ELK高级搜索,深度详解ElasticStack技术栈-下篇
前言:ELK高级搜索,深度详解ElasticStack技术栈-上篇
14. search搜索入门
14.1. 搜索语法入门
14.1.1 query string search
无条件搜索所有
GET /book/_search
结果:
{
"took" : 969,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
解释
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:到几个分片搜索,成功几个,跳过几个,失败几个。
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的所有详细数据
14.1.2 传参
与http请求传参类似
GET /book/_search?q=name:java&sort=price:desc
类比sql: select * from book where name like ’ %java%’ order by price desc
结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
},
"sort" : [
68.6
]
}
]
}
}
14.1.3 图解timeout
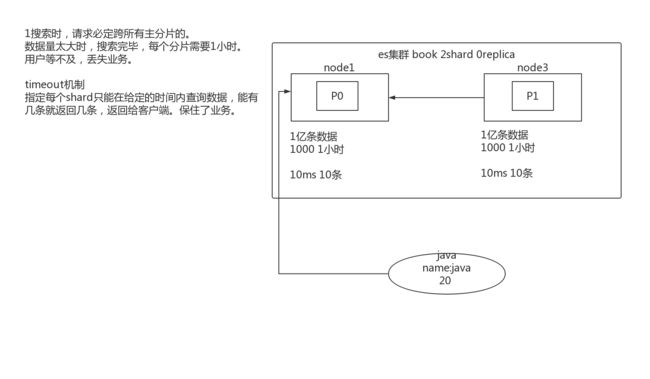
GET /book/_search?timeout=10ms
全局设置:配置文件中设置 search.default_search_timeout:100ms。默认不超时。
14.2. multi-index 多索引搜索
14.2.1 multi-index搜索模式
告诉你如何一次性搜索多个index和多个type下的数据
/_search:所有索引下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有的数据
/index1,index2/_search:同时搜索两个index下的数据
/index*/_search:按照通配符去匹配多个索引
应用场景:生产环境log索引可以按照日期分开。
log_to_es_20190910
log_to_es_20190911
log_to_es_20180910
14.2.2 初步图解一下简单的搜索原理
搜索原理初步图解
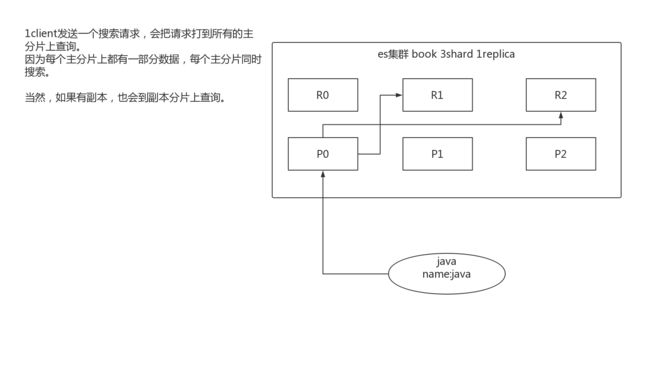
14.3. 分页搜索
14.3.1 分页搜索的语法
sql: select * from book limit 1,5
size,from
GET /book/_search?size=10
GET /book/_search?size=10&from=0
GET /book/_search?size=10&from=20
GET /book/_search?from=0&size=3
14.3.2 deep paging

什么是deep paging
根据相关度评分倒排序,所以分页过深,协调节点会将大量数据聚合分析。
deep paging性能问题
-
消耗网络带宽,因为所搜过深的话,各 shard 要把数据传递给 coordinate node,这个过程是有大量数据传递的,消耗网络。
-
消耗内存,各 shard 要把数据传送给 coordinate node,这个传递回来的数据,是被 coordinate node 保存在内存中的,这样会大量消耗内存。
-
消耗cup,coordinate node 要把传回来的数据进行排序,这个排序过程很消耗cpu。
所以:鉴于deep paging的性能问题,所有应尽量减少使用。
14.4. query string基础语法
14.4.1 query string基础语法
GET /book/_search?q=name:java
GET /book/_search?q=+name:java
GET /book/_search?q=-name:java
一个是掌握q=field:search content的语法,还有一个是掌握+和-的含义
- +:代表包含
- -:代表不包含
14.4.2 _all metadata的原理和作用
GET /book/_search?q=java
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的。
es中_all元数据。建立索引的时候,插入一条docunment,es会将所有的field值经行全量分词,把这些分词,放到_all field中。在搜索的时候,没有指定field,就在_all搜索。
举例
{
name:jack
email:[email protected]
address:beijing
}
_all : jack,[email protected],beijing
14.5. query DSL入门
14.5.1 DSL
query string 后边的参数原来越多,搜索条件越来越复杂,不能满足需求。
GET /book/_search?q=name:java&size=10&from=0&sort=price:desc
DSL:Domain Specified Language,特定领域的语言
es特有的搜索语言,可在请求体中携带搜索条件,功能强大。
-
查询全部
GET /book/_searchGET /book/_search { "query": { "match_all": {} } }结果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "book", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "Bootstrap开发", "description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。", "studymodel" : "201002", "price" : 38.6, "timestamp" : "2019-08-25 19:11:35", "pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg", "tags" : [ "bootstrap", "dev" ] } }, { "_index" : "book", "_type" : "_doc", "_id" : "2", "_score" : 1.0, "_source" : { "name" : "java编程思想", "description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。", "studymodel" : "201001", "price" : 68.6, "timestamp" : "2019-08-25 19:11:35", "pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg", "tags" : [ "java", "dev" ] } }, { "_index" : "book", "_type" : "_doc", "_id" : "3", "_score" : 1.0, "_source" : { "name" : "spring开发基础", "description" : "spring 在java领域非常流行,java程序员都在用。", "studymodel" : "201001", "price" : 88.6, "timestamp" : "2019-08-24 19:11:35", "pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg", "tags" : [ "spring", "java" ] } } ] } } -
排序
GET /book/_search?sort=price:descGET /book/_search { "query" : { "match" : { "name" : " java" } }, "sort": [ { "price": "desc" } ] }结果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "book", "_type" : "_doc", "_id" : "2", "_score" : null, "_source" : { "name" : "java编程思想", "description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。", "studymodel" : "201001", "price" : 68.6, "timestamp" : "2019-08-25 19:11:35", "pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg", "tags" : [ "java", "dev" ] }, "sort" : [ 68.6 ] } ] } } -
分页查询
GET /book/_search?size=10&from=0GET /book/_search { "query": { "match_all": {} }, "from": 0, "size": 1 }结果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "book", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "Bootstrap开发", "description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。", "studymodel" : "201002", "price" : 38.6, "timestamp" : "2019-08-25 19:11:35", "pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg", "tags" : [ "bootstrap", "dev" ] } } ] } } -
指定返回字段
GET /book/ _search? _source=name,studymodelGET /book/_search { "query": { "match_all": {} }, "_source": ["name", "studymodel"] }结果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "book", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "studymodel" : "201002", "name" : "Bootstrap开发" } }, { "_index" : "book", "_type" : "_doc", "_id" : "2", "_score" : 1.0, "_source" : { "studymodel" : "201001", "name" : "java编程思想" } }, { "_index" : "book", "_type" : "_doc", "_id" : "3", "_score" : 1.0, "_source" : { "studymodel" : "201001", "name" : "spring开发基础" } } ] } }
通过组合以上各种类型查询,实现复杂查询。
14.5.2 Query DSL语法
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
GET /test_index/_search
{
"query": {
"match": {
"test_field": "test"
}
}
}
14.5.3 组合多个搜索条件(bool)
搜索需求:title必须包含elasticsearch,content可以包含elasticsearch也可以不包含,author_id必须不为11
sql where and or !=
初始数据:
POST /website/_doc/1
{
"title": "my hadoop article",
"content": "hadoop is very bad",
"author_id": 111
}
POST /website/_doc/2
{
"title": "my elasticsearch article",
"content": "es is very bad",
"author_id": 112
}
POST /website/_doc/3
{
"title": "my elasticsearch article",
"content": "es is very goods",
"author_id": 111
}
搜索:
GET /website/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
结果:
{
"took" : 488,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "website",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.47000363,
"_source" : {
"title" : "my elasticsearch article",
"content" : "es is very bad",
"author_id" : 112
}
}
]
}
}
更复杂的搜索需求:
select * from test_index where name='tom' or (hired =true and (personality ='good' and rude != true ))
GET /test_index/_search
{
"query": {
"bool": {
"must": { "match":{ "name": "tom" }},
"should": [
{ "match":{ "hired": true }},
{ "bool": {
"must":{ "match": { "personality": "good" }},
"must_not": { "match": { "rude": true }}
}}
],
"minimum_should_match": 1
}
}
}
14.6. full-text search 全文检索
14.6.1 全文检索
重新创建book索引
PUT /book/
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"studymodel":{
"type": "keyword"
},
"price":{
"type": "double"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"pic":{
"type":"text",
"index":false
}
}
}
}
插入数据
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "dev"]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "java", "dev"]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"timestamp":"2019-08-24 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "spring", "java"]
}
搜索
GET /book/_search
{
"query" : {
"match" : {
"description" : "java程序员"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
14.6.2 _score初探
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
结果分析:
-
建立索引时, description字段 term倒排索引
java 2,3
程序员 3
-
搜索时,直接找description中含有java的文档 2,3,并且3号文档含有两个java字段,一个程序员,所以得分高,排在前面。2号文档含有一个java,排在后面。
14.7. DSL 语法练习
14.7.1 match_all
搜索:
GET /book/_search
{
"query": {
"match_all": {}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.7.2 match
搜索:
GET /book/_search
{
"query": {
"match": {
"description": "java程序员"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
14.7.3 multi_match
搜索:
GET /book/_search
{
"query": {
"multi_match": {
"query": "java程序员",
"fields": ["name", "description"]
}
}
}
结果:
{
"took" : 21,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9331132,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
14.7.4 range query
范围查询
搜索:
GET /book/_search
{
"query": {
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.7.5 term query
分词查询
注意:字段为keyword时,存储和搜索都不分词
搜索:
GET /book/_search
{
"query": {
"term": {
"description": "java程序员"
}
}
}
结果:
java程序员会被分词器分开,所以查不到
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
搜索:
GET /book/_search
{
"query": {
"term": {
"description": "java程序员"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.7936629,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.7936629,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
14.7.6 terms query
多个分词查询
搜素:
GET /book/_search
{
"query":{
"terms":{
"tags":[
"search",
"java",
"nosql"
]
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.7.7 exist query
查询有某些字段的文档
GET /_search
{
"query": {
"exists": {
"field": "name"
}
}
}
结果:
{
"took" : 630,
"timed_out" : false,
"_shards" : {
"total" : 27,
"successful" : 27,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "goods",
"_type" : "electronic_goods",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "小米空调",
"price" : 1999.0,
"service_period" : "one year"
}
}
]
}
}
14.7. 8 Fuzzy query
返回包含与搜索词类似的词的文档,该词由Levenshtein编辑距离度量。
包括以下几种情况:
-
更改角色(box→fox)
-
删除字符(aple→apple)
-
插入字符(sick→sic)
-
调换两个相邻字符(ACT→CAT)
搜素
GET /book/_search
{
"query": {
"fuzzy": {
"description": {
"value": "jave"
}
}
}
}
结果
{
"took" : 30,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.59524715,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.59524715,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.43470988,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
14.7.9 IDs
搜素
GET /book/_search
{
"query": {
"ids" : {
"values" : ["1", "4", "100"]
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
}
]
}
}
14.7.10 prefix 前缀查询
搜素
GET /book/_search
{
"query": {
"prefix": {
"description": {
"value": "spring"
}
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.7.11 regexp query 正则查询
GET /book/_search
{
"query": {
"regexp": {
"description": {
"value": "j.*a",
"flags" : "ALL",
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.8. Filter
14.8.1 filter与query示例
需求:用户查询description中有"java程序员",并且价格大于80小于90的数据。
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
},
{
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
]
}
}
}
结果:
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 3.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 3.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
使用filter:
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
],
"filter": {
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
}
}
}
结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
14.8.2 filter与query对比
-
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响。 -
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
应用场景:
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query 如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter
14.8.3 filter与query性能
-
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据 -
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果
14.9. 定位错误语法
验证错误语句:
GET /book/_validate/query?explain
搜索:
GET /book/_validate/query?explain
{
"query": {
"mach": {
"description": "java程序员"
}
}
}
结果:
{
"valid" : false,
"error" : "org.elasticsearch.common.ParsingException: no [query] registered for [mach]"
}
正确
GET /book/_validate/query?explain
{
"query": {
"match": {
"description": "java程序员"
}
}
}
结果:
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "book",
"valid" : true,
"explanation" : "description:java description:程序员"
}
]
}
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法。
合法以后,explain就像mysql的执行计划,可以看到搜索的目标等信息。
14.10. 定制排序规则
14.10.1 默认排序规则
默认情况下,是按照_score降序排序的
然而,某些情况下,可能没有有用的_score,比如说filter
搜索:
GET book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
]
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
当然,也可以是constant_score
14.10.2 定制排序规则
相当于sql中order by ?sort=sprice:desc
搜索:
GET /book/_search
{
"query": {
"constant_score": {
"filter" : {
"term" : {
"studymodel" : "201001"
}
}
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
},
"sort" : [
68.6
]
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"sort" : [
88.6
]
}
]
}
}
14.11. Text字段排序问题
如果对一个text field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了。
通常解决方案是
-
方案一:fielddata:true
创建索引
PUT /website { "mappings":{ "properties":{ "title":{ "type":"text", "fielddata": true }, "content":{ "type":"text" }, "post_date":{ "type":"date" }, "author_id":{ "type":"long" } } } }插入数据
PUT /website/_doc/1 { "title": "first article", "content": "this is my second article", "post_date": "2019-01-01", "author_id": 110 } PUT /website/_doc/2 { "title": "second article", "content": "this is my second article", "post_date": "2019-01-01", "author_id": 110 } PUT /website/_doc/3 { "title": "third article", "content": "this is my third article", "post_date": "2019-01-02", "author_id": 110 }搜索
GET /website/_search { "query": { "match_all": {} }, "sort": [ { "title": { "order": "desc" } } ] }结果:
{ "took" : 9, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "website", "_type" : "_doc", "_id" : "3", "_score" : null, "_source" : { "title" : "third article", "content" : "this is my third article", "post_date" : "2019-01-02", "author_id" : 110 }, "sort" : [ "third" ] }, { "_index" : "website", "_type" : "_doc", "_id" : "2", "_score" : null, "_source" : { "title" : "second article", "content" : "this is my second article", "post_date" : "2019-01-01", "author_id" : 110 }, "sort" : [ "second" ] }, { "_index" : "website", "_type" : "_doc", "_id" : "1", "_score" : null, "_source" : { "title" : "first article", "content" : "this is my second article", "post_date" : "2019-01-01", "author_id" : 110 }, "sort" : [ "first" ] } ] } } -
方案二:将一个text field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序。
创建索引
PUT /website { "mappings":{ "properties":{ "title":{ "type":"text", "fields":{ "keyword":{ "type":"keyword" } } }, "content":{ "type":"text" }, "post_date":{ "type":"date" }, "author_id":{ "type":"long" } } } }插入数据
PUT /website/_doc/1 { "title": "first article", "content": "this is my second article", "post_date": "2019-01-01", "author_id": 110 } PUT /website/_doc/2 { "title": "second article", "content": "this is my second article", "post_date": "2019-01-01", "author_id": 110 } PUT /website/_doc/3 { "title": "third article", "content": "this is my third article", "post_date": "2019-01-02", "author_id": 110 }搜索
GET /website/_search { "query": { "match_all": {} }, "sort": [ { "title.keyword": { "order": "desc" } } ] }结果:
{ "took" : 13, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "website", "_type" : "_doc", "_id" : "3", "_score" : null, "_source" : { "title" : "third article", "content" : "this is my third article", "post_date" : "2019-01-02", "author_id" : 110 }, "sort" : [ "third article" ] }, { "_index" : "website", "_type" : "_doc", "_id" : "2", "_score" : null, "_source" : { "title" : "second article", "content" : "this is my second article", "post_date" : "2019-01-01", "author_id" : 110 }, "sort" : [ "second article" ] }, { "_index" : "website", "_type" : "_doc", "_id" : "1", "_score" : null, "_source" : { "title" : "first article", "content" : "this is my second article", "post_date" : "2019-01-01", "author_id" : 110 }, "sort" : [ "first article" ] } ] } }
14.12. Scroll分批查询
场景:下载某一个索引中1亿条数据,到文件或是数据库。
不能一下全查出来,系统内存溢出。所以使用scoll滚动搜索技术,一批一批查询。
scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
搜索
GET /book/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 1
}
结果:
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABiecWamZaT0NXMG5UbzZjRElHYVdaX0FYdw==",
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
}
]
}
}
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
搜素
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABiecWamZaT0NXMG5UbzZjRElHYVdaX0FYdw=="
}
结果:
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABiecWamZaT0NXMG5UbzZjRElHYVdaX0FYdw==",
"took" : 12,
"timed_out" : false,
"terminated_early" : true,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
]
}
}
与分页区别:
-
分页给用户看的 deep paging
-
scroll是用户系统内部操作,如下载批量数据,数据转移。零停机改变索引映射。
15. java api实现搜索
15.1. 全部搜索
rest api
GET /book/_search
{
"query": {
"match_all": {}
}
}
代码实现
@SpringBootTest
public class TestSearch {
@Autowired
RestHighLevelClient client;
/**
* 1、全部搜索
*
* GET /book/_search
* {
* "query": {
* "match_all": {}
* }
* }
*
*/
@Test
public void testSearchAll() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 将一个匹配所有文档的查询添加到 searchSourceBuilder 中
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
// 获取某些字段--> name
searchSourceBuilder.fetchSource(new String[]{"name"}, new String[]{});
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
}
结果
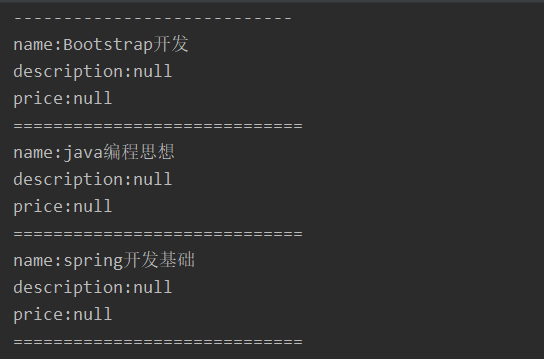
15.2. 分页搜索
rest api
GET /book/_search
{
"query": {
"match_all": {}
},
"from": 0
, "size": 2
}
代码实现
@Test
public void testSearchPage() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 将一个匹配所有文档的查询添加到 searchSourceBuilder 中
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
// 设置分页查询参数
int page = 1; //第几页
int size = 2; //页数
int from = (page -1) * 2; //下标计算
searchSourceBuilder.from(from);
searchSourceBuilder.size(size);
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果

15.3. id搜索(文档ID查询)
rest api
GET /book/_search
{
"query": {
"ids": {
"values": ["1","4","100"]
}
}
}
代码实现
@Test
public void testSearchIds() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 创建一个文档ID查询,并将文档ID "1"、"4" 和 "100" 添加到查询中
searchSourceBuilder.query(QueryBuilders.idsQuery().addIds("1","4","100"));
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果

15.4. match搜索(匹配查询)
rest api
GET /book/_search
{
"query": {
"match": {
"description": "java程序员"
}
}
}
代码实现
@Test
public void testSearchMatch() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 创建一个匹配查询,并指定要匹配的字段为 "description",待匹配的关键字为 "java程序员"
searchSourceBuilder.query(QueryBuilders.matchQuery("description", "java程序员"));
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果
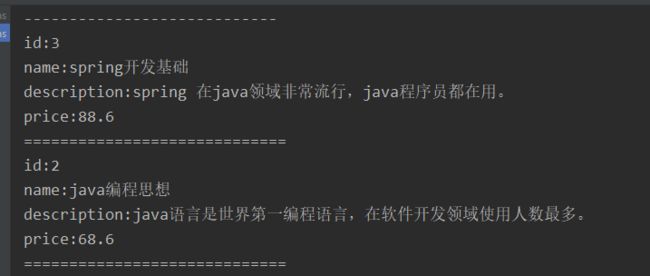
15.5. multi_match搜索(多字段匹配查询)
rest api
GET /book/_search
{
"query": {
"multi_match": {
"query": "java程序员",
"fields": ["name", "description"]
}
}
}
代码实现
@Test
public void testSearchMultiMatch() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 创建一个匹配查询,并指定要匹配的字段为 "description",待匹配的关键字为 "java程序员"
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("java程序员", "name", "description"));
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果
15.6. 按term搜索(精确匹配查询)
rest api
GET /book/_search
{
"query": {
"term": {
"description": "java程序员"
}
}
}
代码实现
@Test
public void testSearchTerm() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 创建一个匹配查询,并指定要匹配的字段为 "description",待匹配的关键字为 "java程序员"
searchSourceBuilder.query(QueryBuilders.termQuery("description", "程序员"));
// 将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果

15.7. 按bool query搜索
rest api
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "java程序员",
"fields": ["name","description"]
}
}
],
"should": [
{
"match": {
"studymodel": "201001"
}
}
]
}
}
}
代码实现
@Test
public void testSearchBool() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1.1、构建bool请求体
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 1)、构建multiMatch请求
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("java程序员", "name", "description");
boolQueryBuilder.must(multiMatchQueryBuilder);
// 2)、构建match请求
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("studymodel", "201001");
boolQueryBuilder.should(matchQueryBuilder);
// 3)、将 boolQueryBuilder 作为查询条件添加到搜索请求中
searchSourceBuilder.query(boolQueryBuilder);
// 1.2、将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果
15.8. filter搜索
rest api
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "java程序员",
"fields": ["name","description"]
}
}
],
"filter": {
"range": {
"price": {
"gte": 50,
"lte": 90
}
}
}
}
}
}
代码实现
@Test
public void testSearchFilter() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1.1、构建bool请求体
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 1)、构建multiMatch请求
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("java程序员", "name", "description");
boolQueryBuilder.must(multiMatchQueryBuilder);
// 2)、构建了一个基于范围查询的过滤器条件
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(50).lte(90);
boolQueryBuilder.filter(rangeQueryBuilder);
// 3)、将 boolQueryBuilder 作为查询条件添加到搜索请求中
searchSourceBuilder.query(boolQueryBuilder);
// 1.2、将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果
15.9. sort搜索
rest api
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "java程序员",
"fields": ["name","description"]
}
}
],
"filter": {
"range": {
"price": {
"gte": 50,
"lte": 90
}
}
}
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
代码实现
@Test
public void testSearchSort() throws IOException {
// 1、构建索引请求
SearchRequest searchRequest = new SearchRequest("book");
// 1.1、构建搜素请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1.1、构建bool请求体
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 1)、构建multiMatch请求
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("java程序员", "name", "description");
boolQueryBuilder.must(multiMatchQueryBuilder);
// 2)、构建了一个基于范围查询的过滤器条件
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(50).lte(90);
boolQueryBuilder.filter(rangeQueryBuilder);
// 3)、将 boolQueryBuilder 作为查询条件添加到搜索请求中
searchSourceBuilder.query(boolQueryBuilder);
// 1.2、按照价格升序排序
searchSourceBuilder.sort("price", SortOrder.ASC);
// 1.3、将 searchSourceBuilder 中构建好的搜索查询内容应用到 searchRequest 上
searchRequest.source(searchSourceBuilder);
// 2、执行搜素
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
SearchHits hits = searchResponse.getHits();
// 3.1、获取数据
SearchHit[] searchHits = hits.getHits();
System.out.println("----------------------------");
for (SearchHit hit : searchHits) {
String id = hit.getId();
float score = hit.getScore();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String name = (String) sourceAsMap.get("name");
String description = (String) sourceAsMap.get("description");
Double price = (Double) sourceAsMap.get("price");
System.out.println("id:" + id);
System.out.println("name:" + name);
System.out.println("description:" + description);
System.out.println("price:" + price);
System.out.println("=============================");
}
}
结果

16. 评分机制详解
16.1. 评分机制 TF\IDF
16.1.1 算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
-
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。
 举例: 搜索请求:hello world
举例: 搜索请求:hello worlddoc1 : hello you and me,and world is very good.
doc2 : hello,how are you
-
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关.


举例:搜索请求:hello worlddoc1 : hello ,today is very good
doc2 : hi world ,how are you
整个index中1亿条数据。hello的document 1000个,有world的document 有100个。
doc2 更相关
-
Field-length norm:field长度,field越长,相关度越弱
举例:搜索请求:hello world
doc1 : {“title”:“hello article”,"content ":“balabalabal 1万个”}
doc2 : {“title”:“my article”,"content ":“balabalabal 1万个,world”}
16.1.2 _score是如何被计算出来的
rest api
GET /book/_search?explain=true
{
"query": {
"match": {
"description": "java程序员"
}
}
}
结果
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.137549,
"hits" : [
{
"_shard" : "[book][0]",
"_node" : "MDA45-r6SUGJ0ZyqyhTINA",
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 2.137549,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"_explanation" : {
"value" : 2.137549,
"description" : "sum of:",
"details" : [
{
"value" : 0.7936629,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7936629,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7675597,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 1.3438859,
"description" : "weight(description:程序员 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.3438859,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.98082924,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.6227967,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},
{
"_shard" : "[book][0]",
"_node" : "MDA45-r6SUGJ0ZyqyhTINA",
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.57961315,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
},
"_explanation" : {
"value" : 0.57961315,
"description" : "sum of:",
"details" : [
{
"value" : 0.57961315,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.57961315,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.56055,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 19.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
]
}
}
16.1.3 分析一个document是如何被匹配上的
rest api
GET /book/_explain/3
{
"query": {
"match": {
"description": "java程序员"
}
}
}
结果
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"matched" : true,
"explanation" : {
"value" : 2.137549,
"description" : "sum of:",
"details" : [
{
"value" : 0.7936629,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7936629,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7675597,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 1.3438859,
"description" : "weight(description:程序员 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.3438859,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.98082924,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.6227967,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 35.333332,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
16.2. Doc value
搜索的时候,要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引,也就是doc values,以供排序,聚合,过滤等操作使用
doc values是被保存在磁盘上的,此时如果内存足够,os会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os会将其写入磁盘上
倒排索引
doc1: hello world you and me
doc2: hi, world, how are you
| term | doc1 | doc2 |
|---|---|---|
| hello | * | |
| world | * | * |
| you | * | * |
| and | * | |
| me | * | |
| hi | * | |
| how | * | |
| are | * |
搜索时:
hello you --> hello, you
hello --> doc1
you --> doc1,doc2
doc1: hello world you and me
doc2: hi, world, how are you
sort by 出现问题
正排索引
doc1: { “name”: “jack”, “age”: 27 }
doc2: { “name”: “tom”, “age”: 30 }
| document | name | age |
|---|---|---|
| doc1 | jack | 27 |
| doc2 | tom | 30 |
16.3. query phase
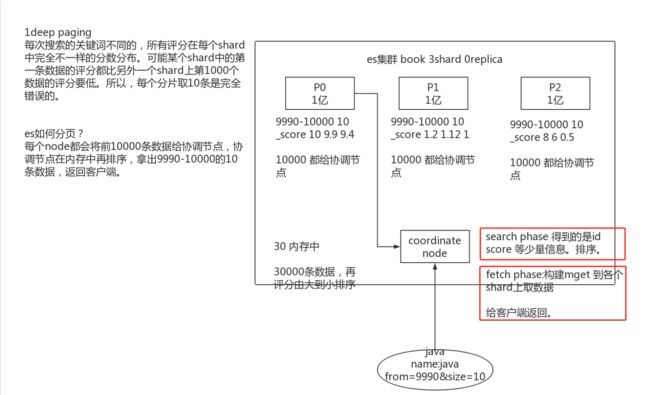
-
query phase
(1)搜索请求发送到某一个coordinate node,构建一个priority queue,长度以paging操作from和size为准,默认为10(2)
coordinate node将请求转发到所有shard,每个shard本地搜索,并构建一个本地的priority queue(3)各个
shard将自己的priority queue返回给coordinate node,并构建一个全局的priority queue -
replica shard如何提升搜索吞吐量
一次请求要打到所有shard的一个replica/primary上去,如果每个shard都有多个replica,那么同时并发过来的搜索请求可以同时打到其他的replica上去
16.4. fetch phase
-
fetch phbase工作流程
(1)
coordinate node构建完priority queue之后,就发送mget请求去所有shard上获取对应的document(2)各个
shard将document返回给coordinate node(3)
coordinate node将合并后的document结果返回给client客户端 -
一般搜索,如果不加
from和size,就默认搜索前10条,按照_score排序
16.5. 搜索参数小总结

-
preference
决定了哪些shard会被用来执行搜索操作
_primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3
GET /_search?preference=_shards:2,3bouncing results问题,两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上;每次页面上看到的搜索结果的排序都不一样。这就是bouncing result,也就是跳跃的结果。
搜索的时候,是轮询将搜索请求发送到每一个replica shard(primary shard),但是在不同的shard上,可能document的排序不同
解决方案就是将preference设置为一个字符串,比如说user_id,让每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results了
-
timeout
已经讲解过原理了,主要就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
GET /_search?timeout=10s -
routing
document文档路由,_id路由,routing=user_id,这样的话可以让同一个user对应的数据到一个shard上去GET /_search?routing=user123 -
search_type
default:query_then_fetch
dfs_query_then_fetch,可以提升revelance sort精准度
17. 聚合入门
17.1 聚合示例
17.1.1 需求:计算每个studymodel下的商品数量
sql语句: select studymodel,count(*) from book group by studymodel
rest api
GET /book/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"group_by_model": {
"terms": { "field": "studymodel" }
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_model" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "201001",
"doc_count" : 2
},
{
"key" : "201002",
"doc_count" : 1
}
]
}
}
}
17.1.2 需求:计算每个tags下的商品数量
rest api
GET /book/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"group_by_tags": {
"terms": { "field": "tags" }
}
}
}
报错
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [tags] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "book",
"node": "jfZOCW0nTo6cDIGaWZ_AXw",
"reason": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [tags] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [tags] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [tags] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
},
"status": 400
}
设置字段"fielddata": true
“fielddata”: true 是对字段启用 fielddata 特性的设置。fielddata 是一种允许在聚合、排序和脚本中使用字段值的一种数据结构。
当你将 “fielddata”: true 应用于某个字段时,Elasticsearch 会为该字段构建一个倒排索引,以便能够快速检索和分析该字段的值。这样,你就可以在聚合操作、排序操作或使用脚本时,方便地访问和操作该字段的值。
需要注意的是,启用 fielddata 特性会消耗一定的内存空间,特别是对于文本字段或具有大量不同值的字段。因此,你需要谨慎使用 fielddata,并确保在需要使用字段值进行聚合、排序或脚本操作时才启用它。
PUT /book/_mapping/
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}
结果
{
"acknowledged" : true
}
再次查询,返回结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "dev",
"doc_count" : 2
},
{
"key" : "java",
"doc_count" : 2
},
{
"key" : "bootstrap",
"doc_count" : 1
},
{
"key" : "spring",
"doc_count" : 1
}
]
}
}
}
17.1.3 需求:加上搜索条件,计算每个tags下的商品数量
rest api
GET /book/_search
{
"size": 0,
"query": {
"match": {
"description": "java程序员"
}
},
"aggs": {
"group_by_tags": {
"terms": { "field": "tags" }
}
}
}
结果
{
"took" : 34,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "java",
"doc_count" : 2
},
{
"key" : "dev",
"doc_count" : 1
},
{
"key" : "spring",
"doc_count" : 1
}
]
}
}
}
17.1.4 需求:先分组,再算每组的平均值,计算每个tag下的商品的平均价格
rest api
GET /book/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : {
"field" : "tags"
},
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "dev",
"doc_count" : 2,
"avg_price" : {
"value" : 53.599999999999994
}
},
{
"key" : "java",
"doc_count" : 2,
"avg_price" : {
"value" : 78.6
}
},
{
"key" : "bootstrap",
"doc_count" : 1,
"avg_price" : {
"value" : 38.6
}
},
{
"key" : "spring",
"doc_count" : 1,
"avg_price" : {
"value" : 88.6
}
}
]
}
}
}
17.1.5 需求:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
rest api
GET /book/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : {
"field" : "tags",
"order": {
"avg_price": "desc"
}
},
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
结果
{
"took" : 13,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "spring",
"doc_count" : 1,
"avg_price" : {
"value" : 88.6
}
},
{
"key" : "java",
"doc_count" : 2,
"avg_price" : {
"value" : 78.6
}
},
{
"key" : "dev",
"doc_count" : 2,
"avg_price" : {
"value" : 53.599999999999994
}
},
{
"key" : "bootstrap",
"doc_count" : 1,
"avg_price" : {
"value" : 38.6
}
}
]
}
}
}
17.1.6 需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格
rest api
GET /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 40
},
{
"from": 40,
"to": 60
},
{
"from": 60,
"to": 80
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
结果
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_price" : {
"buckets" : [
{
"key" : "0.0-40.0",
"from" : 0.0,
"to" : 40.0,
"doc_count" : 1,
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "bootstrap",
"doc_count" : 1,
"average_price" : {
"value" : 38.6
}
},
{
"key" : "dev",
"doc_count" : 1,
"average_price" : {
"value" : 38.6
}
}
]
}
},
{
"key" : "40.0-60.0",
"from" : 40.0,
"to" : 60.0,
"doc_count" : 0,
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key" : "60.0-80.0",
"from" : 60.0,
"to" : 80.0,
"doc_count" : 1,
"group_by_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "dev",
"doc_count" : 1,
"average_price" : {
"value" : 68.6
}
},
{
"key" : "java",
"doc_count" : 1,
"average_price" : {
"value" : 68.6
}
}
]
}
}
]
}
}
}
17.2. 两个核心概念:bucket和metric
17.2.1 bucket:一个数据分组
city name
北京 张三
北京 李四
天津 王五
天津 赵六
天津 王麻子
划分出来两个bucket,一个是北京bucket,一个是天津bucket
北京bucket:包含了2个人,张三,李四
上海bucket:包含了3个人,王五,赵六,王麻子
17.2.2 metric:对一个数据分组执行的统计
metric,就是对一个bucket执行的某种聚合分析的操作,比如说求平均值,求最大值,求最小值
select count(*) from book group studymodel
bucket:group by studymodel --> 那些studymodel相同的数据,就会被划分到一个bucket中
metric:count(*),对每个user_id bucket中所有的数据,计算一个数量。还有avg(),sum(),max(),min()
17.3. 电视案例
创建索引及映射
PUT /tvs
PUT /tvs/_mapping
{
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date"
}
}
}
插入数据
POST /tvs/_bulk
{ "index": {}}
{ "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-10-28" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2019-05-18" }
{ "index": {}}
{ "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2019-07-02" }
{ "index": {}}
{ "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2019-08-19" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }
{ "index": {}}
{ "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2020-01-01" }
{ "index": {}}
{ "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2020-02-12" }
结果
{
"took" : 56,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "MrmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "M7mnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "NLmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "NbmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "NrmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "N7mnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "OLmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "tvs",
"_type" : "_doc",
"_id" : "ObmnHowBGuOn3FYdKMSH",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1,
"status" : 201
}
}
]
}
17.3.1 统计哪种颜色的电视销量最高
rest api
GET /tvs/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
查询条件解析
size:只获取聚合结果,而不要执行聚合的原始数据aggs:固定语法,要对一份数据执行分组聚合操作popular_colors:就是对每个aggs,都要起一个名字,terms:根据字段的值进行分组field:根据指定的字段的值进行分组
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4
},
{
"key" : "绿色",
"doc_count" : 2
},
{
"key" : "蓝色",
"doc_count" : 2
}
]
}
}
}
返回结果解析
hits.hits:我们指定了size是0,所以hits.hits就是空的aggregations:聚合结果popular_color:我们指定的某个聚合的名称buckets:根据我们指定的field划分出的bucketskey:每个bucket对应的那个值doc_count:这个bucket分组内,有多少个数据
数量,其实就是这种颜色的销量
每种颜色对应的bucket中的数据的默认的排序规则:按照doc_count降序排序
17.3.2 统计每种颜色电视平均价格
rest api
GET /tvs/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
在一个aggs执行的bucket操作(terms),平级的json结构下,再加一个aggs,这个第二个aggs内部,同样取个名字,执行一个metric操作,avg,对之前的每个bucket中的数据的指定的field,price field,求一个平均值
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4,
"avg_price" : {
"value" : 3250.0
}
},
{
"key" : "绿色",
"doc_count" : 2,
"avg_price" : {
"value" : 2100.0
}
},
{
"key" : "蓝色",
"doc_count" : 2,
"avg_price" : {
"value" : 2000.0
}
}
]
}
}
}
buckets,除了key和doc_countavg_price:我们自己取的metric aggs的名字value:我们的metric计算的结果,每个bucket中的数据的price字段求平均值后的结果
相当于sql: select avg(price) from tvs group by color
17.3.3 继续下钻分析
每个颜色下,平均价格及每个颜色下,每个品牌的平均价格
rest api
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"color_avg_price": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4,
"color_avg_price" : {
"value" : 3250.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "长虹",
"doc_count" : 3,
"brand_avg_price" : {
"value" : 1666.6666666666667
}
},
{
"key" : "三星",
"doc_count" : 1,
"brand_avg_price" : {
"value" : 8000.0
}
}
]
}
},
{
"key" : "绿色",
"doc_count" : 2,
"color_avg_price" : {
"value" : 2100.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "TCL",
"doc_count" : 1,
"brand_avg_price" : {
"value" : 1200.0
}
},
{
"key" : "小米",
"doc_count" : 1,
"brand_avg_price" : {
"value" : 3000.0
}
}
]
}
},
{
"key" : "蓝色",
"doc_count" : 2,
"color_avg_price" : {
"value" : 2000.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "TCL",
"doc_count" : 1,
"brand_avg_price" : {
"value" : 1500.0
}
},
{
"key" : "小米",
"doc_count" : 1,
"brand_avg_price" : {
"value" : 2500.0
}
}
]
}
}
]
}
}
}
17.3.4 更多的metric
count:bucket,terms,自动就会有一个doc_count,就相当于是countavg:avg aggs,求平均值max:求一个bucket内,指定field值最大的那个数据min:求一个bucket内,指定field值最小的那个数据sum:求一个bucket内,指定field值的总和
rest api
GET /tvs/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} },
"sum_price" : { "sum": { "field": "price" } }
}
}
}
}
结果
{
"took" : 28,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4,
"max_price" : {
"value" : 8000.0
},
"min_price" : {
"value" : 1000.0
},
"avg_price" : {
"value" : 3250.0
},
"sum_price" : {
"value" : 13000.0
}
},
{
"key" : "绿色",
"doc_count" : 2,
"max_price" : {
"value" : 3000.0
},
"min_price" : {
"value" : 1200.0
},
"avg_price" : {
"value" : 2100.0
},
"sum_price" : {
"value" : 4200.0
}
},
{
"key" : "蓝色",
"doc_count" : 2,
"max_price" : {
"value" : 2500.0
},
"min_price" : {
"value" : 1500.0
},
"avg_price" : {
"value" : 2000.0
},
"sum_price" : {
"value" : 4000.0
}
}
]
}
}
}
17.3.5 划分范围 histogram
rest api
GET /tvs/_search
{
"size" : 0,
"aggs":{
"price":{
"histogram":{
"field": "price",
"interval": 2000
},
"aggs":{
"income": {
"sum": {
"field" : "price"
}
}
}
}
}
}
histogram:类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作
"histogram":{
"field": "price",
"interval": 2000
}
interval:2000,划分范围,02000,20004000,40006000,60008000,8000~10000,buckets
bucket有了之后,一样的,去对每个bucket执行avg,count,sum,max,min,等各种metric操作,聚合分析
结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 3,
"income" : {
"value" : 3700.0
}
},
{
"key" : 2000.0,
"doc_count" : 4,
"income" : {
"value" : 9500.0
}
},
{
"key" : 4000.0,
"doc_count" : 0,
"income" : {
"value" : 0.0
}
},
{
"key" : 6000.0,
"doc_count" : 0,
"income" : {
"value" : 0.0
}
},
{
"key" : 8000.0,
"doc_count" : 1,
"income" : {
"value" : 8000.0
}
}
]
}
}
}
17.3.6 按照日期分组聚合
-
date_histogram,按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket -
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的 -
extended_bounds,min,max:划分bucket的时候,会限定在这个起始日期,和截止日期内
rest api
GET /tvs/_search
{
"size" : 0,
"aggs": {
"date_sales": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2019-01-01",
"max" : "2020-12-31"
}
}
}
}
}
结果
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"date_sales" : {
"buckets" : [
{
"key_as_string" : "2019-01-01",
"key" : 1546300800000,
"doc_count" : 0
},
{
"key_as_string" : "2019-02-01",
"key" : 1548979200000,
"doc_count" : 0
},
{
"key_as_string" : "2019-03-01",
"key" : 1551398400000,
"doc_count" : 0
},
{
"key_as_string" : "2019-04-01",
"key" : 1554076800000,
"doc_count" : 0
},
{
"key_as_string" : "2019-05-01",
"key" : 1556668800000,
"doc_count" : 1
},
{
"key_as_string" : "2019-06-01",
"key" : 1559347200000,
"doc_count" : 0
},
{
"key_as_string" : "2019-07-01",
"key" : 1561939200000,
"doc_count" : 1
},
{
"key_as_string" : "2019-08-01",
"key" : 1564617600000,
"doc_count" : 1
},
{
"key_as_string" : "2019-09-01",
"key" : 1567296000000,
"doc_count" : 0
},
{
"key_as_string" : "2019-10-01",
"key" : 1569888000000,
"doc_count" : 1
},
{
"key_as_string" : "2019-11-01",
"key" : 1572566400000,
"doc_count" : 2
},
{
"key_as_string" : "2019-12-01",
"key" : 1575158400000,
"doc_count" : 0
},
{
"key_as_string" : "2020-01-01",
"key" : 1577836800000,
"doc_count" : 1
},
{
"key_as_string" : "2020-02-01",
"key" : 1580515200000,
"doc_count" : 1
},
{
"key_as_string" : "2020-03-01",
"key" : 1583020800000,
"doc_count" : 0
},
{
"key_as_string" : "2020-04-01",
"key" : 1585699200000,
"doc_count" : 0
},
{
"key_as_string" : "2020-05-01",
"key" : 1588291200000,
"doc_count" : 0
},
{
"key_as_string" : "2020-06-01",
"key" : 1590969600000,
"doc_count" : 0
},
{
"key_as_string" : "2020-07-01",
"key" : 1593561600000,
"doc_count" : 0
},
{
"key_as_string" : "2020-08-01",
"key" : 1596240000000,
"doc_count" : 0
},
{
"key_as_string" : "2020-09-01",
"key" : 1598918400000,
"doc_count" : 0
},
{
"key_as_string" : "2020-10-01",
"key" : 1601510400000,
"doc_count" : 0
},
{
"key_as_string" : "2020-11-01",
"key" : 1604188800000,
"doc_count" : 0
},
{
"key_as_string" : "2020-12-01",
"key" : 1606780800000,
"doc_count" : 0
}
]
}
}
}
17.3.7 统计每季度每个品牌的销售额
rest api
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_sold_date": {
"date_histogram": {
"field": "sold_date",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2019-01-01",
"max": "2020-12-31"
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
},
"total_sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_sold_date" : {
"buckets" : [
{
"key_as_string" : "2019-01-01",
"key" : 1546300800000,
"doc_count" : 0,
"total_sum_price" : {
"value" : 0.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key_as_string" : "2019-04-01",
"key" : 1554076800000,
"doc_count" : 1,
"total_sum_price" : {
"value" : 3000.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "小米",
"doc_count" : 1,
"sum_price" : {
"value" : 3000.0
}
}
]
}
},
{
"key_as_string" : "2019-07-01",
"key" : 1561939200000,
"doc_count" : 2,
"total_sum_price" : {
"value" : 2700.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "TCL",
"doc_count" : 2,
"sum_price" : {
"value" : 2700.0
}
}
]
}
},
{
"key_as_string" : "2019-10-01",
"key" : 1569888000000,
"doc_count" : 3,
"total_sum_price" : {
"value" : 5000.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "长虹",
"doc_count" : 3,
"sum_price" : {
"value" : 5000.0
}
}
]
}
},
{
"key_as_string" : "2020-01-01",
"key" : 1577836800000,
"doc_count" : 2,
"total_sum_price" : {
"value" : 10500.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "三星",
"doc_count" : 1,
"sum_price" : {
"value" : 8000.0
}
},
{
"key" : "小米",
"doc_count" : 1,
"sum_price" : {
"value" : 2500.0
}
}
]
}
},
{
"key_as_string" : "2020-04-01",
"key" : 1585699200000,
"doc_count" : 0,
"total_sum_price" : {
"value" : 0.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key_as_string" : "2020-07-01",
"key" : 1593561600000,
"doc_count" : 0,
"total_sum_price" : {
"value" : 0.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key_as_string" : "2020-10-01",
"key" : 1601510400000,
"doc_count" : 0,
"total_sum_price" : {
"value" : 0.0
},
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
}
]
}
}
}
17.3.8 搜索与聚合结合,查询某个品牌按颜色销量
搜索与聚合可以结合起来。
sql select count(*) from tvs where brand like "%小米%" group by color
es aggregation,scope,任何的聚合,都必须在搜索出来的结果数据中执行,搜索结果,就是聚合分析操作的scope
rest api
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
}
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "绿色",
"doc_count" : 1
},
{
"key" : "蓝色",
"doc_count" : 1
}
]
}
}
}
17.3.9 global bucket:单个品牌与所有品牌销量对比
aggregation,scope,一个聚合操作,必须在query的搜索结果范围内执行
出来两个结果,一个结果,是基于query搜索结果来聚合的; 一个结果,是对所有数据执行聚合的
global bucket:全局范围的聚合(Global Aggregation)是一种特殊的桶聚合,它不会将搜索结果划分为多个桶进行聚合,而是将所有文档作为一个桶进行聚合。
rest api
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"single_brand_avg_price": {
"avg": {
"field": "price"
}
},
"all": {
"global": {},
"aggs": {
"all_brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
结果
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"all" : {
"doc_count" : 8,
"all_brand_avg_price" : {
"value" : 2650.0
}
},
"single_brand_avg_price" : {
"value" : 2750.0
}
}
}
17.3.10 过滤 + 聚合:统计价格大于1200的电视平均价格
搜索+聚合
过滤+聚合
rest api
GET /tvs/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 1200
}
}
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"avg_price" : {
"value" : 2885.714285714286
}
}
}
17.3.11 bucket filter:统计品牌最近一个月的平均价格
rest api
GET /tvs/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"recent_150d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-150d"
}
}
},
"aggs": {
"recent_150d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_140d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-140d"
}
}
},
"aggs": {
"recent_140d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_130d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-130d"
}
}
},
"aggs": {
"recent_130d_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
-
aggs.filter,针对的是聚合去做的如果放query里面的filter,是全局的,会对所有的数据都有影响
但是,如果,比如说,你要统计,长虹电视,最近1个月的平均值; 最近3个月的平均值; 最近6个月的平均值
-
bucket filter:对不同的bucket下的aggs,进行filter
结果
{
"took" : 22,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"recent_130d" : {
"meta" : { },
"doc_count" : 0,
"recent_130d_avg_price" : {
"value" : null
}
},
"recent_140d" : {
"meta" : { },
"doc_count" : 0,
"recent_140d_avg_price" : {
"value" : null
}
},
"recent_150d" : {
"meta" : { },
"doc_count" : 0,
"recent_150d_avg_price" : {
"value" : null
}
}
}
}
17.3.12 排序:按每种颜色的平均销售额降序排序
rest api
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_price": "asc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "蓝色",
"doc_count" : 2,
"avg_price" : {
"value" : 2000.0
}
},
{
"key" : "绿色",
"doc_count" : 2,
"avg_price" : {
"value" : 2100.0
}
},
{
"key" : "红色",
"doc_count" : 4,
"avg_price" : {
"value" : 3250.0
}
}
]
}
}
}
相当于sql子表数据字段可以立刻使用。
17.3.13 排序:按每种颜色的每种品牌平均销售额降序排序
rest api
GET /tvs/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4,
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "三星",
"doc_count" : 1,
"avg_price" : {
"value" : 8000.0
}
},
{
"key" : "长虹",
"doc_count" : 3,
"avg_price" : {
"value" : 1666.6666666666667
}
}
]
}
},
{
"key" : "绿色",
"doc_count" : 2,
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "小米",
"doc_count" : 1,
"avg_price" : {
"value" : 3000.0
}
},
{
"key" : "TCL",
"doc_count" : 1,
"avg_price" : {
"value" : 1200.0
}
}
]
}
},
{
"key" : "蓝色",
"doc_count" : 2,
"group_by_brand" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "小米",
"doc_count" : 1,
"avg_price" : {
"value" : 2500.0
}
},
{
"key" : "TCL",
"doc_count" : 1,
"avg_price" : {
"value" : 1500.0
}
}
]
}
}
]
}
}
}
18. java api实现聚合
简单聚合,多种聚合,详见代码。
18.1. 按照颜色分组,计算每个颜色卖出的个数
rest api
"aggregations" : {
"group_by_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "红色",
"doc_count" : 4
},
{
"key" : "绿色",
"doc_count" : 2
},
{
"key" : "蓝色",
"doc_count" : 2
}
]
}
}
代码实现
@SpringBootTest
public class TestAggs {
@Autowired
RestHighLevelClient client;
@Test
public void testAggs() throws IOException {
// 1、构建请求
// 1.1、请求头
SearchRequest searchRequest = new SearchRequest("tvs");
// 1.2、请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_color").field("color");
searchSourceBuilder.aggregation(termsAggregationBuilder);
// 1.3、请求体放入请求头
searchRequest.source(searchSourceBuilder);
// 2、执行
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
/**
* "aggregations" : {
* "group_by_color" : {
* "doc_count_error_upper_bound" : 0,
* "sum_other_doc_count" : 0,
* "buckets" : [
* {
* "key" : "红色",
* "doc_count" : 4
* },
* {
* "key" : "绿色",
* "doc_count" : 2
* },
* {
* "key" : "蓝色",
* "doc_count" : 2
* }
* ]
* }
*/
Aggregations aggregations = searchResponse.getAggregations();
Terms group_by_color = aggregations.get("group_by_color");
List<? extends Terms.Bucket> buckets = group_by_color.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println("key:" + key);
long docCount = bucket.getDocCount();
System.out.println("docCount:" + docCount);
System.out.println("=================================");
}
}
}
结果
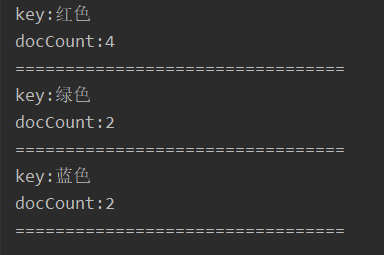
18.2. 按照颜色分组,计算每个颜色卖出的个数,每个颜色卖出的平均价格
rest api
GET /tvs/_search
{
"size": 0,
"query": {"match_all": {}},
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
代码实现
@Test
public void testAggsAndAvg() throws IOException {
// 1、构建请求
// 1.1、请求头
SearchRequest searchRequest = new SearchRequest("tvs");
// 1.2、请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_color").field("color");
// 1.3、terms聚合下填充一个子聚合
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avg_price").field("price");
termsAggregationBuilder.subAggregation(avgAggregationBuilder);
searchSourceBuilder.aggregation(termsAggregationBuilder);
// 1.4、请求体放入请求头
searchRequest.source(searchSourceBuilder);
// 2、执行
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
/**
* "aggregations" : {
* "group_by_color" : {
* "doc_count_error_upper_bound" : 0,
* "sum_other_doc_count" : 0,
* "buckets" : [
* {
* "key" : "红色",
* "doc_count" : 4,
* "avg_price" : {
* "value" : 3250.0
* }
* },
* {
* "key" : "绿色",
* "doc_count" : 2,
* "avg_price" : {
* "value" : 2100.0
* }
* },
* {
* "key" : "蓝色",
* "doc_count" : 2,
* "avg_price" : {
* "value" : 2000.0
* }
* }
* ]
* }
* }
*/
Aggregations aggregations = searchResponse.getAggregations();
Terms group_by_color = aggregations.get("group_by_color");
List<? extends Terms.Bucket> buckets = group_by_color.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println("key:" + key);
long docCount = bucket.getDocCount();
System.out.println("docCount:" + docCount);
Aggregations aggregations1 = bucket.getAggregations();
Avg avg_price = aggregations1.get("avg_price");
double value = avg_price.getValue();
System.out.println("value:" + value);
System.out.println("=================================");
}
}
结果
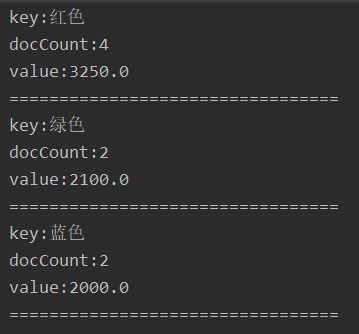
18.3. 按照颜色分组,计算每个颜色卖出的个数,以及每个颜色卖出的平均值、最大值、最小值、总和。
rest api
GET /tvs/_search
{
"size" : 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} },
"sum_price" : { "sum": { "field": "price" } }
}
}
}
}
代码实现
@Test
public void testAggsAndMore() throws IOException {
// 1、构建请求
// 1.1、请求头
SearchRequest searchRequest = new SearchRequest("tvs");
// 1.2、请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_color").field("color");
// 1.3、termsAggregationBuilder里放入多个子聚合
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avg_price").field("price");
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("min_price").field("price");
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("max_price").field("price");
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("sum_price").field("price");
termsAggregationBuilder.subAggregation(avgAggregationBuilder);
termsAggregationBuilder.subAggregation(minAggregationBuilder);
termsAggregationBuilder.subAggregation(maxAggregationBuilder);
termsAggregationBuilder.subAggregation(sumAggregationBuilder);
// 1.4、将指定的 termsAggregationBuilder 对象添加到搜索请求构建器 searchSourceBuilder 中,从而构建一个包含聚合查询的搜索请求。
searchSourceBuilder.aggregation(termsAggregationBuilder);
// 1.5、请求体放入请求头
searchRequest.source(searchSourceBuilder);
// 2、执行
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
/**
* {
* "key" : "红色",
* "doc_count" : 4,
* "max_price" : {
* "value" : 8000.0
* },
* "min_price" : {
* "value" : 1000.0
* },
* "avg_price" : {
* "value" : 3250.0
* },
* "sum_price" : {
* "value" : 13000.0
* }
* }
*/
Aggregations aggregations = searchResponse.getAggregations();
Terms group_by_color = aggregations.get("group_by_color");
List<? extends Terms.Bucket> buckets = group_by_color.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println("key:" + key);
long docCount = bucket.getDocCount();
System.out.println("docCount:" + docCount);
Aggregations aggregations1 = bucket.getAggregations();
Max max_price = aggregations1.get("max_price");
double maxPriceValue = max_price.getValue();
System.out.println("maxPriceValue:" + maxPriceValue);
Min min_price = aggregations1.get("min_price");
double minPriceValue = min_price.getValue();
System.out.println("minPriceValue:" + minPriceValue);
Avg avg_price = aggregations1.get("avg_price");
double avgPriceValue = avg_price.getValue();
System.out.println("avgPriceValue:" + avgPriceValue);
Sum sum_price = aggregations1.get("sum_price");
double sumPriceValue = sum_price.getValue();
System.out.println("sumPriceValue:" + sumPriceValue);
System.out.println("=================================");
}
}
结果

18.4. 按照售价每2000价格划分范围,算出每个区间的销售总额 histogram
rest api
GET /tvs/_search
{
"size":0,
"aggs":{
"by_histogram":{
"histogram":{
"field":"price",
"interval":2000
},
"aggs":{
"income":{
"sum":{
"field":"price"
}
}
}
}
}
}
代码实现
@Test
public void testAggsAndHistogram() throws IOException {
// 1、构建请求
// 1.1、请求头
SearchRequest searchRequest = new SearchRequest("tvs");
// 1.2、请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
HistogramAggregationBuilder histogramAggregationBuilder = AggregationBuilders.histogram("by_histogram").field("price").interval(2000);
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("income").field("price");
histogramAggregationBuilder.subAggregation(sumAggregationBuilder);
searchSourceBuilder.aggregation(histogramAggregationBuilder);
//请求体放入请求头
searchRequest.source(searchSourceBuilder);
// 2、执行
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
/**
* {
* "key" : 0.0,
* "doc_count" : 3,
* "income" : {
* "value" : 3700.0
* }
* }
*/
Aggregations aggregations = searchResponse.getAggregations();
Histogram group_by_color = aggregations.get("by_histogram");
List<? extends Histogram.Bucket> buckets = group_by_color.getBuckets();
for (Histogram.Bucket bucket : buckets) {
String keyAsString = bucket.getKeyAsString();
System.out.println("keyAsString:" + keyAsString);
long docCount = bucket.getDocCount();
System.out.println("docCount:" + docCount);
Aggregations aggregations1 = bucket.getAggregations();
Sum income = aggregations1.get("income");
double value = income.getValue();
System.out.println("value:" + value);
System.out.println("=================================");
}
}
结果
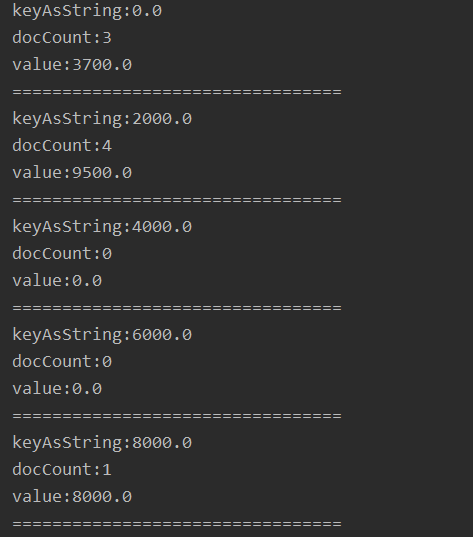
18.5. 计算每个季度的销售总额
rest api
GET /tvs/_search
{
"size":0,
"aggs":{
"sales":{
"date_histogram":{
"field":"sold_date",
"interval":"quarter",
"format":"yyyy-MM-dd",
"min_doc_count":0,
"extended_bounds":{
"min":"2019-01-01",
"max":"2020-12-31"
}
},
"aggs":{
"income":{
"sum":{
"field":"price"
}
}
}
}
}
}
GET /tvs/_search
{
"size":0,
"aggs":{
"date_sales":{
"date_histogram":{
"field":"sold_date",
"interval":"quarter",
"format":"yyyy-MM-dd",
"min_doc_count":0,
"extended_bounds":{
"min":"2019-01-01",
"max":"2020-12-31"
}
},
"aggs":{
"income":{
"sum":{
"field":"price"
}
}
}
}
}
}
代码实现
@Test
public void testAggsAndDateHistogram() throws IOException {
// 1、构建请求
// 1.1、请求头
SearchRequest searchRequest = new SearchRequest("tvs");
// 1.2、请求体
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
DateHistogramAggregationBuilder dateHistogramAggregationBuilder = AggregationBuilders.dateHistogram("date_sales").field("sold_date").calendarInterval(DateHistogramInterval.QUARTER)
.format("yyyy-MM-dd").minDocCount(0).extendedBounds(new ExtendedBounds("2019-01-01", "2020-12-31"));
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("income").field("price");
dateHistogramAggregationBuilder.subAggregation(sumAggregationBuilder);
searchSourceBuilder.aggregation(dateHistogramAggregationBuilder);
// 1.3、请求体放入请求头
searchRequest.source(searchSourceBuilder);
// 2、执行
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取结果
/**
* {
* "key_as_string" : "2019-01-01",
* "key" : 1546300800000,
* "doc_count" : 0,
* "income" : {
* "value" : 0.0
* }
* }
*/
Aggregations aggregations = searchResponse.getAggregations();
ParsedDateHistogram date_histogram = aggregations.get("date_sales");
List<? extends Histogram.Bucket> buckets = date_histogram.getBuckets();
for (Histogram.Bucket bucket : buckets) {
String keyAsString = bucket.getKeyAsString();
System.out.println("keyAsString:" + keyAsString);
long docCount = bucket.getDocCount();
System.out.println("docCount:" + docCount);
Aggregations aggregations1 = bucket.getAggregations();
Sum income = aggregations1.get("income");
double value = income.getValue();
System.out.println("value:" + value);
System.out.println("====================");
}
}
结果
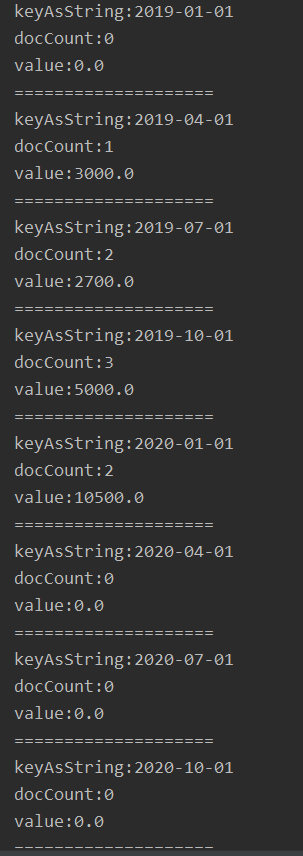
19. es7 sql新特性
19.1. 快速入门
rest api
POST /_sql?format=txt
{
"query": "SELECT * FROM tvs "
}
结果
brand | color | price | sold_date
---------------+---------------+---------------+------------------------
长虹 |红色 |1000 |2019-10-28T00:00:00.000Z
长虹 |红色 |2000 |2019-11-05T00:00:00.000Z
小米 |绿色 |3000 |2019-05-18T00:00:00.000Z
TCL |蓝色 |1500 |2019-07-02T00:00:00.000Z
TCL |绿色 |1200 |2019-08-19T00:00:00.000Z
长虹 |红色 |2000 |2019-11-05T00:00:00.000Z
三星 |红色 |8000 |2020-01-01T00:00:00.000Z
小米 |蓝色 |2500 |2020-02-12T00:00:00.000Z
19.2. 启动方式
-
http 请求
-
客户端:elasticsearch-sql-cli.bat
-
代码
19.3. 显示方式

19.4. sql 翻译
rest api
POST /_sql/translate
{
"query": "SELECT * FROM tvs "
}
结果
{
"size" : 1000,
"_source" : false,
"stored_fields" : "_none_",
"docvalue_fields" : [
{
"field" : "brand"
},
{
"field" : "color"
},
{
"field" : "price"
},
{
"field" : "sold_date",
"format" : "epoch_millis"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
19.5. 与其他DSL结合
rest api
POST /_sql?format=txt
{
"query": "SELECT * FROM tvs",
"filter": {
"range": {
"price": {
"gte" : 1200,
"lte" : 2000
}
}
}
}
结果
brand | color | price | sold_date
---------------+---------------+---------------+------------------------
长虹 |红色 |2000 |2019-11-05T00:00:00.000Z
TCL |蓝色 |1500 |2019-07-02T00:00:00.000Z
TCL |绿色 |1200 |2019-08-19T00:00:00.000Z
长虹 |红色 |2000 |2019-11-05T00:00:00.000Z
19.6. java 代码实现sql功能
-
前提 es拥有白金版功能
kibana中管理-》许可管理 开启白金版试用
-
导入依赖
<dependency>
<groupId>org.elasticsearch.plugingroupId>
<artifactId>x-pack-sql-jdbcartifactId>
<version>7.3.0version>
dependency>
<repositories>
<repository>
<id>elastic.coid>
<url>https://artifacts.elastic.co/mavenurl>
repository>
repositories>
3代码
public class TestJDBC {
public static void main(String[] args) {
try {
// 1、创建连接
Connection connection = DriverManager.getConnection("jdbc:es://http://localhost:9200");
// 2、创建statement
Statement statement = connection.createStatement();
// 3、执行sql
ResultSet results = statement.executeQuery("select * from tvs");
// 4、获取结果
while (results.next()) {
System.out.println(results.getString(1));
System.out.println(results.getString(2));
System.out.println(results.getString(3));
System.out.println(results.getString(4));
System.out.println("============================");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
大型企业可以购买白金版,增加Machine Learning、高级安全性x-pack。
20. Logstash学习
20.1 Logstash基本语法组成

20.1.1 什么是Logstash
logstash是一个数据抽取工具,将数据从一个地方转移到另一个地方。如hadoop生态圈的sqoop等。下载地址:https://www.elastic.co/cn/downloads/logstash
logstash之所以功能强大和流行,还与其丰富的过滤器插件是分不开的,过滤器提供的并不单单是过滤的功能,还可以对进入过滤器的原始数据进行复杂的逻辑处理,甚至添加独特的事件到后续流程中。
Logstash配置文件有如下三部分组成,其中input、output部分是必须配置,filter部分是可选配置,而filter就是过滤器插件,可以在这部分实现各种日志过滤功能。
20.1.2 配置文件:
input {
#输入插件
}
filter {
#过滤匹配插件
}
output {
#输出插件
}
配置文件:test1.config
input {
stdin {
}
}
output {
stdout {
codec=>rubydebug
}
}
20.1.3 启动操作:
logstash.bat -e 'input{stdin{}} output{stdout{}}'
为了好维护,将配置写入文件,启动
logstash.bat -f ../config/test1.conf
控制台输入内容
hello word
结果
20.2. Logstash输入插件(input)
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
20.2.1 标准输入(Stdin)
input{
stdin{
}
}
output {
stdout{
codec=>rubydebug
}
}
20.2.2 读取文件(File)
logstash使用一个名为filewatch的ruby gem库来监听文件变化,并通过一个叫.sincedb的数据库文件来记录被监听的日志文件的读取进度(时间戳),这个sincedb数据文件的默认路径在 .sincedb_123456,而logstash插件存储目录,默认是LOGSTASH_HOME/data。
input {
file {
path => ["/var/*/*"]
start_position => "beginning"
}
}
output {
stdout{
codec=>rubydebug
}
}
默认情况下,logstash会从文件的结束位置开始读取数据,也就是说logstash进程会以类似tail -f命令的形式逐行获取数据。
配置文件:test2.config
input {
file {
path => ["D:/learningStation/ELK/logstash-7.3.0/nginx*.log"]
start_position => "beginning"
}
}
output {
stdout {
codec=>rubydebug
}
}
启动操作
logstash.bat -f ../config/test2.conf
结果
20.2.3 读取TCP网络数据
input {
tcp {
port => "1234"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
}
output {
stdout{
codec=>rubydebug
}
}
20.3. Logstash过滤器插件(Filter)
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
20.13.1 Grok 正则捕获
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。他是目前logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:
%{语法: 语义}
例如输入的内容为:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
%{IP:clientip}匹配模式将获得的结果为:clientip: 172.16.213.132
%{HTTPDATE:timestamp}匹配模式将获得的结果为:timestamp: 07/Feb/2018:16:24:19 +0800
而%{QS:referrer}匹配模式将获得的结果为:referrer: “GET / HTTP/1.1”
下面是一个组合匹配模式,它可以获取上面输入的所有内容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}
通过上面这个组合匹配模式,我们将输入的内容分成了五个部分,即五个字段,将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是使用grok的目的。
例子:
配置文件:test3.config
input {
stdin {
}
}
filter{
grok{
match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output {
stdout {
codec=>rubydebug
}
}
启动操作
logstash.bat -f ../config/test3.conf
控制台输入内容
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
结果
20.13.2 时间处理(Date)
date插件是对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成LogStash::Timestamp对象,然后转存到@timestamp字段里,这在之前已经做过简单的介绍。
下面是date插件的一个配置示例(这里仅仅列出filter部分):
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
20.13.3 数据修改(Mutate)
(1)正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,只对字符串字段有效,下面是一个关于mutate插件中gsub的示例(仅列出filter部分):
filter {
mutate {
gsub => ["filed_name_1", "/" , "_"]
}
}
这个示例表示将filed_name_1字段中所有"/“字符替换为”_"。
(2)分隔符分割字符串为数组
split可以通过指定的分隔符分割字段中的字符串为数组,下面是一个关于mutate插件中split的示例(仅列出filter部分):
filter {
mutate {
split => ["filed_name_2", "|"]
}
}
这个示例表示将filed_name_2字段以"|"为区间分隔为数组。
(3)重命名字段
rename可以实现重命名某个字段的功能,下面是一个关于mutate插件中rename的示例(仅列出filter部分):
filter {
mutate {
rename => { "old_field" => "new_field" }
}
}
这个示例表示将字段old_field重命名为new_field。
(4)删除字段
remove_field可以实现删除某个字段的功能,下面是一个关于mutate插件中remove_field的示例(仅列出filter部分):
filter {
mutate {
remove_field => ["timestamp"]
}
}
这个示例表示将字段timestamp删除。
(5)GeoIP 地址查询归类
filter {
geoip {
source => "ip_field"
}
}
综合例子:
配置文件:test4.conf
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
stdout {
codec => "rubydebug"
}
}
启动操作
logstash.bat -f ../config/test4.conf
控制台输入内容
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 200 5039
结果
20.4. Logstash输出插件(output)
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。 一些常用的输出包括:
file: 表示将日志数据写入磁盘上的文件。elasticsearch:表示将日志数据发送给Elasticsearch。Elasticsearch可以高效方便和易于查询的保存数据。
1、输出到标准输出(stdout)
output {
stdout {
codec => rubydebug
}
}
2、保存为文件(file)
output {
file {
path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}
3、输出到elasticsearch
output {
elasticsearch {
host => ["192.168.1.1:9200","172.16.213.77:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
host:是一个数组类型的值,后面跟的值是elasticsearch节点的地址与端口,默认端口是9200。可添加多个地址。index:写入elasticsearch的索引的名称,这里可以使用变量。Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+ 号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。这种以天为单位分割的写法,可以很容易的删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。manage_template:用来设置是否开启logstash自动管理模板功能,如果设置为false将关闭自动管理模板功能。如果我们自定义了模板,那么应该设置为false。template_name:这个配置项用来设置在Elasticsearch中模板的名称。
20.5. 综合案例
配置文件:test5.conf
input {
file {
path => ["D:/learningStation/ELK/logstash-7.3.0/nginx.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
启动操作
logstash.bat -f ../config/test5.conf
使用kibana查询
rest api
GET /logstash-2023.12.01-000001/_search
结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "logstash-2023.12.01-000001",
"_type" : "_doc",
"_id" : "XAtKI4wBJWH2-vp0vzz4",
"_score" : 1.0,
"_source" : {
"path" : "D:/learningStation/ELK/logstash-7.3.0/nginx.log",
"clientip" : [
"172",
"16",
"213",
"132"
],
"bytes" : "5036",
"referrer" : "GET / HTTP/1.1",
"response_new" : "403",
"host" : "DESKTOP-2UTH0A1",
"@version" : "1",
"@timestamp" : "2019-02-07T08:24:16.000Z"
}
},
{
"_index" : "logstash-2023.12.01-000001",
"_type" : "_doc",
"_id" : "XQtKI4wBJWH2-vp0vzz4",
"_score" : 1.0,
"_source" : {
"path" : "D:/learningStation/ELK/logstash-7.3.0/nginx.log",
"clientip" : [
"172",
"16",
"213",
"133"
],
"bytes" : "5037",
"referrer" : "GET / HTTP/1.1",
"response_new" : "403",
"host" : "DESKTOP-2UTH0A1",
"@version" : "1",
"@timestamp" : "2019-02-07T08:24:17.000Z"
}
},
{
"_index" : "logstash-2023.12.01-000001",
"_type" : "_doc",
"_id" : "XgtKI4wBJWH2-vp0vzz4",
"_score" : 1.0,
"_source" : {
"path" : "D:/learningStation/ELK/logstash-7.3.0/nginx.log",
"clientip" : [
"172",
"16",
"213",
"134"
],
"bytes" : "5038",
"referrer" : "GET / HTTP/1.1",
"response_new" : "403",
"host" : "DESKTOP-2UTH0A1",
"@version" : "1",
"@timestamp" : "2019-02-07T08:24:18.000Z"
}
}
]
}
}
21. kibana学习
21.1. 基本查询
1是什么:elk中数据展现工具。
2下载:https://www.elastic.co/cn/downloads/kibana
3使用:建立索引模式,index partten
discover 中使用DSL搜索。
21.2. 可视化
绘制图形
21.3. 仪表盘
将各种可视化图形放入,形成大屏幕。

21.4. 使用模板数据指导绘图
点击主页的添加模板数据,可以看到很多模板数据以及绘图。
21.5. 其他功能
监控,日志,APM等功能非常丰富。
堆栈监测
22. 集群部署
见部署图
22. 1. 节点的三个角色
- 主节点:master节点主要用于集群的管理及索引 比如新增结点、分片分配、索引的新增和删除等。
- 数据节点:data 节点上保存了数据分片,它负责索引和搜索操作。
- 客户端节点:client 节点仅作为请求客户端存在,client的作用也作为负载均衡器,client 节点不存数据,只是将请求均衡转发到其它结点。
通过下边两项参数来配置结点的功能:
node.master: #是否允许为主节点
node.data: #允许存储数据作为数据节点
node.ingest: #是否允许成为协调节点
四种组合方式:
master=true,data=true:即是主结点又是数据节点
master=false,data=true:仅是数据节点
master=true,data=false:仅是主节点,不存储数据
master=false,data=false:即不是主节点也不是数据节点,此时可设置ingest为true表示它是一个客户端。
23. 项目实战
23.1. 项目一:ELK用于日志分析
需求:集中收集分布式服务的日志
23.1.1. 逻辑模块程序随时输出日志
@SpringBootTest
public class TestLog {
private static final Logger LOGGER = LoggerFactory.getLogger(TestLog.class);
@Test
public void testLog() {
Random random = new Random();
while (true) {
int userid = random.nextInt(10);
LOGGER.info("userId:{},send:{}", userid, "hello world.I am " + userid);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
23.1.2. logstash收集日志到es
grok 内置类型
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
INT (?:[+-]?(?:[0-9]+))
BASE10NUM (?[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})
BASE16NUM (?(?"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``))
UUID [A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12}
# Networking
MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})
CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4})
WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2})
COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2})
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?/(?>[\w_%!$@:.,-]+|\\.)*)+
TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+))
WINPATH (?>[A-Za-z]+:|\\)(?:\\[^\\?*]*)+
URIPROTO [A-Za-z]+(\+[A-Za-z+]+)?
URIHOST %{IPORHOST}(?::%{POSINT:port})?
# uripath comes loosely from RFC1738, but mostly from what Firefox
# doesn't turn into %XX
URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%_\-]*)+
#URIPARAM \?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)?
URIPARAM \?[A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]]*
URIPATHPARAM %{URIPATH}(?:%{URIPARAM})?
URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})?
# Months: January, Feb, 3, 03, 12, December
MONTH \b(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|Nov(?:ember)?|Dec(?:ember)?)\b
MONTHNUM (?:0?[1-9]|1[0-2])
MONTHNUM2 (?:0[1-9]|1[0-2])
MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9])
# Days: Monday, Tue, Thu, etc...
DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)
# Years?
YEAR (?>\d\d){1,2}
HOUR (?:2[0123]|[01]?[0-9])
MINUTE (?:[0-5][0-9])
# '60' is a leap second in most time standards and thus is valid.
SECOND (?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?)
TIME (?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9])
# datestamp is YYYY/MM/DD-HH:MM:SS.UUUU (or something like it)
DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR}
DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR}
ISO8601_TIMEZONE (?:Z|[+-]%{HOUR}(?::?%{MINUTE}))
ISO8601_SECOND (?:%{SECOND}|60)
TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?
DATE %{DATE_US}|%{DATE_EU}
DATESTAMP %{DATE}[- ]%{TIME}
TZ (?:[PMCE][SD]T|UTC)
DATESTAMP_RFC822 %{DAY} %{MONTH} %{MONTHDAY} %{YEAR} %{TIME} %{TZ}
DATESTAMP_RFC2822 %{DAY}, %{MONTHDAY} %{MONTH} %{YEAR} %{TIME} %{ISO8601_TIMEZONE}
DATESTAMP_OTHER %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{TZ} %{YEAR}
DATESTAMP_EVENTLOG %{YEAR}%{MONTHNUM2}%{MONTHDAY}%{HOUR}%{MINUTE}%{SECOND}
# Syslog Dates: Month Day HH:MM:SS
SYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME}
PROG (?:[\w._/%-]+)
SYSLOGPROG %{PROG:program}(?:\[%{POSINT:pid}\])?
SYSLOGHOST %{IPORHOST}
SYSLOGFACILITY <%{NONNEGINT:facility}.%{NONNEGINT:priority}>
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
# Shortcuts
QS %{QUOTEDSTRING}
# Log formats
SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:
COMMONAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}
# Log Levels
LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
写logstash配置文件。
%{DATA:datetime}\ \[%{DATA:thread}\]\ %{DATA:level}\ \ %{DATA:class} - %{GREEDYDATA:logger}
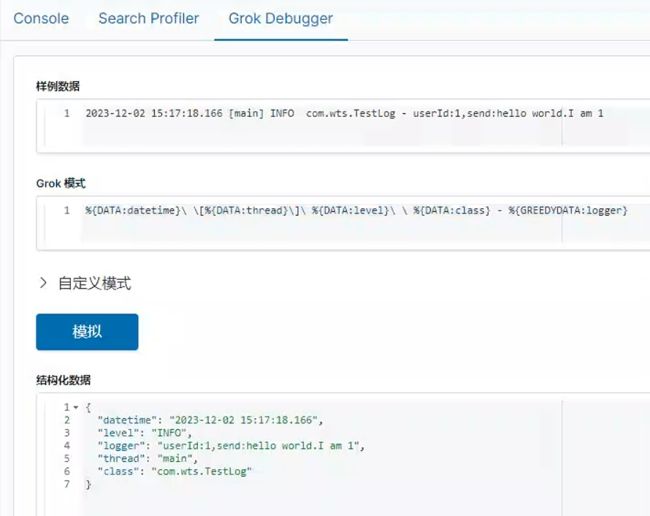
配置文件:test6.conf
input {
file {
path => ["D:/logs/log-*.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{DATA:datetime}\ \[%{DATA:thread}\]\ %{DATA:level}\ \ %{DATA:class} - %{GREEDYDATA:logger}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss.SSS"]
}
if "_grokparsefailure" in [tags] {
drop { }
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logger-%{+YYYY.MM.dd}"
}
}
启动操作
logstash.bat -f ../config/test6.conf
- kibana展现数据
rest api
GET logger-2023.12.02/_search
结果
{
"took" : 171,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3921,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "LHhyKYwBFtgQZ58-ehGk",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:47:58.461",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.630Z",
"thread" : "main",
"logger" : "userId:9,send:hello world.I am 9\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "KHhyKYwBFtgQZ58-ehKm",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:41:51.212",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.339Z",
"thread" : "main",
"logger" : "userId:2,send:hello world.I am 2\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "-nhyKYwBFtgQZ58-ehOn",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-02 15:17:19.182",
"@version" : "1",
"path" : "D:/logs/log-2023-12-02.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.864Z",
"thread" : "main",
"logger" : "userId:1,send:hello world.I am 1\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "rHhyKYwBFtgQZ58-ehGl",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-02 15:18:16.449",
"@version" : "1",
"path" : "D:/logs/log-2023-12-02.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.875Z",
"thread" : "main",
"logger" : "userId:6,send:hello world.I am 6\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "AXhyKYwBFtgQZ58-ehOn",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:42:43.448",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.353Z",
"thread" : "main",
"logger" : "userId:7,send:hello world.I am 7\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "6XhyKYwBFtgQZ58-fRTL",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:46:56.805",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.622Z",
"thread" : "main",
"logger" : "userId:6,send:hello world.I am 6\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "MnhyKYwBFtgQZ58-ehGk",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:48:01.485",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.633Z",
"thread" : "main",
"logger" : "userId:0,send:hello world.I am 0\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "b3hyKYwBFtgQZ58-ehSo",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:43:48.679",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.377Z",
"thread" : "main",
"logger" : "userId:6,send:hello world.I am 6\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "LnhyKYwBFtgQZ58-ehKm",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:41:54.273",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.340Z",
"thread" : "main",
"logger" : "userId:7,send:hello world.I am 7\r",
"host" : "DESKTOP-2UTH0A1"
}
},
{
"_index" : "logger-2023.12.02",
"_type" : "_doc",
"_id" : "k3hyKYwBFtgQZ58-ehKm",
"_score" : 1.0,
"_source" : {
"class" : "com.wts.TestLog",
"datetime" : "2023-12-01 15:49:05.692",
"@version" : "1",
"path" : "D:/logs/log-2023-12-01.log",
"level" : "INFO",
"@timestamp" : "2023-12-02T07:33:36.648Z",
"thread" : "main",
"logger" : "userId:5,send:hello world.I am 5\r",
"host" : "DESKTOP-2UTH0A1"
}
}
]
}
}
23.2. 项目二:学成在线站内搜索模块
23.2.1 mysql导入course_pub表
/*
Navicat Premium Data Transfer
Source Server : local
Source Server Type : MySQL
Source Server Version : 50721
Source Host : localhost:3306
Source Schema : xc_course
Target Server Type : MySQL
Target Server Version : 50721
File Encoding : 65001
Date: 10/11/2019 02:50:34
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for course_pub
-- ----------------------------
DROP TABLE IF EXISTS `course_pub`;
CREATE TABLE `course_pub` (
`id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '主键',
`name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '课程名称',
`users` varchar(500) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '适用人群',
`mt` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '大分类',
`st` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '小分类',
`grade` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '课程等级',
`studymodel` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '学习模式',
`teachmode` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '教育模式',
`description` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '课程介绍',
`timestamp` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) COMMENT '时间戳logstash使用',
`charge` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '收费规则,对应数据字典',
`valid` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '有效性,对应数据字典',
`qq` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '咨询qq',
`price` float(10, 2) NULL DEFAULT NULL COMMENT '价格',
`price_old` float(10, 2) NULL DEFAULT NULL COMMENT '原价格',
`expires` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '过期时间',
`start_time` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程有效期-开始时间',
`end_time` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程有效期-结束时间',
`pic` varchar(500) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程图片',
`teachplan` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '课程计划',
`pub_time` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '发布时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of course_pub
-- ----------------------------
INSERT INTO `course_pub` VALUES ('297e7c7c62b888f00162b8a7dec20000', 'test_java基础33', 'b1', '1-3', '1-3-3', '200002', '201002', NULL, 'java 从入门到删库跑路', '2019-10-28 11:26:25', '203002', '204002', '32432', NULL, NULL, NULL, NULL, NULL, 'group1/M00/00/00/wKgZhV2tIgiAaYVMAAA2T52Dthw246.jpg', '{\"children\":[{\"children\":[],\"id\":\"40288f9b6e0c10d8016e0c37f72a0000\",\"pname\":\"1\"},{\"children\":[{\"id\":\"40288581632b593e01632bd53ff10001\",\"mediaFileoriginalname\":\"solr.avi\",\"mediaId\":\"5fbb79a2016c0eb609ecd0cd3dc48016\",\"pname\":\"Hello World\"},{\"id\":\"40288f9b6e106273016e106485f30000\",\"mediaFileoriginalname\":\"lucene.avi\",\"mediaId\":\"c5c75d70f382e6016d2f506d134eee11\",\"pname\":\"java基础\"}],\"id\":\"40288581632b593e01632bd4ec360000\",\"pname\":\"程序入门\"},{\"children\":[{\"id\":\"40288f9b6dce18e3016dcef16d860001\",\"mediaFileoriginalname\":\"solr.avi\",\"mediaId\":\"5fbb79a2016c0eb609ecd0cd3dc48016\",\"pname\":\"三级节点\"}],\"id\":\"40288f9b6dce18e3016dcef12a1d0000\",\"pname\":\"二级节点\"},{\"children\":[{\"id\":\"40288c9a6ca3968e016ca417fa8d0001\",\"mediaFileoriginalname\":\"lucene.avi\",\"mediaId\":\"c5c75d70f382e6016d2f506d134eee11\",\"pname\":\"test04-01\"}],\"id\":\"40288c9a6ca3968e016ca417b4a50000\",\"pname\":\"test04\"},{\"children\":[{\"id\":\"40288581632b593e01632bd5d31f0003\",\"mediaFileoriginalname\":\"solr.avi\",\"mediaId\":\"5fbb79a2016c0eb609ecd0cd3dc48016\",\"pname\":\"表达式\"},{\"id\":\"40288581632b593e01632bd606480004\",\"pname\":\"逻辑运算\"}],\"id\":\"40288581632b593e01632bd597810002\",\"pname\":\"编程基础\"},{\"children\":[{\"id\":\"402881e764034e4301640351f3d70003\",\"pname\":\"一切皆为对象\"}],\"id\":\"402881e764034e430164035091a00002\",\"pname\":\"面向对象\"},{\"children\":[{\"id\":\"402899816ad8457c016ad9282a330001\",\"pname\":\"test06\"}],\"id\":\"402899816ad8457c016ad927ba540000\",\"pname\":\"test05\"}],\"id\":\"4028858162bec7f30162becad8590000\",\"pname\":\"test_java基础33\"}', '2019-10-28 11:26:24');
INSERT INTO `course_pub` VALUES ('297e7c7c62b888f00162b8a965510001', 'test_java基础node', 'test_java基础', '1-3', '1-3-2', '200001', '201001', NULL, 'test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2test_java基础2', '2019-10-24 16:26:34', '203001', '204001', '443242', NULL, NULL, NULL, NULL, NULL, NULL, '{\"children\":[{\"children\":[{\"id\":\"402881e66417407b01641744fc650001\",\"pname\":\"入门程序\"}],\"id\":\"402881e66417407b01641744afc30000\",\"pname\":\"基础知识\"},{\"children\":[],\"id\":\"4028858162e5d6e00162e5e0727d0001\",\"pname\":\"java基础语法\"},{\"children\":[{\"id\":\"4028d0866b158241016b502433d60002\",\"pname\":\"第二节\"}],\"id\":\"4028d0866b158241016b5023f51e0001\",\"pname\":\"第二章\"}],\"id\":\"4028858162e5d6e00162e5e0227b0000\",\"pname\":\"test_java基础2\"}', '2019-10-24 16:26:33');
SET FOREIGN_KEY_CHECKS = 1;
23.2.2 创建索引xc_course
23.2.3 创建映射
PUT /xc_course
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"description" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"grade" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"mt" : {
"type" : "keyword"
},
"name" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"users" : {
"index" : false,
"type" : "text"
},
"charge" : {
"type" : "keyword"
},
"valid" : {
"type" : "keyword"
},
"pic" : {
"index" : false,
"type" : "keyword"
},
"qq" : {
"index" : false,
"type" : "keyword"
},
"price" : {
"type" : "float"
},
"price_old" : {
"type" : "float"
},
"st" : {
"type" : "keyword"
},
"status" : {
"type" : "keyword"
},
"studymodel" : {
"type" : "keyword"
},
"teachmode" : {
"type" : "keyword"
},
"teachplan" : {
"analyzer" : "ik_max_word",
"search_analyzer": "ik_smart",
"type" : "text"
},
"expires" : {
"type" : "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"pub_time" : {
"type" : "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"start_time" : {
"type" : "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"end_time" : {
"type" : "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "xc_course"
}
23.2.4 logstash创建模板文件
Logstash的工作是从MySQL中读取数据,向ES中创建索引,这里需要提前创建mapping的模板文件以便logstash使用。
在logstach的config目录创建xc_course_template.json,内容如下:
{
"mappings" : {
"doc" : {
"properties" : {
"charge" : {
"type" : "keyword"
},
"description" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"end_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"expires" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"grade" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"mt" : {
"type" : "keyword"
},
"name" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"pic" : {
"index" : false,
"type" : "keyword"
},
"price" : {
"type" : "float"
},
"price_old" : {
"type" : "float"
},
"pub_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"qq" : {
"index" : false,
"type" : "keyword"
},
"st" : {
"type" : "keyword"
},
"start_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"status" : {
"type" : "keyword"
},
"studymodel" : {
"type" : "keyword"
},
"teachmode" : {
"type" : "keyword"
},
"teachplan" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"users" : {
"index" : false,
"type" : "text"
},
"valid" : {
"type" : "keyword"
}
}
}
},
"template" : "xc_course"
}
23.2.5 logstash配置mysql.conf
1、ES采用UTC时区问题
ES采用UTC 时区,比北京时间早8小时,所以ES读取数据时让最后更新时间加8小时
where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)
mysql.conf
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/xc_course?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => root
# the path to our downloaded jdbc driver
jdbc_driver_library => "D:/maven/apache-maven-3.5.2/repository/com/mysql/mysql-connector-j/8.0.31/mysql-connector-j-8.0.31.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
#statement_filepath => "/conf/course.sql"
statement => "select * from course_pub where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)"
#定时配置
schedule => "* * * * *"
record_last_run => true
last_run_metadata_path => "D:/ELK/logstash-7.3.0/config/logstash_metadata"
}
}
output {
elasticsearch {
#ES的ip地址和端口
hosts => "localhost:9200"
#hosts => ["localhost:9200"]
#ES索引库名称
index => "xc_course"
document_id => "%{id}"
document_type => "_doc"
template =>"D:/ELK/logstash-7.3.0/config/xc_course_template.json"
template_name =>"xc_course"
template_overwrite =>"true"
}
stdout {
#日志输出
codec => json_lines
}
}
2、logstash每个执行完成会在/config/logstash_metadata记录执行时间下次以此时间为基准进行增量同步数据到索引库。
23.2.6 启动
logstash.bat -f ..\config\mysql.conf
23.2.7 后端代码
- application.yml
server:
port: 40100
spring:
application:
name: service-search
heima:
elasticsearch:
hostlist: 127.0.0.1:9200 #多个节点用逗号分隔
course:
source_field: id,name,grade,mt,st,charge,valid,pic,qq,price,price_old,status,studymodel,teachmode,expires,pub_time,start_time,end_time
# 日志配置
logging:
config: classpath:logback-spring.xml
level:
com.wts: info
- Controller
@RestController
@RequestMapping("/search/course")
public class EsCourseController {
@Autowired
EsCourseService esCourseService;
@GetMapping(value="/list/{page}/{size}")
public QueryResponseResult<CoursePub> list(@PathVariable("page") int page, @PathVariable("size") int size, CourseSearchParam courseSearchParam) {
return esCourseService.list(page,size,courseSearchParam);
}
}
- EsCourseService
@Service
public class EsCourseService {
@Value("${heima.course.source_field}")
private String source_field;
@Autowired
RestHighLevelClient restHighLevelClient;
/**
* 课程搜索
*
* @param page
* @param size
* @param courseSearchParam
* @return
*/
public QueryResponseResult<CoursePub> list(int page, int size, CourseSearchParam courseSearchParam) {
if (courseSearchParam == null) {
courseSearchParam = new CourseSearchParam();
}
// 1、创建搜索请求对象
SearchRequest searchRequest = new SearchRequest("xc_course");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 过虑源字段
String[] source_field_array = source_field.split(",");
searchSourceBuilder.fetchSource(source_field_array, new String[]{});
// 创建布尔查询对象
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 搜索条件
// 根据关键字搜索
if (StringUtils.isNotEmpty(courseSearchParam.getKeyword())) {
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(courseSearchParam.getKeyword(), "name", "description", "teachplan")
.minimumShouldMatch("70%")
.field("name", 10);
boolQueryBuilder.must(multiMatchQueryBuilder);
}
if (StringUtils.isNotEmpty(courseSearchParam.getMt())) {
// 根据一级分类
boolQueryBuilder.filter(QueryBuilders.termQuery("mt", courseSearchParam.getMt()));
}
if (StringUtils.isNotEmpty(courseSearchParam.getSt())) {
// 根据二级分类
boolQueryBuilder.filter(QueryBuilders.termQuery("st", courseSearchParam.getSt()));
}
if (StringUtils.isNotEmpty(courseSearchParam.getGrade())) {
// 根据难度等级
boolQueryBuilder.filter(QueryBuilders.termQuery("grade", courseSearchParam.getGrade()));
}
// 设置boolQueryBuilder到searchSourceBuilder
searchSourceBuilder.query(boolQueryBuilder);
// 设置分页参数
if (page <= 0) {
page = 1;
}
if (size <= 0) {
size = 12;
}
// 起始记录下标
int from = (page - 1) * size;
searchSourceBuilder.from(from);
searchSourceBuilder.size(size);
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.postTags("");
// 设置高亮字段
// node学习
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
QueryResult<CoursePub> queryResult = new QueryResult();
List<CoursePub> list = new ArrayList<CoursePub>();
try {
// 2、执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3、获取响应结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits().value;
// 匹配的总记录数
// long totalHits = hits.totalHits;
queryResult.setTotal(totalHits);
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
CoursePub coursePub = new CoursePub();
// 源文档
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
// 取出id
String id = (String) sourceAsMap.get("id");
coursePub.setId(id);
// 取出name
String name = (String) sourceAsMap.get("name");
// 取出高亮字段name
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields != null) {
HighlightField highlightFieldName = highlightFields.get("name");
if (highlightFieldName != null) {
Text[] fragments = highlightFieldName.fragments();
StringBuffer stringBuffer = new StringBuffer();
for (Text text : fragments) {
stringBuffer.append(text);
}
name = stringBuffer.toString();
}
}
coursePub.setName(name);
// 图片
String pic = (String) sourceAsMap.get("pic");
coursePub.setPic(pic);
// 价格
Double price = null;
try {
if (sourceAsMap.get("price") != null) {
price = (Double) sourceAsMap.get("price");
}
} catch (Exception e) {
e.printStackTrace();
}
coursePub.setPrice(price);
// 旧价格
Double price_old = null;
try {
if (sourceAsMap.get("price_old") != null) {
price_old = (Double) sourceAsMap.get("price_old");
}
} catch (Exception e) {
e.printStackTrace();
}
coursePub.setPrice_old(price_old);
// 将coursePub对象放入list
list.add(coursePub);
}
} catch (IOException e) {
e.printStackTrace();
}
queryResult.setList(list);
QueryResponseResult<CoursePub> queryResponseResult = new QueryResponseResult<CoursePub>(CommonCode.SUCCESS, queryResult);
return queryResponseResult;
}
}