深度学习——第3章 Python程序设计语言(3.3 Python数据类型)
3.3 Python数据类型
目录
1. Python数值数据类型
2. Python库的导入和使用
3. Python序列数据类型
4. Python组合数据类型
计算机能处理各种类型的数据,包括数值、文本等,不同的数据属于不同的数据类型,有不同的存储方式,支持不同的运算和操作。
Python语言提供了丰富的内置数据类型,用于有效处理各种类型的数据。
Python语言中,一切皆为对象,每个对象都归属于某个确定的数据类型。
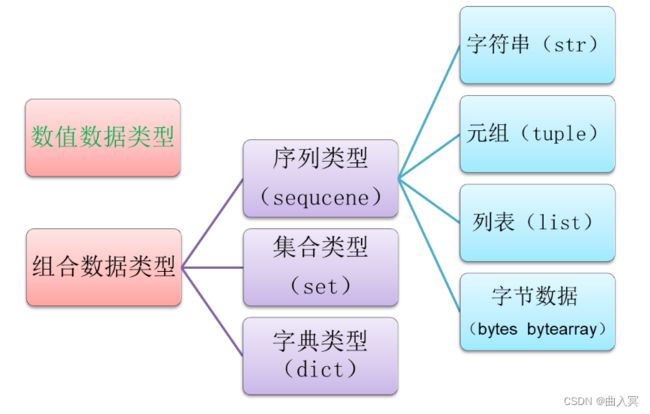
Python数据类型可简单分为数值数据类型和合数据类型两种。
Python提供4种数值数据类型:整型、浮点数型、复数型、布尔数据类型,对应数学中的整数、实数、复数、布尔逻辑值。
组合数据类型将多个相同或不同类型的数据组织起来,通过单一表示使数据更有序、更容易操作。根据数据之间的关系,组合数据类型可以分为序列类型、集合类型、和映射类型三类:
- 序列类型:是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他
- 集合类型:是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
- 字典类型(映射类型):是“键-值”数据项的组合,每个元素是一个键值对,表示为(key,value)
Python数值数据类型
整数(int)数据类型
Python的整数(integer;int)数据类型与数学中的整数概念一致。
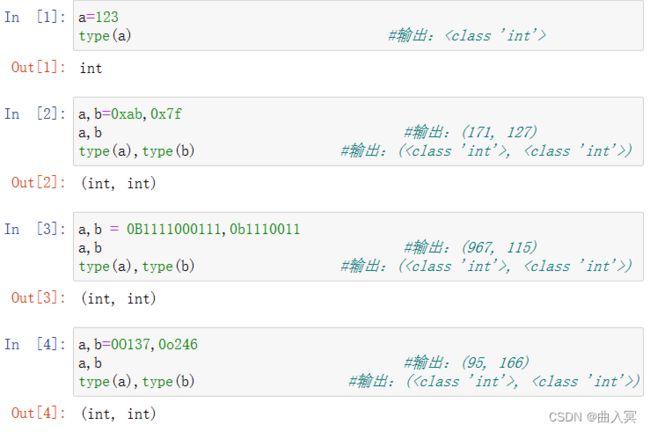
有四种进制表示形式:
- 十进制(Decimal):1010,99,-217
- 二进制(Binary):以0b或0B开头:0b010,0B101
- 八进制(Octonary):以0o或0O开头:0o123,-0O456
- 十六进制(Hexadecimal):以0x或0X开头:0x9a,-0X89
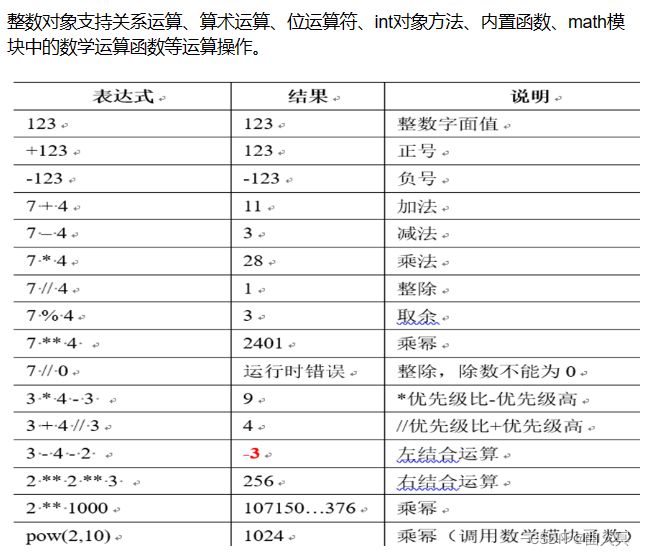
整数对象支持关系运算、算术运算、位运算符、int对象方法、内置函数、math模块中的数学运算函数等运算操作。
浮点(float)数据类型
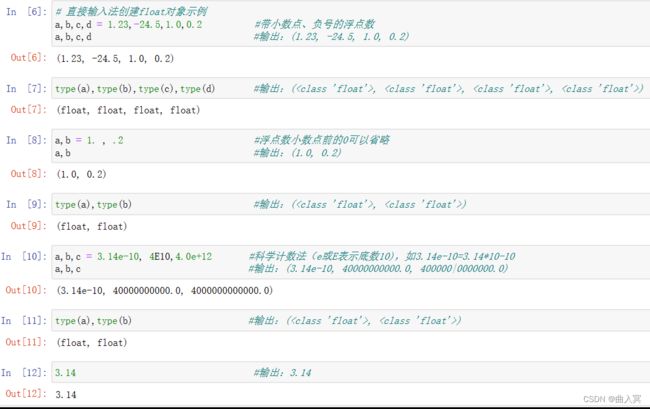
浮点数据类型与数学中实数的概念一致,是带有小数点和小数的数字。
浮点数据类型(float)是表示实数的数据类型,与其他计算机语言的双精度(double)和单精度对应,Python浮点类型的精度与系统相关。
浮点数取值范围和小数精度都存在限制,但常规计算可忽略。
取值范围数量级约 − 1 0 307 -10^{307} −10307至 1 0 308 10^{308} 10308,精度数量级 1 0 − 16 10^{-16} 10−16。
浮点数可以采用科学计数法表示:
使用字母e或E作为幂的符号,以10为基数,格式为:
例如:
4.3e-3 值为0.0043
9.6E5 值为960000.0
浮点数对象支持关系运算、算术运算、 float对象方法、内置函数、math模块中的数学运算函数等运算操作。
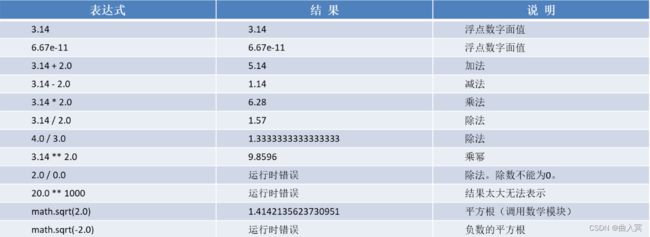
数值数据类型支持对象方法运算、关系运算、算术运算、位运算(整数int类型) ,同时可以使用内置函数、math模块中的数学运算函数进行数学运算。
内置函数
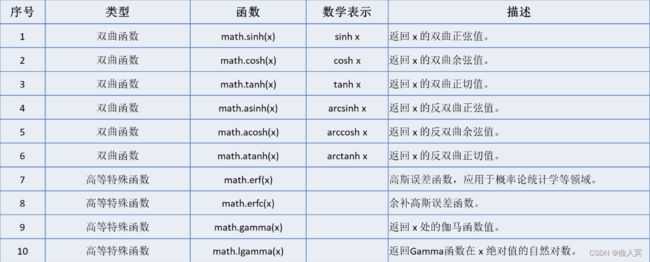
内置函数是python里自带可直接使用的函数,例如print()、input()等,python3.8.2共提供73个内置函数,可使用:
print(dir(__builtins__))
命令查看,可分类为输入输出类、数学运算类、集合操作类、逻辑判断类、迭代相关类、序列属性类等。

数学运算类内置函数
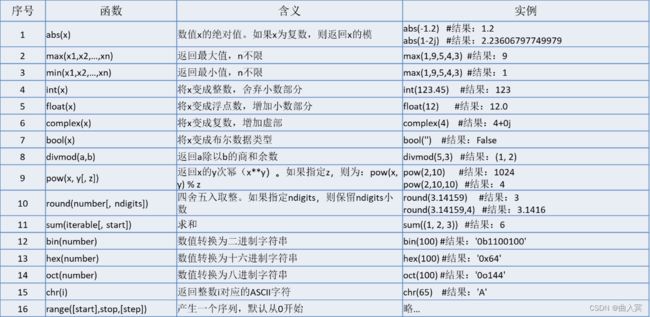
Python内置标准数学函数(math)库
math库是Python提供的内置数学类标准函数库。
math库一共提供了5个数学常数和50个函数(截止Python 3.8.2)。
50个函数包括:21个数论与表示函数,8个幂函数与对数函数,9个三角函数,2个角度转换函数,6个双曲函数和4个高等特殊函数。
Python官方文档(中文)
Python官方文档(英文)
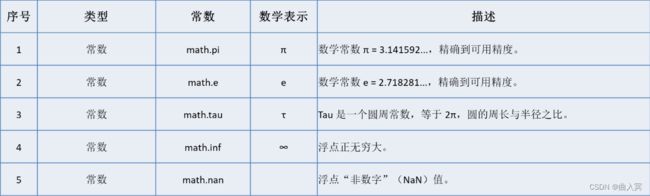
math库包括5个数学常数:
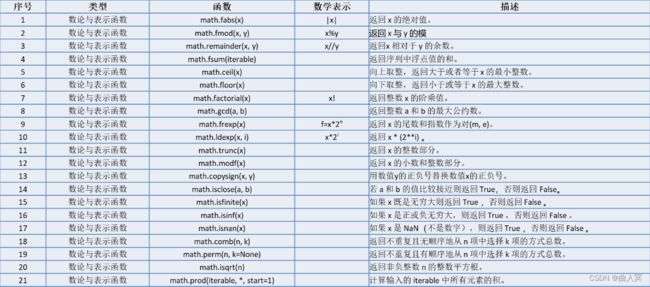
math库包括21个数论与表示函数:
math库包括8个幂函数与对数函数:
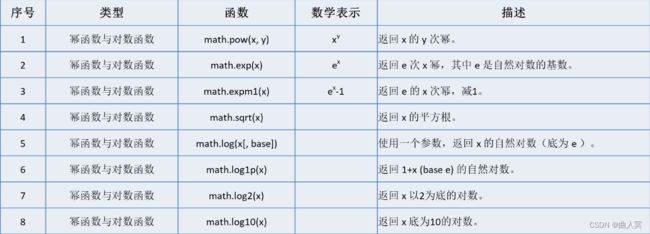
math库包括2个角度转换函数和9个三角函数:
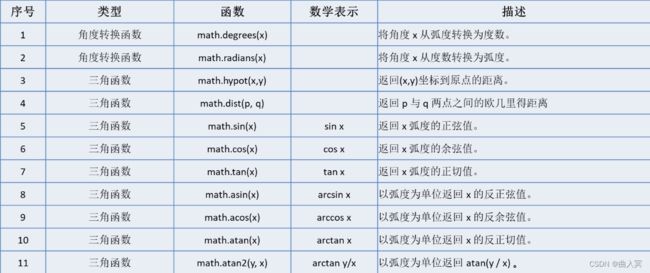
math库包括6个双曲函数和4个高等特殊函数:
Python库的导入和使用
Python标准库
Python语言的核心只包含数字、字符串、列表、字典、文件等常见类型和函数,而由Python标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML处理等额外的功能。
Python标准库的主要功能有:
- 文本处理,包含文本格式化、正则表达式匹配、文本差异计算与合并、Unicode支持,二进制数据处理;
- 文件处理,包含文件操作、创建临时文件、文件压缩与归档、操作配置文件;
- 操作系统功能,包含线程与进程支持、IO复用、日期与时间处理、调用系统函数、日志(logging);
- 网络通信,包含网络套接字,SSL加密通信、异步网络通信;
- 网络协议,支持HTTP,FTP,SMTP,POP,IMAP,NNTP,XMLRPC等多种网络协议,并提供了编写网络服务器的框架;
- W3C格式支持,包含HTML,SGML,XML的处理;
- 其它功能,包括国际化支持、数学运算、HASH、Tkinter等。
Python第三方库
Python社区提供了大量的第三方模块,使用方式与标准库类似。它们的功能覆盖科学计算、Web开发、数据库接口、图形系统多个领域。第三方模块可以使用Python或者C语言编写。SWIG,SIP常用于将C语言编写的程序库转化为Python模块。Boost C++ Libraries包含了一组函式库,Boost.Python,使得以Python或C++编写的程式能互相调用。
Python库的导入和使用
Python包含了数量众多的库(模块),通过import语句,可以导入模块并使用其定义的功能。
使用import语句可以导入模块。
其基本形式如下:
import 模块名 #导入模块
import 模块1, 模块2, …, 模块n #导入多个模块
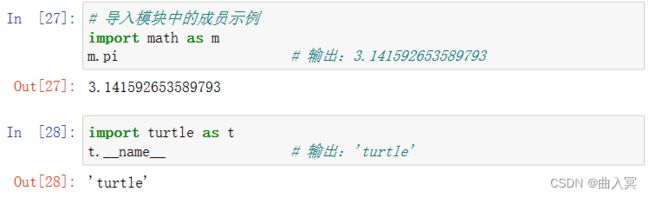
import 模块名 as 模块别名 #导入模块并使用别名
其中模块名是要导入的模块的名称。模块名区分大小写。
导入模块后,可以使用全限定名称访问模块中定义的成员,即:
模块名.函数名/变量名
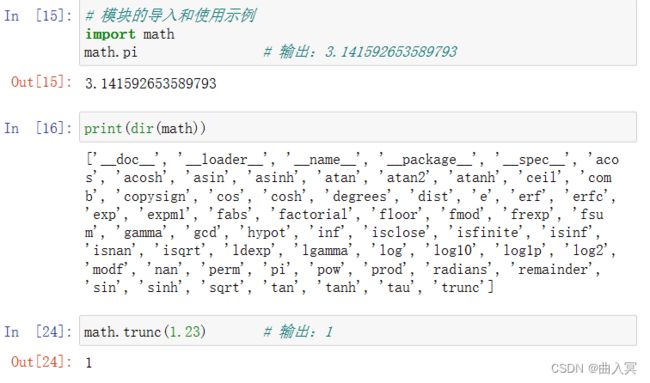
Python使用from…import语句导入模块中的成员。其基本形式如下:
from 模块名 import 成员名 #导入模块中的具体成员
成员名 #直接调用
如果希望同时导入一个模块中的多个成员,可以采用下列形式:
from 模块名 import 成员1, 成员2, …, 成员n
如果希望同时导入一个模块中的所有成员,可以采用下列形式:
from 模块名 import *
# 导入模块中的成员示例
from math import pi,sin
x=sin(2*pi)
print('{0:.2f}'.format(x)) # 输出:-0.00
注意:虽然from … import 语句可以简化代码,但建议避免使用,因为这样可能导致名称冲突(导入多个模块时,多个模块中可能存在同一个名称的函数),且导致程序的可读性差。例如,导入多个模块时,无法准确确定某个名称的函数具体属于哪一个模块。
推荐模块导入方法:
import 模块名 as 新名字
可以用这种方法给导入的命名空间一个新的名称。
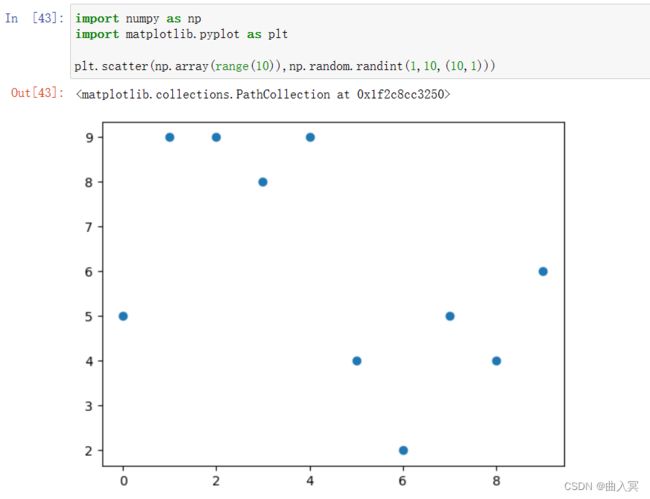
实例:一元二次方程求解
问题描述:
编写程序,输入一元二次方程的三个系数 a , b , c a,b,c a,b,c,求 a x 2 + b x + c = 0 ax^2+bx+c=0 ax2+bx+c=0方程的解。
备注:尽量使用内置函数和标准数学库中的函数。
解题思路:
-
Δ = b 2 − 4 a c \Delta=b²-4ac Δ=b2−4ac
-
当 Δ < 0 \Delta<0 Δ<0时, x x x无实数根;当 Δ = 0 \Delta=0 Δ=0时, x x x有两个相同实根;当 Δ > 0 \Delta>0 Δ>0时, x x x有两个不相同的实数根。
-
a a a应该不等于 0 0 0,在程序中应予考虑。
# 求解一元二次方程考虑各种情况
from math import sqrt
a, b, c = eval(input("请依次输入一元二次议程的a,b,c(用半角逗号分隔):")) #!输入三个系数
dert = b ** 2 - 4 * a * c
if a == 0 and b == 0 and c == 0:
print("本方程有无穷解。")
if a == 0 and b == 0 and c != 0:
print("本方程无解。")
elif a == 0 and b != 0:
print("本方程有一个实根:", -c / b)
elif dert < 0:
print(
"本方程无实根,有两个共轭复根,分别是:x1=",
complex(-b / (2 * a), sqrt(-dert) / (2 * a)),
",x2=",
complex(-b / (2 * a), -sqrt(-dert) / (2 * a)),
)
elif dert == 0:
print("本方程有两个相等实根:{}。".format(-b / (2 * a)))
else:
print("本方程有两个实根:x1=", (-b + sqrt(dert)) / (2 * a), ",x2=", (-b - sqrt(dert)) / (2 * a))
实例:三角形计算
问题描述:
输入三角形的三条边长,确认可构成三角形后计算面积、周长,最长边长、最短边长,以及对应的高和角度。
备注:尽量使用内置函数和标准数学库中的函数。
解题思路:
- 三角形面积公式的海伦公式:=√(−)(−)(−),其中 p = ( a + b + c ) / 2 p=(a+b+c)/2 p=(a+b+c)/2(半周长)
- 三角形某边对应的高公式:2倍的面积除以某边长。
- 某角两条夹边平方后相加所得的和减去对边的平方,所得再除以两边之积的二倍,得到的就是这个角的余弦值。即 cos A = ( b 2 + c 2 − a 2 ) / 2 b c \cos A= (b2+c2-a2)/2bc cosA=(b2+c2−a2)/2bc。
- math.acos函数值为数字的弧度。
- 角度等于弧度 × 180 / π \times 180/\pi ×180/π值。
# 输入三角形三条边长,求面积、周长、某边长所对应的高、最长边长、最短边长
import math
while True:
a = float(input("请输入边长a:"))
b = float(input("请输入边长b:"))
c = float(input("请输入边长c:"))
if a > 0 and b > 0 and c > 0 and a + b > c and a + c > b and b + c > a:
break
else:
print("三条边不能构成三角形,请重新输入!")
p = (a + b + c) / 2
area = round(math.sqrt(p * (p - a) * (p - b) * (p - c)), 2) # !求面积
perimeter = a + b + c # !求周长
# height = round(2 * area / a, 2) # !a边对应的高
max_side = max(a, b, c) # !最长边
max_side_height = round(2 * area / max_side, 2) #!最长边对应的高
min_side = min(a, b, c) # !最短边
min_side_height = round(2 * area / min_side, 2) #!最短边对应的高
mid_side = a + b + c - max_side - min_side
max_side_angle = round(
math.degrees(math.acos((min_side ** 2 + mid_side ** 2 - max_side ** 2) / (2 * min_side * mid_side))), 1
) # !求最长边对应的角度
min_side_angle = round(
math.acos((max_side ** 2 + mid_side ** 2 - min_side ** 2) / (2 * max_side * mid_side)) * 180 / math.pi, 1
) # !求最短边对应的角度
mid_side_angle = 180 - max_side_angle - min_side_angle
print("三角形的三条边为:", a, b, c)
print("三角形的面积为:", area)
print("三角形的周长为:", perimeter)
print("三角形的最长边为:", max_side, "其对应的高为:", max_side_height, "其对应的角度为:", max_side_angle)
print("三角形的最短边为:", min_side, "其对应的高为:", min_side_height, "其对应的角度为:", min_side_angle)
print("三角形的中间边为:", mid_side, "其对应的角度为:", mid_side_angle)
实例:鸡兔同笼问题
问题描述:
一个笼子里装有若干只鸡和兔子,上面数有 h h h个头,下面数有 f f f只脚,请计算鸡和兔各有多少只。
备注:尽量使用内置函数和标准数学库中的函数。
解题思路:
- 已知head个头和feet只脚,则兔子数 r = ( f − 2 h ) / 2 r=(f-2h)/2 r=(f−2h)/2,鸡的数量 c c c为 h − r h-r h−r。
- 应该是偶数; f f f应该大于等于 h h h的2倍,并且小于等于 h h h的4倍。否则程序一定会计算错误。
# 求解鸡免同笼问题
while True:
h = int(input("请输入鸡和兔的总个数:"))
while True:
f = int(input("请输入动物脚的总数(应该是偶数):"))
if f % 2 == 0:
break
else:
print("动物脚的总数应该为偶数,请重新输入!")
if f >= 2 * h and f <= 4 * h:
break
else:
print("无解,请重新输入!")
r = int(f / 2 - h)
c = h - r
print("兔子有", r, "只,鸡有", c, "只。", sep="")
Python序列数据类型
序列数据类型是Python的基础数据结构,是一组有顺序的元素的集合。序列数据可以包含一个或多个元素(对象,元素也可以是其他系列数据),也可以是一个没有任何元素的空系列。
Python内置的序列数据类型包括:字符串(str)、元组(tuple)、**列表(list)**和字节数据(bytes和bytearray)。
字符串数据类型( str)
字符串(str)是字符的有序序列,由0个或多个字符组成的有序字符序列。
Python中没有独立的字符数据类型,长度为1的字符串就是字符。
str数据类型是不可变对象。
字符串的创建
Python中字符串可以使用以下4种方式创建:
- 一对单引号(’ ')。包含在单引号中的字符串,字符串里可以包含双引号。
- 一对双引号(" ")。包含在双引号中的字符串,字符串里可以包含单引号。
- 一对三单引号(‘’’ ‘’')。包含在三单引号中的字符串,字符串可以跨行,也可以包括小于连续三个的单引号和双引号。
- 一对三双引号(“”" “”")。包含在三双引号中的字符串,字符串可以跨行,也可以包括小于连续三个的单引号和双引号。
# 直接输入法创建str对象示例
'abc' #输出:'abc' "Hello" #输出:'Hello'
type("python") #输出:转义字符
转义字符以反斜杠开始,紧跟一个字母,如“\n”(新行)和“\t”(制表符)。转义符形成一些组合,表达一些不可打印的含义;可以使用反斜线的方式进行转义,使引号变为普通字符;如果字符串中希望包含反斜杠,则它前面必须还有另一个反斜杠。
示例:
Python转义字符表:

字符串的遍历
可以通过for和in组成的循环来遍历(挨个访问)字符串中的每个字符。
for <var> in <string>:
操作语句
字符串的序号
字符串有两排序方式:
- 正向递增序号,从0开始编号
- 反向递减序号,最后一位是-1
字符串的索引和切片
使用下标运算符“[ ]”和“:” 可以获取字符串中的一个或多个字符。
- 索引
获取字符串中的单个字符串。
**方法:<字符串>[M] **
- 切片
获取字符串中的一段子串。
方法:<字符串>[M:N] #注意,获取的子串不包括第N个字符

字符串切片的高级用法(1或2个冒号)
- <字符串>[M:N],M缺失表示至开头,N缺失表示至结尾
示例:“一二三四五六七八九”[:3],结果是"一二三"
- <字符串>[M:N:K],根据步长K对字符串切片
示例: “一二三四五六七八九”[1:8:2],结果是"二四六八"
- 字符串逆序:<字符串>[::-1]
示例: “一二三四五六七八九”[::-1],结果是"九八七六五四三二一"

字符串的运算及操作
字符串数据类型是Python的基本数据类型。
对于Python这一面向对象的程序设计语言来说,任一数据类型都可以从以下四个方面来探究对其运算或操作的方法:
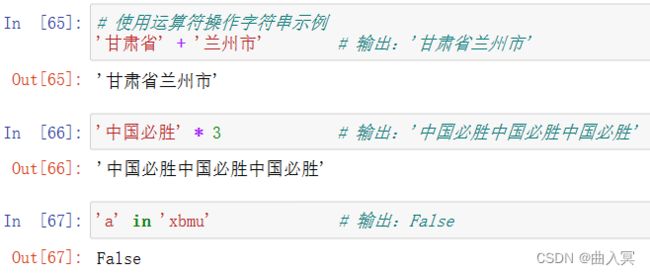
(1)运算符
索引、切片、关系运算、 拼接运算串、重复运算符、成员测试

(2)内置函数
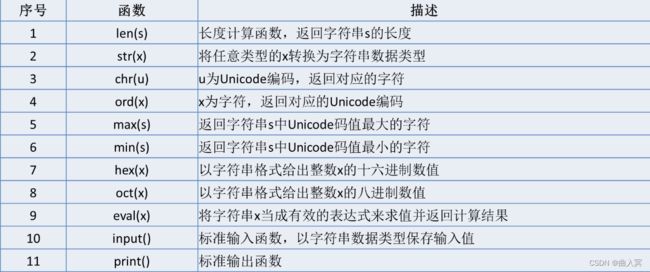
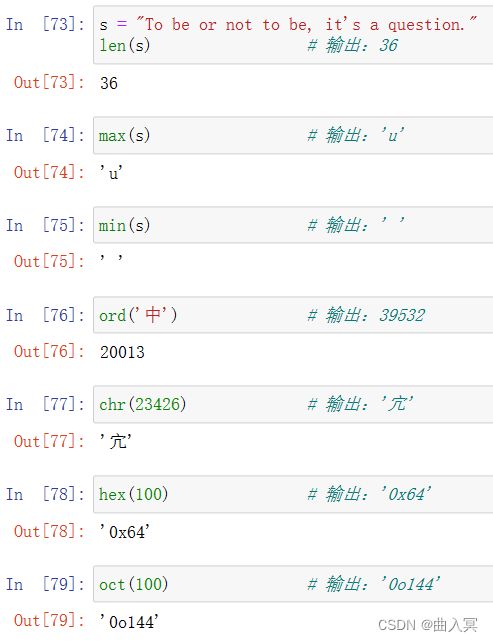
(3)字符串类对象方法

字符串对象方法共有44个,可分为is测试、查找、替换、大小写转换、分割、修剪、编码、格式化等。
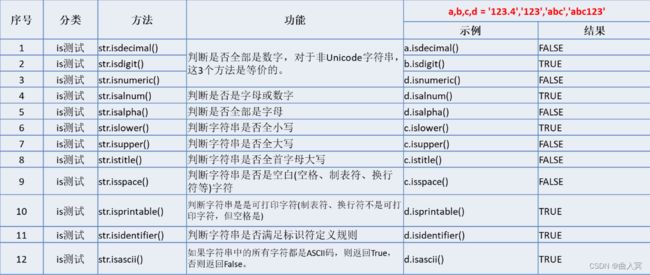

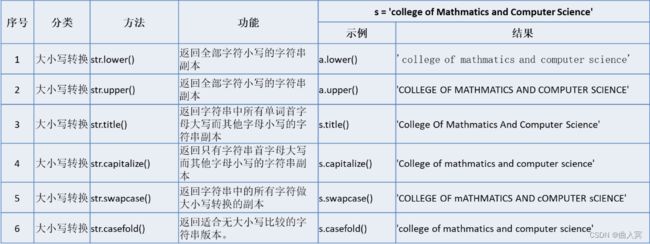
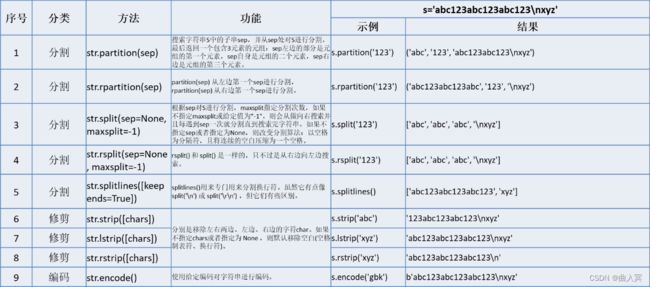
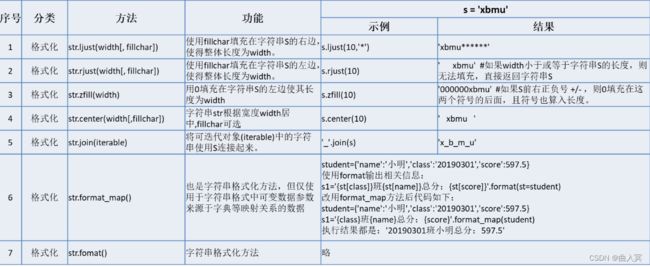
(4)库函数(标准库和第三方库)
NLTK、jieba、SnowNLP、thulac、gensim
程序案例:凯撒密码
问题描述:使用凯撒密码对输入的明文字符串进行加密及还原。
要求:加密算法为字母(包括大小写字母)向后偏移4(可以任意设置),即a替换为e,Z替换为D,其它依此类推。
说明:涉及字符串编码、遍历、内置函数等知识的综合运用
备注:凯撒密码作为一种最为古老的对称加密体制,在古罗马的时候都已经很流行。其基本思想是:通过把字母移动一定的位数来实现加密和解密。明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推X将变成A,Y变成B,Z变成C。由此可见,位数就是凯撒密码加密和解密的密钥。
# 使用凯撒密码对输入的明文字符串进行加密及还原。
# 加密算法为字母(包括大小写字母)向后偏移4,即a替换为e,Z替换为D,其它依此类推。
ms = input("请输入明文:")
ps = ""
hs = ""
print("明文:{}".format(ms))
for s in ms:
if 65 <= ord(s) <= 90:
ps += chr(ord("A") + (ord(s) - ord("A") + 4) % 26)
elif 97 <= ord(s) <= 122:
ps += chr(ord("a") + (ord(s) - ord("a") + 4) % 26)
else:
ps += s
print("密文:{}".format(ps))
for s in ps:
if 65 <= ord(s) <= 90:
hs += chr(ord("A") + (ord(s) - ord("A") - 4) % 26)
elif 97 <= ord(s) <= 122:
hs += chr(ord("a") + (ord(s) - ord("a") - 4) % 26)
else:
hs += s
print("原文:{}".format(hs))
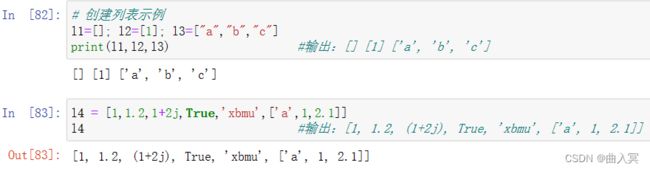
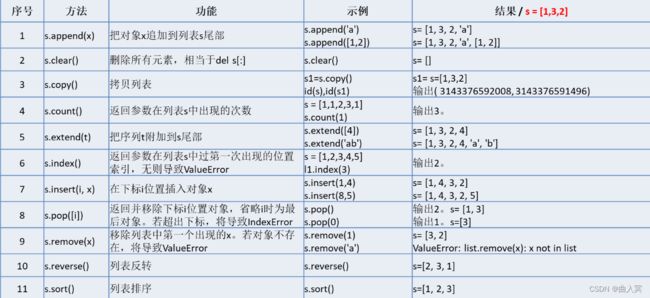
列表数据类型(list)
列表(list)是包含0个或多个对象的有序序列,属于序列数据类型。列表的长度和内容是可变的,数据项可以访问、增加、删除或修改。
列表没有长度限制,元素类型可以不同,使用非常灵活。
Python没有数组,可以用列表代替。
列表就是多项数据组合而成的一个数据结构,其中,每一项数据我们称之为元素(Element)。
元素可以是相同的数据类型,也可以是任意不同的数据类型,如整型、浮点型、字符串,甚至是列表本身。
列表的创建
列表采用方括号中用逗号分隔的项目创建。格式如下:
列表名 = [元素0,元素1,元素2,元素3,…,元素n]
如果[]内不包含任何元素,表示该列表为空列表。例如L=[],执行这条语句时,将产生一个空列表。列表中的元素以“,”相间隔,例如,语句L=[3,1,5]定义了一个含有三个元素的列表。
列表(list)是Python程序设计语言中功能最为强大的数据类型。
列表的运算和操作
(1)运算符
访问(索引)、切片、 拼接、关系运算、重复运算符、成员测试

之前我们已经学习过字符串的“遍历”、“序号”、“索引”、“切片”概念或操作。由于列表数据类型与字符串同属序列数据类型,一些操作方法是通用的,同学们可将一些对字符串的操作知识迁移到列表数据类型中来。
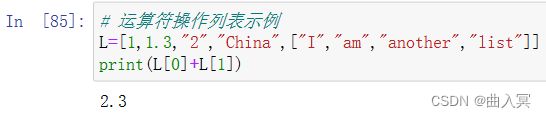
访问列表元素(通过索引)
修改列表元素(通过索引)
访问想要改变的元素并对其进行赋值,即可完成修改。例如将上例的列表L中的第一个元素整数1改成浮点数1.0,即L[0] = 1.0;将第二个元素浮点数1.3改成字符’a’,即L[1] = ‘a’,就可以改变L列表中原有的元素。
访问列表元素(通过切片)
分片是可以一次性获取列表中多个连续元素的操作,使用方法与字符串切片方法一致,分单冒号切片及双冒号高级切片两种。
修改列表元素(通过切片)
访问想要改变的列表切片并对其进行赋值,即可完成修改。
# 通过切片修改列表示例
ls = ['cat','dog','tiger',123]
ls[1:2] = ['a','b','c','d']
ls
#输出['cat', 'a', 'b', 'c', 'd', 'tiger', 123]
判断元素是否在列表中
可以利用成员关系操作符in判断某个元素在不在列表当中,如果在则返回True,否则返回False。
#<程序:判断元素在不在序列中>
L = [1,1.3,"2","China",["I","am","another","list"]]
print("China" in L) #输出为True
print("I" in L) #输出为False
由上例可见," China"确实在列表L中,但是"I"明明在L中为什么会输出False呢?原因很简单,“I"在L的子列表中,而in只判断该元素是否为列表L中的元素却不会继续判断元素是否在子列表中,所以如果我们想判断"I"在不在子列表中,只能用"I” in L[4]。借助in操作符,我们还可以用not in判断某个元素是否不在序列中。
删除列表元素
通过保留关键字del可以删除列表元素。列表元素的访问可以通过索引或切片两种方式。

列表的连接和重复
我们之前学过的算术操作符+、可以运用到列表上,只是操作结果不相同。连接符+:对于两个列表,“+”则表示连接操作,需要注意的是,进行连接操作的必须是两个列表。复制():对于列表而言,操作符“*”表示将原列表重复复制多次。
(2)内置函数

计算列表长度并完成列表的遍历
使用内置函数len()获取列表长度,再进行循环访问,就可以完成列表的遍历操作。

(3)类对象方法
列表解析表达式
列表解析表达式是python语言的一个亮点语法。本质上是用列表来构建列表,通过对已有列表中的每一个元素应用一个指定的表达式来构建出一个新的列表。
列表解析式的优势是编码简单,运行速度快。格式如下:
[expr for i1 in 序列1…for iN in 序列N] #迭代序列里所有内容,计算生成列表
[expr for i1 in 序列1…for iN in 序列N if cond_expr] #按条件迭代,计算生成列表
列表解析表达式的三个核心要素:
- 作用于输入序列的运算表达式expr
- 对输入序列的循环表达式for i1 in 序列1…for iN in 序列N
- 对输入序列的过滤条件if cond_expr (过滤条件是可选的)。

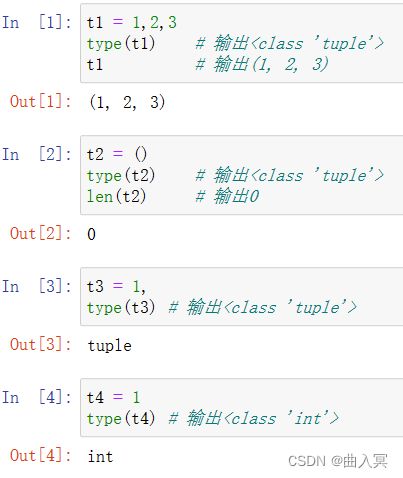
元组数据类型(tuple)
元组(tuple) 属序列数据类型,是一组有序系列,包含零个或多个元素。
元组和列表十分类似,但元组是不可变的对象,不能修改、添加或删除元组中的项目,可以访问元组中的项目。
元组也称之为定值表,一旦创建就不能被修改,元组其实就是戴着枷锁的列表。
元组的创建
元组采用圆括号中用逗号分隔的元素创建,圆括号可以省略。格式:
元组名 = (元素0, 元素1, 元素2, 元素3, …, 元素n)
或者元组名 = 元素0, 元素1, 元素2, 元素3, …, 元素n
其中,x1,x2,…,xn为任意对象。如果元组中只有一个元素时,后面的逗号不能省略,Python解释器把(x1)只解释为x1,例如(1)解释为整数1,在(1,)的情况下解释为元组。
元组的运算和操作
元组和列表是近亲关系,所以元组和列表在实际使用中非常相似。
**元组数据类型继承了序列类型的全部通用操作。**包括索引访问、切片操作、连接操作、重复操作、成员关系操作、比较运算操作,以及求元组长度、最大值、最小值等。
元组因为创建后不能修改,因此没有特殊操作。
元组元素的遍历(挨个访问)方法与列表一样(循环结构配合len())。
此处从略
程序案例:格式化输出杨辉三角
问题描述:编写程序,格式化输出杨辉三角。
杨辉三角即二项式定理的系数表,各元素满足如下条件:第一列及对角线上的元素均为1;其余每个元素等于它上一行同一列元素与上一行前一列元素之和。综合运用字符串、列表处理知识完成案例。
说明:先生成杨辉三角每一行的系统列表,再按字符串格式输出。
备注:杨辉三角形,又称贾宪三角形,帕斯卡三角形,是二项式系数在三角形中的一种几何排列。杨辉三角中,第3行的三个数恰好对应着两数和的平方的展开式的每一项的系数,即 ( a + b ) 2 = a 2 + 2 a b + b 2 (a+b)^2=a^2+2ab+b^2 (a+b)2=a2+2ab+b2。第4行的四个数恰好依次对应两数和的立方的展开式的每一项的系数。
N = 10 #!N值为生成杨辉三角的行数
yh_list = [[1]] # *初始化杨辉三角为[[1]]
for i in range(N - 1): # ?生成杨辉三角
templist = [1]
for j in range(len(yh_list) - 1):
templist.append(yh_list[i][j] + yh_list[i][j + 1])
templist.append(1)
yh_list.append(templist)
# print(yh_list) #!输出杨辉三角
for i in range(len(yh_list)): # *格式化输出1
print(str(yh_list[i]).center(50))
for i in range(len(yh_list)): # ?格式化输出2
temp_str = ""
for j in range(len(yh_list[i])):
temp_str += " " + str(yh_list[i][j])
print(temp_str.center(51))
输出结果:

random标准库
随机数在计算机应用中十分常见,Python内置的random库主要用于产生各种分布的伪随机数序列。random库采用梅森旋转算法(Mersenne Twister)生成伪随机数序列,可用于对随机性要求更高的加解密算法之外的大多数工程应用。
random库的使用方法与其它库一样,先导入后使用。
import random
random.<b>() #库函数引用
random模块包含各种伪随机数生成函数,以及各种根据概率分布生成随机数的函数。

使用random库主要目的是生成随机数,同学们只需要查阅该库的随机数生成函数,找到符合使用场景的函数使用即可。该库提供了不同类型的随机数函数,所有函数都是基于最基本的random.random()函数的扩展实现。
random生成伪随机数库帮助文档
本课件选择random库中比较常用函数进行介绍。
设置种子及生成小数类随机函数

生成随机数之前可以通过seed()函数指定随机数种子,随机种子一般是一个整数,只要种子相同,每次生成的随机数序列也相同。这种情况便于测试和同步数据。
伪随机数和真随机数
随机数或随机事件是不确定性的产物,结果不可预测,产生之前不可预见。无论计算机产生的随机数看起来多么“随机”,它们也不是真正意义上的随机数。因为计算机是按照一定算法产生随机数的,结果是确定的、可预见的,称为“伪随机数”。真正意义上的随机数是不能评价的。如果存在评价随机数的方法,即判断一个数字是否是随机数,那么这个随机数就有确定性,将不再是随机数。
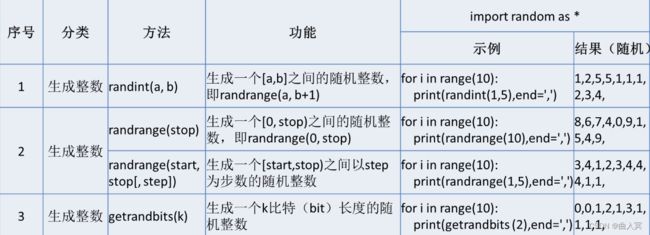
生成整数类随机函数
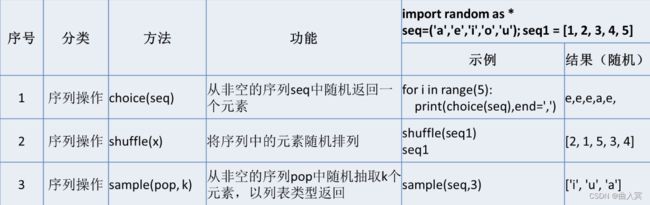
序列操作类随机函数
程序案例:计算最大公约数和最小公倍数
问题描述:编写程序,产生两个1-100之间(包含0和100)的随机数a和b,求这两个整数的最大公约数和最小公倍数。
说明:综合运用列表、字符串的操作和运算方法完成案例。
#
#!产生两个1-100之间(包含0和100)的随机数a和b。
#!求这两个整数的最大公约数和最小公倍数。
from random import randint
# ?生成随机数
print("{0}生成随机整数{0}(1-100间)".format("-" * 10))
c_a = a = randint(1, 100)
c_b = b = randint(1, 100)
print("a={}\nb={}".format(a, b))
# ?求最大公约数
while c_a % c_b != 0:
c_a, c_b = c_b, c_a % c_b
print("{}和{}的最大公约数是:{},最大公倍数是:{:d}。".format(a, b, c_b, int(a * b / c_b)), end="")
程序案例:蒙特卡罗方法计算圆周率 π \pi π
问题描述:蒙特卡罗方法求解π的基本步骤如下:
1.随机向单位正方形和圆结构内拋洒大量的“飞镖”点
2.计算每个点到圆心的距离从而判断该点是否在圆内
3.用圆内的点数除以总点数就是 π / 4 \pi/4 π/4的值。
随机点数量越大,越充分覆盖整个图形,计算得到的π值越精确。实际上,这个方法的思想是利用离散点值表示图形的面积,通过面积比例来求解 π \pi π值。
说明:先理解蒙特卡罗方法的思想,再程序实现。
备注:随着计算机的出现,数学家找到了求解 π \pi π的另类方法:蒙特卡罗(Monte Carlo)方法,又称随机抽样或统计试验方法。当所要求解的问题是某种事件出现的概率,或者是某个随机变量的期望值时,它们可以通过某种"试验" 的方法,得到这种事件出现的频率,或者这个随机变数的平均值,并用它们作为问题的解。这就是蒙特卡罗方法的基本思想。
#!使用蒙特·卡罗方法计算PI值
from math import sqrt
from random import random
from time import perf_counter
d = 2 ** 20
dots = 0
start = perf_counter()
for i in range(1, d + 1):
a, b = random(), random()
if sqrt(a ** 2 + b ** 2) <= 1.0:
dots += 1
pi = 4 * (dots / d)
end = perf_counter()
print("PI = {},计算耗时:{:.5f}s".format(pi, end - start))
#输出结果:PI = 3.1416664123535156,计算耗时:0.79713s
Python组合数据类型
组合数据类型将多个相同或不同类型的数据组织起来,通过单一表示使数据更有序、更容易操作。根据数据之间的关系,组合数据类型可以分为序列类型、集合类型、和映射类型三类:
- 序列类型:是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他
- 集合类型:是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
- 字典类型(映射类型):是“键-值”数据项的组合,每个元素是一个键值对,表示为(key,value)
集合数据类型
集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合。集合数据类型是没有顺序的简单对象的聚集,集合中的元素不可重复。集合元素类型只能是不可变数据(固定)类型,例如整数、浮点数、布尔值、复数、字符串、元组等,而列表、字典和集合类型本身都是可变数据类型,不能作为集合的元素出现。
Python编译器中界定不可变(固定)数据类型与否主要考察类型是否能够进行哈希运算。能够执行哈希运算的类型都可以作为集合元素。Python提供了一种同名的具体数据类型——集合(set)。
集合的创建
Python集合数据类型包括可变集合对象(set)和不可变集合对象(frozenset)。可变集合(set)通过花括号中用逗号分隔的项目定义,其基本形式如下:
集合名 = {元素0, 元素1, 元素2, 元素3, …, 元素n}
集合元素不重复,且无序。集合中可以包含内置不可变对象,不能包含内置可变对象。
注意:集合的输出顺序与定义顺序不一定一致;{}表示空字典,非空集合;字典数据类型(dict)也使用花括号定义,定义空集合只能使用类对象方法set()。

集合元素是无序的,所以无法通过下标索引或切片的方式访问,但可以通过循环遍历的方法访问。
集合的运算和操作
集合数据类型支持以下运算:
- 成员测试
- 并、交、差、补
- 集合的比较
- 集合的长度、最大最小值
- 集合的类对象方法
另一角度:
- 运算符:关系运算、成员测试、并、交、差、补
- 内置函数: len(), max(), min(), sum() …
- 集合对象方法

集合解析表达式
与列表解析表达式语法类似,Python可以使用集合解析表达式。它可以简单高效地处理一个可迭代对象,并生成结果集合。
集合解析表达式的格式如下:
{expr for i1 in 序列1... for iN in 序列N} #迭代序列里所有内容,并计算生成集合
{expr for i1 in 序列1... for iN in 序列N if cond_expr} #按条件迭代,并计算生成集合
集合解析表达式的三个核心要素:
- 作用于输入序列的运算表达式expr;
- 对输入序列的循环表达式for i1 in 序列1…for iN in 序列N;
- 输入序列的过滤条件 if cond_expr (过滤条件可无)。
集合数据类型的应用
集合数据类型与其他类型最大的不同在于它不包含重复元素,当需要对一维数据进行去重或进行数据重复处理时,一般通过集合来完成。
程序案例:集合生成及运算
问题描述:随机生成0到100闭区间内的10个整数,组成集合A和集合B,输出A和B的元素、长度、最大值、最小值以及并集、交集和差集。
from random import randint
def createset():
s = set()
for i in range(10):
s.add(randint(0,100))
return s
def main():
A = createset()
B = createset()
print('集合A:{}'.format(A))
print('集合B:{}'.format(B))
print('集合A的长度为:{}'.format(len(A)))
print('集合B的长度为:{}'.format(len(B)))
print('集合A的最大值为:{}'.format(max(A)))
print('集合B的最大值为:{}'.format(max(B)))
print('集合A的最小值为:{}'.format(min(A)))
print('集合B的最小值为:{}'.format(min(B)))
print('集合A和B的并集为:{}'.format(A | B))
print('集合A和B的交集为:{}'.format(A & B))
print('集合A和B的差集为:{}'.format(A - B))
print('集合A和B的补集为:{}'.format(A ^ B))
if __name__ == '__main__':
main()
输出结果:

程序案例:重复元素判定
问题描述:编写函数,接收列表为参数,如果一个元素在列表中出现了不止一次,则返回True。
利用集合的无重复性,获得一个更快更便捷的版本。
解题思路:第一种方法:编写函数,判定元素是否重复并返回结果;第二种方法:基于列表生成集合,如果列表和集合的长度不一,则有重复元素。
# 重复元素判定。
# 编写一个函数,接受列表为参数,如果一个元素在列表中出现了不止一次,
# 则返回True。不要改变原来列表的值,同时编写调用这个函数和调试结果的程序。
# 利用集合的无重复性,获得一个更快更便捷的版本。
from random import randint
list_lenth = 10
def createlist(n):
lst = []
for i in range(n):
lst.append(randint(0, 100))
return lst
lst = createlist(list_lenth)
print(sorted(lst))
print(set(lst))
def dertermine_if_repeat_item_in_list(lst):
l = len(lst)
for i in range(l - 1):
for j in range(i + 1, l):
if lst[i] == lst[j]:
return True
return False
print("列表有" if dertermine_if_repeat_item_in_list(lst) else "列表无", "重复元素。", sep="")
print("列表", "有" if len(lst) != len(set(lst)) else "无", "重复元素。", sep="")
输出结果:

字典数据类型
索引和映射的概念
索引是按照一定顺序检索内容的体系。编程语言的索引主要包括两类:数字索引,也称为位置索引;字符索引,也称为单词索引。数字索引采用数字作为索引数的方法,可以通过整数序号找到内容。字符索引采用字符作为索引词,通过具体的索引词找到数据,例如,现实生活中的汉语词典,通过汉语词找到释义。Python语言中,字符串、列表、元组等都采用数字索引,字典采用字符索引。
列表是存储和检索数据的有序序列。当访问列表中的元素时,可以通过整数索引来查找它,索引是元素在列表中的序号。
很多应用程序需要更灵活的信息查找方式,例如,在检索学生或员工信息时,需要基于身份证号码进行查找,而不是信息存储的序号。在编程术语中,根据一个信息查找另一个信息的方式构成了“键值对”,它表示索引用的键和对应的值构成的成对关系,即通过一个特定的键(身份证号码)来访问值(学生信息)。实际应用中有很多“键值对”的例子,例如,姓名和电话号码、用户和密码、邮政编码和运输成本、国家名称和首都等。由于键不是序号,无法使用列表类型进行有效存储和索引。
通过任意键信息查找一组数据中值信息的过程叫作映射,Python语言中通过字典来实现映射。
字典的创建
字典(dict,或映射map):是一组键:值对的数据结构。每个键对应于一个值,键不能重复,根据键可以查询到值。
字典是键(key)和值(value)的映射关系集合,该集合以键为索引,一个键信息只对应一个值信息。
字典的键必须是不可变对象,但字典的值可以是任意对象;字典长度是可变的,可以通过对键信息赋值实现增加或修改键值对;字典中元素以键信息为索引访问;一般而言,应使用简单的对象作为键。
字典通过花(大)括号中用逗号分隔的键:值对定义。基本形式如下:
字典名 = {key1:value1,[key2:value2,…,keyn:valuen]}
键:值对使用冒号分隔,不同键值对通过逗号分隔。
从Python设计角度考虑,大括号{}可以表示集合,因此字典类型也具有和集合类似的性质,即键值之间没有顺序且不能重复,可以把字典看成元素是键值对的集合。
字典打印出来的顺序可能与创建之初的顺序不同,这不是错误。字典是集合类型的延续,各个元素并没有顺序之分。如果要保持一个集合中元素的顺序,需要使用列表,而不是字典。
直接使用大括号{}可以创建一个空的字典;定义空集合使用set()。

字典的运算和操作
字典d可以通过键key来访问,示例如下:
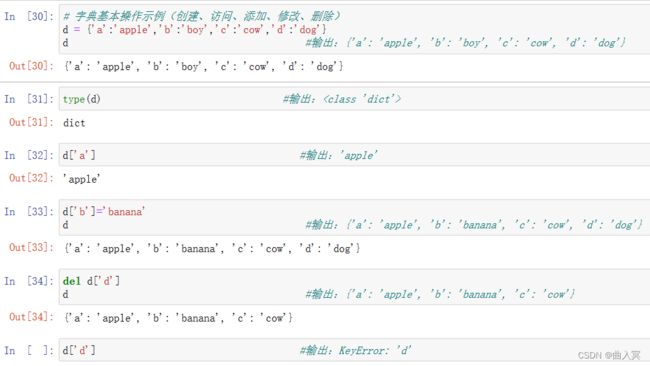
通过以下对象方法,可以动态访问字典数据:
d.keys(): #返回字典d的键key列表。
d.values(): #返回字典d的值value列表。
d.items(): #返回字典d的(key,value)列表。

与其他组合类型一样,字典可以通过for * in语句对其元素进行遍历,示例如下:

字典的类对象方法

字典解析表达式
字典数据结构也可以采用与列表解析表达式和集合解析表达式类似的方式生成。使用字典解析表达式,可以简单高效地处理一个可迭代对象并生成结果字典。格式如下:
字典名称 = {k:v for i1 in 序列1... for iN in 序列N} #迭代序列里所有内容,并计算生成字典
字典名称 = {k:v for i1 in 序列1... for iN in 序列N if cond_expr} #按条件迭代,并计算生成字典
三个核心要素:k:v键值对;k和v的循环表达式;过滤条件(可选)。

程序案例:凯撒密码
问题描述:使用凯撒密码对输入的明文字符串进行加密及还原,字母偏移量13,加密解密使用同一个算法。要求构建一个字典来破译密码。
解题思路:先构建字典;遍历输入的原始字符串,从字典中映射值(有则返回值,无则返回原值)形成列表,再构建为加密字符串。解密方法与加密方法完全一致。
# 构建字典,方法一
pwdt1 = {}
for c in [65, 97]:
for i in range(26):
# pwdt1.update({chr(c + i): chr(c + (i + 13) % 26)}) #类对象方法
pwdt1[chr(c + i)] = chr(c + (i + 13) % 26) # 运算符生成
print(pwdt1) # 输出字典
# 构建字典,方法二
pwdt2 = {chr(65 + k): chr(65 + (k + 13) % 26) for k in range(26)} # 字典解析表达式,先生成大写字母
dt_temp = {chr(97 + k): chr(97 + (k + 13) % 26) for k in range(26)} # 字典解析表达式,生成小写字母
pwdt2.update(dt_temp) # 字典合并
print(pwdt2) # 输出并判断两个字典是否一致
print(pwdt1 == pwdt2) # 输出并判断两个字典是否一致
# 输入加密字符串
original_str = input("请输入原始字符串:")
encryption_str = "".join([pwdt1.get(c, c) for c in original_str])
print("加密字符串为:", encryption_str)
decode_str = "".join([pwdt1.get(c, c) for c in encryption_str])
print("解密字符串为:", decode_str)
输出结果:
