Mybatis一级缓存和二级缓存原理剖析与源码详解
Mybatis一级缓存和二级缓存原理剖析与源码详解
在本篇文章中,将结合示例与源码,对MyBatis中的一级缓存和二级缓存进行说明。
MyBatis版本:3.5.2
文章目录
- Mybatis一级缓存和二级缓存原理剖析与源码详解
-
- ⼀级缓存
-
- 场景一
- 场景二
- ⼀级缓存原理探究与源码分析
- createCacheKey方法源码解析
- BaseExecutor.query()方法源码解析
- 二级缓存
-
- 场景一
- 场景二
- 场景三
- 场景四
- 场景五
- 二级缓存源码分析
⼀级缓存
场景一
在⼀个sqlSession中,对User表根据id进⾏两次查询,查看他们发出sql语句的情况
public class MybatisCacheDemo {
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = factory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User u1 = userMapper.selectUserById(1);
System.out.println(u1);
//第⼆次查询,由于是同⼀个sqlSession,会在缓存中查询结果
//如果有,则直接从缓存中取出来,不和数据库进⾏交互
User u2 = userMapper.selectUserById(1);
System.out.println(u2);
}
}
执行得到的查询结果如下:

场景二
同样是对user表进⾏两次查询,只不过两次查询之间进⾏了⼀次update操作。
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = factory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User u1 = userMapper.selectUserById(1);
System.out.println(u1);
//第⼆步进⾏了⼀次更新操作,sqlSession.commit()
u1.setUsername("windy");
userMapper.update(u1);
sqlSession.commit();
//第⼆次查询,由于是同⼀个sqlSession.commit(),会清空缓存信息
//则此次查询也会发出sql语句
User u2 = userMapper.selectUserById(1);
System.out.println(u2);
}
查看控制台打印情况:
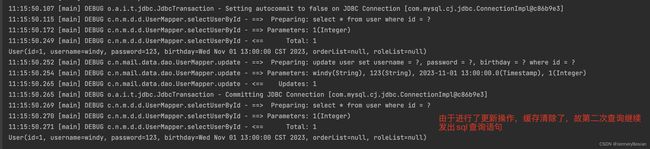
总结
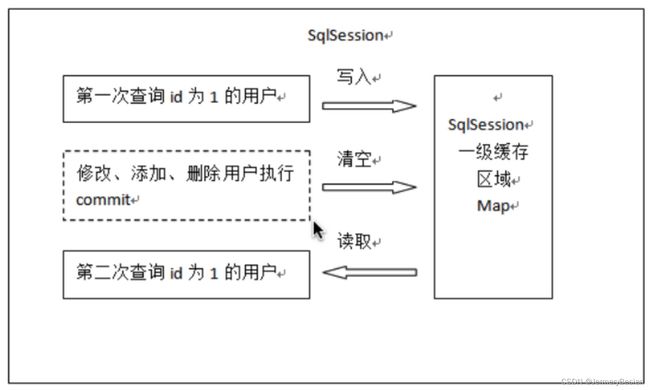
1、第⼀次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,如果没有,从数据库查询⽤户信息。得到⽤户信息,将⽤户信息存储到⼀级缓存中。
2、 如果中间sqlSession去执⾏commit操作(执⾏插⼊、更新、删除),则会清空SqlSession中的 ⼀级缓存,这样做的⽬的是为了让缓存中存储的是最新的信息,避免脏读。
3、 第⼆次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,缓存中有,直接从缓存中获取⽤户信息
⼀级缓存原理探究与源码分析
⼀级缓存到底是什么?⼀级缓存什么时候被创建、⼀级缓存的⼯作流程是怎样的?相信你现在应该会有 这⼏个疑
问,那么我们本节就来研究⼀下⼀级缓存的本质。
我们知道,MyBatis中的SqlSession可以用于执行SQL语句,封装了对数据库的操作,包括增删改查、事务控制等,是MyBatis中最重要的核心对象之一。为此,我们进入该类中,看看能不能找到查询相关的执行逻辑,进而探究查询过程中使用缓存的代码逻辑。
public interface SqlSession extends Closeable {
void select(String var1, Object var2, ResultHandler var3);
}
⬇️
public class DefaultSqlSession implements SqlSession {
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = this.configuration.getMappedStatement(statement);
this.executor.query(ms, this.wrapCollection(parameter), rowBounds, handler);
} catch (Exception var9) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var9, var9);
} finally {
ErrorContext.instance().reset();
}
}
}
⬇️
public interface Executor {
<E> List<E> query(MappedStatement var1, Object var2, RowBounds var3, ResultHandler var4) throws SQLException;
}
⬇️
public abstract class BaseExecutor implements Executor {
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
return this.query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
}
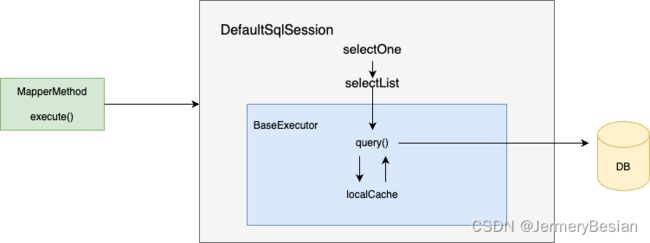
就这样,经过层层递进,我们终于第一次看到了一个跟缓存相关的类:CacheKey,这里我们暂且不管这个类的实现和作用。将上面的查询调用链总结如下所示:

有了上面的调用链之后,我们就对整个执行mybatis查询的调用方法链有了一个初步的认知。接下来,就从上面BaseExecutor的query()方法中来一探究竟。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
createCacheKey方法源码解析
在上述query()方法中,先会在MappedStatement中获取绑定关联的SQL语句,然后生成CacheKey。这个CacheKey实际上就是一个缓存主键,用于唯一标识一个查询结果。
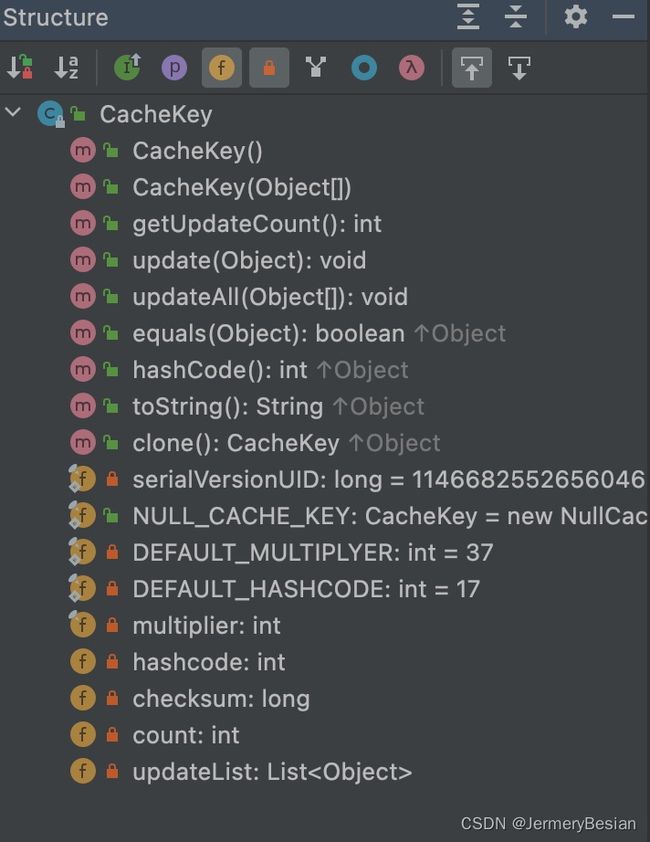
CacheKey中包含multiplier,hashcode,checksum,count和updateList等属性用于判断CacheKey之间是否相等,具体判断逻辑可以查看equals方法如下所示:
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
可以看到,equals方法中,对上述hashcode、checksum、count和updateList属性进行判断,用于判断两个CacheKey是否属于同一个CacheKey。同时hashcode,checksum,count和updateList字段会在CacheKey的update() 方法中被更新,如下所示:
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
主要逻辑就是在update()方法中,更新CacheKey的相关属性值,这些传入的参数object都与唯一确定CacheKey有关。
在了解了CacheKey类的相关原理后,我们回到上面BaseExecutor的query()方法中,看一下createCacheKey方法实现了什么功能:
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 创建CacheKey对象
CacheKey cacheKey = new CacheKey();
// 基于MappedStatement的id更新CacheKey
cacheKey.update(ms.getId());
// 基于RowBounds的offset更新CacheKey
// RowBounds 是用于分页查询的参数对象。offset 表示查询的起始位置或偏移量,它指定了从结果集的哪一行开始返回数据。
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
// 基于Sql语句更新CacheKey
cacheKey.update(boundSql.getSql());
// 获取绑定sql的参数元数据Mapping
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
// MetaObject提供了一些便捷的方法,封装了一些根据parameterObject类型,获取相应propertyName值的方法,而不需要直接使用反射操作。
// MetaObject会根据传入的parameterObject类型,封装成不同的Wrapper
// 例如: MapWrapper、CollectionWrapper、BeanWrapper
MetaObject metaObject = configuration.newMetaObject(parameterObject);
// 如果是MapWrapper,则getValue会调用Map的get方法
// 如果是BeanWrapper,则getValue会调用Bean对象的get属性方法
value = metaObject.getValue(propertyName);
}
// 基于查询参数值更新CacheKey
cacheKey.update(value);
}
}
// 基于Environment的id更新CacheKey
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
上面的代码非常清晰明确的展示了如何去确定唯一的CacheKey,依据就是MappedStatement id + RowBounds offset + RowBounds limit + SQL + Parameter值 + Environment id相等。
上面代码中,boundSql.getParameterMappings();就是获取从查询sql占位符中解析出的参数元数据信息。然后进行遍历,获取每个参数名,并从查询接口传入的参数中获取相应的参数值。Mybatis在执行Mapper接口方法时,会利用反射对调用方法时传入的参数进行解析,封装成parameterObject。(具体可以参考MapperMethod类的execute方法源码)。
比如下面的查询接口:
User selectUserById(@Param("id") int id);
User selectUserByEntity(User user);
对于第一个查询接口,parameterObject会被解析成一个Map类型,内容为: {"id":id值, "param1":id值}。
而对于第二个查询接口,parameterObject仍然被保留为原始的User类。
因此,configuration.newMetaObject(parameterObject)方法就是根据传入的parameterObject参数,封装成MetaObject类对象,然后借助MetaObject中封装的objectWrapper属性,利用不同Wrapper的get方法获取propertyName相应的值。
至此,我们详细分析了createCacheKey方法内的实现原理。
BaseExecutor.query()方法源码解析
在上面获取到CacheKey后,会调用BaseExecutor中重载的query() 方法。源码如下所示:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// queryStack是BaseExecutor的成员变量
// queryStack主要用于递归调用query()方法时防止一级缓存被清空
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 先从一级缓存localCache中根据CacheKey判断是否命中缓存,如果命中,则直接返回查询结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 处理存储过程相关逻辑
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 未命中,则直接查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 如果一级缓存作用范围是STATEMENT时,每次query执行完毕后都需要清空一级缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
这里就是mybatis执行查询时的核心query逻辑了。上面query()方法的执行逻辑还是比较好理解的,如上述代码注释所示。
localCache是一个PerpetualCache类型的对象,而PerpetualCache内部主要是基于一个Map(实际为HashMap)用于数据存储。
而查询数据库的queryFromDatabase源码如下所示:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 插入CacheKey的占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 根据入参执行查询sql语句
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将查询结果放入localCache一级缓存
localCache.putObject(key, list);
// 如果ms的类型为CALLABLE(存储过程或可调用语句),则将参数对象(parameter)与缓存键(key)关联起来,存储在localOutputParameterCache缓存中。
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
上面的doQuery方法,实际上就是根据传入的参数,创建Statement对象,然后将参数值set到sql的相应占位符上去,最后执行ps.execute()执行查询结果并返回。
最后,我们再来看一下,为什么在最初的场景二中,执行了update方法后,就没有命中缓存而是重新查了一次数据库。
MyBatis中如果是执行增,改和删操作,并且在禁用二级缓存的情况下,均会调用到BaseExecutor的update() 方法,如下所示:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
显而易见,上面的update代码中,执行了clearLocalCache()来清楚一级缓存。所以Mybatis中的一级缓存在执行了增、改和删操作后,会被清空立即失效。目的就在于,执行了更新操作后,如果不清除缓存,可能会导致脏读。
总结
至此,我们就基本分析完了Mybatis一级缓存的执行逻辑。总结一下,实际上就是当用户调用查询接口方法时,Mybatis会根据查询的MappedStatement id + RowBounds offset + RowBounds limit + SQL + Parameter值 + Environment id唯一创建一个CacheKey,来标识一个查询请求。接着,在执行查询SQL时,会首先根据该CacheKey从localCache缓存中判断是否命中,如果命中,则直接返回查询结果。否则,创建、初始化Statement对象,用入参替换占位符,执行查询SQL,并将查询结果放入localCache缓存中,以便下次查询时直接返回。
一级缓存的使用流程可以用下图进行概括:
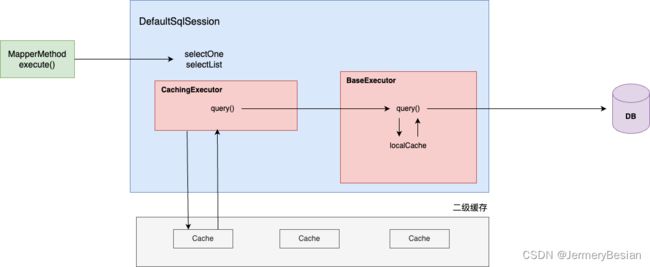
二级缓存
⼆级缓存的原理和⼀级缓存原理⼀样,第⼀次查询,会将数据放⼊缓存中,然后第⼆次查询则会直接去 缓存中取。但是⼀级缓存是基于sqlSession的,⽽⼆级缓存是基于mapper⽂件的namespace的,也就是说多个sqlSession可以共享⼀个mapper中的⼆级缓存区域,并且如果两个mapper的namespace 相同,即使是两个mapper,那么这两个mapper中执⾏sql查询到的数据也将存在相同的⼆级缓存区域中
和⼀级缓存默认开启不⼀样,⼆级缓存需要我们⼿动开启
首先在全局配置文件sqlMapConfig.xml文件中加入如下代码:
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="localCacheScope" value="STATEMENT"/>
</settings>
上述配置文件中将一级缓存的作用范围设置为了STATEMENT,目的是为了在例子中屏蔽一级缓存对查询结果的干扰。
其次在UserMapper.xml⽂件中开启缓存:
<cache eviction="LRU"
type="org.apache.ibatis.cache.impl.PerpetualCache"
flushInterval="600000"
size="1024"
readOnly="true"
blocking="false"
>
cache>
下面我们接着来看几个实用二级缓存的场景。
场景一
创建两个会话,会话1以相同SQL语句连续执行两次查询,会话2以相同SQL语句执行一次查询。代码如下所示:
public class MybatisCacheDemo2 {
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
System.out.println(userMapper1.selectUserById(1));
System.out.println(userMapper1.selectUserById(1));
System.out.println(userMapper2.selectUserById(1));
}
}
执行结果如下所示:
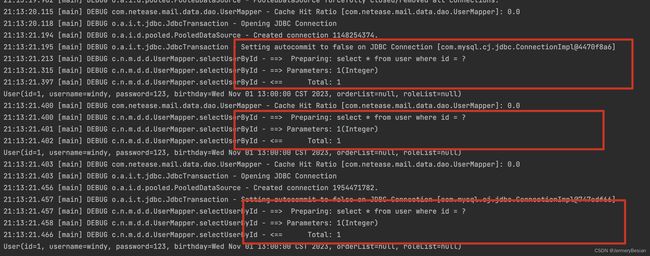
可以看到,Mybatis在开启二级缓存后,每次查询会先去二级缓存中查看是否命中查询结果(上图中打印出的Cache Hit Ratio…)。未命中时才会使用一级缓存以及直接去查询数据库。上面的截图显示,无论是同一会话的两次查询还是另一会话的一次查询,均是查询的数据库,这点跟我们上面的一级缓存场景有不同(在一级缓存中,同一会话的相同sql第二次查询结果是直接从缓存中获取到的)。
这是为什么呢?
实际上,在二级缓存中,将查询结果写入到二级缓存中时需要执行事务提交操作,上面的场景中并没有事务提交,因此二级缓存中是没有内容的,最终导致三次查询均是直接访问数据库。这里暂时先给出结论,直接源码性分析,我们留在下面统一来进行分析。
场景二
创建两个会话,会话1执行完查询操作后提交事物,接着会话1再执行相同的查询,然后会话2以相同sql语句执行一次查询。代码如下所示:
public class MybatisCacheDemo2 {
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
System.out.println(userMapper1.selectUserById(1));
sqlSession1.commit();
System.out.println(userMapper1.selectUserById(1));
System.out.println(userMapper2.selectUserById(1));
}
}
执行结果如下所示:
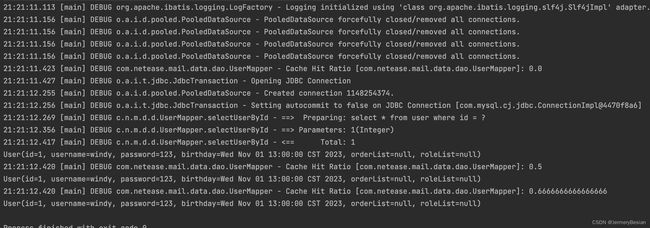
可以看到,在会话1提交了事务之后,后两次的查询都是命中了二级缓存(三次查询命中二次,所以Cache Hit Ratio=0.666),验证了我们上面的结论。
场景三
创建两个会话,会话1执行一次查询并提交事务,然后会话2执行一次更新并提交事务,接着会话1再执行一次相同的查询。代码如下所示:
public class MybatisCacheDemo2 {
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 场景三
// 将事务隔离级别设置为读已提交
SqlSession sqlSession1 = sqlSessionFactory.openSession(TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(TransactionIsolationLevel.READ_COMMITTED);
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
System.out.println(userMapper1.selectUserById(1));
sqlSession1.commit();
User user = new User();
user.setId(1);
user.setUsername("lisi");
userMapper2.update(user);
sqlSession2.commit();
System.out.println(userMapper1.selectUserById(1));
}
}
执行结果如下所示:
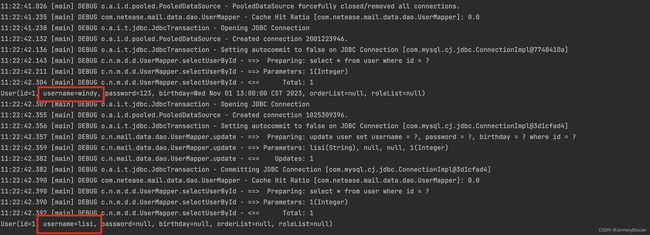
执行结果表明,执行更新操作并提交事务后,会清空二级缓存,执行新增和删除操作也是同理。
场景四
创建两个会话,每个会话操作不同的数据表。会话1首先执行一次表1和表2的级联查询,然后提交事务。会话2针对表2执行一次更新操作以更新某个字段值并提交事务。最后,会话1再执行一次表1和表2的级联查询。代码如下所示:
public class MybatisCacheDemo2 {
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 场景四
// 将事务隔离级别设置为读已提交
SqlSession sqlSession1 = sqlSessionFactory.openSession(TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(TransactionIsolationLevel.READ_COMMITTED);
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
OrderMapper orderMapper = sqlSession2.getMapper(OrderMapper.class);
System.out.println(userMapper1.selectUserOrder(2));
sqlSession1.commit();
System.out.println();
// 更新order表的total字段从20.0 -> 30.0
orderMapper.update(3, 30.0);
sqlSession2.commit();
System.out.println(userMapper1.selectUserOrder(2));
}
}
执行结果如下所示:
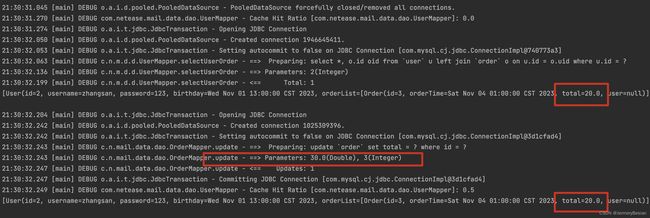
可以看到,在会话1第一次多表查询时,得到的用户id=2的order表total字段=20.0,并提交了事务。然后会话2执行更新操作将order表uid=2的total字段值更新为30.0并提交事务。接着,会话1再次执行了多表查询,得到的关联结果中,用户id=2的order表total字段值仍然为20.0,出现了脏读。
上述问题的原因就在于之前提到过的,二级缓存的作用范围是同一命名空间,这里的命令空间就是映射文件的na mespace,可以理解为每一个映射文件持有一份二级缓存。所有会话对该映射文件的所有操作,都会共享这个二级缓存。所以上面的场景中,会话2对Order表执行的更新操作并提交事务时,清空的是OrderMapper.xml这个映射文件持有的二级缓存。UserMapper.xml的二级缓存无法感知到Order表的数据发生了变化,仍然保留着原先的缓存数据。最终导致会话1第二次执行相同的多表查询时从二级缓存中命中了脏数据,发生了脏读。
场景五
在场景四的基础上,在OrderMapper.xml文件中添加下面的标签:
<cache-ref namespace="com.example.mybatis.data.dao.UserMapper"/>
再次执行上面场景四中的测试代码,得到结果如下所示:

这一次,会话1在第二次执行多表查询语句时,获取了Order表中更新的total字段值。
原理在于,在OrderMapper.xml文件中使用
至此,介绍完上面二级缓存的几个测试场景后,我们对Mybatis的二级缓存机制进行一个总结:
- Mybatis中的二级缓存默认不开启,可以在Mybatis配置文件的
- Mybatis的二级缓存作用范围是基于mapper的命名空间,这里的命令空间就是映射文件的namespace。也就是说多个sqlSession可以共享⼀个mapper中的⼆级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执⾏sql查询到的数据也将存在相同的⼆级缓存区域中。
- Mybatis中执行查询操作后,需要提交事务才能将查询结果缓存到二级缓存中。
- Mybatis中执行增、删、改操作并提交事务后,会清空相应的二级缓存
- Mybatis中需要在映射文件中添加
最后对
- eviction:缓存淘汰策略。LRU表示最近最少使用的优先被淘汰;FIFO表示先被缓存的会先被淘汰;SOFT表示基于软引用规则来淘汰; WEAK表示基于弱引用规则来淘汰。
- flushInterval: 缓存刷新间隔,单位毫秒
- type:缓存类型
- size:最多缓存的对象格式
- blocking: 缓存未命中时是否阻塞
- readOnly:缓存中的对象是否只读。配置为true时,表示缓存对象只读,命中缓存时会直接将缓存对象返回,性能更快,但是线程不安全;配置为false时,表示缓存对象可读写,命中缓存时会讲缓存的对象克隆然后返回克隆的对象,性能更慢,但是线程安全。
- namespace: 其他映射文件的命名空间,设置之后则当前映射文件将和其他映射文件将持有同一份二级缓存。
二级缓存源码分析
介绍了上面那么多原理和结论,接下来我们去代码中一探究竟,来找到上面原理的支撑依据,在源码中加深我们的印象和理解。
首先,Mybatis中开启二级缓存之后,执行查询操作时,调用链如下所示:

与一级缓存中不同的是换了一个Executor执行类。
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
query()方法的执行逻辑与我们上面在分析一级缓存中的一致。在此不再赘述,直接来看重载的query()方法如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 取出MappedStatement中对应的二级缓存
Cache cache = ms.getCache();
if (cache != null) {
// 清空二级缓存(如果需要的话)
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从二级缓存中根据CacheKey命中查询结果
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 未命中,则查询数据库
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果缓存到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
上面的源码中可以看到,二级缓存在根据CacheKey命中查询结果时,并没有一个类似localCache的缓存,而是通过调用tcm.getObject(cache, key)来获取,这是与之前分析一级缓存时的不同。那么就要去思考为什么要这样去处理。
观察tcm可以发现它是一个TransactionalCacheManager类的对象,根据该类的名称:事务缓存管理器,也可以联系到该类实现的功能可能跟我们之前提及的二级缓存要提交事务这一特性有关。点进该类可以发现, 该类包含一个transactionalCaches属性,类型是Map。该Map的键为Cache,值为TransactionCache,即一个二级缓存对应一个TransactionalCache。
继续看该类的getObject()方法,如下所示:
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
通过上面的代码可以知道,一个二级缓存对应一个TransactionalCache,且TransactionalCache中持有这个二级缓存的引用。当调用TransactionalCacheManager的getObject()方法时,TransactionalCacheManager会将调用请求转发给TransactionalCache。
接着看TransactionalCache的getObject()方法:
@Override
public Object getObject(Object key) {
// issue #116
// delegate是一个Cache类型对象
// 在二级缓存中命中查询结果
Object object = delegate.getObject(key);
if (object == null) {
// 未命中则将CacheKey添加到entriesMissedInCache中,用于统计命中率
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
到这里就可以知道了,在CachingExecutor中通过CacheKey命中二级缓存结果时,步骤如下:
- CachingExecutor将请求发送给TransactionalCacheManager
- TransactionalCacheManager将请求转发给二级缓存对应的TransactionalCache
- 最后再由TransactionalCache根据其持有的二级缓存引用,将请求最终传递到二级缓存中。
在上述getObject()方法中,如果clearOnCommit为true的话,则getObject方法会一直返回null。那clearOnCommit参数是在什么地方被设置为true的呢?其实就是在CachingExecutor的flushCacheIfRequired()方法中。回到上面CachingExecutor的query()方法中,找到flushCacheIfRequired()这个方法,看一下它的代码:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
调用TransactionalCacheManager的clear()方法时,最终会调用到TransactionalCache的clear()方法,代码如下:
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
可以看到,在TransactionalCache的clear()方法中,将其clearOnCommit属性设置为了true。并且我们会发现还执行了entriesToAddOnCommit.clear(),这个entriesToAddOnCommit属性是什么呢?
同样回到上面CachingExecutor的query()方法中,看到下面这行代码,也就是上面说的将查询结果放入二级缓存的过程是借助于TransactionalCacheManager来控制的。
tcm.putObject(cache, key, list);
继续看TransactionalCacheManager的putObject方法:
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
最终,会调用到TransactionalCache的putObject方法:
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
到这里就可以看到,TransactionalCacheManager在将查询结果放入二级缓存中时,会利用TransactionalCache先将结果缓存到entriesToAddOnCommit中。那么entriesToAddOnCommit中的值与二级缓存是如何关联上的呢?
我们在上面介绍过,查询结果要缓存到二级缓存中时需要事务提交,那么会不会是在会话执行commit操作时,将entriesToAddOnCommit中暂存的查询结果刷新到二级缓存中的呢?为此,我们首先进入DefaultSqlSession的commit()方法中来一探究竟:
@Override
public void commit() {
commit(false);
}
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
在DefaultSqlSession的commit()方法中会调用到CachingExecutor的commit()方法:
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}
在CachingExecutor的commit()方法中,会调用TransactionalCacheManager的commit()方法
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
最终,会调用TransactionalCache的commit()方法,并在其中调用flushPendingEntries()方法和reset()方法。
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
// 将entriesToAddOnCommit中暂存的查询结果全部缓存到二级缓存中
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
// delegate是Cache类型对象,代表二级缓存
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
至此,一切都很明显了,当调用SqlSession的commit()方法时,会一路传递到TransactionalCache的commit()方法,最终调用TransactionalCache的flushPendingEntries()方法,将暂存在entriesToAddOnCommit中的查询结果转存入二级缓存中。同时,reset()方法会将刚刚提到的clearOnCommit属性值设置为false,从而使得后续调用该TransactionalCache对象持有的二级缓存来命中查询结果时,执行getObject不会一直返回null。
弄清楚上面的流程之后,我们也可以很清晰地知道为什么当执行增、删、改操作并提交事务后,二级缓存会被清空。原因就是,当调用update()方法时,会调用到CachingExecutor的flushCacheIfRequired方法。
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
已经知道flushCacheIfRequired()方法中如果所执行的方法对应的MappedStatement的flushCacheRequired字段为true的话(默认即为true),则最终会讲TransactionalCache中的clearOnCommit字段置为true。随后,在执行SqlSession的commit()事务提交时,会执行delegate.clear();将二级缓存清空。而加载映射文件时,解析CRUD标签为MappedStatement时有如下一行:
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
即如果没有在CRUD标签中显式的设置flushCache属性,则会给flushCache字段一个默认值,且默认值为非查询标签下默认为true。
至此,二级缓存的执行流程源码也已经分析的十分清晰了。
总结
- Mybatis中二级缓存默认不开启,需要手动配置开启,开启后,查询二级缓存会执行CachingExecutor的query()方法。
- 在二级缓存中,并不是直接将查询结果放入二级缓存中的,而是由TransactionalCacheManager将插入请求传递给二级缓存对应的TransactionalCache,而TransactionalCache中又持有该二级缓存的引用,所有最终由TransactionalCache将查询结果先缓存在entriesToAddOnCommit中。
- 只有当会话进行事务提交,执行SqlSession的commit()方法后,才会将entriesToAddOnCommit中的结果刷新到二级缓存中。
- 另外,当执行增、删、改操作的update()方法后,会将TransactionalCache的clearOnCommit属性值置为true,并在commit()提交事务后,执行
delegate.clear();来清空二级缓存。
整体二级缓存的流程可以用下图进行概括:
参考文章:
一文搞懂MyBatis一级缓存和二级缓存