深入剖析Kafka--Producer篇
转自:https://blog.csdn.net/szwandcj/article/details/76796459
背景
Kafka诞生于Linkedin,以可靠性和巨量吞吐著称,网上清一色将它归为消息队列,用户可以按主题发布及订阅流经Kafka的数据,从这角度看它确实是消息队列,但这仅仅是它的一个方面,在这之上它首先是流式数据传输管道。
管道对实时分析的价值是巨大的,首先它是实时分析系统的天然缓冲屏障,可以通过固定的消费频率避免被突如其来的流量峰值击垮;其次它架起了业务系统到分析系统的数据路径,也将分析和业务两个系统在一定程度上解耦。仅从数据角度看,管道成了分析系统的入口。
为什么是更深入
经过我过人的”视野“洞察后,我决定踢开”百撕不得其姐“的Spark,改从入口的Kafka突破。小卡也的确很贴心,Producer端完全java化了,我也逐渐了适应了Idea烦人的快捷键和界面,看起源码来开始得心应手。其实一开始我也没打算看源码,买了本厚厚的书,期待它能像《深度理解Java虚拟机》一样开启我的智慧,结果它光只贴源码了,我一直认为真正的懂是撇开代码能讲清楚一件事,所以决定还是一行行的阅读代码,然后尽可能分析得比书更深入,所以就叫《更加深入剖析Kafka》,这一周会陆续补完生产者篇。
数据集成
数据集成从领域/系统集成角度看很类似早期的数据库表接口,有过这种经历的都会明白其中的痛苦,suffer a lot,这也是为什么业界在反思后更多主张依赖抽象的接口集成方式。理论上对任何事物做抽象后都是数据,所以数据集成架构可以解决任何事情,但这种解决是建立在人对数据有所定义上,当数据的生产和消费不是一个人时就很容易出现问题。
消息系统也有类似问题,如果由源系统定义消息结构,消息的任何变动就需要充分评估,这就像回到了关系集成的时代,要改表尤其修改某个字段语义变得几乎不可能,先召集大家开会,再制定改动方案,而往往是即使做了充分的事前评估,落地时还是一堆问题,几乎永远评估不到这份数据的使用全貌。因此往往源系统定义的消息都会字段超多,因为只能加字段而无法改和删。如果在协作上由下游系统定义消息结构,它就会更类似是个抽象接口,但在下游系统很多且共通性很小时这也变得几乎不可能。所以消息只能带来松耦合而无法换来高内聚,源系统开发一定会是想拿刀捅死胆敢要求修改消息结构的那群人,呲牙瞠目的喊“How dare u,fucker”
我不是反对消息以及数据集成,只是反思这种方式,也不主张接口万岁,没有一种集成方式是万能的。集成方式应该基于团队协作方式制定,比如提供web服务那肯定是接口比消息更适合。
地图
我喜欢抠代码细节会比较啰嗦,所以光生产者篇就会很长。我觉得架构设计就是细节,系统设计撇开细节只谈愿景是无意义的。比如Spring Ioc,原型上很简单,不就是个反射吗,很多人也跟我这么说过,但是深入到细节里就会发现其扩展性之优秀、配置可描述性之完备以及场景丰富度支撑之多等都是看到后会真心发出”挖草“的。Kafka也是这样的优秀中间件,很多细节处理得都特别精妙,简直就是极尽所能在榨干工程师智慧获得性能和稳定性上的一点一点提升。
本篇会分三章去叙述:
第一章主要讲关键概念、集群拓扑结构以及客户端如何自感知结构变更
第二章主要讲客户端、传输协议和最核心的积累器
第三章则主要讲优异性能和吞吐的关键批次
概念
Broker,Server,Producer和Consumer是Kafka的四个关键概念,每个中间件都有自己特有的一套术语命名方式,用大白话讲它们分别就是节点、服务端、消息生产者和消息消费者。
生产者
生产者泛指一切消息源,KafkaProducer并不是Kafka的生产者实现,而是提供给生产者使用的编程API。生产者使用KafkaProducer.send实际只是将消息暂存至待发送批次,而在此之前它会依次被过滤、序列化和分区。
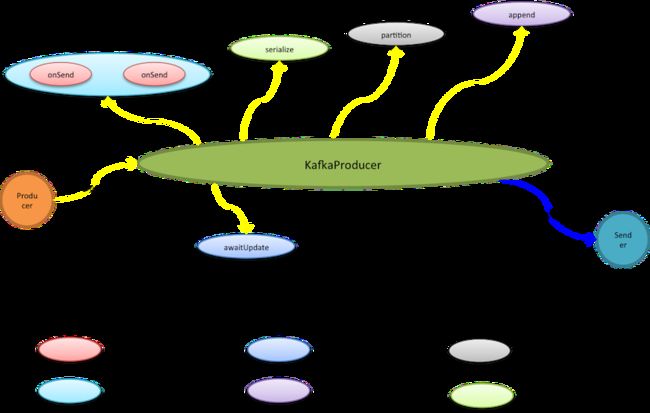
* 过滤是链式动作,通过interceptor.classes可以指定多个ProducerInterceptor类型的过滤器,按预定义顺序它们被编排入过滤链(ProducerInterceptors)。消息发送、异常以及ack动作都会触发过滤链的相应过滤动作,过滤器再根据编排顺序被依次调用。消息发送就会先过滤再处理,过滤器可以修改消息内容,但无法终止消息发送甚至无法中断过滤链,因为过滤链catch所有异常且不抛出只log记录。
* 消息被传输之前是暂存在预分配的ByteBuffer上,因此需要将消息序列化成Byte数组。KafkaProducer按照用户预定义的key.serializer和value.serializer序列化方式进行序列化,将键和值都转成Byte数组。
发送者
发送者是个守护线程,它1)收集可发送批次,将发送到相同节点的多个批次合并到同个请求,这些请求被放入<处理中请求(InFlightRequests)>,接着再写进网络通道。2)客户端开始网络轮询,发送通道中的缓冲数据,同时接收服务端应答数据。3)移除InFlightRequests中的完成请求,并进行客户端响应,关闭相关批次,释放批次所占内存。
集群
集群是对完整能力的纵向切分,目标是将流量均摊而且能水平扩展。Kafka在纵向以外又对集群横向切分。两个维度的交叉切分形成网格化的精细布局,数据被填入网格中,使读写甚至清理都效率很多,同时还能有效避免Hadoop的单点困境,领袖网格在各个节点均匀分布,流量也相应被切分平摊。
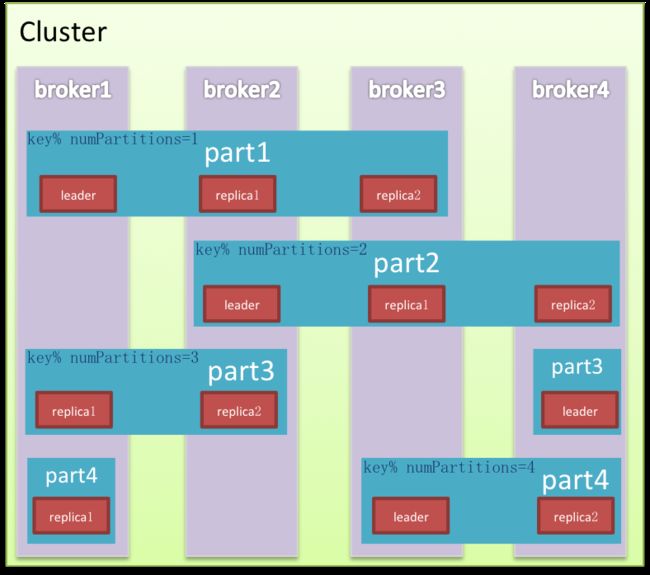
节点Node是集群的物理组成单元,也是垂直切分后的计算单元。Kafka除极少数以外的服务能力均由领袖提供,是非典型中心化集群,因为Kafka会尽量保证领袖的均匀分布,这样中心流量就被均匀打散。
分区是逻辑存储单元,是水平切分的产物,数据相对均匀的分散在各个分区,磁盘I/O处理效率也会因此大大提升。同时为保证集群高可用,分区内节点以及角色也是相对动态的,Kafka在分区内做冗余备份有多份Replica,在leader/follower故障的情况下自动做备援转移到可用节点。
元数据
节点、分区以及领袖、备份的分布等集群拓扑信息被称为元数据Metadata,元数据会动态变化,例如单点Broker故障,又或者使用Admin删除topic,…… ,因此客户端需要不断更新以及时感知这些变化。
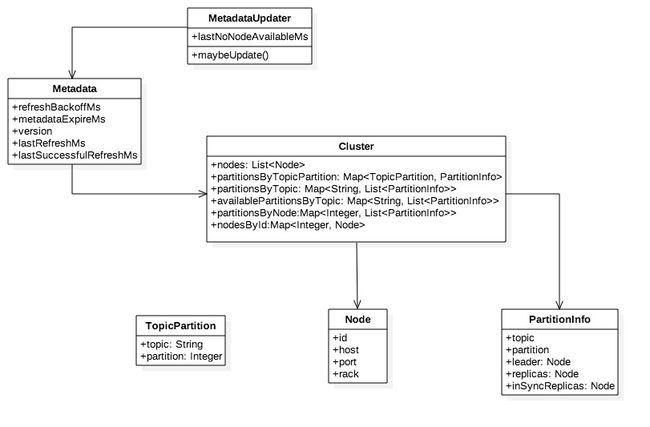
+ MetadataUpdater是刷新元数据的外观类,是KafkaClient组成部分,它尝试发起元数据更新,如果满足更新条件则立即发起更新请求。
+ Metadata的refreshBackoffMs和metadataExpireMs分别代表刷新周期和失效延时,lastRefreshMs和lastSuccessfulRefreshMs则分别代表上次刷新时间和上次成功刷新时间,注意二者区别,前者只要发生update就会被记录无关成功与否。version代表元数据版本,每次成功更新默认加1。
+ Cluster是客户端维护的集群拓扑结构,可以进行多维查询,在元数据更新成功后会被覆盖。
+ 分区信息(PartitionInfo)中的inSyncReplicas即ISR是指在同步状态的副本,其他属性都比较直观不做过多说明,。
元数据更新
每个topic都是一个二维拓扑结构,映射到具体的节点和分区;集群容纳多个topic,因此集群拓扑结构是三维的,映射到具体topic加节点加分区。更新实质就是拉取服务端的相关topics的拓扑信息,因此每次更新都需要指定感兴趣的topics。
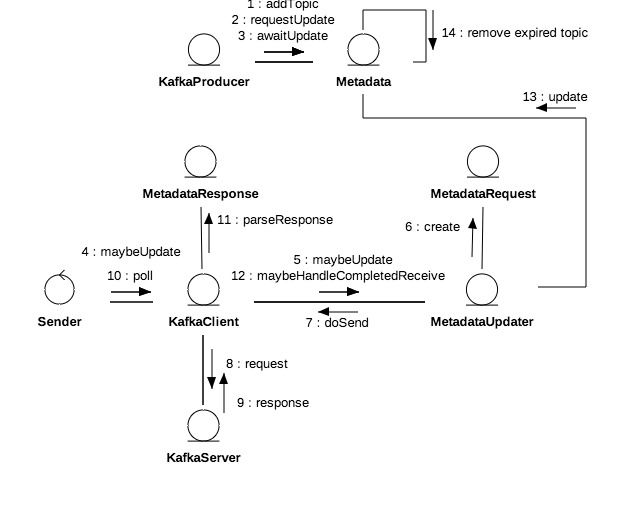
元数据更新是周期性的,客户端每次轮询网络都会先尝试更新元数据。MetadataUpdater是客户端的元数据更新组件,它会综合元数据更新延时和重连延时判定是否需要发起更新,其公式为A=Max(元数据更新延时,重连延时)。如果A>0或者有元数据获取正在进行中不进行更新。
1. 元数据更新延时=Max(失效时间, 更新时间),
+ 更新时间=上次刷新时间+刷新周期(retry.backoff.ms)-当前时间。
+ 失效时间=上次成功刷新时间+失效延时(metadata.max.age.ms)-当前时间,如果元数据被标记为强制更新(needUpdate),则立即失效。
2. 重连延时=无可用节点发生时间+重试周期-now。
3. 元数据获取是指请求已发送但结果还未返回,正在等待结果获取中。
生产者每次发送消息前都会强制元数据更新,它标记元数据需要更新并阻塞等待直至超时或更新成功。但这并不意味每一笔消息都产生一次网络更新请求,参考以上更新发起条件,即使标记需要更新在更新周期以外也不会发生更新,因此同一更新周期内的多次更新会堵塞等待同一笔更新成功。

上图假设刷新周期是100ms,并且在第一次和第二次轮询期间无更新请求。生产者的请求在阶段3进来,此时元数据轮询请求已经发出,因此用户线程实际只阻塞了10ms。假设阶段3有多个用户线程,则平均等待时间应为<刷新周期+更新请求时间/2>。
服务端的任意节点而非仅领袖节点都有完整的拓扑结构,为了获得最快的响应速度客户端只需请求负载最小的可用节点。负载的依据是客户端自己发出的到每个节点处理中请求数,即inFlightRequests大小,所以其并不代表绝对意义上的最小负载。如无可用节点,客户端会记录下无可用节点时间lastNoNodeAvailableMs。
选出的节点若是断开状态但可进行重试(距离最近建立连接的时间超过reconnect.backoff.ms),则立即初始化连接。因为Non-blocking I/O建立连接不一定立即成功,所以不能立即发送更新请求而是延到之后的执行周期。
客户端收到服务端更新应答后对元数据更新,更新会做两件事情:淘汰过期(默认5分钟)topic和覆盖客户端拓扑结构。如果发生网络异常比如建立连接失败、连接断开以及连接超时,直接标记元数据需要更新,因为此时有可能是服务端拓扑结构发生变化。但这种情况更新不需要重新指定topic,因为发生连接问题不会有服务端响应则更不会有元数据更新。
客户端
客户端和服务端都是网络传输的终(端)点,两者角色是相对而言的,前者主动发起请求并接收后者应答。
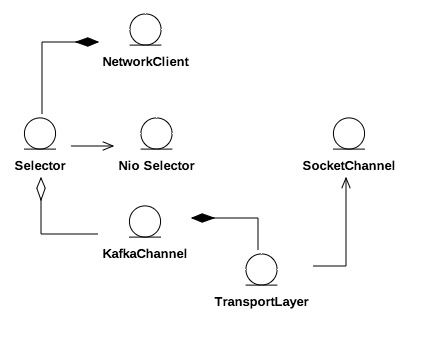
两端之间由通道(连接)连通,每个客户端都有0到多个通道连接0到多个服务端。通道通过传输层交换数据,传输层有加密和明文两种实现。客户端通过选择器轮询所有通道,标记连接状态并收发网络数据,客户端获得所有通道处理结果再统一应答。这样就将客户端与具体网络I/O实现解耦,网络对客户端而言就成为一个整体。
客户端请求
客户端请求来自上游,它是发送给客户端而非由客户端发出的,它是网络请求的载体而非网络请求。客户端对请求的处理分成两步:1)客户端收到请求,记录其为处理中请求,再将网络请求写入发送缓冲。2)客户端开始轮询:选择器先全通道轮询并记录轮询结果:已发送请求(completedSends)、已接收回复(completedReceives)和所有无效通道(disconnected);客户端再拉取选择器轮询结果,判断哪些请求已完成,并逐一回复。

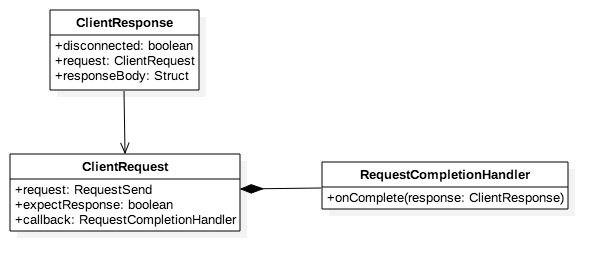
客户端请求有三个关键属性,依次为网络请求、需要网络响应和请求完成回调接口。
* 网络请求是个数据载体,它可以承载各种类型请求,任何类型的请求在其中都以一定格式序列化成字节数据,网络I/O传输的也是这部分字节。
* 需要网络响应用于标识客户端请求是否需要服务端确认,如果不需要则在网络请求发送成功后客户端请求立即成功。
* 回调接口注册在上游,用于请求完成后回调执行,它的回调方法参数是客户端响应,因此执行时会将响应回复给上游。
客户端响应也有三个关键属性,分别是坏连接标识,客户端请求引用和网络响应。客户端请求必定有回复,反馈网络I/O结果。如果有坏连接代表该笔请求失败。
场景演绎
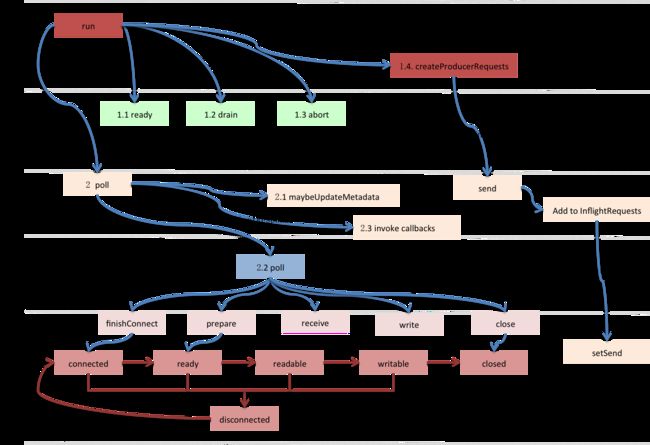
客户端上游有可能是生产者或者元数据更新组件,两者的请求类型分别为ProduceRequest和MetadataRequest,它们按传输报文格式将批次/主题转成标准格式Struct。
以发送者上游举例,它挤出批次,并构建生产请求。消息发送是以批次为最小单位,但出于节省网络资源,会将同节点下所有待发送批次合并到一个请求。
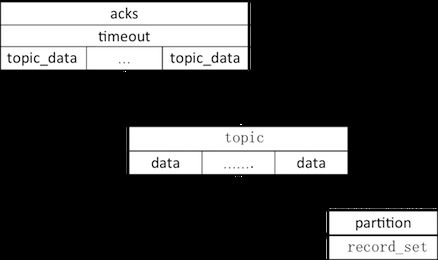
节点下的批次是个topic_data数组,topic_data是归属同一topic的所有批次,一个data就是一个批次消息集。Acks和timeout分别表示需要确认收到的replica个数和请求超时时间。
生产请求构建完成后,被序列化成字节缓冲写入RequestSend,后者再作为ClientRequest的网络请求属性发送给客户端,……
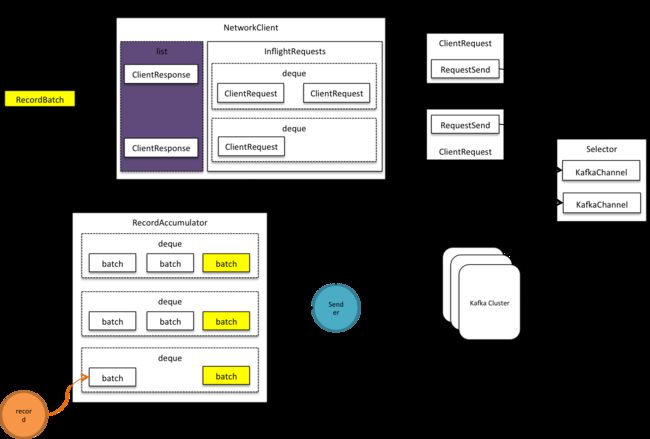
积累器
生产者就好比在向一个有分槽的水池注水,每次注入必须向同一个水槽,当前水槽容量不足则换一个,老水槽即使还有剩余空间,也不能被再次使用,除非水被排出。发送者排水也水槽为单位,一次性排出被排水槽全部水量。总水位满则禁止注水,生产者需等待足够水量放出,一段时间还没有足够空间则放弃。
在Kafka中,水池就是积累器即下图的RecordAccumulator,水槽则是消息批次即RecordBatch,注水和排水则分别应对追加消息和提取消息过程。
积累器以分区分组批次,每组一个队列,按时间先后将分区排队,只有最后/新入队的批次是开放状态,允许消息追入。消息只被追加到相应分组的最新批次,相应的也只有最老批次才被挤出,如果只有一个批次,先close再挤出。
挤出
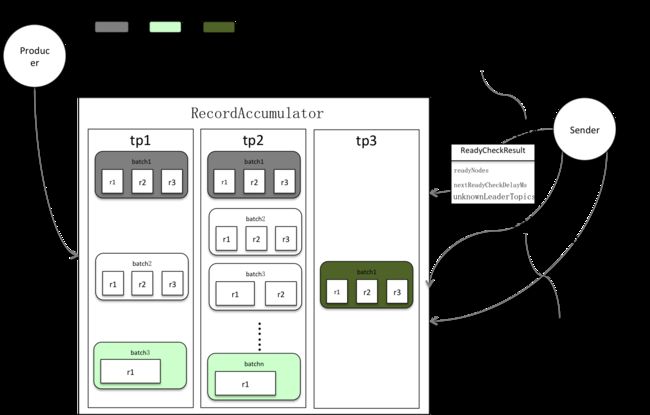
积累器在挤出前会做就绪检查(ready),就绪检查返回上图ReadyCheckResult,它有三个属性ReadyNodes、UnknownLeaderTopics和NextReadyCheckDelayMs。分别代表有待发送批次节点,分区leader未知topic和下次就绪检查时间点。
* 积累器被关闭或预分配总内存占满以及Producer强制刷新
KafkaProducer#flush()三个全局性动作会让任意批次进入待发送;此外批次被关闭或逗留时间超时也会使该它进入待发送。有待发送批次意味该节点处于就绪状态,需提取待发送批次发送。
* 领袖未决可能因为集群拓扑结构发生变化,需要更新元数据,Sender会申请对这些节点做元数据更新。
* 生产频率较低时,积累器很难积累满至少一个批次,如果此时就绪检查又在逗留超时之前,就会发生无就绪节点的情况。比较好的处理方式就是堵塞这段时间,因为在这段时间之前,Sender执行多少次都会一样。Kafka将这段时间交给nio select,获取更多读事件同时又堵塞了线程,这里是特别特别棒的细节处理,因为CPU不断来回切换select线程会非常浪费CPU资源。
就绪检查是整个Sender的先奏,它决定了后面挤出批次的范围甚至客户端轮询网络I/O事件的时间跨度:
1) 就绪节点被选出后,Sender对它们做连接分析,移除坏连接节点。
2) Sender会对剩下的节点做挤出(drain),返回<就绪节点->待发送批次集合>的映射。积累器遍历就绪节点的所有分区队列,每个分区只挤出最老批次,最终每个就绪节点就都提取出一个批次集合。集合长度会有限制,里面的元素即批次总大小必须小于max.request.size。max.request.size是单笔请求的大小上限,在网络传输时每个集合(节点)下的的批次会合并到一个请求,这样有利于显著减少网络开销,因此提取的批次总大小不能超过该值。
3) 最后Sender还会做丢弃(abort),它遍历所有未挤出批次将请求超时的丢弃。请求超时由timeout.ms决定,它从批次处于可发送状态(记录满或逗留时间到)的时间A开始算,如果
追加
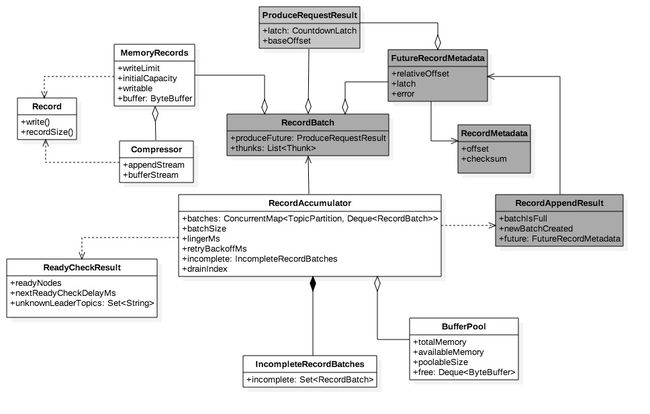
积累器收到消息后找到归属分区的最新批次队追加,如果批次无足够剩余容量则申请新批次。如下图,Producer追加三条消息,第一条较小追加成功;第二条5k大于剩余容量4k,新分配默认大小批次;第三条20k不仅大于剩余空间11k还大于默认大小16k,按消息大小新分配批次。

新批次会记录到incomplete未完成批次中,在生产者关闭时要丢弃所有未完成批次,保证所有消息源能感知到消息状态。生产者有可能同步等待消息发送结果或预定义拦截器触发结果事件。
消息追加成功返回RecordAppendResult,结构在图3.0.2中用灰色底标注,它有三个属性,其中batchIsFull和newBatchCreated用于判断是否有关闭和新建批次,它们可用于判断是否立即需要唤醒被nio select堵塞的线程。因为批次集满或者新建意味着下次提取有极大可能可以挤出数据,所以此时应该快速进入下次ready周期。
另一属性future是FutureRecordMetadata类型,它是批次返回的消息追入返回值,是对RecordMetadata的引用。后者代表消息元数据,记录消息在分区上存储的偏移量等元属性,它只会在Sender成功发送或废弃消息后才会生成,也就是在主线程追加成功后某个未来时间段,因此对追加来说是未来结果。
ProduceRequestResult是批次的全局变量同时也是未来消息元数据全局变量。它由批次初始化并在批次返回未来消息元数据时传递进去。未来消息元数据是每次追加的返回值,因此是消息级的实例;而ProduceRequestResult是批次级别的实例,因为它由批次初始化。
类似Jdk Future,未来消息元数据也可以堵塞get。ProduceRequestResult内置CountdownLatch且count times是1,它被用来堵塞未来消息元数据的get请求。另一方面Sender线程会保证done每个批次,done会释放回写批次在分区存储的开始位移即baseOffset到ProduceRequestResult以及拉开latch。

因为latch的count times是1,所以countdown就会将其拉开,从而所有被堵塞的线程被释放。这里也是Kafka设计上的一处精妙点,批次级的ProduceRequestResult用来堵塞消息级请求,批次的完成就可以用来释放消息级的请求。
主线程请求被释放会获取服务端的返回值,未来消息元数据可以方便读取ProduceRequestResult(见图4.0.2两者关系),用后者来自服务端返回的开始位移加上自身记录的消息在批次中的相对顺序即relativeOffset即可算出消息在服务端的分区存储偏移量,再构造RecordMetadata作为返回值;如果批次不是正常完成,例如服务端处理失败或批次被丢弃,ProduceRequestResult被标记有异常,此时直接抛出执行异常。
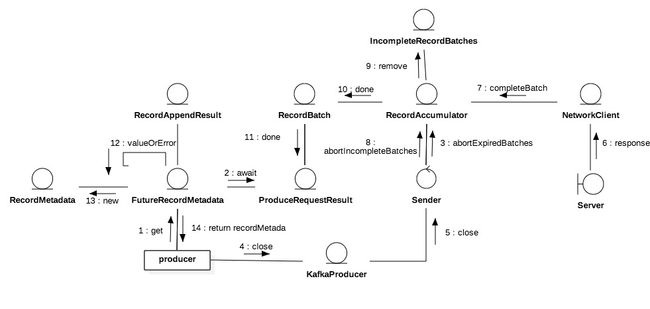
以下三种动作会触发批次done:
1)超时丢弃;2)Producer强制关闭;3)服务端响应。
* Producer强制关闭会把Sender标记为forceClosed,Sender执行完网络轮询后如果需要强制关闭会丢弃incomplete中所有未完成批次。
* 丢弃done会把批次完成状态标记为异常:超时丢弃为超时异常,强制关闭为非法状态异常。
批次
积累器在创建批次之前,就在堆上为它预分配一段空间,这段空间用于装载消息。消息最终会顺序落到内存块中形成消息集。批次的逻辑结构如下:
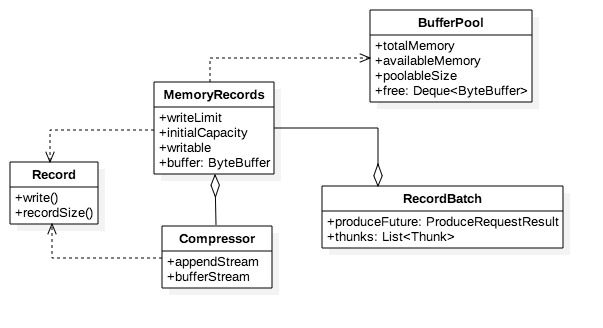
* MemoryRecords即消息集的抽象,它容纳0到多条Record。
* Record则代表消息在内存中的状态,即按二进制协议格式化之后的消息结构,它是消息集的元素。
* 用户可通过compression.type配置压缩方式,开启压缩可显著增大内存使用率、同时减少网络开销。Compressor负责压缩消息,它的属性appendStream是个包装流,其结构是DataOutputStream—>压缩处理流—>ByteBufferStream。
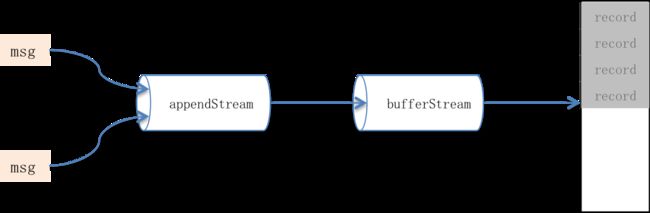
批次失效会关闭消息集使其变为只读状态,并引起Compressor关闭:释放全部I/O资源并在开启压缩时在缓冲头部位置填充协议元数据。关闭后缓冲将不再有消息写入,它被回给消息集并flip后等待发送。
数据协议
批次是消息存储的最小物理单元,读取时就只能按批次整块读取,因此如果没有标准数据协议就无法对数据块做反序列化。
Kafka把消息分割成写前日志、协议头和协议体三部分,协议头和协议体合成协议正文。日志标识消息在批次中的相对顺序和原始正文大小;消息头声明CRC、魔数和属性;最后消息体记录追加时间以及key和value值。
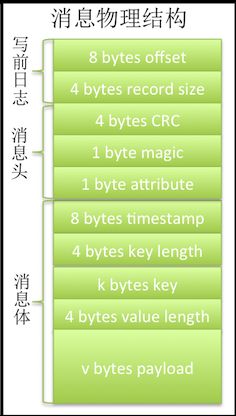
CRC即checkSum值,用于校验消息是否完整;魔数用于声明所用协议版本;属性占1个字节即8位,目前只使用了前三位,每一位代表一种压缩协议,为0即不压缩;key和value几乎一致,前4个字节标识内容长度,如果内容为-1,则表示无内容填入。
当开启压缩时,Compressor会对消息集偏移在起始位置预留出报文头长度的位置,在批次关闭后再将报文头相关数据写入,因为正文长度、payload长度以及消息数量都只能在消息只读后确定。报文头加上消息集才是完整的压缩报文。压缩报文结构和消息几乎一致,也分日志和正文两个部分,但是在个别属性上会有细微差异:1)offset分别被用于标识消息数量;2)没有key值,所有key长度都是-1;3)value长度是消息集(压缩后)的长度,payload就是消息集本身。报文头并不会被压缩,因此可以很容易被读取,程序识别报文的长度、压缩协议、版本号以及CRC等属性之后就可以选用合适的方式读取一定长度的消息以及校验批次的完整性。
批次管理
批次创建后会逗留linger.ms时间,它集聚该段时间内归属该分组(区)的消息。如果生产速率特别高又或者有超大消息流入很快将分区打满,则实际逗留时间会低于linger.ms。想象一下极端场景,批次大小默认16k,如果消息以5k、12k间隔发,则内存实际利用率只有(5+12)/(2*16)。
另一方面,积累器挤出前先要做就绪节点检查,挤出动作也只针对leader在这些节点上的分区批次,但节点ready to drain后,可能因为连接或者inflightRequests超限等问题,被从发送就绪列表移除,从而导致这些节点的可发送批次不会被挤出。它们始终占据分组队列的最高挤出优先级,这会导致:1)后追加的消息被积压,即使连接恢复后新入的消息也只能等待顺序处理,整体投递延时猛增。2)批次占据的内存得不到释放,有可能发生雪崩:因为只有追加没有挤出,问题节点的批次有可能占满全部内存空间导致其他正常节点分区无法为新批次申请空间。Kafka提供请求超时timeout.ms解决这个问题,从逗留截止开始计算批次超时则被废弃–释放内存空间并从分组队列移除。
理想状况下,单位时间内追入和挤出应该恰好相等且内存被充分使用。长期观察下调好linger.ms、batch.size、timeout.ms以及batch.size和buffer.memory这几个参数将有助于达到这个目标。
内存管理
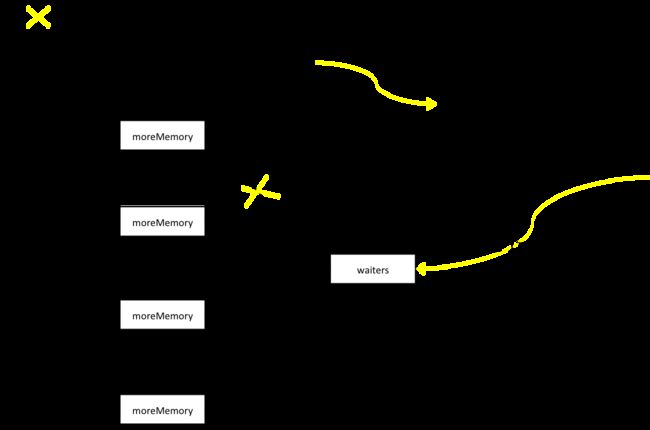
消息集内存直接分配在堆上,如果对它不加以限制在消息生产速率足够高时很可能频繁出现fgc乃至oom,另一方面频繁的内存申请和释放操作也很吃系统资源,因此Kafka自建了内存池BufferPool管理内存。
内存池有四个关键属性:totalMemory代表内存池上限,由buffer.memory决定;poolableSize指池化内存块大小,由batch.size设置;free和availableMemory则分别代表池化内存和闲置内存大小。注意free和available的区别,前者是已申请但未使用,后者是未申请未使用,它们之间关系:totalMemory= 可使用空间+已使用空间,可使用空间=availableMemory+free.size()*poolableSize代表。
只有固定大小的内存块被释放后才会进入池化列表,非常规释放后只会增加可用内存大小,而释放内存则由虚拟机回收。因此如果超大消息比较多,依然有可能会引起fgc乃至oom。
积累器通过内存池预分配消息集内存,如果没有足够内存则用户主线程被放入有序队列并进入等待。批在批次done时释放出部分空间,同时唤醒队首线程,如果没有释放出足够的空间则继续进入等待,如果已经释放出足够空间,分配空间且线程出队。