即兴MQ-Rabbit
文章目录
-
- 引言
- 消息队列
-
- AMQP和JMS
-
- AMQP
- JMS
- AMQP 与 JMS 区别
- 消息队列常见产品
- 当前主流MQ对比表格
- RabbitMQ介绍
- 安装方法就不阐述了
- 项目依赖和简单配置介绍
-
- xml
- application.yml
- 配置rabbitMQ的Configuration类
- 消费者示例
- 生产者示例
- 最后
- 20220704 23:00加稿
-
- AMQP
- RabbitMQ运转流程
- 生产者流转过程分析
- 消费者流转过程分析
- RabbitMQ工作模式
-
- Work queues工作队列模式
-
- 小结
- 发布订阅模式类型
- Publish/Subscribe发布与订阅模式
引言
MQ作为中大型项目中作用于异步处理,应用解耦,流量削锋和消息通讯等场景,尤其重要,今天就即兴选择RabbitMQ来吹一下怎么玩儿
- 任务异步处理
将不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理。提高了应用程序的响应时间。
- 应用程序解耦合
MQ相当于一个中介,生产方通过MQ与消费方交互,它将应用程序进行解耦合。
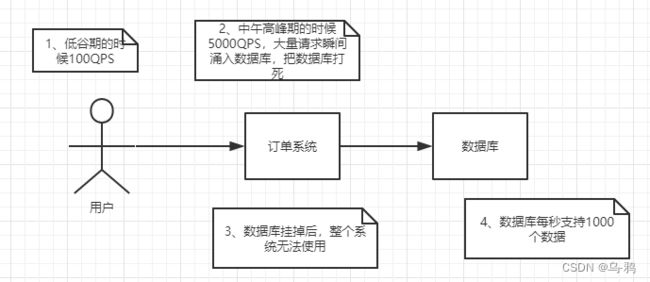
- 削峰填谷
如订单系统,在下单的时候就会往数据库写数据。但是数据库只能支撑每秒1000左右的并发写入,并发量再高就容易宕机。低峰期的时候并发也就100多个,但是在高峰期时候,并发量会突然激增到5000以上,这个时候数据库肯定卡死了。
消息被MQ保存起来了,然后系统就可以按照自己的消费能力来消费,比如每秒1000个数据,这样慢慢写入数据库,这样就不会卡死数据库了。
但是使用了MQ之后,限制消费消息的速度为1000,但是这样一来,高峰期产生的数据势必会被积压在MQ中,高峰就被“削”掉了。但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000QPS,直到消费完积压的消息,这就叫做“填谷”
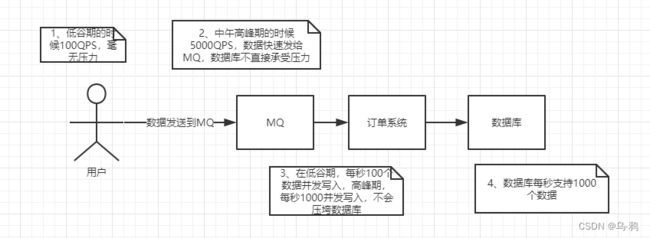

消息队列
MQ的本质 大概地讲就是(一发一存一消费),在直白点就是一个(转发器)
消息:就是要传输的数据,可以是最简单的文本字符串,也可以是自定义的复杂格式(只要能按预定格式解析出来即可)
队列:是一种先进先出数据结构。它是存放消息的容器,消息从队尾入队,从对头出队,入队即发消息的过程,出队即收消息的过程。
-
如今我们最常用的消息队列产品(RocketMQ,Kafka等等),你会发现:它们都在最原始的消息模型上做了扩展,同时提出了一些新名词,比如:主题(topic),分区(partition),队列(queue)等等
-
最初的消息队列就是上一节讲的原始模型,它是一个严格意义上的队列(Queue)。消息按照什么顺序写进去,就按照什么顺序读出来。不过队列没有"读"这个操作,读就是出队,从队头中"删除"这个消息。
-
生产者先将消息投递到一个叫做(队列)的容器中,然后再从这个容器中取出消息,最后再转发给消费者,仅此而已
目前MQ的应用场景非常多,例如:系统解耦,异步通信和流量削峰。除此之外,还有延迟通知,最终一致性保证,顺序消息,流式处理等等。
AMQP和JMS
MQ是消息通信的模型;实现MQ的大致有两种主流方式:AMQP、JMS。
AMQP
AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
JMS
JMS即Java消息服务(JavaMessage Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
AMQP 与 JMS 区别
- JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
- JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
- JMS规定了两种消息模式;而AMQP的消息模式更加丰富
消息队列常见产品
- ActiveMQ:基于JMS
- ZeroMQ:基于C语言开发
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品
- Kafka:类似MQ的产品;分布式消息系统,高吞吐量
当前主流MQ对比表格
| 特性 | activityMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 成熟度 | 成熟 | 成熟 | 比较成熟 | 成熟的日志领域 |
| 实效性 | 微秒级 | 毫秒级 | 毫秒级 | |
| 社区活跃度 | 低 | 高 | 高 | 高 |
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ | 10万级别,这是kafka最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十个到几百个的时候,吞吐量会大幅度下降所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | ||
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,消息可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用偶尔会有较低概率丢失消息而且现在社区以及国内应用都越来越少,官方社区现维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | rlang语言开发,性能极其好,延时很低;吞吐量到万级,MQ功能比较完备而且开源提供的管理界面非常棒,用起来很好用社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用rabbitmq也比较多一些但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的 | kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集 |
此表格纯照抄百度文库
RabbitMQ介绍
贴官网传送门
RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开发中应用非常广泛。
RabbitMQ提供了6种模式:简单模式,work模式,Publish/Subscribe发布与订阅模式,Routing路由模式,Topics主题模式,RPC远程调用模式(远程调用,不太算MQ;暂不作介绍);
官网对应模式介绍:传送门

六种工作模式:工作队列模式、发布订阅模式、路由模式、通配符Topics模式、(RPC模式、Head模式)
安装方法就不阐述了
给你们一个示例:传送门
项目依赖和简单配置介绍
xml
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
application.yml
spring:
rabbitmq:
host: localhost #安装MQ的服务器ip
port: 5672 #端口
virtual-host: / #虚拟主机
username: guest #用户名
password: guest #密码
listener:
simple:
prefetch: 1 #指定当前只能接收一条消息,当该消息处理完成后再去接收下一个消息;避免一下子把队列中的所有消息全部接收造成不良后果;
virtual-host: /
listener:
simple:
prefetch: 10
acknowledge-mode: manual
配置rabbitMQ的Configuration类
@Configuration
public class RabbitConfig {
@Value("${spring.rabbitmq.host}")
private String addresses;
@Value("${spring.rabbitmq.port}")
private Integer port;
@Value("${spring.rabbitmq.username}")
private String username;
@Value("${spring.rabbitmq.password}")
private String password;
@Value("${spring.rabbitmq.virtual-host}")
private String virtualHost;
public RabbitConfig() {
}
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setAddresses(this.addresses);
connectionFactory.setPort(this.port);
connectionFactory.setUsername(this.username);
connectionFactory.setPassword(this.password);
connectionFactory.setVirtualHost(this.virtualHost);
return connectionFactory;
}
@Bean
public RabbitAdmin rabbitAdmin(ConnectionFactory connectionFactory) {
return new RabbitAdmin(connectionFactory);
}
@Bean
public RabbitTemplate rabbitTemplate() {
RabbitTemplate rabbitTemplate = new RabbitTemplate(this.connectionFactory());
rabbitTemplate.setMessageConverter(new Jackson2JsonMessageConverter());
return rabbitTemplate;
}
// /**
// * 声明交换机
// */
// @Bean("XXX_LOCALHOST")
// public TopicExchange getTopicExchange() {
// return new TopicExchange("xxx.localhost");
// }
//
// /**
// * 声明队列
// * @return
// */
// @Bean("XXX_LOCALHOST_QUEUES")
// public Queue localhostQueue() {
// return new Queue("xxx.localhost.queues");
// }
//
// /**
// * 声明队列
// * @return
// */
// @Bean("XXX_PRIVATE_CHAT_QUEUES")
// public Queue privateQueue() {
// return new Queue("xxx.privateChat.queues");
// }
//
// /**
// * 将队列绑定到交换机
// * @param queue
// * @param topicExchange
// * @return
// */
// @Bean
// public Binding xxxLocalhostBinding(@Qualifier("XXX_LOCALHOST_QUEUES") Queue queue,
// @Qualifier("XXX_LOCALHOST") TopicExchange topicExchange) {
// return BindingBuilder.bind(queue).to(topicExchange).with("xxx.localhost.queues");
// }
//
// /**
// * 将队列绑定到交换机
// * @param queue
// * @param topicExchange
// * @return
// */
// @Bean
// public Binding robotPrivateBinding(@Qualifier("ROBOT_PRIVATE_CHAT_QUEUES") Queue queue,
// @Qualifier("XXX_LOCALHOST") TopicExchange topicExchange) {
// return BindingBuilder.bind(queue).to(topicExchange).with("xxx.privateChat.queues");
// }
xxx为我的私密内容,别照着抄
消费者示例
@Slf4j
@Component
public class RabbitMQConsume {
// @Value("${spring.rabbitmq.template.exchange}")
// public String EXCHANGES_NAME;
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(value = PublicConstants.RabbitMQQueues.LOCALHOST_QUEUES_NAME),
exchange = @Exchange(value = PublicConstants.RabbitMQExchanges.LOCALHOST_EXCHANGES_NAME)
)
)
@RabbitHandler
public void handle(@Payload Map<String,Object> dataMap, Channel channel, @Headers Map<String,Object> headers){
try {
// 处理业务
System.out.println("消费消息: " + dataMap);
//手动确认正确的从消息队列中取出数据,并且处理完毕
// TODO: 这里插入消费逻辑
Long tag = (Long)headers.get(AmqpHeaders.DELIVERY_TAG);
channel.basicAck(tag,false);//消息队列确认
} catch (Exception e) {
e.printStackTrace();
}
}
}
生产者示例
公用rabbitMqServiceImpl业务层: 接口我就不写了直接写实现
/**
* 生产私聊MQ
* @param privateChatDTO
*/
@Override
public void productionXxxMessageMethods(XXXDTO xxxDTO) {
rabbitTemplate.convertAndSend(PublicConstants.RabbitMQExchanges.XXX_EXCHANGES_NAME, null ,xxxDTO);
}
我们的业务层:
// 注入rabbitMQService
@Autowired
private RabbitMqService rabbitMqService;
/**
* 生产消息方法:service层
* @param privateChatVO
* @param msgId
*/
@Override
public XXXDTO productionMethods(XXXVO xxxVO) {
XXXDTO xxxDTO = xxxVO.toBean(XXXDTO.class);
log.info("==========发送消息内容: " + xxxDTO.toString() + " 已经生产消息到MQ");
rabbitMqService.productionXxxMessageMethods(xxxDTO);
return xxxDTO;
}
最后
我这使用的是纯Spring Boot的方式去操作rabbitMQ,纯的注解化, 其中也有使用xml形式的,我认为现在项目应该很少使用到xml方式的,如果有需要的评论提出,我抽空补一下
之所以选用纯Spring Boot 注解方式是因为这样更美观,更规范,更牛逼
20220704 23:00加稿
AMQP
AMQP 一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
AMQP是一个二进制协议,拥有一些现代化特点:多信道、协商式,异步,安全,扩平台,中立,高效。
RabbitMQ是AMQP协议的Erlang的实现。
| 概念 | 说明 |
|---|---|
| 连接Connection | 一个网络连接,比如TCP/IP套接字连接。 |
| 会话Session | 端点之间的命名对话。在一个会话上下文中,保证“恰好传递一次”。 |
| 信道/通道Channel | 多路复用连接中的一条独立的双向数据流通道。为会话提供物理传输介质。 |
| 客户端Client | AMQP连接或者会话的发起者。AMQP是非对称的,客户端生产和消费消息,服务器存储和路由这些消息。 |
| 服务节点Broker | 消息中间件的服务节点;一般情况下可以将一个RabbitMQ Broker看作一台RabbitMQ 服务器。 |
| 端点 | AMQP对话的任意一方。一个AMQP连接包括两个端点(一个是客户端,一个是服务器)。 |
| 消费者Consumer | 一个从消息队列里请求消息的客户端程序。 |
| 生产者Producer | 一个向交换机发布消息的客户端应用程序。 |
RabbitMQ运转流程
- 生产者发送消息
- 生产者创建连接(Connection),开启一个信道(Channel),连接到RabbitMQ Broker;
- 声明队列并设置属性;如是否排它,是否持久化,是否自动删除;
- 将路由键(空字符串)与队列绑定起来;
- 发送消息至RabbitMQ Broker;
- 关闭信道;
- 关闭连接;
- 消费者接收消息
- 消费者创建连接(Connection),开启一个信道(Channel),连接到RabbitMQ Broker
- 向Broker 请求消费相应队列中的消息,设置相应的回调函数;
- 等待Broker回应闭关投递响应队列中的消息,消费者接收消息;
- 确认(ack,自动确认)接收到的消息;
- RabbitMQ从队列中删除相应已经被确认的消息;
- 关闭信道;
- 关闭连接;

生产者流转过程分析
- 客户端与代理服务器Broker建立连接。会调用newConnection() 方法,这个方法会进一步封装Protocol Header 0-9-1 的报文头发送给Broker ,以此通知Broker 本次交互采用的是AMQPO-9-1 协议,紧接着Broker 返回Connection.Start 来建立连接,在连接的过程中涉及Connection.Start/.Start-OK 、Connection.Tune/.Tune-Ok ,Connection.Open/ .Open-Ok 这6 个命令的交互。
- 客户端调用connection.createChannel方法。此方法开启信道,其包装的channel.open命令发送给Broker,等待channel.basicPublish方法,对应的AMQP命令为Basic.Publish,这个命令包含了content Header 和content Body()。content Header 包含了消息体的属性,例如:投递模式,优先级等,content Body 包含了消息体本身。
- 客户端发送完消息需要关闭资源时,涉及到Channel.Close和Channl.Close-Ok 与Connetion.Close和Connection.Close-Ok的命令交互。
消费者流转过程分析
- 消费者客户端与代理服务器Broker建立连接。会调用newConnection() 方法,这个方法会进一步封装Protocol Header 0-9-1 的报文头发送给Broker ,以此通知Broker 本次交互采用的是AMQPO-9-1 协议,紧接着Broker 返回Connection.Start 来建立连接,在连接的过程中涉及Connection.Start/.Start-OK 、Connection.Tune/.Tune-Ok ,Connection.Open/ .Open-Ok 这6 个命令的交互。
- 消费者客户端调用connection.createChannel方法。和生产者客户端一样,协议涉及Channel . Open/Open-Ok命令。
- 在真正消费之前,消费者客户端需要向Broker 发送Basic.Consume 命令(即调用channel.basicConsume 方法〉将Channel 置为接收模式,之后Broker 回执Basic . Consume - Ok 以告诉消费者客户端准备好消费消息。
- Broker 向消费者客户端推送(Push) 消息,即Basic.Deliver 命令,这个命令和Basic.Publish 命令一样会携带Content Header 和Content Body。
- 消费者接收到消息并正确消费之后,向Broker 发送确认,即Basic.Ack 命令。
- 客户端发送完消息需要关闭资源时,涉及到Channel.Close和Channl.Close-Ok 与Connetion.Close和Connection.Close-Ok的命令交互。
RabbitMQ工作模式
Work queues工作队列模式

Work Queues与入门程序的简单模式相比,多了一个或一些消费端,多个消费端共同消费同一个队列中的消息。
应用场景:对于任务过重或任务较多情况使用工作队列可以提高任务处理的速度。
生产者
public void sandWorkQueuesMethod(){
if (int i = 0; i <= 10; i++){
rabbitTemplate.convertAndSend(PublicConstants.RabbitMQExchanges.LOCALHOST_EXCHANGES_NAME, null, i+1);
}
}
消费者
多个消费者消费同一个队列的消息,可以理解为多个线程在抢同一个cpu的时间碎片,代码我就不贴了太重复了
小结
在一个队列中如果有多个消费者,那么消费者之间对于同一个消息的关系是竞争的关系。
使用默认的交换机,默认交换机的转发规则是按照队列的名称转发
工作队列模式多个消费者间存在的是 “竞争” 关系
负载均衡
发布订阅模式类型
订阅模式示例图:

前面案例中,只有3个角色:
- P:生产者,也就是要发送消息的程序
- C:消费者:消息的接受者,会一直等待消息到来。
- queue:消息队列,图中红色部分
而在订阅模型中,多了一个exchange角色,而且过程略有变化:
- P:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
- C:消费者,消息的接受者,会一直等待消息到来。
- Queue:消息队列,接收消息、缓存消息。
- Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有常见以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Publish/Subscribe发布与订阅模式

睡觉先睡觉先