插值计算得到的新模型总是可能带来一定的变形,因为原始数据点是实测的,因而是精确的,而插值点可能会有一定的误差。此外,应注意到地形起伏变化的不均衡性,有的地区平坦和缓,有的地区起伏骤变,用统一网格较难适应这种变化的差异。但是设计和选用适宜的插值算法仍然是必要的。使原始数据中包括的地理特征能够无明显损失地传递到内插计算的数字高程模型中去。
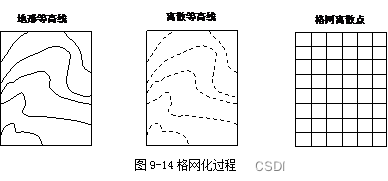 格网化过程
格网化过程
自五十年代末DEM方法提出后,已从基本理论到内插方法进行了大量研究,相继出现了多种插值算法,积累了丰富的经验。概括他们的较为统一的认识,将有助于设计和选择插值算法,建立起精度较高的DEM数据,这就是:
(1)对于地形模型,因无一定数学规律可循,其精度主要决定于原始数据的获取(密度和分布)。
(2)一般情况下,DEM精度与原始数据密度基本上呈线性关系。
(3)在原始数据一定密度的条件下,尤其密度较高条件下,在同一样点网上展铺不同类型的数学面,产生的DEM精度无明显差别。
(4)由于地形的千变万化──平原、丘陵、山地、黄土、喀斯特等等,各种算法只有一定的适应性。
(5)由于地形在地性线(山脊、山谷、断崖等)上发生转折,在分块拟合曲面时,跨越地性线的数据点不宜参加曲面方程的拟合。
8.5.2 网格尺寸的确定
这是DEM数据网格化的一个重要问题,它首先关系到派生数据的密度,并直接影响地形模型的精度。网格过细不仅不会提高DEM精度,反而产生冗余的“游离”数据,即相邻格网点值差别微小且不包含有效的地形特征信息。网格过大则不仅丢失了地形特征信息且会造成地形扭曲。并且,若网格过大,派生的网格点数明显低于样点采集数,那意味着样点的采集工作就是失败的,采集了许多实际无用的样点。
因此,一般情况下,样点的密度基本上决定了网格点密度。网格点数宜大于或接近样点数。在采集优选点情况下,可考虑:n< N< 2n,式中N为网格点数,n为采样点数。
8.5.3 空间插值方法
1. 移动平均法
移动平均法认为任一点上场的趋势分量可以从该点一定邻域内其它各点的值及其分布特点平均求得,参加平均的邻域称做窗口。窗口的形状可以是方形或圆形。圆形比较合理,但方形更方便计算机取数。求平均时可以用算术平均值、众数或其它加权平均数。选用大小不同的窗口,可以实现数据的分解,大窗口使区域趋势成分比重增大,小窗口则可突出一些局部异常。逐格移动窗口逐点逐行计算直到覆盖全区,就得到了网格化的数据点图。
移动平均在求趋势分量时只涉及一定范围,因此在接图的边界上,只要适当的扩边,把相邻图幅影响范围内的数据接上一起处理,即可以方便地实现拼接。这类方法已成为各国区域化探数据处理的标准方法。我国区域化探中常用的是8×8km的窗口。
移动平均保持了对一般趋势的反映,而且很容易填补一些小的数据空缺,使图面完整,但移动平均有一定的平滑效应和边缘效应。
当原始取样点分布较稀且不规则时,可以采用定点数而不定范围的取数方法,即搜索邻近的点直到预定的数目为止。搜索方法可以是四方搜索或八方搜索等。此时由于距离可能相差较大,因此常同时采用距离倒数或距离平方倒数加权的办法,以便压低远处的点的影响。
2. 距离平方倒数加权法
距离平方倒数加权法主要原理是某点(或某待估网格)的估计值与周围已知点值的距离平方倒数成一定关系,以空间位置的加权平均来计算。
3. 趋势面拟合技术
地球表面起伏变化、千姿百态。多年来为了准确合理地表现这一形态,人们曾就地形曲面数学模型以及相应的数值逼近方法作过不少努力。多项式回归分析是描述大范围空间渐变特征的最简单方法。多项式回归的基本思想是用多项式表示线(数据是一维时)或面(数据是二维时)按最小二乘法原理对数据点进行的拟合,一维的拟合称为线拟合技术,但地理信息系统研究的对象在空间上和时间上都有复杂的分布特征,在空间上的分布常是不规则的曲面,数据往往是二维的,而且以更为复杂的方式变化,一维拟合技术不能反映区域性趋势变化,因此必须利用趋势面分析技术。其基本思想是:用函数所代表的面来逼近(或拟合)现象特征的趋势变化。
 一元线性回归分析和一元非线性回归分析
一元线性回归分析和一元非线性回归分析
回归函数的次数并非越高越好,在实际工作中,一般只用到二次,超过三次的复项多项式往往会导致解的奇异,高次趋势面不仅计算复杂(如六次趋势面方程系数达28个),而且次数高的多项式在观测点逼近方面效果虽好,但在内插、外推的效果上则常常降低分离趋势的作用,使整体趋势分离,降低趋势规律的反映。趋势面是一种平滑函数,很难正好通过原始数据点,这就是说在多重回归中的残差属正态分布的独立误差,而且趋势面拟合产生的偏差几乎都具有一定程度的空间非相关性。
整体趋势面拟合除应用整体空间的独立点内插外,另一个最有成效的应用之一是揭示区域中不同于总趋势的最大偏离部分。因此,在利用某种局部内插方法以前,可以利用整体趋势面拟合技术从数据中去掉一些宏观特征(例如最小二乘配置法)。
4.样条函数
最小二乘曲面拟合假设了所有样品值被观测到的概率相等,而没有考虑样品间的相对位置。当观测点数比较大时,需要用高阶多项式去拟合,这不但使计算复杂化,并且高阶多项式还可能在观测点之间产生振荡。因此,多采用分块拟合的办法,用低阶多项式进行局部拟合。样条函数拟合即是常用的方法,它将数据平面分成若干单元,在每一单元上用低阶多项式,通常为三次多项式(三次样条函数)构造一个局剖曲面,对单元内的数据点进行最佳拟合,并使由局部曲面组成的整个表面连续。
5. 克立金法
克立金法最初是由南非金矿地质学家克立金(D.G.Krige)根据南非金矿的具体情况提出的计算矿产储量的方法;按照样品与待估块段的相对空间位置和相关程度来计算块段品位及储量,并使估计误差为最小。然后,法国学者马特隆(G.Matheron)对克立金法进行了详细的研究,使之公式化和合理化。
克立金法基本原理是根据相邻变量的值(如若干样品元素含量值),利用变差函数所揭示的区域化变量的内在联系来估计空间变量数值的方法。
地质变量是区域化变量,具有空间结构性,即在空间点x和x+h处的变量值z(x)和z(x+h)具有自相关性。这种相关依赖于两点间的向量h和矿化特征。区域化变量的空间特征由变差函数来描述。
变差函数为区域变量z(x)的增量平方的数学期望,即区域化变量增量的方差。变差函数即是距离h的函数,又是方向a的函数。
8.5.4 几种典型数据网格化插值方法选择
遥感数据是按影像方式记录的栅格数据,内插放大或重采样时,常用矩形网格内插法,如最邻近点法、双线性插值法或立方卷积法。
地球物理数据,特别是位场数据,是典型的空间连续型数据。一般多用样条函数插值方法,使生成的曲面具有连续的二阶导数和最小的平方曲率。三次样条插值比较适合于高频成分较多的场,对于台阶异常,Akimn样条插值可能显得更为合理,也可以用最小二乘曲面拟合法和距离反比加权法。
一些资料的测线间距大于探测目标的埋深,形成欠采样资料。当测线与场源地质体不垂直时,常规插值常常形成虚假孤立异常,这时可用方向增强插值的方法弥补采样的缺陷。在对水系沉积物或分散流数据加权插值时,可考虑沿水系的方向给予较大的权。对测线与目标地质体走向不垂直时的数据,可选取长矩形插值窗口,矩形的长边平行于地质体走向并同时加大走向方向各点的权重。
化探异常数据具有较强的随机性和采样点稀疏不规则的特点,因此网格化估值方法常用滑动平均法、距离平方倒数法和克立金法。
8.6 DEM的数据源和采样方法
地表的高程数据通常用航测仪器从立体航空像对上获取,在航测方法不能即时供给数据时,现有地形图的数字化也是常用的方式。此外,地面测量、声纳测量、雷达和扫描仪数据也可作为DEM的数据来源。
摄影测量采样法还可以进一步分成:
(1)选择采样。在采样之前或者采样过程中选择需采集高程数据的样点;
(2)适应性采样。采样过程中发现某些地面没有包含什么信息时,取消某些样点以减少冗余数据;
(3)先进的采样法。采样和分析同时进行时,数据分析支配采样进程。先进采样法在产生高程矩阵时能按地表起伏变化的复杂性进行客观自动地采样。实际上它是连续的不同密度的采样过程:首先按粗略格网采样,然后对变化较复杂的地区进行细格网(采样密度增加一倍)采样。需采样的点是由计算机对前一次采样获得的数据点进行分析后确定的,即确定是否继续进行高一级密度的采样。
计算机分析过程是在前一次采样数据中选择相邻的9个点作为窗口,计算沿行或列方向邻接点之间的一阶和二阶差分。由于差分中包括了地面曲率信息,因此可按曲率信息选取阈值。如果曲率超过阈值时就有必要进行另一级格网密度的采样。先进采样法在无云层覆盖、无人工地物和地形起伏变化不突然(无陡坎)地区的航片上实施时,能获得良好的效果。地形起伏变化特别复杂且多陡崖地区的采样必须用混合采样法才能保征精度。在陡崖区用手工描绘出需进行选择性采样的范围并用手工进行采样,其余地区则进行自动采样。半自动采样法和混合采样法对地形突变地区而言都不可能获得满意的结果,必须选择多种采样方法才能按需要获得全部地形数据。先进采样法及混合采样法获取的数据必须自动转换成统一的高程矩阵。
8.7 DEM的应用
8.7.1 DEM的主要用途
数字高程模型有许多用途,其中最重要的一些用途是:
1. 在国家数据库中存储数字地形图的高程数据;
2. 计算道路设计、其它民用和军事工程中挖填土石方量;
3. 为军事目的(武器导向系统、驾驶训练)的地表景观设计与规划(土地景观构筑)等显示地形的三维图形;
4. 越野通视情况分析(也是为了军事和土地景观规划等目的);
5. 规划道路线路、坝址选择等;
6. 不同地面的比较和统计分析;
7. 计算坡度、坡向图,用于地貌晕渲的坡度剖面图。帮助地貌分析,估计浸蚀和径流等;
8. 显示专题信息或将地形起伏数据与专题数据如土壤、土地利用、植被等进行组合分析的基础;
9. 提供土地景观和景观处理模型的影象模拟需要的数据;
10. 用其它连续变化的特征代替高程后,DEM还可以表示如下一些表面:通行时间和费用、人口、直观风景标志、污染状况、地下水水位等。
8.7.2 DEM的应用
不论DEM是高程矩阵、数组、规则的点数据还是三角网数据等形式,都可以从中获得多种派生产品。
1. 三维方块图、剖面图及地层图
三维方块图是为人们熟知的数字地面模型的形式之一,它是以数值的形式表示地表数量变化(不只是高程)的富有吸引力的直观方法。现在已有许多可供三维方块图计算用的标准程序。这些程序用线划描绘或阴影栅格显示法表示规则或不规则x、y、z数据组的立体图形。三维方块图计算要求用户指定一个观察点和垂直夸大的比例尺。由于计算中包括了透视因子,使模拟结果产生的模型更加容易被人们接受。另外,计算过程中还包括解决隐藏物的方法。一般情况下都以观察点到目标物的视线为准,隐藏在较高物体后面的其它物体则不予表示,实在需要表示时则改变观察点的位置。如果在屏幕上显示以栅格数据为基础的三维立体图,为使高物体后面的物体也能显示出来,可采用逐行显示的办法一一显示。
2. 视线图
确定土地景观中点与点之间相互通视的能力对军事活动、微波通讯网的规划及娱乐场所和风景旅游点的研究和规划都是十分重要的。按传统的等高线图来确定通视情况较为困难,因为在分析中必须取大量的剖面数据并加以比较。
数字高程模型(无论是高程矩阵或不规则三角网)的建立为这类分析提供极为方便的基础,能方便地算出一个观察点所看到的各个部分。用前面提到的隐藏线算法的改进算法就能实现,在DEM中辨认出观察点所在的位置,从这个位置引出所有的射线,比较射线通过的每个点(高程矩阵中即为象元)的高程,将不被物体隐藏的各点进行特殊编码,从而得出一幅简单的地图。
由于DEM通常是立体航空像片对上直接获取的,高程数据中可能没有包括地面物体的高度(如树林、建筑物)等特征,因此得到的结果需进行仔细地检查、判读才能最后确定通视情况。有些分析目的要求把物体的高度加入DEM数据中,以便计算它们对通视情况的影响。
3. 等高线图
从高程矩阵中很容易得到等高线图,方法是把高程矩阵中各象元的高程分成适当的高程类别,然后用不同的颜色或灰度输出每一类别。这类等高线图与传统地形图上的等高线不同,它是高程区间或者可以看作某种精度的等高带,而不是单一的线。实际上两高程类别之间的分界线可视为等高线。这样的等高线图对简单环境制图来说已满足要求,但从制图观点来看还过于粗糙,必须用特殊的算法将同高度的点连成线。连接等高线时如果原高程数据点不规则或间隔过大,必须同时使用内插技术内插到需要的密度。等高线连接的结果用笔绘图仪输出。
从不规则三角网(TIN)数据中产生的等高线是用水平面与TIN相交的办法实现的。TIN中的山脊、山谷线等数据主要用来引导等高线的起始点。形成等高线后还要进行第二次处理以便消除三角形边界上人为形成的线划。
4. 地形特征的数字表征
数字地形参量是地形特征的数字表征,它们从不同的角度描述了地形和水系的各种特性。描述地形特征的参数很多,对于不同的应用目的,可有不同的选择和不同的定义。主要有坡度、坡向、视场因子、粗糙度、高程变异、汇水能力、流出方向、山脊密度和水系密度等九个参量。
根据图像处理的特点,地形参数采用网格法来定义,取3×3像元的计算窗口,以中心像元和其邻域八个像元的高程数据,作曲面拟合,计算地形特征参量(坡度、坡向、视场因子、地表粗糙度、高程变异、汇水能力、流出方向、山脊、山谷、沟壑密度等等)。
5.地貌晕渲图
制图工作者为了增加丘陵和山地地区描述高差起伏的视觉效果而发展了许多有关的制图技术,其中最成功的一种是“阴影立体法”即地貌晕渲法。用这种技术绘制的图件看起来很动人,但费用太高,晕渲的质量和精度很大程度上取决于制图工作者的主观意识和技巧。
数字地图特别是数字地形图(主要指DEM)投入生产并加以应用后,地貌晕渲便能自动、精确地实现。自动晕渲的原理是基于“地面在人们眼里看到的是什么样子、用何种理想的材料来制作、以什么方向为光源照明方向”等模式。制图输出时如果用灰度级和连续色调技术表示明暗程度,得到的成果看起来与航片十分相似。
实际上,从高程矩阵中自动生成的地貌晕渲图与航片有许多不同之处,主要表现在:(1)晕渲图不包含任何地面覆盖信息,仅仅是数字化的地表起伏显示;(2)光源方向一般确定为西北45°方向,这一方向对人的本能感觉来说要比天文真实性好。航片上的阴影主要随太阳角变化;(3)晕渲图通常都经过了平滑和综合处理因而没有航片上显示出的地形细节丰富。
 自动化生产的地貌晕渲图
自动化生产的地貌晕渲图
6.从DEM数据自动形成地形轮廓线
高程矩阵中没有贮存山脊、山谷线等地形特征线,或者地形图数字化时没有单独数字化地形特征线的情况下,用程序自动地将它们从高程矩阵中提取出来也许是必要的。例如,从叠置到DEM上的卫星图象上勾绘出集水范围线使遥感图象与特殊地理景观联系在一起。高程矩阵用于其它数量分析,如费用量、集中范围、旅行时间等时,应有一种方法来描绘线、面特征。
到目前为止,人们要进行水系的流域分析和水网分析时需花大量劳动从航片或地图上透绘所需的数据。这一工作不仅十分乏味,而且很容易发生数据误差或错误。特别是在地形起伏不大的地区,用眼睛判断分水线什么位置还不是一件容易的事情。另外,即使用非常详细的地形图来估算兰色线划表示的水系网中所有潜在的水源实际模型,也会出现严重偏低的估计结果。这些理由都说明自动描绘地形特征线程序的必要性。
(1)山脊线和谷底线的探测
为了自动探测山脊线和谷底线,设计了专门的运算算子。较为简单的算子是4个象元的局部算子。该算子在高程矩阵中移动并比较每一位置处4个象元的高程值,同时标出其中高程最大(探测谷底线)或最小(探测山脊线)的象元。标记过程完成后,剩下一些未标记的象元就是需要的山谷或山脊线所在象元。下一步就是把它们连接成线模式形成山脊或山谷线。
虽然这类简单算子工作起来效果良好,但与习惯的概念相反——探测谷底,标出最大高程的象元。因此又发展了另一种算子,它的原理是在运算之前首先确定水系网的出口象元和起始象元,然后用3×3象元算子置于起始象元上比较出3×3象元阵列中高程最低的象元,水流则从起始象元流向那个最低象元。把3×3象元算子移到新找出的那个最低象元。重复比较过程又找出一个最低象元……,流水线则被探测出来。探测山脊线时则找出最高高程值的象元并标记出来。虽然这种方法有效、可行,但要花大量的计算时间和内存,而且要比简单方法慢20倍。
(2)集水范围的确定
集水范围即流域范围的确定对流域分析十分必要。流域探测除确定边界线外还要将整个范围从整个数据库中分离出来。探测方法与山脊线或山谷线的探测类似。首先需交互式地确定河流流域的出口并作为搜索工作的起始点,以3×3算子的中心象元置于起始点上,比较中心象元相邻近的8个象元的坡向。如果坡向朝向中心象元,则认为它是中心象元的上游,算子的中心象元移至新的“上游”点,重复比较过程又能得到新的“上游”点。当算子中已有作为“上游”点加以标记的象元时则不予比较。整个数据范围都运算完毕后。流域范围就全部标记出来了。用户可以对这些象元重编码形成某一流域的分布图。
7.剖面分析
剖面是一个假想的垂直于海拔零平面的平面与地形表面相交,并延伸其地表与海拔零平面之间的部分,研究地形剖面,常常可以线代面,研究区域的地貌形态、轮廓形状,地势变化、地质构造等。
剖面图的绘制也是在DEM格网上进行的。已知两点A和B,求这两点的剖面图的原理是:首先内插出A、B两点的高程值;还要求出AB连线与DEM格网的所有交点,插值出各交点的坐标和高程,并把交点以离开始点的距离进行排序,最后选择一定的垂直比例尺和水平比例尺,以各点的高程和距始点的距离为纵横坐标绘制剖面图。
DEM数据还有其它用途,如线路勘查设计、土石方量估计等都是比较有效且经济效益高的方法。
8.8 DEM分析的误差与精度
DEM已经在测绘、资源与环境、灾害防治、国防等各应用领域内发挥着越来越巨大的作用。然而,各类DEM误差的存在不同程度地降低了分析与应用结果的可信度。强化对基于地形图的DEM精度检查与质量评估的研究,为各类GIS分析产品提供科学合理的质量标准,对评价DEM数据质量,减少生产单位质量检查的盲目性等方面有着深远的影响,具有十分重要的理论意义和应用价值。
8.8.1 DEM的误差研究概况
关于DEM的误差,国外己有很多研究,20世纪80年代以来,对DEM误差问题的研究取得了一些重要的成果。如从不同侧面进行了DME高程采样误差的成因分析,对DEM误差的量化、检测方法和空间分布等进行了研究。国内学者对于DEM数据精度作了深层次的研究,从不同角度探讨了DEM误差的成因、影响因素、数学模拟以及对GIS空间分析应用的影响,初步建立了一套利用不同信息源建立DEM的技术规范。另外,对地形描述的不确定性研究中提出区别于高程采样误差的DME地形描述误差概念,对DME地形描述误差的形成条件、空间分布特征、数学模拟方法等一系列问题进行了系统分析,提出了DEM地形描述误差在宏观与微观两个层面的数学模拟的模型。同时,还对不同比例尺、不同栅格分辨率DEM的不确定性特征与转换模型进行了研究,为有效估算DEM的地形描述精度及确定适宜的DEM分辨率提供了理论依据等等。并且,随着技术的发展,DEM生产自动化程度的提高,将会研发出自动化程度较高的DEM数据质量控制与检查软件,以满足生产作业和数据应用中的急需。
8.8.2 DEM的误差来源
DEM误差的产生与DEM的生产过程密切相关,DEM的生产一般经过原始数据的采集和内插建模两个阶段,在此基础上,把DEM误差分为数据源误差和内插建模误差。原始数据的采集误差:主要来自原始资料的误差、采点设备误差、人为误差、采集过程中产生的误差等。内插建模误差:在建立DEM的过程中,由于需要经过内插计算和建模处理,内插点的计算高程总是与实际量测高程之间存在差异,称为内插计算及建模误差。该误差一方面与内插算法有关,另一方面也与原始数据的分布和密度有关。
8.8.3 DEM的误差分析
原始数据的采集主要是利用不同的采集方式获取DEM原始数据的过程,数据采集可分为直接采集方法和间接采集方法两种(牛志宏,2007)。
1.直接采集数据的误差
直接法采集数据主要包括通过GPS测量和全站仪等测量仪器直接从野外获取数据,是DEM数据局部更新的主要方法。通过该方法获取的数据精度高,实时性强,但野外观测量大,需耗费大量的人力、物力。随着实时差分(RTK)技术的出现,采用GPS获取DEM数据也越来越广泛。因此,直接法采集数据的误差主要是GPS和全站仪等的观测误差。
2.间接采集数据的误差
(1)通过地图采集数据的误差。主要包括原图误差和数字化误差。原图误差主要包括地图制作过程中地图控制点的展绘、编绘误差、绘图误差、综合误差、地图复制误差、分色板套合误差、图纸变形误差等。
地图数字化主要有两种方式:手扶跟踪数字化和扫描数字化。目前采用较多的是扫描数字化方法。扫描数字化的误差主要包括扫描图像的误差、图像定向误差和扫描处理软件对数字栅格图像处理的误差。由于扫描数字化方式获取数据速度快、劳动强度小、自动化程度高等优点已成为获取DEM数据的主要手段。
(2)通过遥感图像采集数据的误差。遥感数据获取与处理的每一个过程都会引入误差,一般分为获取遥感图像的误差、图像处理和解译误差。获取遥感图像的误差主要表现为空间分辨率、几何畸变和辐射误差。遥感图像处理和解译误差主要包括图像压缩、数据分析和判读分析、影像存储、影像增强、处理、量化、空间滤波,以及影像模式识别等过程产生的误差,特别是图像压缩和数据分析和判读过程中的误差。
(3)通过摄影测量采集数据的误差。此类误差主要可归结为像点误差与定向误差。像点误差是在进行绝对定向前各种系统误差与偶然误差的综合误差,主要表现为获取航片误差与坐标量测误差。定向误差包括相对定向和绝对定向的误差,相对定向误差主要取决于像点误差,特别是同名像点量测的误差以及对像点坐标系统误差的校正程度,其定向精度可根据平差结果进行估计。绝对定向误差主要与采用的模型、地面点的误差、分布等有关。减弱该类误差主要是选取合适的数学模型、采用足够多的分步均匀的像控点。
3.DEM内插建模误差
DEM的内插是根据若干相邻参考点的高程求出待定点上的高程值,一般将其分为三类:即整体内插、分块内插和逐点内插。整体内插主要是通过多项式函数来实现的,它的拟合模型是由研究区域内所有采样点的观测值建立的。分块内插是把需要建立数字高程模型的地区切割成一定尺寸的规则分块,在每一分块上展铺一张数学面。逐点内插法是以待插点为中心,定义一个局部函数去拟合周围的数据点,数据点的范围随待插点的位置变化而变化,如移动拟合法、加权平均法、Voronoi图法等。
8.8.4 DEM的误差评价模型
DEM精度评估可通过两种不同的方式来进行,一种是平面精度和高程精度分开评定,另一种是两种精度同时评定。对前者,平面的精度结果可独立于垂直方向的精度结果而获得,但对后者,两种精度的获取必须同时进行。在实际应用中,一般只讨论DEM的高程精度评定问题。
数字高程模型的精度评定可有三种途径:一是理论分析,二是试验检测,三是理论与试验相结合。理论分析和理论与试验相结合方法的共同特点都是试图寻求对地表起伏复杂变化的统一量度和各种内插数学模型的通用表达方式,使评定方法、评定所得的精度和某些带规律性的结论有比较普遍的理论意义,所不同的是前者纯粹是理论研究,而后者要通过大量的实验来建立数学模型。应当指出,由于影响数字高程模型的因素是多种多样的,因此无论采用哪种途径都不能很好地解决所有的问题。
在实际应用中,常用的DEM精度评定模型有检查点法、剖面法等。
(1)检查点法
检查点法即事先将检查点按格网或任意形式进行分布,对生成的DEM在这些点处进行检查。将这些点处的内插高程和实际高程逐一比较得到各个点的误差,然后算出中误差。这种方法简单易行,是一种比较常用的方法。
(2)剖面法
剖面法是将一定的剖面量测计算高程点和实际高程点进行比较的精度计算方法。剖面可以沿X方向、Y方向或任意方向。可以用数学方法(如传递函数法)计算任意剖面的误差,也可以用实际剖面和内插剖面相比较的方法估算高程误差。
8.9 习题
-
什么叫数字高程模型(DEM)? 其数据分布有何特征?
-
什么叫DEM数据网格化?网格尺寸如何确定?
-
主要的空间插值方法有哪几种?各自如何进行插值?
-
试述格拉茨地面模型的基本思想。
-
高程矩阵如何建立,有何优缺点?
-
什么叫不规则三角网(TIN)模型?它是如何建立的?有何优点?
-
DEM有几种主要的数据源?如何进行采样?
-
试述DEM主要用途。
-
DEM三维表达有哪些方法?
-
DEM的误差来源有哪些?如何对误差进行分析评价?