Hadoop概述
一、什么是Hadoop
二、Hadoop发展史
1.Hadoop创始人为Doug Cutting,为了实现与谷歌类似的全文搜索功能,他在Lucene框架基础上进行优化升级,查询引擎和索引引擎。
2.2001年年底Lucene成为Apache基金会的一个子项目。
3.对于海量数据的场景,Lucene框架面对与Google同样的困难,存储海量数据困难,检索海量数据速度慢。
4.学习和模仿Google解决这些问题的办法:微型版Nutch。
5.三篇论文可以说是Google是Hadoop的事项之源。(Google-Bigtable、Google-File-System、Google-MapReduce)
6.2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础DougCutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7.2005年Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
8.2006年3月份,Map-Reduce和NutchDistributed Files System(NDFS)分别被纳入到Hadoop项目中,Hadoop就此正式诞生,标志着大数据时代来临。
9.名字来源于Doug Cutting儿子的玩具大象。
三、Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera内部集成了很多大数据框架,对应产品CDH。2008
Hortonworks文档较好,对应产品HDP。2011
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP。
1.Apache Hadoop
官网地址:Apache Hadoop
下载地址:Apache Hadoop
2.Cloudera Hadoop
官网地址:CDH
下载地址:CDH 6 Download Information | 6.x | Cloudera Documentation
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司**。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
3.Hortonworks Hadoop
官网地址:Enterprise Data Management Platforms & Products | Cloudera
下载地址:Cloudera Enterprise Downloads
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)2018年Hortonworks目前已经被Cloudera公司收购。
四、Hadoop的优势
1.高可靠性
Hadoop底层维护多个数据父本,所以即使Hadoop某个元素或存储出现故障,也不会导致数据的丢失。
2.高扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
3.高效性
在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4.高容错性
能够自动将失败的任务重新分配。
五、Hadoop组成
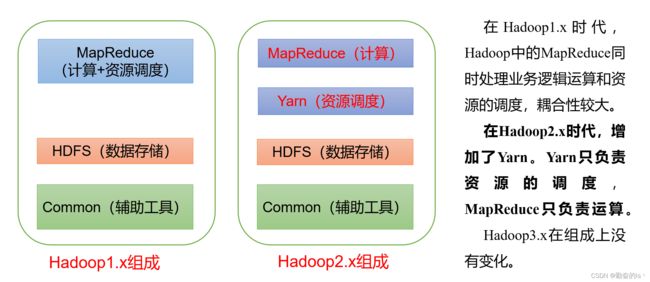
1.HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
a.NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限)、以及每个文件的块列表和块所在的DataNode等。
b.DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
c.SecondaryNameNode(2nn):每隔一段时间对NameNode元数据备份。
2.YARN架构概述
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。

3.MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
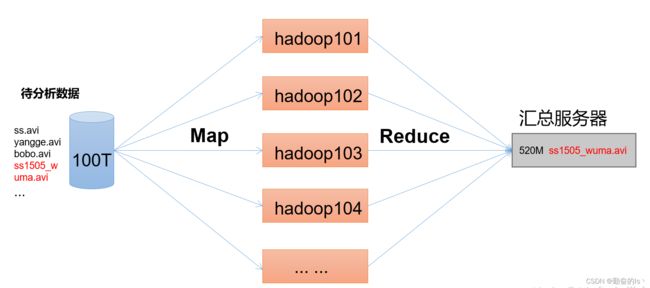
4.HDFS、YARN、MapReduce三者关系
5.大数据技术生态体系
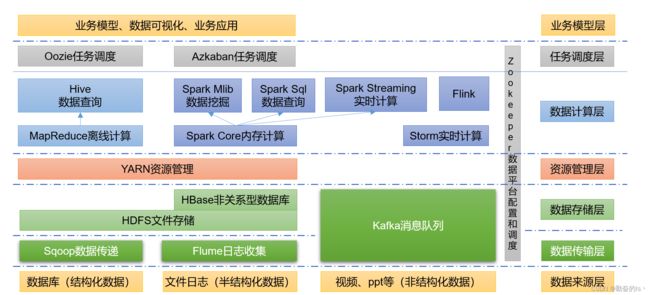
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
7.推荐系统框架图
