MySQL学习笔记——基础篇03:单行函数及聚合函数
该文章为个人笔记,只记录重点,可能内容不全,需要所有的函数语句请查询专业文章。
文中理解为本人理解,如有错误欢迎大佬指出。
一、单行函数
单行函数的定义:
-
操作数据对象
-
接受参数返回一个结果
-
只对一行进行变换
-
每行返回一个结果
-
可以嵌套
-
参数可以是一列或一个值
常用的单行数值函数
1.基本函数
LEAST(e1,e2,e3…) 返回列表中最小值

GREATEST(e1,e2,e3…) 返回列表中最大值
RAND() 返回0~1的随机值

RAND(x) 以作种产生随机值,相同的x会产生相同的随机值。
ROUND(x) 返回一个对x的值进行四舍五入后,最接近于X的整数
ROUND(x,y) 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位
TRUNCATE(x,y) 返回数字x截断为y位小数的结果

2.不常用函数(省略)
以下函数为不常用函数,在此省略,需要查询可查专业文章。
角度与弧度函数
三角函数
指数与对数函数
进制的转换函数
3.字符串函数
由于字符串函数数量众多,我只记录常用函数。
注意!MySQL中,字符串位置从1开始。
LENGTH(s) 返回字符串s的字节数,和字符集有关
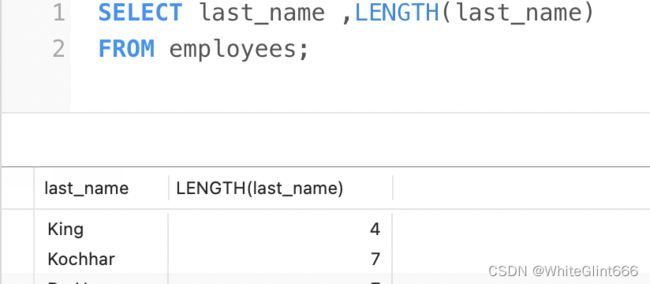
CONCAT(s1,s2,......,sn) 连接s1,s2,......,sn为一个字符串

INSERT(str, idx, len, replacestr) 将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr
REPLACE(str,a,b) 用字符串b替换字符串str中所有出现的字符串a
UPPER(s) / LOWER(s) 转为大写/小写字母
LEFT(str,n) / RIGHT(str,n) 返回字符串str最左/右边的n个字符
LPAD(str, len, pad)/RPAD(str ,len, pad) 用字符串pad对str最左/右边进行填充,直到str的长度为len个字符
NULLIF(value1,value2) 比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1
字符操作函数还有很多,如需全面函数请移步专业文章。
4.日期和时间函数
1.获取时间,日期
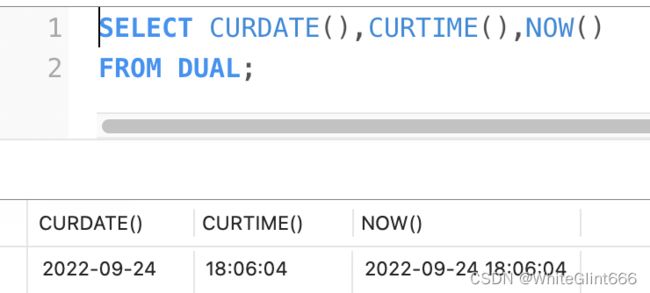
CURDATE() 返回当前日期,只包含年、月、日
CURTIME() 返回当前时间,只包含时、分、秒
NOW() / SYSDATE() 返回当前系统日期和时间
2.获取月份,星期,星期数,天数等函数。
YEAR(date) / MONTH(date) / DAY(date) 返回具体的日期值
HOUR(time) / MINUTE(time) / SECOND(time) 返回具体的时间值
DAYOFYEAR(date) 返回日期是一年中的第几天
3.时间和秒钟转换的函数
TIME_TO_SEC(time)将 time 转化为秒并返回结果值。转化的公式为:小时*3600+分钟*60+秒
SEC_TO_TIME(seconds) 将 seconds 描述转化为包含小时、分钟和秒的时间
4.计算日期和时间的函数
DATE_ADD(datetime, INTERVAL expr type),ADDDATE(date,INTERVAL expr type) 返回与给定日期时间相差INTERVAL时间段的日期时间
注:1.INTERVAL 为间隔的意思,是语法规则,不可漏写。
2.当日期为负数时可做减法。
举例: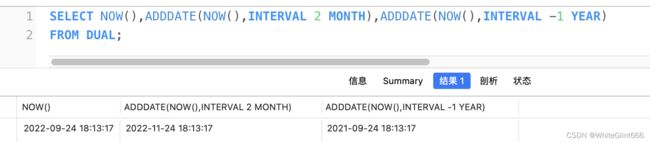
DATEDIFF(date1,date2) 返回date1 - date2的日期间隔天数(常用函数)
TIMEDIFF(time1, time2) 返回time1 - time2的时间间隔
5.流程控制函数
IF(value,value1,value2) 如果value的值为TRUE,返回value1,否则返回value2
IFNULL(value1, value2) 如果value1不为NULL,返回value1,否则返回value2
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END
相当于c++的 if...else if..else
CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 .... [ELSE 值n] END
相当于c++的swithch....case...
二、聚合函数
1.聚合函数的介绍
聚合函数作用于一组数据,并对一组数据返回一个值。
聚合函数类型
-
AVG() 求平均值 只能对数值型数据使用
-
SUM() 求总和 只能对数值型数据使用
-
MAX() 求最大值 可以对任意数据类型的数据使用
-
MIN() 求最小值 可以对任意数据类型的数据使用
-
COUNT() 返回表中记录总数,适用于任意数据类型。
注意:聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
2.聚合函数的使用
可以对数值型数据使用AVG 和 SUM 函数。

可以对任意数据类型的数据使用 MIN 和 MAX 函数。

COUNT(*)返回表中记录总数,适用于任意数据类型。

问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代 count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2.GROUP BY

GROUP BY在什么情况下使用?
当你使用了聚合函数时,同时你想将数据进行分组处理,这时就需要使用 GROUP BY。
注意!在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中
举例:
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
当有多个列时:
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;即,除了使用聚合函数的字段外,其余字段均要写入 GROUP BY中
在GROUP BY 中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
3 HAVING的使用
首先说结论,HAVING是对分组的过滤条件,如果分组有条件必须使用HAVING。HAVING和WHERE可以起到相同的作用,但HAVING运行时间更长,故能使用WHERE就使用WHERE。
过滤分组:HAVING子句
-
行已经被分组。
-
使用了聚合函数。
-
满足HAVING 子句中条件的分组将被显示。
-
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用
代码举例
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;WHERE和HAVING的对比

WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
原理:WHERE先筛选后连接,HAVING先连接后筛选,连接后数据量庞大,故HAVING时间更长。