3.pytorch加载数据
1. Dataset
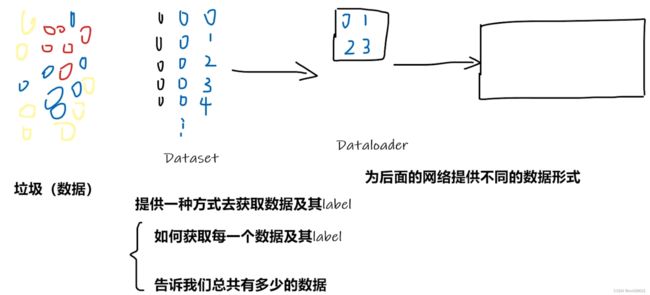
所谓Dataset,其实就是一个负责处理索引(index)到样本(sample)映射的一个类(class)。
torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。
Map式数据集
一个Map式的数据集必须要重写getitem(self, index),len(self) 两个内建方法,用来表示从索引到样本的映射(Map).
这样一个数据集dataset,举个例子,当使用dataset[idx]命令时,可以在你的硬盘中读取你的数据集中第idx张图片以及其标签(如果有的话);len(dataset)则会返回这个数据集的容量。
参考
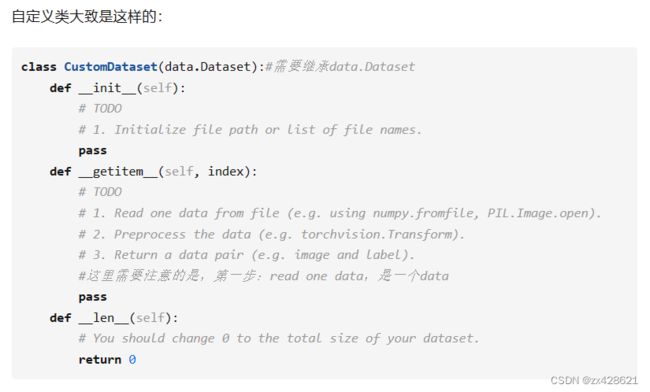
例子1:
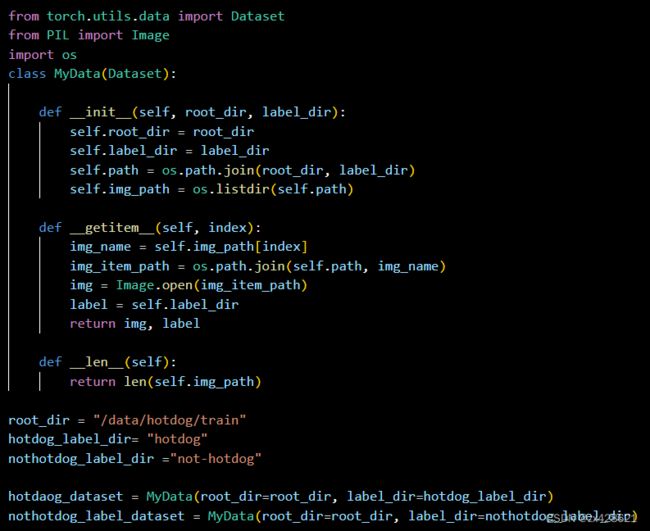
例子-1: 自己实验中写的一个例子:这里我们的图片文件储存在“./data/faces/”文件夹下,图片的名字并不是从1开始,而是从final_train_tag_dict.txt这个文件保存的字典中读取,label信息也是用这个文件中读取。

例子2:
DataLoader

Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生 一个个batch的样本集合。
参数解释:

dataset (Dataset) – 定义好的Map式或者Iterable式数据集。
batch_size (python:int, optional) – 一个batch含有多少样本 (default: 1)。
shuffle (bool, optional) – 每一个epoch的batch样本是相同还是随机 (default: False)。
sampler (Sampler, optional) – 决定数据集中采样的方法. 如果有,则shuffle参数必须为False。
batch_sampler (Sampler, optional) – 和 sampler 类似,但是一次返回的是一个batch内所有样本的index。和 batch_size, shuffle, sampler, and drop_last 三个参数互斥。
num_workers (python:int, optional) – 多少个子程序同时工作来获取数据,多线程。 (default: 0) collate_fn (callable, optional) – 合并样本列表以形成小批量。
pin_memory (bool, optional) – 如果为True,数据加载器在返回前将张量复制到CUDA固定内存中。
drop_last (bool, optional) – 如果数据集大小不能被batch_size整除,设置为True可删除最后一个不完整的批处理。如果设为False并且数据集的大小不能被batch_size整除,则最后一个batch将更小。
(default: False) timeout (numeric, optional) – 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。
(default: 0) worker_init_fn (callable, optional*) – 每个worker初始化函数 (default: None)
采样器:
sampler 重点参数,采样器,是一个迭代器。PyTorch提供了多种采样器,用户也可以自定义采样器。
所有sampler都是继承 torch.utils.data.sampler.Sampler这个抽象类。
关于迭代器

SequentialSampler

RandomSampler:

SubsetRandomSampler:

batch_sampler:
前面的采样器每次都只返回一个索引,但是我们在训练时是对批量的数据进行训练,而这个工作就需要BatchSampler来做。也就是说BatchSampler的作用就是将前面的Sampler采样得到的索引值进行合并,当数量等于一个batch大小后就将这一批的索引值返回。
class BatchSampler(Sampler):
# Wraps another sampler to yield a mini-batch of indices.
# Args:
# sampler (Sampler): Base sampler.
# batch_size (int): Size of mini-batch.
# drop_last (bool): If ``True``, the sampler will drop the last batch if
# its size would be less than ``batch_size``
# Example:
# >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
# >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
# 批次采样
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \
batch_size <= 0:
raise ValueError("batch_size should be a positive integeral value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
WeightedRandomSampler:
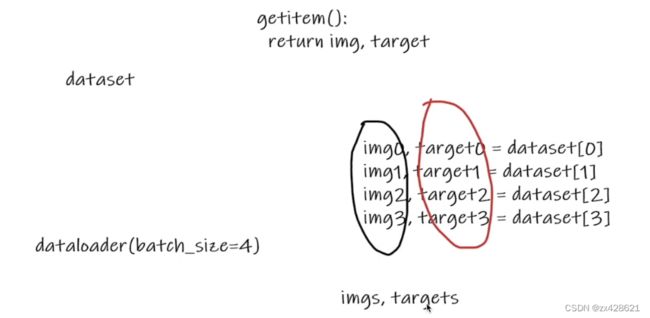
例子1:
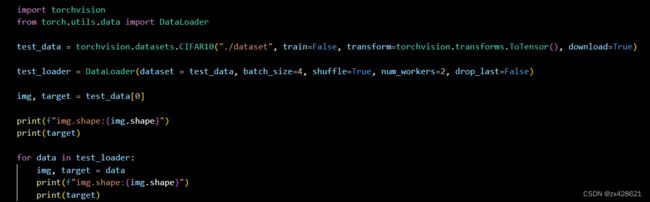
dataset
dataloader