Go 程序编译过程(基于 Go1.21)
版本说明
- Go 1.21
官方文档
Go 语言官方文档详细阐述了 Go 语言编译器的具体执行过程,Go1.21 版本可以看这个:https://github.com/golang/go/tree/release-branch.go1.21/src/cmd/compile
大致过程如下:
-
解析 (
cmd/compile/internal/syntax):- 词法分析器和语法分析器:源代码被分词(词法分析)并解析(语法分析)。
- 语法树构建:为每个源文件构建一个语法树。
-
类型检查 (
cmd/compile/internal/types2):- 类型检查:
types2包是go/types的一个移植版本,它使用syntax包的 AST(抽象语法树)而不是go/ast。
- 类型检查:
-
IR 构建(“noding”):
- 编译器类型 (
cmd/compile/internal/types) - 编译器 AST (
cmd/compile/internal/ir) - AST 转换 (
cmd/compile/internal/typecheck) - 创建编译器 AST (
cmd/compile/internal/noder) - 这个阶段使用自己的 AST 定义和 Go 类型的表示,这些定义和表示形式是用 C 编写时遗留下来的。它的所有代码都是根据这些编写的,因此类型检查后的下一步是转换语法和
types2表示形式到ir和types。这个过程被称为“noding”。
- 编译器类型 (
-
中间阶段:
- 死代码消除 (
cmd/compile/internal/deadcode) - 函数调用内联 (
cmd/compile/internal/inline) - 已知接口方法调用的去虚拟化 (
cmd/compile/internal/devirtualize) - 逃逸分析 (
cmd/compile/internal/escape) - 在 IR 表示上执行几个优化过程:死代码消除、(早期的)去虚拟化、函数调用内联和逃逸分析。
- 死代码消除 (
-
Walk (
cmd/compile/internal/walk):- 求值顺序和语法糖:这是对 IR 表示的最后一次遍历,它有两个目的:将复杂的语句分解为简单的单个语句,引入临时变量并遵守求值顺序;将高级 Go 构造转换为更原始的构造。
-
通用 SSA (
cmd/compile/internal/ssa和cmd/compile/internal/ssagen):- 在这个阶段,IR 被转换为静态单赋值(SSA)形式,这是一种具有特定属性的低级中间表示,使得从中实现优化并最终生成机器代码变得更容易。
-
生成机器代码 (
cmd/compile/internal/ssa和cmd/internal/obj):- 这是编译器的机器依赖阶段,以“lower”过程开始,将通用值重写为它们的机器特定变体。然后进行最终的代码优化过程。最后,Go 函数被转换为一系列
obj.Prog指令,这些指令被汇编器(cmd/internal/obj)转换为机器代码,并写出最终的目标文件。
- 这是编译器的机器依赖阶段,以“lower”过程开始,将通用值重写为它们的机器特定变体。然后进行最终的代码优化过程。最后,Go 函数被转换为一系列

编译过程
Go 程序的编译过程符合经典编译原理的过程拆解,即三阶段编译器,分别为编译器前端、中端和后端:
- 前端(Front End): 前端的任务是进行语法分析和语义分析。这一阶段会将源代码转换为一个中间表示。在这个过程中,编译器会检查代码的语法和语义,比如语法错误、类型错误等。前端通常是依赖于具体语言的,比如 Go 的前端和 C++ 的前端就会有很大的不同。
- 中间端(Middle End): 中间端的任务是对中间表示进行优化。这一阶段的优化是语言无关的,比如常量折叠、死代码消除、循环优化等。这些优化可以提高生成的代码的性能,但是不会改变程序的语义。
- 后端(Back End): 后端的任务是将优化后的中间表示转换为目标机器代码。这一阶段会进行更多的优化,比如寄存器分配、指令选择、指令调度等。后端通常是依赖于具体机器的,比如 x86 的后端和 ARM 的后端就会有很大的不同。
参考《Go 语言底层原理剖析(郑建勋)》一书,本文将 Go 语言编译器执行流程拆分为以下几个阶段:
- 词法解析
- 语法解析
- 抽象语法树构建
- 类型检查
- 死代码消除
- 去虚拟化
- 函数内联
- 逃逸分析
- 变量捕获
- 闭包重写
- 遍历函数
- SSA 生成
- 机器码生成
下面本文将以此书为参考并结合 Go1.21.0 版本,对每个过程进行阐述。
如果只想对 Go 程序的编译过程做一个简单的了解,那阅读到这里就已经足够了。
词法解析
词法解析过程主要负责将源代码中的字符序列转换成一系列的标记(tokens),这些标记是编译器更进一步处理的基本单位。在 Go 语言的编译器中,tokens.go 文件包含了与词法分析有关的标记定义。
词法解析的过程可以分为几个关键步骤:
- 扫描(Scanning):编译器的扫描器会逐字符读取源代码,识别出基本的语法单位,如标识符、关键字、字面量、运算符等。
- 标记生成(Token Generation):每当扫描器识别出一个有效的语法单位时,它会生成一个相应的标记。例如,对于一个变量名,扫描器会生成一个标识符标记。
- 去除空白字符和注释:在生成标记的过程中,扫描器还会忽略空白字符(如空格、换行符)和注释,因为它们对程序的逻辑没有影响。
- 错误处理:如果扫描器在源代码中遇到无法识别的字符或序列,它会生成一个错误消息。
我们来看以下 tokens.go 文件中的 token 定义,它们实质上是用 iota 声明的一系列整数:
const (
_ token = iota
_EOF // EOF
// names and literals
_Name // name
_Literal // literal
// operators and operations
// _Operator is excluding '*' (_Star)
_IncOp // opop
_Define // :=
...
// delimiters
_Lparen // (
_Rparen // )
...
// keywords
_Break // break
...
// empty line comment to exclude it from .String
tokenCount //
)
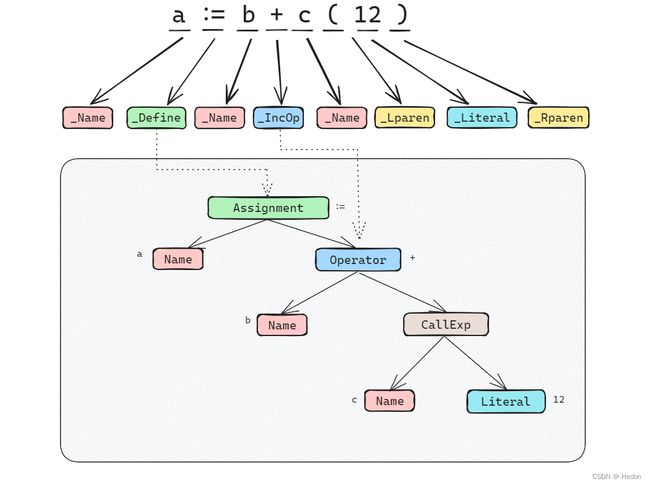
举个例子,a := b + c(12) 这个表达式,被解析后,如下图所示:

语法解析
语法解析发生在词法解析之后,其主要目的是分析源代码中标记(tokens)的排列和结构,以确定它们是否形成了有效的语句。核心算法位于两个文件中:
- syntax/nodes.go:定义了语法节点(Syntax Nodes),这些节点是构成抽象语法树(AST)的基本元素。每个节点代表了 Go 语法中的一个构造,比如变量声明、函数调用、表达式等。通过这些节点,编译器能够理解和表示程序代码的结构。
- syntax/parser.go:包含了解析器的实现。解析器负责读取词法分析阶段生成的标记流,并根据这些标记构建 AST。它遵循 Go 语言的语法规则,确保代码符合语法结构,并在遇到语法错误时提供相应的反馈。
Go 语言采用了标准的自上而下的递归下降(Top-Down Recursive-Descent)算法,以简单高效的方式完成无须回溯的语法扫描。
下面我们来看下 nodes.go 文件中对各个节点的声明(以下都省略了 struct 中的具体属性):
声明 Declarations
type (
Decl interface {
Node
aDecl()
}
ImportDecl struct {} // 导入声明
ConstDecl struct {} // 常量声明
TypeDecl struct {} // 类型声明
VarDecl struct {} // 变量声明
FuncDecl struct {} // 函数声明
)
表达式 Expressions
type (
Expr interface {
Node
typeInfo
aExpr()
}
// 省略了结构体属性
BadExpr struct {} // 无效表达式
Name struct {} // Value
BasicLit struct {} // Value
CompositeLit struct {} // Type { ElemList[0], ElemList[1], ... }
KeyValueExpr struct {} // Key: Value
FuncLit struct {} // func Type { Body }
ParenExpr struct {} // (X)
SelectorExpr struct {} // X.Sel
IndexExpr struct {} // X[Index]
SliceExpr struct {} // X[Index[0] : Index[1] : Index[2]]
AssertExpr struct {} // X.(Type)
TypeSwitchGuard struct {} // Lhs := X.(type)
Operation struct {} // 操作 +-*\
CallExpr struct {} // Fun(ArgList[0], ArgList[1], ...)
ListExpr struct {} // ElemList[0], ElemList[1], ...
ArrayType struct {} // [Len]Elem
SliceType struct {} // []Elem
DotsType struct {} // ...Elem
StructType struct {} // struct { FieldList[0] TagList[0]; FieldList[1] TagList[1]; ... }
Field struct {} // Name Type
InterfaceType struct {} // interface { MethodList[0]; MethodList[1]; ... }
FuncType struct {} // type FuncName func (param1, param2) return1, return2
MapType struct {} // map[Key]Value
ChanType struct {} // chan Elem, <-chan Elem, chan<- Elem
)
语句 Statements
type (
// 所有语句的通用接口
Stmt interface {
Node
aStmt()
}
// 更加简单语句的通用接口
SimpleStmt interface {}
EmptyStmt struct {} // 空语句
LabeledStmt struct {} // 标签语句
BlockStmt struct {} // 代码块语句
ExprStmt struct {} // 表达式语句
SendStmt struct {} // 发送语句,用于 channel
DeclStmt struct {} // 声明语句
AssignStmt struct {} // 赋值语句
BranchStmt struct {} // 分支语句,break, continue
CallStmt struct {} // 调用语句
ReturnStmt struct {} // 返回语句
IfStmt struct {} // if 条件语句
ForStmt struct {} // for 循环语句
SwitchStmt struct {} // switch 语句
SelectStmt struct {} // select 语句
)
我们可以重点来看一下最常用的赋值语句:
type AssignStmt struct {
Op Operator // 操作符 0 means no operation
Lhs, Rhs Expr // 左右两个表达式 Rhs == nil means Lhs++ (Op == Add) or Lhs-- (Op == Sub)
simpleStmt
}
举例
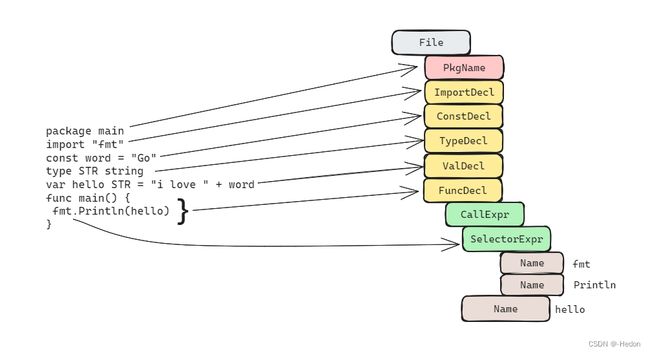
package main
import "fmt"
const name = "hedon"
type String string
var s String = "hello " + word
func main() {
fmt.Println(s)
}
上面的源代码会被解析成如下图所示:
再来看一个赋值语句是如何解析的,就以之前的 a := b + c(12) 为例:
抽象语法树构建
编译器前端必须构建程序的中间表示形式,以便在编译器中端及后端使用,抽象语法树(Abstract Syntax Tree,AST)是一种常见的树状结构的中间态。
抽象语法树
抽象语法树(AST,Abstract Syntax Tree)是源代码的树状结构表示,它用于表示编程语言的语法结构,但不包括所有语法细节。AST 是编译器设计中的关键概念,广泛应用于编译器的各个阶段。
基本概念:
- 结构:AST 是一种树形结构,其中每个节点代表程序中的一种构造(如表达式、语句等)。
- 抽象性:它抽象出了代码的语法结构,省略了某些语法细节(如括号、特定的语法格式等)。
节点类型:
- 根节点:代表整个程序或一段完整代码。
- 内部节点:通常代表控制结构(如循环、条件语句)和操作符(如加、减、乘、除)。
- 叶节点:代表程序中的基本元素,如常量、变量和标识符。
构建过程:
- 词法分析:源代码首先经过词法分析,分解为一系列标记(tokens)。
- 语法分析:然后,基于这些标记,语法分析器根据编程语言的语法规则构建 AST。
- 树的构建:在这个过程中,分析器会根据语言的语法创建不同类型的节点,并按照程序的结构将它们组织成树。
使用场景:
- 语义分析:编译器使用 AST 来进行类型检查和其他语义分析。
- 代码优化:在优化阶段,编译器会对 AST 进行变换,以提高代码的执行效率。
- 代码生成:编译器根据 AST 生成中间代码或目标代码。
优点:
- 简化处理:由于省略了不必要的语法细节,AST 使得编译器的设计更为简洁和高效。
- 灵活性:AST 可以轻松地进行修改和扩展,便于实现各种编译器功能。
- 可视化:AST 的树形结构使得代码的逻辑结构一目了然,有助于理解和调试。
Go 构建抽象语法树
在 Go 语言源文件中的任何一种 Declarations 都是一个根节点,如下 pkgInit(decls) 函数将源文件中的所有声明语句都转换为节点(Node),代码位于:syntax/syntax.go 和 syntax/parser.go 中。
Parse()
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}
下面是对 Parse() 函数的一个简单解释:
- 作用:解析单个 Go 源文件并返回相应的语法树。
- 参数
base: 位置基础信息。src: 要解析的源文件。errh: 错误处理函数。pragh: 用于处理每个遇到的编译指令(pragma)。mode: 解析模式。
- 返回值:返回一个
File类型的指针,表示解析后的 AST,以及可能的错误。 - 错误处理
- 如果
errh不为空:将会调用它处理每个遇到的错误,解析器尽可能多地处理源文件。此时,只有在没有找到正确的包声明时,返回的语法树才为nil。 - 如果
errh为空:解析器在遇到第一个错误时立即终止,返回的语法树为nil。
- 如果
其中 File 类型结构如下:
type File struct {
Pragma Pragma // 编译指令
PkgName *Name // 包名
DeclList []Decl // 源文件中的各种声明
EOF Pos // 解析位置
GoVersion string // go 版本
node // 该源文件的 AST 根节点
}
parser.fileOrNil()
具体的解析过程在 parser.fileOrNil() 方法中:
func (p *parser) fileOrNil() *File {
if trace {
defer p.trace("file")()
}
// 1. 初始化文件节点
f := new(File)
f.pos = p.pos()
// 2. 解析包声明
f.GoVersion = p.goVersion
p.top = false
if !p.got(_Package) { // 包声明必须放在第一位,这跟我们学 Go 语法对应上了
p.syntaxError("package statement must be first")
return nil
}
f.Pragma = p.takePragma() // 获取编译指令
f.PkgName = p.name() // 获取包名
p.want(_Semi) // _Semi 在之前的 tokens.go 中可以发现是分号(;),是的,包声明后面就是得带分号
// 3. 处理包声明错误
if p.first != nil {
return nil
}
// 4. 循环解析顶层声明
// 循环处理文件中的所有声明,包括 import、const、type、var 和 func
// 对每种类型的声明,调用其解析函数,如 importDecl、constDecl 进行解析
prev := _Import
for p.tok != _EOF {
if p.tok == _Import && prev != _Import {
p.syntaxError("imports must appear before other declarations")
}
prev = p.tok
switch p.tok {
case _Import:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
case _Const:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
default:
// 5. 处理异常和错误
if p.tok == _Lbrace && len(f.DeclList) > 0 && isEmptyFuncDecl(f.DeclList[len(f.DeclList)-1]) {
p.syntaxError("unexpected semicolon or newline before {")
} else {
p.syntaxError("non-declaration statement outside function body")
}
p.advance(_Import, _Const, _Type, _Var, _Func)
continue
}
// Reset p.pragma BEFORE advancing to the next token (consuming ';')
// since comments before may set pragmas for the next function decl.
p.clearPragma()
if p.tok != _EOF && !p.got(_Semi) {
p.syntaxError("after top level declaration")
p.advance(_Import, _Const, _Type, _Var, _Func)
}
}
// 6. 完成解析,记录文件结束的位置
p.clearPragma()
f.EOF = p.pos()
return f
}
总结 parser.fileOrNil() 方法的处理过程大致如下:
- 初始化文件节点:
f := new(File): 创建一个新的File节点。f.pos = p.pos(): 设置节点的位置信息。
- 解析包声明(Package Clause):
f.GoVersion = p.goVersion: 记录 Go 版本。p.top = false: 设置状态,表示不再处于文件顶层。if !p.got(_Package) {...}: 检查是否存在包声明,如果没有,则报错并返回nil。f.Pragma = p.takePragma(): 获取与包声明相关的编译指令。f.PkgName = p.name(): 获取包名。p.want(_Semi): 确认包声明后有分号。
- 处理包声明错误:
if p.first != nil {...}: 如果已有错误,停止解析并返回nil。
- 解析顶层声明:
- 通过一个循环处理文件中的所有声明,包括导入(import)、常量(const)、类型(type)、变量(var)和函数(func)。
- 对每种类型的声明,调用相应的解析函数(如
p.importDecl、p.constDecl等)。 - 将解析得到的声明添加到
f.DeclList中。
- 处理异常和错误:
- 在解析过程中遇到的任何不符合语法的情况都会触发错误处理。
- 使用
p.syntaxError报告语法错误。 - 使用
p.advance在遇到错误时跳过一些标记,以尝试恢复到一个已知的稳定状态。
- 完成解析:
- 当遇到文件结束标记(EOF)时,完成解析。
f.EOF = p.pos(): 记录文件结束的位置。- 返回构建的
File节点。
Op 字段
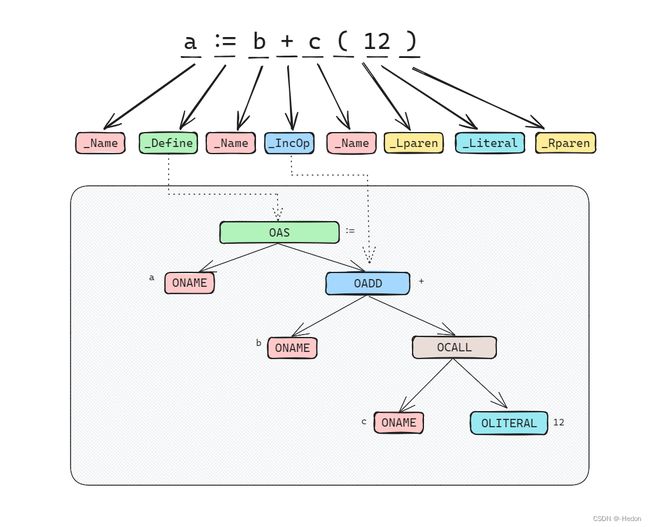
AST 每个节点都包含了当前节点属性的 Op 字段,定义在 ir/node.go 中,以 O 开头。与词法解析阶段中的 token 相同的是,Op 字段也是一个整数。不同的是,每个 Op 字段都包含了语义信息。例如,当一个节点的 Op 操作为 OAS 时,该节点代表的语义为 Left := Right,而当节点的操作为 OAS2 时,代码的语义为 x,y,z = a,b,c。
这里仅展示部分 Op 字段的定义:
type Op uint8
// Node ops.
const (
OXXX Op = iota
// names
ONAME // var or func name
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name
OLITERAL // literal
ONIL // nil
// expressions
OADD // X + Y
...
// X = Y or (if Def=true) X := Y
// If Def, then Init includes a DCL node for X.
OAS
// Lhs = Rhs (x, y, z = a, b, c) or (if Def=true) Lhs := Rhs
// If Def, then Init includes DCL nodes for Lhs
OAS2
...
// statements
OLABEL // Label:
...
OEND
)
以前面举例的赋值语句 a := b + c(12) 为例,该赋值语句最终会编程如下图所示的抽象语法树,节点之间具有从上到下的层次结构和依赖关系。
类型检查
完成 AST 的初步构建后,就进入类型检查阶段遍历节点树并决定节点的类型。具体的代码在 types2/check,go。
checker.CheckFiles()
其中最核心的方法就是 checker.CheckFiles():
func (check *Checker) checkFiles(files []*syntax.File) (err error) {
// 1. 不检查 unsafe 包
if check.pkg == Unsafe {
return nil
}
// 2. 检查 go 版本
check.version, err = parseGoVersion(check.conf.GoVersion)
if err != nil {
return err
}
if check.version.after(version{1, goversion.Version}) {
return fmt.Errorf("package requires newer Go version %v", check.version)
}
if check.conf.FakeImportC && check.conf.go115UsesCgo {
return errBadCgo
}
// 3. 错误处理
defer check.handleBailout(&err)
// 4. 详细检查每个地方
print := func(msg string) {
if check.conf.Trace {
fmt.Println()
fmt.Println(msg)
}
}
print("== initFiles ==")
check.initFiles(files)
print("== collectObjects ==")
check.collectObjects()
print("== packageObjects ==")
check.packageObjects()
print("== processDelayed ==")
check.processDelayed(0) // incl. all functions
print("== cleanup ==")
check.cleanup()
print("== initOrder ==")
check.initOrder()
if !check.conf.DisableUnusedImportCheck {
print("== unusedImports ==")
check.unusedImports()
}
print("== recordUntyped ==")
check.recordUntyped()
if check.firstErr == nil {
check.monomorph()
}
check.pkg.goVersion = check.conf.GoVersion
check.pkg.complete = true
// 5. 更新和清理
check.imports = nil
check.dotImportMap = nil
check.pkgPathMap = nil
check.seenPkgMap = nil
check.recvTParamMap = nil
check.brokenAliases = nil
check.unionTypeSets = nil
check.ctxt = nil
return
}
总结 checker.checkFiles() 的过程大致如下:
- 检查特殊包:如果是
Unsafe包,则直接返回,因为它不能进行类型检查且不应被修改。 - 解析Go版本:根据配置解析 Go 版本,并进行兼容性检查。
- 错误处理:设置一个延迟函数来处理任何可能出现的错误。
- 类型检查的步骤:
initFiles: 初始化文件。collectObjects: 收集对象。packageObjects: 打包对象。processDelayed: 处理延迟的任务(包括所有函数)。cleanup: 清理。initOrder: 初始化顺序。unusedImports: 检查未使用的导入。recordUntyped: 记录未定类型。monomorph: 如果没有错误,进行单态化处理。
- 更新和清理:
- 更新包的 Go 版本和完成状态。
- 清理不再需要的内部数据结构,释放内存。
- 返回:函数完成类型检查并返回。
可以看出具体的检查步骤都封装在第 4 点的各个函数中,其实检查的东西我们学习 Go 语言时所需要掌握的那些语法,我们以 initFiles 为例子来分析一下,对于其他检查函数,你有兴趣的话也可以了解一下,这里推荐将函数源代码拷贝发给 ChatGPT-4,相信对你会有很大的帮助。
checker.initFiles()
// initFiles 初始化与文件相关的类型检查器
// 参数中的 files 必须都属于同一个 package
func (check *Checker) initFiles(files []*syntax.File) {
// 1. 初始化
check.files = nil
check.imports = nil
check.dotImportMap = nil
check.firstErr = nil
check.methods = nil
check.untyped = nil
check.delayed = nil
check.objPath = nil
check.cleaners = nil
// 2. 确定包名和有效文件
pkg := check.pkg
for _, file := range files {
switch name := file.PkgName.Value; pkg.name {
case "":
if name != "_" {
pkg.name = name
} else {
check.error(file.PkgName, BlankPkgName, "invalid package name _")
}
fallthrough
case name:
check.files = append(check.files, file)
default:
check.errorf(file, MismatchedPkgName, "package %s; expected %s", name, pkg.name)
// ignore this file
}
}
// 3. 对每个文件,解析其中指定的 Go 版本
for _, file := range check.files {
v, _ := parseGoVersion(file.GoVersion)
if v.major > 0 {
if v.equal(check.version) {
continue
}
// Go 1.21 introduced the feature of setting the go.mod
// go line to an early version of Go and allowing //go:build lines
// to “upgrade” the Go version in a given file.
// We can do that backwards compatibly.
// Go 1.21 also introduced the feature of allowing //go:build lines
// to “downgrade” the Go version in a given file.
// That can't be done compatibly in general, since before the
// build lines were ignored and code got the module's Go version.
// To work around this, downgrades are only allowed when the
// module's Go version is Go 1.21 or later.
// If there is no check.version, then we don't really know what Go version to apply.
// Legacy tools may do this, and they historically have accepted everything.
// Preserve that behavior by ignoring //go:build constraints entirely in that case.
if (v.before(check.version) && check.version.before(version{1, 21})) || check.version.equal(version{0, 0}) {
continue
}
if check.posVers == nil {
check.posVers = make(map[*syntax.PosBase]version)
}
check.posVers[base(file.Pos())] = v
}
}
}
总结 checker.initFiles() 方法的大致流程如下:
- 初始化状态:清空
Checker结构体中与文件相关的多个字段,如files,imports,dotImportMap等,为新的检查过程做准备。 - 确定包名和有效文件:
- 遍历提供的文件,确定包名,并收集有效的文件。
- 如果文件的包名与
Checker中的包名不匹配,则报错并忽略该文件。
- 处理Go版本:
- 对每个文件,解析其中指定的 Go 版本。
- 处理 Go 版本的兼容性和升级逻辑,尤其是在 Go 1.21 引入的一些特性,如
//go:build行的处理。
可以看到 Go 语言开发团队在这里写了一大段关于 Go1.21 的注释,这段注释描述了 Go 1.21 版本引入的关于 Go 版本设置的两个新特性,这里简单解释一下:
- 升级 Go 版本的特性:在 Go 1.21 版本中,可以在
go.mod文件里设置一个较旧的Go版本,同时允许在源文件中通过//go:build行来指定一个更高的 Go 版本。这样做可以向后兼容,即允许旧版本代码在新版本的 Go 环境中运行。 - 降级 Go 版本的限制:Go 1.21 也允许通过
//go:build行来降低源文件中的 Go 版本。但这通常不是向后兼容的,因为在以前,//go:build行被忽略,代码总是使用模块定义的 Go 版本。为了避免兼容性问题,仅当模块的 Go 版本为 1.21 或更高时,才允许这种降级。
未指定版本的情况:如果没有明确指定 check.version,编译器就不确定应该使用哪个 Go 版本。为了保持与旧工具的兼容,如果没有明确的版本约束,编译器将忽略 //go:build 行的限制。
死代码消除
类型检查阶段完成后,编译器前端工作基本完成,后面就进入中端了。这个阶段 Go 语言编译器将对 AST 进行分析和重构,从而完成一系列优化。
第一部分是死代码消除(dead code elimination),过程识别并移除不会在运行时执行的代码。这包括未使用的变量、函数、常量等。通过删除这些无用代码片段,可以减小最终程序的大小并提高运行效率。
这部分的代码在:deadcode/deadcode.go。打开代码文件,可以看到核心就是 Func() 和 stmt() 这 2 个函数。
Func()
func Func(fn *ir.Func) {
// 1. 对函数体进行预处理
stmts(&fn.Body)
// 2. 空函数体直接返回
if len(fn.Body) == 0 {
return
}
// 3. 遍历函数体,对其中每个节点进行处理
for _, n := range fn.Body {
// 节点有任何初始化操作,则不可消除,提前返回。
if len(n.Init()) > 0 {
return
}
switch n.Op() {
case ir.OIF:
n := n.(*ir.IfStmt)
// 如果 if 语句判断条件不是常量,或者 if else 中的 body 不为空,则不可消除,提前返回
if !ir.IsConst(n.Cond, constant.Bool) || len(n.Body) > 0 || len(n.Else) > 0 {
return
}
case ir.OFOR:
n := n.(*ir.ForStmt)
// 如果 for 循环条件不是常量或一直为真,则不可消除,提前返回
if !ir.IsConst(n.Cond, constant.Bool) || ir.BoolVal(n.Cond) {
return
}
default:
return
}
}
// 4. 标记隐藏闭包为死代码
ir.VisitList(fn.Body, markHiddenClosureDead)
// 5. 重置函数体,替换为一个空语句,进行清理和优化
fn.Body = []ir.Node{ir.NewBlockStmt(base.Pos, nil)}
}
- 语句处理(
stmts(&fn.Body)):对函数体中的语句进行预处理或转换,以便于后续的分析和优化。 - 空函数体直接返回:如果函数体为空,没有任何代码需要执行,因此函数直接返回。这是一种优化,避免对空函数体进行不必要的分析。
- 遍历函数体:
- 节点初始化检查:如果任何节点有初始化操作,意味着可能存在副作用或必要的代码执行,因此函数提前返回。
If和For语句特殊处理ir.OIF:如果If语句的条件不是常量布尔值,或者If语句有非空的 body 或 else 分支,则提前返回,因为这些分支可能包含重要的代码。ir.OFOR:对于For循环,如果条件不是常量布尔值或者布尔值为真,意味着循环可能执行,因此提前返回。
- 标记隐藏闭包为死代码(
markHiddenClosureDead):如果所有节点都不触发提前返回,意味着整个函数体可能没有有效的代码执行。此时,将隐藏的闭包标记为死代码,可能是为了进一步的优化处理,如移除这些代码。 - 重置函数体:最后,将函数体替换为一个空的新块语句,这表明原始的函数体被认为是无效的或不会被执行,从而进行了代码的清理和优化。
stmt()
这个函数的目的是通过分析和简化控制流结构,来识别和移除那些在程序执行中永远不会到达的代码部分。这样的优化可以减少编译后的代码量,并提高程序运行时的效率。
func stmts(nn *ir.Nodes) {
// 1. 标记最后一个标签,其对应的 Op 字段就是 OLABEL
var lastLabel = -1
for i, n := range *nn {
if n != nil && n.Op() == ir.OLABEL {
lastLabel = i
}
}
// 2. 处理 if 和 switch 语句
for i, n := range *nn {
cut := false
if n == nil {
continue
}
if n.Op() == ir.OIF {
n := n.(*ir.IfStmt)
n.Cond = expr(n.Cond)
// if 语句根据条件是否为常量来保留和移除分支
if ir.IsConst(n.Cond, constant.Bool) {
var body ir.Nodes
if ir.BoolVal(n.Cond) {
ir.VisitList(n.Else, markHiddenClosureDead)
n.Else = ir.Nodes{}
body = n.Body
} else {
ir.VisitList(n.Body, markHiddenClosureDead)
n.Body = ir.Nodes{}
body = n.Else
}
// 如果 then 或 else 分支以 panic 或 return 语句结束,那么可以安全地移除该节点之后的所有语句。
// 这是因为 panic 或 return 会导致函数终止,后续的代码永远不会被执行。
// 同时,注释提到要避免移除标签(labels),因为它们可能是 goto 语句的目标,
// 而且为了避免 goto 相关的复杂性,没有使用 isterminating 标记。
// might be the target of a goto. See issue 28616.
if body := body; len(body) != 0 {
switch body[(len(body) - 1)].Op() {
case ir.ORETURN, ir.OTAILCALL, ir.OPANIC:
if i > lastLabel {
cut = true
}
}
}
}
}
// 尝试简化 switch 语句,根据条件值决定哪个分支始终被执行
if n.Op() == ir.OSWITCH {
n := n.(*ir.SwitchStmt)
func() {
if n.Tag != nil && n.Tag.Op() == ir.OTYPESW {
return // no special type-switch case yet.
}
var x constant.Value // value we're switching on
if n.Tag != nil {
if ir.ConstType(n.Tag) == constant.Unknown {
return
}
x = n.Tag.Val()
} else {
x = constant.MakeBool(true) // switch { ... } => switch true { ... }
}
var def *ir.CaseClause
for _, cas := range n.Cases {
if len(cas.List) == 0 { // default case
def = cas
continue
}
for _, c := range cas.List {
if ir.ConstType(c) == constant.Unknown {
return // can't statically tell if it matches or not - give up.
}
if constant.Compare(x, token.EQL, c.Val()) {
for _, n := range cas.Body {
if n.Op() == ir.OFALL {
return // fallthrough makes it complicated - abort.
}
}
// This switch entry is the one that always triggers.
for _, cas2 := range n.Cases {
for _, c2 := range cas2.List {
ir.Visit(c2, markHiddenClosureDead)
}
if cas2 != cas {
ir.VisitList(cas2.Body, markHiddenClosureDead)
}
}
// Rewrite to switch { case true: ... }
n.Tag = nil
cas.List[0] = ir.NewBool(c.Pos(), true)
cas.List = cas.List[:1]
n.Cases[0] = cas
n.Cases = n.Cases[:1]
return
}
}
}
if def != nil {
for _, n := range def.Body {
if n.Op() == ir.OFALL {
return // fallthrough makes it complicated - abort.
}
}
for _, cas := range n.Cases {
if cas != def {
ir.VisitList(cas.List, markHiddenClosureDead)
ir.VisitList(cas.Body, markHiddenClosureDead)
}
}
n.Cases[0] = def
n.Cases = n.Cases[:1]
return
}
// TODO: handle case bodies ending with panic/return as we do in the IF case above.
// entire switch is a nop - no case ever triggers
for _, cas := range n.Cases {
ir.VisitList(cas.List, markHiddenClosureDead)
ir.VisitList(cas.Body, markHiddenClosureDead)
}
n.Cases = n.Cases[:0]
}()
}
// 3. 对节点的初始化语句递归调用 stmt 函数进行处理
if len(n.Init()) != 0 {
stmts(n.(ir.InitNode).PtrInit())
}
// 4. 遍历其他控制结构,递归处理它们的内部语句
switch n.Op() {
case ir.OBLOCK:
n := n.(*ir.BlockStmt)
stmts(&n.List)
case ir.OFOR:
n := n.(*ir.ForStmt)
stmts(&n.Body)
case ir.OIF:
n := n.(*ir.IfStmt)
stmts(&n.Body)
stmts(&n.Else)
case ir.ORANGE:
n := n.(*ir.RangeStmt)
stmts(&n.Body)
case ir.OSELECT:
n := n.(*ir.SelectStmt)
for _, cas := range n.Cases {
stmts(&cas.Body)
}
case ir.OSWITCH:
n := n.(*ir.SwitchStmt)
for _, cas := range n.Cases {
stmts(&cas.Body)
}
}
// 5. 如果确定了是可以消除的代码,则对函数体进行阶段,且标记其中的闭包为死代码
if cut {
ir.VisitList((*nn)[i+1:len(*nn)], markHiddenClosureDead)
*nn = (*nn)[:i+1]
break
}
}
}
- 标记最后一个标签:遍历所有节点,记录最后一个标签(
OLABEL)的位置。这对于后面判断是否可以安全地移除代码非常重要。 - 处理
if和switch语句:- 对于
if语句,它根据条件是否为常量来决定保留哪个分支,移除另一个分支。 - 对于
switch语句,它尝试简化switch,根据条件值决定哪个分支将始终被执行。
- 对于
- 节点初始化:如果节点有初始化语句,对这些初始化语句递归调用
stmts函数。 - 遍历其他控制结构:对于
for、if、range、select和switch等控制结构,递归地处理它们的内部语句。 - 消除死代码:如果判断一个节点之后的所有代码都是无效的,它会标记这些代码为死代码并截断函数体。
去虚拟化
去虚拟化(Devirtualization)是编译器优化的一种技术,用于提高面向对象程序的性能。在面向对象编程中,方法调用通常是通过虚拟函数表(vtable)动态解析的,这被称为虚拟调用。虚拟调用允许对象在运行时表现出多态行为,但这也带来了一定的性能开销。
去虚拟化的目的是在编译时静态确定方法调用的目标,从而避免运行时的动态查找。如果编译器能够确定一个特定的接口调用总是调用同一个方法,它可以将这个虚拟调用替换为直接调用,减少运行时开销。这种优化特别适用于那些调用目标不会因为程序执行的不同路径而改变的情况。
这部分的代码在 devirtuailze/devirtualize.go。
核心就 2 个函数:
Static():遍历函数中的所有节点,尤其注意跳过在go或defer语句中的调用,并对其他接口方法调用尝试进行静态去虚拟化优化。staticCall():针对一个具体的接口方法调用,如果可能,将其替换为直接的具体类型方法调用,以优化性能。
Static()
func Static(fn *ir.Func) {
ir.CurFunc = fn
goDeferCall := make(map[*ir.CallExpr]bool)
// 1. VisitList 对 fn.Body 中所有节点调用后面的 func
ir.VisitList(fn.Body, func(n ir.Node) {
switch n := n.(type) {
// 2. 跳过 go 和 defer 语句
case *ir.GoDeferStmt:
if call, ok := n.Call.(*ir.CallExpr); ok {
goDeferCall[call] = true
}
return
// 3. 调用 staticCall 尝试进行去虚拟化
case *ir.CallExpr:
if !goDeferCall[n] {
staticCall(n)
}
}
})
}
- 设定当前函数为
fn。 - 遍历函数体内的节点,特别注意
go和defer语句。如果调用发生在这些语句中,它会被跳过,因为去虚拟化可能改变程序的语义。 - 对于不在
go或defer语句中的接口方法调用,调用staticCall函数尝试进行去虚拟化。
staticCall()
func staticCall(call *ir.CallExpr) {
// 1. 检查调用是否为接口方法调用,如果不是,直接返回
if call.Op() != ir.OCALLINTER {
return
}
// 2. 获取接收器和相关类型
sel := call.X.(*ir.SelectorExpr)
r := ir.StaticValue(sel.X)
// 3. 检查接收器是否是接口转换,如果不是,直接返回
if r.Op() != ir.OCONVIFACE {
return
}
recv := r.(*ir.ConvExpr)
// 4. 提取接收器类型
typ := recv.X.Type()
if typ.IsInterface() {
return
}
// 5. shape 类型直接返回,因为这一般涉及到泛型,需要通过字典进行间接调用
if typ.IsShape() {
return
}
if typ.HasShape() {
if base.Flag.LowerM != 0 {
base.WarnfAt(call.Pos(), "cannot devirtualize %v: shaped receiver %v", call, typ)
}
return
}
if sel.X.Type().HasShape() {
if base.Flag.LowerM != 0 {
base.WarnfAt(call.Pos(), "cannot devirtualize %v: shaped interface %v", call, sel.X.Type())
}
return
}
// 6. 类型断言和方法选择,尝试确定调用的具体方法
dt := ir.NewTypeAssertExpr(sel.Pos(), sel.X, nil)
dt.SetType(typ)
x := typecheck.Callee(ir.NewSelectorExpr(sel.Pos(), ir.OXDOT, dt, sel.Sel))
switch x.Op() {
case ir.ODOTMETH:
x := x.(*ir.SelectorExpr)
if base.Flag.LowerM != 0 {
base.WarnfAt(call.Pos(), "devirtualizing %v to %v", sel, typ)
}
call.SetOp(ir.OCALLMETH)
call.X = x
case ir.ODOTINTER:
x := x.(*ir.SelectorExpr)
if base.Flag.LowerM != 0 {
base.WarnfAt(call.Pos(), "partially devirtualizing %v to %v", sel, typ)
}
call.SetOp(ir.OCALLINTER)
call.X = x
default:
if base.Flag.LowerM != 0 {
base.WarnfAt(call.Pos(), "failed to devirtualize %v (%v)", x, x.Op())
}
return
// 7. 根据类型断言的结果,尝试将接口方法调用转换为直接方法调用或保留为接口方法调用。
types.CheckSize(x.Type())
switch ft := x.Type(); ft.NumResults() {
case 0:
case 1:
call.SetType(ft.Results().Field(0).Type)
default:
call.SetType(ft.Results())
}
// 8. 对可能修改后的方法调用进行进一步的类型检查和调整。
typecheck.FixMethodCall(call)
}
- 检查是否为接口方法调用:函数首先判断传入的调用是否是接口方法调用(
ir.OCALLINTER),这是去虚拟化的前提条件。 - 处理形状类型:代码中提到,如果接收器的类型是形状类型(用于泛型),则无法去虚拟化,因为这需要通过字典进行间接调用。
- 处理形状类型的接收器:如果接收器的类型具有形状类型,则当前无法进行去虚拟化。注释中还提到了一些待实现(TODO)的优化点,例如处理非泛型的提升方法。
- 处理形状类型的接口:如果调用的接口本身是一个形状类型,由于指针身份的不同,类型断言可能会失败,因此在这种情况下也无法去虚拟化。
- 转换方法调用:根据调用的具体情况,将接口方法调用转换为直接的方法调用(
OCALLMETH)或保留为接口方法调用(OCALLINTER)。 - 更新调用类型:为了正确处理函数返回值,需要更新调用的类型,确保参数大小和栈偏移量正确。
- 反糖化方法调用:如果创建了直接方法调用,需要对其进行后续的类型检查和调整。
函数内联
函数内联是将一个函数的代码直接插入到每个调用点,而不是进行常规的函数调用。这意味着函数的整个体被复制到每个调用该函数的地方。
优点:
- 减少开销:内联消除了函数调用的开销,如参数传递、栈操作等。
- 提升性能:有助于其他优化,比如循环展开、常量传播,因为编译器可以看到函数体内的代码。
选择哪些函数内联:
- 小函数:通常是小函数,因为它们的内联带来的性能提升相对于代码膨胀的代价来说是值得的。
- 调用频率高的函数:这些函数如果内联,可以显著减少运行时的调用开销。
在 Go 语言中,可以通过 //go:noinline 来禁止函数内联。
这部分的主要实现在 inline.inl.go,核心函数是:CanInline() 和 InlineImpossible()。
CanInline()
// Inlining budget parameters, gathered in one place
const (
// budget 是内联复杂度的衡量,
// 超过 80 表示编译器认为这个函数太复杂了,就不进行函数内联了
inlineMaxBudget = 80
)
// CanInline 用于判断 fn 是否可内联。
// 如果可以,会将 fn.Body 和 fn.Dcl 拷贝一份放到 fn.Inl,
// 其中 fn 和 fn.Body 需要确保已经经过类型检查了。
func CanInline(fn *ir.Func, profile *pgo.Profile) {
// 函数名必须有效
if fn.Nname == nil {
base.Fatalf("CanInline no nname %+v", fn)
}
// 如果不能内联,输出原因
var reason string
if base.Flag.LowerM > 1 || logopt.Enabled() {
defer func() {
if reason != "" {
if base.Flag.LowerM > 1 {
fmt.Printf("%v: cannot inline %v: %s\n", ir.Line(fn), fn.Nname, reason)
}
if logopt.Enabled() {
logopt.LogOpt(fn.Pos(), "cannotInlineFunction", "inline", ir.FuncName(fn), reason)
}
}
}()
}
// 检查是否符合不可能内联的情况,如果返回的 reason 不为空,则表示有不可以内联的原因
reason = InlineImpossible(fn)
if reason != "" {
return
}
if fn.Typecheck() == 0 {
base.Fatalf("CanInline on non-typechecked function %v", fn)
}
n := fn.Nname
if n.Func.InlinabilityChecked() {
return
}
defer n.Func.SetInlinabilityChecked(true)
cc := int32(inlineExtraCallCost)
if base.Flag.LowerL == 4 {
cc = 1 // this appears to yield better performance than 0.
}
// 设置内联预算,后面如果检查函数的复杂度超过预算了,就不内联了
budget := int32(inlineMaxBudget)
if profile != nil {
if n, ok := profile.WeightedCG.IRNodes[ir.LinkFuncName(fn)]; ok {
if _, ok := candHotCalleeMap[n]; ok {
budget = int32(inlineHotMaxBudget)
if base.Debug.PGODebug > 0 {
fmt.Printf("hot-node enabled increased budget=%v for func=%v\n", budget, ir.PkgFuncName(fn))
}
}
}
}
// 遍历函数体,计算复杂度,判断是否超过内联预算
visitor := hairyVisitor{
curFunc: fn,
budget: budget,
maxBudget: budget,
extraCallCost: cc,
profile: profile,
}
if visitor.tooHairy(fn) {
reason = visitor.reason
return
}
// 前面检查都没问题,则标记为可以内联,并复制其函数体和声明到内联结构体中
n.Func.Inl = &ir.Inline{
Cost: budget - visitor.budget,
Dcl: pruneUnusedAutos(n.Defn.(*ir.Func).Dcl, &visitor),
Body: inlcopylist(fn.Body),
CanDelayResults: canDelayResults(fn),
}
// 日志和调试
if base.Flag.LowerM > 1 {
fmt.Printf("%v: can inline %v with cost %d as: %v { %v }\n", ir.Line(fn), n, budget-visitor.budget, fn.Type(), ir.Nodes(n.Func.Inl.Body))
} else if base.Flag.LowerM != 0 {
fmt.Printf("%v: can inline %v\n", ir.Line(fn), n)
}
if logopt.Enabled() {
logopt.LogOpt(fn.Pos(), "canInlineFunction", "inline", ir.FuncName(fn), fmt.Sprintf("cost: %d", budget-visitor.budget))
}
}
- 基本检查:验证函数是否已经进行了类型检查,以及函数名是否有效。
- 判断是否可以内联:调用
InlineImpossible函数来检查是否有任何基本的限制条件阻止内联(例如函数太大、递归等)。 - 内联预算设置:根据函数的特征和可能的性能剖析信息来设定内联预算。这个预算是内联决策的关键参数之一。
- 详细分析:
hairyVisitor结构用于遍历函数体,判断是否超出了内联预算。这涉及对函数体的复杂度和大小的评估。 - 内联决策:如果函数通过了所有检查并且未超出预算,则标记为可以内联,并复制其函数体和声明(Dcl)到内联结构体中。
- 日志和调试:根据编译器的日志级别,输出关于内联决策的详细信息,例如为什么一个函数不能被内联或者它的内联成本是多少。
InlineImpossible()
func InlineImpossible(fn *ir.Func) string {
var reason string // reason, if any, that the function can not be inlined.
if fn.Nname == nil {
reason = "no name"
return reason
}
// If marked "go:noinline", don't inline.
if fn.Pragma&ir.Noinline != 0 {
reason = "marked go:noinline"
return reason
}
// If marked "go:norace" and -race compilation, don't inline.
if base.Flag.Race && fn.Pragma&ir.Norace != 0 {
reason = "marked go:norace with -race compilation"
return reason
}
// If marked "go:nocheckptr" and -d checkptr compilation, don't inline.
if base.Debug.Checkptr != 0 && fn.Pragma&ir.NoCheckPtr != 0 {
reason = "marked go:nocheckptr"
return reason
}
// If marked "go:cgo_unsafe_args", don't inline, since the function
// makes assumptions about its argument frame layout.
if fn.Pragma&ir.CgoUnsafeArgs != 0 {
reason = "marked go:cgo_unsafe_args"
return reason
}
// If marked as "go:uintptrkeepalive", don't inline, since the keep
// alive information is lost during inlining.
//
// TODO(prattmic): This is handled on calls during escape analysis,
// which is after inlining. Move prior to inlining so the keep-alive is
// maintained after inlining.
if fn.Pragma&ir.UintptrKeepAlive != 0 {
reason = "marked as having a keep-alive uintptr argument"
return reason
}
// If marked as "go:uintptrescapes", don't inline, since the escape
// information is lost during inlining.
if fn.Pragma&ir.UintptrEscapes != 0 {
reason = "marked as having an escaping uintptr argument"
return reason
}
// The nowritebarrierrec checker currently works at function
// granularity, so inlining yeswritebarrierrec functions can confuse it
// (#22342). As a workaround, disallow inlining them for now.
if fn.Pragma&ir.Yeswritebarrierrec != 0 {
reason = "marked go:yeswritebarrierrec"
return reason
}
// If a local function has no fn.Body (is defined outside of Go), cannot inline it.
// Imported functions don't have fn.Body but might have inline body in fn.Inl.
if len(fn.Body) == 0 && !typecheck.HaveInlineBody(fn) {
reason = "no function body"
return reason
}
// If fn is synthetic hash or eq function, cannot inline it.
// The function is not generated in Unified IR frontend at this moment.
if ir.IsEqOrHashFunc(fn) {
reason = "type eq/hash function"
return reason
}
return ""
}
- 无函数名:如果函数没有名字,不能内联。
- 有
go:noinline指令:显式标记为不内联。 - 有
go:norace指令并在-race编译模式下:在竞态检测编译模式下不内联标记为norace的函数。 - 有
go:nocheckptr指令并在-d checkptr编译模式下:在指针检查编译模式下不内联标记为nocheckptr的函数。 - 有
go:cgo_unsafe_args指令:对于标记为cgo_unsafe_args的函数,由于参数布局的假设,不内联。 - 有
go:uintptrkeepalive指令:不内联标记为uintptrkeepalive的函数。 - 有
go:uintptrescapes指令:不内联标记为uintptrescapes的函数。 - 有
go:yeswritebarrierrec指令:为了防止写屏障记录检查器的混淆,不内联标记为yeswritebarrierrec的函数。 - 无函数体:本地定义但没有函数体的函数(外部定义的 Go 函数)不可内联。
- 是合成的 hash 或 eq 函数:不能内联这些类型的函数。
举例
我们通过一段代码来看看编译器的函数内联情况。
func SayHello() string {
s := "hello, " + "world"
return s
}
func Fib(index int) int {
if index < 2 {
return index
}
return Fib(index-1) + Fib(index-2)
}
func ForSearch() int {
var s = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 0}
res := 0
for i := 0; i < len(s); i++ {
if s[i] == i {
res = i
}
}
return res
}
func main() {
SayHello()
Fib(65)
ForSearch()
}
在编译时我们可以加入 -m=2 标签,来打印函数的内联调试信息。在 main.go 目录下执行:
go tool compile -m=2 main.go
输出:
main.go:3:6: can inline SayHello with cost 7 as: func() string { s := "hello, " + "world"; return s }
main.go:8:6: cannot inline Fib: recursive
main.go:15:6: can inline ForSearch with cost 45 as: func() int { s := []int{...}; res := 0; for loop; return res }
main.go:26:6: cannot inline main: function too complex: cost 116 exceeds budget 80
main.go:27:10: inlining call to SayHello
main.go:29:11: inlining call to ForSearch
main.go:16:15: []int{...} does not escape
main.go:29:11: []int{...} does not escape
可以看到 SayHello() 和 ForSearch 都被内联了,而 Fib() 因为有递归,所以不会被内联。
逃逸分析
逃逸分析是 Go 语言中非常重要的优化阶段,用于标识变量内存应该被分配在栈上还是堆上。
在传统的 C 或 C++ 开发中,开发者经常会犯的错误就是函数返回了一个栈上的对象指针,在函数执行完毕后,函数栈会被销毁,如果继续访问被销毁栈上的对象指针,那么就会出现问题。
Go 语言能够通过编译时的逃逸分析识别这种问题,自动将这类变量放置到堆区,并借助 Go 运行时的垃圾回收机制自动释放内存。编译器会尽可能地将变量放置在栈上,因为栈中的对象会随着函数调用结束被自动销毁,这可以减轻运行时分配和垃圾回收的负担。
在 Go 语言中,开发者模糊了栈区和堆区的区别,不管是字符串、数组字面量,还是通过 new、make 标识符创建的对象,都既可能被分配到栈上,也可能被分配到堆上。但是,整体上会遵循 2 个原则:
- 指向栈上对象的指针不能被存储到堆上;
- 指向栈上对象的指针不能超过该栈对象的生命周期。
这部分的代码主要在 escape。
分析过程
Go 语言通过对 AST 的静态数据流分析来实现逃逸分析(escape/graph.go),在这个过程,它会构建带权重的有向图,其中权重可以表面当前变量引用和解引用的数量。
- 引用(&a) 减 1
- 解引用(*a)加 1
func (k hole) deref(where ir.Node, why string) hole { return k.shift(1).note(where, why) } // 解引用
func (k hole) addr(where ir.Node, why string) hole { return k.shift(-1).note(where, why) } // 引用
具体来说,Go 逃逸分析会按照如下规则生成数据流图(带权重的有向图):
- 每个变量作为一个节点(location);
- 每个赋值动作是一个有向边(edge),赋值给谁则指向谁;
- 解引用(deref),即
*操作会给边的权重 +1; - 引用(addr),即
&操作会给边权重 -1。
其中:节点权重 = 指向的节点权重 + 边权重
逃逸分析的目标就是找到其中节点权重为 -1 的变量,并结合上述提到的 2 个原则,来判断要不要将变量分配到堆上。
分析实例
我们举一个例子来进行分析:
package main
var o *int
func main() {
l := new(int)
*l = 42
m := &l
n := &m
o = **n
}
再次回顾一下,* 是加 1,& 是减一。按照常规思路,我们从上往下分析:
先画出节点的赋值顺序,赋值给谁,边就指向谁:

然后根据引用和解引用给边赋权重,因为 new(int) 其实就是分配一个 int(0) 并取地址,相当于 &,所以指向 l 的边权重是 -1:

节点权重 = 边权重 + 指向节点权重,因为没有对 o 变量进行任何的操作,所以 o 权重为 0,从左往右推可以得到:

经过分析,我们就找到了节点权重为 -1 的节点 new(int),又由于它的节点变量地址最终会被传递到变量 o 上,结合之前的 2 个原则,o 是一个全局变量,声明周期是超过函数栈的,所以 new(int) 会被分配到堆上。
可以执行下面语句输出逃逸结果:
go tool compile -m main.go
如:
/escape/main.go:5:6: can inline main
/escape/main.go:6:10: new(int) escapes to hea
也可以执行下面语句输出数据流图构建过程:
go build -gcflags="-m -m -l" main.go
如:
# command-line-arguments
./main.go:6:10: new(int) escapes to heap:
./main.go:6:10: flow: l = &{storage for new(int)}:
./main.go:6:10: from new(int) (spill) at ./main.go:6:10
./main.go:6:10: from l := new(int) (assign) at ./main.go:6:4
./main.go:6:10: flow: m = &l:
./main.go:6:10: from &l (address-of) at ./main.go:8:7
./main.go:6:10: from m := &l (assign) at ./main.go:8:4
./main.go:6:10: flow: n = &m:
./main.go:6:10: from &m (address-of) at ./main.go:9:7
./main.go:6:10: from n := &m (assign) at ./main.go:9:4
./main.go:6:10: flow: {heap} = **n:
./main.go:6:10: from *n (indirection) at ./main.go:10:7
./main.go:6:10: from *(*n) (indirection) at ./main.go:10:6
./main.go:6:10: from o = *(*n) (assign) at ./main.go:10:4
./main.go:6:10: new(int) escapes to heap
如果我们试一下,把 o 放在 main() 里面呢?
func main() {
var o *int
l := new(int)
*l = 42
m := &l
n := &m
o = **n
o = o // 让编译通过
}
执行下面语句:
go tool compile -m main.go
输出:
/escape/main.go:3:6: can inline main
/escape/main.go:5:10: new(int) does not escape
如我们所想,虽然 new(int) 的权重为 -1,但是它的声明周期始终没有超过 main(),所以没必要逃逸到堆上。
变量捕获
变量捕获主要是针对闭包(closure)场景而言的,由于闭包函数中可能引用闭包外的变量,因此变量捕获需要明确在闭包中通过值引用或者地址引用的方式来捕获变量。
这一过程在前面提到的逃逸分析过程中进行,具体实现在 escape/escape.go 的 flowClosure() 函数中:
func (b *batch) flowClosure(k hole, clo *ir.ClosureExpr) {
// 遍历闭包中的所有变量
for _, cv := range clo.Func.ClosureVars {
n := cv.Canonical()
loc := b.oldLoc(cv)
// 如果变量未被捕获,则触发错误
if !loc.captured {
base.FatalfAt(cv.Pos(), "closure variable never captured: %v", cv)
}
// 根据变量的特性决定是通过值还是引用捕获
// 如果变量未被重新赋值或取址,并且小于等于 128 字节,则通过值捕获
n.SetByval(!loc.addrtaken && !loc.reassigned && n.Type().Size() <= 128)
if !n.Byval() {
n.SetAddrtaken(true)
// 特殊情况处理:字典变量不通过值捕获
if n.Sym().Name == typecheck.LocalDictName {
base.FatalfAt(n.Pos(), "dictionary variable not captured by value")
}
}
// 记录闭包捕获变量的方式(值或引用)
if base.Flag.LowerM > 1 {
how := "ref"
if n.Byval() {
how = "value"
}
base.WarnfAt(n.Pos(), "%v capturing by %s: %v (addr=%v assign=%v width=%d)", n.Curfn, how, n, loc.addrtaken, loc.reassigned, n.Type().Size())
}
// 建立闭包变量的数据流
k := k
if !cv.Byval() {
k = k.addr(cv, "reference")
}
b.flow(k.note(cv, "captured by a closure"), loc)
}
}
举个例子:
package main
func main() {
a := 1
b := 2
go func() {
add(a, b)
}()
a = 99
}
func add(a, b int) {
a = a + b
}
执行下面语句看看变量的捕获方式:
go tool compile -m=2 main.go | grep "capturing"
输出:
main.go:4:2: main capturing by ref: a (addr=false assign=true width=8)
main.go:5:2: main capturing by value: b (addr=false assign=false width=8)
可以看到 a 是通过 ref 地址引用 的方式进行引用的,而 b 是通过 value 值传递 的方式进行引用的。
简单分析一下:上述例子中,闭包引用了 a 和 b 这 2 个闭包外声明的变量,而变量 a 在闭包之前又做了一些其他的操作,而 b 没有,所以对于 a,因为闭包外有操作,所以闭包内的操作可能是有特殊意义的,需要反馈到闭包外,就需要用 ref 地址引用了,而 b 在闭包外并不关心,所以闭包内的操作不会影响到闭包外,故直接使用 value 值传递 即可。
闭包重写
逃逸分析后,现在我们进入 walk 阶段了。这里首先会进行闭包重写。其核心逻辑在 walk/closure.go 中。
闭包重写分为 2 种情况:
- 闭包定义后被立即调用
- 闭包定义后不立即调用
闭包定义后被立即调用
在闭包定义后被立即调用的情况下,闭包只会被调用一次,这时可以将闭包转换为普通函数的调用形式。
如:
func main() {
a := 1
b := 2
go func() {
add(a, b)
}()
a = 99
}
func add(a, b int) {
a = a + b
}
会被转换为普通函数的调用形式:
func main() {
a := 1
b := 2
go func1(&a, b)
a = 99
}
// 注意这里 a 的类型的 *int,因为在变量捕获阶段,判断了 a 应该用地址引用
func func1(a *int, b int) {
add(*a, b)
}
func add(a, b int) {
a = a + b
}
编译器具体的处理逻辑在 directClosureCall() 中:
// directClosureCall rewrites a direct call of a function literal into
// a normal function call with closure variables passed as arguments.
// This avoids allocation of a closure object.
//
// For illustration, the following call:
//
// func(a int) {
// println(byval)
// byref++
// }(42)
//
// becomes:
//
// func(byval int, &byref *int, a int) {
// println(byval)
// (*&byref)++
// }(byval, &byref, 42)
func directClosureCall(n *ir.CallExpr) {
clo := n.X.(*ir.ClosureExpr)
clofn := clo.Func
// 如果闭包足够简单,不进行处理,留给 walkClosure 处理。
if ir.IsTrivialClosure(clo) {
return // leave for walkClosure to handle
}
// 将闭包中的每个变量转换为函数的参数。对于引用捕获的变量,创建相应的指针参数。
var params []*types.Field
var decls []*ir.Name
for _, v := range clofn.ClosureVars {
if !v.Byval() {
// 对于引用捕获的变量,创建相应的指针参数。
addr := ir.NewNameAt(clofn.Pos(), typecheck.Lookup("&"+v.Sym().Name))
addr.Curfn = clofn
addr.SetType(types.NewPtr(v.Type()))
v.Heapaddr = addr
v = addr
}
v.Class = ir.PPARAM
decls = append(decls, v)
fld := types.NewField(src.NoXPos, v.Sym(), v.Type())
fld.Nname = v
params = append(params, fld)
}
// 创建一个新的函数类型,将捕获的变量作为前置参数,并更新函数的声明。
f := clofn.Nname
typ := f.Type()
typ = types.NewSignature(nil, append(params, typ.Params().FieldSlice()...), typ.Results().FieldSlice())
f.SetType(typ)
clofn.Dcl = append(decls, clofn.Dcl...)
// 将原始的闭包调用重写为对新函数的调用,并将捕获的变量作为实际参数传递。
n.X = f
n.Args.Prepend(closureArgs(clo)...)
// 调整调用表达式的类型,以反映参数和返回值类型的变化。
if typ.NumResults() == 1 {
n.SetType(typ.Results().Field(0).Type)
} else {
n.SetType(typ.Results())
}
// 虽然不再是传统意义上的闭包,但为了确保函数被编译,将其添加到待编译列表中。
ir.CurFunc.Closures = append(ir.CurFunc.Closures, clofn)
}
这段代码是 Go 编译器中的 directClosureCall 函数,用于将直接调用的函数字面量重写为正常的函数调用,同时将闭包变量作为参数传递。这避免了闭包对象的分配。
主要步骤如下:
- 检查闭包是否简单:如果闭包足够简单,不进行处理,留给
walkClosure处理。 - 处理闭包变量:将闭包中的每个变量转换为函数的参数。对于引用捕获的变量,创建相应的指针参数。
- 更新函数类型和声明:创建一个新的函数类型,将捕获的变量作为前置参数,并更新函数的声明。
- 重写调用:将原始的闭包调用重写为对新函数的调用,并将捕获的变量作为实际参数传递。
- 更新调用表达式类型:调整调用表达式的类型,以反映参数和返回值类型的变化。
- 添加到待编译列表:虽然不再是传统意义上的闭包,但为了确保函数被编译,将其添加到待编译列表中。
这个函数的目的是优化闭包的调用,通过避免闭包对象的分配来提高性能。
闭包定义后不立即调用
如果闭包定义后不被立即调用,而是后续调用,那么同一个闭包可能会被调用多次,这个时候就必须创建闭包对象了。
编译器具体的处理逻辑在 walkClosure() 中:
func walkClosure(clo *ir.ClosureExpr, init *ir.Nodes) ir.Node {
clofn := clo.Func
// 如果没有闭包变量,闭包被视为全局函数,直接返回函数名。
if ir.IsTrivialClosure(clo) {
if base.Debug.Closure > 0 {
base.WarnfAt(clo.Pos(), "closure converted to global")
}
return clofn.Nname
}
// 对于复杂闭包,设置需要上下文标记,并进行运行时检查。
ir.ClosureDebugRuntimeCheck(clo)
clofn.SetNeedctxt(true)
// 确保闭包函数不会被重复添加到编译队列。
if !clofn.Walked() {
clofn.SetWalked(true)
ir.CurFunc.Closures = append(ir.CurFunc.Closures, clofn)
}
// 构造一个复合字面量表达式来表示闭包实例。
typ := typecheck.ClosureType(clo)
// 将闭包函数和捕获的变量作为字段添加到闭包结构中。
clos := ir.NewCompLitExpr(base.Pos, ir.OCOMPLIT, typ, nil)
clos.SetEsc(clo.Esc())
clos.List = append([]ir.Node{ir.NewUnaryExpr(base.Pos, ir.OCFUNC, clofn.Nname)}, closureArgs(clo)...)
for i, value := range clos.List {
clos.List[i] = ir.NewStructKeyExpr(base.Pos, typ.Field(i), value)
}
// 创建闭包结构的地址,并进行类型转换以符合闭包类型。
addr := typecheck.NodAddr(clos)
addr.SetEsc(clo.Esc())
cfn := typecheck.ConvNop(addr, clo.Type())
// 如果存在预分配的闭包对象,进行相关处理。
if x := clo.Prealloc; x != nil {
if !types.Identical(typ, x.Type()) {
panic("closure type does not match order's assigned type")
}
addr.Prealloc = x
clo.Prealloc = nil
}
// 对最终构建的闭包表达式进行进一步处理。
return walkExpr(cfn, init)
}
- 检查是否为简单闭包:如果没有闭包变量,闭包被视为全局函数,直接返回函数名。
- 处理非简单闭包:对于复杂闭包,设置需要上下文标记,并进行运行时检查。
- 防止重复处理:确保闭包函数不会被重复添加到编译队列。
- 创建闭包结构:构造一个复合字面量表达式来表示闭包实例。
- 填充闭包参数:将闭包函数和捕获的变量作为字段添加到闭包结构中。
- 地址和类型转换:创建闭包结构的地址,并进行类型转换以符合闭包类型。
- 处理预分配的闭包:如果存在预分配的闭包对象,进行相关处理。
- 表达式处理:对最终构建的闭包表达式进行进一步处理。
遍历函数
闭包重写后,会进入 walk 阶段,如官方 文档所说:这是对 IR 表示的最后一次遍历,它有两个目的:
- 将复杂的语句分解为简单的单个语句,引入临时变量并遵守求值顺序;
- 将高级 Go 构造转换为更原始的构造。
举个例子,walkRange() 函数针对不同类型的 range 语句(数组、切片、映射、通道和字符串)进行处理,将其转换为更基本的循环结构,并应用必要的变换。
func walkRange(nrange *ir.RangeStmt) ir.Node {
// ... 省略代码 ...
// 遍历 range 语句的不同情况
switch t.Kind() {
default:
base.Fatalf("walkRange")
// 处理数组、切片、指针(指向数组)的情况
case types.TARRAY, types.TSLICE, types.TPTR:
// ... 省略代码 ...
// 处理映射的情况
case types.TMAP:
// ... 省略代码 ...
// 处理通道的情况
case types.TCHAN:
// ... 省略代码 ...
// 处理字符串的情况
case types.TSTRING:
// ... 省略代码 ...
}
// ... 省略代码 ...
// 构建并返回新的 for 语句
nfor.PtrInit().Append(init...)
typecheck.Stmts(nfor.Cond.Init())
nfor.Cond = typecheck.Expr(nfor.Cond)
nfor.Cond = typecheck.DefaultLit(nfor.Cond, nil)
nfor.Post = typecheck.Stmt(nfor.Post)
typecheck.Stmts(body)
nfor.Body.Append(body...)
nfor.Body.Append(nrange.Body...)
var n ir.Node = nfor
n = walkStmt(n)
base.Pos = lno
return n
}
这部分代码在 walk,对其他优化感兴趣的读者可以阅读这部分的代码。
SSA 生成
遍历函数(Walk)阶段后,编译器会将 AST 转换为下一个重要的中间表示形态,称为 SSA,其全称为 Static Single Assignment,静态单赋值。SSA 被大多数现代的编译器(包括 GCC 和 LLVM)使用,用于编译过程中的优化和代码生成。其核心特点和用途如下:
- 变量唯一赋值:在 SSA 形式中,每个变量只被赋值一次,使得变量的使用和修改更加清晰。
- 方便的数据流分析:SSA 使得数据流分析更加直接和高效,因为每个变量的赋值点只有一个。
- 优化算法的基础:许多编译器优化技术,如死代码消除、常量传播、强度削减等,在 SSA 形式下更易实现。
- Phi 函数:SSA 引入了 Phi 函数来处理变量在不同控制流路径上的不同赋值。
- 代码生成:SSA 形式简化了目标代码生成的过程,因为它提供了更清晰的操作和变量使用视图。
官方对 SSA 生成阶段进行了详细的描述:Introduction to the Go compiler’s SSA backend
Go 提供了强有力的工具查看 SSA 初始及其后续优化阶段生成的代码片段,可以通过编译时指定 GOSSAFUNC={pkg.func} 实现。
以下面代码为例:
package main
var d uint8
func main() {
var a uint8 = 1
a = 2
if true {
a = 3
}
d = a
}
我们可以自行简单分析一下,这段代码前面 a 的所有操作其实都是无意义的,整段代码其实就在说 d = 3 这件事。
在 linux 或者 mac 上执行:
GOSSAFUNC=main.main go build main.go
在 Windows 上执行:
$env:GOSSAFUNC="main"
go build .\main.go
可以看到输出:
dumped SSA to .\ssa.html
通过浏览器打开生成的 ssa.html 文件,我们可以看到 SSA 的初始阶段、优化阶段和最终阶段的代码片段。

我们直接看最终的结果,来看看我们前面的分析正确与否:
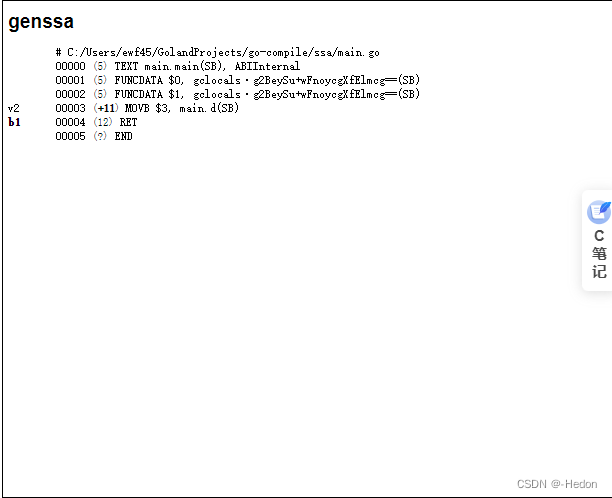
可以看到这一行:00003 (**+11**) MOVB $3, main.d(SB),那其实就是直接 d = 3。
机器码生成
在 SSA 阶段,编译器先执行与特定指令集无关的优化,再执行与特定指令集有关的优化,并最终生成与特定指令集有关的指令和寄存器分配方式。如 ssa/_gen/genericOps.go 中包含了与特定指令集无关的 Op 操作,在 ssa/_gen/AMD64Ops.go 中包含了和 AMD64 指令集相关的 Op 操作。
机器码生成阶段是编译器的机器依赖阶段,主要过程如下:
- Lowering 过程:这个过程将通用的 SSA 形式转换为特定于目标机器的变体。这包括将通用操作符替换为针对特定硬件优化的操作。
- 代码优化:在机器特定的形式上执行最终优化,进一步提高代码效率。
- 生成机器指令:将 Go 函数转换为
obj.Prog指令序列。 - 汇编和输出:这些指令由
cmd/internal/obj模块的汇编器处理,转换为机器代码,并输出最终的目标文件。
Go 为我们了解 Go 语言程序的编译和链接过程提供了一个非常好用的命令:
go build -n
其中 -n 表示只输出编译过程中将要执行的 shell 命令,但不执行。
以下面程序为例:
package main
import (
"fmt"
"github.com/spf13/cast"
)
func main() {
i := cast.ToInt("1")
fmt.Println(i)
}
这个程序引入了标准库 fmt 以及第三方库 github.com/spf13/cast。
在工程目录下执行:
go build -n -o main
可以看到输出:
mkdir -p $WORK/b001/
cat >$WORK/b001/importcfg.link << 'EOF' # internal
packagefile go-compilation=/Users/wangjiahan/Library/Caches/go-build/48/48745ff5ef7f8945297b5894ec377f47e246d94739e0b8f00e86b6d58879e71d-d
packagefile fmt=/Users/wangjiahan/Library/Caches/go-build/10/10ab74ff0df27a2f4bdbe7651290f13ad466f3df63e11241e07ccd21c169b206-d
packagefile github.com/spf13/cast=/Users/wangjiahan/Library/Caches/go-build/77/77eed0b7028cfc4c90d78d6670325d982325399573dff9d7f82ffbf76e4559e8-d
...
packagefile net/url=/Users/wangjiahan/Library/Caches/go-build/72/72d0ef9b8f99a52bf1de760bb2f630998d6bb66a3d2a3fa66bd66f4efddfbc71-d
modinfo "0w\xaf\f\x92t\b\x02A\xe1\xc1\a\xe6\xd6\x18\xe6path\tgo-compilation\nmod\tgo-compilation\t(devel)\t\ndep\tgithub.com/spf13/cast\tv1.6.0\th1:GEiTHELF+vaR5dhz3VqZfFSzZjYbgeKDpBxQVS4GYJ0=\nbuild\t-buildmode=exe\nbuild\t-compiler=gc\nbuild\tCGO_ENABLED=1\nbuild\tCGO_CFLAGS=\nbuild\tCGO_CPPFLAGS=\nbuild\tCGO_CXXFLAGS=\nbuild\tCGO_LDFLAGS=\nbuild\tGOARCH=arm64\nbuild\tGOOS=darwin\n\xf92C1\x86\x18 r\x00\x82B\x10A\x16\xd8\xf2"
EOF
mkdir -p $WORK/b001/exe/
cd .
/opt/homebrew/opt/go/libexec/pkg/tool/darwin_arm64/link -o $WORK/b001/exe/a.out -importcfg $WORK/b001/importcfg.link -buildmode=pie -buildid=FDJiS-4glijTlqBbjVbe/UWsngURatTblImv3DE6-/OjO-hZGekrr-XpHFs_zA/FDJiS-4glijTlqBbjVbe -extld=cc /Users/wangjiahan/Library/Caches/go-build/48/48745ff5ef7f8945297b5894ec377f47e246d94739e0b8f00e86b6d58879e71d-d
/opt/homebrew/opt/go/libexec/pkg/tool/darwin_arm64/buildid -w $WORK/b001/exe/a.out # internal
mv $WORK/b001/exe/a.out main
这里建议你先尝试自行分析一下这个编译过程,再继续往下阅读。
经过分析,上述过程可以分为以下 8 个步骤:
- 创建工作目录:
mkdir -p $WORK/b001/创建一个临时工作目录,用于存放编译过程中的临时文件。 - 生成导入配置文件:
cat >$WORK/b001/importcfg.link << 'EOF'命令开始创建一个名为importcfg.link的文件,这个文件包含了编译过程中需要的包文件路径。 - 写入包文件路径:接下来的多行内容是对
importcfg.link文件的填充,指定了各个依赖包的存储位置。 - 结束文件写入:
EOF标志着importcfg.link文件内容的结束。 - 创建可执行文件目录:
mkdir -p $WORK/b001/exe/创建一个目录,用于存放最终的可执行文件。 - 编译链接:
/opt/homebrew/opt/go/libexec/pkg/tool/darwin_arm64/link -o $WORK/b001/exe/a.out ...这一步是编译链接的核心,它使用Go的链接工具,根据之前生成的importcfg.link文件,将代码编译成可执行文件。 - 更新构建ID:
/opt/homebrew/opt/go/libexec/pkg/tool/darwin_arm64/buildid -w $WORK/b001/exe/a.out这一步更新了可执行文件的构建ID。 - 移动可执行文件:
mv $WORK/b001/exe/a.out main将编译好的可执行文件移动到当前目录,并重命名为main。
如下图所示:

参考资料
- Go1.21 官方文档
- 《Go 语言底层原理剖析》
- 《Go 语言设计与实现》
- Go: Overview of the Compiler
- 维基百科 - AST
- 维基百科 - SSA
- Go 机制:逃逸分析学习笔记
- ChatGPT-4
以上便是 Go 语言在 1.21.0 这个版本下编译过程的整个过程,笔者会在阅读完《用 Go 语言自制解释器》和《用 Go 语言自制编译器》这两本书后,若有对编译原理有更深入的体会和感悟,再回过来对本文的内容进行勘误和进一步提炼。