LangChain学习指南(二)——Retrieval
在上一章中,已经介绍了Langchain最最核心的module——model IO之后,本章继续介绍另一重要的模块Retrieval。
Retrieval这一模块在开发应用时也是至关重要的一部分,直接汉译过来即”检索“。该功能经常被应用于构建一个“私人的知识库”,构建过程更多的是将外部数据存储到知识库中,而细化这一模块的主要职能有四部分,其包括数据的获取、整理、存储和查询。这里参考一下第一篇文章中展示的结构图: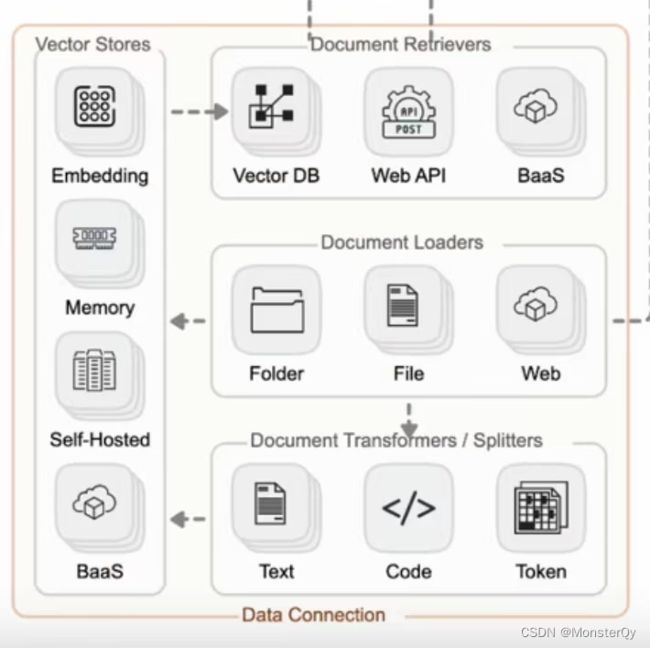
首先,在该过程中可以从本地/网站/文件等资源库去获取数据,当数据量较小时,我们可以直接进行存储,但当数据量较大的时候,则需要对其进行一定的切片,切分时可以按照数据类型进行切片处理,比如针对文本类数据,可以直接按照字符、段落进行切片;代码类数据则需要进一步细分以保证代码的功能性;此外,除了按照数据类型进行切片处理,也可以直接根据token进行切片。而后利用Vector Stores进行向量存储,其中Embedding完成的就是数据的向量化,虽然这一能力往往被嵌套至大模型中,但是我们也要清楚并不是所有的模型都能直接支持文本向量化这一能力的。除此之外的memory、self-hosted以及baas则是指向量存储的三种载体形式,可以选择直接存储于内存中,也可以选择存储上云。最后则利用这些向量化数据进行检索(Documnet Retrievers)检索形式可以是直接按照向量相似度去匹配相似内容,也可以直接网络,或者借用其他服务实现检索以及数据的返回。
一.向量数据库
1.1基本概念
从上文中我们可以发现,对于retrievers来说,向量数据库发挥着很大的作用,它不仅实现向量的存储也可以通过相似度实现向量的检索,但是向量数据库到底是什么呢?它和普通的数据库有着怎样的区别呢?相信还是有很多同学和我一样有一点点疑惑,所以在介绍langchain在此module方面的能力前,先介绍一下向量数据库,以及它在LLM中所发挥的作用。
我们在对一个事物进行描述的时候,通常会根据事物的各方面特征进行表述。设想这样一个场景,假设你是一名摄影师,拍了大量的照片。为了方便管理和查找,你决定将这些照片存储到一个数据库中。传统的关系型数据库(如 MySQL、PostgreSQL 等)可以帮助你存储照片的元数据,比如拍摄时间、地点、相机型号等。但是,当你想要根据照片的内容(如颜色、纹理、物体等)进行搜索时,传统数据库可能无法满足你的需求,因为它们通常以数据表的形式存储数据,并使用查询语句进行精确搜索。但向量包含了大量信息,使用查询语句很难精确地找到唯一的向量。
那么此时,向量数据库就可以派上用场。我们可以构建一个多维的空间使得每张照片特征都存在于这个空间内,并用已有的维度进行表示,比如时间、地点、相机型号、颜色…此照片的信息将作为一个点,存储于其中。以此类推,即可在该空间中构建出无数的点,而后我们将这些点与空间坐标轴的原点相连接,就成为了一条条向量,当这些点变为向量之后,即可利用向量的计算进一步获取更多的信息。当要进行照片的检索时,也会变得更容易更快捷。但在向量数据库中进行检索时,检索并不是唯一的而是查询和目标向量最为相似的一些向量,具有模糊性。
那么我们可以延伸思考一下,只要对图片、视频、商品等素材进行向量化,就可以实现以图搜图、视频相关推荐、相似宝贝推荐等功能,那应用在LLM中,小则可直接实现相关问题提示,大则我们完全可以利用此特性去历史对话记录中找到一些最类似的对话,然后重新喂给大模型,这将极大的提高大模型的输出结果的准确性。
为更好的了解向量数据库,接下来将继续介绍向量的几种检索方式,以对向量数据库有一个更深度的了解。
1.2存储方式
因为每一个向量所记录的信息量都是比较多的,所以自然而然其所占内存也是很大的,举个例子,如果我们的一个向量维度是256维的,那么该向量所占用的内存大小就是:256*32/8=1024字节,若数据库中共计一千万个向量,则所占内存为10240000000字节,也就是9.54GB,已经是一个很庞大的数目了,而在实际开发中这个规模往往更大,因此解决向量数据库的内存占用问题是重中之重的。我们往往会对每个向量进行压缩,从而缩小其内存占用。常常利用乘积量化方法
乘积量化:该思想将高维向量分解为多个子向量。例如,将一个D维向量分解为m个子向量,每个子向量的维度为D/m。然后对每个子向量进行量化。对于每个子向量空间,使用聚类算法将子向量分为K个簇,并将簇中心作为量化值。然后,用子向量在簇中的索引来表示原始子向量。这样,每个子向量可以用一个整数(量化索引)来表示。最后将量化索引组合起来表示原始高维向量。对于一个D维向量,可以用m个整数来表示,其中每个整数对应一个子向量的量化索引。此外这类方法不仅可以用于优化存储向量也可以用于优化检索。
1.3检索方式
通过上段文字的描述,我们不难发现,向量检索过程可以抽象化为“最近邻问题“,对应的算法就是最近邻搜索算法,具体有如下几种:
1.暴力搜索:依次比较向量数据库中所有的的向量与目标向量的相似度,然后找出相似度最高一个或一些向量,这样得到的结果质量是极高的,但这对于数据量庞大的数据库来说无疑是十分耗时的。
2.聚类搜索:这类算法首先初始化K个聚类中心,将数据对象分组成若干个类别或簇(cluster)。其主要目的是根据数据的相似性或距离度量来对数据进行分组,然后根据所选的聚类算法,通过迭代计算来更新聚类结果。例如,在K-means算法中,需要不断更新簇中心并将数据对象分配给最近的簇中心;在DBSCAN算法中,需要根据密度可达性来扩展簇并合并相邻的簇。最后设置一个收敛条件,用于判断聚类过程是否结束。收敛条件可以是迭代次数、簇中心变化幅度等。当满足收敛条件时,聚类过程结束。这样的搜索效率大大提高,但是不可避免会出现遗漏的情况。
3.位置敏感哈希:此算法首先选择一组位置敏感哈希函数,该函数需要满足一个特性:对于相似的数据点,它们的哈希值发生冲突的概率较高;对于不相似的数据点,它们的哈希值发生冲突的概率较低。而后利用该函数对数据集中的每个数据点进行哈希。将具有相同哈希值的数据点存储在相同的哈希桶中。在检索过程中,对于给定的查询点,首先使用LSH函数计算其哈希值,然后在相应的哈希桶中搜索相似的数据点。最后根据需要,可以在搜索到的候选数据点中进一步计算相似度,以找到最近邻。
4.分层级的导航小世界算法:这是一种基于图的近似最近邻搜索方法,适用于大规模高维数据集。其核心思想是将数据点组织成一个分层结构的图,使得在高层次上可以快速地找到距离查询点较近的候选点,然后在低层次逐步细化搜索范围,从而加速最近邻搜索过程。
该算法首先创建一个空的多层图结构。每一层都是一个图,其中节点表示数据点,边表示节点之间的连接关系。最底层包含所有数据点,而上层图只包含部分数据点。每个数据点被分配一个随机的层数,表示该点在哪些层次的图中出现。然后插入数据点:对于每个新插入的数据点,首先确定其层数,然后从最高层开始,将该点插入到相应的图中。插入过程中,需要找到该点在每层的最近邻,并将它们连接起来。同时,还需要更新已有节点的连接关系,以保持图的导航性能。其检索过程是首先在最高层的图中找到一个起始点,然后逐层向下搜索,直到达到底层。在每一层,从当前点出发,沿着边进行搜索,直到找到一个局部最近邻。然后将局部最近邻作为下一层的起始点,继续搜索。最后,在底层找到的结果则为最终结果。
1.4向量数据库与AI
前文中大概介绍了向量数据库是什么以及向量数据库所依赖的一些实现技术,接下来我们来谈论一下向量数据库与大模型之间的关系。为什么说想要用好大模型往往离不开向量数据库呢?对于大模型来讲,处理的数据格式一般都是非结构化数据,如音频、文本、图像…我们以大语言模型为例,在喂一份数据给大模型的时候,数据首先会被转为向量,在上述内容中我们知道如果向量较近那么就表示这两个向量含有的信息更为相似,当大量数据不断被喂到大模型中的时候,语言模型就会逐渐发现词汇间的语义和语法。当用户进行问答的时候,问题输入Model后会基于Transformer架构从每个词出发去找到它与其他词的关系权重,找到权重最重的一组搭配,这一组就为此次问答的答案了。最后再将这组向量返回回来,也就完成了一次问答。当我们把向量数据库接入到AI中,我们就可以通过更新向量数据库的数据,使得大模型能够不断获取并学习到业界最新的知识,而不是将能力局限于预训练的数据中。这种方式要比微调/重新训练大模型的方式节约更多成本。
二.Langchain中的retrieval
2.1DataLoaders
上文中我们已经知道,一般在用户开发(LLM)应用程序,往往会需要使用不在模型训练集中的特定数据去进一步增强大语言模型的能力,这种方法被称为检索增强生成(RAG)。LangChain 提供了一整套工具来实现 RAG 应用程序,首先第一步就是进行文档的相应加载即DocumentLoader:
LangChain提供了多种文档加载器,支持从各种不同的来源加载文档(例如,私有的存储桶或公共网站),支持的文档类型也十分丰富:如 HTML、PDF 、MarkDown文件等…
# 1.加载 md文件。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")# 路径。
print(loader.load())
可以看到文件被成功加载
# 2.加载 CSV 数据,每个文档一行。
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./index.csv')
data = loader.load()
# 3.自定义 csv 解析和加载 指定csv文件的字段名fieldname即可
loader = CSVLoader(file_path='./index.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['title','content']
})
data = loader.load()
# 4.可以使用该 source_column 参数指定文件加载的列。
loader = CSVLoader(file_path='./index.csv', source_column="context")
data = loader.load()
————————————————————————————————————————————
除了上述的单个文件加载,我们也可以批量加载一个文件夹内的所有文件,该加载依赖unstructured,所以开始前需要pip一下。如加载md文件就:pip install “unstructured[md]”
从文件夹加载所有文档
from langchain.document_loaders import DirectoryLoader
#使用 glob 参数来控制要加载的文件。它不支持 .rst 文件和 .html 文件。可以开启多线程进行加载.
loader = DirectoryLoader('/Users/kyoku/Desktop/LLM/documentstore', glob='**/*.md', use_multithreading=True
)
docs = loader.load()
len(docs)
对于html文件的加载,往往依赖于其他loader如UnstructuredHTMLLoader/BSHTMLLoader
#html
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("./index.html")
data = loader.load()
# 使用 BeautifulSoup4 加载 HTML 4
from langchain.document_loaders import BSHTMLLoader
loader = BSHTMLLoader("./index.html")
data = loader.load()
2.2文本拆分DataTransformers
当文件内容成功加载之后,通常会对数据集进行一系列处理,以便更好地适应你的应用。比如说,可能想把长文档分成小块,这样就能更好地放入模型。LangChain 提供了很多现成的文档转换器,可以轻松地拆分、组合、过滤文档,还能进行其他操作。
虽然上述步骤听起来较为简单,但实际上有很多潜在的复杂性。最好的情况是,把相关的文本片段放在一起。这种“相关性”可能因文本的类型而有所不同。
Langchain提供了工具RecursiveCharacterTextSplitter用来进行文本的拆分,其运行原理为:首先尝试用第一个字符进行拆分,创建小块。如果有些块太大,它就会尝试下一个字符,以此类推。默认情况下,它会按照 [“\n\n”, “\n”, " ", “”] 的顺序尝试拆分字符。以下为示例代码:
# 打开一个文本
with open('./test.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
可以看到是被拆分成了一个数组的形式。![]()
除了上述的文本拆分,代码拆分也经常被应用于llm应用的构建中:
# CodeTextSplitter 允许您使用多种语言支持拆分代码。导入枚举 Language 并指定语言。
# 支持的语言'cpp', 'go', 'java', 'kotlin', 'js', 'ts', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol', 'csharp', 'cobol'
#下面是一个使用 PythonTextSplitter 的示例
from langchain.text_splitter import (RecursiveCharacterTextSplitter, Language)
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
调用特定的拆分器可以保证拆分后的代码逻辑,这里我们只要指定不同的Language就可以对不同的语言进行拆分。
2.3向量检索简单应用
在实际开发中我们可以将数据向量化细分为两步:一是将数据向量化(向量化工具:openai的embeding、huggingface的n3d…),二是将向量化后的数据存储到向量数据库中,常见比较好用的免费向量数据库有Meta的faiss、chrome的chromad以及lance。
1.高性能:利用 CPU 和 GPU 的并行计算能力,实现了高效的向量索引和查询操作。
2.可扩展性:支持大规模数据集,可以处理数十亿个高维向量的相似性搜索和聚类任务。
3.灵活性:提供了多种索引和搜索算法,可以根据具体需求选择合适的算法。
4.开源:是一个开源项目,可以在 GitHub 上找到其源代码和详细文档。
安装相关库:
pip install faiss-cpu (显卡好的同学也可以install gpu版本)
准备一个数据集,这个数据集包含一段关于信用卡年费收取和提高信用卡额度的咨询对话。客户向客服提出了关于信用卡年费和额度的问题,客服则详细解答了客户的疑问:
text = """客户:您好,我想咨询一下信用卡的问题。\n客服:您好,欢迎咨询建行信用卡,我是客服小李,请问有什么问题我可以帮您解答吗?\n客户:我想了解一下信用卡的年费如何收取?\n客服:关于信用卡年费的收取,我们会在每年的固定日期为您的信用卡收取年费。当然,如果您在一年内的消费达到一定金额,年费会自动免除。具体的免年费标准,请您查看信用卡合同条款或登录我们的网站查询。\n客户:好的,谢谢。那我还想问一下,如何提高信用卡的额度?\n客服:关于提高信用卡额度,您可以通过以下途径操作:1. 登录建行信用卡官方网站或手机APP,提交在线提额申请;2. 拨打我们的客服热线,按语音提示进行提额申请;3. 您还可以前往附近的建行网点,提交提额申请。在您提交申请后,我们会根据您的信用状况进行审核,审核通过后,您的信用卡额度将会相应提高。\n客户:明白了,非常感谢您的解答。\n客服:您太客气了,很高兴能够帮到您。如果您还有其他问题,请随时联系我们。祝您生活愉快!"""
list_text = text.split('\n')
#用openai的embedding工具即可,不过注意这个也是收费的
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
db = FAISS.from_texts(list_text, OpenAIEmbeddings())#存储向量化后的数据
# 相似性搜索
query = "信用卡的额度可以提高吗"
docs = db.similarity_search(query)
print(docs[0].page_content)
# 输出:客户:好的,谢谢。那我还想问一下,如何提高信用卡的额度?
# 上述介绍的是第一种方法去检索相似向量,除此之外还可以先将检索句进行向量化,然后用向量化后数据进行匹配
# 按向量搜索相似性
embedding_vector = OpenAIEmbeddings().embed_query(query)
print(f'embedding_vector:{embedding_vector}')
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)# 输出:结果是一样的
除了上述直接输出效果最好的结果,也可以按照相似度分数进行输出,不过这里的规则是分数越低,相似度越高。
#带分数的查找
docs_and_scores = db.similarity_search_with_score(query)
docs_and_scores
如果每次都要调用embedding无疑太浪费,所以最后我们也可以直接将数据库保存起来,避免重复调用。
# 保存和加载
db.save_local("faiss_index")
new_db = FAISS.load_local("faiss_index", OpenAIEmbeddings())
在官网中还介绍了另外两种向量数据库的使用方法,这里不再赘述。