python爬取CSDN文章并保存为pdf文档
目录
一、安装requests、parsel和pdfkit库
二、获取发送请求的url地址
三、获取数据
1.headers
2.获取响应体的属性内容,获取网页源代码。
四、解析数据
1.把获取到的html字符串数据转成 selector 解析对象,返回的就是selector对象
2.根据标签属性内容,提取相关数据
2.1查找每一篇文章的url地址
2.2把每一个url地址提取出来
2.3获取文章详情页标题和内容
五、保存数据
1.把文章内容保存成html文件
2.替换特殊字符
六、把html文件转成pdf文件
全部代码:
wkhtmltopdf下载地址
wkhtmltopdf安装
一、安装requests、parsel和pdfkit库
确保已经安装了requests、parsel和pdfkit。以下是安装命令:
pip install pdfkit
pip install parsel
pip install requests
安装失败可能的原因:
1.pip不是内部命令
需要设置python的环境变量
2.安装到一半出现很多红色报错
网络连接超时,切换成国内镜像源
3.安装成功了,但是pycharm调用失败
I.是否安装多个python版本
II.pycharm里面python解释器是否设置好
二、获取发送请求的url地址
搜索标题,Response就是服务器给我们返回的文章内容。

点击Preview就是预览的意思。

-
Request URL:发送请求的url地址
https://blog.csdn.net/m0_74830349/article/details/133458302 -
Request Method:请求方式
-
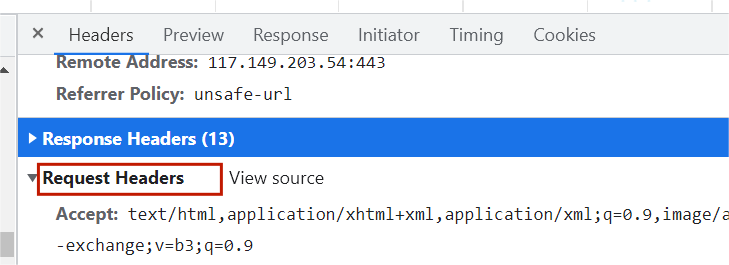
Request Headers:请求头,参数就在这个里面
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36


三、获取数据
1.headers
headers请求头,把python代码伪装成浏览器进行请求,可以在开发者工具里面进行查询。
user-agent:浏览器的基本信息。
response对象:200状态码,表示请求成功。
import requests
url = 'https://blog.csdn.net/m0_74830349/article/details/133458302'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
print(response)
2.获取响应体的属性内容,获取网页源代码。
# print(response)
print(response.text)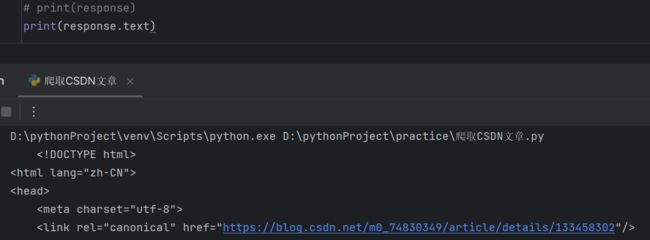
四、解析数据
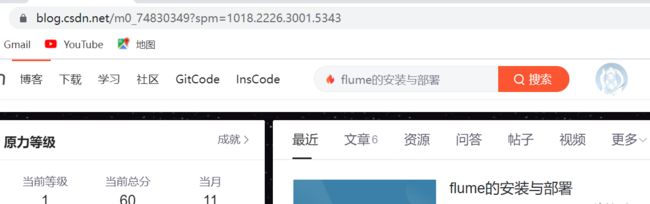
进入主页,url地址改变了:
import requests
import parsel
url = 'https://blog.csdn.net/m0_74830349?spm=1018.2226.3001.5343'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
# print(response)
# print(response.text)
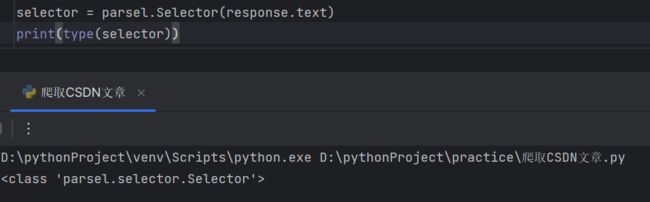
selector = parsel.Selector(response.text)
print(type(selector))1.把获取到的html字符串数据转成 selector 解析对象,返回的就是selector对象
2.根据标签属性内容,提取相关数据
# print(type(selector))
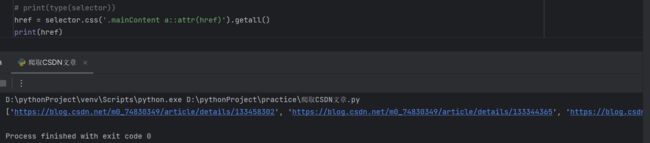
href = selector.css('.mainContent a::attr(href)').getall()
print(href)2.1查找每一篇文章的url地址
由图可知,每一篇文章的地址都在mainContent下


2.2把每一个url地址提取出来
getall返回的是列表,现在对于文章详情页url地址发送请求。
# print(href)
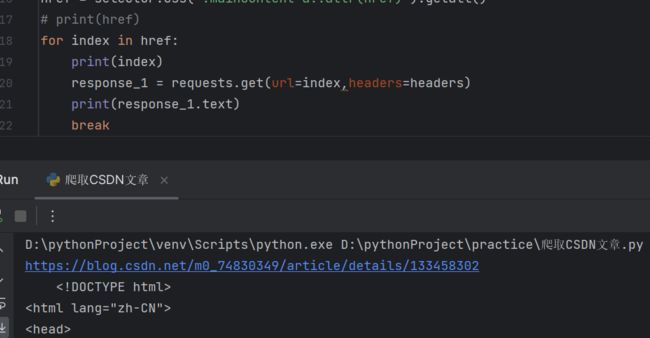
for index in href:
print(index)
response_1 = requests.get(url=index,headers=headers)
print(response_1.text)
break 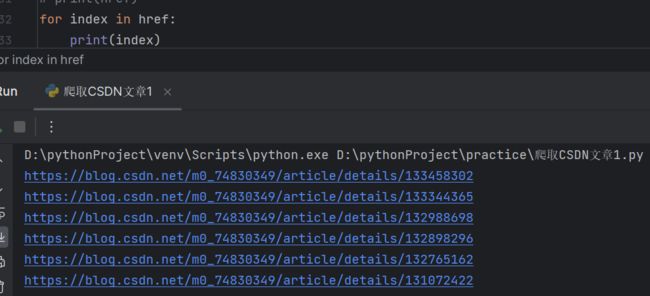
2.3获取文章详情页标题和内容
# print(response_1.text)
selector_1 = parsel.Selector(response_1.text)
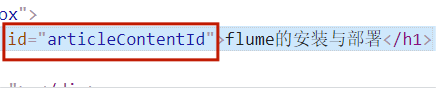
title = selector_1.css('#articleContentId::text').get()
content_views = selector_1.css('#content_views').get()
print(title)
print(content_views)
break
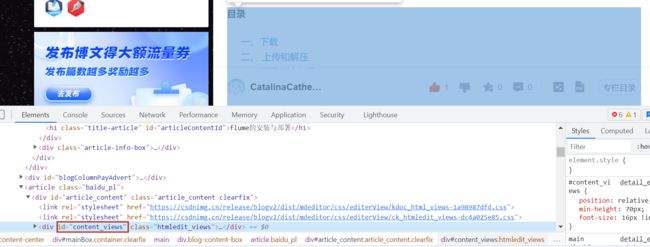

五、保存数据
1.把文章内容保存成html文件
os:文件操作模块
保存下来的html文件存放在pdf文件夹下面。
import os
filename = 'pdf\\' #文件名字
if not os.path.exists(filename): #如果没有这个文件夹的话
os.mkdir(filename) #自动创建一下这个文件夹
html_str = """
Document
{article}
"""html_content = html_str.format(article=content_views)
# print(title)
# print(content_views)
# break
with open(filename + title + '.html', mode='w',encoding='utf-8')as f:
f.write(html_content)
print('正在保存:', title) 


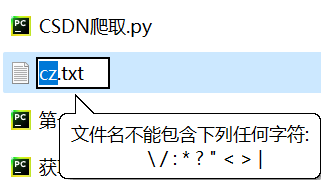
2.替换特殊字符
在Windows系统中文件名不能包含\/:*?"<>|
import re
def change_title(name):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_name = re.sub(mode,'_',name)
return new_namenew_title = change_title(title)

删掉之前的pdf文件夹,重新运行一下。
六、把html文件转成pdf文件
import pdfkitnew_title = change_title(title)
content_views = selector_1.css('#content_views').get()
html_content = html_str.format(article=content_views)
html_path = filename + new_title + '.html'
pdf_path = filename + new_title + '.pdf'
# print(title)
# print(content_views)
# break
with open(html_path, mode='w',encoding='utf-8') as f:
f.write(html_content)
print('正在保存:', title)
config = pdfkit.configuration(wkhtmltopdf=r'D:\wkhtmltopdfoct\wkhtmltopdf\binwkhtmltopdf.exe')
pdfkit.from_file(html_path,pdf_path,configuration=config)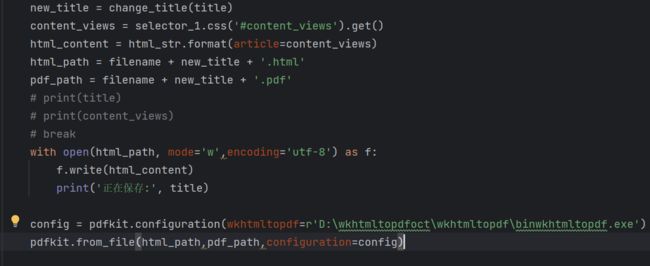
下载完成:
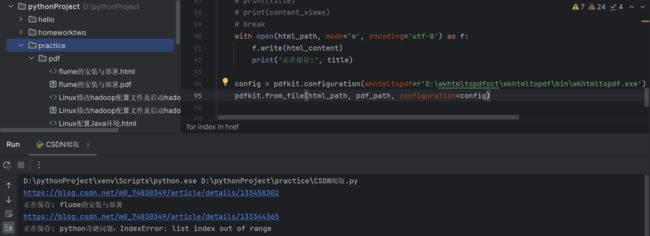
全部代码:
import requests
import parsel
import os
import re
import pdfkit
def change_title(name):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_name = re.sub(mode,'_',name)
# new_name = re.sub(r'[\\\/\:\*\?\"\<\>\|]','_',name)
return new_name
filename = 'pdf\\' #文件名字
if not os.path.exists(filename): #如果没有这个文件夹的话
os.mkdir(filename) #自动创建一下这个文件夹
html_str = """
Document
{article}
"""
url = 'https://blog.csdn.net/m0_74830349?spm=1018.2226.3001.5343'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
# print(response)
# print(response.text)
selector = parsel.Selector(response.text)
# print(type(selector))
href = selector.css('.mainContent a::attr(href)').getall()
# print(href)
for index in href:
# print(index)
response_1 = requests.get(url=index,headers=headers)
# print(response_1.text)
selector_1 = parsel.Selector(response_1.text)
title = selector_1.css('#articleContentId::text').get()
new_title = change_title(title)
content_views = selector_1.css('#content_views').get()
html_content = html_str.format(article=content_views)
html_path = filename + new_title + '.html'
pdf_path = filename + new_title + '.pdf'
# print(title)
# print(content_views)
# break
with open(html_path, mode='w',encoding='utf-8') as f:
f.write(html_content)
print('正在保存:', title)
config = pdfkit.configuration(wkhtmltopdf=r'D:\wkhtmltopdfoct\wkhtmltopdf\binwkhtmltopdf.exe')
pdfkit.from_file(html_path,pdf_path,configuration=config)填写自己软件的安装地址:D:\wkhtmltopdfoct\wkhtmltopdf\binwkhtmltopdf.exe
wkhtmltopdf下载地址
wkhtmltopdf
wkhtmltopdf安装
http://t.csdnimg.cn/2YZZH