SQLserver 索引碎片
索引碎片主要导致olap类收到影响。oltp少量数据查询只有索引高度有关。
1. rowid
默认的索引是B-树索引。索引建立在表中的一个或多个列或者是表的表达式上,将列值和行编号一起存储。行编号是唯一标记表中行的伪列。
行编号是物理表中的行数据的内部地址,包含两个地址,其一是指向数据表中包含该行的块所丰放数据文件的地址,另一个可以直接定位到数据行自身的这一行在数据块中的地址。
2. IAM
数据库表A有十万条记录,查询速度本来还可以,但导入一千条数据后,问题出现了。当选择的数据在原十万条记录之间时,速度还是挺快的;但当选择的数据在这一千条数据之间时,速度变得奇慢。这个应该不准确,插入的1千条可能全是中间数据,导致了碎片,但查询一千条中的单条是没问题的(索引层高)。
凭经验,这是索引碎片问题。检查索引碎片DBCC SHOWCONTIG(表),得到如下结果:
DBCC SHOWCONTIG 正在扫描 'A' 表...
表: 'A'(884198200);索引 ID: 1,数据库 ID: 13
已执行 TABLE 级别的扫描。
- 扫描页数.....................................: 3127
- 扫描扩展盘区数...............................: 403
- 扩展盘区开关数...............................: 1615
- 每个扩展盘区上的平均页数.....................: 7.8
- 扫描密度[最佳值:实际值]....................: 24.20%[391:1616]
- 逻辑扫描碎片.................................: 68.02%
- 扩展盘区扫描碎片.............................: 38.46%
- 每页上的平均可用字节数.......................: 2073.2
- 平均页密度(完整)...........................: 74.39%
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
由上我们看出,逻辑扫描碎片和扩展盘区扫描碎片都非常大,果真需要对索引碎片进行处理了。
一般有两种方法解决,一是利用DBCC INDEXDEFRAG整理索引碎片,二是利用DBCC DBREINDEX重建索引。二者各有优缺点。调用微软的原话如下:
DBCC INDEXDEFRAG 命令是联机操作,所以索引只有在该命令正在运行时才可用。而且可以在不丢失已完成工作的情况下中断该操作。这种方法的缺点是在重新组织数据方面没有聚集索引的除去/重新创建操作有效。
重新创建聚集索引将对数据进行重新组织,其结果是使数据页填满。填满程度可以使用 FILLFACTOR 选项进行配置。这种方法的缺点是索引在除去/重新创建周期内为脱机状态,并且操作属原子级。如果中断索引创建,则不会重新创建该索引。
也就是说,要想获得好的效果,还是得用重建索引,所以决定重建索引。
DBCC DBREINDEX(表,索引名,填充因子)
第一个参数,可以是表名,也可以是表ID。
第二个参数,如果是'',表示影响该表的所有索引。
第三个参数,填充因子,即索引页的数据填充程度。如果是100,表示每一个索引页都全部填满,此时select效率最高,但以后要插入索引时,就得移动后面的所有页,效率很低。如果是0,表示使用先前的填充因子值。
DBCC DBREINDEX(A,'',100)
重新测试查询速度,飞快。
另:一般来说填充因子使用系统默认的值即可。
DBCC SHOWCONTIG 检查碎片程度
DBCC SHOWCONTIG (Transact-SQL) - SQL Server | Microsoft Learn
1. 语法
DBCC SHOWCONTIG
[ ( { table_name | table_id | view_name | view_id } [ , index_name | index_id ] ) ]
[ WITH { [ , [ ALL_INDEXES ] ] [ , [ TABLERESULTS ] ] [ , [ FAST ] ] [ , [ ALL_LEVELS ] ] [ NO_INFOMSGS ] } ]
2. 示例
以前面的案例中,显示结果如下:
DBCC SHOWCONTIG ('person1') WITH ALL_INDEXES
====
DBCC SHOWCONTIG 正在扫描 'person1' 表...
表: 'person1' (245575913);索引 ID: 1,数据库 ID: 8
已执行 TABLE 级别的扫描。
- 扫描页数................................: 4009
- 扫描区数..............................: 502
- 区切换次数..............................: 501
- 每个区的平均页数........................: 8.0
- 扫描密度 [最佳计数:实际计数].......: 100.00% [502:502]
- 逻辑扫描碎片 ..................: 0.37%
- 区扫描碎片 ..................: 0.80%
- 每页的平均可用字节数.....................: 44.2
- 平均页密度(满).....................: 99.45%
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
4. 判断碎片化
DBCC SHOWCONTIG 可确定表是否高度碎片化。索引的碎片程度可通过以下方式确定:
(1) 比较“区切换次数”和“扫描区数”的值
“区切换次数”的值应尽可能接近于“扫描区数”的值。 此比率将作为“扫描密度”值计算。 此值应尽可能的大,可通过减少索引碎片得到改善。
(2)了解“逻辑扫描碎片”和“区扫描碎片”的值
“逻辑扫描碎片”和“区扫描碎片”(对于较小的区)的值是表的碎片级别的最好指标。 这两个值应尽可能接近零,但 0% 到 10% 之间的值都是可接受的。
优化索引维护以提高查询性能并减少资源消耗
- 项目
- 2023/01/25
- 18 个参与者
反馈
适用于: SQL Server Azure SQL DatabaseAzure SQL 托管实例Analytics Platform System (PDW)
本文可帮助你决定何时以及如何执行索引维护。 它介绍了索引碎片和页面密度等概念,以及它们对查询性能和资源消耗的影响。 它介绍了索引维护方法(即重新组织索引和重新生成索引),并推荐了一种可平衡潜在性能提升和维护所需的资源消耗的索引维护策略。
备注
本文中的信息不适用于 Azure Synapse Analytics 中的专用 SQL 池。 有关 Azure Synapse Analytics 中专用 SQL 池的索引维护的信息,请参阅为 Azure Synapse Analytics 中的专用 SQL 池表编制索引。
概念:索引碎片和页面密度
什么是索引碎片以及它对性能有怎样的影响:
-
在 B 树(行存储)索引中,当索引包含的页中,索引中的逻辑排序(基于索引中的键值)与索引页的物理排序不匹配时,就存在碎片。
备注
SQL Server 文档在提到索引时一般使用 B 树这个术语。 在行存储索引中,SQL Server 实现了 B+ 树。 这不适用于列存储索引或内存中数据存储。 有关详细信息,请查看 SQL Server 索引体系结构和设计指南。
-
每当对基础数据执行插入、更新或删除操作时,数据库引擎都会自动修改索引。 例如,在表中添加行可能会导致拆分行存储索引中的现有页,以腾出空间来插入新行。 随着时间的推移,这些修改可能会导致索引中的数据分散在数据库中(含有碎片)。
-
对于使用完全或范围索引扫描读取多个页面的查询,碎片多的索引会降低查询性能,因为读取查询所需的数据可能需要额外的 I/O。 查询可能需要大量的小型 I/O 请求来读取相同数量的数据,而不是使用少量的大型 I/O 请求。
-
存储子系统的顺序 I/O 性能优于随机 I/O 性能时,索引碎片可能会降低性能,因为读取碎片索引需要更多的随机 I/O。
什么是页面密度(也称为页面填充度)以及它对性能有怎样的影响:
- 数据库中的每个页面包含的行数可以变化。 如果行占用了页面上的所有空间,则页面密度为 100%。 如果页面是空白的,则页面密度为 0%。 如果密度为 100% 的页面拆分为两个页面以容纳新行,则这两个新页面的密度约为 50%。
- 页面密度较低时,存储相同数量的数据需要更多的页面。 这意味着,读写此数据需要更多的 I/O,缓存此数据需要更多的内存。 内存有限时,要缓存的查询所需页面较少,从而导致磁盘 I/O 增加。 因此,页面密度较低会降低性能。
- 当数据库引擎向页中添加行时,如果索引的 填充因子 设置为 100 (或 0 以外的值,则不会完全填充页面,这在此上下文中) 等效。 这会导致页面密度较低,同样会增加 I/O 开销,并降低性能。
- 页面密度较低可能会增加中间 B 树级别的数量。 这会适度增加在索引扫描和索引查找中找到查找叶级别页面的 CPU 和 I/O 开销。
- 当查询优化器编译查询计划时,会考虑读取查询所需数据需要的 I/O 开销。 页面密度较低时,需要读取的页面数量更多,因此 I/O 开销更高。 这可能会影响对查询计划的选择。 例如,页面密度因页面拆分而随时间降低时,优化器可能会使用不同的性能和资源消耗配置文件为同一查询编译其他计划。
提示
在许多工作负载中,提高页面密度会比减少碎片更能提升性能。
为避免在不必要的情况下降低页面密度,Microsoft 不建议将填充因子设置为 100 或 0 以外的值,除非索引遇到大量页面拆分,例如,包含非顺序 GUID 值的前导列并且频繁修改的索引。
度量索引碎片和页面密度
碎片和页面密度都是决定是否执行索引维护以及要使用哪种维护方法时要考虑的因素。
对于行存储和列存储索引的碎片定义有所不同。 对于行存储索引,可以通过 sys.dm_db_index_physical_stats 确定特定索引、表或索引视图上的所有索引、某个数据库中的所有索引或所有数据库中的所有索引的碎片和页面密度。 对于已分区索引,sys.dm_db_index_physical_stats() 会对每个分区提供此信息。
sys.dm_db_index_physical_stats 返回的结果集包含以下列:
| 列 | 说明 |
|---|---|
avg_fragmentation_in_percent |
逻辑碎片(索引中的无序页面)。 |
avg_page_space_used_in_percent |
平均页面密度。 |
对于列存储索引中的压缩行组,将碎片定义为已删除的行数与总行数之比,并以百分比形式表示。 可以通过 sys.dm_db_column_store_row_group_physical_stats 确定特定索引、表上的所有索引或数据库中所有索引的每个行组的总行数和已删除的行数。
sys.dm_db_column_store_row_group_physical_stats 返回的结果集包含以下列:
| 列 | 说明 |
|---|---|
total_rows |
以物理方式存储在行组中的行数。 对于压缩行组,这包括标记为已删除的行。 |
deleted_rows |
以物理方式存储在压缩行组中且标记为要删除的行数。 对于增量存储中的行组,值为 0。 |
可使用以下公式计算列存储索引中压缩行组的碎片:
SQL复制
100.0*(ISNULL(deleted_rows,0))/NULLIF(total_rows,0)
提示
对于行存储索引和列存储索引,在删除或更新大量行后检查索引或堆碎片和页面密度尤其重要。 对于堆,如果频繁进行更新,则可能也需要定期检查碎片以避免前推记录激增。 有关堆的详细信息,请参阅堆(没有聚集索引的表)。
若要获取用于确定碎片和页面密度的查询示例,请参阅示例。
索引维护方法:重新组织和重新生成
可以通过使用以下方法之一来减少索引碎片并增加页面密度:
- 重新组织索引
- 重新生成索引
备注
对于已分区索引,可以对索引的所有分区或单个分区使用以下方法之一。
重新组织索引
与重新生成索引相比,重新组织索引消耗的资源更少。 因此,应首选此索引维护方法,除非出于特定原因需要使用索引重新生成。 重新组织始终属于联机操作。 也就是说,在执行 ALTER INDEX ... REORGANIZE 操作期间不保留长期对象级锁,且对基础表的查询或更新可以继续进行。
- 对于 行存储索引,数据库引擎仅对表和视图中的聚集索引和非聚集索引的叶级别进行碎片整理,方法是对叶级页面进行物理重新排序,以匹配叶节点 (从左到右) 的逻辑顺序。 重新组织还会压缩索引页,使页面密度等于索引的填充因子。 若要查看填充因子设置,请使用 sys.indexes。 有关语法示例,请参阅示例 - 行存储重新组织。
- 如果使用列存储索引,则在一段时间内插入、更新和删除数据后,增量存储可能最终会有多个小行组。 重新组织列存储索引会强制增量存储行组移到列存储中的压缩行组,并将较小的压缩行组合并为较大的行组。 重新组织操作还会以物理方式删除列存储标记为已删除的行。 重新组织列存储索引可能需要额外的 CPU 资源来压缩数据,这可能会降低此操作运行期间的整体系统性能。 但是,一旦压缩数据后,查询性能就会提高。 有关语法示例,请参阅示例 - 列存储重新组织。
备注
从 SQL Server 2019 (15.x) 、Azure SQL Database 和 Azure SQL 托管实例 开始,元组移动器受后台合并任务帮助,该任务可自动压缩已存在一段时间的较小开放增量行组(由内部阈值确定),或合并已从中删除大量行的压缩行组。 随着时间的推移,这会提高列存储索引的质量。 在大多数情况下,此操作无需发出 ALTER INDEX ... REORGANIZE 命令。
提示
如果取消重新组织操作,或此操作因其他原因中断,则截至到该时刻它完成的进度将保留在数据库中。 若要重新组织较大的索引,可以多次启动和停止该操作,直到此操作完成。
重新生成索引
重新生成索引将会删除并重新创建索引。 重新生成操作可以脱机或联机执行,具体取决于索引类型和数据库引擎版本。 脱机索引重新生成耗费的时间通常比联机重新生成少,但它会在重新生成操作持续期间保留对象级锁,阻止查询访问表或视图。
联机索引重新生成操作结束时才需要对象级锁,届时必须将锁短暂保留一段时间,重新生成才能完成。 联机索引重新生成可以作为可恢复的操作启动,具体取决于数据库引擎的版本。 可恢复的索引重新生成操作可以暂停,并保留截至到该时刻完成的进度。 可恢复的重新生成操作可以在暂停或中断后恢复,也可在无需完成重新生成时中止。
有关 Transact-SQL 语法,请参阅 ALTER INDEX REBUILD。 有关联机索引重新生成操作的详细信息,请参阅联机执行索引操作。
备注
索引执行联机重新生成时,对索引列中数据的每个修改都必须更新该索引的其他副本。 这可能会导致数据修改语句的性能在执行联机重新生成期间略微下降。
可恢复的联机索引操作暂停时,这会继续影响此性能,直到此可恢复的操作完成或中止。 如果不打算完成可恢复的索引操作,请将其中止,而不要暂停它。
提示
根据可用资源数和工作负载模式,在 ALTER INDEX REBUILD 语句中指定高于默认 MAXDOP 值的值,这样可能会缩短重新生成操作的持续时间,但会增加 CPU 消耗。
-
对于行存储索引,重新生成会消除索引的所有级别中的碎片,并根据指定的或当前的填充因子来压缩页面。 如果指定
ALL,将通过单个操作删除表中的所有索引并重新生成它们。 重新生成具有 128 个或更多盘区的索引时,数据库引擎会延迟页面解除分配并获取关联的锁,直到重新生成完成。 有关语法示例,请参阅示例 - 行存储重新生成。 -
对于列存储索引,重新生成会消除碎片,将任何增量存储行移到列存储中,并以物理方式删除标记为已删除的行。 有关语法示例,请参阅示例 - 列存储重新生成。
提示
从 SQL Server 2016 (13.x) 开始,通常不需要重新生成列存储索引,因为
REORGANIZE以联机操作的形式执行重新生成的基本内容。
使用索引重新生成从数据损坏中恢复
在早期版本的 SQL Server 中,有时可以重新生成行存储非聚集索引,以更正由于索引中的数据损坏而导致的不一致。
从 SQL Server 2008 (10.0.x) 开始,你仍可以通过脱机重新生成非聚集索引来修复非聚集索引中的此类不一致。 但是,你不能通过联机重新生成索引来纠正非聚集索引的不一致,因为联机重新生成机制会使用现有的非聚集索引作为重新生成的基础,因此仍存在不一致。 脱机重新生成索引有时可以强制扫描聚集索引(或堆),进而将非聚集索引中的不一致数据替换为聚集索引或堆中的数据。
若要确保将聚集索引或堆用作数据源,请删除并重新创建非聚集索引,而不要重新生成它。 与早期版本一样,建议通过从备份还原受影响的数据来从不一致问题进行恢复;但是,可以通过脱机重新生成或重新创建非聚集索引来纠正非聚集索引的不一致数据。 有关详细信息,请参阅 DBCC CHECKDB (Transact-SQL)。
自动索引和统计信息管理
利用自适应索引碎片整理等解决方案,自动管理一个或多个数据库的索引碎片和统计信息更新。 此过程根据碎片级别以及其他参数,自动选择是重新生成索引还是重新组织索引,并使用线性阈值更新统计信息。
有关重新生成和重新组织行存储索引的注意事项
以下场景会导致自动在表上重新生成所有行存储非聚集索引:
- 在表上创建聚集索引,包括通过
CREATE CLUSTERED INDEX ... WITH (DROP_EXISTING = ON)使用不同的键重新创建聚集索引 - 删除聚集索引,从而使表存储为堆
以下场景不会自动在同一个表上重新生成所有行存储非聚集索引:
- 重新生成聚集索引
- 更改聚集索引存储,例如应用分区方案或将聚集索引移到其他文件组
重要
如果索引所在的文件组处于脱机或只读状态,便无法重新组织或重新生成索引。 如果指定了关键字 ALL,但有一个或多个索引位于脱机文件组或只读文件组中,该语句将失败。
当索引重新生成发生时,物理介质必须有足够的空间来存储索引的两个副本。 重新生成完成后,数据库引擎将删除原始索引。
如果使用 ALTER INDEX ... REORGANIZE 语句指定了 ALL,表上的聚集索引、非聚集索引和 XML 索引都会进行重新组织。
重新生成或重新组织小型行存储索引可能不会减少碎片。 在 2014 (12.x) (包括 2014 SQL Server)中,SQL Server数据库引擎使用混合盘区分配空间。 因此,小型索引的页面有时存储在混合区上,这会让这类索引隐式产生碎片。 混合区最多可由八个对象共享,因此在重新组织或重新生成小索引之后可能不会减少小索引中的碎片。
有关重新生成列存储索引的注意事项
重新生成列存储索引时,数据库引擎将从原始列存储索引中读取所有数据,包括增量存储。 它将数据合并为新的行组,并将所有行组压缩到列存储中。 数据库引擎以物理方式删除标记为已删除的行,对列存储进行碎片整理。
备注
从 SQL Server 2019 (15.x) 开始,元组移动器受后台合并任务帮助,该任务可自动压缩已存在一段时间的小型开放增量存储行组(由内部阈值确定),或合并已删除大量行的压缩行组。 随着时间的推移,这会提高列存储索引的质量。 有关列存储术语和概念的详细信息,请参阅列存储索引:概述。
重新生成分区,而不是整个表
如果索引很大,则重新生成整个表将需要很长时间,并且在执行重新生成期间需要足够的磁盘空间来存储整个索引的额外副本。
对于已分区表,如果只有某些分区(例如,UPDATE、DELETE 或 MERGE 语句影响了其中许多行的分区)中存在碎片,则你不需要重新生成整个列存储索引。
在加载或修改数据后重新生成分区,这样可确保所有数据都存储在列存储中的压缩行组中。 当数据加载进程使用小于 102,400 行的批将数据插入分区时,该分区最终可能会在增量存储中出现多个打开的行组。 重新生成会将所有增量存储行移到列存储中的压缩行组。
有关重新组织列存储索引的注意事项
重新组织列存储索引时,数据库引擎会将增量存储中的每个已关闭行组作为压缩行组压缩到列存储中。 从 SQL Server 2016 (13.x) 开始,在 Azure SQL Database 中, REORGANIZE 命令将联机执行以下附加的碎片整理优化:
- 在逻辑删除了 10% 或更多行时从行组中物理移除行。 例如,如果包含 100 万行的压缩行组删除了 100,000 行,则数据库引擎将删除已删除的行并重新压缩包含 900,000 行的行组,从而减少存储占用空间。
- 合并一个或多个压缩行组,以将每个行组的行增加到最多 1,048,576 行。 例如,如果大容量插入 5 个分别具有 102,400 行的批,将获得 5 个压缩行组。 如果你运行 REORGANIZE,这些行组将合并到一个具有 512,000 行的压缩行组中。 这假定不存在任何字典大小或内存限制。
- 数据库引擎尝试合并行组,其中 10% 或更多行已与其他行组一起标记为已删除。 例如,行组 1 已压缩且具有 500,000 行,而行组 21 未压缩且具有 1,048,576 行。 行组 21 已将其 60% 的行标记为已删除,它还剩余 409,830 行。 数据库引擎倾向于组合这两个行组,以压缩包含 909,830 行的新行组。
在执行数据加载后,增量存储中可能会有多个小型行组。 可以使用 ALTER INDEX REORGANIZE 强制这些行组移到列存储,然后将较小的压缩行组合并为较大的压缩行组。 重新组织操作还将删除列存储标记为已删除的行。
备注
使用 Management Studio 重新组织列存储索引会将压缩的行组组合在一起,但不强制将所有行组压缩到列存储中。 将压缩关闭的行组,但不会将开放的行组压缩到列存储中。 若要强制压缩所有行组,请使用包含 COMPRESS_ALL_ROW_GROUPS = ON的 Transact-SQL 示例。
执行索引维护之前要考虑的事项
索引维护通过重新组织或重新生成索引实现,它需要消耗大量资源。 这会导致 CPU 消耗、内存占用量和存储 I/O 大幅增加。 但是,它带来的好处可能意义重大,也可能微不足道,具体取决于数据库工作负载和其他因素。
为避免产生可能不利于查询工作负载的不必要资源消耗,Microsoft 不建议任意执行索引维护。 相反,应使用建议的策略根据经验确定每个工作负载可通过执行索引维护获得的性能提升,并将这些提升与获得它们需产生的资源成本和对工作负载的影响进行权衡。
当索引碎片较多或其页面密度较低时,更有可能认可重新组织或重新生成索引带来的性能提升。 但是,这并不是要考虑的唯一因素。 查询模式(事务处理与分析和报告)、存储子系统行为、可用内存和数据库引擎随时间的改进情况等因素都很重要。
重要
决定执行索引维护之前,应在每个工作负载的特定上下文下考虑多个因素,其中包括维护的资源成本。 不应仅根据固定的碎片或页面密度阈值做出这些决策。
索引重新生成的积极影响
客户通常会发现,重新生成索引后性能得到提升。 但在许多情况下,这些提升与碎片减少或页面密度增加无关。
索引重新生成具有一个重大的好处:它会通过扫描索引中的所有行来更新索引键列的统计信息。 此操作等同于执行 UPDATE STATISTICS ... WITH FULLSCAN,与默认的采样式统计信息更新相比,它会让统计信息保持最新,有时它还会提高统计信息的质量。 统计信息更新时,引用这些统计信息的查询计划将重新编译。 如果由于统计信息陈旧、统计采样率不够高或者其他原因,导致以前的查询计划的性能不佳,那么重新编译的计划通常性能会更高。
客户通常会错误地将此提升归因于索引重新生成本身,将其视为碎片降低和页面密度增加的结果。 实际上,通常通过更新统计信息能以更低的资源成本获得同样的提升,而不必重新生成索引。
提示
与索引重新生成相比,更新统计信息消耗的资源成本很少,并且此操作通常几分钟内 便可完成,而索引重新生成可能需要数小时。
索引维护策略
Microsoft 建议客户考虑并采用以下索引维护策略:
- 不要假定索引维护始终会显著改进工作负载。
- 衡量重新组织或重新生成索引对工作负载的查询性能的特定影响。 可通过查询存储使用 A/B 测试技术衡量“维护前”和“维护后”的性能。
- 如果发现重新生成索引会提高性能,请尝试将其替换为更新统计信息。 这样可能会获得相似的提升。 在这种情况下,你可能不需要那么频繁地(或完全不需要)重新生成索引,而可以改为定期执行统计信息更新。 若要获得某些统计信息,你可能需要使用
WITH SAMPLE ... PERCENT或WITH FULLSCAN子句提高采样率(这种情况并不常见)。 - 随着时间的推移监视索引碎片和页面密度,以确定这些值的升降与查询性能是否相关。 如果增加碎片或降低页面密度导致性能下降到让人无法接受的程度,则重新组织或重新生成索引。 通常,重新组织或重新生成性能下降的查询所使用的特定索引即可。 这样就不必因维护数据库中每个索引产生更高的资源成本。
- 通过在碎片/页面密度和性能之间建立关联,你还可以确定维护索引的频率。 不要假定必须按固定计划执行维护。 更好的策略是监视碎片和页面密度,并在性能下降到不可接受的程度前根据需要运行索引维护。
- 如果已确定需要维护索引并且可接受其资源成本,则在资源使用率低的时段(如果存在这样的时段)内执行维护,并牢记资源使用模式可能会随时间而变化。
Azure SQL 数据库和Azure SQL 托管实例中的索引维护
除了上述注意事项和策略外,在Azure SQL数据库和Azure SQL 托管实例考虑索引维护的成本和优势尤为重要。 只有考虑了以下几点事项并证明需要执行此操作后,客户才应执行此操作。
- Azure SQL数据库和Azure SQL 托管实例实现资源治理,以根据预配的定价层设置 CPU、内存和 I/O 消耗的边界。 这些限制适用于所有用户工作负载,包括索引维护。 当所有工作负载的累计资源消耗接近资源限制时,其他工作负载的性能可能会因重新生成或重新组织操作争用资源而下降。 例如,由于并发的索引重新生成操作,事务日志 I/O 达到 100%,导致大批量加载速度变慢。 在Azure SQL 托管实例中,通过在资源分配受限的单独Resource Governor工作负荷组中运行索引维护来减少这种影响,但代价是延长索引维护持续时间。
- 为减少成本,客户通常会为数据库、弹性池和托管实例预配最少的资源空余空间。 客户会选择足以满足应用程序工作负载需求的定价层。 若要应对索引维护导致的资源使用量大幅增长同时不降低应用程序性能,客户可能需要预配更多的资源并增加成本,但这不一定会提高应用程序性能。
- 在弹性池中,资源由池中的所有数据库共享。 即使特定数据库处于空闲状态,在该数据库上执行索引维护也可能会影响同一个池中其他数据库内并发运行的应用程序工作负载。 有关详细信息,请参阅密集弹性池中的资源管理。
- 对于 Azure SQL Database 和 Azure SQL 托管实例 中使用的大多数存储类型,顺序 I/O 和随机 I/O 的性能没有差异。 这会降低索引碎片对查询性能的影响。
- 如果在使用读取扩展或异地复制副本,则在主要副本上执行索引维护时,这些副本上的数据延迟通常会增加。 如果为异地副本预配的资源量不足以支撑索引维护导致的事务日志生成的增长,则异地副本可能会远远滞后于主副本,并导致系统重设它的种子。 这会导致此副本在重设种子完成前不可用。 此外,在“高级”和“业务关键”服务层中,用于实现高可用性的副本可能同样会在执行索引维护期间远远落后于主副本。 如果在索引维护执行期间或完成不久后需要执行故障转移,则故障转移所需的时间可能会超出预期。
- 如果索引重新生成在主要副本上运行,并且一个长时间运行的查询同时在可读副本上执行,则查询可能会自动终止,以防止阻塞副本上的重做线程。
在 Azure SQL Database 和 Azure SQL 托管实例 中可能需要一次性或定期索引维护时,存在一些特定但罕见的情况:
- 要增加数据库的页面密度并减少其已用空间大小,进而将其保持在定价层的大小限制范围之内,此时可能需要执行索引维护。 这样就无需扩展到大小限制更大的更高定价层。
- 如果需要收缩数据文件,则在收缩文件之前重新生成或重新组织索引可增加页面密度。 这样可提高收缩操作的运行速度,因为它需要移动的页面减少。
提示
如果已确定Azure SQL数据库和Azure SQL 托管实例工作负荷需要索引维护,则应重新组织索引,或使用联机索引重新生成。 这样做时,查询工作负载可以在重新生成索引期间访问表。
此外,让此操作可恢复,这样就不必在计划或计划外的数据库故障转移中断此操作时重头开始重启该操作。 当索引较大时,使用可恢复的索引操作尤为重要。
提示
脱机索引操作通常比联机操作更快完成。 只有查询将无法在执行脱机索引操作期间访问表时(例如通过顺序 ETL 进程将数据加载到临时表后),才能使用此操作。
限制和局限
盘区超过 128 个的行存储索引通过两个单独的阶段重新生成:逻辑阶段和物理阶段。 在逻辑阶段,将把由索引使用的现有分配单元标记为释放,对数据行进行复制并排序,然后将它们移到为存储重新生成的索引而创建的新分配单元。 在物理阶段,先前标记为取消分配的分配单元在发生在后台的短事务中被物理删除,而且不需要很多锁。 有关分配单元的详细信息,请参阅页和区体系结构指南。
ALTER INDEX REORGANIZE 语句要求包含索引的数据文件具有可用的空间,因为该操作仅可在同一文件中分配临时工作,而不能在同一个文件组内的另一个文件中进行分配。 尽管文件组可能有可用空间,当数据文件空间不足时,用户仍会在执行重新组织操作期间遇到错误 1105:Could not allocate space for object '###' in database '###' because the '###' filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup。
当 ALLOW_PAGE_LOCKS 设置为 OFF 时,无法重新组织索引。
截至 2017 SQL Server (14.x) ,重新生成聚集列存储索引是脱机操作。 在重新生成时,数据库引擎必须获取表或分区上的独占锁。 即使在使用 NOLOCK、读取已提交的照隔离 (RCSI) 或快照隔离时,数据在重新生成期间仍处于脱机状态且不可用。 从 2019 SQL Server (15.x) 开始,可以使用 选项重新生成ONLINE = ON聚集列存储索引。
警告
对超过 1,000 个分区的表创建和重新生成非对齐索引是可能的,但不支持。 这样做可能会导致性能下降,或在执行这些操作的过程中占用过多内存。 Microsoft 建议,当分区数超过 1,000 时,只使用对齐索引。
统计信息限制
- 创建或重新生成索引时,将通过扫描表中的所有行创建或更新统计信息,这等同于在
CREATE STATISTICS或UPDATE STATISTICS中使用FULLSCAN子句。 但是,从 2012 SQL Server 2012 (11.x) 开始,创建或重新生成分区索引时,不会通过扫描表中的所有行来创建或更新统计信息。 而会改为使用默认采样率。 若要通过扫描表中所有行的方法创建或更新已分区索引上的统计信息,请使用 CREATE STATISTICS 或 UPDATE STATISTICS 以及FULLSCAN子句。 - 同样,当索引创建或索引重新生成操作可恢复时,将使用默认采样率来创建或更新统计信息。 如果创建或上次更新统计信息时将
PERSIST_SAMPLE_PERCENT子句设置为了ON,则可恢复索引操作将使用所保留的采样率来创建或更新统计信息。 - 重新组织索引后,统计信息不会更新。
示例
使用 Transact-SQL 检查行存储索引的碎片和页面密度
下面的示例可确定当前数据库中所有行存储索引的平均碎片和页面密度。 它通过 SAMPLED 模式快速返回可操作的结果。 若要获得更准确的结果,请使用 DETAILED 模式。 这需要扫描所有索引页面,并且可能需要很长时间。
SQL复制
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_fragmentation_in_percent,
ips.avg_page_space_used_in_percent,
ips.page_count,
ips.alloc_unit_type_desc
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
上一语句返回如下的结果集:
复制
schema_name object_name index_name index_type avg_fragmentation_in_percent avg_page_space_used_in_percent page_count alloc_unit_type_desc
------------ --------------------- ---------------------------------------- ------------- ---------------------------- ------------------------------ ----------- --------------------
dbo FactProductInventory PK_FactProductInventory CLUSTERED 0.390015600624025 99.7244625648629 3846 IN_ROW_DATA
dbo DimProduct PK_DimProduct_ProductKey CLUSTERED 0 89.6839757845318 497 LOB_DATA
dbo DimProduct PK_DimProduct_ProductKey CLUSTERED 0 80.7132814430442 251 IN_ROW_DATA
dbo FactFinance NULL HEAP 0 99.7982456140351 239 IN_ROW_DATA
dbo ProspectiveBuyer PK_ProspectiveBuyer_ProspectiveBuyerKey CLUSTERED 0 98.1086236718557 79 IN_ROW_DATA
dbo DimCustomer IX_DimCustomer_CustomerAlternateKey NONCLUSTERED 0 99.5197553743514 78 IN_ROW_DATA
有关详细信息,请参阅 sys.dm_db_index_physical_stats。
使用 Transact-SQL 检查列存储索引的碎片的具体步骤
下面的示例可确定当前数据库中具有压缩行组的所有列存储索引的平均碎片。
SQL复制
SELECT OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
100.0 * (ISNULL(SUM(rgs.deleted_rows), 0)) / NULLIF(SUM(rgs.total_rows), 0) AS avg_fragmentation_in_percent
FROM sys.indexes AS i
INNER JOIN sys.dm_db_column_store_row_group_physical_stats AS rgs
ON i.object_id = rgs.object_id
AND
i.index_id = rgs.index_id
WHERE rgs.state_desc = 'COMPRESSED'
GROUP BY i.object_id, i.index_id, i.name, i.type_desc
ORDER BY schema_name, object_name, index_name, index_type;
上一语句返回类似如下的结果集:
复制
schema_name object_name index_name index_type avg_fragmentation_in_percent
------------ ---------------------- ------------------------------------ ------------------------- ----------------------------
Sales InvoiceLines NCCX_Sales_InvoiceLines NONCLUSTERED COLUMNSTORE 0.000000000000000
Sales OrderLines NCCX_Sales_OrderLines NONCLUSTERED COLUMNSTORE 0.000000000000000
Warehouse StockItemTransactions CCX_Warehouse_StockItemTransactions CLUSTERED COLUMNSTORE 4.225346161484279
使用 SQL Server Management Studio 维护索引
重新组织或重新生成索引
- 在“对象资源管理器”中,展开包含要重新组织索引的表的数据库。
- 展开 “表” 文件夹。
- 展开要为其重新组织索引的表。
- 展开 “索引” 文件夹。
- 右键单击要重新组织的索引,然后选择 “重新组织” 。
- 在 “重新组织索引” 对话框中,确认正确的索引位于 “要重新组织的索引” 网格中,然后单击 “确定” 。
- 选中 “压缩大型对象列数据” 复选框,以指定也压缩所有包含大型对象 (LOB) 数据的页。
- 单击“确定” 。
重新组织表中的所有索引
- 在“对象资源管理器”中,展开包含您要重新组织索引的表的数据库。
- 展开 “表” 文件夹。
- 展开要为其重新组织索引的表。
- 右键单击 “索引” 文件夹,然后选择 “全部重新组织” 。
- 在 “重新组织索引” 对话框中,确认正确的索引位于 “要重新组织的索引” 中。 若要从 “要重新组织的索引” 网格中删除索引,请选择该索引,再按 Delete 键。
- 选中 “压缩大型对象列数据” 复选框,以指定也压缩所有包含大型对象 (LOB) 数据的页。
- 单击“确定” 。
使用 Transact-SQL 维护索引
备注
有关使用 Transact-SQL 重新生成或重新组织索引的更多示例,请参阅 ALTER INDEX 示例 - 行存储索引 和 ALTER INDEX 示例 - 列存储索引。
重新组织某个索引
下面的示例重新组织 AdventureWorks2016 数据库中 HumanResources.Employee 表内的 IX_Employee_OrganizationalLevel_OrganizationalNode 索引。
SQL复制
ALTER INDEX IX_Employee_OrganizationalLevel_OrganizationalNode
ON HumanResources.Employee
REORGANIZE;
下面的示例重新组织 AdventureWorksDW2016 数据库中 dbo.FactResellerSalesXL_CCI 表内的 IndFactResellerSalesXL_CCI 列存储索引。
SQL复制
-- This command will force all closed and open row groups into columnstore.
ALTER INDEX IndFactResellerSalesXL_CCI
ON FactResellerSalesXL_CCI
REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
重新组织表中的所有索引
下面的示例重新组织 AdventureWorks2016 数据库中 HumanResources.Employee 表内的所有索引。
SQL复制
ALTER INDEX ALL ON HumanResources.Employee
REORGANIZE;
重新生成索引
下面的示例在 AdventureWorks2016 数据库的 Employee 表中重新生成单个索引。
SQL复制
ALTER INDEX PK_Employee_BusinessEntityID ON HumanResources.Employee
REBUILD
;
重新生成表中的所有索引
下面的示例使用 ALL 关键字重新生成所有与 AdventureWorks2016 数据库中的表关联的索引。 其中指定了三个选项。
SQL复制
ALTER INDEX ALL ON Production.Product
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON,
STATISTICS_NORECOMPUTE = ON)
;
有关详细信息,请参阅 ALTER INDEX。
原文:Microsoft SQL Server 2000 Index Defragmentation Best Practices
来源:Microsoft TechNet
作者:Mike Ruthruff
时间:February 2003
Summary As Microsoft SQL Server 2000 maintains indexes to reflect updates to their underlying tables, these indexes can become fragmented. Depending on workload characteristics, this fragmentation can ......
--------------------------------------------------------------------------------
摘要 既然SQL Server 2000为了反应数据的更新,需要维护表上的索引,因而这些索引会形成碎片。根据工作量的特征,这些碎片会影响对应的工作性能。该白皮书提供能帮助你决定是否需要整理碎片以改善性能的信息。SQL Server 2000提供了一些命令来实现索引的碎片整理。这里比较其中两个命令:DBCC DBREINDEX 和 DBCC INDEXDEFRAG。
目录
概述
了解碎片
整理碎片前需要考虑的因素
小规模环境 vs. 大规模环境
决定何时进行索引碎片整理
DBCC DBREINDEX vs. DBCC INDEXDEFRAG
结论
更多信息
附录 A: 测试环境
概述
本白皮书提供在生产环境中,决定是否进行索引的碎片整理工作以改善工作性能的信息。另外,本文比较了Microsoft SQL Server 2000中用于索引碎片整理的两个命令:DBCC DBREINDEX 和 DBCC INDEXDEFRAG。这个比较包括不同的数据库和硬件环境的测试结果。关于测试环境,请见章节"小规模环境 vs. 大规模环境"和附录A。
注意: 并不是在任何情况下,碎片整理都会改善性能。每个场景是不同的。也因为如此,所以是否要进行碎片整理工作要根据分析结果而定。
白皮书叙述索引碎片整理的重要性以及常规处理流程。下面列举本文的关键观点:
在索引碎片整理前,请确保系统资源的一些问题,比如物理磁盘碎片,不合理的基础结构等因素会给性能带来负面影响。
DBCC SHOWCONTIG可以显示索引碎片数量。当运行该命令时,要特别注意逻辑碎片(Logical Fragmentation)和页密度(Page Density)两个指标。
决定是否要碎片整理,考察工作类型很重要。不是所有情况下,都能从碎片整理中受益。对读取比较多的工作类型来说,磁盘I/O是最重要的性能指标。测试显示决策支持系统(DSS: Decision Support System)比很多在线事务处理系统(OLTP: Online Transaction Processing),从碎片整理中获益更多。
碎片将影响磁盘性能和SQL Server预读管理(read-ahead manager)的效果。Windows性能监视器有几个关键指标可以用来支持这一观点。
决定是否用 DBCC DBREINDEX 还是 DBCC INDEXDEFRAG 取决于你的需求以及硬件环境。
DBCC DBREINDEX会带来更新统计(updating statistics)的副作用,而DBCC INDEXDEFRAG不会。可以通过在执行DBCC INDEXDEFRAG后执行UPDATE STATISTICS来增加其影响。
了解碎片
当索引所在页面的基于主关键字的逻辑顺序,和数据文件中的物理顺序不匹配时,碎片就产生了。(这里的碎片SSD后还有影响吗,或者都在buffer中的话)所有的叶级页包含了指向前一个和后一个页的指针。这样就形成一个双链表。理想情况下,数据文件中页的物理顺序会和逻辑顺序匹配。整个磁盘的工作性能在物理顺序匹配逻辑顺序时将显著提升。对某些特定的查询而言,这将带来极佳的性能。当物理排序和逻辑排序不匹配时,磁盘的工作性能会变得低效,这是因为磁头必须向前和向后移动来查找索引,而不是只象某个单一方向来搜索。碎片会影响I/O性能,不过对于位于SQL Server数据缓冲内的数据页而言,碎片并不会带来任何影响。
当索引第一次创建时,没有或者只有极少碎片。随着时间推移,插入,更新和删除数据,和这些数据相关的索引上的碎片就增加了(主要还是原有页面存不下,新开了一个页)。为了整理碎片,SQL Server提供如下命令:
CREATE INDEX后的DROP INDEX命令
不带DROP_EXISTING选项的CREATE INDEX命令
DBCC INDEXDEFRAG
DBCC DBREINDEX
本文用 DBCC INDEXDEFRAG 和 DBCC DBREINDEX 命令来进行测试。这些命令都可以在在线和离线场景下执行。DBCC DBREINDEX按照CREATE INDEX的方式创建索引;因此DBCC DBREINDEX的执行结果和用CREATE INDEX命令的结果很相似。上面所有这些命令的测试结果和功能描述会在本文后面提到。
整理碎片前需要考虑的因素
系统资源问题
在索引碎片整理之前,要确认系统任何性能问题和系统资源限制无关。关于这方面的详细讨论已经超出了本文的范围,不过有些更常见的资源问题和I/O子系统性能,内存使用以及CPU使用率相关。关于分析这些类型资源问题的更深入讨论,请见本文最后的“更多的信息”章节。
物理磁盘碎片
在某些系统上,磁盘碎片会带来很糟的性能。要确定是否存在磁盘碎片,可以使用Microsoft Windows自带的系统工具,或者第三方提供的工具来分析SQL Server所在的分区。对于常规的I/O子系统上的规模较小的数据库,建议在运行索引碎片整理工具前,先进行磁盘碎片整理。而对于更智能的磁盘子系统上的规模较大的数据库,例如SAN(存储区域网络 storage area networks)环境,磁盘碎片整理就不是必要的。(windows 2000 年代才要磁盘整理)
执行情况较差的查询
当考察任何性能相关问题时,你必须能识别出那些查询执行效率较差。这里讨论的一些信息在后面也会用到,这些信息用于决定那些索引碎片将被整理。
可以使用SQL Profiler(事件探查器)来识别执行效率差的查询(关于这方面更多的信息,请参考SQL Server联机帮助的"SQL Profiler"主题)。运行SQL Profiler会带来开销;不过,只监控下面介绍的一些事件可以收集到必要的信息,而且对性能的影响尽可能的小(一般来说,小于10%的CPU使用率,当然有根据情况有些差异)。
SQL Profiler提供了一个名叫SQLProfilerTSQL_Duration的跟踪模板,可以捕获相关的事件。可以很快捷地利用它来识别执行效率较差的查询。也可以手工创建SQL Profiler跟踪来捕获下述事件:
TSQL: SQLBatchCompleted
Stored Procedures: RPC:Completed
运行SQL Profiler的时间长度要根据服务器工作量而定。为了让跟踪更有效,需要选择代表性的任务类型,至少应该选择那些能显示性能低下的工作类型。当跟踪被捕获后,检场跟踪日志中持续时间那列数据。该列数据以毫秒为单位,表示每个批处理或者查询运行需要的时间。
标识出引起性能最差的查询
这里列举能够标识出造成最糟糕性能的查询的一些建议:
按查询持续时间对跟踪进行分组。将注意力首先放在前10个最差的查询上。
如果在应用中大量使用了存储过程,考虑使用SQLProfilerSP_Counts模板来标识被调用最多的那些存储过程。将注意力放在被调用最频繁,同时也是引起较差性能的存储过程。
将收集的数据放到SQL Server表中。这样,就可以通过查询表来对工作性能进行更为详细的分析(例如,平均运行时间,最大运行时间,等等)。
基础结构
当找出运行时间最长,性能最差得查询后,必须确保数据库基础架构对于那个查询来说是最优的。例如确保存在适当的索引并且被那个查询正确地使用了。可以使用查询分析器来显示和检查查询计划,以发现在查询任务中那些索引被用到了。当使用查询分析器图形化显示查询的执行计划时,以前的数据会以警告的方式标识(例如表名会以红色字体显示)。在整理碎片之前要解决这些问题。
检查查询计划时,要牢记以下建议:
找到执行计划中开销较大的步骤。这些步骤是查询中最耗时的部分。解决这些步骤带来的问题将会使性能大幅提高。
找出执行索引扫描的步骤。索引扫描是从碎片整理中获利最大的部分。注意那些性能较差的查询索引扫描中用到的索引,在碎片整理的时候可以集中在这些索引上进行。
利用SQL Profiler中捕获的跟踪信息,以及手工从查询计划中获取的信息,就可以使用索引向导(Index Tuning Wizard)来分析工作量。利用索引想到生成的报表来决定是否要对基础结构做改动。在碎片整理前做完这些改动。
小规模环境 vs. 大规模环境
这里做的测试基于两台服务器,两台服务器之间的I/O子系统相差很大。一台服务器代表小规模环境,而另一台代表大规模环境。用来解释测试结果,每台环境的规格如下。
小规模环境
在小规模环境中,数据库大小在10GB-20GB之间。数据分布再两个物理磁盘上,tempdb和数据库日志分别在两个使用RAID 0的额外磁盘上。DSS数据库包含两个文件组,每个文件组内有一个文件。OLTP数据库只包含一个文件组,文件组内有一个数据文件。
大规模环境
Micorosoft和Hitachi Data System系统配合,可以用Hitachi Freedom Storage Lightning 9900 Series Lightning 9960 system来构建SAN环境,用于存储数据。用于测试的那个数据库大小大约为1TB。数据分散在64个物理磁盘上,使用RAID1+0结构。存储数据的磁盘由8个LUNs(Logical Unit Numbers)连接,数据库包含一个文件组,该文件组中包含8个数据文件。tempdb和数据库日志单独放在一组磁盘上,与数据文件隔离开,48个磁盘用于存放tempdb,而日志分布在8个磁盘上。为了快速备份和恢复有碎片的数据库镜像,在SAN中维护中有两个Hitachi ShadowImage拷贝数据/日志备份,Lightning 9960系统用于同步在线数据和ShadowImage备份数据。在该环境中,重复在三个碎片级别上运行两次,因为大容量的存储需要维护每个级别(大约1.4TB)的备份。
索引碎片整理对性能的影响
测试结果在后面会详细讨论。但是,虽然碎片整理对两个环境(小规模和大规模)环境都带来负面影响,但是无疑对大规模环境的影响要小得多。因为大规模环境从SAN中获取了极高的I/O性能,因此这个结论应该是对的:数据不光分散在多个磁盘上,而且SAN还提供16GB的数据缓冲区。I/O benchmark测试显示创建1TB数据量,最大的读取速度为354 MB/sec, 而小规模环境下只有71 MB/sec。
注意: 这些数值会根据各人的实现步骤和存储配置而变。
显然,高性能的I/O子系统对SQL Server性能十分有利,不过,索引碎片整理的确会对所有系统带来性能的提升。当创建数据库时,要谨慎考虑I/O子系统,并确保尽可能将日志文件和数据库数据文件隔离开。
决定何时进行索引碎片整理
决定何时进行索引碎片整理时,请考虑以下重要的建议:
标识有碎片的索引。
了解何种任务会从碎片整理中获利。
确定查询的I/O性能。
理解碎片整理带来的影响和SQL Server预读管理器。
/***************************************************************************************/
下一节中,测试的结果可以用来帮助理解这些建议。
使用 DBCC SHOWCONTIG 来标识有碎片的索引
在决定何时进行碎片整理前,必须先确定那些索引有碎片。DBCC SHOWCONTIG可以用于衡量索引上的碎片程度和页密度级别(Page Density level)。
下面是运行 DBCC SHOWCONTIG 后的得到的示例信息:
DBCC SHOWCONTIG scanning 'table_1' table...
Table: 'table_1' (453576654); index ID: 1, database ID: 8
TABLE level scan performed.
- Pages Scanned................................: 48584
- Extents Scanned..............................: 6090
- Extent Switches..............................: 12325
- Avg. Pages per Extent........................: 8.0
- Scan Density [Best Count:Actual Count].......: 49.27% [6073:12326]
- Logical Scan Fragmentation ..................: 10.14%
- Extent Scan Fragmentation ...................: 32.74%
- Avg. Bytes Free per Page.....................: 1125.2
- Avg. Page Density (full).....................: 86.10%
DBCC SHOWCONTIG scanning 'table_1' table...
Table: 'table_1' (453576654); index ID: 2, database ID: 8
LEAF level scan performed.
- Pages Scanned................................: 41705
- Extents Scanned..............................: 5221
- Extent Switches..............................: 6094
- Avg. Pages per Extent........................: 8.0
- Scan Density [Best Count:Actual Count].......: 85.55% [5214:6095]
- Logical Scan Fragmentation ..................: 7.80%
- Extent Scan Fragmentation ...................: 6.63%
- Avg. Bytes Free per Page.....................: 877.7
- Avg. Page Density (full).....................: 83.20%
检查DBCC SHOWCONTIG运行后的结果时,需要特别留意Logical Scan Fragmentation和Average Page Density。Logic scan fragmentattion表示索引上乱序的百分比(注意: 该数值和堆和文本索引不相关。所谓堆表示一个没有聚集索引的表。)。Page density是索引叶级页填充程度的度量。请查找SQL Server联机帮助的“DBCC SHOWCONTIG”主题以获取更多信息。
分析DBCC SHOWCONTIG的输出结果
在分析DBCC SHOWCONTIG的输出结果时,请考虑下面问题:
碎片会影响I/O。因此,要集中关注较大的索引,因为这些索引被SQL Server放入缓存的可能性比较小。通过DBCC SHOWCONTIG得到的页数,可以估算出索引的大小(每页大小为8KB)。一般来说,没有必要关注那些碎片级别小于1,000页的索引。在测试中,包含超过10,000页的索引才会影响性能,特别是包含更多的页(超过50,000页)的索引,会引起最大的性能提升。
逻辑扫描碎片(logical scan fragmentation)值太高,会大大降低索引扫描的性能。在测试中,那些逻辑碎片大于10%的聚集索引,在碎片整理后性能得到了提升;对那些大于20%的聚集索引,性能提升尤其明显。因此关注那些逻辑碎片大于等于20%的索引。注意,对于堆(Index ID=0)来说,该标准是无意义的。
平均页密度(average page density)太低,将导致查询中需要读取更多的页。重新组织这些页,可以提高平均页密度,从而完成相同的查询只要读取较少的页。一般来说,在第一次载入数据后,表拥有较高的页密度。随着数据的插入,页密度会降低,从而带来叶级页拆分。检查平均页密度时,记住该值依赖于创建表时设置的填充因子取值。
虽然扫描密度(scan density)可以作为碎片级别的参考,不过当索引跨越多个文件时,该参考无效。因此,当检查跨越多个文件的索引时,扫描密度不应该被考虑。
监视碎片级别
有规律地监控索引的碎片级别是良好的实践习惯。SQL Server联机帮助的"DBCC SHOWCONTIG"主题中,有一个示例脚本,用于自动捕获和重建碎片程度较大的索引。建议每隔一段固定时间就使用带TABLERESULTS选项的DBCC SHOWCONTIG命令,将得到的结果保存在表内。这样做可以使你不受时间限制地监控碎片级别。另外,还建议在繁忙的服务器上使用带有WITH FAST选项的DBCC SHOWCONTIG命令。带有WITH FAST选项的DBCC SHOWCONTIG命令可以避免扫描索引的叶级页,从而是的执行比较快。不过,因为它不扫描叶级页,所以就无法报告页密度指标。
表1 显示在小规模和大规模DSS环境下,运行DBCC SHOWCONTIG命令所需的时间。每次测试中,都带 ALL_INDEXES 和 TABLERESULTS 选项。 表1 DBCC SHOWCONTIG 执行结果 DBCC SHOWCONTIG options Total number of index pages (all indexes) Run time (minutes)
Small-Scale Environment
Not using the WITH FAST option 1,702,889 5.02
Using the WITH FAST option 1,702,889 0.90
Large-Scale Environment
Not using the WITH FAST option 111,626,354 382.35
Using the WITH FAST option 111,626,354 48.73
理解哪些工作类型从索引的碎片整理中获益最多
当你决定进行索引的碎片整理时,理解有些工作类型将比另一些工作类型从碎片整理中获益更多这个结论,是十分重要的。碎片会对I/O带来负面影响。在大范围内用到索引页的查询受碎片的影响最大,从而也最能从碎片整理中获益。
测试利用两种数据库工作类型,比较了碎片整理前和整理后的性能。测试对象包括了具有代表性的OLTP和DSS数据库。OLTP数据库上的工作主要集中在特定范围的数据的更新(insert,update和delete)和有选择性的读取。而对于DSS系统,由于主要是读取工作类型,因此测试集中在多表联接的查询任务。特别是这些查询必须需要扫描到一个或更多的索引。测试结果表明碎片对OLTP工作影响极小,而对DSS系统则从碎片整理获益多多。
DBCC INDEXDEFRAG 和 DBCC DBREINDEX 命令常用来整理索引碎片。对这两个命令特定功能的更详细讨论后面会涉及到。
OLTP型工作量
测试中,OLTP数据库模拟数据仓库环境下的订单处理流程。工作量包括5个存储过程,涉及流程包括新建订单,订单状态查询,分发,库存状态,以及交付流程。存储过程中用到了插入,更新和删除语句以及有目的选择的SELECT查询。
图1 显示了使用DBCC INDEXDEFRAG 和 DBCC DBREINDEX 进行索引碎片整理前后,每个存储过程完成查询时性能的差异。
图1: 碎片整理前后,OLTP型工作环境下,每个存储过程的平均执行时间。值越小表示性能越好。点击看原图
--------------------------------------------------------------------------------
如图1所示,碎片整理前后,存储过程性能差别不是很大。因为存储过程中的基础查询有选择性地选取部分数据,因此索引碎片给性能带来的影响不大。图1还显示运行碎片整理工具的确降低存储过程的性能;不过在存储过程运行期间本身就会给性能带来10%-20%之间的波动。图1显示的差异也在这个范围之内。更重要的是,结果显示当碎片级别上升时,并未带来存储过程性能的下降。
DSS型工作量
测试中,DSS工作量包含22个由复杂SELECT语句构成的报表类型的查询。这些查询严格地以批处理方式在服务器端运行。所有查询包含一个或多个多表联接,大多数查询需要扫描很大范围的索引。
表2 记录测试中用到的索引的平均碎片和页密度级别。碎片级别通过下属行为组合得到:
以Bulk INSERT方式插入新数据到数据库,并模拟周期性地刷新数据。
删除某个范围内的数据。
按关键值执行一些更新操作,虽然这至少会影响碎片级别,不过和插入和删除操作相比,更新涉及到的记录相对还是比较少。
表2 小规模和大规模环境中平均逻辑碎片和页密度测试 Fragmentation level Average logical fragmentation (%) Average page density (%)
Small-Scale Environment
Low (1) 7.8 80.1
Medium (2) 16.6 68.1
High (3) 29.5 69.2
Large-Scale Environment
Low (1) 5.9 84.4
Medium (2) 13.8 70.3
DSS工作类型的测试结果和OLTP工作类型相差很大。在整理索引碎片后,性能提高很明显。因为此时工作量的性能强烈依赖于磁盘吞吐量(大多数查询会包含索引扫描),因此该结果是可以预料到的。下面的图2和图3显示DSS型工作量在整理索引碎片前后的性能收益情况。如图中所示,性能从碎片整理中显著提升。
在小规模环境中,在碎片较低级别,性能提升了60%,而在碎片较高级别提升了460%。在大规模环境中,在碎片较低级别性能提升13%,在中等级别提升了40%。结果显示大规模环境中,碎片对性能影响影响相对较小,这是因为该环境从磁盘子系统的表现获益更多一些。更详细的讨论见本文后面的“碎片对磁盘吞吐量的影响和SQL Server预读管理器”章节。
图2: 小规模环境下,整个DSS型工作量在不同碎片级别下的运行时间。取值越低表示性能越好。 点击看原图
--------------------------------------------------------------------------------
图3: 大规模环境下,整个DSS型工作量在不同碎片级别下的运行时间。取值越低表示性能越好。点击看原图
--------------------------------------------------------------------------------
图2从数值上显示,在小规模环境下,DBCC INDEXDEFRAG的结果比DBCC DBREINDEX要好一些。不过,在大多数情况下,完全重建索引应该具有更好的性能。
在解释这些测试结果时,需要牢记以下几点:
图2和图3显示的结果意味着这是应用DBCC INDEXDEFRAG的“最佳”场合。测试中,DBCC INDEXDEFRAG运行在一个禁止的系统上;因此DBCC INDEXDEFRAG可以完全消除碎片。当DBCC INDEXDEFRAG运行在一个动态的系统上,即数据保持在线更新,DBCC INDEXDEFRAG会跳过那些被锁住的页。因此DBCC INDEXDEFRAG也许就无法完全消除碎片。要衡量DBCC INDEXDEFRAG发挥了多大作用,可以在DBCC INDEXDEFRAG后立刻运行DBCC SHOWCONTIG。
数据的分布情况会影响磁盘性能。小规模环境中,数据只分布在两个物理磁盘(磁盘容量加起来一共33.5GB)上,在数据库创建前,这两个磁盘是空的。数据库创建后,数据文件大小在22GB到30GB之间。当数据库创建时,数据分布在磁盘外围部分。DBCC INDEXDEFRAG整理碎片也是从最邻近原始数据的位置开始。因为DBCC DBREINDEX完全重建索引,在释放旧的索引页前,它必须首先给新索引页分配空间。分配新空间使得数据离原始数据位置较远,并且分布在磁盘内侧,因此造成I/O吞吐量有轻微的下降。在小规模环境下的benchmark测试中,这种下降表现为读取数据吞吐量下降15%。
剩余空间容量同样会影响DBCC DBREINDEX。如果没有大量连续的空闲空间,DBREINDEX会强迫使用数据文件中的空闲空间,从而导致索引重建时带有一小部分数量的逻辑碎片。关于DBCC DBREINDEX对剩余空间的需求的信息,见本文后面的"DBCC DBREINDEX"章节。
确定查询的I/O流量
因为具有大量I/O读写的查询从碎片整理中获益最多,所以讨论如何确定某个特定查询的I/O流量是必要的。SET STATISTICS IO命令可以报告完成一个特定查询时,服务器实例上的读取量和读取类型。可以在查询管理器中选择该命令开关为ON和OFF,使用方法如下:
SET STATISTIC IO ON
GO
SELECT * FROM table_1
GO
SET STATISTIC IO OFF
GO
输出示例
Table 'table_1'.
Scan count 1,
logical reads 12025,
physical reads 0,
read-ahead reads 11421.
表3 关于SET STATISTIC IO 输出结果的描述 Value Description
Scan count Number of scans performed
logical reads Number of pages read from the data cache
physical reads Number of pages read from disk
read-ahead reads Number of pages placed into the cache for the query
通过physical reads和read-ahead reads值,可以对某个特定查询涉及的I/O量有一个估计。physical reads和read-ahead reads都表示从磁盘读取的页数。多数情况下,read-ahead reads比physical reads数值要大。
注意 在通过SQL Profiler 获取信息时,reads列表示的是逻辑读取量(logical reads),而不是物理读取量(physical reads)。
除了重新对页进行排序,通过增加索引叶级页的页密度,索引的碎片整理还降低执行某个查询的I/O数量。页密度的提高导致完成相同的查询需要读取更少的页,从而提高性能。
理解碎片整理带来的影响和SQL Server预读管理器
碎片对大量读取磁盘边缘的操作带来负面影响。可以使用Windows性能监视器来获取这种影响的衡量。通过性能监视器,可以观测磁盘活动情况,并且有助于决定何时进行碎片整理。
为了理解为什么碎片对DSS型工作具有如此的影响,首先很重要的是要理解碎片是如何影响SQL Server预读管理器的。为了完成需要扫描一个或多个索引的查询,SQL Server预读管理器负责提前对索引页进行扫描,并且将额外的数据页放到SQL Server数据缓存中。根据基础页的物理顺序,预读管理器动态地调整读取量。当碎片较少时,预读管理器即时可以读取较大的数据块,更高效地利用I/O子系统。当数据产生碎片时,预读管理器只能读取较小的数据块。预读的数量虽然和数据的物理顺序无关,不过,因为较小的读取请求消耗更多的CPU/时钟,所以最终就会降低整个磁盘的吞吐量。
在所有情况下,预读管理器能提高性能;但是,当存在碎片,且预读管理器无法读取较大的数据块,整个磁盘的吞吐量就下降。通过检查性能监视器中的Physical Disk相关的计数器可以发现该现象。下表列举并描述了这些计数器。 表4 性能监视器中物理磁盘计数器 Physical Disk counter Description
Avg Disk sec/ Read 该计数器用于衡量磁盘延迟。测试显示当碎片出于很高水平(大于等于30%)时,会增加磁盘延迟。
Disk Read Bytes/ sec 该计数器能很好地衡量全面的磁盘吞吐量。一段时间内工作量的下降趋势可以用来表示碎片正在影响性能。
Avg Disk Bytes/ Read 该计数器用于衡量每个读取请求带来的数据读取量。当索引页连续,SQL Server预读管理器可以一次读取较大的数据块,对I/O子系统的利用效率较高。测试显示该计数器值和碎片数量间有着直接联系。当碎片级别上升,该值就下降,从而影响全面的磁盘吞吐量。
Avg Disk Read Queue Length 一般而言,该计数器为每两个物理磁盘上持续的平均数值。测试中,很可能由于较高的延迟和较低的全面磁盘吞吐量,使得该计数器随着碎片的增加而增加。
图4到图7显示在DSS型工作中,性能监视器报告的磁盘吞吐量和平均读取大小。
图4: 小规模环境下,DSS工作流的磁盘吞吐量。数值越高表示磁盘吞吐能力越好。点击看原图
--------------------------------------------------------------------------------
图5: 小规模环境下,DSS工作流的磁盘吞吐量。数值越高表示磁盘吞吐能力越好。点击看原图
--------------------------------------------------------------------------------
图6: 小规模环境下,DSS工作中每次磁盘读取的平均大小。数值越高表示每次读取字节数越多。点击看原图
--------------------------------------------------------------------------------
图7: 小规模环境下,DSS工作中每次磁盘读取的平均大小。数值越高表示每次读取字节数越多。点击看原图
--------------------------------------------------------------------------------
上面的图显示碎片对磁盘性能的影响趋势。虽然使用DBCC DBREINDEX和DBCC INDEXDEFRAG得到的结果不同,但是注意在所有系统上,都得到了一致的结果,即每次读取的平均大小和整体磁盘吞吐量随着碎片的增加而降低。正如你所见的,整理所有碎片对磁盘吞吐量提高极大。
每次读取的平均大小还可以用来展示,碎片是如何影响预读管理器读取较大数据块的能力的。这点需牢记在心,不过,平均读取数量较大并不总是意味着整体吞吐量较高。平均读取量大表示数据传输中,CPU负荷较小。当索引没有碎片时,读取64KB大小数据的速度和读取256KB大小数据的速度几乎一样。这个结论在那些数据分布在多个磁盘上的大型系统而言,尤其如此。这些普遍和特殊的结论,会根据不同的系统,因为各种各样的原因(例如,不同的I/O子系统,工作类型差异,数据在磁盘的分布特征等等)而不同。当监视系统时,寻找那些持续时间较长的磁盘吞吐量和读取数量的下降阶段。这些阶段以及DBCC SHOWCONTIG命令提供的信息,可以用于帮助来确定什么时候该进行索引的碎片整理了。
测试结果显示碎片也会带来磁盘延迟,不过,至于那些最高级别的碎片才会对磁盘延迟带来巨大的负面影响,并且也只在小规模环境下才有此现象。在大规模环境下,由于SAN提供了很高的I/O性能,因此磁盘延迟值十分小而从来不会带来问题。
DBCC DBREINDEX vs. DBCC INDEXDEFRAG
除了使用CREATE INDEX命令来删除或者重新创建索引,还可以使用DBCC DBREINDEX和DBCC INDEXDEFRAG命令来帮助维护索引。
DBCC DBREINDEX
DBCC DBREINDEX用于在指定的表上重建一个或多个索引。DBCC DBREINDEX是离线操作方式。当该操作运行时,涉及到的表就无法被用户访问。DBCC DBREINDEX动态地重建索引。没有必要知道参与重建的表结构到底如何,是否用主键或者唯一性约束等信息;重建的时候会自动管理的。DBCC DBREINDEX完全重建索引,也就是说,将页密度级别恢复到最初(默认)的填充因子水平;当然你也可以选择页密度的新值。从内部运行看,DBCC DBREINDEX和手工用T-SQL语句来运行删除然后重新创建索引十分相似。
下面两点是DBCC DBREINDEX比DBCC INDEXDEFRAG优越的地方:
DBCC DBREINDEX在重建索引过程中,自动重建统计;这将显著提高工作性能。
DBCC DBREINDEX可以运行在多处理器环境下,利用多处理器的优势,当重建较大和碎片厉害的索引时,速度可以十分快。
DBCC DBREINDEX的所有工作是一个单一的,原子事务。必须完成创建新的索引并替换旧索引,然后旧索引页被释放。完成重建需要数据文件中有足够的空余空间。如果空余空间不够,DBCC DBREINDEX要么无法重建索引,要么会产生大于0的逻辑碎片。所需空余空间视情况而定,取决于事务中要创建的索引数目。对于聚集索引而言,一个不错的指导公式为:所需空余空间 = 1.2 * (平均行大小) * (行数量)。
对于非聚集索引,可以通过计算非聚集索引包含的每行平均大小(非聚集索引包含关键字长度 + 聚集中的索引关键字或者row ID长度)乘以行数量得到所需空间。如果对整个表进行索引重建,需要为聚集索引和非聚集索引留出足够的空间。同样,如果重建不唯一非聚集索引,也需要为聚集和非聚集索引留出空余空间。因为SQL Server必须为每行创建唯一标识,因此非聚集索引是隐式重建的。使用DBCC DBREINDEX时,较佳的做法是指定那些索引需要整理。这样做可以使得对操作有更多的控制力,以及避免不必要的麻烦。
DBCC INDEXDEFRAG
DBCC INDEXDEFRAG用于对指定的索引进行重建。和DBCC DBREINDEX类似,也不需顾及表的基础结构;不过,DBCC INDEXDEFRAG无法用一个语句对所有的索引进行重建。对于每个希望进行碎片整理的索引,都必须运行一次DBCC INDEXDEFRAG。
和DBCC DEREINDEX不同的是,DBCC INDEXDEFRAG是在线操作的;因此在整理索引碎片时,仍然可以访问被整理到的表和索引。另外一个和DBCC INDEXDEFRAG很不同的地方是,DBCC INDEXDEFRAG可以中止和重新开始而不丢失任何工作信息。整个DBCC DBREINDEX操作作为一个原子事务运行。这意味着如果中止DBCC DBREINDEX操作,整个操作会回滚,继续的话必须重新开始。但是,如果中止DBCC INDEXDEFRAG,任务会立刻中止并不会丢失已经完成的任务,因为DBCC INDEXDEFRAG每个工作单位是独立的事务。
DBCC INDEXDEFRAG包括两个阶段:
压缩页并试图根据索引创建时指定的填充因子来调整页密度。DBCC INDEXDEFRAG会根据最初的填充因子,尽可能提高页密度级别。而DBCC INDEXDEFRAG不会,但是它会将那些高于最初填充因子的页密度降低。
通过移动页来使得物理顺序和索引叶级页的逻辑顺序一致,从而整理索引碎片。这个工作由一系列独立的很小的事务来完成;因此DBCC INDEXDEFRAG对整体系统性能,影响很小。图8显示DBCC INDEXDEFRAG的碎片整理阶段中页移动情况。
图8: DBCC INDEXDEFRAG的数据文件页移动情况
--------------------------------------------------------------------------------
DBCC INDEXDEFRAG并不会帮助整理分散插入到数据文件中的索引,这种分散插入称为Interleave。同样,DBCC INDEXDEFRAG也不对扩展页碎片进行整理。当索引扩展页(扩展页=8页)中的数据并不连续的时候,出现Interleave,此时多个扩展页的数据在文件中是交叉状态。因为即使逻辑顺序和物理顺序一致情况下,所有的索引页也不见得一定是连续的,因此即使没有逻辑碎片情况下,Interleave也会存在。
虽然上面提到了DBCC INDEXDEFRAG的限制,但是测试显示,DBCC INDEXDEFRAG对性能的改善和DBCC DBREINDEX一样有用。实际上,从测试结果可以看出,即使重建了索引,使得Interleave最小,这部分优化并不会对性能带来显著提升。减少逻辑碎片级别这部分优化才对性能提升最多。这就是为什么检查索引碎片时,建议将重点放在逻辑碎片整理和页密度碎片上的原因。表5总结了DBCC DBREINDEX和DBCC INDEXDEFRAG之间的差别。 表5 DBCC DBREINDEX 和 DBCC INDEXDEFRAG的比较 Functionality DBCC DBREINDEX DBCC INDEXDEFRAG
Online/Offline Offline Online
Faster when logical fragmentation is: High Low
Parallel processing Yes No
Compacts pages Yes Yes
Can be stopped and restarted without losing work completed to that point No Yes
Able to untangle interleaved indexes May reduce interleaving No
Additional free space is required in the data file for defragmenting Yes No
Faster on larger indexes Yes No
Rebuilds statistics Yes No
Log space usage High in full recovery mode (logs entire contents of the index), low in bulk logged or simple recovery mode (only logs allocation of space) Varies based on the amount of work performed
May skip pages on busy systems No Yes
性能: DBCC DBREINDEX vs. DBCC INDEXDEFRAG
测试显示,无论是DBCC DBREINDEX还是DBCC INDEXDEFRAG,都可以有效地整理索引碎片,并将页密度恢复到初始填充因子规定的页密度附近。基于这些结果,下面需要决定什么时候应用哪种整理方式。
如果允许有一段时间进行离线索引重建,DBCC DBREINDEX一般来说比DBCC INDEXDEFRAG要快。DBCC DBREINDEX可以充分利用多处理器系统的平行性能。DBCC INDEXDEFRAG用于对生产环境干扰不大,对工作性能影响不大的场合。测试显示,即使同时几个DBCC INDEXDEFRAG并行工作,对性能下降的影响也从来不会超出10%。但是,这也同样使得DBCC INDEXDEFRAG针对较大的索引整理时,需要很长的时间才能完成。而且,工作时间的长短还依赖于当时在服务器上运行的访问工作。
图9为DBCC INDEXDEFRAG和DBCC DBREINDEX的性能比较。图中的数据为小规模环境下,对所有索引进行整理的时间(大规模环境下结果类似,DBCC INDEXDEFRAGY运行时间为DBCC INDEXREINDEX的8倍)。当碎片级别增加,索引大小增加时,DBCC DBREINDEX可以比DBCC INDEXDEFRAG执行得更快。
图9: 小规模环境下,整理所有索引碎片所需时间点击看原图
--------------------------------------------------------------------------------
日志考虑: DBCC DBREINDEX vs. DBCC INDEXDEFRAG
最后要考察的问题是使用DBCC INDEXDEFRAG和DBCC DBREINDEX时,写入事务日志的数据量差别。DBCC INDEXDEFRAG中写入事务日志的数据量依赖于碎片的级别和完成的工作量。测试显示,当数据库完全恢复模式下,DBCC INDEXDEFRAG写入事务日志的数据量远远小于DBCC DBREINDEX。DBCC INDEXDEFRAG的日志数据量,可以变化很大。这是因为DBCC INDEXDEFRAG完成的碎片整理工作量由页移动数量和必要的页压缩数量决定。因为DBCC INDEXDEFRAG工作由一系列小事务组成,因此可以通过备份来回收DBCC INDEXDEFRAG使用的那部分日志空间。
从日志使用的角度看,DBCC DBREINDEX和DBCC INDEXDEFRAG稍有不同;在大批量(bulk)日志恢复模式下,日志量具有最大的差异。在完全恢复模式下,DBCC DBREINDEX对每个索引页有日志镜像,在日志恢复模式下,就没有。因此,在完全恢复模式下,DBCC DBREINDEX所需的日志空间大约等于索引页数量乘以8KB。可以通过DBCC SHOWCONTIG来确定给定索引的页数量。在大规模环境下,运行DBCC DBREINDEX时,建议将恢复模式改为日志恢复模式。而在运行结束后,再改为完全恢复模式。
注意:由于大规模环境下,回滚事务需要付出巨大的时间代价,因此理解日志的需求很重要。
图10 显示在小规模和中度碎片级别环境下,DBCC INDEXDEFRAG和DBCC DBREINDEX日志空间使用的差别。虽然DBCC INDEXDEFRAG日志空间波动很大,不过测试结果可以体现DBCC DBREINDEX和DBCC INDEXDEFRAG的一般性差别。
图10: 对DSS型数据库所有索引碎片整理时,DBCC INDEXDEFRAG和DBCC DBREINDEX所用的整个日志空间点击看原图
--------------------------------------------------------------------------------
结论
对于不同的工作类型,索引碎片整理具有十分不同的影响。某些应用可以从碎片整理中获取很大的性能提升。理解应用特征,系统性能和SQL Server提供的碎片统计信息,是正确决定何时进行碎片整理的关键。SQL Server提供一些命令来完成索引碎片整理。本文可以帮助我们来决定何时以及如何整理索引碎片,从而使性能得到最大的改善。
一、总结
1、数据库的存储本身是无序的,建立聚集索引之后,就会按照聚集索引的物理顺序存入硬盘;
2、建立索引完全是为了提升读取的速度,相对写入的速度就会降低,没有索引的表写入时最快的,但是大多数系统读的频率要高于写的频率;
3、索引碎片分为内部碎片和外部碎片。
内部碎片:是指索引页没有100%存储满,有剩余空间,这就是内部碎片;产生原因是在insert或者update数据时,该页不足以放下新增或更新的数据,造成分页,导致索引页的平均密度变小,就产生了内部碎片;
外部碎片:是指做插入或更新操作时,原来页无法容纳新的行,导致分页(分页会将原来页大约一半的数据放到新页上,达到一个平衡状态),而新的页和原来的页在物理上又不连续了(分页之前,他们之间有好多页面),而聚集索引要求行之前是连续的,所以分页后,新叶和原来页物理上的不连续是造成外部碎片的原因。
4、修改填充因子,也有可能解决索引碎片的问题,一千万的数据量修改填充因子用了1分钟(只是测试,表没有做删除的操作);
5、索引碎片查出的记录数(record_count)与直接select count(*)查出的数据量可能不一样,具体解释参考下面对字段意思的解释处;

7.如果数据库里有批量数据的删除,导致avg_page_space_used_in_percent页的百分比变小,产生了碎片,这个时候可以通过收缩数据文件来增大页百分比,释放更多的空间(已测试过,但是做数据文件的收缩要慎重)
二、具体SQL操作
1.查看索引碎片
命令:SELECT page_count,avg_page_space_used_in_percent,record_count,
avg_record_size_in_bytes,avg_fragmentation_in_percent,fragment_count
FROM sys.dm_db_index_physical_stats(DB_ID('run'),object_id('dbo.Person'),NULL,NULL,'sampled')
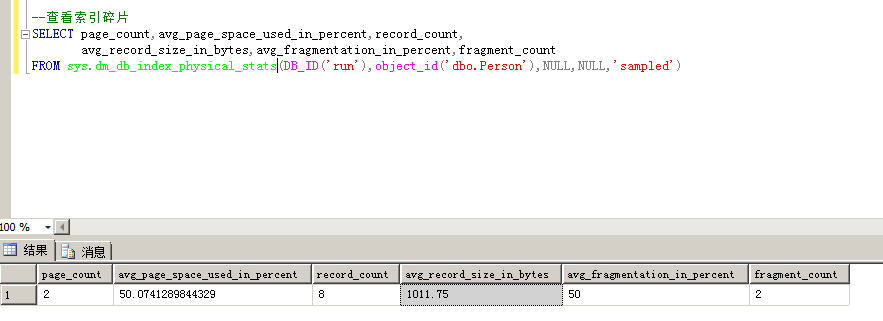
page_count:索引或数据页的总数
avg_page_space_used_in_percent:平均数据页面使用空间的百分比
record_count:记录数,该数可能与对表查询select count(*)查出的结果值不一样,这是因为一行可能包含多个记录,比如LOB字段或可变长度的数据等等,详情参考官方解释
avg_record_size_in_bytes:平均每条记录数的大小(字节)
avg_fragmentation_in_percent:索引的逻辑碎片,按百分比计算,值越小表示碎片越少,平均每个区的剩余空间(也就是碎片的百分比)
fragment_count:叶级别中的碎片数(外部碎片的数量),也有可能是小的表保存在混合区上
官方参考地址:sys.dm_db_index_physical_stats (Transact-SQL) | Microsoft Learn

2.显示数据库里所有索引的碎片信息
命令:
use [run]
DBCC SHOWCONTIG WITH ALL_INDEXES

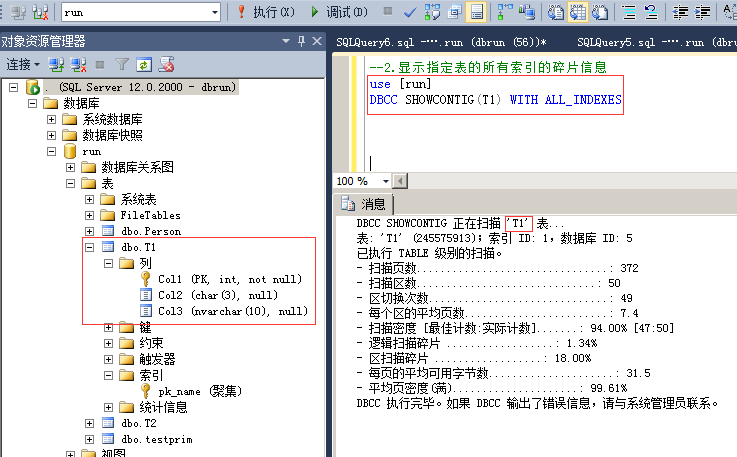
3.显示指定表的所有索引的碎片信息
命令:
use [run]
DBCC SHOWCONTIG(T1) WITH ALL_INDEXES
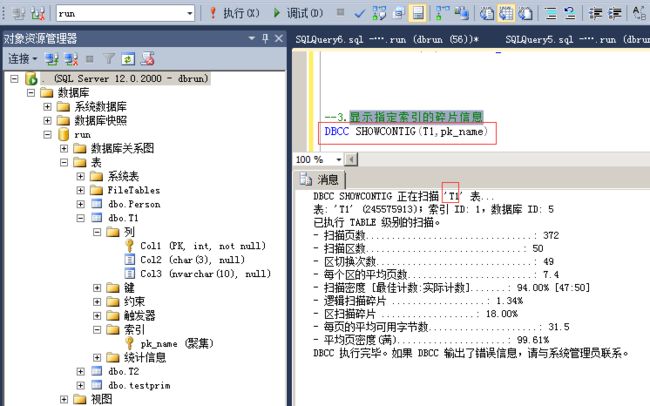
4.显示指定索引的碎片信息
命令:
DBCC SHOWCONTIG(T1,pk_name)
查出结果的解释:
扫描页数:该表的数据存储的页数;
扫描区数:一个区有8页,用扫描页数除以8可以得出估计的区数,如果扫描出的区数比你算出的要多,说明存在外部碎片,比算出的值高的多,说明外部碎片越多(如果数据量少的话不能作为参考值,比如扫面页数少于8页,就可能是存储在混合区里,不是单独给该表分配的区);
扫描密度:最佳值:实际值,该比值应该尽可能接近100%,低了说明有外部碎片;
逻辑扫描碎片:无序页的百分比,该比值应该在0%到10%之间,高了则说明有外部碎片;
区扫描碎片:无序扩展盘区在扫面索引叶级页中所占的百分比。该百分比高,说明有外部碎片;
每页的平均可用字节数:每页还剩余的空间,剩的越多说明有内部碎片,这个值要参考是否有设置填充因子,默认填充因子是0,就是页100%填充数据,如果填充因子是80%,就表示只填充80%的数据,剩下的20%留着给insert和update使用,以防做插入和更新时出现分页的情况。
平均密度:每页上数据量的密度,该值越高,表示每页填充的越满,值越低,表示每页上剩余空间越多,内部碎片越多。这个是相对的,要看系统读写比例,密度越低,页上剩余的空间大,插入更新数据时的性能就会越好(不会造成分页);相反密度越高,页上剩余空间小,插入更新数据时可能会造成分页,性能就会低,相反查询的性能就会好,因为扫描的页少,跨区扫描页少,所以查询性能会好;
5、查看索引的填充因子
命令:
select object_name(object_id) as tname,name as indexName,type_desc,fill_factor
from run.sys.indexes where name='pk_name'
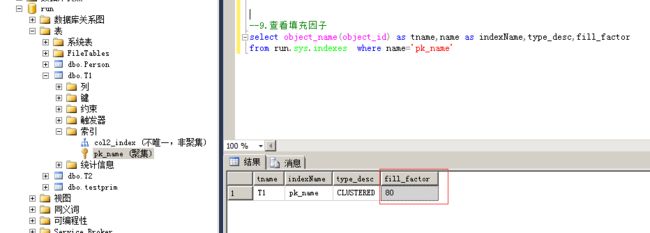
6.修改索引的填充因子
注:也是在图形化页面修改,也可以生成脚本
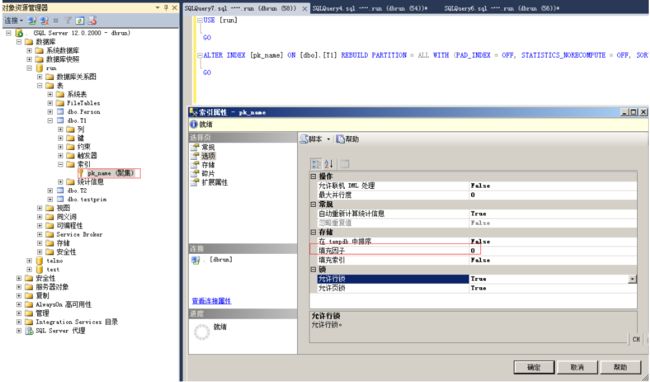
命令:alter index pk_name on dbo.T1 rebuild with (fillfactor=80)

7、打开IO统计,查看查询读取磁盘的IO次数
命令:
set statistics io on
select top 100 col2 from run.dbo.T1 where col2='99'
set statistics io off

三、索引碎片的解决办法
1、删除索引重新创建
这种操作会造成阻塞,会导致非聚集索引重建2次(删除重建,建立重建),数据量大的情况下耗时非常长,生产环境不建议这么做。
2.使用drop_existing语句重建索引
该方法可以避免重建2次索引,因为该语句是原子性的,不会导致非聚集索引重建2次,但同样会造成阻塞。
该方法可以重新创建使用约束的索引(如:唯一性约束)
命令:create unique clustered index pk_name on T1(Col1) with (drop_existing=on)

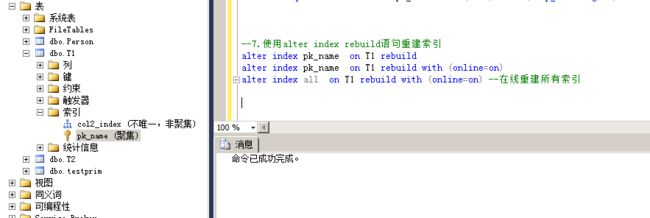
3.使用alter index rebuild语句重建索引
该种方式也是重建索引,但是是动态重建索引而不是卸载在重新重建,但是依旧会造成阻塞;
可以通过online关键字减少锁,但是会造成重建时间加长;
原子性操作,中途终止会事务回滚;
命令:
alter index pk_name on T1 rebuild
alter index pk_name on T1 rebuild with (online=on)
alter index all on T1 rebuild with (online=on) --在线重建所有索引
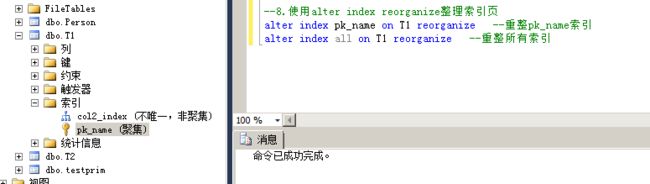
4.使用alter index reorganize整理索引页
该种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级节点,当遇到加锁的页时跳过,所以不会造成阻塞,但整理效果会比前3种差。
重整索引不会锁定任何对象,它仅仅是优化当前的B树的叶子节点。
命令:
alter index pk_name on T1 reorganize --重整pk_name索引
alter index all on T1 reorganize --重整所有索引