1.性能测试的概念:
通过一定的手段,在多并发情况下,获取被测系统的各项性能指标, 验证被测系统在高并发下的处理能力、响应能力、稳定性等,能否满足预期。定位性能瓶颈,排查性能隐患,保障系统的质量,提升用户的体验。
2.什么样的系统需要做性能测试:
用户量大,PV比较高的系统
系统核心模块/接口
业务逻辑/算法比较复杂
促销/活动推广计划
技术选型
容量评估
新项目、新系统
3.性能测试指标
TPS/QPS 每秒处理的事务数 TPS越高,吞吐量越大,正比例关系。 TPS=1s/响应时间*并发数=并发数/响应时间
响应时间 网络传输的总时间+各组件业务处理时间

平均响应时间
TOP响应时间:将所有请求的响应时间从大到小排序,计算指定比例的请求都是小于某个时间。
tp90:90%的请求响应时间临界值,都小于它。
tp95:95%的请求响应时间临界值,都小于它。
tp99:99%的请求响应时间临界值,都小于它。
并发数/虚拟用户(Vuser):
成功率:
PV(page view)/UV(unique visitor):页面、接口的访问量/页面、接口的每日唯一访客(用户日活量)
吞吐量: 网络中上行和下行的流量综合,吞吐量代表网络的流量
总结:在系统达到瓶颈之前,TPS和并发数策划那个正比关系,和响应时间呈反比关系。
4.性能测试流程
需求调研:项目背景、测试范围、业务逻辑&数据流向、系统架构、配置信息、测试数据量、外部依赖、系统使用场景,业务比例、日常业务量、预期指标、上线时间
测试计划:项目描述、业务模型及性能指标、测试环境说明、测试资源、测试方法及场景设计原则(基准测试、单交易负载测试、混合场景测试、高可用性测试、异常场景测试、稳定性测试、其他特殊场景)、测试进度安排及测试准则
环境搭建:原则--测试机器硬件配置尽量与线上一致,系统版本与线上一致,测试环境部署线上最小单元模块,应用、中间件、数据库配置要与线上一致,其他特殊配置
数据准备:业务接口---适合数据表关系复杂的,优点:数据完整性比较好,存储过程---适合表数量少,简单,有点:速度快,脚本导入---适合数据逻辑复杂,自由度比较高,注意数据量级:测试数据+基础数据
测试脚本:选择工具、协议、参数化、关联、检查点、事物判断
压测执行:分布式执行,监控(linux、中间件、数据库),收集测试结果,数据分析,瓶颈定位
调优回归:性能调优、反复尝试、回归验证、监控工具、全链路排查、日志分析、模块隔离
5.常用工具
loadrunner---功能强大、重量级、商业软件收费
jmeter----小巧灵活、轻量级、开源
Ngrinder--平台级产品、开源
6.入门学习环境搭建(以一个web项目OA系统为例子练习)
1.安装VirtualBox,下载winXP虚拟系统快照文件(已装LR11);
2.启动VirtualBox,新建32位XP系统虚拟机--选择已有文件,设置共享文件夹E:\\share--新增固定分配位置;
3.开启虚拟机,从我的电脑-网络驱动器-共享文件里拷贝出jdk、mysql(typical-standard-密码123456)、navicat、apache-tomcat,然后在32位XP系统安装好,配置jdk环境变量,向数据库中导入oa系统sql,讲oa项目代码移动至tomcat下webapps目录下,修改 OA\WEB-INF\classes\jdbc.properties 文件中的用户名和密码,设置为 mysql 的用户名和密码;
4. 双击运行 apache-tomcat-7.0.6\bin\startup.bat
5. 在浏览器里打开 http://localhost:8080/TestOA/userAction_loginUI.action
6. 在登录页输入用户名/密码:admin/1234,即可登录成功。
7.LR三大组件
virtual user generator:脚本生成器,录制编写脚本
controller:调度压力机、场景管理、展示性能图表、监控等
analysis:对测试数据进行分析
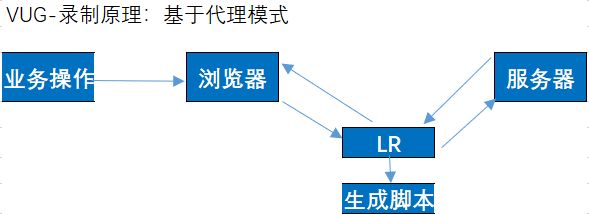
8.脚本录制和回放
新建script---options设置recording:HTML-base script--》advance脚本类型修改为第二项urls only ---advance:utf-8----开始录制。完成后回放
tools-generation options-display--勾选第一项,可展示浏览器运行过程。
9.参数化
随机数:random number,例如:编辑内容
唯一数:unique number,全局唯一,分block块儿,例如:user1-user10,长度依次取0-10%,10%-20%......默认设置start:1,block:100,那么第二个值从101开始取
文件: file.dat 最常用,例如:登录账号、id之类的
| 组合 | Sequential | Random | Unique |
| each iteration |
结果:分别将15条数据写入数据表中
功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取
如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条
|
结果:表中写入15条数据,但可能有重复数据出现
功能说明:每次从参数化文件中随机选择一行数据进行赋值
|
结果:分别将15条数据写入数据表中
功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。
注:如果设置迭代次数为16次。结果:在执行第16次迭代时会抛异常,异常日志可在LoadRunner的回放日志(replayLog)中看到
|
| each occurance |
结果:分别将15条数据写入数据表中
功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取
如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条
|
结果:表中写入15条数据,但可能有重复数据出现
功能说明:每次从参数化文件中随机选择一行数据进行赋值
|
结果:分别将15条数据写入数据表中
功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。
注:如果设置迭代次数为16次,而参数化文件中只有15条数据,明显数据不够。此时可以设置“when out of values”属性来判断当数据不够时的处理方式
Abort Vuser:中断虚拟用户
Countinue in a cylic manage:循环取参数化文件中的值,即:当参数化文件中的值取完后又从参数化文件的第一行开始取值。
Countinue with last value:继续用最后一条数据
|
| once |
结果:表中写入15条一模一样的数据。
功能说明:每次迭代都取参数化文件中第一行的数据。
|
结果:表中写入15条相同数据
功能说明:第一次迭代时随机从参数化文件中取一行数据,后面每次迭代都用第一次迭代的数据。
|
结果:表中写入15条相同数据
功能说明:每次都取参数文件中的第一条数据进行赋值
|