周报8_YMK
周报8
这周主要看了HPC-AI的文档
另一个任务是在做计网课程的presentation
看了一篇大模型训练优化的模型,ZeRO++: Extremely Efficient Collective Communication for Giant Model Training(https://arxiv.org/pdf/2306.10209.pdf)
是微软DeepSpeed框架下的,它的上一个工作是2022年发在International Conference on High Performance Computing, Networking, Storage and Analysis (SC)上的,ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
ZeRO++主要是为了降低数据并行时,GPU之间的通讯量的
这里简单介绍一下ZeRO,ZeRO 将模型权重、梯度以及优化器状态(比如动量,方差)分别切分到各GPU上,从而可在有限的显存上训练更大的模型。
这样一来,模型前向计算和反向计算都需要提前聚合当前层对应的全量参数,这个聚合的过程是通过调用通信原语 All-Gather 来完成的。
之后便需要对计算好的梯度进行平均,把平均后的梯度值传播到各 GPU 上,用于各 GPU 更新自己负责的那一部分模型权重,这个平均以及传播的过程是通过调用通信原语 Reduce-Scatter 来完成的。
至此完成一步迭代,也就是说ZeRO是在用通信换显存,在有限的显存中训练更大的模型。分析这个过程可以发现,ZeRO 相比于普通的数据并行,后者只需要对最后计算出的梯度做一次 All-Reduce 通信,而前者需要两次 All-Gather 通信 + 一次 Reduce-Scatter 通信,通信量以及通信频率都大幅增长。
如果机器集群节点间的网络带宽再拉跨一些,那么 ZeRO 的训练效率简直不堪入目。这也是目前很多大模型都是基于张量并行和流水并行对模型进行精细切分,让一些频繁通信的操作(张量并行)尽量限制在节点内部的原因,把通信压力小的操作放在节点间完成,比如流水并行。
所以ZeRO作为数据并行的方法,也需要降低自己的通讯成本,进而提升训练效率,具体优化策略也就是接下来将要介绍的 ZeRO++。
先说结论:ZeRO++ 相比 ZeRO 将总通信量减少了 4 倍,而不会影响模型质量。
- 每个 GPU 上 batch size 较小时:无论是在数千个 GPU 上预训练大型模型,还是在数百个甚至数十个 GPU 上对其进行微调,ZeRO++ 提供比 ZeRO 高 2.2 倍的吞吐量,直接减少训练时间和成本。
- 低带宽计算集群: ZeRO++ 使低带宽集群能够实现与带宽高 4 倍的高端集群类似的吞吐量。因此,ZeRO++ 可以跨更广泛的集群进行高效的大型模型训练。
瓶颈分析:
如前面提到的,ZeRO的通信开销主要由三部分组成:
- 假设模型大小为 M。在前向传播过程中,ZeRO 执行全收集 / 广播 (all-gather/broadcast) 操作以在需要之时为每个模型层收集参数(总共大小为 M)。
- 在向后传递中,ZeRO 对每一层的参数采用类似的通信模式来计算其局部梯度(总大小为 M)。
- 此外,ZeRO 在对每个局部梯度计算完毕后会立刻使用 reduce 或 reduce-scatter 通信进行平均和分割储存(总大小为 M)。
因此,ZeRO 总共有 3M 的通信量,平均分布在两个全收集 / 广播 (all-gather/broadcast) 和一个减少分散 / 减少 (reduce-scatter/reduce) 操作中。
通信过程中的权重量化 (qwZ)
首先,为了减少 all-gather 期间的参数通信量,在 All-Gather 通信之前,首先把 FP16(两字节) 权重量化成 INT8(单字节),这样一来通信数据量就下降了一半,Al-Gather 通信之后,再通过反量化将 INT8 反量化成 FP16。
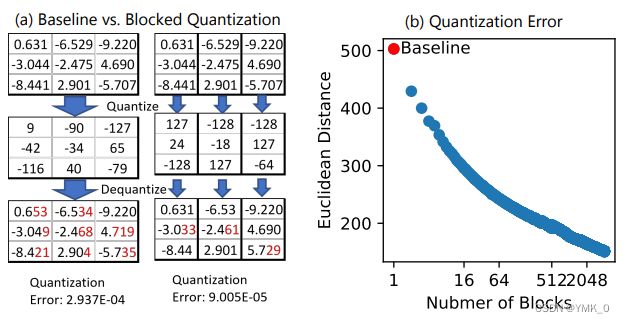
然而,简单地对权重进行量化会降低模型训练的准确性。为了保持良好的模型训练精度,我们采用分区量化Blocked Quantization,即对模型参数的每个子集进行独立量化。

如下图(a)是两种量化策略的对比,Blocked Quantization 相比于 Baseline 具有更小的量化误差;下图(b)说明 Block 切得越多,欧式距离越小,量化损失也就越小,但是也会带来额外的开销(scale 和 zero);
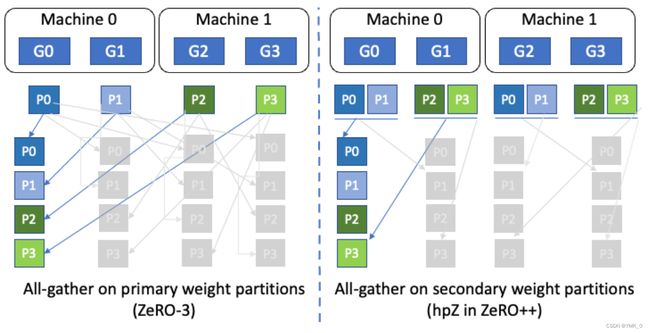
ZeRO 模型权重的分层分割存储 (hpZ)
第二,减少反向传递期间全收集 (all-gather) 权重的通信开销。由于 ZeRO 把整个模型权重切分到所有的 GPU 上,所以反向计算梯度时需要所有 GPU 参与通信,把权重分片聚拢起来,但是节点间的网络带宽远远小于节点内部,导致节点间通信成为瓶颈。
为了缓解这个问题,ZeRO++ 采用分层切片的策略尽量减少反向计算时的跨节点通信。简单来说,与在ZeRO中将整个模型权重分散在所有机器上不同,ZeRO++在每台机器内维护一个完整的模型副本。(用GPU显存换取通信效率)
具体来讲,已知前向计算时会把所有权重 All-Gather 起来,之后便对权重进行切片,切成多少片可以根据集群配置进行调节,一般情况下会把权重切片尽量限制在单个节点内部,也就是一个节点有多少张卡,就切成多少片,因为每个节点都拥有完整的权重,在反向计算梯度时只需要在节点内部执行 All-Gather 通信,完全避免了跨节点的通信。

ZeRO 通信过程中梯度量化 (qgZ)
ZeRO 在反向计算完成之后需要一次 Reduce-Scatter 通信,如果直接将量化策略应用到 Reduce-Scatter 通信原语,会造引发一系列的量化和反量化(量化和反量化的次数为所有 GPU 的个数),这不可避免地会引入巨大的量化误差,如下图左所示:

为了减少量化和反量化的次数(Q+D),可如上图右所示,首先对全部梯度量化,然后所有 GPU 进行一次 All-to-All 通信,最后执行反量化操作。这个过程只需一次量化和反量化操作,因此也被称作 1-hop all-to all。但是肉眼可见的这个1-hop all-to all的通信开销太大了。
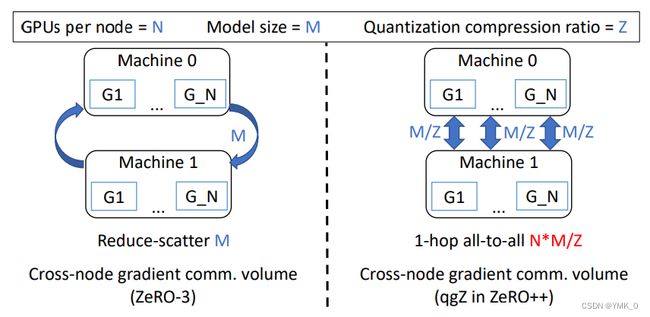
从上图可以看出,基于 Reduce-Scatter 的 ZeRO3 跨机通信量为 M,而基于 1-hop all-to-all 的算法跨机通信量为 N * M / Z(其中 Z 为压缩比率,比如 FP16 量化为 INT8,也就是从 2 个字节压缩成 1 个字节,因此压缩比率为 2;由于每张卡都要发送压缩后的数据,所以需要对压缩后的数据乘上 N)。
相比于 Reduce-Scatter,1-hop all-to-all 的跨机通信总量大幅增加,因此需要进一步优化以减少跨机通信数据量。ZeRO++ 提出基于分层策略的 2-hop all-to-all 算法:
具体来讲,4步:
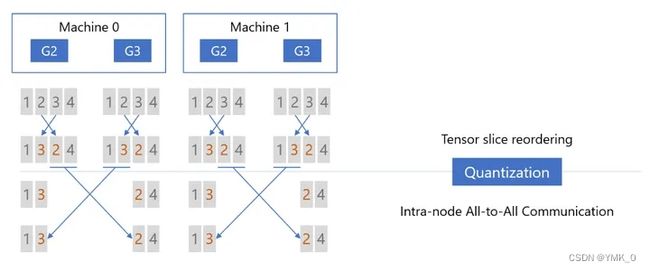
Step1: Tensor Slice Reordering(张量切片重排),重排的原因稍后解释,重排后进行量化(Quantizaiton),然后在节点内执行 All-to-All 通信:
Step2:在各个节点内部首先执行反量化(Dequantization),然后把反量化的结果相加(Reducetion),减小精度损失:
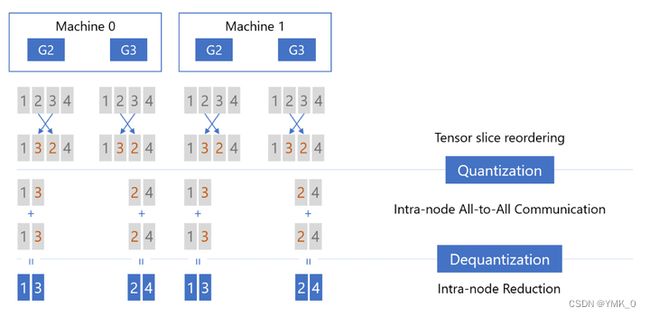
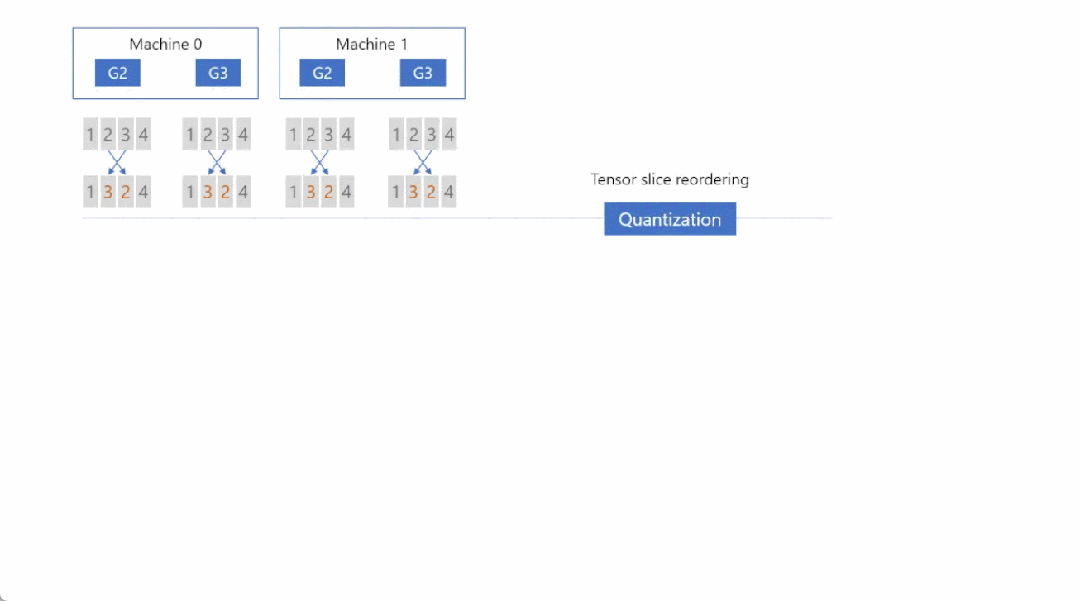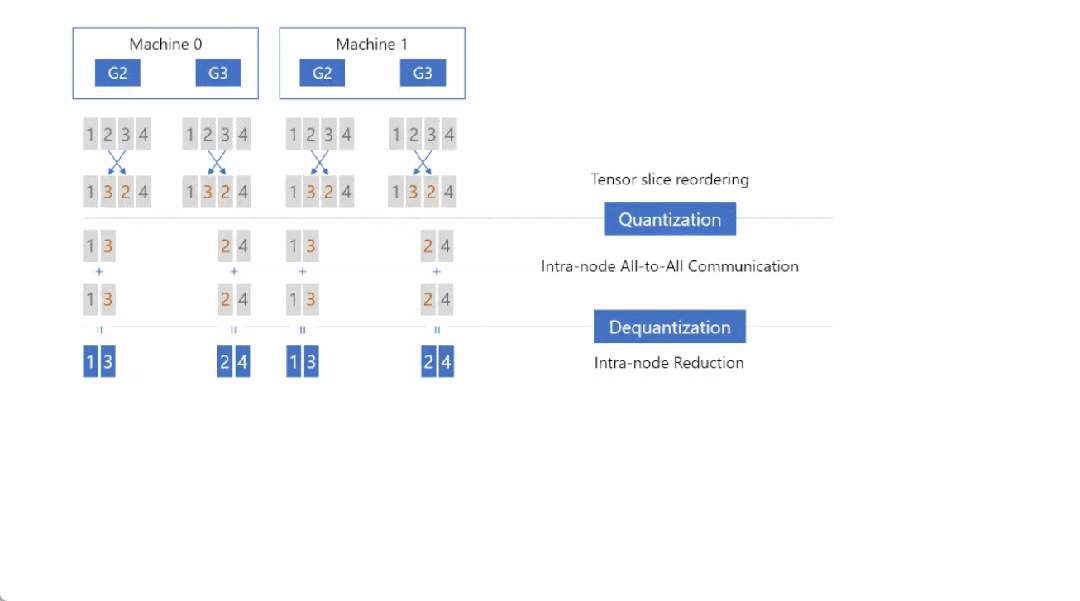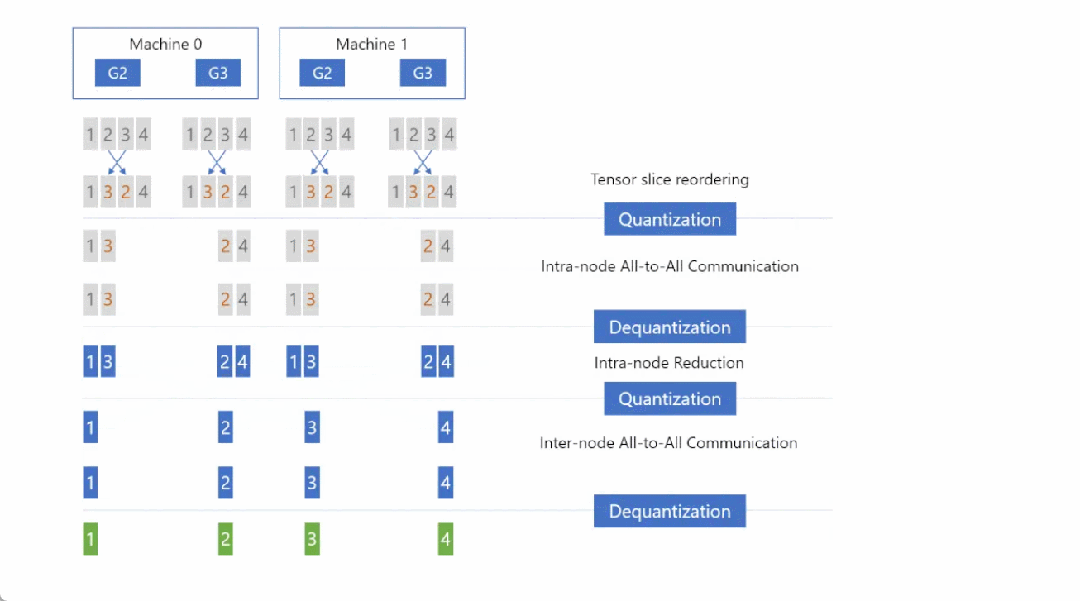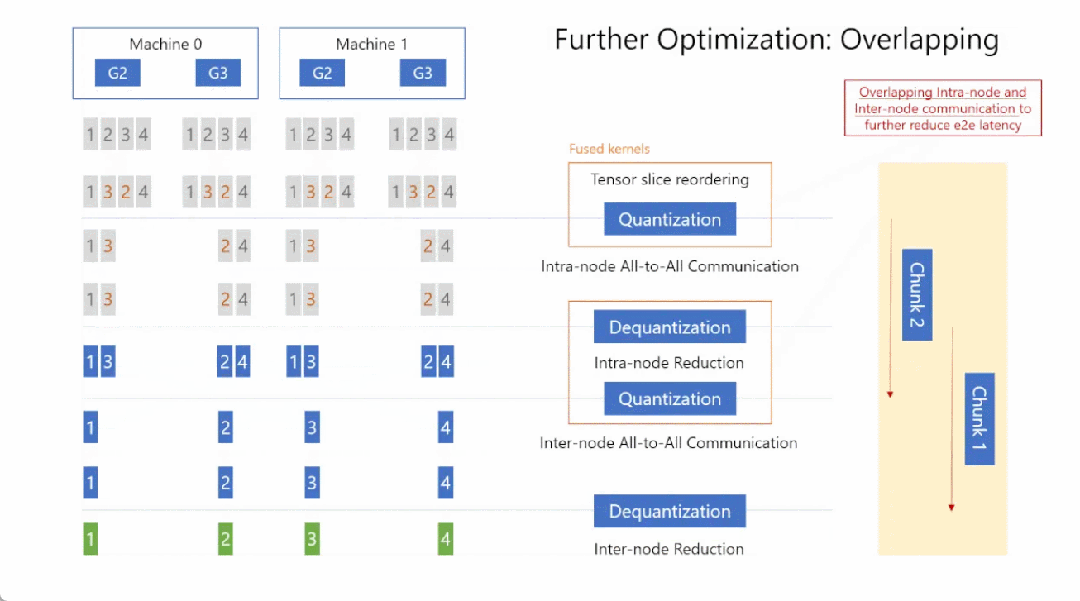
Step3:执行 Reduction 之后,再次对张量进行量化(Quantization),然后对量化后的结果执行第二次 All-to-All 通信,只不过这一次是节点间(以下图为例:Machine 0 的 G2 和 Machine 1 的 G2,Machine 0 的 G3 和 Machine 1 的 G3):

Step4:节点间 All-to-All 通信之后,首先进行反量化(Dequantization),然后执行 Reduction 操作,这时每张卡上都拿到了权重(Primary Parameters)对应的、平均后的梯度:

总体流程是这样
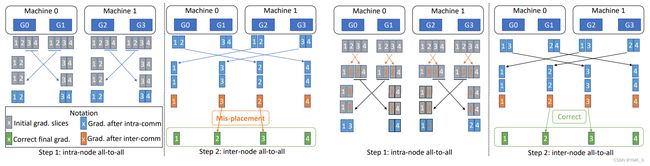
那么为什么要重排呢?可以看这张图,左边是(未重排)右边是(重排)
如果没有切片重排,两次 ALL-to-ALL 通信之后,每张卡上的张量切片无法与正确的切片顺序对齐。
接下来我们分析一下2-hop all-to-all ,节点间的通信开销

第一次 All-to-All 通信之后,总参数量从 M/Z 降到 M / (Z * N),其中 N 为每个节点的 GPU 个数;
第二次 All-to-All 通信每张卡发送的数据量为 M / ( Z * N),那么每台机器的跨机通信量就是 (N * M) / (Z * N) ,也就是 M / Z(FP16 -> INT4,所以是 0.25M)。
至此,已经完整介绍前向通信优化(qwZ),反向通信优化(hpZ),以及梯度通信优化(qgZ)。节点间通信量如下图:
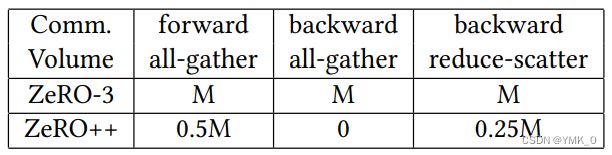
相比于 ZeRO,ZeRO++在前向时量化权重节省了一半的跨机通信量(PF16 -> INT8),后向时由于权重都已经存在本地节点,所以跨机通信量为 0,最后的梯度同步可减少 3/4 跨机通信量。