强化学习-赵世钰(二):贝尔曼/Bellman方程【用于计算给定π下的State Value:①线性方程组法、②迭代法】、Action Value【根据状态值求解得到;用来评价action优劣】

State Value :the average Return that an agent can obtain if it follows a given policy/π【给定一个policy/π,所有可能的trajectorys得到的所有return的平均值/期望值: v π ( s ) ≐ E [ G t ∣ S t = s ] v_\pi(s)\doteq\mathbb{E}[G_t|S_t=s] vπ(s)≐E[Gt∣St=s]】.
Return:the discounted sum of all the rewards collected along a trajectory【return 等于沿着一个特定的 trajectory 收集到的所有 rewards 的折现总和: G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … , G_t\doteq R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots, Gt≐Rt+1+γRt+2+γ2Rt+3+…,】
v π ( s ) v_π(s) vπ(s):从状态 s s s 出发,遵循策略 π π π 能够获得的期望回报。
-
从给定状态 s i s_i si 出发基于给定的policy/π所包含的trajectorys之所以有多个,是因为在每个state时agent接下来要采取的action是按该policy下的概率来采样的,如下图:
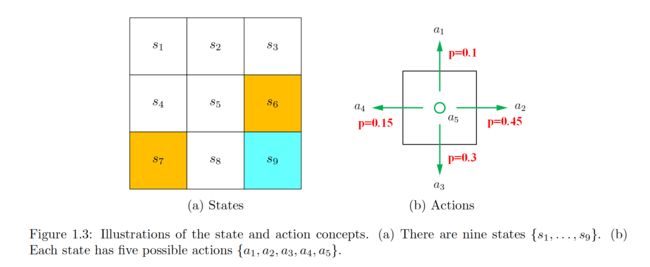
如果每一个state处所采取的action是固定的(以箭头表示),则每一个state在该policy中只有一个固定的trajectory;
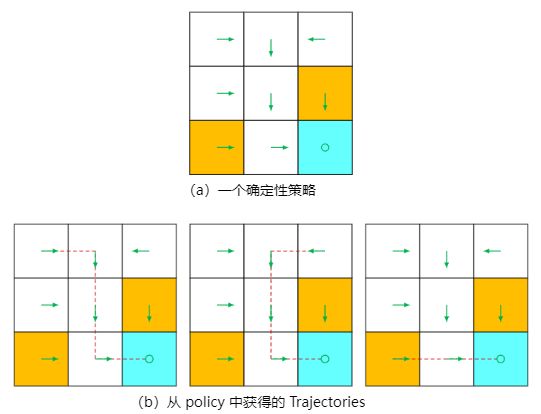
-
v π ( s ) v_{\pi}(s) vπ(s) depends on s s s:This is because its defnition is a conditional expectation with the condition that the agent starts from S t = s . S_t=s. St=s.
-
v π ( s ) v_{\pi}(s) vπ(s) depends on π \pi π:This is because the trajectories are generated by following the policy π \pi π. For a different policy, the state value may be different.【不同的policy/π得到的trajectories集合是不一样的】
-
v π ( s ) v_{\pi}(s) vπ(s) does not depend on t t t:If the agent moves in the state space, t t t represents the current time step. The value of υ π ( s ) \upsilon_{\pi}(s) υπ(s) is determined once the policy is given.
state values和returns之间的关系进一步明确如下:
- When both the policy and the system model are deterministic, starting from a state always leads to the same trajectory. In this case, the return obtained starting from a state is equal to the value of that state. 【当 policy 和 system model 都是确定性的时候,从一个状态开始总是会导致相同的轨迹。在这种情况下,从一个状态开始获得的return等于该状态的state value】
- By contrast, when either the policy or the system model is stochastic, starting from the same state may generate different trajectories. In this case, the returns of different trajectories are different, and the state value is the mean of these returns.【相反,当 policy 或 system model 中的任何一个是随机的时候,从相同的 state 开始可能会产生不同的trajectory。在这种情况下,不同trajectory的return是不同的,而state value是这些return的平均值。】
- The greater the state value is, the better the corresponding policy is.
- State values can be used as a metric to evaluate whether a policy is good or not.
While state values are important, how can we analyze them?
- The answer is the Bellman equation(贝尔曼方程), which is an important tool for analyzing state values.
- In a nutshell, the Bellman equation describes the relationships between the values of all states.【贝尔曼方程描述了所有状态值之间的关系。】
- By solving the Bellman equation, we can obtain the state values. This process is called policy evaluation, which is a fundamental concept in reinforcement learning. 【通过解决贝尔曼方程,我们可以得到状态值。这个过程被称为策略评估,是强化学习中的基本概念。】
Finally, this chapter introduces another important concept called the action value.
2.1 Motivating example 1: Why are returns important?
The previous chapter introduced the concept of returns. In fact, returns play a fundamental role in reinforcement learning since they can evaluate whether a policy is good or not. This is demonstrated by the following examples.

Consider the three policies shown in Figure 2.2. It can be seen that the three policies are different at s1. Which is the best and which is the worst? Intuitively,
- the leftmost policy is the best because the agent starting from s 1 s_1 s1 can avoid the forbidden area. 【最左边的策略是最好的,因为从 s 1 s_1 s1开始的agent可以避开禁区】
- The middle policy is intuitively worse because the agent starting from s 1 s_1 s1 moves to the forbidden area. 【中间的策略直观上更差,因为从 s 1 s_1 s1开始的agent会移动到禁区】
- The rightmost policy is in between the others because it has a probability of 0.5 to go to the forbidden area.【最右边的策略介于其他两者之间,因为它 有0.5的概率进入禁区】
While the above analysis is based on intuition, a question that immediately follows is whether we can use mathematics to describe such intuition. The answer is yes and relies on the return concept. 【尽管上述分析是基于直觉的,但紧随其后的一个问题是我们是否可以使用数学来描述这种直觉。答案是肯定的,这依赖于return的概念】
In particular, suppose that the agent starts from s 1 s_1 s1.
- Following the first policy, the trajectory is s1 → s3 → s4 → s4 · · · . The corresponding discounted return is
r e t u r n 1 = 0 + γ 1 + γ 2 1 + … = γ ( 1 + γ + γ 2 + … ) = γ 1 − γ , \begin{aligned} return_1& =0+\gamma1+\gamma^21+\ldots \\ &=\gamma(1+\gamma+\gamma^2+\ldots) \\ &=\frac\gamma{1-\gamma}, \\ \end{aligned} return1=0+γ1+γ21+…=γ(1+γ+γ2+…)=1−γγ,
where γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ∈(0,1) is the discount rate. - Following the second policy, the trajectory is s1 → s2 → s4 → s4 · · · . The discounted return is
r e t u r n 2 = − 1 + γ 1 + γ 2 1 + … = − 1 + γ ( 1 + γ + γ 2 + … ) = − 1 + γ 1 − γ . \begin{aligned} return_2& \begin{aligned}=-1+\gamma1+\gamma^21+\ldots\end{aligned} \\ &=-1+\gamma(1+\gamma+\gamma^2+\ldots) \\ &=-1+\frac\gamma{1-\gamma}. \end{aligned} return2=−1+γ1+γ21+…=−1+γ(1+γ+γ2+…)=−1+1−γγ.
- Following the third policy, two trajectories can possibly be obtained. One is s1 → s3 → s4 → s4 · · · , and the other is s1 → s2 → s4 → s4 · · · . The probability of either of the two trajectories is 0.5. Then, the average return that can be obtained starting from s 1 s_1 s1 is
r e t u r n 3 = 0.5 ( − 1 + γ 1 − γ ) + 0.5 ( γ 1 − γ ) = − 0.5 + γ 1 − γ . \begin{aligned} return_3& \begin{aligned}=0.5\left(-1+\frac{\gamma}{1-\gamma}\right)+0.5\left(\frac{\gamma}{1-\gamma}\right)\end{aligned} \\ &=-0.5+\frac\gamma{1-\gamma}. \end{aligned} return3=0.5(−1+1−γγ)+0.5(1−γγ)=−0.5+1−γγ.
By comparing the returns of the three policies, we notice that:
r e t u r n 1 > r e t u r n 3 > r e t u r n 2 return_1 > return_3 > return_2 return1>return3>return2
for any value of γ. r e t u r n 1 > r e t u r n 3 > r e t u r n 2 return_1 > return_3 > return_2 return1>return3>return2 suggests that the first policy is the best because its return is the greatest, and the second policy is the worst because its return is the smallest.
This mathematical conclusion is consistent with the aforementioned intuition: the first policy is the best since it can avoid entering the forbidden area, and the second policy is the worst because it leads to the forbidden area.
2.2 Motivating example 2: How to calculate returns?
While we have demonstrated the importance of returns, a question that immediately follows is how to calculate the returns when following a given policy.

There are two ways to calculate returns. 【有两种计算return的方法】
- The first is simply by definition: a return equals the discounted sum of all the rewards collected along a trajectory【return 等于沿着一个 trajectory 收集到的所有奖励的折现总和】. Consider the example in Figure 2.3. Let v i v_i vi denote the return obtained by starting from s i s_i si for i = 1, 2, 3, 4. Then, the returns obtained when starting from the four states in Figure 2.3 can be calculated as

- The second way, which is more important, is based on the idea of bootstrapping. By observing the expressions of the returns in (2.2), we can rewrite them as
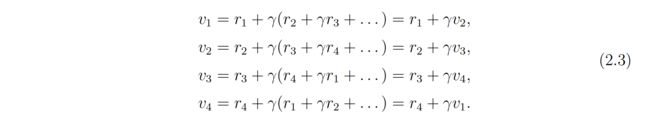
The above equations indicate an interesting phenomenon that the values of the returns rely on each other. More specifically, v1 relies on v2, v2 relies on v3, v3 relies on v4, and v4 relies on v1. This reflects the idea of bootstrapping, which is to obtain the values of some quantities from themselves.
At first glance, bootstrapping is an endless loop because the calculation of an unknown value relies on another unknown value. In fact, bootstrapping is easier to understand if we view it from a mathematical perspective. In particular, the equations in (2.3) can be reformed into a linear matrix-vector equation:

which can be written compactly as
v = r + γ P v . v=r+\gamma Pv. v=r+γPv.
Thus, the value of v v v can be calculated easily as v = ( I − γ P ) − 1 r v=(I-\gamma P)^{-1}r v=(I−γP)−1r, where I I I is the identity matrix with appropriate dimensions. One may ask whether I − γ P I-\gamma P I−γP is always invertible. The answer is yes and explained in Section 2.7.1.
In fact, (2.3) is the Bellman equation for this simple example. Although it is simple, (2.3) demonstrates the core idea of the Bellman equation: the return obtained by starting from one state depends on those obtained when starting from other states.
2.3 State values
We mentioned that returns can be used to evaluate policies. However, they are inapplicable to stochastic systems because starting from one state may lead to different returns.【我们提到过returns可以用来评估policies。然而,在随机系统中,returns是不适用的,因为从一个state出发可能会导致不同的returns】
Motivated by this problem, we introduce the concept of state value in this section.
First, we need to introduce some necessary notations.
Consider a sequence of time steps t = 0 , 1 , 2 , … t=0,1,2,\ldots t=0,1,2,… At time t t t, the agent is at state S t S_t St, and the action taken following a policy π \pi π is A t . A_t. At. The next state is S t + 1 S_{t+1} St+1, and the immediate reward obtained is R t + 1 . R_{t+1}. Rt+1. This process can be expressed concisely as
S t → A t S t + 1 , R t + 1 S_t\xrightarrow{A_t}S_{t+1},R_{t+1} StAtSt+1,Rt+1
Note that S t , S t + 1 , A t , R t + 1 S_t,S_{t+1},A_t,R_{t+1} St,St+1,At,Rt+1 are all random variables. Moreover, S t , S t + 1 ∈ S , A t ∈ A ( S t ) S_t,S_{t+1}\in\mathcal{S},A_t\in\mathcal{A}(S_t) St,St+1∈S,At∈A(St), and R t + 1 ∈ R ( S t , A t ) R_{t+1}\in\mathcal{R}(S_t,A_t) Rt+1∈R(St,At).
Starting from t t t, we can obtain a state-action-reward trajectory:
S t → A t S t + 1 , R t + 1 → A t + 1 S t + 2 , R t + 2 → A t + 2 S t + 3 , R t + 3 … . \begin{aligned}S_t\xrightarrow{A_t}S_{t+1},R_{t+1}\xrightarrow{A_{t+1}}S_{t+2},R_{t+2}\xrightarrow{A_{t+2}}S_{t+3},R_{t+3}\ldots.\end{aligned} StAtSt+1,Rt+1At+1St+2,Rt+2At+2St+3,Rt+3….
By definition, the discounted return along the trajectory【注:在给定π条件下,可能有多个trajectory】 is
G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … , G_t\doteq R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots, Gt≐Rt+1+γRt+2+γ2Rt+3+…,
where γ ∈ (0, 1) is the discount rate. Note that Gt is a random variable since R t + 1 , R t + 2 , … \begin{aligned}R_{t+1},R_{t+2},\ldots\end{aligned} Rt+1,Rt+2,… are all random variables.
Since G t G_t Gt is a random variable, we can calculate its expected value (also called the expectation or mean):
v π ( s ) ≐ E [ G t ∣ S t = s ] v_\pi(s)\doteq\mathbb{E}[G_t|S_t=s] vπ(s)≐E[Gt∣St=s]
Here, v π ( s ) v_π(s) vπ(s) is called the state-value function or simply the state value of s.
Some important remarks are given below.
- v π ( s ) v_{\pi}(s) vπ(s) depends on s s s:This is because its defnition is a conditional expectation with the condition that the agent starts from S t = s . S_t=s. St=s.
- v π ( s ) v_{\pi}(s) vπ(s) depends on π \pi π:This is because the trajectories are generated by following the policy π \pi π. For a different policy, the state value may be different.【不同的policy/π得到的trajectories集合是不一样的】
- v π ( s ) v_{\pi}(s) vπ(s) does not depend on t t t:If the agent moves in the state space, t t t represents the current time step. The value of υ π ( s ) \upsilon_{\pi}(s) υπ(s) is determined once the policy is given.
state values和returns之间的关系进一步明确如下:
- When both the policy and the system model are deterministic, starting from a state always leads to the same trajectory. In this case, the return obtained starting from a state is equal to the value of that state. 【当 policy 和 system model 都是确定性的时候,从一个状态开始总是会导致相同的轨迹。在这种情况下,从一个状态开始获得的return等于该状态的state value】
- By contrast, when either the policy or the system model is stochastic, starting from the same state may generate different trajectories. In this case, the returns of different trajectories are different, and the state value is the mean of these returns.【相反,当 policy 或 system model 中的任何一个是随机的时候,从相同的 state 开始可能会产生不同的trajectory。在这种情况下,不同trajectory的return是不同的,而state value是这些return的平均值。】
2.4 Bellman equation【贝尔曼公式】
Bellman equation, a mathematical tool for analyzing state val- ues. In a nutshell, the Bellman equation is a set of linear equations that describe the relationships between the values of all the states.【贝尔曼方程,这是一种分析状态值的数学工具。简而言之,贝尔曼方程是一组线性方程,描述了所有状态值之间的关系。】
贝尔曼公式推导:
- First, note that G t G_t Gt can be rewritten as
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = R t + 1 + γ ( R t + 2 + γ R t + 3 + … ) = R t + 1 + γ G t + 1 \begin{aligned} G_{t}& \begin{aligned}=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots\end{aligned} \\ &=R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\ldots) \\ &=R_{t+1}+\gamma G_{t+1} \end{aligned} Gt=Rt+1+γRt+2+γ2Rt+3+…=Rt+1+γ(Rt+2+γRt+3+…)=Rt+1+γGt+1
where G t + 1 = R t + 2 + γ R t + 3 + … . \begin{aligned}G_{t+1}=R_{t+2}+\gamma R_{t+3}+\ldots.\end{aligned} Gt+1=Rt+2+γRt+3+…. This equation establishes the relationship between G t G_t Gt and G t + 1 G_{t+1} Gt+1.
State Value 表示为(2.4) :
υ π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] \begin{aligned} \upsilon_{\pi}(s)&=\mathbb{E}[G_t|S_t=s]\\ &=\mathbb{E}[R_{t+1}+\gamma G_{t+1}|S_t=s] \\ &=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s] \end{aligned} υπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]
- 第一项 E [ R t + 1 ∣ S t = s ] \mathbb{E}[R_{t+1}|S_t=s] E[Rt+1∣St=s] 表示 the expectation of immediate rewards,根据the law of total expectation,可被改写为(2.5):
E [ R t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r \begin{aligned} \mathbb{E}[R_{t+1}|S_t=s]&=\sum_{a\in\mathcal{A}}\pi(a|s)\mathbb{E}[R_{t+1}|S_t=s,A_t=a]\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r \end{aligned} E[Rt+1∣St=s]=a∈A∑π(a∣s)E[Rt+1∣St=s,At=a]=a∈A∑π(a∣s)r∈R∑p(r∣s,a)r- Here, A A A and R R R are the sets of possible actions and rewards, respectively.
- It should be noted that A may be different for different states.
- In this case, A A A should be written as A ( s ) A(s) A(s). Similarly, R R R may also depend on ( s , a ) (s, a) (s,a).
- We drop the dependence on s s s or ( s , a ) (s, a) (s,a) for the sake of simplicity in this book. 【为了书写简洁】
- Nevertheless, the conclusions are still valid in the presence of dependence.
- 第二项 E [ G t + 1 ∣ S t = s ] \mathbb{E}[G_{t+1}|S_t=s] E[Gt+1∣St=s] ,表示 the expectation of the future rewards,可被改写为:
E [ G t + 1 ∣ S t = s ] = ∑ s ′ ∈ S E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ ∈ S E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) (due to the Markov property) = ∑ s ′ ∈ S v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ ∈ S v π ( s ′ ) ∑ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{aligned} \mathbb{E}[G_{t+1}|S_t=s]&=\sum_{s'\in\mathcal{S}}\mathbb{E}[G_{t+1}|S_t=s,S_{t+1}=s']p(s'|s)\\ &=\sum_{s'\in\mathcal{S}}\mathbb{E}[G_{t+1}|S_{t+1}=s']p(s'|s)\quad\text{(due to the Markov property)}\\ &=\sum_{s^{\prime}\in\mathcal{S}}v_\pi(s^{\prime})p(s^{\prime}|s) \\ &=\sum_{s^{\prime}\in\mathcal{S}}v_\pi(s^{\prime})\sum_{a\in\mathcal{A}}p(s^{\prime}|s,a)\pi(a|s) \end{aligned} E[Gt+1∣St=s]=s′∈S∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∈S∑E[Gt+1∣St+1=s′]p(s′∣s)(due to the Markov property)=s′∈S∑vπ(s′)p(s′∣s)=s′∈S∑vπ(s′)a∈A∑p(s′∣s,a)π(a∣s)- The above derivation uses the fact that E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] = E [ G t + 1 ∣ S t + 1 = s ′ ] \mathbb{E}[G_{t+1}|S_t=s,S_{t+1}=s']=\mathbb{E}[G_{t+1}|S_{t+1}=s'] E[Gt+1∣St=s,St+1=s′]=E[Gt+1∣St+1=s′],which is due to the Markov property that the future rewards depend merely on the present state rather than the previous ones.
- s ′ s' s′ 表示 s s s 的下一个时刻的状态;
将(2.5)-(2.6)代入(2.4),得公式(2.7):
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) , ⏟ mean of future rewards = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , for all s ∈ S \begin{aligned} \color{red}{v_{\pi}(s)}&=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s] \\[2ex] &=\underbrace{\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s'),}_{\text{mean of future rewards}}\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\left[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\right],\quad\text{for all }s\in\mathcal{S} \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=mean of immediate rewards a∈A∑π(a∣s)r∈R∑p(r∣s,a)r+mean of future rewards γa∈A∑π(a∣s)s′∈S∑p(s′∣s,a)vπ(s′),=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],for all s∈S
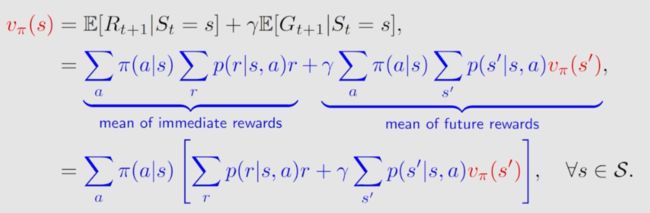
This equation is the Bellman equation, which characterizes the relationships of state values. It is a fundamental tool for designing and analyzing reinforcement learning algorithms.【这个方程是贝尔曼方程,它描述了state value之间的关系。它是设计和分析强化学习算法的基本工具。】
- v π ( s ) v_\pi( s) vπ(s) and v π ( s ′ ) v_\pi( s^\prime) vπ(s′) are unknown state values to be calculated.
- the Bellman equation refers to a set of linear equations for all states rather than a single equation.
- If we put these equations together, it becomes clear how to calculate all the state values.
- π ( a ∣ s ) \pi(a|s) π(a∣s) is a given policy.
- Since state values can be used to evaluate a policy, solving the state values from the Bellman equation is a p o l i c y e v a l u a t i o n policy\:evaluation policyevaluation process.
- p ( r ∣ s , a ) p( r|s, a) p(r∣s,a) and p ( s ′ ∣ s , a ) p( s^\prime|s, a) p(s′∣s,a) represent the system model.
- We will first show how to calculate the state values w i t h with with this model and then show how to do that w i t h o u t without without the model by using model-free algorithms later in this book.
In addition to the expression in (2.7), readers may also encounter other expressions of the Bellman equation in the literature. We next introduce two equivalent expressions.
- First, it follows from the law of total probability that
p ( s ′ ∣ s , a ) = ∑ r ∈ R p ( s ′ , r ∣ s , a ) , p ( r ∣ s , a ) = ∑ s ′ ∈ S p ( s ′ , r ∣ s , a ) . \begin{aligned}p(s'|s,a)&=\sum_{r\in\mathcal{R}}p(s',r|s,a),\\p(r|s,a)&=\sum_{s'\in\mathcal{S}}p(s',r|s,a).\end{aligned} p(s′∣s,a)p(r∣s,a)=r∈R∑p(s′,r∣s,a),=s′∈S∑p(s′,r∣s,a).
Then, equation (2.7) can be rewritten as
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S ∑ r ∈ R p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] \begin{aligned}v_{\pi}(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s^{\prime}\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)\left[r+\gamma v_{\pi}(s')\right]\end{aligned} vπ(s)=a∈A∑π(a∣s)s′∈S∑r∈R∑p(s′,r∣s,a)[r+γvπ(s′)] - Second, the reward r r r may depend solely on the next state s ′ s^{\prime} s′ in some problems. As a result, we can write the reward as r ( s ′ ) r(s^{\prime}) r(s′) and hence p ( r ( s ′ ) ∣ s , a ) = p ( s ′ ∣ s , a ) p(r(s^{\prime})|s,a)=p(s^{\prime}|s,a) p(r(s′)∣s,a)=p(s′∣s,a), substituting which into (2.7) gives
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) [ r ( s ′ ) + γ v π ( s ′ ) ] \begin{aligned}v_\pi(s)&=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)\left[r(s')+\gamma v_\pi(s')\right]\end{aligned} vπ(s)=a∈A∑π(a∣s)s′∈S∑p(s′∣s,a)[r(s′)+γvπ(s′)]
2.5 Examples for illustrating the Bellman equation
We next use two examples to demonstrate how to write out the Bellman equation and calculate the state values step by step. Readers are advised to carefully go through the examples to gain a better understanding of the Bellman equation.【我们接下来使用两个例子来演示如何写出贝尔曼方程并逐步计算状态值。建议读者仔细阅读这些例子,以更好地理解贝尔曼方程。】
If we compare the state values of the two policies in the above examples, it can be seen that:【如果我们比较下述示例中两种策略的状态值,可以看到】
v π 1 ( s i ) ≥ v π 2 ( s i ) , i = 1 , 2 , 3 , 4 , v_{\pi_1}(s_i)\geq v_{\pi_2}(s_i),\quad i=1,2,3,4, vπ1(si)≥vπ2(si),i=1,2,3,4,
- which indicates that the policy in Figure 2.4 is better because it has greater state values.【这表明图2.4中的策略更好,因为它具有更大的状态值。】
- This mathematical conclusion is consistent with the intuition that the first policy is better because it can avoid entering the forbidden area when the agent starts from s 1 s_1 s1. 【这个数学结论与直觉一致,即第一个policy更好,因为当agent 从 s 1 s_1 s1开始时,它可以避免进入禁区。】
- As a result, the above two examples demonstrate that state values can be used to evaluate policies.【这两个例子证明了state value可以 用来评估policy】
2.5.1 example01【policy是确定性的】

Consider the first example shown in Figure 2.4, where the policy is deterministic【policy是确定性的】.
We next write out the Bellman equation and then solve the state values from it.
First, consider state s 1 . s_1. s1. Under the policy:
- The probabilities of taking the actions are π ( a = a 3 ∣ s 1 ) = 1 \pi( a= a_3|s_1) = 1 π(a=a3∣s1)=1 and π ( a ≠ a 3 ∣ s 1 ) = 0 \pi( a≠a_3|s_1) = 0 π(a=a3∣s1)=0.
- The state transition probabilities are p ( s ′ = s 3 ∣ s 1 , a 3 ) = 1 p( s^\prime= s_3|s_1, a_3) = 1 p(s′=s3∣s1,a3)=1 and p ( s ′ ≠ s 3 ∣ s 1 , a 3 ) = 0. p( s^\prime≠s_3|s_1, a_3) = 0. p(s′=s3∣s1,a3)=0.
- The reward probabilities are p ( r = 0 ∣ s 1 , a 3 ) = 1 p( r= 0|s_1, a_3) = 1 p(r=0∣s1,a3)=1 and p ( r ≠ 0 ∣ s 1 , a 3 ) = 0. p( r\neq0|s_1, a_3) = 0. p(r=0∣s1,a3)=0.
Substituting these values into
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) , ⏟ mean of future rewards = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , for all s ∈ S \begin{aligned} \color{red}{v_{\pi}(s)}&=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s] \\[2ex] &=\underbrace{\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s'),}_{\text{mean of future rewards}}\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\left[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\right],\quad\text{for all }s\in\mathcal{S} \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=mean of immediate rewards a∈A∑π(a∣s)r∈R∑p(r∣s,a)r+mean of future rewards γa∈A∑π(a∣s)s′∈S∑p(s′∣s,a)vπ(s′),=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],for all s∈S
gives
v π ( s 1 ) = 0 + γ v π ( s 3 ) v_\pi(s_1)=0+\gamma v_\pi(s_3) vπ(s1)=0+γvπ(s3)
Similarly, it can be obtained that
υ π ( s 2 ) = 1 + γ υ π ( s 4 ) v π ( s 3 ) = 1 + γ υ π ( s 4 ) υ π ( s 4 ) = 1 + γ υ π ( s 4 ) \begin{aligned} &\upsilon_{\pi}(s_2) =1+\gamma\upsilon_{\pi}(s_4) \\ &v_{\pi}(s_{3}) =1+\gamma\upsilon_{\pi}(s_4) \\ &\upsilon_{\pi}(s_{4}) =1+\gamma\upsilon_\pi(s_4) \\ \end{aligned} υπ(s2)=1+γυπ(s4)vπ(s3)=1+γυπ(s4)υπ(s4)=1+γυπ(s4)
We can solve the state values from these equations. Since the equations are simple, we can manually solve them. Here, the state values can be solved as:【我们可以从这些方程中解出状态值。由于这些方程很简单,我们可以手动解决它们。在这里,状态值可以被解决为】
υ π ( s 4 ) = 1 1 − γ , υ π ( s 3 ) = 1 1 − γ , υ π ( s 2 ) = 1 1 − γ , υ π ( s 1 ) = γ 1 − γ . \begin{gathered} \upsilon_\pi(s_4) =\frac1{1-\gamma}, \\ \upsilon_{\pi}(s_{3}) =\frac1{1-\gamma}, \\ \upsilon_{\pi}(s_{2}) =\frac1{1-\gamma}, \\ \upsilon_{\pi}(s_{1}) =\frac\gamma{1-\gamma}. \end{gathered} υπ(s4)=1−γ1,υπ(s3)=1−γ1,υπ(s2)=1−γ1,υπ(s1)=1−γγ.
Furthermore, if we set γ = 0.9 γ = 0.9 γ=0.9, then
υ π ( s 4 ) = 1 1 − 0.9 = 10 , υ π ( s 3 ) = 1 1 − 0.9 = 10 , υ π ( s 2 ) = 1 1 − 0.9 = 10 , υ π ( s 1 ) = 0.9 1 − 0.9 = 9. \begin{gathered} \upsilon_\pi(s_4) \begin{aligned}=\frac{1}{1-0.9}=10,\end{aligned} \\ \upsilon_{\pi}(s_{3}) =\frac1{1-0.9}=10, \\ \upsilon_{\pi}(s_{2}) =\frac1{1-0.9}=10, \\ \upsilon_{\pi}(s_{1}) =\frac{0.9}{1-0.9}=9. \end{gathered} υπ(s4)=1−0.91=10,υπ(s3)=1−0.91=10,υπ(s2)=1−0.91=10,υπ(s1)=1−0.90.9=9.
2.5.2 example02【policy是随机的】
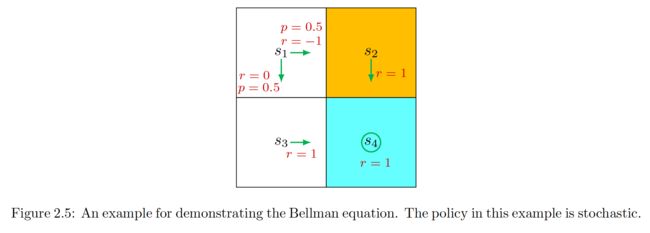
Consider the second example shown in Figure 2.5, where the policy is stochastic【policy是随机的】.
We next write out the Bellman equation and then solve the state values from it.
First, consider state s 1 . s_1. s1. Under the policy:
- At state s 1 s_1 s1, the probabilities of going right and down equal 0.5. The probabilities of taking the actions are π ( a = a 2 ∣ s 1 ) = 0.5 \pi( a= a_2|s_1) = 0.5 π(a=a2∣s1)=0.5 and π ( a = a 3 ∣ s 1 ) = 0.5. \pi( a= a_3|s_1) = 0.5. π(a=a3∣s1)=0.5.
- The state transition probability is deterministic since p ( s ′ = s 3 ∣ s 1 , a 3 ) = 1 p( s^{\prime}= s_3|s_1, a_3) = 1 p(s′=s3∣s1,a3)=1 and p ( s ′ = s 2 ∣ s 1 , a 2 ) = 1. p( s^\prime= s_2|s_1, a_2) = 1. p(s′=s2∣s1,a2)=1.
- The reward probability is also deterministic since p ( r = 0 ∣ s 1 , a 3 ) = 1 p( r= 0|s_1, a_3) = 1 p(r=0∣s1,a3)=1 and p ( r = − 1 ∣ s 1 , a 2 ) = 1. p( r= - 1|s_1, a_2) = 1. p(r=−1∣s1,a2)=1.
Substituting these values into
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) , ⏟ mean of future rewards = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , for all s ∈ S \begin{aligned} \color{red}{v_{\pi}(s)}&=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s] \\[2ex] &=\underbrace{\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s'),}_{\text{mean of future rewards}}\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\left[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\right],\quad\text{for all }s\in\mathcal{S} \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=mean of immediate rewards a∈A∑π(a∣s)r∈R∑p(r∣s,a)r+mean of future rewards γa∈A∑π(a∣s)s′∈S∑p(s′∣s,a)vπ(s′),=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],for all s∈S
gives
v π ( s 1 ) = 0.5 [ 0 + γ v π ( s 3 ) ] + 0.5 [ − 1 + γ v π ( s 2 ) ] \begin{aligned}v_\pi(s_1)=0.5[0+\gamma v_\pi(s_3)]+0.5[-1+\gamma v_\pi(s_2)]\end{aligned} vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)]
Similarly, it can be obtained that
υ π ( s 2 ) = 1 + γ υ π ( s 4 ) , υ π ( s 3 ) = 1 + γ υ π ( s 4 ) , υ π ( s 4 ) = 1 + γ υ π ( s 4 ) . \begin{aligned} &\upsilon_{\pi}(s_{2}) =1+\gamma\upsilon_{\pi}(s_4), \\ &\upsilon_{\pi}(s_{3}) =1+\gamma\upsilon_{\pi}(s_4), \\ &\upsilon_{\pi}(s_{4}) =1+\gamma\upsilon_\pi(s_4). \\ \end{aligned} υπ(s2)=1+γυπ(s4),υπ(s3)=1+γυπ(s4),υπ(s4)=1+γυπ(s4).
The state values can be solved from the above equations. Since the equations are simple, we can solve the state values manually and obtain
v π ( s 4 ) = 1 1 − γ , υ π ( s 3 ) = 1 1 − γ , υ π ( s 2 ) = 1 1 − γ , v π ( s 1 ) = 0.5 [ 0 + γ v π ( s 3 ) ] + 0.5 [ − 1 + γ v π ( s 2 ) ] = − 0.5 + γ 1 − γ \begin{aligned} &v_\pi(s_4) =\frac1{1-\gamma}, \\ &\upsilon_{\pi}(s_{3}) =\frac1{1-\gamma}, \\ &\upsilon_{\pi}(s_{2}) =\frac1{1-\gamma}, \\ &v_{\pi}(s_{1}) =0.5[0+\gamma v_\pi(s_3)]+0.5[-1+\gamma v_\pi(s_2)] =-0.5+\frac\gamma{1-\gamma} \end{aligned} vπ(s4)=1−γ1,υπ(s3)=1−γ1,υπ(s2)=1−γ1,vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)]=−0.5+1−γγ
Furthermore, if we set γ = 0.9 γ = 0.9 γ=0.9, then
υ π ( s 4 ) = 10 , υ π ( s 3 ) = 10 , v π ( s 2 ) = 10 , v π ( s 1 ) = − 0.5 + 9 = 8.5. \begin{aligned} &\upsilon_\pi(s_4) =10, \\ &\upsilon_{\pi}(s_{3}) =10, \\ &v_{\pi}(s_{2}) =10, \\ &v_{\pi}(s_{1}) =-0.5+9=8.5. \end{aligned} υπ(s4)=10,υπ(s3)=10,vπ(s2)=10,vπ(s1)=−0.5+9=8.5.
2.6 Matrix-vector form of the Bellman equation【贝尔曼方程的矩阵-向量形式】
The Bellman equation in (2.7) is in an element-wise form. Since it is valid for every state, we can combine all these equations and write them concisely in a matrix-vector form, which will be frequently used to analyze the Bellman equation.【贝尔曼方程(2.7)是以元素形式表示的。由于它对于每个状态都有效,我们可以将所有这些方程组合起来,并以矩阵-向量形式简洁地写出来,将经常用于分析贝尔曼方程。】
To derive the matrix-vector form, we first rewrite the Bellman equation【为了得到矩阵-向量形式,我们首先将贝尔曼方程重写】
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a ∈ A π ( a ∣ s ) ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) , ⏟ mean of future rewards = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , for all s ∈ S \begin{aligned} \color{red}{v_{\pi}(s)}&=\mathbb{E}[R_{t+1}|S_t=s]+\gamma\mathbb{E}[G_{t+1}|S_t=s] \\[2ex] &=\underbrace{\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r}_{\text{mean of immediate rewards}}+\underbrace{\gamma\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s'),}_{\text{mean of future rewards}}\\ &=\sum_{a\in\mathcal{A}}\pi(a|s)\left[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_{\pi}(s')\right],\quad\text{for all }s\in\mathcal{S} \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=mean of immediate rewards a∈A∑π(a∣s)r∈R∑p(r∣s,a)r+mean of future rewards γa∈A∑π(a∣s)s′∈S∑p(s′∣s,a)vπ(s′),=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],for all s∈S
重写为:
v π ( s ) = r π ( s ) + γ ∑ s ′ ∈ S p π ( s ′ ∣ s ) v π ( s ′ ) ( 2.8 ) \begin{aligned}v_{\pi}(s)=r_{\pi}(s)+\gamma\sum_{s'\in\mathcal{S}}p_{\pi}(s'|s)v_{\pi}(s')\quad\quad\quad(2.8)\end{aligned} vπ(s)=rπ(s)+γs′∈S∑pπ(s′∣s)vπ(s′)(2.8)
其中:
r π ( s ) ≐ ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r p π ( s ′ ∣ s ) = ˙ ∑ a ∈ A π ( a ∣ s ) p ( s ′ ∣ s , a ) \begin{aligned} &r_{\pi}(s)\doteq\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r \\[4ex] &p_{\pi}(s'|s)\dot{=}\sum_{a\in\mathcal{A}}\pi(a|s)p(s'|s,a) \end{aligned} rπ(s)≐a∈A∑π(a∣s)r∈R∑p(r∣s,a)rpπ(s′∣s)=˙a∈A∑π(a∣s)p(s′∣s,a)
- r π ( s ) r_{\pi}( s) rπ(s) denotes the mean of the immediate rewards;
- p π ( s ′ ∣ s ) p_{\pi}(s^{\prime}|s) pπ(s′∣s) is the probability of transitioning from s s s to s ′ s^{\prime} s′ under policy π . \pi. π.
Suppose that the states are indexed as s i s_i si with i = 1 , … , n , i= 1, \ldots , n, i=1,…,n, where n = ∣ S ∣ . n= |S|. n=∣S∣. For state s i s_i si, ( 2.8) can be written as
v π ( s i ) = r π ( s i ) + γ ∑ s j ∈ S p π ( s j ∣ s i ) v π ( s j ) ( 2.9 ) \begin{aligned}v_{\pi}(s_{i})=r_{\pi}(s_{i})+\gamma\sum_{s_{j}\in\mathcal{S}}p_{\pi}(s_{j}|s_{i})v_{\pi}(s_{j})&\quad\quad\quad(2.9)\end{aligned} vπ(si)=rπ(si)+γsj∈S∑pπ(sj∣si)vπ(sj)(2.9)
令: v π = [ v π ( s 1 ) , … , v π ( s n ) ] T ∈ R n v_\pi=[v_\pi(s_1),\ldots,v_\pi(s_n)]^T\in\mathbb{R}^n vπ=[vπ(s1),…,vπ(sn)]T∈Rn, r π = [ r π ( s 1 ) , … , r π ( s n ) ] T ∈ R n r_\pi=[r_\pi(s_1),\ldots,r_\pi(s_n)]^T\in\mathbb{R}^n rπ=[rπ(s1),…,rπ(sn)]T∈Rn,and P π ∈ R n × n P_\pi\in\mathbb{R}^{n\times n} Pπ∈Rn×n with [ P π ] i j = p π ( s j ∣ s i ) [P_\pi]_{ij}=p_\pi(s_j|s_i) [Pπ]ij=pπ(sj∣si)。Then, (2.9) can be written in the following matrix-vector form:
v π = r π + γ P π v π , ( 2.10 ) \color{red}{\begin{aligned}v_{\pi}&=r_{\pi}+\gamma P_{\pi}v_{\pi},\end{aligned}\quad\quad(2.10)} vπ=rπ+γPπvπ,(2.10)
where v π v_π vπ is the unknown to be solved, and r π r_π rπ, P π P_π Pπ are known.
The matrix P π P_\mathrm{\pi} Pπ has some interesting properties.
- First, it is a nonnegative matrix meaning that all its elements are equal to or greater than zero. This property is denoted as P π ≥ 0 P_{\pi}\geq0 Pπ≥0, where 0 denotes a zero matrix with appropriate dimensions. In this book, ≥ \geq ≥ or ≤ \leq ≤ represents an elementwise comparison operation.
- Second, P π P_\pi Pπ is a stochastic matrix meaning that the sum of the values in every row is equal to one. This property is denoted as P π 1 = 1 P_{\pi}\mathbf{1}=\mathbf{1} Pπ1=1, where 1 = [ 1 , … , 1 ] T \mathbf{1}=[1,\ldots,1]^T 1=[1,…,1]T has appropriate dimensions.

Consider the example shown in Figure 2.6. The matrix-vector form of the Bellman equation is
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] ⏟ v π = [ r π ( s 1 ) r π ( s 2 ) r π ( s 3 ) r π ( s 4 ) ] ⏟ r π + γ [ p π ( s 1 ∣ s 1 ) p π ( s 2 ∣ s 1 ) p π ( s 3 ∣ s 1 ) p π ( s 4 ∣ s 1 ) p π ( s 1 ∣ s 2 ) p π ( s 2 ∣ s 2 ) p π ( s 3 ∣ s 2 ) p π ( s 4 ∣ s 2 ) p π ( s 1 ∣ s 3 ) p π ( s 2 ∣ s 3 ) p π ( s 3 ∣ s 4 ) p π ( s 4 ∣ s 4 ) p π ( s 1 ∣ s 4 ) p π ( s 2 ∣ s 4 ) p π ( s 3 ∣ s 4 ) p π ( s 4 ∣ s 4 ) ] ⏟ P π [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] ⏟ v π \underbrace{\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right]}_{v_\pi}=\underbrace{\left[\begin{array}{c}r_\pi(s_1)\\r_\pi(s_2)\\r_\pi(s_3)\\r_\pi(s_4)\end{array}\right]}_{r_\pi}+\gamma\underbrace{\left[\begin{array}{cccc}p_\pi(s_1|s_1)&p_\pi(s_2|s_1)&p_\pi(s_3|s_1)&p_\pi(s_4|s_1)\\p_\pi(s_1|s_2)&p_\pi(s_2|s_2)&p_\pi(s_3|s_2)&p_\pi(s_4|s_2)\\p_\pi(s_1|s_3)&p_\pi(s_2|s_3)&p_\pi(s_3|s_4)&p_\pi(s_4|s_4)\\p_\pi(s_1|s_4)&p_\pi(s_2|s_4)&p_\pi(s_3|s_4)&p_\pi(s_4|s_4)\end{array}\right]}_{P_\pi}\underbrace{\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right]}_{v_\pi} vπ vπ(s1)vπ(s2)vπ(s3)vπ(s4) =rπ rπ(s1)rπ(s2)rπ(s3)rπ(s4) +γPπ pπ(s1∣s1)pπ(s1∣s2)pπ(s1∣s3)pπ(s1∣s4)pπ(s2∣s1)pπ(s2∣s2)pπ(s2∣s3)pπ(s2∣s4)pπ(s3∣s1)pπ(s3∣s2)pπ(s3∣s4)pπ(s3∣s4)pπ(s4∣s1)pπ(s4∣s2)pπ(s4∣s4)pπ(s4∣s4) vπ vπ(s1)vπ(s2)vπ(s3)vπ(s4)
Substituting the specific values into the above equation gives
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] = [ 0.5 ( 0 ) + 0.5 ( − 1 ) 1 1 1 ] + γ [ 0 0.5 0.5 0 0 0 0 1 0 0 0 1 0 0 0 1 ] [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] \left.\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right.\right]=\left[\begin{array}{c}0.5(0)+0.5(-1)\\1\\1\\1\end{array}\right]+\gamma\left[\begin{array}{cccc}0&0.5&0.5&0\\0&0&0&1\\0&0&0&1\\0&0&0&1\end{array}\right]\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right] vπ(s1)vπ(s2)vπ(s3)vπ(s4) = 0.5(0)+0.5(−1)111 +γ 00000.50000.50000111 vπ(s1)vπ(s2)vπ(s3)vπ(s4)
It can be seen that P π P_\pi Pπ satisfies P π 1 = 1 P_{\pi}\mathbf{1}=\mathbf{1} Pπ1=1.
2.7 从贝尔曼方程求解 State Values【Solving state values from the Bellman equation】
Calculating the state values of a given policy is a fundamental problem in reinforcement learning. This problem is often referred to as policy evaluation. 【计算给定策略的状态值是强化学习中的一个基本问题。这个问题通常被称为策略评估。】
In this section, we present two methods for calculating state values from the Bellman equation.【介绍两种从贝尔曼方程计算state values的方法】
2.7.1 Closed-form solution
Since v π = r π + γ P π v π \operatorname{Since}v_{\pi}=r_{\pi}+\gamma P_{\pi}v_{\pi} Sincevπ=rπ+γPπvπ is a simple linear equation, its closed-form solution can be easily obtained as
v π = ( I − γ P π ) − 1 r π . v_\pi=(I-\gamma P_\pi)^{-1}r_\pi. vπ=(I−γPπ)−1rπ.
Some properties of ( I − γ P π ) − 1 (I-\gamma P_{\pi})^{-1} (I−γPπ)−1 are given below.
-
I − γ P π I-\gamma P_{\pi} I−γPπ is invertible. The proof is as follows. According to the Gershgorin circle theorem [4], every eigenvalue of I − γ P π I-\gamma P_{\pi} I−γPπ lies within at least one of the Gershgorin circles. The i i ith Gershgorin circle has a center at [ I − γ P π ] i i = 1 − γ p π ( s i ∣ s i ) [I-\gamma P_{\pi}]_{ii}=1-\gamma p_{\pi}(s_{i}|s_{i}) [I−γPπ]ii=1−γpπ(si∣si) and a radius equal to ∑ j ≠ i [ I − γ P π ] i j = − ∑ j ≠ i γ p π ( s j ∣ s i ) . \sum_{j\neq i}[I-\gamma P_{\pi}]_{ij}=-\sum_{j\neq i}\gamma p_{\pi}(s_{j}|s_{i}). ∑j=i[I−γPπ]ij=−∑j=iγpπ(sj∣si). Since γ < 1 \gamma<1 γ<1, we know that the radius is less than the magnitude of the center: ∑ j ≠ i γ p π ( s j ∣ s i ) < 1 − γ p π ( s i ∣ s i ) \sum_{j\neq i}\gamma p_\pi(s_j|s_i)<1-\gamma p_\pi(s_i|s_i) ∑j=iγpπ(sj∣si)<1−γpπ(si∣si) Therefore, all Gershgorin circles do not encircle the origin, and hence, no eigenvalue of I − γ P π I-\gamma P_{\pi} I−γPπ is zero.
-
( I − γ P π ) − 1 ≥ I (I-\gamma P_{\pi})^{-1}\geq I (I−γPπ)−1≥I, meaning that every element of ( I − γ P π ) − 1 (I-\gamma P_{\pi})^{-1} (I−γPπ)−1 is nonnegative and, more specifically, no less than that of the identity matrix. This is because P π P_\mathrm{\pi} Pπ has nonnegative entries, and hence, ( I − γ P π ) − 1 = I + γ P π + γ 2 P π 2 + ⋯ ≥ I ≥ 0. (I-\gamma P_{\pi})^{-1}=I+\gamma P_{\pi}+\gamma^{2}P_{\pi}^{2}+\cdots\geq I\geq0. (I−γPπ)−1=I+γPπ+γ2Pπ2+⋯≥I≥0.
-
For any vector r ≥ 0 r\geq 0 r≥0, it holds that ( I − γ P π ) − 1 r ≥ r ≥ 0 (I- \gamma P_{\pi})^{-1}r\geq r\geq0 (I−γPπ)−1r≥r≥0 This property follows from the second property because [ ( I − γ P π ) − 1 − I ] r ≥ 0. [(I-\gamma P_{\pi})^{-1}-I]r\geq0. [(I−γPπ)−1−I]r≥0. As a consequence, if r 1 ≥ r 2 r_1\geq r_2 r1≥r2, we have ( I − γ P π ) − 1 r 1 ≥ ( I − γ P π ) − 1 r 2 . \begin{aligned}\text{have }(I-\gamma P_{\pi})^{-1}r_{1}\geq(I-\gamma P_{\pi})^{-1}r_{2}.\end{aligned} have (I−γPπ)−1r1≥(I−γPπ)−1r2.
2.7.2 Iterative solution
Although the closed-form solution is useful for theoretical analysis purposes, it is not applicable in practice because it involves a matrix inversion operation, which still needs to be calculated by other numerical algorithms. In fact, we can directly solve the Bellman equation using the following iterative algorithm:【尽管闭式解对于理论分析目的很有用,但在实践中不适用,因为它涉及矩阵求逆运算,仍需要
通过其他数值算法进行计算。实际上,我们可以使用以下迭代算法直接解决贝尔曼方程:】
v k + 1 = r π + γ P π v k , k = 0 , 1 , 2 , … ( 2.11 ) \color{red}{\begin{aligned}v_{k+1}=r_{\pi}+\gamma P_{\pi}v_{k},\quad k=0,1,2,\ldots\end{aligned}\quad\quad\quad\quad\quad(2.11)} vk+1=rπ+γPπvk,k=0,1,2,…(2.11)
This algorithm generates a sequence of values { v 0 , v 1 , v 2 , … } \{ v_0, v_1, v_2, \ldots \} {v0,v1,v2,…} , where v 0 ∈ R n v_0\in \mathbb{R} ^n v0∈Rn is an initial guess of v π v_\pi vπ.
It holds that【大家认为】
v k → v π = ( I − γ P π ) − 1 r π , as k → ∞ ( 2.12 ) \begin{aligned}v_k\to v_\pi&=(I-\gamma P_\pi)^{-1}r_\pi,\quad\text{ as }k\to\infty \quad\quad\quad\quad\quad\quad (2.12)\end{aligned} vk→vπ=(I−γPπ)−1rπ, as k→∞(2.12)
2.7.3 Illustrative examples
We next apply the algorithm in (2.11) to solve the state values of some examples.
The examples are shown in Figure 2.7. The orange cells represent forbidden areas. The blue cell represents the target area. The reward settings are r boundary = r forbidden = − 1 r_{\text{boundary}}=r_{\text{forbidden}}=-1 rboundary=rforbidden=−1,and r target = 1 r_{\text{target}}= 1 rtarget=1. Here, the discount rate is γ = 0.9 \gamma = 0.9 γ=0.9.

- Figure 2.7(a) shows two “good” policies and their corresponding state values obtained by (2.11). The two policies have the same state values but differ at the top two states in the fourth column. Therefore, we know that different policies may have the same state values.
- Figure 2.7(b) shows two “bad” policies and their corresponding state values. These two policies are bad because the actions of many states are intuitively unreasonable. Such intuition is supported by the obtained state values. As can be seen, the state values of these two policies are negative and much smaller than those of the good policies in Figure 2.7(a).
2.8 From state value to action value
While we have been discussing state values thus far in this chapter, we now turn to the action value, which indicates the “value” of taking an action at a state. While the concept of action value is important, the reason why it is introduced in the last section of this chapter is that it heavily relies on the concept of state values. It is important to understand state values well first before studying action values.
State Value:
v π ( s ) ≐ E [ G t ∣ S t = s ] \begin{aligned}v_\pi(s)\doteq\mathbb{E}[G_t|S_t=s]\end{aligned} vπ(s)≐E[Gt∣St=s]
Action Value:
q π ( s , a ) ≐ E [ G t ∣ S t = s , A t = a ] \begin{aligned}q_\pi(s,a)\doteq\mathbb{E}[G_t|S_t=s,A_t=a]\end{aligned} qπ(s,a)≐E[Gt∣St=s,At=a]
As can be seen, the action value is defined as the expected return that can be obtained after taking an action at astate. 【动作值被定义为在某个状态下采取某个动作后可以获得的预期回报】
It must be noted that q π ( s , a ) q_\pi(s,a) qπ(s,a) depends on a state-action pair ( s , a ) (s,a) (s,a) rather than an action alone. It may be more rigorous to call this value a state-action value, but it is conventionally called an action value for simplicity.【必须注意的是, q ( s , a ) q(s, a) q(s,a)取决于state-action对 ( s , a ) (s, a) (s,a),而不仅仅是一个action 。为了简单起见,通常将这个值称为 action value,尽管更严谨的说法应该是state-action value】
What is the relationship between action values and state values? 【行动值和状态值之间的关系是什么?】
- First, it follows from the properties of conditional expectation that
E [ G t ∣ S t = s ] ⏟ v π ( s ) = ∑ a ∈ A E [ G t ∣ S t = s , A t = a ] ⏟ q π ( s , a ) π ( a ∣ s ) \begin{aligned}\underbrace{\mathbb{E}[G_t|S_t=s]}_{v_\pi(s)}&=\sum_{a\in\mathcal{A}}\underbrace{\mathbb{E}[G_t|S_t=s,A_t=a]}_{q_\pi(s,a)}\pi(a|s)\end{aligned} vπ(s) E[Gt∣St=s]=a∈A∑qπ(s,a) E[Gt∣St=s,At=a]π(a∣s)
It then follows that
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) . ( 2.13 ) \color{red}{\begin{aligned}v_{\pi}(s)=\sum_{a\in\mathcal{A}}\pi(a|s)q_{\pi}(s,a).&&(2.13)\end{aligned}} vπ(s)=a∈A∑π(a∣s)qπ(s,a).(2.13)
As a result, a state value is the expectation of the action values associated with that state. 【State Value是与该state相关联的Action Value的期望值】 - Second, since the state value is given by
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) [ ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) ] , \begin{aligned}v_\pi(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\Big[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_\pi(s')\Big],\end{aligned} vπ(s)=a∈A∑π(a∣s)[r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′)],
comparing it with (2.13) leads to
q π ( s , a ) = ∑ r ∈ R p ( r ∣ s , a ) r + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) v π ( s ′ ) . ( 2.14 ) \color{red}{\begin{aligned}q_\pi(s,a)=\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_\pi(s').\quad\quad\quad\quad(2.14)\end{aligned}} qπ(s,a)=r∈R∑p(r∣s,a)r+γs′∈S∑p(s′∣s,a)vπ(s′).(2.14)
It can be seen that the action value consists of two terms.- The first term is the mean of the immediate rewards;
- the second term is the mean of the future rewards.
Both (2.13) and (2.14) describe the relationship between state values and action values. They are the two sides of the same coin:
- (2.13) shows how to obtain state values from action values【action values---->state values】;
- (2.14) shows how to obtain action values from state values【state values---->action values】;
2.8.1 Illustrative examples

We next present an example to illustrate the process of calculating action values and discuss a common mistake that beginners may make.
Consider the stochastic policy shown in Figure 2.8. We next only examine the actions of s 1 s_1 s1. The other states can be examined similarly. The action value of ( s 1 , a 2 ) (s_1, a_2) (s1,a2) is
q π ( s 1 , a 2 ) = − 1 + γ v π ( s 2 ) q_\pi(s_1,a_2)=-1+\gamma v_\pi(s_2) qπ(s1,a2)=−1+γvπ(s2)
where s 2 s_2 s2