Openstack运维指南文档整理
本文主要译自David Stilson所著的《OpenStack Operations Guide》,目前Openstack社区官网中已经找不到该文档了,估计是内容需要更新,但其中的体系结构和运维方法的介绍十分全面,非常值得初学者学习与参考的,本文仅为个人学习Openstack过程中的内容摘录,详细内容请阅读原文,翻译不当之处在所难免,恳请各位指正。
一、体系结构
1 体系结构示例
nova-network网络架构
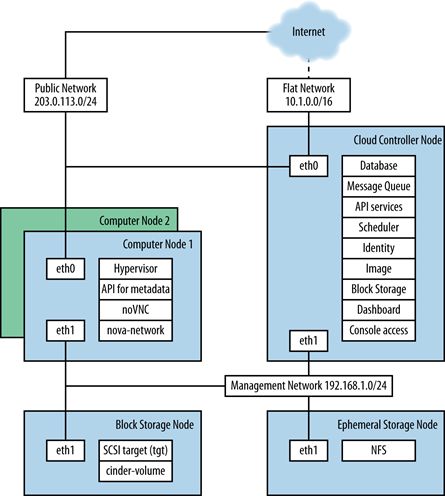

当前OpenStack网络结构
早期的开发实现
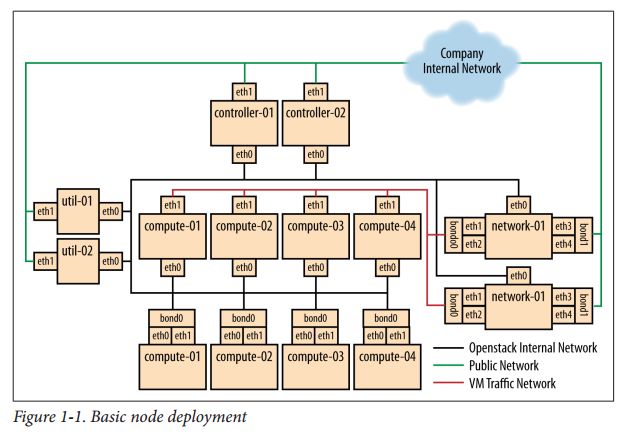
最大程度的提高网络连接的性能(引入bond双网卡绑定)
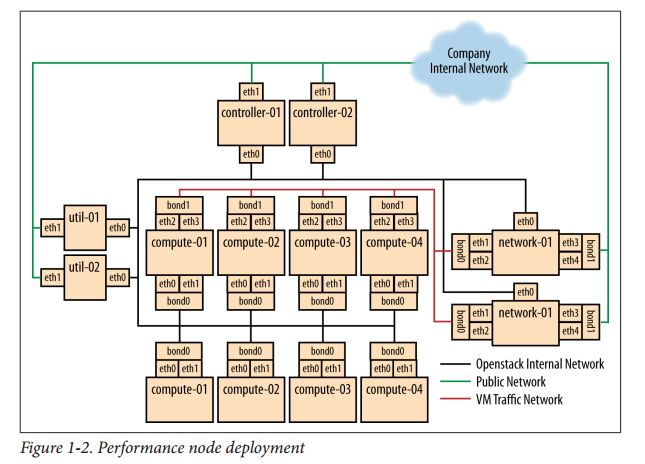
节点图
- 控制点
- 计算节点
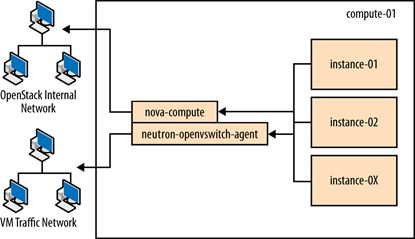
- 网络节点
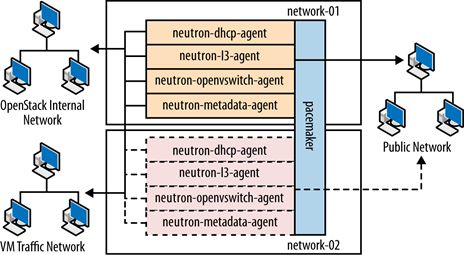
- 存储节点
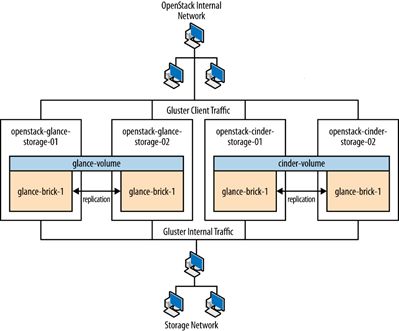
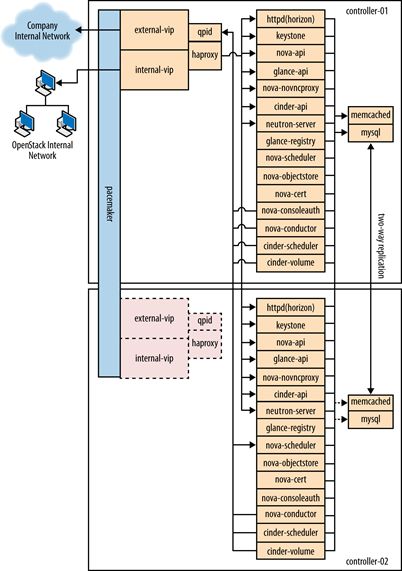
2 云控制及云管理设计
硬件选择
服务分离
数据库
消息队列
Conductor服务
API
扩展
调度
镜像
安全认证
网络注意事项
3 计算节点
计算节点通常比存储节点需要更多的内存和CPU资源。
三种常见存储
- 存储不在计算节点上-采用共享文件系统
- 优点:一旦计算节点出现故障,虚拟机通常很容易恢复;专门存储系统维护简单;盘数可伸缩;额外存储可另作他用。
- 缺点:高I/O虚拟机实例可能会影响其他无关虚拟机实例;网络的使用会降低性能。
- 适用于当可靠性和扩展性要求较高的云环境。
- 存储在计算节点上-采用共享文件系统
- 优点:当需要额外存储时能够扩展到外部存储
- 缺点:引入共享文件系统会丢失本地数据的优势;多节点上的虚拟机恢复变得复杂;计算节点机箱大小会限制上面硬盘的数目;网络的使用会降低性能。
- 适用于部署在现有的规格不大可能改变的服务器上。
- 存储在计算节点上-不采用共享文件系统
- 优点:高I/O虚拟机实例不会影响其他无关虚拟机实例;直接I/O访问可以提高性能。
- 缺点:如果计算节点失败,运行在上面的实例会丢失;计算节点机箱大小会限制上面硬盘的数目;节点间的虚拟机迁移变的复杂;扩容困难。
- 适用于高I/O但低可靠的应用场景。
热迁移
物理主机间虚拟机的无缝迁移,例如执行升级时需要重启计算节点但这只适用于共享存储。
过载使用
Openstack允许在计算节点上过载使用CPU和内存。
CPU分配比例:16:1
RAM分配比例:1.5:1
4 伸缩性
因该对面向用户的服务例如dashboard、nova-api、Object Storage proxy进行负载均衡,如利用循环复用DNS负载均衡技术、硬件负载均衡器、Pound或HAProxy软件负载均衡器等标准HTTP负载均衡方法。
硬件购买
容量规划
试机检测:CPU、Disk基准测试
5 存储选择
短暂存储
永久存储:对象存储、块存储、文件系统存储
对象存储:large datasets
块存储:永久性、
文件系统存储
二、运维
1 CLI基本操作
检查API调用
| 1 |
openstack --debug server list |
利用cURL进一步检查
| 1 2 3 |
curl -s -X POST http://203.0.113.10:35357/v2.0/tokens \ -d '{"auth": {"passwordCredentials": {"username":"test-user", "password":"test-password"}, "tenantName":"test-project"}}' \ -H "Content-type: application/json" | jq . |
查看Json响应的目录结构
| 1 2 3 |
TOKEN=`curl -s -X POST http://203.0.113.10:35357/v2.0/tokens \ -d '{"auth": {"passwordCredentials": {"username":"test-user", "password":"test-password"}, "tenantName":"test-project"}}' \ -H "Content-type: application/json" | jq -r .access.token.id` |
请求服务endpoint
| 1 2 3 |
curl -s \ -H "X-Auth-Token: $TOKEN" \ http://203.0.113.10:8774/v2.0/98333aba48e756fa8f629c83a818ad57/servers | jq . |
查看服务器
| 1 |
# openstack service list |
查看cinder返回值
| 1 |
cinder-manage host list | sort |
查看目录结构
| 1 |
# openstack catalog list |
检测计算节点
检查虚拟机
| 1 |
nova diagnostics |
网络
查看网络
| 1 |
nova network-list |
查看计算服务
| 1 |
openstack compute service list |
浮动IP查询
| 1 |
openstack ip floating list |
工程及用户查询
| 1 2 |
openstack project list openstack user list |
虚拟机查询
| 1 2 |
nova list --all-tenants nova show |
2 工程及用户管理
一组用户可以被成为project或tenant,两个术语可以互换,Openstack计算模块最初实现有其认证系统成为project,当认证系统后来被移动到Keystone时被称为tenant。
创建Project
| 1 |
openstack project create demo |
设置配额
1、设置镜像配额
在/etc/glance/glance-api.conf配置文件中[DEFAULT]标签中
| 1 |
user_storage_quota = 5368709120 |
2、设置计算服务配额
查看默认配置
| 1 |
nova quota-defaults |
设置方式
| 1 |
nova quota-class-update default key value |
例如
| 1 2 |
nova quota-class-update default --instances 15 tenant=$(openstack project list | awk '/tenantName/ {print $2}') |
查看当前设置
| 1 2 |
nova quota-show --tenant $tenant nova quota-update --quotaName quotaValue tenantID |
例如
| 1 |
nova quota-update --floating-ips 20 $tenant |
3、设置存储配额
| 1 2 |
cinder quota-defaults $tenant cinder quota-show $tenant |
用户间干扰
计算密集的用户对其他用户造成干扰,需要采取合适的方案进行隔离,例如主机聚合(host aggregation)、分区(regions)。
用户消耗大量带宽,需要限制其传送速率而避免影响其他用户,或者移动其他高带宽的区域。另外,用户虚拟机如果遭受DDOS攻击而变成僵尸网络。虽然网络上其他服务器被黑了,解决方案是一样,联系用户并给予处理时间,如果未能处理,关闭虚拟机。
如果用户反复申请云资源,联系用户并了解其目的,可能他并不知道他的操作是不合适的。或者他的请求在队列中或滞后而造成错误。
3 面向用户的操作
1、镜像操作
增加镜像
| 1 2 3 4 |
wget http://download.cirros-cloud.net/0.3.4/cirros-0.3.4-x86_64-disk.img openstack image create --file cirros-0.3.4-x86_64-disk.img \ --public --container-format bare \ --disk-format qcow2 "cirros image" |
查看帮助
| 1 |
openstack help image create |
查看镜像属性
| 1 |
openstack image show |
添加签名镜像
……
删除镜像
| 1 |
openstack image delete |
镜像服务数据库查询
| 1 2 3 4 |
mysql> select glance.images.id, glance.images.name, keystone.tenant.name, is_public from glance.images inner join keystone.tenant on glance.images.owner=keystone.tenant.id; |
| 1 |
select name, value from image_properties where id =’ fe4a4c4a-fdcd-4a64-bdf4-4203c1d439ab’; |
虚拟机元数据
| 1 |
nova show 实例名 |
虚拟机用户数据
文件注入
| 1 2 |
nova boot --image ubuntu-cloudimage --flavor 1 \ --file /root/.ssh/authorized_keys=special_authorized_keysfile authkeyinstance |
关联与移除安全组
| 1 2 |
nova add-secgroup nova remove-secgroup |
浮动IP
| 1 2 3 |
nova floating-ip-create openstack ip floating add nova remove-floating-ip |
连接块存储
| 1 |
nova volume-attach |
可以利用如下制定卷的信息
| 1 |
--block-device-mapping |
参数格式
例如启动虚拟机时同时连接块存储
| 1 2 3 |
nova boot --image 4042220e-4f5e-4398-9054-39fbd75a5dd7 \ --flavor 2 --key-name mykey --block-device-mapping vdc=13:::0 \ boot-with-vol-test |
快照
| 1 |
nova image-create |
Live Snapshots
虚拟机运行时无需中断而拍摄快照(QEMU 1.3+ and libvirt 1.0+ are used)
快照获取文件系统状态,但不会保存内存的状态,因此,为了保证数据完整,拍摄快照前需要确保:运行的程序已经将数据写入到磁盘;文件系统不存在“脏”缓存数据:程序已经发出了写磁盘命令,但操作系统尚未完成该写操作。
如果不能完成程序的写磁盘操作,需要停止这些运行的服务
拍摄快照前同步命令
Sync
仅执行sync不能保证文件系统的一致性,建议使用fsfreeze工具,它会暂停访问文件系统的新需求,创建稳定的磁盘镜像,支持ext3, ext4,和XFS文件系统,
当给块存储卷拍摄快照时,例如被客户机操作系统识别为/dev/vdb并挂载在/mnt上时,fsfreeze命令具备两个参数
-f 冻结系统
-u 解冻系统
拍摄快照前,在虚拟机中执行fsfreeze前需要挂载文件系统,
| 1 |
fsfreeze -f /mnt |
当执行fsfreeze –f时,正在执行的操作允许执行完成,新的写操作将被暂停,其他修改文件系统的操作也被暂停,最重要的是所有脏数据、元数据、日志信息要被写入到磁盘。
一旦volume被冻结,此时不允许读写该卷,所有的I/O操作将会被挂起,直到操作系统被解封。
拍摄快照完成后,执行以下命令解封
| 1 |
fsfreeze -u /mnt |
如果想备份根文件系统/,不能仅仅运行以上命令,以为会冻结系统,运行以下命令代替:
| 1 |
fsfreeze -f / && read x; fsfreeze -u / |
确保window客户机快照一致性
Window上运行了Volume Shadow Copy Service,VSS提供的框架可以使兼容的应用程序在live文件系统上一致性地备份。QEMU提供的客户机代理能够在KVM虚拟机监控程序运行虚拟机,此客户机代理能够与window VSS服务一致,保证一致性快照。至少需要QEMU 1.7,相关客户机代理命令如下:
guest-file-flush,写“脏”缓存数据到磁盘,类Linux上的sync操作。
guest-fsfreeze,暂停磁盘I/O,类Linux上fsfreeze –f操作
guest-fsfreeze-thaw,恢复磁盘I/O,类Linux上fsfreeze –u操作
4 维护、故障和调试
管理节点、存储代理的失败及维护
有计划的维护
云管理节点或存储代理维护有计划维护,如凌晨1点、2点。如果需要不间断服务,需要研究选择HA。
重启
执行reboot,重启前备份,
重启后产看服务启动情况
| 1 2 3 4 |
# ps aux | grep nova- # ps aux | grep glance- # ps aux | grep keystone # ps aux | grep cinder |
所有控制节点失败,考虑HA方案。
或者利用配置管理工具,例如Puppet,自动构建云管理节点。存在可用的备用服务器情况下,恢复不会超过15分钟。
计算节点上nova-compute服务,在长时间重启之后不总会重新连接管理节点上rabbitmq,需要重启计算节点上nova服务。
计算节点的失败及维护
OpenStack Docs: Zed Administrator Guides
计划维护
因软件或硬件升级而需要重启计算节点,需要执行以下步骤
- 取消该节点上的虚拟机创建调度
| 1 |
nova service-disable --reason maintenance c01.example.com nova-compute |
- 验证所有虚拟机实例已经从该节点转移
如果利用的共享存储
列出需要转移的实例
| 1 |
nova list --host c01.example.com --all-tenants |
依次迁移所有实例
| 1 |
nova live-migration |
如果没有利用共享存储
| 1 |
nova live-migration --block-migrate |
- 停止该节点上的计算服务
| 1 |
systemctl stop nova-compute |
- 关闭计算节点,执行维护、恢复计算节点
- 开启计算节点:systemctl start nova-compute
- 解除该节点上的虚拟机调度限制,nova service-enable c01.example.com nova-compute
重启计算节点之后
检查服务是否运行
查看AMQP
| 1 |
grep AMQP /var/log/nova/nova-compute |
列出该节点上的虚拟机实例
| 1 |
nova list --host c01.example.com --all-tenants |
可以重启该实例
| 1 |
nova reboot |
如果实例未启动,计算节点上virsh list将不会显示该实例,查看计算节点日志,
| 1 |
tail -f /var/log/nova/nova-compute.log |
再次执行nova reboot,查看错误原因
错误可能是在libvirt的XML(/etc/libvirt/qemu/instance-xxxxxxxx.xml)某项,但该文件不存在了,可以利用该文件强制重新生成该文件,
从失败的虚拟机实例上检查和恢复数据
情景:不能通过ssh访问、VNC控制台显示启动失败、内核错误信息。这些可能预示着VM冲突,如果需要恢复文件或检查实例内容,qemu-nbd可以用来挂载磁盘。
获取实例硬盘(/var/lib/nova/instances/instance-xxxxxx/disk)需要以下几步:
- 利用virsh命令挂起实例
| 1 2 |
virsh list virsh suspend 140 |
- 连接qemu-nbd设备到硬盘
| 1 2 3 |
cd /var/lib/nova/instances/instance-0000274a ls –lh qemu-nbd -c /dev/nbd0 `pwd`/disk |
Ceph作为存储后端,未找到该存储后端。
- 挂载qemu-nbd设备
| 1 2 3 4 5 |
mount /dev/nbd0p1 /mnt/ umount /mnt qemu-nbd -c /dev/nbd1 `pwd`/disk.local mount /dev/nbd1 /mnt/ ls -lh /mnt/ |
- 检查后取消挂载
| 1 |
umount /mnt |
- 断开qemu-nbd设备连接
| 1 |
qemu-nbd -d /dev/nbd0 |
- 恢复实例
| 1 |
virsh resume 30 |
如果不执行最后三步,openstack将不再能管理实例,不能执行openstack命令,并标记为关机。
管理虚拟机实例浮动IP地址
假设Public_AGILE不支持浮动IP,利用neutron ports提供一个变通方法
- 创建一个端口
| 1 |
neutron port-create Public_AGILE |
- 分配一个同名端口
| 1 2 |
neutron port-create Public_AGILE --name \ "example-fqdn-01.sys.example.com" |
- 利用端口创建实例
| 1 2 |
nova boot --flavor m1.medium --image ubuntu.qcow2 --key-name team_key \ --nic port-id=PORT_ID "example-fqdn-01.sys.example.com" |
- 验证实例
| 1 |
Openstack server show |
- 测试联通
| 1 |
nc -v -w 2 96.118.182.107 22 |
解除绑定
| 1 2 3 |
neutron port-list | grep -B1 96.118.182.107 neutron port-update 731c3b28-3753-4e63-bae3-b58a52d6ccca \ --device_id "" --device_owner "" --binding:host_id "" |
全部计算节点失败
如果节点失败,几个小时未恢复时,如果使用了共享存储可以重启实例,实例保存在/var/lib/nova/instances中。
查询元数据
| 1 2 |
mysql> select uuid from instances where host = 'c01.example.com' and deleted = 0; |
更新元数据到另一个计算节点
| 1 2 |
mysql> update instances set host = 'c02.example.com' where host = 'c01.example.com' and deleted = 0; |
如果利用了网络服务ML2插件,更新网络服务元数据声明所有端口更新到另一个计算节点
| 1 2 3 4 |
mysql> update ml2_port_bindings set host = 'c02.example.com' where host = 'c01.example.com'; mysql> update ml2_port_binding_levels set host = 'c02.example.com' where host = 'c01.example.com'; |
然后重启实例
| 1 |
nova reboot --hard |
/var/lib/nova/instances目录下说明
_base包含缓存的基础镜像
instance-xxxxxxxx目录对应不同实例
存储节点失败和管理
OpenStack Docs: Zed Administrator Guides
重启reboot
关闭节点
替换Swift盘
处理全部出现故障
优先顺序,尽量恢复对影响用户使用服务,尽管所列为单一条目,但恢复的每一步需要大量的工作。例如,启动数据库后,需要检查其完整性;启动nova服务后,需要验证hypervisor与数据库是否一致,如不一致需要修复不一致。
| Table. Example service restoration priority list | |
| Priority | Services |
| 1 | Internal network connectivity |
| 2 | Backing storage services |
| 3 | Public network connectivity for user virtual machines |
| 4 | nova-compute, nova-network, cinder hosts |
| 5 | User virtual machines |
| 10 | Message queue and database services |
| 15 | Keystone services |
| 20 | cinder-scheduler |
| 21 | Image Catalog and Delivery services |
| 22 | nova-scheduler services |
| 98 | cinder-api |
| 99 | nova-api services |
| 100 | Dashboard node |
配置管理
Openstack云需要管理大量机器,手动配置容易出错,需要利用配置管理工具,这些工具自动配置。配置工具例如Puppet、Chef、Juju, Ansible, 和Salt。
硬件处理
增加计算节点:利用自动化部署系统引导裸机服务器安装操作系统,并利用配置工具部署安装计算节点,实现自动化的云扩展。
如果块存储节点同计算节点分离开,扩展方法类同。
增加对象存储节点:利用自动化安装及部署工具,然后增加对象存储的本地磁盘到对象存储环中,然后利用相同命令增加目的磁盘到环中。
组件替换:需要考虑处理时间及节约时间
数据库
查看配置文件中连接
| 1 2 |
grep -hE "connection ?=" /etc/nova/nova.conf /etc/glance/glance-*.conf \ /etc/cinder/cinder.conf /etc/keystone/keystone.conf |
性能及优化
MySQL :: MySQL 8.0 Reference Manual :: 8.1 Optimization Overview
RabbitMQ故障排除
1、服务挂起Hang
当重启或挂起时,Rabbitmq容易挂起,需要手动重启控制节点上的RabbitMQ
| 1 2 |
# service rabbitmq-server stop # service rabbitmq-server start |
如果无法停止,利用pkill结束服务并重启
| 1 2 |
# pkill -KILL -u rabbitmq # service rabbitmq-server start |
重启后验证是否运行
| 1 2 3 |
# ps -ef | grep rabbitmq # rabbitmqctl list_queues # rabbitmqctl list_queues 2>&1 | grep -i error |
如果存在错误,运行cluster_status确保没有partitions
| 1 |
rabbitmqctl cluster_status |
重启服务,如果还存在错误,删除/var/lib/rabbitmq/mnesia/目录下内容并重启。
2、服务警告Alert
判断哪个节点发出Alert
在受影响的环境中尝试重启nova虚拟机
如果不能够启动虚拟机,继续寻找原因
登录受影响的控制节点查看日志/var/log/rabbitmq,查看日志中连接问题
检查/etc/init.d中nova*, cinder*, neutron*, 或者glance*,检查RabbitMQ消息队列,重启受影响的openstack服务。
如果在Dashboard中创建虚拟机成功,问题解决,否则检查/var/log/rabbitmq日志,重启所有控制节点上的rabbitmq服务
| 1 2 |
# service rabbitmq-server stop # service rabbitmq-server start |
然后在创建虚拟机检查日志是否还存在错误。
3、数据库管理内存过度消耗
检查内存消耗
| 1 |
rabbitmqctl status |
编辑/etc/rabbitmq/rabbitmq.config配置文件,改变参数collect_statistics_interval在30000-60000毫秒,或者关闭collect_statistics,设置其值为none。
4、扩展云时文件描述限制
执行rabbitmqctl status查看文件描述扩展,修改配置文件/etc/security/limits.conf调整至合适的值。
HDWMY
Hourly:检查预警系统并采取措施;检查ticket queue for new tickets
Daily:检查失败虚拟机或出错虚拟机,并找出原因;检查安全补丁并安装更新所需要的
Weekly:检查云使用量(用户配额、磁盘空间、镜像使用、超大实例、带宽及IP网络资源使用)、检验预警机制是否还能工作;
Monthly:检查过去几个月的使用量及趋势、检查需要移除的用户账户、检查需要移除的系统运维账户。
Quarterly:审查过去几月使用情况和趋势、准备关于使用情况的季度报告和统计、审查和规划云资源扩展、审查和计划openstack升级
Semiannually:升级、清理(不用的服务,并注意一些新的服务)
判定损坏部件
查看日志,如
| 1 |
tail -f /var/log/nova/nova-api.log |
在CLI上运行daemon
| 1 |
sudo -u glance -H glance-api |
运行缓慢时需要采取的措施
认证:可能是token表变大,可用利用keystone-manage token_flush命令修复
镜像:后端存储连接缓慢,检查存储服务是否Down掉
块存储:检查认证相关服务、后端存储、镜像、AMQP、SQL
计算服务:认证、授权、AMQP、SQL
网络服务:与物理或虚拟网络相关、namespaces不存在、DHCP daemons暂停或挂起、检查网络、AMQP、SQL
AMQP broker:MQ服务停止或者无法处理请求队列
SQL后端:加锁或长连接。
5 网络故障排除
OpenStack Docs: Zed Administrator Guides
检查网卡状态
在计算节点和运行nova-network的网络节点上,利用如下命令查看网卡的IP、VLANs、启动状态等相关信息。
利用 “ip a”检查网卡状态
# ip a
查看启动状态
| 1 2 3 4 5 6 7 8 |
# ip a | grep state 1: lo: 2: eth0: qlen 1000 3: eth1: master br100 state UP qlen 1000 4: virbr0: 5: br100: |
可以忽略virbr0的状态,它是libvirt创建的默认的网桥,不会在Openstack中使用。
(实际环境中,ovs-system、br-tun、br-int处于DOWN状态,br-ex处于UNKNOWN状态)
网络流量可视化
登录虚拟机实例中ping一个外部主机,例如Google,ping的数据包路由如下图所示。
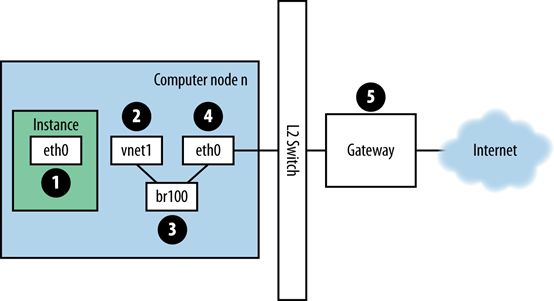
- 数据包从eth0传送至计算主机的虚拟网卡,例如vnet1,可以在该虚拟网卡被用在/etc/libvirt/qemu/instance-xxxxxxxx.xml中;
- 虚拟机实例产生数据包,并传送至虚拟机的虚拟机网卡,例如eth0;
- 数据包又从vnet1传送至计算节点的网桥上,例如br100,如果使用了FlatDHCPManager,网桥就在计算节点上,如果使用了VlanManager,网桥存在于每个VLAN上。可以执行如下命令查看网桥;
1
$ brctl show
可以查看nova.conf配置文件下flat_interface_bridge选项;
- 数据包传送至计算节点的主网卡eth0,从brctl输出中可以找到,或从conf的flat_interface可以找到;
- 但数据包达到物理网卡eth0后,会传送至计算节点的默认网关。
ping回复的路径是反方向的,可以看到,一个数据包传输经过了4个不同网卡。任何一个网卡出现问题,网络就会出现问题。
Openstack网络服务流量可视化
相比于nova-network,OpenStack网络服务更灵活,因为它具有可插拔式的后端。Openstack网络可以基于开源插件或供应商专用插件配置,可以利用Open vSwitch或Linux Bridge等Linux主机上自带设备来控制SDN硬件。
可以参考OpenStack Docs: Zed Administrator Guides 进行排错。
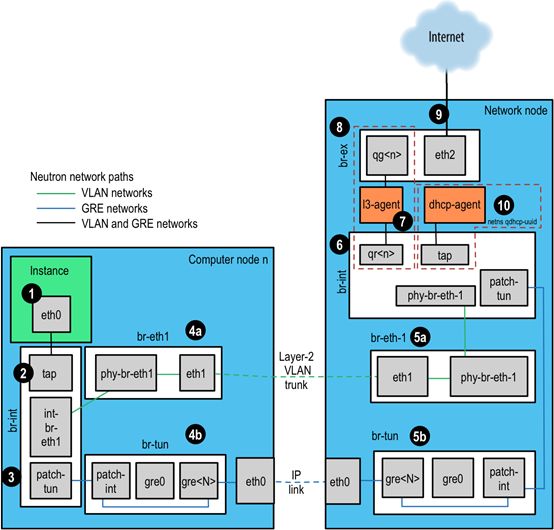
Open vSwitch (OVS)是最流行的网络部署驱动,参考neutron网络路径介绍ovs流量路径。
- 虚拟机实例产生数据包,并传送至虚拟机的虚拟机网卡,例如eth0;
- 数据包传送至计算主机上的Test Access Point (TAP)设备,例如tapf5b40a0a-65,可以在/etc/libvirt/qemu/instance-xxxxxxxx.xml文件中找到TAP的使用;
- TAP设备连接到集成网桥br-int,br-int连接所有虚拟机实例的TAP设备和系统上的其他网桥。例如此处的int-br-eth1和patch-tun,int-br-eth1是连接到网桥br-eth1虚拟接口对的一半,br-eth1处理VLAN网络,其中集成了物理设备eth1,patch-tun是一个Open vSwitch的内部端口,连接了br-tun网桥用于GRE网络;
TAP设备和虚拟机接口设备int-br-eth1、phy-br-eth1是典型的Linux网络设备,可用被ip和tcpdump等工具探测到。Open vSwitch内部设备如patch-tun,只在Open vSwitch环境中可见,如果运行tcpdump -i patch-tun会报设备不存在的错误。
数据包可以在内部接口中监测到,但需要一些网络的操作,首先需要创建一个虚拟的网络设备能够让Linux工具监测到,然后将其增加到网桥所包含的并且你想检测到的内部接口上。最后,需要通知Open vSwitch反馈检测到所有流量从内部接口到该虚拟端口。最后,你可以运行tcpdump在虚拟接口上并查看内部端口的流量。
在集成网桥br-int的patch-tun内部接口上捕获流量:
- 创建生成一个虚拟的接口snooper0
| 1 2 |
# ip link add name snooper0 type dummy # ip link set dev snooper0 up |
- 添加snooper0到br-int网桥
| 1 |
# ovs-vsctl add-port br-int snooper0 |
- 创建patch-tun 到 snooper0的镜像
| 1 2 3 4 |
# ovs-vsctl -- set Bridge br-int mirrors=@m -- --id=@snooper0 \ get Port snooper0 -- --id=@patch-tun get Port patch-tun \ -- --id=@m create Mirror name=mymirror select-dst-port=@patch-tun \ select-src-port=@patch-tun output-port=@snooper0 select_all=1 |
- 采集流量,通过运行tcpdump -i snooper0查看patch-tun上的流量;
- 清理br-int所有镜像并删除虚拟接口
| 1 2 3 |
# ovs-vsctl clear Bridge br-int mirrors # ovs-vsctl del-port br-int snooper0 # ip link delete dev snooper0 |
在集成网桥上,网络通过内部的VLANs来区分而不管网络服务如何定义他们。这允许同一台宿主机器上的虚拟机实例可以直接连接而不通过其他虚拟或物理网络。内部的VLAN IDs基于同一个节点上出现的顺序而创建,不同节点上VLAN IDs可能不同。
VLAN tags在网络设置的外部标记之间转换,内部标记出现在几个地方,在br-int,从int-br-eth1传入的数据包被从外部标记到内部标记。
通过使用ovs-ofctl发现所给的外部VLAN所使用的内部标记
- 找到所关心网络的外部VLAN标记、provider:segmentation_id即为网络服务返回值
| 1 2 3 4 5 6 7 8 |
neutron net-show --fields provider:segmentation_id +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | provider:network_type | vlan | | provider:segmentation_id | 2113 | +---------------------------+--------------------------------------+ |
- 利用ovs-ofctl dump-flows br-int:查找满足provider:segmentation_id条件的输出
| 1 2 3 4 |
# ovs-ofctl dump-flows br-int | grep vlan=2113 cookie=0x0, duration=173615.481s, table=0, n_packets=7676140, n_bytes=444818637, idle_age=0, hard_age=65534, priority=3, in_port=1,dl_vlan=2113 actions=mod_vlan_vid:7,NORMAL |
可以看到,数据包接受到了从端口ID为1的VLAN tag 2113,已经转成内部internal VLAN tag 7。更近一步查看,可以发现端口1实际上就是int-br-eth1。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# ovs-ofctl show br-int OFPT_FEATURES_REPLY (xid=0x2): dpid:000022bc45e1914b n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: OUTPUT SET_VLAN_VID SET_VLAN_PCP STRIP_VLAN SET_DL_SRC SET_DL_DST SET_NW_SRC SET_NW_DST SET_NW_TOS SET_TP_SRC SET_TP_DST ENQUEUE 1(int-br-eth1): addr:c2:72:74:7f:86:08 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 2(patch-tun): addr:fa:24:73:75:ad:cd config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 3(tap9be586e6-79): addr:fe:16:3e:e6:98:56 config: 0 state: 0 current: 10MB-FD COPPER speed: 10 Mbps now, 0 Mbps max LOCAL(br-int): addr:22:bc:45:e1:91:4b config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0 |
- 下一步决定虚拟网络是配置使用1q VLAN tags或GRE
- 基于VLAN的网络通过虚拟接口int-br-eth1推出集成网桥br-int,通过br-eth1上的phy-br-eth1到达。在这个上面的数据包包含VLAN tag,在与以上相反的过程中转成外部Tag。
| 1 2 3 4 |
# ovs-ofctl dump-flows br-eth1 | grep 2113 cookie=0x0, duration=184168.225s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=4,in_port=1,dl_vlan=7 actions=mod_vlan_vid:2113,NORMAL |
数据包此时已经携带了外部VLAN tag,并通过eth1退出物理网络。Layer2交换机的这个接口连接到必须被配置接受VLAN ID的网络流量。数据包的下一跳同样也在同一个layer-2的网络上。
- 基于GRE网络patch-tun连接到隧桥br-tun上patch-int接口,这个网桥同样包含一个对等的GRE隧道接口,一个位于计算节点上,一个位于网络节点上。端口命名从gre-1命名开始按照顺序命名。
查找该接口
| 1 2 3 4 5 6 |
# ovs-vsctl show | grep -A 3 -e Port\ \"gre- Port "gre-1" Interface "gre-1" type: gre options: {in_key=flow, local_ip="10.10.128.21", out_key=flow, remote_ip="10.10.128.16"} |
所有br-tun上的接口都在Open vSwitch内部,为了能够监控上面的流量,必须像上面br-int网桥上的patch-tun一样建立端口。
利用ovs-ofctl命令发现用于GRE tunnel上的内部VLAN tag标记。
- 寻找所感兴趣的provider:segmentation_id
| 1 2 3 4 5 6 7 |
# neutron net-show --fields provider:segmentation_id +--------------------------+-------+ | Field | Value | +--------------------------+-------+ | provider:network_type | gre | | provider:segmentation_id | 3 | +--------------------------+-------+ |
- 执行ovs-ofctl dump-flows br-tun
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# ovs-ofctl dump-flows br-tun|grep 0x3 cookie=0x0, duration=380575.724s, table=2, n_packets=1800, n_bytes=286104, priority=1,tun_id=0x3 actions=mod_vlan_vid:1,resubmit(,10) cookie=0x0, duration=715.529s, table=20, n_packets=5, n_bytes=830, hard_timeout=300,priority=1, vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:a6:48:24 actions=load:0->NXM_OF_VLAN_TCI[], load:0x3->NXM_NX_TUN_ID[],output:53 cookie=0x0, duration=193729.242s, table=21, n_packets=58761, n_bytes=2618498, dl_vlan=1 actions=strip_vlan,set_tunnel:0x3, output:4,output:58,output:56,output:11,output:12,output:47, output:13,output:48,output:49,output:44,output:43,output:45, output:46,output:30,output:31,output:29,output:28,output:26, output:27,output:24,output:25,output:32,output:19,output:21, output:59,output:60,output:57,output:6,output:5,output:20, output:18,output:17,output:16,output:15,output:14,output:7, output:9,output:8,output:53,output:10,output:3,output:2, output:38,output:37,output:39,output:40,output:34,output:23, output:36,output:35,output:22,output:42,output:41,output:54, output:52,output:51,output:50,output:55,output:33 |
- 数据包此时已经在网络节点上接收到,但去往l3-agent或dhcp-agent的任何流量只在各自的网络namespace中可见。
- 接下来,同在计算节点上的一样,数据包通过网络节点上的集成网桥;
- 数据包进入l3-agent,实际上是进入路由器网络命名空间上的TAP设备,路由器命名空间命名格式为router-
,在路由器的命名空间上执行ip a可以查看TAP设备名称,此处为qr-e6256f7d-31。
| 1 2 3 4 5 6 |
# ip netns exec qrouter-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a | grep state 10: qr-e6256f7d-31: state UNKNOWN 11: qg-35916e1f-36: qdisc pfifo_fast state UNKNOWN qlen 500 28: lo: |
- l3-agent路由器命名空间上的qg-
接口将数据包通过eth2设备发送到下一跳到br-ex外部网桥上,该网桥同br-eth1类似,可采用相同方法检查。 - 外部网桥包含物理网卡eth2,最后将数据包发送至外部路由及目的主机;
- 运行于OpenStack networks 上的DHCP agents运行在命名空间同l3-agents,其命名空间命名格式为qdhcp-
,并且有TAP设备存在与集成网桥上。DHCP的问题调试通常与网络命名空间关联。
查找网络路径上的错误
利用ping命令,如果可以ping通外网服务器,则没有问题,
如果不能ping通外网,尝试ping虚拟机所在主机IP,如果可以,问题则出在计算节点和计算节点的网关上面;
如果不能ping通所在计算节点,问题可能是虚拟机实例和计算节点,主要包括计算节点上网卡与虚拟机虚拟机网卡连接的网桥问题。
最后测试是两个虚拟机之间可否相互ping通,如果可以,问题可能与计算节点上的防火墙相关。
tcpdump
使用tcpdump是一个很好且深入的网络故障排除方法。
例如执行以下命令:
| 1 |
tcpdump -i any -n -v 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo' |
运行在如下机器上:
可用的云外的服务器上、计算节点上、运行在计算节点上的虚拟机实例上。
在虚拟机实例上ping云外服务器,查看各个服务器上的输出。外部服务器上会收到ping请求并返回ping回复。在计算节点上可以看到通过的虚拟机和外部之间的ping请求和ping回复。因为tcpdump可以捕获在网桥和输出接口之间的数据包。
iptables
通过nova-network或neutron,Openstack计算服务能够自动管理iptables,包括转发的数据包、来着计算节点上虚拟机实例的、转发的浮动IP流量和管理安全规则。执行以下命令可以查看iptables的配置
| 1 |
# iptables-save |
调试nova-network的DHCP问题(参考)
可以通过虚拟机实例的日志查看
| 1 |
$ nova console-log |
如果无法通过DHCP获取IP,错误如下,
| 1 2 3 4 5 6 7 8 9 |
udhcpc (v1.17.2) started Sending discover... Sending discover... Sending discover... No lease, forking to background starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ] cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id wget: can't connect to remote host (169.254.169.254): Network is unreachable |
如果dnsmasq进程出错,重启,然后在查看进程
| 1 2 3 |
# killall dnsmasq # restart nova-network # ps aux | grep dnsmasq |
如果仍不能获取IP,需要检查dnsmasq是否收到了虚拟机的DHCP请求,在运行dnsmasq的节点上查看/var/log/syslog检查dnsmasq的输出,如下:
| 1 2 3 4 5 6 7 |
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3 fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3 fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3 fa:16:3e:56:0b:6f test |
如果未发现DHCPDISCOVER,问题出在虚拟机到运行dnsmasq机器过程中。日志输出如下:
| 1 2 |
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100) fa:16:3e:78:44:84 no address available |
这是与dnsmasq或nova-network相关的问题。
检查dnsmasq的日志信息,并查看相应进程,输出类似下面:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# ps aux | grep dnsmasq 108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq -u libvirt-dnsmasq --strict-order --bind-interfaces --pid-file=/var/run/libvirt/network/default.pid --conf-file= --except-interface lo --listen-address 192.168.122.1 --dhcp-range 192.168.122.2,192.168.122.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases --dhcp-lease-max=253 --dhcp-no-override nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro |
上面dnsmasq进程具备DHCP子网范围为192.168.122.0,属于libvirt,可忽略。其他两个进程属于nova-network。
如果问题不出在dnsmasq上,可以利用tcpdump采集网卡流量判断数据包是否丢失。
DHCP流量利用UDP、客户端端口为68、服务器端口为67,尝试启动虚拟机并监听网卡知道未发现流量。如果监听br100上67、68端口,命令如下:
| 1 |
# tcpdump -i br100 -n port 67 or port 68 |
同时利用ip a和brctl show确保网卡已经启动并正确配置。
调试DNS问题
如果可以ssh登录虚拟机,但需要很长时间才能弹出提示符,可能是DNS的问题,之所以会是DNS的问题是因为SSH服务器在做做一个反向DNS查找在所连接的IP地址,如果机器上DNS停止工作,必须等待DNS反向查询超时出现才能继续处理SSH登录。
调试DNS的问题,首先要确定宿主机上运行dnsmasq进程并能保证虚拟机实例能够正确解析出IP,如果宿主机无法解析域名,虚拟机实例也无法解析。
宿主机上运行host命令判断DNS的是否工作:
| 1 2 3 4 |
$ host openstack.org openstack.org has address 174.143.194.225 openstack.org mail is handled by 10 mx1.emailsrvr.com. openstack.org mail is handled by 20 mx2.emailsrvr.com. |
如果运行Cirros镜像,可以运行ping命令代替,
| 1 2 |
$ ping openstack.org PING openstack.org (174.143.194.225): 56 data bytes |
在openstack云中,dnsmasq进程作为虚拟机实例的DNS服务器和DHCP服务器,如果该进程出现问题会影响虚拟机实例相关的问题,可以重启dnsmasq进程和nova-network,但会影响未出该问题的其他租户,
| 1 2 |
# killall dnsmasq # restart nova-network |
如果问题尚未修复,需要利用tcpdump采集数据包查看失败原因,DNS服务器监听UDP 53端口,需要查看计算节点网桥上的DNS请求,例如
| 1 2 |
# tcpdump -i br100 -n -v udp port 53 tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes |
此时,SSH到虚拟机,执行ping openstack.org命令,可以看到tcpdump如下输出:
| 1 2 3 4 5 6 7 |
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF], proto UDP (17), length 59) 192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31) 16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 75) 192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A 174.143.194.225 (47) |
Open vSwitch故障排除
按照前面的实例,Open vSwitch通常问题会出现在br-int、br-tun和br-ex等网桥或者连接的端口上面。尽管Open vSwitch驱动可以自动管理,但手动执行ovs-vsctl命令十分有用。
在计算节点上执行ovs-vsctl list-br可以列出系统上的网桥。
| 1 2 3 4 |
# ovs-vsctl list-br br-int br-tun eth1-br |
查看内部物理端口,例如网桥eth1-br,包含物理网卡eth1和虚拟接口phy-eth1-br:
| 1 2 3 |
# ovs-vsctl list-ports eth1-br eth1 phy-eth1-br |
类似可以查看其他网桥端口br-int、br-tun,如果这些连接丢失或者错误,预示着配置错误,网桥可以通过ovs-vsctl add-br来进行添加,端口可以通过ovs-vsctl add-port进行添加。
网络命名空间的处理
Linux网络命名空间具备内核功能,网络服务利用overlapping IP地址范围用于支持多个隔离的l2网络,该功能可以关闭,但默认开启。如果开启,网络节点将在隔离命名空间中运行dhcp-agents和l3-agents。在这些接口上的网卡和流量将在默认命名空间上不可见。
执行ip netns查看是否使用网络命名空间:
| 1 2 3 4 5 6 |
# ip netns qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 qdhcp-a4d00c60-f005-400e-a24c-1bf8b8308f98 qdhcp-fe178706-9942-4600-9224-b2ae7c61db71 qdhcp-0a1d0a27-cffa-4de3-92c5-9d3fd3f2e74d qrouter-8a4ce760-ab55-4f2f-8ec5-a2e858ce0d39 |
L3-agent路由器命名空间命名为qrouter-
可以利用ip netns exec
| 1 2 3 4 5 6 7 8 9 10 11 12 |
# ip netns exec qdhcp-e521f9d0-a1bd-4ff4-bc81-78a60dd88fe5 ip a 10: tape6256f7d-31: link/ether fa:16:3e:aa:f7:a1 brd ff:ff:ff:ff:ff:ff inet 10.0.1.100/24 brd 10.0.1.255 scope global tape6256f7d-31 inet 169.254.169.254/16 brd 169.254.255.255 scope global tape6256f7d-31 inet6 fe80::f816:3eff:feaa:f7a1/64 scope link valid_lft forever preferred_lft forever 28: lo: link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever |
可以看到DHCP服务器上利用tape6256f7d-31设备且IP为10.0.1.100,通过169.254.169.254不难看出dhcp-agent运行着metadata-proxy服务。
6 日志
日志保存位置
| Node type | Service | Log location |
| Cloud controller | nova-* | /var/log/nova |
| Cloud controller | glance-* | /var/log/glance |
| Cloud controller | cinder-* | /var/log/cinder |
| Cloud controller | keystone-* | /var/log/keystone |
| Cloud controller | neutron-* | /var/log/neutron |
| Cloud controller | horizon | /var/log/apache2/ |
| All nodes | misc (swift, dnsmasq) | /var/log/syslog |
| Compute nodes | libvirt | /var/log/libvirt/libvirtd.log |
| Compute nodes | Console (boot up messages) for VM instances: | /var/lib/nova/instances/instance- |
| Block Storage nodes | cinder-volume | /var/log/cinder/cinder-volume.log |
日志阅读
Openstack服务运用标准的日志级别,按照严重程度递增为:DEBUG, INFO, AUDIT, WARNING, ERROR, CRITICAL和TRACE。
禁用DEBUG级别,例如编辑/etc/nova/nova.conf文件
| 1 |
debug=false |
Keystone略有不同,修改日志级别,编辑/etc/keystone/logging.conf的logger_root 和handler_file部分。
Horizon日志在/etc/openstack_dashboard/local_settings.py中配置,因为horizon采用了Django Web框架,参考 Django Logging framework conventions.
排除错误的首要步骤就是找到日志中CRITICAL, TRACE和ERROR等信息输出。
例如:
2013-02-25 20:26:33 6619 ERROR nova.openstack.common.rpc.common [-] AMQP server on localhost:5672 is unreachable:
[Errno 111] ECONNREFUSED. Trying again in 23 seconds.
跟踪虚拟机实例请求
如果虚拟机实例发生错误,需要跟踪控制节点和计算节点上nova-*服务日志中有关虚拟机中的部分。典型方法是查找服务日志中与UUID相关的部分,虚拟机实例的UUID可以通过以下查询:
| 1 |
$ nova list |
查看/var/log/nova-*.log文件,如控制节点上的nova-api.log和nova-scheduler.log文件,计算节点上的nova-network.log和nova-compute.log文件。如果没有ERROR或CRITICAL出现,新增的日志内容会提供问题的线索。
添加自定义的日志记录语句
如果日志信息不足,需要在nova-*服务中增加自定义的日志记录。源文件在/usr/lib/python2.7/dist-packages/nova处。为了增加日志语句,文件首部需要增加如下文件,大多数文件中已经存在,
| 1 2 |
from nova.openstack.common import log as logging LOG = logging.getLogger(__name__) |
增加调试级别语句如下:
| 1 |
LOG.debug("This is a custom debugging statement") |
可能会发现所有现存日志之前都在下划线和括号包围,例如
| 1 |
LOG.debug(_("Logging statement appears here")) |
这个格式是利用gettext 国际化的类库支持将日志消息翻译成不同的语言,
RabbitMQ Web管理接口或rabbitmqctl
RabbitMQ日志文件对于调试Openstack相关问题作用不大,建议采用RabbitMQ web 管理接口作为代替,在管理节点上开启如下:
| 1 2 |
# /usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_management # service rabbitmq-server restart |
RabbitMQ Web管理接口可以通过控制节点的http://localhost:55672访问。
除了应用RabbitMQ web管理接口之外,运行rabbitmqctl命令也可以作为替代。例如,rabbitmqctl list_queues| grep cinder显示队列中关于cinder的信息。如果存在消息,可能预示着cinder服务没有合适的连接rabbitmq,可能需要进行重启。
RabbitMQ的监控包括队列长度数量、服务器处理时间长度。
日志的集中管理
云有诸多机器组成,需要检查每台机器上的日志片段,一个比较好的方案是将所有节点上的日志发送到一个集中的位置,方便访问。
同日志工具的组织要求一样,集中日志引擎的选择也将独立于所使用的操作系统。
对于系统日志的选择,有许多系统日志引擎可选,每种都有不同的特点及配置要求,如
rsyslog。它可以发送日志到远程位置,并且无需安装额外组件而只需修改配置文件即可,可以考虑在管理网上面运行日志传输,或者使用加密VPN而避免窃听。
rsyslog客户端配置
首先,除了Openstack的标准位置外,配置所有的OpenStack组件记录日志到syslog日志文件。同时,配置每个组件记录到不同的系统日志设备中,这样更容易分拆日志到中心服务器的独立组件中。配置如下:
nova.conf:
| 1 2 3 4 5 6 7 8 9 10 11 |
use_syslog=True syslog_log_facility=LOG_LOCAL0 glance-api.conf和glance-registry.conf: use_syslog=True syslog_log_facility=LOG_LOCAL1 cinder.conf: use_syslog=True syslog_log_facility=LOG_LOCAL2 keystone.conf: use_syslog=True syslog_log_facility=LOG_LOCAL3 |
默认的,对象存储记录到syslog中。
接下来,创建/etc/rsyslog.d/client.conf,追加以下内容:
| 1 |
*.* @192.168.1.10 |
以上指明所有日志发往的主机。
rsyslog服务器的配置
指定一个服务器作为中心日志服务器,最好是选择一个仅用于记录日志目的的服务器。创建/etc/rsyslog.d/server.conf,内容如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Enable UDP $ModLoad imudp # Listen on 192.168.1.10 only $UDPServerAddress 192.168.1.10 # Port 514 $UDPServerRun 514 # Create logging templates for nova $template NovaFile,"/var/log/rsyslog/%HOSTNAME%/nova.log" $template NovaAll,"/var/log/rsyslog/nova.log" # Log everything else to syslog.log $template DynFile,"/var/log/rsyslog/%HOSTNAME%/syslog.log" *.* ?DynFile # Log various openstack components to their own individual file local0.* ?NovaFile local0.* ?NovaAll & ~ |
以上配置能够将每个计算节点上日志文件分隔开,并且能够聚合所有节点上的nova日志文件。
7 监控
监控概述
监控分为故障监控和使用量趋势监控。前者确保所有服务启动、运行、并创建一个功能性的云平台;后者包括监控过去时间内资源的使用量,主要用于潜在瓶颈和升级决策提供信息服务。
Nagios是一种开源的监控服务。它能够执行任意的命令用于检验服务器和网络服务的状态,具备直接在服务器上远程执行命令、运行服务器基于被动监控的方式推送通知。自从1999年以来,Nagios被广泛应用,尽管新的监控服务不断出现,Nagios仍是一个行之有效的系统管理产品。
进程监控
基本监控仅仅是检查服务进程是否运行,例如,检查控制节点上的nova-api服务是否进行,如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
# ps aux | grep nova-api nova 12786 0.0 0.0 37952 1312 ? Ss Feb11 0:00 su -s /bin/sh -c exec nova-api --config-file=/etc/nova/nova.conf nova nova 12787 0.0 0.1 135764 57400 ? S Feb11 0:01 /usr/bin/python /usr/bin/nova-api --config-file=/etc/nova/nova.conf nova 12792 0.0 0.0 96052 22856 ? S Feb11 0:01 /usr/bin/python /usr/bin/nova-api --config-file=/etc/nova/nova.conf nova 12793 0.0 0.3 290688 115516 ? S Feb11 1:23 /usr/bin/python /usr/bin/nova-api --config-file=/etc/nova/nova.conf nova 12794 0.0 0.2 248636 77068 ? S Feb11 0:04 /usr/bin/python /usr/bin/nova-api --config-file=/etc/nova/nova.conf root 24121 0.0 0.0 11688 912 pts/5 S+ 13:07 0:00 grep nova-api |
可以通过Nagios and NRPE创建关键进程的自动警告,例如,确保计算节点上nova-compute进程是否运行,在Nagios服务器上创建警告如下:
| 1 2 3 4 5 6 7 8 |
define service { host_name c01.example.com check_command check_nrpe_1arg!check_nova-compute use generic-service notification_period 24x7 contact_groups sysadmins service_description nova-compute } |
然后在实际的计算节点上,创建如下的NRPE配置:
| 1 |
\command[check_nova-compute]=/usr/lib/nagios/plugins/check_procs -c 1: -a nova-compute |
Nagios无论何时总会检查至少有一个nova-compute在运行。
资源告警
资源告警是当一个或多个资源极低时提供通告功能。针对特定的云环境需要设定合适的监控阈值,资源使用量告警不仅限于Openstack,任何通用类型都可以。
监控资源包括:
-> 硬盘使用量
-> 服务器负载
-> 内存使用量
-> 网络I/O
-> 可用的vCPUs
例如,利用Nagios监控计算节点上的磁盘使用量,Nagios配置如下:
| 1 2 3 4 5 6 7 |
define service { host_name c01.example.com check_command check_nrpe!check_all_disks!20% 10% use generic-service contact_groups sysadmins service_description Disk } |
在计算节点上,NRPE配置如下:
| 1 |
command[check_all_disks]=/usr/lib/nagios/plugins/check_disk -w $ARG1$ -c $ARG2$ -e |
Nagios会在计算节点上磁盘使用量超过80%时发出WARNING警告,超过90%时发出CRITICAL警告。
StackTach
StackTach是一个用于收集和报告nova服务所发送通知的工具。通知与日志同等重要,但更具体。当重大事件发生时,几乎所有的Openstack组件都能产生通知。通知是放置于可供下游系统消费的Openstack队列之中的消息。
配置nova.conf,使得nova能够发送通知:
| 1 2 |
notification_topics=monitor notification_driver=messagingv2 |
一旦nova开始发送通知,例如安装配置StackTach,消耗队列的StackTach workers被配置用于读取RabbitMQ通知并保存与数据库中,用户就可以通过浏览器接口或命令行工具(如Stacky)查询实例,请求和服务器。因为StackTach比较新且一直在变化,安装说明很快就会过时,具体可参考官网http://stacktach.com/。
Logstash
Logstash是一个高性能的日志索引和查询引擎。它可以审阅用一个简单test审阅多源日志,查找错误和事件,查找日志事件趋势。具备4个主要层次,
- -> Log Pusher
- -> Log Indexer
- -> ElasticSearch
- -> Kibana
每层都可以水平扩展,当日志数增加时,可以增加更多的Log Pusher、Log Indexer、ElasticSearch节点。
OpenStack Telemetry
Telemetry服务的数据收集服务可以用于计费。根据部署配置,收集的数据可以被用户获取得到。提供Restful API。
OpenStack特定资源
内存、磁盘、CPU这些通用资源对于所有服务都很重要,针对Openstack而言,这些资源重要性也体现在确保足够的资源创建虚拟机上。可以利用如下命令查看Openstack资源使用量:
例如:
| 1 |
# nova usage-list |
此命令可以显示每个租户运行了多少个实例,并基于所有实例的统计数据。此命令可以快速浏览云中使用情况,但不具备更多细节。
接下来,nova数据库中包含了具有存储使用量的三个表。nova.quotas、nova.quota_usages存储配额信息,租户配额不同于默认配额,它存储与nova.quotas表中:
| 1 |
mysql> select project_id, resource, hard_limit from quotas; |
nova.quota_usages表中存储了多少个资源在被当前租户使用。
| 1 |
mysql> select project_id, resource, in_use from quota_usages where project_id like '628%'; |
对比,当前用户使用量与配额限制,可查看使用量。利用利用SQL或者脚本定制。例如
novac/novac-quota-report at dev · cybera/novac · GitHub。
智能告警
智能告警可以作为运维的一种持续集成方式。例如,可以简单地通过判断glance-api或glance-registry进程是否运行、或查看glace-api端口9292是否有响应来检查镜像服务是否启动并运行。
但如何判断镜像是否能够成功上传到镜像服务?可能运行镜像服务所在的硬盘已经满了或者S3服务后端已经不再运行了,这时自然需要检查镜像的上传,如下:
| 1 2 3 4 5 6 7 |
#!/bin/bash # assumes that reasonable credentials have been stored at # /root/auth . /root/openrc wget http://download.cirros-cloud.net/0.3.4/cirros-0.3.4-x86_64-disk.img glance image-create --name='cirros image' --is-public=true --container-format=bare --disk-format=qcow2 < cirros-0.3.4-x86_64-disk.img |
将这个脚本集成到预警系统如Nagios中,可以形成一种自动检测镜像上传至镜像目录的方法。
智能预警需要花费相当多的时间来计划和实现上述方法,实现智能预警的大概提纲如下:
- -> 回顾云中一些经常性的操作
- -> 创建这些操作的自动测试方法
- -> 将测试方法集成到预警系统中
其他一些智能预警包括:
- -> 实例创建与销毁
- -> 用户创建
- -> 对象创建与销毁
- -> 卷的创建并销毁
趋势分析
趋势分析可以很好的预见云的日常状态,例如,如果着手开始增加计算节点那么云的忙等待就很少发生。
趋势分析与告警略微不同,预警只有成功或失败的两个结果,但确实分析需要记录特定时间点上的当前状态,一旦记录的足够的时间点,就可以看到过去一段时间的变化值。
一些趋势情况包括:
- -> 每个计算节点上的实例数
- -> 正在使用的虚拟机类型
- -> 正在使用卷的数目
- -> 每小时对象存储请求数
- -> 每小时nova-api请求数
- -> 存储服务的I/O统计数目
例如,记录nova-api使用量追踪扩展控制节点的需求,留意nova-api的请求数,可以决定是否需要增加更多的nova-api进程数或引入新节点来运行nova-api。为了获取大概的请求数,可以统计/var/log/nova/nova-api.log中的INFO数目,如:
| 1 |
# grep “INFO” /var/log/nova/nova-api.log | wc |
通过进一步获取成功的请求数:
| 1 |
# grep " 200 " /var/log/nova/nova-api.log | wc |
周期性的运行该命令并记录该结果,可以创建过去一段时间的趋势报告用于显示nova-api使用的变化。
collectd工具可以存储该信息,参见collectd’s documentation。
8 备份与故障恢复
参考:OpenStack Docs: Zed Administrator Guides
备份频率关乎丢失数据恢复的速度。如果不容许有任何的数据丢失,参考高可用部署,OpenStack High Availability Guide 提供了减少单点故障的解决方案。其他的备份情况应该包括:
- -> 保持多少的备份
- -> 是否需要现场备份
- -> 备份频率
此处只介绍备份Openstack组件运行时所需的配置文件和数据库,不涉及对象存储中对象或块存储中的数据备份。通常这个部分留给用户自己备份。
数据库备份
Openstack的数据包含nova、glance、cinder、keystone等数据库实例,将所有数据库实例备份到同一个文件中如下:
| 1 |
mysqldump --opt --all-databases -uroot -h 192.168.100.201 -p123456 > openstack.sql |
单独备份一个数据库实例,如下:
| 1 |
mysqldump -uroot -h 192.168.100.201 -p123456 --opt nova > nova.sql |
每天备份的脚本,如下:
| 1 2 3 4 5 6 7 |
#!/bin/bash backup_dir="/var/lib/backups/mysql" filename="${backup_dir}/mysql-`hostname`-`eval date +%Y%m%d`.sql.gz" # Dump the entire MySQL database /usr/bin/mysqldump --opt --all-databases | gzip > $filename # Delete backups older than 7 days find $backup_dir -ctime +7 -type f -delete |
该脚本备份整个数据库并删除超过三天的备份。
文件系统的备份
Compute
管理节点和计算节点上的/etc/nova目录需要定期备份。
/var/log/nova目录如果使用了中心化管理日志方法就无需备份,强烈建议使用中心化日志服务器或备份日志目录。
/var/lib/nova是另一个重要的备份目录,但计算节点上的/var/lib/nova/instances子目录例外,因为该目录包含了运行虚拟机的KVM镜像。当需要备份虚拟机副本才需要备份该目录,但大多数情况下不需要备份。应该注意到,备份一个正在运行的虚拟机实例,可能会导致从备份中恢复的虚拟机实例无法启动。
Image Catalog and Delivery
Glance与nova相对应的目录是/etc/glance and /var/log/glance。
/var/lib/glance应该被备份,特别注意/var/lib/glance/images,如果利用基于文件的glance后端,/var/lib/glance/images是存储镜像的位置应该考虑备份。
存在两种方法保证该目录的稳定性,第一种是确保该目录运行在RAID磁盘阵列中,如果一个磁盘损坏,目录仍可用;另一个方法是运用工具同步或复制镜像到另外服务器上。如下:
| 1 |
# rsync -az --progress /var/lib/glance/images backup-server:/var/lib/glance/images/ |
Identity
/etc/keystone和/var/log/keystone与以上组件对应。
/var/lib/keystone尽管不包含所使用的数据,但以防万一仍需备份。
Block Storage
/etc/cinder和/var/log/cinder与以上组件对应。
/var/lib/cinder也应该需要备份。
Object Storage
/etc/swift十分重要,需要备份。该目录包含配置文件、Ring文件和Ring生成器文件。一旦丢失,会导致集群上数据无法获取。最好的方法是复制Ring生成器文件和Ring文件到所有的存储节点。多副本备份同样适用于存储集群。
Telemetry
备份包含配置文件的/etc/ceilometer目录。
Orchestration
备份HOT模板yaml文件和/etc/heat/目录。
备份恢复
备份恢复相当简单。首先,确保所要恢复的服务不再运行。例如,如果要恢复nova服务,首先关掉所有的nova服务:
| 1 |
# systemctl stop openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-conductor.service openstack-nova-novncproxy.service |
然后导入先前备份的数据库
| 1 |
# mysql nova < nova.sql |
然后恢复nova后端目录
| 1 2 |
# mv /etc/nova{,.orig} # cp -a /path/to/backup/nova /etc/ |
一旦文件恢复后,启动nova所有服务。
| 1 |
# systemctl start openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-conductor.service openstack-nova-novncproxy.service |
9 定制化
创建Openstack开发环境
定制Swift中间件
定制Nova调度器
定制Dashboard
10高级配置
……
11 升级
升级前需要考虑的事情
升级计划
- -> 检查发布说明 release notes,了解新版本的新的、更新的、过时的特点。找到不同版本间的不兼容性。
- -> 考虑新升级对用户的影响。升级过程会中断包括dashboard在内的管理环境。如果准备升级,现存虚拟机实例、网络、或存储将继续运转,但实例可能会经历间歇性地网络中断。
- -> 考虑云环境的升级方法。如果运行实例时进行升级,那可能发生危险。应考虑利用live migration方法将虚拟机临时迁移到其他计算节点上。但要确保这个过程中数据库的一致性。否则环境会变得不可靠。同时需要周知用户,留给他们足够的备份时间。
- -> 考虑采用的结构和配置文件选项,并将现存的配置文件进行合并。 OpenStack Configuration Reference 包含但多数新的、更新的和过时等大多数服务的配置选项。
- -> 正如其他主系统升级一样,升级可能会由于种种原因而失败。出现此情景时,确保能够恢复到先前版本。包括数据库、配置文件和软件包。参考下面的环境回滚操作。
- -> 开发一个升级流程并利用与真实环境相似的实验环境彻底评估。
升级前的测试环境
最重要的是升级前的测试。发布新版本后计划立即升级,未发现的漏洞会妨碍升级进程。一些开发者倾向于等到第一次单点发行宣布后再升级。然而,如果有很重要的部署,可能首先需要进行部署和测试发布版,确保用例可以被修复。
尽管存在几乎一样的结构,但每个云环境都是不同的,你必须利用近乎克隆当前的环境来测试不同的版本。这并非说采用相同规格和同等的硬件作为生产环境,重点是考虑考虑所升级环境的硬件和规模,以下给出减少成本的建议:
- -> 运用自己的云环境:利用自己的Openstack环境搭建测试环境,尽管可能比较奇怪,特别是在计算节点上实现双虚拟化,但这确实是一个快速测试配置的方法;
- -> 运用公有云:利用公有云测试自己搭建云环境的控制节点的扩展能力,因为大多数公有云按照小时收费,这意味着利用多个节点进行测试却相当廉价。
- -> 确保相同系统上具有另外的存储端点endpoint:如果利用了外部存储和共享文件系统,可以通过创建第二个共享或挂载点endpoint来测试其是否工作。这允许在新版本接管云存储前测试该系统。
- -> 监控网络:即使在小规模的测试中,检查过剩数据包情况用于检测组件间通信发生的可怕错误。
安装测试环境时,可以利用以下的一种方法:
- -> 参考安装文档,完全的手动安装,检查最后的安装包和配置文件。
- -> 创建软件包仓库的URLs创建自动配置框架的克隆()
强烈建议备份数据库,并利用这些备份数据测试升级后的版本。因为一些MYSQL的bugs由于数据库表版本的不同而未发现。这可能会影响真实的大数据集。
人工测试存在局限性,升级后需要检查云的性能。
升级级别
一般升级流程
特殊的升级说明
Upgrading the Networking service
前提
- -> 升级前清理环境确保状态一致
- -> 网络采用OpenStack Networking service (neutron),需要检查数据的版本,例如:
-
1
2
# su -s /bin/sh -c "neutron-db-manage --config-file /etc/neutron/neutron.conf \
--config-file /etc/neutron/plugins/ml2/ml2_conf.ini current" neutron
执行备份
- 保存各节点的配置文件。例如
| 1 2 3 4 5 6 |
# for i in keystone glance nova neutron openstack-dashboard cinder heat ceilometer; \ do mkdir $i-kilo; \ done # for i in keystone glance nova neutron openstack-dashboard cinder heat ceilometer; \ do cp -r /etc/$i/* $i-kilo/; \ done |
- 备份数据库。例如:
| 1 |
mysqldump -u root -p --opt --add-drop-database --all-databases > icehouse-db-backup.sql |
管理软件仓库
在所有计算节点上,
清除先前的软件发布包;
增加新的发布包;
更新软件仓库的数据库。
升级每个节点上的软件包
如果软件包管理器提示更新配置文件,拒绝发生改变。包管理器会在新版本配置文件前增加后缀用于区分。
升级服务
在每个节点上更新服务,通常会修改一个或多个配置文件,首先要停止服务,同步数据库schema,开启服务。一些服务需要不同的步骤,建议在升级下个服务前验证操作。
升级服务的顺序和升级服务改变描述如下:
控制节点
- 认证服务:同步数据库前清除过期的tokens;
- 镜像服务;
- 计算服务,包括网络组件;
- 网络服务;
- 块存储;
- Dashboard:在一般情况下,升级此项需要重启Apache HTTP服务;
- Orchestration服务;
- Telemetry服务;一般情况下,只需重启该服务即可。
- 计算服务:编辑配置文件,重启该服务;
- 网络服务:编辑配置文件,重启该服务。
存储节点
块存储服务:升级该服务,只需要重启该服务;
计算节点
网络服务:编辑配置文件,重启该服务。
最后步骤
所有版本升级时需要执行以下操作完成升级过程:
- 修改/etc/nova/nova.conf配置减少DHCP超时时长至最初环境原始值;
- 更新所有Openstack集群所需的.ini文件的密码和pipelines;
- 迁移后,通过nova image-list和glance image-list可以看到不同的结果,为了确保一致,修改/etc/glance/policy.json和/etc/nova/policy.json文件包含”context_is_admin”: “role:admin”条目,这能够保证限制获得私有镜像;
- 检查环境能够正常运行,及时通知用户云环境可以正常运行。
失败时回滚
回滚操作主要包括:恢复配置文件、恢复数据库、恢复软件包。
以Ubuntu介绍回滚操作,其他版本同样适用:
执行回滚
- 停止所有Openstack服务;
- 拷贝备份的配置文件目录到/etc/
目录; - 从备份数据恢复数据库:
| 1 |
# mysql -u root -p < RELEASE_NAME-db-backup.sql |
- OpenStack安装包的降级带原来安装包:
- 决定所需安装的Openstack安装包。利用dpkg –get-selections,过滤Openstack安装包,并限定deinstall状态,将最终结果保存至文件。例如,以下命令是包含控制节点上的keystone、glance、nova、neutron和cinder服务。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# dpkg --get-selections | grep -e keystone -e glance -e nova -e neutron \ -e cinder | grep -v deinstall | tee openstack-selections cinder-api install cinder-common install cinder-scheduler install cinder-volume install glance install glance-api install glance-common install glance-registry install neutron-common install neutron-dhcp-agent install neutron-l3-agent install neutron-lbaas-agent install neutron-metadata-agent install neutron-plugin-openvswitch install neutron-plugin-openvswitch-agent install neutron-server install nova-api install nova-cert install nova-common install nova-conductor install nova-consoleauth install nova-novncproxy install nova-objectstore install nova-scheduler install python-cinder install python-cinderclient install python-glance install python-glanceclient install python-keystone install python-keystoneclient install python-neutron install python-neutronclient install python-nova install python-novaclient install |
- 利用apt-cache policy命令决定恢复的软件包版本。如果删除了这些软件库,首先需要重装他们并运行apt-get update。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# apt-cache policy nova-common nova-common: Installed: 1:2013.2-0ubuntu1~cloud0 Candidate: 1:2013.2-0ubuntu1~cloud0 Version table: *** 1:2013.2-0ubuntu1~cloud0 0 500 http://ubuntu-cloud.archive.canonical.com/ubuntu/ precise-updates/havana/main amd64 Packages 100 /var/lib/dpkg/status 1:2013.1.4-0ubuntu1~cloud0 0 500 http://ubuntu-cloud.archive.canonical.com/ubuntu/ precise-updates/grizzly/main amd64 Packages 2012.1.3+stable-20130423-e52e6912-0ubuntu1.2 0 500 http://us.archive.ubuntu.com/ubuntu/ precise-updates/main amd64 Packages 500 http://security.ubuntu.com/ubuntu/ precise-security/main amd64 Packages 2012.1-0ubuntu2 0 500 http://us.archive.ubuntu.com/ubuntu/ precise/main amd64 Packages |
这会提示安装包的当前版本,最新的候选版本,除了软件仓库以外的其他所有版本。选择合适的版本,例如1:2013.1.4-0ubuntu1~cloud0,从冗长列表中手动挑选版本会很费时,考虑利用以下脚本进行处理:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# for i in `cut -f 1 openstack-selections | sed 's/neutron/quantum/;'`; do echo -n $i ;apt-cache policy $i | grep -B 1 grizzly | grep -v Packages | awk '{print "="$1}';done | tr '\n' ' ' | tee openstack-grizzly-versions cinder-api=1:2013.1.4-0ubuntu1~cloud0 cinder-common=1:2013.1.4-0ubuntu1~cloud0 cinder-scheduler=1:2013.1.4-0ubuntu1~cloud0 cinder-volume=1:2013.1.4-0ubuntu1~cloud0 glance=1:2013.1.4-0ubuntu1~cloud0 glance-api=1:2013.1.4-0ubuntu1~cloud0 glance-common=1:2013.1.4-0ubuntu1~cloud0 glance-registry=1:2013.1.4-0ubuntu1~cloud0 quantum-common=1:2013.1.4-0ubuntu1~cloud0 quantum-dhcp-agent=1:2013.1.4-0ubuntu1~cloud0 quantum-l3-agent=1:2013.1.4-0ubuntu1~cloud0 quantum-lbaas-agent=1:2013.1.4-0ubuntu1~cloud0 quantum-metadata-agent=1:2013.1.4-0ubuntu1~cloud0 quantum-plugin-openvswitch=1:2013.1.4-0ubuntu1~cloud0 quantum-plugin-openvswitch-agent=1:2013.1.4-0ubuntu1~cloud0 quantum-server=1:2013.1.4-0ubuntu1~cloud0 nova-api=1:2013.1.4-0ubuntu1~cloud0 nova-cert=1:2013.1.4-0ubuntu1~cloud0 nova-common=1:2013.1.4-0ubuntu1~cloud0 nova-conductor=1:2013.1.4-0ubuntu1~cloud0 nova-consoleauth=1:2013.1.4-0ubuntu1~cloud0 nova-novncproxy=1:2013.1.4-0ubuntu1~cloud0 nova-objectstore=1:2013.1.4-0ubuntu1~cloud0 nova-scheduler=1:2013.1.4-0ubuntu1~cloud0 python-cinder=1:2013.1.4-0ubuntu1~cloud0 python-cinderclient=1:1.0.3-0ubuntu1~cloud0 python-glance=1:2013.1.4-0ubuntu1~cloud0 python-glanceclient=1:0.9.0-0ubuntu1.2~cloud0 python-quantum=1:2013.1.4-0ubuntu1~cloud0 python-quantumclient=1:2.2.0-0ubuntu1~cloud0 python-nova=1:2013.1.4-0ubuntu1~cloud0 python-novaclient=1:2.13.0-0ubuntu1~cloud0 |
- 利用apt-get install命令安装每个安装包指定的版本,先前的脚本会顺便创建package=version键值对:
| 1 |
# apt-get install `cat openstack-grizzly-versions` |
此操作会完成回滚操作,当解决掉了所有妨碍升级的问题之后,应移除升级的软件仓库避免因运行apt-get update而导致意外升级。