使用pytorch从零开始实现迷你GPT
生成式建模知识回顾:
[1] 生成式建模概述
[2] Transformer I,Transformer II
[3] 变分自编码器
[4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II
[5] 自回归模型
[6] 归一化流模型
[7] 基于能量的模型
[8] 扩散模型 I, 扩散模型 II
在本文中,我们将使用 PyTorch 构建一个类似于 GPT-3 的简单decoder-only transformer模型。我们将编写代码来定义模型架构(layers, modules and functions)、跑跑训练(包括损失计算和反向传播)和inference,以更好地理解像 GPT 这样的模型如何端到端工作。我们将在本文中使用 PyTorch 来利用其训练和推理功能。您可以在Github代码仓查看整篇文章的最终 Python 脚本。
注意:本文仅仅是 LLM 的(过度)简化版本,因此其唯一目的是了解更多有关为 LLM 提供支持的机制(例如 ChatGPT 背后的机制)的信息。
初始化
首先,让我们从导入所有依赖项(即我们将使用的组件)开始:
import torch # Import PyTorch
import torch.nn as nn # Import the NN (neural network) library from PyTorch
import torch.optim as optim # Import the optimizer (for training) from PyTorch
import pprint # Import Pretty Print Library for formatted output (Pprint)
数据和词汇
接下来,我们将从训练数据集和词汇开始。在这种情况下,词汇是指模型可以将其转换为数学表示并“理解”(即训练/推断)的标记(tokens, 或“单词(words)”)的集合。在实践中,像 GPT-3 这样的模型可以拥有大量词汇(即它可以“理解”大量“单词”或标记);然而,就本文而言,我们将仅使用一些硬编码的输入和输出文本序列构建一个训练数据集,然后使用这些文本序列中的所有单词以编程方式构建词汇表。
# Function to obtain training data, vocab and mapping from word to index and vice versa
def get_data_and_vocab():
# Define training data
training_data = {
"how are you": "i am fine " ,
"who is john": "a nice person " ,
"who is nice": "john " ,
"where is john": "at home " ,
"how is john": "i dont know " ,
"who are you": "mini gpt model "
}
# Extract input and target phrases
data_words = [k for k, _ in training_data.items()]
target_words = [v for _, v in training_data.items()]
# Build vocabulary from training data
vocabulary_words = list(set([element.lower() for nestedlist in [x.split(" ") for x in data_words] for element in nestedlist] + [element.lower() for nestedlist in [x.split(" ") for x in target_words] for element in nestedlist]))
# Ensure token is at the end of vocabulary list, and there's a blank at the beginning
vocabulary_words.remove("" )
vocabulary_words.append("" )
vocabulary_words.insert(0, "")
# Create mappings from word to index and index to word
word_to_ix = {vocabulary_words[k].lower(): k for k in range(len(vocabulary_words))}
ix_to_word = {v: k for k, v in word_to_ix.items()}
# Return all the necessary data and mappings
return training_data, data_words, target_words, vocabulary_words, word_to_ix, ix_to_word
在这里,您可以看到我们有 6 个输入文本序列及其相应的预期输出文本序列。然后,我们使用它来生成词汇表,以包含该数据集中可用的所有单词。出于本文的目的,我们将在这 6 个示例上训练我们的模型,然后尝试让我们的模型预测相同 6 个示例的输出序列,并看看我们的模型是否可以“学习”正确。显然,在实践中我们会有单独的验证集来计算模型的准确性;但是,只有当我们拥有大型数据集并且实际上正在训练要在实践中使用的模型时,这才有用。本文的目的是了解 GPT-3 或 GPT-4 等decoder-only transformer模型如何通过代码在非常小的规模上工作。
术语
在继续之前,我们将在这里定义一些单词和短语。这些将有助于理解本文的其余部分。
注意:这些定义是在本文的上下文中;这些单词和短语在不同的上下文中可能有不同的含义。
-
Token:token是指模型可以将其解释为一个唯一的嵌入向量的一个单独的“单词”。出于本文的目的,我们将互换使用“token”和“单词”这两个词,尽管这可能并不总是正确的。在训练复杂模型时,您可以使用多个单词或符号甚至单词的一部分来定义tokens(例如,GPT-3 可以使用其tokenization方案处理各种单词,包括罕见的和词汇表外的单词)。然而,在这个例子中,我们将为一个单词使用一个标记,因此我们可以同义地使用它们。
-
词汇表(Vocabulary):我们的词汇表是我们的模型可以操作的tokens(“单词”)列表(即理解为输入或在其输出中使用)。任何不在词汇表中的tokens如果存在于输入中,则无法被模型“理解”,并且永远不会出现在模型的输出中。该模型只能对可以数学“理解”的输入进行操作。像 GPT-3/4 这样的大型模型将具有非常大的词汇表,但对于我们的迷你 GPT 类模型显然不会出现这种情况。
-
文本序列(Text sequence):文本序列是按特定顺序(或序列)的tokens的集合(或列表)。我们模型的输入是一个输入序列(例如“how are you”代表 3 个 token 的序列),我们模型的最终输出是输出序列(例如“i am Fine”代表 3 个 token 的序列)。
-
词汇索引(Vocabulary Index):词汇表中特定单词/token的唯一索引(整数)(例如“how”在词汇表中可以具有索引1,而“are”可以具有索引2)。将其视为代表特定单词/token的一个整数。如果词汇表有 100 个单词或标记,则每个标记将有一个介于 0 到 99 之间的唯一词汇索引。注意: “Indices”是“index”的复数;因此词汇索引将引用这些整数的集合,使用词汇索引整数而不是文本/字符串表示文本序列。
文本序列的转换
现在,我们定义了检索数据集和词汇的函数。我们现在将定义两个辅助函数,以帮助将表示以文本/字符串形式编写的“单词”集合的文本序列转换为将进入模型的相应张量。
在我们的模型中,文本序列转换为数学表示的方式遵循以下顺序:“how are you?” -> [1, 2, 3] -> [[0.12, 0.33, 0.44], [0.25, 0.60, 0.11], [0.33, 0.44, 0.45]。第一步是将每个单词/token转换为其词汇表中定义的词汇索引(在此示例中,假设“how”映射到索引 1,“are”映射到索引 2,“you”映射到索引 3)。稍后我们将进行第二步(即将这些索引[1,2,3]转换为嵌入向量[[0.12, 0.33, 0.44], [0.25, 0.60, 0.11], [0.33, 0.44, 0.45]]);第二步是生成将在模型内部发生的嵌入。
下面给出第一步转换的代码(字符串文本序列到词汇索引张量):
# Function to convert a batch of sequences of words to a tensor of indices
def words_to_tensor(seq_batch, device=None):
index_batch = []
# Loop over sequences in the batch
for seq in seq_batch:
word_list = seq.lower().split(" ")
indices = [word_to_ix[word] for word in word_list if word in word_to_ix]
t = torch.tensor(indices)
if device is not None:
t = t.to(device) # Transfer tensor to the specified device
index_batch.append(t)
# Pad tensors to have the same length
return pad_tensors(index_batch)
# Function to convert a tensor of indices to a list of sequences of words
def tensor_to_words(tensor):
index_batch = tensor.cpu().numpy().tolist()
res = []
for indices in index_batch:
words = []
for ix in indices:
words.append(ix_to_word[ix].lower()) # Convert index to word
if ix == word_to_ix["" ]:
break # Stop when token is encountered
res.append(" ".join(words))
return res
# Function to pad a list of tensors to the same length
def pad_tensors(list_of_tensors):
tensor_count = len(list_of_tensors) if not torch.is_tensor(list_of_tensors) else list_of_tensors.shape[0]
max_dim = max(t.shape[0] for t in list_of_tensors) # Find the maximum length
res = []
for t in list_of_tensors:
# Create a zero tensor of the desired shape
res_t = torch.zeros(max_dim, *t.shape[1:]).type(t.dtype).to(t.device)
res_t[:t.shape[0]] = t # Copy the original tensor into the padded tensor
res.append(res_t)
# Concatenate tensors along a new dimension
res = torch.cat(res)
firstDim = len(list_of_tensors)
secondDim = max_dim
# Reshape the result to have the new dimension first
return res.reshape(firstDim, secondDim, *res.shape[1:])
这里我们有 3 个函数。第一个函数words_to_tensor接受文本序列(字符串)列表,并使用词汇索引将它们转换为表示所有这些字符串/序列的张量。由于文本序列可以具有不同的长度,因此在转换为张量之前将它们全部转换为相同的长度非常重要(因为张量具有固定的维度)。为此,包含每个序列的词汇索引的数组用 0 填充,以使其等于最长文本序列的大小(因此所有序列具有相同的大小)。例如:[“hello”, “how are you”, “are you”] -> [[4, 0, 0], [1, 2, 3], [2, 3, 0]]。请注意表示每个字符串的词汇索引如何具有相同的长度(在本例中为 3),即使它们实际上可能包含更少的单词(少于 3 个)。我们在最后添加了零(第一个序列有 2 个零,因为它只有 1 个标记;最后一个序列有 1 个零,因为它有 2 个标记),以弥补较短的长度并将所有词汇索引数组放入大小相同(所有序列的最大长度)。这里的数字 3 代表最长序列的长度(在本例中为“how are you”)。此过程称为零填充。
第二个函数的作用tensor_to_words与第一个函数的作用相反。它采用使用词汇索引表示数字格式的文本序列列表的张量,并将其转换为文本序列(字符串)列表。
注意:包含词汇索引序列和文本/字符串序列列表的张量本质上表示相同的信息,并且具有一对一的映射关系(即,您可以轻松地将一个映射到另一个)。张量只是文本序列的数学表示。
第三个函数pad_tensors用在第一个函数中。它确保表示每个序列的数组都用零填充,以使其与每个其他序列的长度相同(等于列表中最长序列的长度)。然后,它使用所有填充的词汇索引序列构造一个更大的张量(成为第一个函数的输出)。
Self-Attention
现在我们已经拥有了处理数据转换和词汇的大部分辅助函数,我们将从迷你 GPT 类模型的第一个模块开始。我们将定义网络中自注意力模块的架构。
在开始之前,请记住我们的自注意力模块接收什么作为输入以及产生什么作为输出:
- 输入:一批输入序列,其中每个序列表示为向量集合,每个向量代表每个标记。注意:在这种情况下,标记由向量表示,而不是由词汇索引表示(我们将在本文后面介绍该过程)。该张量的维度将是(batch_size x max_token_count x embed_size)其中max_token_count表示最长序列的长度并embed_size表示位置编码嵌入向量的大小。
- 输出:自注意力层的输出是输入的转换版本,与输入具有相同的维度。本质上,您最终会得到一个代表一批文本序列的张量,其中每个序列都表示为向量的集合(每个向量代表每个标记)。然后,该输出可能会进入另一个自注意力层。
话虽如此,下面给出该模块的初始化代码 :
# Define Self-Attention module
class SelfAttention(nn.Module):
def __init__(self, embed_size, head_count):
super(SelfAttention, self).__init__()
self.embed_size = embed_size # Size of word embeddings
self.head_count = head_count # Number of attention heads
# Create linear layers for query, key and value projections for each head
self.query_layers = nn.ModuleList([nn.Linear(embed_size, embed_size, bias=False) for _ in range(head_count)])
self.key_layers = nn.ModuleList([nn.Linear(embed_size, embed_size, bias=False) for _ in range(head_count)])
self.value_layers = nn.ModuleList([nn.Linear(embed_size, embed_size, bias=False) for _ in range(head_count)])
self.fc_out = nn.Linear(head_count * embed_size, embed_size) # Final linear layer to combine head outputs
让我们了解我们正在初始化什么,因为这是我们的自注意力模块的基础。首先,我们初始化各种线性(全连接)层,称为查询层(Q)、键层(K)和值层(V)。我们本质上是为每个注意力头定义一个查询、一个键和一个值层。什么是注意力头?注意力头是一个独立的自注意力子模块,它为每个输入序列(和token)计算自己的输出向量。通过在每一层有多个注意力头,我们可以并行且独立地计算每个输入序列的多个注意力输出。一旦我们从自注意力层中的不同注意力头获得了这些不同的注意力输出,我们就将其传递到最终的全连接层,该层将每个序列(和token)的不同注意力头的输出组合成每个序列和token的一个最终输出向量。
本质上,我们从输入维度(batch_size x max_token_count x embed_size)到初始输出维度(head_count x batch_size x max_token_count x embed_size)(其中每个注意力头都有自己的一组输出;因此我们在前面有一个额外的维度),再(batch_size x max_token_count x embed_size)通过使用全连接层组合来自不同注意力头的输出。我们将在自注意力模块的forward方法中看到它的实际效果。
这是自注意力模块的其余代码 :
class SelfAttention(nn.Module):
def __init__(self, embed_size, head_count):
# ...
# (same as last one)
def forward(self, embeddings):
batch_size, token_count = embeddings.shape[:2]
qkvs = torch.zeros(self.head_count, 3, batch_size, token_count, self.embed_size).to(embeddings.device)
# Loop over heads and compute query, key and value projections
for i in range(self.head_count):
qkvs[i, 0] = self.query_layers[i](embeddings)
qkvs[i, 1] = self.key_layers[i](embeddings)
qkvs[i, 2] = self.value_layers[i](embeddings)
# Compute energy terms for each head, batch, and pair of tokens
energy = torch.zeros(self.head_count, batch_size, token_count, token_count).to(embeddings.device)
# Create a mask with false on and below the diagonal, and true above the diagonal
mask = torch.triu(torch.ones((token_count, token_count)), diagonal=1).bool()
for h in range(self.head_count):
for b in range(batch_size):
for i in range(token_count):
for j in range(token_count):
energy[h, b, i, j] = torch.dot(qkvs[h, 0, b, i], qkvs[h, 1, b, j])
energy[h, b] = energy[h, b].masked_fill(mask, float('-inf')) # Apply mask
# Compute attention scores
attention = torch.nn.functional.softmax(energy, dim=3)
# Compute weighted sum of values for each head and token
out = torch.zeros(batch_size, token_count, self.head_count, self.embed_size).to(embeddings.device)
for h in range(self.head_count):
for b in range(batch_size):
for i in range(token_count):
for j in range(token_count):
out[b, i, h] += (attention[h, b, i, j] * qkvs[h, 2, b, j])
# Reshape and pass through final linear layer
out = out.reshape(batch_size, token_count, self.head_count * self.embed_size)
return self.fc_out(out)
然后我们计算每个单词相对于其他单词的能量得分。能量只是单词的查询向量和单词的键向量(本身或任何其他单词)之间的点积。能量分数的总数和张量的维度energy是head_count x batch_size x max_token_count x max_token_count(其中最后两个维度表示序列中所有token的能量分数,其中序列中的所有tokens - 重复的max_token_count;3 消失了,因为现在我们不存储查询、键和值向量分别在此张量中)。在能量得分计算过程中,我们还应用了一个掩码,torch.triu如上所示,以确保最终张量仅包含每个单词及其自身及其前面的单词的能量得分(以及一个单词及其后面的其他单词作为掩码的能量得分)到一个-inf 值,以便在 softmax 之后注意力分数最终为零)。这个过程被称为掩码自注意力(masked self-attention)。
一旦我们的energy张量填充了能量分数,我们就沿着张量的第三个维度应用softmax(包含给定token相对于序列中每个其他标记的屏蔽注意力分数)来计算每个token的注意力分数,使得它们加起来为 1.0(对于每个单独的token)。attention张量与energy张量具有相同的维度- head_count x batch_size x max_token_count x max_token_count。请记住,该张量中的第三维表示序列中每个标记的向量集合,它表示该标记相对于所有其他单词的注意力分数。
在此阶段,我们的注意力张量包含所有序列中所有标记的所有注意力分数。然后,我们使用这些注意力分数来计算每个token的值向量的加权和,并通过该token相对于另一个token的注意力值进行加权。例如,对于第 N 个单词,我们计算(attention_wordN_word1 x word1_value_vector) + (attention_wordN_word2 x word2_value_vector) … + (attention_wordN_wordN x wordN_value_vector)。
这给了我们一个大小的输出张量head_count x batch_size x max_token_count x embed_size,因为序列中的每个token都会得到一个新向量(该向量的大小是embed_size因为该模型中的所有值向量都具有该大小,因此值向量的加权和也具有相同的大小)。
然后,我们重塑这个输出张量,并将其输入到完全连接/线性层,以组合来自各个自注意力头的输出。该层为我们提供了最终的维度输出张量(batch_size x max_token_count x embed_size),它形成了自注意力模块的输出(再次注意:自注意力模块的最终输出与输入张量具有相同的维度)。
Transformer Block
这是我们要讨论的第二个模块。它本质上是自注意力模块的一个封装,并且具有一些附加层。下面给出该模块的代码:
# Define Transformer block module
class TransformerBlock(nn.Module):
def __init__(self, embed_size, head_count):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, head_count) # Self-attention layer
self.norm1 = nn.LayerNorm(embed_size) # Layer normalization
self.norm2 = nn.LayerNorm(embed_size) # Layer normalization
# Feed-forward neural network
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, embed_size),
nn.ReLU(),
nn.Linear(embed_size, embed_size)
)
def forward(self, embeddings):
attention = self.attention(embeddings)
# Apply residual connections and layer normalization
out = self.norm1(attention + embeddings)
out = attention + self.feed_forward(out)
out = self.norm2(out)
return out
该层接受embeddings维度的输入张量(batch_size x max_token_count x embed_size)(与其上面的自注意力模块相同)。然后它在输入上应用自注意力模块。然后,它将自注意力模块的输出与输入嵌入(称为残差连接或跳跃连接)相加,成为残差连接的输出。这个加法操作本质上是将输入中的信息与自注意力模块提取的信息结合起来;这种跳跃连接的想法首先由 Microsoft 在ResNet架构中引入,并已被证明可以缓解深度神经网络中的梯度消失问题(超出了本文的范围)。
然后,Transformer Block模块对残差连接的输出应用归一化,然后是具有ReLU(整流线性单元)激活的线性变换(全连接层),另一个线性变换(全连接层),然后是最后一层归一化它返回 Transformer Block 的输出,其尺寸与其输入相同(batch_size x max_token_count x embed_size)。
为什么我们称其为Transformer Block?嗯,这是Transformer 架构中使用的独立操作block(自注意力头和组合输出)。我们可以将多个block堆叠在一起,其中第一个block接受带有位置编码嵌入的输入张量,并且该块的输出作为输入进入下一个块,然后该块的输出作为下一个block输入,一直持续到最顶层的block。其效果良好的原因是每个block的输入维度和输出维度是相同的。
Transformer(放在一起)
我们首先定义了 Self-attention 模块,然后用它来定义 Transformer Block 模块。在实践中,像 GPT-3 或 GPT-4 这样的模型将具有多个 Transformer Block 模块层(取决于我们决定的架构),其中第一个块的输入将是每个输入序列中每个标记的位置编码嵌入向量。我们模型的最终输出应该是一个大小向量(即我们词汇表中的单词数量),因为它将包含我们词汇表中每个单词成为下一个单词(预测单词)vocab_size的概率。所有这些都集中在我们的最后一个模块——Transformer 中。
__init__这是我们的 Transformer 模块上的函数代码:
# Define Transformer module
class Transformer(nn.Module):
def __init__(self, vocab_size, embed_size, num_layers, head_count):
super(Transformer, self).__init__()
self.embed_size = embed_size # Size of word embeddings
self.vocab_size = vocab_size # Size of vocabulary
self.word_embedding = nn.Embedding(vocab_size, embed_size) # Embedding layer
# List of transformer blocks
self.layers = nn.ModuleList(
[TransformerBlock(embed_size, head_count) for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size, vocab_size) # Final linear layer to produce logits
Transformer 模块使用embed_size我们想要用于模型的嵌入大小(这将是表示通过 Transformer 块的每个序列中的每个标记的向量的大小)和词汇表大小vocab_size(我们从我们拥有的词汇表中获得)进行初始化。使用我们的数据集创建)。
接下来,我们创建一个嵌入层。该层接收表示为词汇索引集合的输入序列(记住我们将单词翻译为词汇索引),然后将它们转换为固定大小的嵌入向量的集合(序列中的每个标记或单词一个;这是我们的自注意力模块最终如何获得每个单词的向量,而不是词汇索引)。这种转换(词汇索引到向量)是我们之前在文本序列转换部分中提到的嵌入生成的第二步。请记住,文本序列(字符串中单词的集合)会被转换为词汇索引序列,然后需要将其转换为嵌入向量序列。该层将为每个输入序列中的每个标记/单词生成嵌入向量。嵌入向量的大小embed_size(如我们的架构中决定的)。每个单词都会有自己独特的嵌入向量。
我们还在 Transformer 初始化器中初始化了几个 Transformer Block 模块,这些模块将在输入上堆叠多层自注意力和线性变换(类似于我们在 Transformer Block部分中描述的方式)。我们决定架构的层数num_layers,Transformer 模块初始化许多 Transformer 块(堆叠在另一个块的顶部),其中输入嵌入进入第一个块,其输出进入第二个块作为输入,这种情况一直持续到最后一个 Transformer Block 产生尺寸为 的输出(batch_size x max_token_count x embed_size)。
最后,我们初始化模型的最后一个线性/全连接层,该层预测词汇表中所有单词成为下一个单词的机会(机会最大的那个最终成为输出)。请注意这个完全连接的层如何为每个大小的输入序列接收一个向量embed_size来生成其输出向量vocab_size(表示每个单词成为下一个单词的机会)。一旦我们通过变压器块完成了所有单词上的所有标记的运行,我们只使用代表每个序列中最后一个标记/单词的输出向量来输入到最后的线性层并预测下一个单词。当我们实现该功能时,您将看到这句话是如何实现的forward函数。
这是forward函数的代码:
class Transformer(nn.Module):
def __init__(self, vocab_size, embed_size, num_layers, head_count):
# same as before
def forward(self, input_tokens, mask=None):
batch_size, token_count = input_tokens.shape[:2]
out = self.word_embedding(input_tokens) # Obtain word embeddings
# Compute position encodings and add to word embeddings
positions = torch.arange(0, token_count).expand(batch_size, token_count).to(input_tokens.device)
position_encoding = self.position_encoding(positions, self.embed_size)
out += position_encoding.reshape(out.shape)
# Pass through each transformer block
for layer in self.layers:
out = layer(out)
# Produce logits for the final token in each sequence
out = self.fc_out(out[:, -1, :].reshape(batch_size, self.embed_size)).reshape(batch_size, self.vocab_size)
return torch.nn.functional.softmax(out, dim=1) # Apply softmax to obtain probabilities
def position_encoding(self, positions, embed_size):
# to be added later
这里发生了什么?好吧,我们从张量开始input_tokens,它将模型的输入序列表示为词汇索引(即序列中每个标记/单词的一个整数词汇索引)。该张量具有维度batch_size x max_token_count(对于每个输入序列以及该序列中的每个标记,我们有一个表示其词汇索引的整数值)。
当我们将此输入张量传递给我们的word_embedding层时,我们最终得到一个大小的张量batch_size x max_token_count x embed_size(嵌入层用大小的向量替换每个词汇索引embed_size,以使用唯一的固定大小向量表示每个单词/标记)。
完成后,我们现在必须以某种方式将单词位置信息插入到该向量中 - 即以序列中每个单词的位置(例如“hello world”->“hello;position 1”,“世界;位置 2”)也在数学上合并到向量中。我们将使用 Google 的《Attention Is All You Need》论文中提出的相同技术来完成此操作(尽管还有其他方法可以实现)。我们不会详细介绍它的工作原理,但本质上它在嵌入向量的每个维度上具有不同波长的单词位置上使用正弦和余弦函数的值。正如您在上面看到的,我们有一个函数存根,它本质上返回一个大小为位置编码的张量batch_size x max_token_count x embed_size(与所有序列的嵌入张量相同的维度)。
一旦我们有了位置编码张量,我们就把它添加到我们的嵌入张量中以创建一个位置编码嵌入张量(因为张量共享相同的维度,所以加法很容易)。现在我们有了第一个变压器块的输入。
此时,我们的模型仅采用位置编码的嵌入张量,将其传递到第一个转换器块,该块的输出进入下一个转换器块作为输入,这样一直持续到我们的最终转换器块。最后,我们得到了尺寸为 的最后一个变压器块的最终输出batch_size x max_token_count x embed_size。
正如您在代码中看到的,然后我们通过执行out[:, -1, :](注意-1中间,为每个序列选择最后一个标记/单词)获取每个序列的最后一个单词的输出向量,并将其传递到最终的线性/完全连接层来预测词汇表中每个单词/标记成为下一个单词/标记的机会。最后一层输出维度为 的张量batch_size x vocab_size。然后我们通过每个序列的softmax函数运行它,得到相同大小的最终输出张量batch_size x vocab_size。对于输入中的每个序列,最终的输出张量包含词汇表中每个单词成为序列中下一个单词的 0 到 1 之间的概率分数。就是这样!这就是我们的迷你 GPT 模型的工作原理。
位置编码
这是实现位置编码的代码。如前所述,它使用三角函数来计算包含位置信息的向量。我们不会对此进行更多详细介绍,因为它超出了本文的范围。
class Transformer(nn.Module):
def __init__(self, vocab_size, embed_size, num_layers, head_count):
# ...
# same as before
# Input tokens represent a tensor of size batch size x token count (the contents are the index of the word in vocab)
def forward(self, input_tokens, mask=None):
# ...
# same as before
def position_encoding(self, positions, embed_size):
# Compute position encoding for each position and dimension
angle_rads = self.get_angles(
positions.unsqueeze(2).float(),
torch.arange(embed_size)[None, None, :].float().to(positions.device),
embed_size
)
sines = torch.sin(angle_rads[:, :, 0::2]) # Compute sine of angle for even dimensions
cosines = torch.cos(angle_rads[:, :, 1::2]) # Compute cosine of angle for odd dimensions
pos_encoding = torch.cat([sines, cosines], dim=-1) # Concatenate sine and cosine values
pos_encoding = pos_encoding[None, ...]
return pos_encoding
def get_angles(self, pos, i, embed_size):
# Compute angle rate for each position and dimension
angle_rates = 1 / torch.pow(10000, (2 * (i//2)) / embed_size)
return pos * angle_rates
推理(从我们的模型生成输出)
下面是我们将用于使用我们的模型运行推理的代码(即使用我们的模型进行预测) :
# Input: PyTorch model, input tensor (batch_size x max_token_count)
# and max_output_token_count (when to stop if not encountered)
# Function to perform inference recursively for each sequence in a batch
def infer_recursive(model, input_vectors, max_output_token_count=10):
model.eval() # Set model to evaluation mode
outputs = []
# Loop over sequences in the batch
for i in range(input_vectors.shape[0]):
print(f"Infering sequence {i}")
input_vector = input_vectors[i].reshape(1, input_vectors.shape[1])
predicted_sequence = []
wc = 0 # Initialize word count
with torch.no_grad(): # Disable gradient computation
while True:
output = model(input_vector) # Pass current input through model
predicted_index = output[0, :].argmax().item() # Get index of predicted token
predicted_sequence.append(predicted_index) # Append predicted index to sequence
# Stop when token is predicted or the maximum output length is reached
if predicted_index == word_to_ix['' ] or wc > max_output_token_count:
break
# Append predicted token to input and increment word count
input_vector = torch.cat([input_vector, torch.tensor([[predicted_index]])], dim=1)
wc += 1
outputs.append(torch.tensor(predicted_sequence)) # Append predicted sequence to outputs
outputs = pad_tensors(outputs) # Pad predicted sequences to the same length
return outputs
我们的推理函数接受 PyTorch 模型(它是Transformer上面定义的模块的实例,包含多个 Transformer 块)、输入张量和最大输出令牌限制的配置参数。输入张量是有维度的batch_size x max_token_count,包含用词汇索引表示的序列集合。本质上,在调用之前,infer_recursive我们必须将words_to_tensor输入文本序列(字符串)转换为这种输入张量。
它对每个序列一一运行推理(这并不理想,但在本文中用于简化代码和解释)。对于每个序列,该函数首先将该序列的输入张量和维度输入1 x max_token_count模型中,并预测紧邻的下一个标记/单词。一旦有了下一个单词/标记,它就会将其添加到输入张量中,输入张量现在具有维度1 x (max_token_count + 1),并将其传递通过模型以预测输出中的第二个单词/标记。随着模型处理越来越长的输入序列,此过程继续进行,直到模型输出(结束标记)或达到限制max_output_token_count。
换句话说,该函数从输入张量开始递归调用模型,然后将每个预测的输出单词添加到该张量并再次运行它以预测下一个(依此类推)。举个例子,考虑一下这个——
- 输入到模型:how are you; 模型输出:i
- 输入到模型:how are you i; 模型输出:am
- 输入到模型中:how are you i am;模型输出:fine
- 输入到模型中:how are you i am fine;模型输出:
显然,该模型采用词汇索引而不是文本单词,并输出词汇表中每个单词成为下一个单词的概率,但其递归调用中输入和输出的底层文本表示将与上面类似。
那么维度模型的输出向量如何1 x vocab_size转换为单个单词呢?我们使用argmax,它告诉我们哪个单词的词汇索引代表最有可能成为下一个单词/标记的单词。然后可以用它来找出该单词的文本表示形式。
在上面的代码中,predicted_sequence跟踪来自argmax一个特定输入序列的所有输出单词(按顺序表示为使用 获取的词汇索引)。一旦完成递归循环,它将输入序列的完整输出序列添加到列表中outputs。然后,该列表被转换为维度的填充张量batch_size x max_output_token_count,并作为推理结果返回(包含每个输入序列的相应输出序列)。
然后我们可以使用tensor_to_words函数将此输出转换为文本序列(字符串)列表。
下面是一个带有不同示例的图表,用于演示推理如何工作:
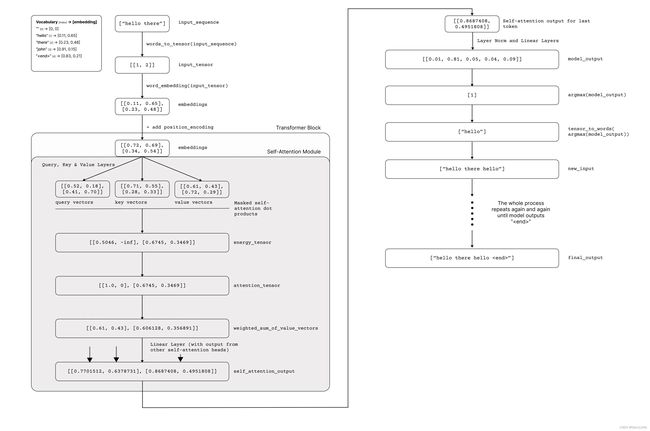
训练
现在我们正处于这个过程中最复杂的部分:训练!
让我们从代码开始——
# Input: PyTorch model (Transformer module),
# data: input tensor (batch_size x max_token_count)
# targets: ground truth/expected output tensor (batch_size x max_token_count)
# optimizer: PyTorch optimizer to use and criterion (which loss function to use)
# Function to train the model recursively over each sequence and token
def train_recursive(model, data, targets, optimizer, criterion):
model.train() # Set model to training mode
optimizer.zero_grad() # Zero the gradients
total_loss = 0 # Initialize total loss
batch_size, token_count, token_count_out = data.shape[0], data.shape[1], targets.shape[1]
# Loop over sequences in the batch
for b in range(batch_size):
end_encountered = False
cur_count = 0
# Loop over tokens in the sequence
while not end_encountered:
target_vector = torch.zeros(model.vocab_size).to(data.device) # Initialize target vector
if cur_count != token_count_out:
expected_next_token_idx = targets[b, cur_count] # Get index of expected next token
target_vector[expected_next_token_idx] = 1 # Set the corresponding element of the target vector to 1
# Concatenate current input and output tokens and pass through model
if cur_count > 0:
model_input = data[b].reshape(token_count).to(data.device)
part_of_output = targets[b, :cur_count].to(data.device)
model_input = torch.cat((model_input, part_of_output))
else:
model_input = data[b]
out = model(model_input.reshape(1, token_count + cur_count))
# Compute loss and accumulate total loss
loss = criterion(out, target_vector.reshape(out.shape))
total_loss += loss
cur_count += 1
# Stop when the end of the sequence is reached
if cur_count > token_count_out:
end_encountered = True
# Backpropagate gradients and update model parameters
total_loss.backward()
optimizer.step()
return total_loss.item() / batch_size
Transformer训练函数将所有训练数据和目标(预期输出)数据以及 PyTorch 模型(模块实例)、优化器(使用哪种数学优化算法)和标准(使用哪种损失函数)作为输入。然后,它将 PyTorch 置于训练模式并将权重梯度(将用于在训练期间进行权重更新)初始化为零。
注意:梯度下降是一个复杂的数学过程,用于训练深度神经网络,不属于本文的讨论范围。不过,我们将探讨如何通过 PyTorch 在该模型中使用该过程。
就像推理函数一样,我们一次对这个模型运行一个序列的训练(尽管权重更新最终发生在整个批次中,total_loss.backward()并且optimizer.step()损失是在批次中的所有序列中累积的)。
我们将通过示例文本序列来了解此过程的工作原理。假设序列是“how are you”,预期输出是“i am Fine ”(带有结束标记)。还假设模型尚未完全具备能力,因此它会犯错误并使用“i am ”进行响应(即,它将跳过最后一个单词并仅输出“i am”)。以下是第一个for循环内的训练过程的工作原理 -
-
该模型将被输入“how are you”作为输入
-
模型将输出单词“i”上概率最高的向量;损失将根据模型的输出和目标向量计算,其中所有单词的概率为 0,“i”的概率为 1.0。即使预测是正确的,这仍然会产生一些损失,因为模型对于其他单词可能具有非 0 概率,并且对于“i”具有 <1.0 概率(即使它是最高概率)。这个损失将被添加到total_loss(这里产生的损失会很低)。
-
然后模型将被输入“how are you i”作为输入。然后,模型将输出单词“am”概率最高的向量。与步骤 2 类似,将根据该向量和所有单词均为 0、单词“am”为 1.0 的向量计算损失。这个损失将被添加到total_loss(这里产生的损失会很低)。
-
然后,模型将被输入“how are you i am”作为输入,然后模型将输出单词“”(结束标记)上概率最高的向量。与步骤 2 和 3 类似,将根据该向量和目标向量计算损失,其中所有单词的概率为 0,单词“fine”的概率为 1.0。该损失将比步骤 2 和 3 的损失高得多,因为模型的输出在错误标记上具有最大概率,并且将被添加到total_loss。
-
然后,模型将被输入“how are you i am fine”(即到目前为止的正确单词序列),并且它将预测一个空字符串“”。与步骤 4 类似,这里的损失会很高,因为模型预计会在这个位置输出“”。这也将被添加到total_loss
-
该模型将为所有序列重复步骤 1-5(或根据每个序列中的单词数量根据需要重复步骤),并且模型所犯的所有“错误”都将以数学方式记录到变量中total_loss。
-
一旦完成整个批次,模型将使用total_loss.backward()(计算dL/dw其中w是权重参数,L是总损失)计算整个模型中所有权重/参数的权重梯度。然后,模型将使用 来对所有权重参数(通过 或lr学习率)在梯度的相反方向上执行权重更新optimizer.step()。
-
然后,它将返回在此过程中计算出的批次的平均损失。(这仅用于记录目的;函数返回什么并不重要)
这样,模型递归地预测下一个单词,并通过将其与每个输入序列的预期下一个单词进行比较来计算损失(循环预测输出序列中的每个单词)。然后,该损失会在批次中所有序列的所有预测令牌中累积,然后用于计算梯度并进行梯度更新(这就是模型“学习”的方式)。
如果您已经完成了这一步,那么恭喜您,现在是时候将所有内容整合在一起了!
使用以上所有内容进行训练和推理
现在,我们将编写一个函数来实际对示例数据集运行训练,然后对相同的训练输入序列运行推理,看看它是否可以匹配预期的输出序列(即看看它是否学习到)。
这是它的代码 –
# Function to demonstrate training and inference
def example_training_and_inference():
# Get model hyperparameters from vocabulary size
vocab_size = len(word_to_ix)
embed_size = 512
num_layers = 4
heads = 3
# Create model, optimizer, and loss function
device = torch.device("cpu")
model = Transformer(vocab_size, embed_size, num_layers, heads).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.00001)
criterion = nn.CrossEntropyLoss()
# Convert training data to tensors
data = words_to_tensor(data_words, device=device)
targets = words_to_tensor(target_words, device=device)
# Train model for 55 epochs
for epoch in range(55):
avg_loss = train_recursive(model, data, targets, optimizer, criterion)
print(f'Epoch {epoch + 1}, Loss: {avg_loss:.4f}')
# Perform inference on training data
input_vector = words_to_tensor(data_words, device=device)
predicted_vector = infer_recursive(model, input_vector)
predicted_words = tensor_to_words(predicted_vector)
# Print training data and model output
print("\n\n\n")
print("Training Data:")
pprint.pprint(training_data)
print("\n\n")
print("Model Inference:")
result_data = {data_words[k]: predicted_words[k] for k in range(len(predicted_words))}
pprint.pprint(result_data)
# Main function to call the demonstration function
if __name__ == "__main__":
# Get training data and vocabulary
training_data, data_words, target_words, vocabulary_words, word_to_ix, ix_to_word = get_data_and_vocab()
# Run the example training and inference function
example_training_and_inference()
该函数example_training_inference将利用上面定义的所有内容来训练我们的迷你 GPT 类模型,然后使用它进行推断。在底部,您会注意到我们在代码中调用该函数main(即,如果所有代码都放入 Python 文件中并在 Python 上运行,它将运行)。在该主块内,我们首先定义训练数据和词汇(以及文本和索引之间的词汇映射)。然后,我们调用该函数(它依赖上面的行来声明这些全局变量);我知道这是丑陋的代码,但可以满足本文的目的。
定义example_training_inference了模型中使用的嵌入大小(512在本例中)、要使用的层/变压器块的数量(4在本例中)以及每个块中自注意力头的数量(3在本例中)。
然后它使用我们的模块实例化模型Transformer。它还实例化了Adam训练/梯度下降的优化器(也用于 GPT-3 训练),并定义了使用交叉熵损失的损失函数——一种用于分类任务的流行损失函数;请记住,预测下一个单词在技术上是一项分类任务,因为我们试图“分类”或预测有限“类”列表(即我们的词汇表)中的下一个标记。然后我们在数据集(一批)上循环55 个时期(即我们在整个训练数据集上训练模型 55 次)。循环(或纪元)的每次迭代都调用train_recursive通过逐字预测输出序列来递归地训练我们的模型。
完成训练后,我们将样本数据中的输入文本序列转换为一个输入张量(使用words_to_tensor),并将其传递到模型中infer_recursive,以预测每个输入序列的输出序列。我们获取模型的输出并将其传递tensor_to_words以将输出转换为文本序列并将其存储在变量中predicted_words。然后,我们使用pprint(Pretty Print)将输入、预期输出和预测输出输出到 stdout,并查看模型的表现。
这是我在 55 个epochs得到的结果 –
Training Data:
{'how are you': 'i am fine ' ,
'how is john': 'i dont know ' ,
'where is john': 'at home ' ,
'who are you': 'mini gpt model ' ,
'who is john': 'a nice person ' ,
'who is nice': 'john ' }
Model Inference:
{'how are you': 'i ' ,
'how is john': 'i i i i i i i i i i i i',
'where is john': 'at home ' ,
'who are you': 'mini ' ,
'who is john': 'a nice person ' ,
'who is nice': 'john ' }
我的模型能够正确得出 6 个序列中的 3 个(where is john, who is john and who is nice)。你的可能会更好!就是这样——希望此时您能够更好地理解 GPT-4、Llama 或 PaLM 等现代大型语言模型 (LLM) 的工作原理。
您可以在此 Github Gist上找到本教程的完整代码。
注意:Github Gist 中包含本文代码的所有评论都是由 ChatGPT 添加的