使用AWS Glue与AWS Kinesis构建的流式ETL作业(二)——数据处理
大纲
- 2 数据处理
-
- 2.1 架构
- 2.2 AWS Glue连接和创建
-
- 2.2.1 创建AWS RedShift连接
- 2.2.2 创建AWS RDS连接(以PG为例)
- 2.3 创建AWS Glue Job
- 2.4 编写脚本
-
-
- 2.4.1 以AWS RedShift为例
- 2.4.2 以PG为例
-
- 2.5 运行脚本
2 数据处理
2.1 架构

2.2 AWS Glue连接和创建
下文中提供了AWS RedShift和PG数据库的连接创建过程,在实际使用中我们可以二选一。
2.2.1 创建AWS RedShift连接
前置条件:需要有一个AWS RedShift。
AWS RedShift具体的创建过程本文不表。需要注意的是:RedShift需要创建一个终端节点,具体的方法请看《Glue连接RedShift的前置条件:创建终端节点》
由于Glue Job 在运行的时候,是在独立的服务器上,因此不能直接访问到私有子网中的服务。于是借助Glue连接,可以使得Job在运行时连接AWS服务。
| 步骤 | 图例 |
|---|---|
| 1、创建连接 |  |
| 2、输入连接名称,连接类型选择“Amazon Redshift” |  |
| 3、选择RedShift集群,输入配置的用户名密码 | 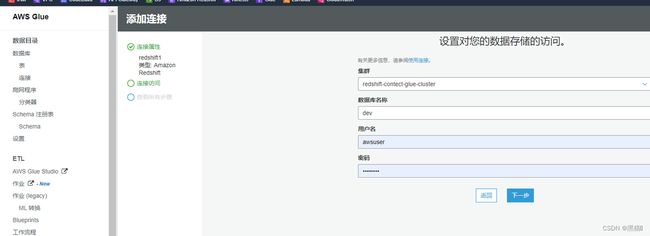 |
| 4、审核 |  |
| 5、测试连接 |  |
2.2.2 创建AWS RDS连接(以PG为例)
| 步骤 | 图例 |
|---|---|
| 1、入口 |  |
| 2 、输入连接名称,连接类型选择“JDBC” |  |
| 3、输入连接PG的JDBC,语法请看使用连接,输入用户名密码,VPC和子网需要选择PG的VPC和子网。并且至少一个选定的安全组必须为所有 TCP 端口指定自引用入站规则 |  |
| 4、检查无误后完成 |  |
2.3 创建AWS Glue Job
| 步骤 | 图例 |
|---|---|
| 1、入口 |  |
| 2、若要在Job中引入其他python包,请在安全配置里面添加作业参数:–additional-python-modules:SQLAlchemy== 1.3.16,psycopg2-binary==2.8.5(值请自定义) |  |
| 3 |  |
2.4 编写脚本
2.4.1 以AWS RedShift为例
import sys
import datetime
import boto3
import base64
from pyspark.sql import DataFrame, Row
from pyspark.context import SparkContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import *
import json
import datetime
import time
args = getResolvedOptions(sys.argv, ['TempDir','JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
sourceData = glueContext.create_data_frame.from_catalog( \
database = "【你的数据库名称】", \
table_name = "【表的名称】", \
transformation_ctx = "datasource0", \
additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
LINCAN_SHARE_PAGE = "lincan_share_page"
share_page_dot = [
("url","string","url","string"),
("ip","string","ip","string"),
("country","string","country","string"),
("city","string","city","string"),
("user_id","string","user_id","string"),
("dot_type","string","dot_type","string"),
("header","string","header","string"),
("header_appname","string","header_appname","string"),
("header_ismobile","string","header_ismobile","string"),
("header_appversion","string","header_appversion","string"),
("header_useragent","string","header_useragent","string"),
("content","string","content","string"),
("content_url","string","content_url","string"),
("content_index","string","content_index","string"),
("content_title","string","content_title","string"),
("create_time","string","create_time","timestamp")
]
def get_connect(table):
connection_options = {
"url": "jdbc:redshift://【RedShift终端节点】:5439/dev",
"user": "【RedShift用户名】",
'database': '【数据库】',
"password": "【密码】",
"dbtable":table,
"redshiftTmpDir": args["TempDir"]
}
return connection_options
class Handle:
def __init__(self,dynamic_frame):
self._time_now = datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")
self.dynamic_frame = dynamic_frame
def run(self):
raise
class SharePageDot(Handle):
def run(self):
print("start share_page dot")
def handle(rec):
message = eval(rec["logEvents.val.message"])
message["header_appname"] = message["header"]["appName"]
message["header_ismobile"] = message["header"]["isMobile"]
message["header_appversion"] = message["header"]["appVersion"]
message["header_useragent"] = message["header"]["userAgent"]
message["header"] = json.dumps(message["header"])
message["content_url"] = message["content"]["url"]
message["content_index"] = message["content"]["index"]
message["content_title"] = message["content"]["title"]
message["content"] = json.dumps(message["content"])
message["create_time"] = datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")
# message["create_time"] = time.time()
return message
self.dynamic_frame.printSchema()
mapped_dyF = Map.apply(frame = self.dynamic_frame, f = handle)
mapped_dyF.printSchema()
if not mapped_dyF:
return
applymapping0 = ApplyMapping.apply(frame = mapped_dyF, mappings = share_page_dot, transformation_ctx = "applymapping0")
datasink1 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = applymapping0, catalog_connection = "redshift", connection_options = get_connect("share_page_dot"),redshift_tmp_dir= args["TempDir"], transformation_ctx="datasink1")
print("end share_page dot")
def processBatch(data_frame, batchId):
if (data_frame.count() > 0):
print("start")
logEvents = DynamicFrame.fromDF(data_frame, glueContext, "from_data_frame").select_fields("logEvents")
dyf_relationize = logEvents.relationalize("logEvents",args["TempDir"]+"/relationalize")
dyf_selectFromCollection = SelectFromCollection.apply(dyf_relationize, 'logEvents_logEvents')
# 筛选
sac_or_mon_dyF = Filter.apply(frame = dyf_selectFromCollection, f = lambda x: x["logEvents.val.id"]!="")
# page dot
page_dot = Filter.apply(frame = sac_or_mon_dyF, f = lambda x: eval(x["logEvents.val.message"])["dot_type"]==LINCAN_PAGE_DOT)
# active dot
active_dot = Filter.apply(frame = sac_or_mon_dyF, f = lambda x: eval(x["logEvents.val.message"])["dot_type"]==LINCAN_ACTIVE_DOT)
# share page dot
share_page = Filter.apply(frame = sac_or_mon_dyF, f = lambda x: eval(x["logEvents.val.message"])["dot_type"]==LINCAN_SHARE_PAGE)
#if page_dot.count()>0 :
# PageDot(page_dot).run()
#if active_dot.count()>0:
# ActiveDot(active_dot).run()
if share_page.count()>0:
SharePageDot(share_page).run()
print("end")
glueContext.forEachBatch(frame = sourceData, batch_function = processBatch, options = {"windowSize": "100 seconds", "checkpointLocation": args["TempDir"] + "/checkpoint/"})
job.commit()
2.4.2 以PG为例
说明:在此脚本中,引入了python其他的包。写入PG使用的是sqlalchemy,是为了实现有则更新,无则写入的操作。若无特殊要求,可参考 “2.4.1”
import sys
import datetime
import boto3
import base64
from pyspark.sql import DataFrame, Row
from pyspark.context import SparkContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import *
import boto3
import json
import datetime
import time
import sqlalchemy
from sqlalchemy.ext.automap import automap_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy.dialects.postgresql import insert
from sqlalchemy.dialects import postgresql
import threading
import copy
import datetime
args = getResolvedOptions(sys.argv, ['TempDir', 'JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
sourceData = glueContext.create_data_frame.from_catalog( \
database = "【你的数据库名称】", \
table_name = "【表的名称】", \
transformation_ctx = "datasource0", \
additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
class DBWrite:
url = 'postgresql+psycopg2://【user+passsword@PG终端节点】:5432/crowd'
base = None
session = None
engine = None
@classmethod
def execute(cls):
cls.engine = sqlalchemy.create_engine(cls.url)
metadata = sqlalchemy.schema.MetaData(bind=cls.engine)
metadata.reflect(cls.engine, schema = "public")
cls.base = automap_base(metadata = metadata)
cls.base.prepare()
cls.session = sessionmaker(bind = cls.engine)
DBWrite.execute()
def processBatch(data_frame, batchId):
if (data_frame.count() > 0):
print("start",str(datetime.datetime.now()))
session = DBWrite.session()
def save_to_pg(row):
row = json.loads(row)
insert_data = {
"create_time": row["create_time"],
"update_time": row["update_time"],
"valid": True,
"crowd_type": row["crowd_type"],
"name": row["name"],
"support_num": row["support_num"],
"target_amount": row["target_amount"],
"status": row["status"],
"surplus_day": row["surplus_day"],
"crowd_category": row["crowd_category"],
"current_amount": row["current_amount"],
"address": row["address"],
"author": row["author"],
"image": row["image"],
"comment_num": row["comment_num"],
"create_data": row["create_time"][:-9],
"unique_key":row["unique_key"]
}
update_data = copy.deepcopy(insert_data)
del update_data["create_time"]
del update_data["create_data"]
Crowd = DBWrite.base.classes.crowd_crowd
insert_stmt = insert(Crowd).values(**insert_data)
insert_stmt = insert_stmt.on_conflict_do_update(
index_elements = ["unique_key"],
set_ = update_data
)
session.execute(insert_stmt)
def handle(rec):
message = rec["logEvents.val.message"]
index = message.find("|312F14DS|")
message = message[index+10:]
message = message.replace(
": true", ": True").replace(": false", ": False")
message = eval(message)
return message
logEvents = DynamicFrame.fromDF(
data_frame, glueContext, "from_data_frame").select_fields("logEvents")
dyf_relationize = logEvents.relationalize(
"logEvents", args["TempDir"]+"/relationalize")
dyf_selectFromCollection = SelectFromCollection.apply(
dyf_relationize, 'logEvents_logEvents')
# 筛选
sac_or_mon_dyF = Filter.apply(
frame=dyf_selectFromCollection, f=lambda x: x["logEvents.val.id"] != "")
mapped_dyF = Map.apply(frame=sac_or_mon_dyF, f=handle)
mapped_dyF = mapped_dyF.toDF()
for info in (mapped_dyF.toJSON().take(mapped_dyF.toJSON().count()+1)):
save_to_pg(info)
session.commit()
session.close()
print("end",str(datetime.datetime.now()))
glueContext.forEachBatch(frame=sourceData, batch_function=processBatch, options={
"windowSize": "100 seconds", "checkpointLocation": args["TempDir"] + "/checkpoint/"})
job.commit()
2.5 运行脚本
我们创建的是Spark Stream 类型的Job,因此Job会一直运行。定时的从AWS Kinesis Data Stream中获取数据进行微批量处理。

