Python数据分析实战【十四】:python的三种排序方法:sort、sorted、sort_values案例学习【文末源码地址】
文章目录
- 一、List.sort()排序
-
- 案例一:按照列表中的元素进行排序
- 案例二:按照销售额数据进行排列
- 二、sorted()排序
-
- 案例一:sorted()对列表进行排序
- 案例二:sorted()对字典进行排序
- 案例三:sorted()对列表中的字典元素排序
- 三、pandas排序
-
- 案例一:pandas按照销售额进行排序
- 案例二:官方案例S操作
- 源码地址
在数据分析的工作中,我经常会遇到对数据排序的场景,比如:
- 按照销售总额对门店进行排序
- 按照日期对销售额镜像排序
如果你也遇到类似的问题,不妨接着往下看,我总结了四种排序方法,建议收藏一下,以后方便查阅。
一、List.sort()排序
sort()方法是python列表内置的方法,这个方法有个弊端:会在原来的列表上进行修改。
在数据分析的过程中,修改原数据是大忌,所以这种方法我不常用。
参数介绍:
- list.sort(key=None,reverse=False)
key:是排序的关键词
reverse:降序,默认为false,即升序排序
案例一:按照列表中的元素进行排序
amount = [10,30,20,40,50]
# 升序排序
# amount.sort()
# 降序排序
amount.sort(reverse=True)
运行结果:
[50, 40, 30, 20, 10]
案例二:按照销售额数据进行排列
这种数据很常见,因为这与读完数据库出来的数据结构很像都是:列表中包含元组,每个元组就是一条数据
# 按照元组中的第二个元素进行升序排列
amount = [("销售额",10),("销售额",30),("销售额",20),("销售额",40),("销售额",50)]
amount.sort(key=lambda x:x[1])
运行结果:
[('销售额', 10), ('销售额', 20), ('销售额', 30), ('销售额', 40), ('销售额', 50)]
按照元组中的第二个元素进行降序序排列
# 按照元组中的第二个元素进行降序序排列
amount = [("销售额",10),("销售额",30),("销售额",20),("销售额",40),("销售额",50)]
amount.sort(key=lambda x:x[1],reverse=True)
运行结果:
[('销售额', 50), ('销售额', 40), ('销售额', 30), ('销售额', 20), ('销售额', 10)]
二、sorted()排序
sorted()方法在实际工作中使用最多,它与sort()只能用在列表上不同,sorted()方法可以用在列表,元组,字典以及所有可迭代对象上。而且,sorted()不会在原来的对象上操作,会生成一个新的对象,这就很nice。
参数介绍:
- sorted(iterable,key=None,reverse=False)
iterable:可迭代的对象,list、dict、tuple
key:排序的关键元素
reverse:排序规则,reverse=True 降序,reverse=False 升序
案例一:sorted()对列表进行排序
amount = [10,30,20,40,50]
# 升序排序
# amount_new = sorted(amount)
# 降序排序
amount_new = sorted(amount,reverse=True)
运行结果:
[50, 40, 30, 20, 10]
案例二:sorted()对字典进行排序
amount = {"A部":10,"C部":30,"B部":20,"E部":40,"D部":50}
# 按照字典的值进行升序排列
# amount_new = dict(sorted(amount.items(),key=lambda x:x[1]))
# 按照字典的值进行降序排序
amount_new = dict(sorted(amount.items(),key=lambda x:x[1],reverse=True))
运行结果:
{'D部': 50, 'E部': 40, 'C部': 30, 'B部': 20, 'A部': 10}
案例三:sorted()对列表中的字典元素排序
amount = [
{"部门":"A部","销售额":10},
{"部门":"C部","销售额":30},
{"部门":"B部","销售额":20},
{"部门":"E部","销售额":40},
{"部门":"D部","销售额":50},
]
# 按照销售额进行升序排列
# amount_new = sorted(amount,key=lambda x:x["销售额"])
# 按照销售额进行降序排列
amount_new = sorted(amount,key=lambda x:x["销售额"],reverse=True)
运行结果:
[{'部门': 'D部', '销售额': 50},
{'部门': 'E部', '销售额': 40},
{'部门': 'C部', '销售额': 30},
{'部门': 'B部', '销售额': 20},
{'部门': 'A部', '销售额': 10}]
三、pandas排序
在数据分析的工作中,pandas是我用的最多的工具,在【数据读取】-【数据分析】-【数据存储】整个过程中都有使用,而且pandas进行排序更加方便快速。
参数介绍:
- sort_values(by,ascending=True)
by:排序的字段名
ascending:ascending=True 升序,ascending=False 降序
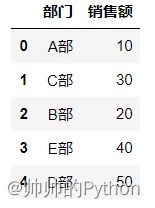
案例一:pandas按照销售额进行排序
import numpy as np
import pandas as pd
df = pd.DataFrame(data={
"部门":["A部","C部","B部","E部","D部"],
"销售额":[10,30,20,40,50]
})
数据展示:
# 按照销售额升序排列
# df2 = df.sort_values(by=["销售额"])
# 按照销售额降序排列
df2 = df.sort_values(by=["销售额"],ascending=False)
运行结果:

案例二:官方案例S操作
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2': [2, 1, 9, 8, 7, 4],
'col3': [0, 1, 9, 4, 2, 3],
'col4': ['a', 'B', 'c', 'D', 'e', 'F']
})
- nan值【空值】,排序的时候放在第一位
# nan值【空值】,排序的时候放在第一位
df2 = df.sort_values(by='col1', ascending=False, na_position='first')
运行结果:

- 按照某一列字母小写排序
# 按照某一列字母小写排序
df2 = df.sort_values(by='col4',key=lambda x:x.str.lower())

源码地址
链接:https://pan.baidu.com/s/1ovfLWgJ7_FxXsOqjH0uXhA?pwd=ck1h
提取码:ck1h