MYSQL连接合集总结-上
再做了一次这部分的leetcode的题目,如下9题,这里先分析前三题。

1.使用唯一标识码替换员工ID
两个表,employees表(id和名字一一对应),employeeUNI表(id和唯一标识一一对应);
题目是把id替换成唯一标识,其实看着很简单,但是因为有可能有没有唯一标识的,所以得用左连接
ok 再次做题成功,左连接和内连接是一样的。
2.产品销售分析
明天再做,有点不想干了,想换脑子了,今天的我来了。
有sales销售这件事的表和product产品这件事的表。
(sales表的话,没想到年份和sales_id为什么是唯一值,年份相同的时候,需要有个额外字段区分因为产品可能相同,但是年份不同的话本身就有区分了。为什么sale_id这一个字段不是主键呢)
这一题不难,想要让你回答的东西很简单。
3.进店却未进行交易的顾客
难读的题,这个题我是做完其他的这个系列的题,留着最后做的。
1.理解表
有两张表-----光临过购物中心的表:光临时间和用户id。交易表:交易id,光临时间,交易额(这里没什么用)
我现在理解为什么这一题难理解,是因为这个光临时间,visit_id 不是那种平常的日期,所以如果没有示例帮助理解的话,很难理解这一题。(我后面理解题的时候再看这两张表,我觉得其实有点搞笑,为什么一个时期只能有一个用户光顾,但是交易可以一个人进行多次,那我觉得一个时期应该也有多个用户啊)
2.理解题
题目是找出光顾但没有交易的顾客id,以及他们只光顾不交易的次数。
于是尝试理解一下,次数也就是记录数,需要用count(),而且基本需要看情况进行分组,因为有时候分组在子查询里这种。那现在重点就是筛选一下找出光顾但没有交易的顾客。而且交易的前提一定是光顾,所以光顾表和交易表左连接,没交易的交易表为null。理解完是下面的语句,然后发现错了(其实中间还是有很多的曲折过程,还是不放上来了,意义不大)
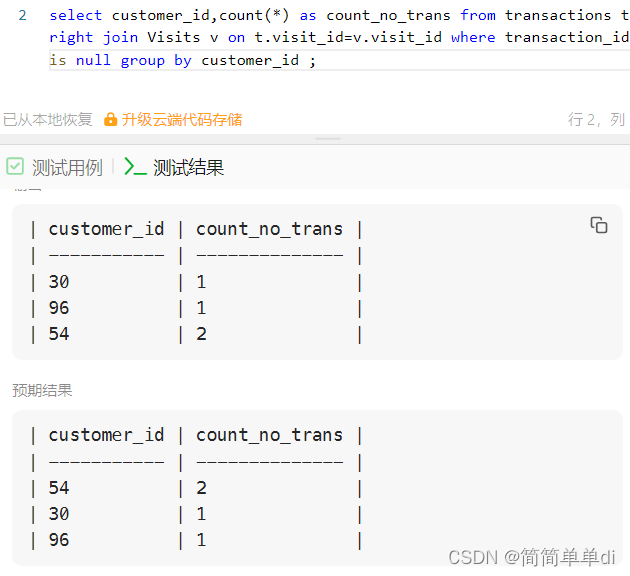
select customer_id,count(*) as count_no_trans From visits v left join transactions t on v.visit_id=t.visit_id group by customer_id having transaction_id is null;
然后我有transaction_id is null放在三个地方()的想法,分别是连接语句on后面的并列and后面,having后面,where后面;最终显示放在where是对的。同时也给我上了一课,理解where和having的区别至关重要,我之前以为我理解了,现在发现并没有,而现在我觉得我理解啦。而且on后面and的并列条件也帮助我更加深刻的理解左连接。
1)transaction_id is null放在连接语句on后面的并列and后面。
得到如下的结果。

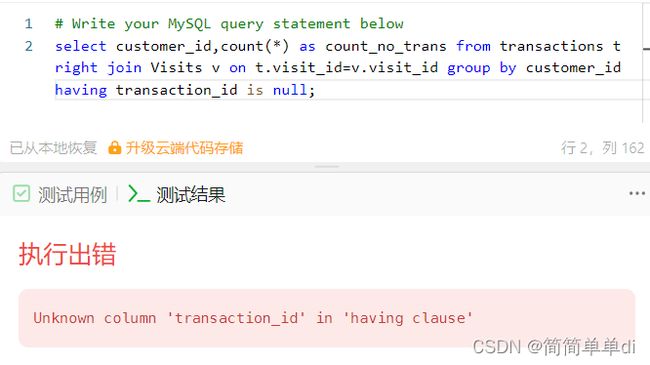
2)transaction_id is null放在having后面
得到如下结果。
3)transaction_id is null放在and后面的呢
这三个有不同的结果的时候,我就觉得我要仔细思考他们的不同了。
1)and为什么会出错。
首先明确这是左连接,所以最后的结果即使不满足and后面的条件,左边所有的visit_id都会显示出来,而且对于这个题来说的话,连接完transaction_id is null的记录更多了。所以在and后面加并不合适啊,达不到筛选transaction_id is null的记录的效果。
2)having为什么出错。
这一点,其实我之前是万万不能理解啊,分组后把transaction_id is null的记录筛选出来不是很正常吗,之前百度的说where和having的区别就是分组前和分组后的区别啊,但是我找啊找,找到了如下的解释:
HAVING子句是GROUP BY子句的一个扩充,用于对分组添加条件。相比之下,WHERE子句用于给查询的SELECT子句添加条件。
我丢,之前没有人和我说过这个区别啊,而我再去百度having怎么使用,又有类似的说法了,真的想骂自己,之前是瞎了吗?没事瞎那么一会儿很正常,嘿嘿。having是用于对分组添加条件,是通过group by那里的字段分组,并且满足having后面的条件的行才行,我笑了这样理解好像没有错啊,好吧我还是根据报错(Unknown column 'transaction_id' in 'having clause')百度靠谱,帮助自己理解,之前一直不愿意这样百度,不知道为啥,可能是惯性,也可能是求快。,下面是很好的解释:
having 后跟的筛选条件所包含的字段必须是select后展示的字段或者group by 的条件字段!!!
3)where为什么正确,就是正确,因为我刚开始看三个都正确。
4.总结上半部分
总结挺费脑子的,我明天总结剩下部分吧,今天再写写新题吧。加上今天早上出去走了一个小时,真的很冷,回来写了会儿就想睡,然后下午又想睡,对于怕冷的我来说,冬天有点难熬啊。