今天我们来讲一下Kafka 4元素中的Producer, 第一个概念就是同步 和 异步
1. sync vs async
在官方文档Producer Configs中有如下:
producer.type的默认值是sync,即同步的方式。这个参数指定了在后台线程中消息的发送方式是同步的还是异步的。如果设置成异步的模式,可以运行生产者以batch的形式push数据,这样会极大的提高broker的性能,但是这样会增加丢失数据的风险。
对于异步模式,还有4个配套的参数,如下:
以batch的方式推送数据可以极大的提高处理效率,kafka producer可以将消息在内存中累计到一定数量后作为一个batch发送请求。batch的数量大小可以通过producer的参数(batch.num.messages)控制。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。在比较新的版本中还有batch.size这个参数。
producers可以一步的并行向kafka发送消息,但是通常producer在发送完消息之后会得到一个响应,返回的是offset值或者发送过程中遇到的错误。这其中有个非常重要的参数“request.required.acks",这个参数决定了producer要求leader partition收到确认的副本个数,如果acks设置为0,表示producer不会等待broker的相应,所以,producer无法知道消息是否发生成功,这样有可能导致数据丢失,但同时,acks值为0会得到最大的系统吞吐量。若acks设置为1,表示producer会在leader partition收到消息时得到broker的一个确认,这样会有更好的可靠性,因为客户端会等待知道broker确认收到消息。若设置为-1,producer会在所有备份的partition收到消息时得到broker的确认,这个设置可以得到最高的可靠性保证。
2. Producer消息路由
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与Partition总数取余,该消息会被发送到该数对应的Partition。(每个Parition都会有个序号,序号从0开始)
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class JasonPartitioner implements Partitioner {
public JasonPartitioner(VerifiableProperties verifiableProperties) {}
@Override
public int partition(Object key, int numPartitions) {
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key) % numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}
}
如果将上例中的类作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic3(包含4个Partition)。
public void sendMessage() throws InterruptedException{
for(int i = 1; i <= 5; i++){
List messageList = new ArrayList>();
for(int j = 0; j < 4; j++){
messageList.add(new KeyedMessage("topic2", String.valueOf(j), String.format("The %d message for key %d", i, j));
}
producer.send(messageList);
}
producer.close();
}
则key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和Partition序号相同。(Partition序号从0开始,本例中的key也从0开始)。下图所示是通过Java程序调用Consumer后打印出的消息列表。
3. Producer 数据发送流程
下面通过对 send 源码分析来一步步剖析 Producer 数据的发送流程。
Producer 的 send 实现
用户是直接使用 producer.send() 发送的数据,先看一下 send() 接口的实现
// 异步向一个 topic 发送数据
@Override
public Future send(ProducerRecord record) {
return send(record, null);
}
// 向 topic 异步地发送数据,当发送确认后唤起回调函数
@Override
public Future send(ProducerRecord record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
数据发送的最终实现还是调用了 Producer 的 doSend() 接口。
Producer 的 doSend 实现
在看代码前,我们先过一下Kafka doSend 的思想
下面是 doSend() 的具体实现
try {
// 1.确认数据要发送到的 topic 的 metadata 是可用的
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 2.序列化 record 的 key 和 value
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
// 3. 获取该 record 的 partition 的值(可以指定,也可以根据算法计算)
int partition = partition(record, serializedKey, serializedValue, cluster);
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize); // record 的字节超出限制或大于内存限制时,就会抛出 RecordTooLargeException 异常
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); // 时间戳
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
// 4. 向 accumulator 中追加数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
// 5. 如果 batch 已经满了,唤醒 sender 线程发送数据
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
}
3.1 key 和 value 的序列化
Producer 端对 record 的 key 和 value 值进行序列化操作,在 Consumer 端再进行相应的反序列化,Kafka 内部提供的序列化和反序列化算法如下图所示:
当然我们也是可以自定义序列化的具体实现,不过一般情况下,Kafka 内部提供的这些方法已经足够使用。
3.2 获取 partition 值
关于 partition 值的计算,分为三种情况:
指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {// 没有指定 key 的情况下
int nextValue = nextValue(topic); // 第一次的时候产生一个随机整数,后面每次调用在之前的基础上自增;
List availablePartitions = cluster.availablePartitionsForTopic(topic);
// leader 不为 null,即为可用的 partition
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {// 有 key 的情况下,使用 key 的 hash 值进行计算
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; // 选择 key 的 hash 值
}
}
// 根据 topic 获取对应的整数变量
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) { // 第一次调用时,随机产生
counter = new AtomicInteger(new Random().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement(); // 后面再调用时,根据之前的结果自增
}
3.3 向 accumulator 写数据
由于生产者发送消息是异步地,所以可以将多条消息缓存起来,等到一定时机批量地写入到Kafka集群中,RecordAccumulator就扮演了缓冲者的角色。生产者每生产一条消息,就向accumulator中追加一条消息,并且要返回本次追加是否导致batch满了,如果batch满了,则开始发送这一批数据。一批消息会首先放在RecordBatch中,然后Batch又放在双端队列Deque
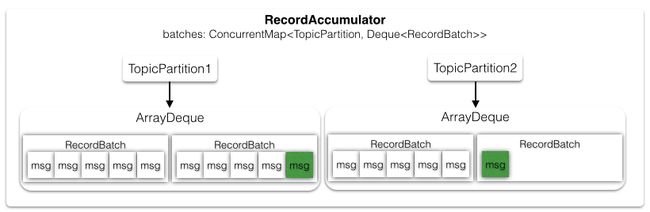
// org.apache.kafka.clients.producer.internals.RecordAccumulator
// 向 accumulator 添加一条 record,并返回添加后的结果(结果主要包含: future metadata、batch 是否满的标志以及新 batch 是否创建)其中, maxTimeToBlock 是 buffer.memory 的 block 的最大时间
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
Deque dq = getOrCreateDeque(tp);// 每个 topicPartition 对应一个 queue
synchronized (dq) {// 在对一个 queue 进行操作时,会保证线程安全
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq); // 追加数据
if (appendResult != null)// 这个 topic-partition 已经有记录了
return appendResult;
}
// 为 topic-partition 创建一个新的 RecordBatch, 需要初始化相应的 RecordBatch,要为其分配的大小是: max(batch.size, 加上头文件的本条消息的大小)
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);// 给这个 RecordBatch 初始化一个 buffer
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {// 如果突然发现这个 queue 已经存在,那么就释放这个已经分配的空间
free.deallocate(buffer);
return appendResult;
}
// 给 topic-partition 创建一个 RecordBatch
MemoryRecordsBuilder recordsBuilder = MemoryRecords.builder(buffer, compression, TimestampType.CREATE_TIME, this.batchSize);
RecordBatch batch = new RecordBatch(tp, recordsBuilder, time.milliseconds());
// 向新的 RecordBatch 中追加数据
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);// 将 RecordBatch 添加到对应的 queue 中
incomplete.add(batch);// 向未 ack 的 batch 集合添加这个 batch
// 如果 dp.size()>1 就证明这个 queue 有一个 batch 是可以发送了
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
batches是一个并发安全的,但是每个TopicPartition里的ArrayDeque并不是线程安全的,所以在修改Deque时都需要同步块操作。队列中只要有一个以上的batch(dq.size),或者追加了这条消息后,当前Batch中的记录满了(batch.records),就可以发送消息了。
3.4 发送 RecordBatch
RecordAccumulator.RecordAppendResult的batch满了,唤醒Sender线程。Sender线程的启动在创建KafkaProducer时。Sender再唤醒NetworkClient(不是线程,相当于通知客户端开始服务了),client也唤醒Selector,最终唤醒NIO的Selector。
为什么需要有wakeup动作:因为可能有线程在select等待事件被阻塞了(没有事件),通过wakeup唤醒那个线程开始工作(有事件进来了)
Sender不仅承载了RecordAccumulator记录的收集器,也要通知客户端服务:把Accumulator收集的批记录通过客户端发送出去。Sender作为一个线程,是在后台不断运行的,如果线程被停止,可能RecordAccumulator中还有数据没有发送出去,所以要优雅地停止。
当 record 写入成功后,如果发现 RecordBatch 已满足发送的条件(通常是 queue 中有多个 batch,那么最先添加的那些 batch 肯定是可以发送了),那么就会唤醒 sender 线程,发送 RecordBatch。
发送消息的工作统一由Sender来控制。之前的wakeup只是一个通知,实际的工作还是由线程的run方法来控制的。同样调用client.send也只是把请求先放到队列中,client.poll才是会将读写真正发送到socket链路上。
void run(long now) {
Cluster cluster = metadata.fetch();
// 获取那些已经可以发送的 RecordBatch 对应的 nodes
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果有 topic-partition 的 leader 是未知的,就强制 metadata 更新
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 如果与node 没有连接(如果可以连接,同时初始化该连接),就证明该 node 暂时不能发送数据,暂时移除该 node
Iterator iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// 返回该 node 对应的所有可以发送的 RecordBatch 组成的 batches(key 是 node.id),并将 RecordBatch 从对应的 queue 中移除
Map> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
if (guaranteeMessageOrder) {
//记录将要发送的 RecordBatch
for (List batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 将由于元数据不可用而导致发送超时的 RecordBatch 移除
List expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
// 发送 RecordBatch
sendProduceRequests(batches, now);
this.client.poll(pollTimeout, now); // 关于 socket 的一些实际的读写操作(其中包括 meta 信息的更新)
}
/**
* Transfer the record batches into a list of produce requests on a per-node basis
*/
private void sendProduceRequests(Map> collated, long now) {
for (Map.Entry> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
/**
* Create a produce request from the given record batches
*/
// 发送 produce 请求
private void sendProduceRequest(long now, int destination, short acks, int timeout, List batches) {
Map produceRecordsByPartition = new HashMap<>(batches.size());
final Map recordsByPartition = new HashMap<>(batches.size());
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records());
recordsByPartition.put(tp, batch);
}
ProduceRequest.Builder requestBuilder =
new ProduceRequest.Builder(acks, timeout, produceRecordsByPartition);
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}